分級智能工業互聯網業務執行可靠性與時延性能分析
2021-11-24 07:39:38馬俊超黃永明
無線電通信技術 2021年6期
關鍵詞:用戶
馬俊超,黃永明
(網絡通信與安全紫金山實驗室,江蘇 南京 211111)
0 引言
工業互聯網(Industrial Internet of Things,IIoT)是工業3.0向工業4.0演進的重要標志。工業4.0的一個趨勢是將原有的有線設施更換為無線設備[1-2],這樣可以提高網絡的可擴展性、靈活性和移動性,也方便未來網絡的升級,節約成本。但是設備的移動進一步加劇了傳輸環境的復雜性,無線設備替代有線設施也會帶來負面的影響。比如,現階段無線環境無法提供有線傳輸那樣可靠且高速的傳輸。因此,如何為工業互聯網提供高可靠低時延的傳輸環境是5G和6G網絡的一個研究熱點[3]。
工業4.0的另一個趨勢是業務復雜度的大幅提升,同時業務執行趨向自動化。比如,在芯片生產中需要檢查制造的芯片產品是否合格、是否存在瑕疵。在傳統工業環境中,這個任務通常由人工執行,即檢查員通過檢查芯片的外表確定該產品是否合格。受益于人工智能的長足發展,基于自動化的工業互聯網中,該任務則由系統計算節點自動化完成。具體來說,該計算節點存儲、計算和訓練人工智能模型(深度神經網絡、卷積神經網絡等)及相應參數[4-5]。當產品到達時,附近的相機通過拍照得到一組該產品的圖像,這些圖像作為人工智能模型的輸入,經過一系列的計算和推演,可以得到芯片產品的特征并以此判定該產品是否合格[6]。
自動化的任務執行優勢為:① 自動化任務執行節省了人力成本;② 隨著計算和存儲資源成本的降低,各網絡節點均可承擔一定計算任務,并且自動識別的計算時延可能低于人工識別。然而自動化也有其自身的挑戰。首先,自動識別結果的可靠性依賴于人工智能模型性能和數據的完整性。如果人工智能模型的參數不精確或者輸入的數據不完整、不充分,則推演的結果很可能出現錯誤或不精確的現象。一般而言,人工智能模型越復雜、參數越完整則需要的存儲空間和計算容量越大;其次,任務執行的節點可能離相機很遠,數據的傳輸會引發過長的時延,甚至傳輸中斷,影響任務執行在可靠性和時延方面的性能[7]。
因此,人工智能計算節點的部署和計算及存儲容量的配置對工業互聯網任務執行的影響很大。未來的工業互聯網普遍采用分級智能的網絡架構,即將網絡按照離用戶的距離以及集中程度分配不同的智能[8-9]。具體來說,離用戶較近的本地端節點只服務于小范圍內的用戶,遵循一種分布式的網絡架構,可以處理近實時的業務,一般都配備有限的存儲和計算資源;相反,離用戶較遠的云端節點組成了一種集中式的網絡架構,一般處理非近實時的業務,并且配備相對豐富的存儲和計算資源。
在基于分級智能的工業互聯網環境下,執行任務節點的選擇及對應的資源分配對任務執行性能有很大影響。比如,任務在離用戶較近的近實時本地節點進行計算時,其時延主要來自于計算過程。此外,由于本地節點只能運行輕量級計算模型且沒有太多數據進行訓練計算,導致結果的精確度和可信度并不高[10]。相反,若任務內容數據被上傳至離用戶較遠的非實時計算節點進行任務執行,時延主要來自于數據的傳輸過程及后續的計算過程[11-13],因為遠端節點普遍有充足的計算資源及訓練參數,因此計算結果的精確度和準確性普遍高于本地節點的計算可靠性。
從內容的角度出發,數據內容特點也會對任務的執行帶來影響。比如,某些任務數據量較少,但是計算非常復雜;而有些任務數據量龐大,但是計算操作相對簡單。工業視覺業務員的任務數據通常是以視頻或圖片等數據形式呈現,而經過編碼技術(如可伸縮編碼方案)部分數據即可表征視頻/圖片內容[14-15]。在這種情況下,網絡可以傳輸和計算部分數據內容并返回計算結果,以降低任務執行時延,但相應計算結果的可靠性也隨之下降。由此可以看出,在基于分級智能的網絡中任務執行的時延性能和可靠性能之間此消彼長,存在一定矛盾。類似的,同樣的內容在本地端計算往往有較好的時延性能,但是可靠性較差;反之,若在遠端執行,則可靠性高而時延較大。執行任意一個任務的時延和可靠性性能主要取決于該任務計算節點的確定以及對應的計算資源和傳輸資源的分配、內容數據量的卸載。
在已有工業互聯網業務執行相關文獻中,大多數的工作都集中在傳輸側,即提供高可靠低時延傳輸[7,16],卻忽略了任務計算過程和任務數據對任務執行的影響;有些工作則專注于人工智能模型的訓練和推演性能,以減少計算復雜度、提升計算可靠性[4,6]。這些工作普遍沒有綜合考慮任務計算和任務傳輸過程,并且忽略了任務內容的影響。文獻[17]以內容為中心,分析了工業視覺中業務執行的挑戰和可能的應對之策。文獻[18]提出了一種輕量級的卷積神經網絡模型計算,尋找工業視覺中重要視頻幀以減少傳輸帶寬占用,并降低傳輸對接下來的計算過程的影響。總之,考慮任務內容特點、任務傳輸及任務計算等過程對工業互聯網業務,尤其是工業視覺業務影響的已有文獻非常少。相關研究仍處在初步階段,需要大量工作進行深入研究以最大化任務執行的性能。
1 系統模型
1.1 系統架構
本節介紹一種典型的基于分級智能的工業互聯網場景。如圖1所示,整個網絡架構可以分為兩層:本地邊緣層和遠程云計算層。其中本地邊緣節點部署在用戶附近,甚至可以和用戶通過有線連接集成在一起,因此可以提供高速傳輸從而降低傳輸時延。由于部署的計算資源和存儲資源非常有限,本地節點無法運行大規模人工智能模型,導致推演計算的結果可靠性較低且需要更長的計算時延。相對而言,遠程云節點擁有豐富的計算和存儲資源,可以運行大規模人工智能模型,并且推演結果的可靠性更高,所需的計算時延更短。然而,由于遠程云節點普遍都部署在離用戶較遠的位置,內容的傳輸時延不可小覷。
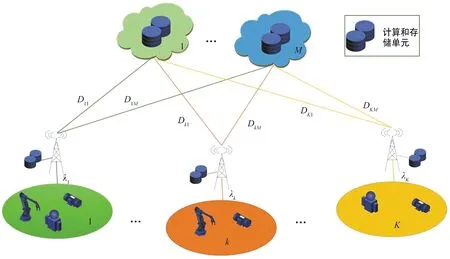
圖1 分級智能網絡系統架構Fig.1 Hierarchical intelligent system architecture
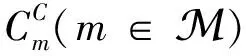
在用戶側,為了方便闡述,假設每一個用戶附著在一個本地節點并且通過有線進行連接。在IIoT環境下,用戶指的是IIoT設備,比如智能制造檢驗中的工業相機,其主要作用是拍攝生產線上的產品圖像,并將其上傳至計算節點(本地節點或遠端節點)以檢驗產品是否合格或有瑕疵。假設第k(k∈K)條生產線上的檢驗任務到達服從速率為λk的任意分布,生成的任務可以由(s,v,)表征[13]。其中,s表示任務內容的數據量,v表示該任務單位數據量計算需要的算力,而Tmax表示任務可忍受時延的上限,一旦任務在經歷Tmax之后仍沒有返回結果則視為計算失敗。假設任務數據量s和單位數據量需要的算力v分別服從[smin,smax]和[vmin,vmax]的Tmax均勻分布。每一個生成的任務被存儲在等待隊列等待后續任務執行。假設每個用戶k最多能存儲Qk個任務,一旦用戶的等待隊列超過了存儲上限,后續到達的任務會自動被丟棄并認定計算失敗。
對于獲取的任務數據(圖像或者視頻內容),系統采用可分級編碼的方式將其處理為多層數據層。根據之前的介紹,計算節點獲取的數據層越多,則輸入的信息越精確,畫面越清晰。相應的,輸出結果的可靠性也就越高,對應的計算時延及后續傳輸時延也會延長。
1.2 任務執行性能建模
在每一個時隙開始,網絡根據各計算節點的情況和各用戶隊列狀態采用合適的調度策略,將任務卸載至合適的計算節點進行后續處理。具體而言,該調度策略應當包括如下決定:① 隊列中哪個內容應該被卸載;② 應當卸載至哪一個計算節點;③ 應當卸載多少數據;根據調度策略和用戶與計算節點之間的信道情況及計算節點的計算能力,卸載的計算任務會有不同的時延和可靠性性能。具體來說,對于被卸載的任務i,其時延性能可表征為:
(1)
其中,Lwait(i)表征了該任務在用戶隊列中等待的時延,s(i)表征了任務i生成多層數據的總體數據量,而o(i)∈(0,1]為卸載的數據率。v(i)定義了任務i單位數據量需要的算力(單位為Mbit/轉)。D(i)表示用戶至計算節點的信道可提供的數據速率,而C(i)/N(i)表示計算節點提供的算力。這里需要指出的是,式(1)的D、C和N等都忽略了上下標,表明這些參數適用于所有邊緣節點和遠程節點,而其具體的取值主要取決于該任務被卸載至哪一個節點。同樣,可靠性的性能可以表征為:
R(i)=r(i)o(i),
(2)
式中,r(i)表示任務i被卸載的計算節點輸出結果的最大有效性。式(2)采用了線性模型來建模可靠性,但這并非是唯一的建模方式,其他的模型只需滿足如下條件皆適用于該模型,所提出的分析方法,可以很好地擴展到其他建模中。這些條件包括:① 總體的可靠性取值不能超過該節點的上限r;② 任務計算結果的可靠性應該和輸入的數據量成正比,也就是說輸入的數據越多(數據層越多)則輸出結果的可靠性更高。由式(1)和式(2)可以看出可靠性和時延之間的矛盾。比如說,被卸載的數據量越大,即o(i)的值越大,則該任務執行結果的可靠性越高,而其需要的傳輸時延及計算時延會相應增加。為了建模二者的矛盾,式(3)給出了一種效用函數(Utility Function)來表征二者的折中,即:
頭顱CT示鞍區腫瘤呈均勻高密度影,邊界清楚,其中64例呈圓形或類圓形,16例不規則。增強MRI示T1WI等或略低信號,T2WI高信號,均具有“腦膜尾征”[3],26例伴腦干水腫。所有患者視交叉、視神經管均存在不同程度的壓迫或侵入,腫瘤向鞍旁發展,包繞頸內動脈,其中20例完全包裹,60例部分包裹。腫瘤直徑≤3 cm 18例,3~5 cm 34例,>5 cm 28例。
(3)
式中,βr和βl∈[0,1]分別表示網絡對可靠性和時延的重視度參數。Tmax保證時延性能的取值和可靠性均在0~1之間。加1操作的目的是保證任務i被執行的效用函數值優于其被丟棄的效用函數。
由時延和可靠性的建模過程(如式(1)和式(2))可以看到調度策略對效用函數的影響。具體而言,任務i的確定由調度方案中的問題①決定,即應該調度哪一個任務;D(i)、C(i)和N(i)則回答了問題②,即任務應該卸載至哪一個計算節點;最后,o(i)的確定體現了調度策略的問題③,即應該卸載多少數據至計算節點以達到效用函數的最大值。需要指出的是,為了方便闡述,假設各節點的計算資源平均分配給計算任務,在選取卸載節點時計算資源分配也在考量范圍內;同理,傳輸信道對任務卸載的影響也在該調度策略中得到體現。
最后,本文的目的是最大化如式(4)所示的時間T(T→∞)內所有任務計算的效用函數值的平均值:
(4)
式中,X(t)表示在時隙t內生成任務的總量,Π={π1,π2,…,πT′}為一系列調度策略,T′為系統在T時隙內調度次數。
2 問題求解
在前一部分,本文提出了一種效用函數建模分析任務執行的可靠性及時延性能的折中,并期待找到一種最優的調度策略Π*以最大化效用函數取值。系統在每個時隙都需追蹤和更新網絡狀態,并據此確定是否需要進行新的調度任務。因此,只有在計算節點空閑及用戶隊列非空的情況下,新的調度策略才有意義,而不是在每個時隙都需要一個調度策略。在提出最優調度算法之前,首先對網絡狀態和調度策略進行詳細建模并確定調度間隙。
2.1網絡狀態及調度策略闡述
2.1.1 網絡狀態
在任意時刻t,系統的網絡狀態可以表示為St={Q,ndiscard,comp_e,comp_c}。其中Q={Q1,Q2,…,QK}表示各節點的隊列,而Qk?Q×3是第k個用戶的隊列,由Q×3的矩陣表示且初始值為全零。對于每一個到達的任務,可以由[twait,s,v]表征并插入到隊列首個非零行,進入排隊隊列等待卸載調度及后續計算。如果隊列已滿則該任務被直接丟棄。ndiscard∈表示系統丟棄的任務數。comp_e={comp_e1,comp_e2,…,comp_eK}記錄了K個邊緣節點的計算狀態。當某一個任務被卸載到本地節點k的第i個計算空間時,該任務的情況可以有[comp_label,delay,reliability]T表征,其中comp_label為該計算任務的計算狀態,可以取值+1、-1和0,分別表示該計算空間有任務正在計算、計算空間有任務已經完成計算并等待返回以及計算空間當前空閑可以接受新的任務;delay表示當前計算任務已經經歷的時延;而reliability表示該任務結果的可靠性。在每個時隙結束前,網絡節點將comp_label=-1對應的任務反饋給用戶并將該網絡空間重置為[0,0,0]T。在每個時隙開始時,只有comp_label=0對應的網絡空間處于空閑狀態,可以接受新的任務。comp_c={comp_c1,comp_c2,…,comp_cM}表征了遠程云端的計算狀態,和comp_e非常類似,在此不做贅述。
2.1.2 調度策略
每次調度過程中,采用的調度策略可以表示為πn={πn,1,πn,2,…,πn,K},而πn,k={task_IDk,comp_IDk,ratiok}是第k個用戶的排隊隊列中的任務。需要注意的是,若用戶k的排隊隊列空白,則該用戶無任務可以調度,故取值為task_IDk=0,對應的后續comp_IDk和ratiok等參數都沒有意義。comp_IDk是指調度任務應該卸載的網絡空間,若和用戶k相連的所有的網絡空間繁忙(即所有的可能comp_IDk=1),則無任務可調度(即task_IDk=0)。最后,ratiok表征根據網絡狀態和信道情況應該卸載多少數據至comp_IDk。
2.2 基于貪婪的調度策略方案
根據之前的表述,系統只有當用戶側的排隊隊列非空且存在空閑網絡節點時進行一次調度策略,故調度間隔是不固定的,并且網絡狀態和調度策略空間非常龐大。基于此,要找到一種最優化的調度方案是非常困難且具有挑戰性的。為了降低算法復雜度,提出了一種基于貪婪的調度方案,即每次調度僅考慮當前網絡狀態而忽略對后續調度的影響,如算法1所示。
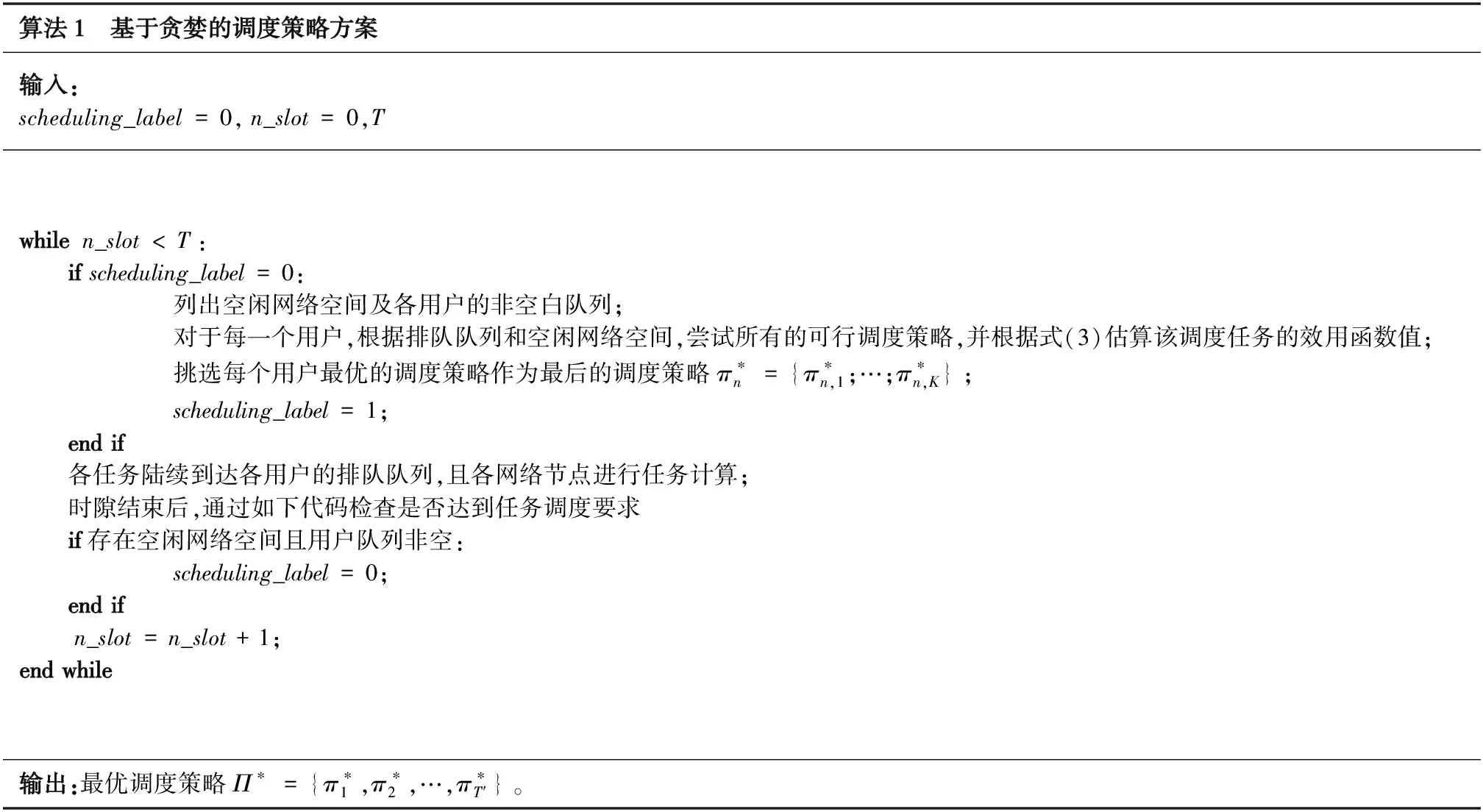
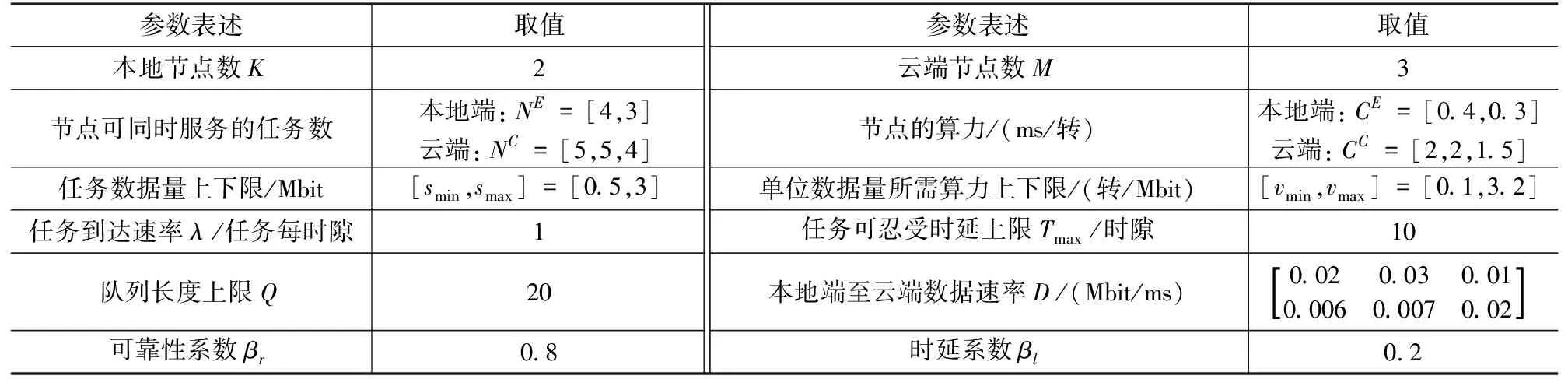
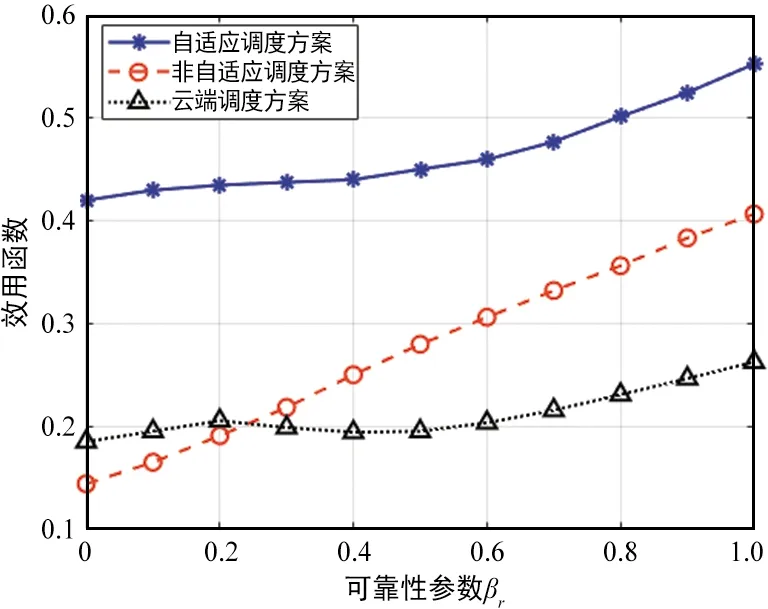
算法1 基于貪婪的調度策略方案輸入:scheduling_label=0,n_slot=0,Twhilen_slot 在該調度策略下,可以統計所有計算任務的效用函數值,根據式(4)即可得到單位任務的效用函數的平均值以及對應的最佳調度策略。 上文分析和建模了自適應調度方案下用戶任務執行的性能,接下來將通過一系列的仿真試驗驗證分析結果,并研究不同參數對效用函數的影響。仿真中的各參數如表1所示。 表1 性能仿真中參數設定 為了對比不同調度方案的性能,在仿真中加入了如下兩種對比任務調度方案。 ① 非自適應任務調度方案 (Non-scalable Task Offloading Scheme):和提出的自適應任務調度方案(Scalable Task Offloading Scheme)相比,非自適應調度方案忽略了任務內容的可伸縮性,每次任務調度時都將所有數據卸載至計算節點。 ② 云端任務調度方案(Cloud Task Offloading Scheme):和提出的自適應任務調度方案相比,云端任務調度方案唯一的不同是需要將所有計算任務自適應地卸載至云端進行計算。 接下來給出不同參數對任務執行的影響以及不同調度方案的性能對比。 圖2顯示了3種任務調度方案隨著服務到達速率λ的性能變化。之前提到各用戶的任務到達服從速率為λ的任意分布(仿真中假設服從泊松分布),因此λ的值越大,兩相鄰任務到達間隔就越大,也就是說任務因排隊隊列無空閑位置而被淘汰的概率逐漸減少,即被成功計算的概率增加。鑒于此,圖2的一個很明顯的結論就是所有方案的效用函數都是關于λ的遞增函數。 圖2 不同任務調度方案效用函數與任務到達速率λ關系Fig.2 Utility performance of different scheduling schemes with task incoming rate λ 從該圖可以看到,當λ值非常小的時候,所有方案的效用函數值都趨于0,這是因為此時幾乎所有的任務都被丟棄掉。隨著λ的增加,3種方案的性能出現了差異。考慮了分級智能和視覺數據的可伸縮性等特點,提出的自適應調度方案性能優于其他兩者。而云計算任務調度算法和非自適應任務調度方案在λ較小時表現的依然非常接近,但是當λ較大時,前者的性能更差,而自適應調度算法依然表現最佳。隨著λ的提高,各方案的性能趨于平穩。這是因為當λ很大時,任務到達比較慢,幾乎所有的請求都被服務而不存在資源不足的困擾。因此λ的增加不會繼續引起任務執行性能發生太大變化。從圖2可以看到自適應調度算法帶來的增益,尤其是當任務到達較慢,網絡負載不高時,增益更明顯。 可靠性系數βr對各對比方案的性能影響如圖3所示。βr表征了網絡對可靠性的重視程度,即βr值越大,則系統更在乎任務執行的可靠性;而反之若βr值越小則說明對時延性能要求更高。從圖3可以得到如下結論:首先,可以看到所有方案的性能隨著βr的提高而增加。從式(3)的效用函數的表征中可以看到,βr的提高可以直觀地提高效用函數的取值。但是可靠性性能的提高不可避免地引起時延性能的惡化。因此,整體的效用函數不是關于βr的線性函數。另外,隨著網絡更注意可靠性的性能,每次調度更傾向卸載全部數據以提高可靠性,因此自適應調度方案和非自適應調度方案的差距隨著βr的提高而縮小。非自適應調度方案和云計算任務調度方案相比,當βr值較小時,前者性能不如后者;而隨著βr的增大,其性能逐步優于后者。這說明當βr值較小時,考慮內容數據特點帶來的增益高于計算節點的選擇,而隨著βr的增加,選取最佳計算節點可以帶來更高增益。最后,對比3種方案的性能可以發現,自適應調度方案的性能明顯優于其他兩種,特別是當βr值較小,網絡更在意時延性能時該增益達到最高。 圖3 不同任務調度方案效用函數與可靠性參數 βr的關系Fig.3 Utility performance of different scheduling schemes with reliability coefficient βr 本文在基于分級智能的工業互聯網環境下研究了工業視覺業務執行的時延性和可靠性的折中。首先提出一種基于自適應的任務調度方案,分析對時延和可靠性的影響。提出一種效用函數建模時延和可靠性的折中并作為用戶任務執行的性能指標,通過貪婪算法得到一種局部最優的任務調度方案以最大化效用函數取值。通過一系列的仿真,分析了不同參數對用戶任務執行的影響并對比了不同算法的性能。仿真結果表明,相比于其他調度方案,自適應調度方案能得到更高的效用函數值,即用戶任務執行的可靠性和時延得到更好的折中。3 性能分析
3.1 任務到達速率λ的影響

3.2 可靠性系數βr的影響
4 結論
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
