基于膠囊網絡模型的抑郁癥預測研究
2021-11-22 08:53:36王汝傳
計算機技術與發展 2021年11期
査 猛,葉 寧*,王汝傳,徐 康
(1.南京郵電大學 計算機學院、軟件學院、網絡空間安全學院,江蘇 南京 210003;2.江蘇省無線傳感網高技術研究重點實驗室,江蘇 南京 210093)
0 引 言
隨著現代生活的快速發展,心理健康問題引起社會各界越來越多的關注。抑郁癥也稱抑郁障礙,是一類以顯著而持久的心境低落為主要特征的情緒障礙疾病,具有慢性、反復發作、遷延不愈、自殺率高的特點[1]。因此,對抑郁癥患者進行早期識別診斷,并及時給予治療十分重要。但是,目前抑郁癥的診斷主要以問卷調查為主,并以醫生的判斷為輔。其準確程度主要依賴于醫生的專業水平和經驗以及患者的配合程度,并且患者的早期診斷和評估具有非常大的限制,如患者沒有意識到自己得病、患者不愿意就醫等[2]。針對抑郁癥的診斷困難問題,由于近年來微博、推特等社交工具的廣泛使用,產生大量的可分析數據,為采用機器學習方法來識別輕度抑郁癥患者提供了數據基礎,因此利用機器學習來預測網絡用戶的抑郁癥傾向得到了越來越多研究人員的關注,并成為自然語言處理領域的研究熱點之一[3]。
國內外許多研究人員針對情緒分析已經做了大量研究,但在社交網絡中利用微博或推特評論并基于深度學習框架關于抑郁癥的研究很少[4]。近年來,不斷有學者提出用圖像領域的卷積神經網絡來解決自然語言處理的任務。受此啟發,文中使用卷積神經網絡來處理微博文本的抑郁癥預測任務,但是卷積神經網絡存在池化層丟失信息以及無法學習文本內在的關聯信息等問題,并且抑郁癥的預測不是情緒的正負極判斷,僅僅通過神經網絡模型訓練得出的預測結果較為不準確。為了解決難以充分利用文本情緒特征和抑郁癥預測不準確的問題,文中設計了融合局部與整體特征的膠囊網絡模型。該模型使用膠囊網絡來彌補卷積神經網絡的缺點,可以充分地學習文本整體與局部的內在空間關系,并且使用情緒詞典準確地找出微博數據中與抑郁癥相關的文本,提高抑郁癥預測的準確率。模型中情緒詞典用于選取文本中的局部特征,膠囊網絡用于學習文本的整體特征,在模型的輸出層使用兩種方法將局部特征和整體特征進行融合得到微博用戶抑郁癥預測的最終結果。通過與幾種典型的機器學習算法對比表明,提出的基于局部與整體特征的膠囊網絡模型在抑郁癥的預測中具有更好的效果。
1 研究現狀
抑郁癥是一種與情緒密切相關的嚴重疾病,對人的健康有著非常大的危害。情緒分析相對于抑郁癥已經被廣泛的研究了很長時間。情緒可以分為基本情緒和復雜情緒,但不同的精神病學家對情緒的詳細分類不同,導致了結果也存在一定的差異。根據Ekman[5]提出的被廣泛使用的模型,有六種基本情緒:驚訝、恐懼、厭惡、憤怒、快樂和悲傷。通過結合這六個情緒,可以得到各種復雜的情緒描述,如抑郁、緊張、焦慮等。目前,在社交媒體網站中用戶產生了豐富的多媒體信息,這種信息不僅包含了用戶的不同觀點和思想,而且包含了用戶的情緒信息,正是這些情緒信息可以用來做心理健康的研究。因此,基于社交媒體的情緒分析現在已經成為了研究熱點,并且隨著深度學習在自然語言處理領域的發展,使用深度學習來解決情緒分類的研究越來越多,如Kim等人[6]用卷積神經網絡對電影評論進行情緒分類;Kalchbrenner等人[7]用卷積神經網絡處理Twitter文本;Wang等人[8]用長短期記憶網絡對文本情緒極性進行分析。這類基于深度學習的方法都取得了比傳統分類器更好的效果,還有一些研究者針對短文本來構建分類模型,如Vo等人[9]提出了使用多樣化特征對Twitter文本進行情緒分類;Tang等人[10]通過情緒種子擴充特定領域情緒詞對用戶評論進行情緒分類。除此以外,還有一批過國內學者利用微博文本進行情緒分析,如馮等人[11]首先將卷積神經網絡應用于微博的情緒分類中,取得了不錯的效果;陳等人[12]提出了多通道卷積神經網絡模型,利用情緒特征信息以及將多方面特征信息進行結合來對微博情緒進行分析;周等人[13]使用基于注意力機制的LSTM模型進行情緒分析,以更好地學習文本中的情緒信息,提升情緒分類的成功率;張等人[14]運用多尺度卷積核改善微博評論中上下文信息有限的條件制約,來提高卷積神經網絡對于微博評論情緒分類的效果。但這些都是情緒分類方面的研究,國內對于利用互聯網數據進行抑郁癥方面的研究還具有很廣闊的前景,現有的關于微博情緒分類的研究主要在于識別文本的基本情緒上,這是因為復雜的情緒分析在不同的領域具有不同的策略,并且對人的情緒進行進一步的研究時會有非常多的限制,如抑郁這一情緒的研究。抑郁癥是一種病因非常復雜的精神疾病,精神病學、心理學、醫學、社會學等方面的專家進行了大量的相關研究。心理學家使用不同的抑郁測量量表,如SDS(自我評價抑郁量表)和CES-D(流行病學研究中心抑郁量表)來確定人們的抑郁程度。醫學研究人員還研究了許多行為信號來檢測人們的心理狀態,比如大腦信號、心率、血壓、聲音韻律和面部表情來獲得心理生理學信息[15]。
隨著移動網絡技術的飛速發展和智能手機的廣泛使用,社交網絡也得到了迅速的發展,許多人使用了一種或多種社交網絡服務表達他們的觀點和情緒,如Facebook、Twitter、微博、微信、QQ等。因為抑郁個體的發帖內容往往含有許多負面情緒詞匯,所以這些文本數據為研究者在社交媒體網站上找到潛在的抑郁癥患者提供了一種可能的途徑。一些研究人員在網上社區或者論壇的基礎上對抑郁問題進行了情緒分析,如Nguyen等人[16]研究了網絡抑郁社區的特征,并與其他社區的特征進行了比較,利用情緒信息、興趣話題和語言風格進行抑郁分析。更多的研究人員使用在線社交網站來預測抑郁癥,如Park等人[17]努力研究在社交網絡中對抑郁癥起決定性的因素;王等人[18]建立了預測抑郁癥的關聯模型,該模型建立在情緒分析算法的基礎上,將患者行為特征與影響抑郁癥預測的原理癥狀進行了比較。上述的研究都是通過情緒分析來進行抑郁分析,可見對于抑郁癥的預測分析網絡中帖子的內容是一個非常有效的方法。
在機器學習領域的發展中,卷積神經網絡原本是用來處理二維圖像的網絡,常用來提取圖像的特征,在圖像處理領域有非常好的效果。在2014年Kim[6]將CNN網絡用在了文本分類任務中,并且取得了目前最好的效果。盡管卷積神經網絡在許多領域取得了非常好的效果,但是卷積神經網絡有兩個無法彌補的缺陷,一個是卷積神經網絡無法學習圖像內部之間的相對位置關系,另一個是訓練一個卷積神經網絡需要大量的數據。在2017年Hinton等人[19]提出了改進的卷積神經網絡——膠囊網絡,膠囊網絡在卷積神經網絡的基礎上增加了膠囊層,并且在膠囊層之間使用動態路由算法來更新參數,這一網絡完美地彌補了卷積神經網絡的缺點,在MNIST手寫數據集上取得了令人滿意的效果。但是膠囊網絡是使用在圖像處理領域的模型,文中受到卷積神經網絡用于文本分類任務的啟發,將膠囊網絡進行細微修改,用于學習微博文本中的情緒特征,通過用戶的帖子來辨別該用戶是否存在抑郁傾向,使用了適用于抑郁癥的情緒詞典來提高預測準確率。實驗結果表明,與傳統的機器學習模型相比取得了不錯的預測效果。一旦通過社交媒體的數據發現了潛在的抑郁癥患者,就為精神病學家提供了有用的線索,從而可以立即進行干預和治療。
2 CapsNet抑郁癥預測模型
2.1 CapsNet模型
近幾年,卷積神經網絡因為可以充分利用多層感知機的結構,具備很好的學習復雜、高維和非線性映射關系的能力,在圖像識別任務和語音識別任務中得到了廣泛的應用。隨著研究的不斷深入,卷積神經網絡也逐漸被應用于自然語言處理領域,并取得了很好的效果,但是卷積神經網絡有著不可彌補的缺點,如需要大量的數據來訓練網絡中的參數,以及無法學習事物內部結構之間的相關關系特征等問題。在2017年CapsNet應運而生——Hinton等人針對CNN的不足提出了膠囊網絡模型。模型的結構如圖1所示。

圖1 CapsNet模型結構
CapsNet的核心結構由3層構成,模型的第一層與CNN中的卷積層相同,通過第一個卷積層粗略映射事物的局部特征,在卷積層后接一個RELU激活函數將線性映射變為非線性映射。結構中的第二層即為膠囊層,其實這是一個特殊的卷積層,由8×32個大小為9×9的卷積核卷積得到,膠囊層可以將卷積層提取的特征圖轉化為向量膠囊,它的維度比正常的卷積層要高一維,由32個長度為8大小為6×6的膠囊組成。第三層為數字膠囊層,是一個維度為16×10的矢量,16是一個向量的維度,10代表類別數,其中向量的長度可以表征實體存在的概率,向量的方向可以表示實例化參數(即實體的某些圖形屬性)。
2.2 動態路由算法
主膠囊層和數字膠囊層之間采用動態路由算法進行更新,這一過程解決了卷積神經網絡在池化操作中丟失局部特征的問題,增強了網絡魯棒性,動態路由算法的結構圖如圖2所示。
在主膠囊層和數字膠囊層之間,一個預測向量首先通過主膠囊層的膠囊向量ui乘以一個權重矩陣Wij計算得到,表達式為:
(1)
然后,在數字膠囊層中,通過對權重Cij和向量uj|i進行線性組合生成膠囊Sj,表達式為:
(2)
其中,cij是動態路由過程中產生的耦合系數,通過對bij進行softmax運算得到cij的值,這一運算保證了膠囊uj的所有系數之和為1,并且bij初始化為0保證了在第一次路由中,每一條路徑的耦合系數是一樣的。cij的表達式為:
(3)
膠囊的長度表示輸入樣本具有所描述的對象膠囊的概率,即膠囊的激活。因此,膠囊的長度在[0,1]范圍內,使用一個非線性壓縮函數進行膠囊的壓縮,表達式為:
(4)
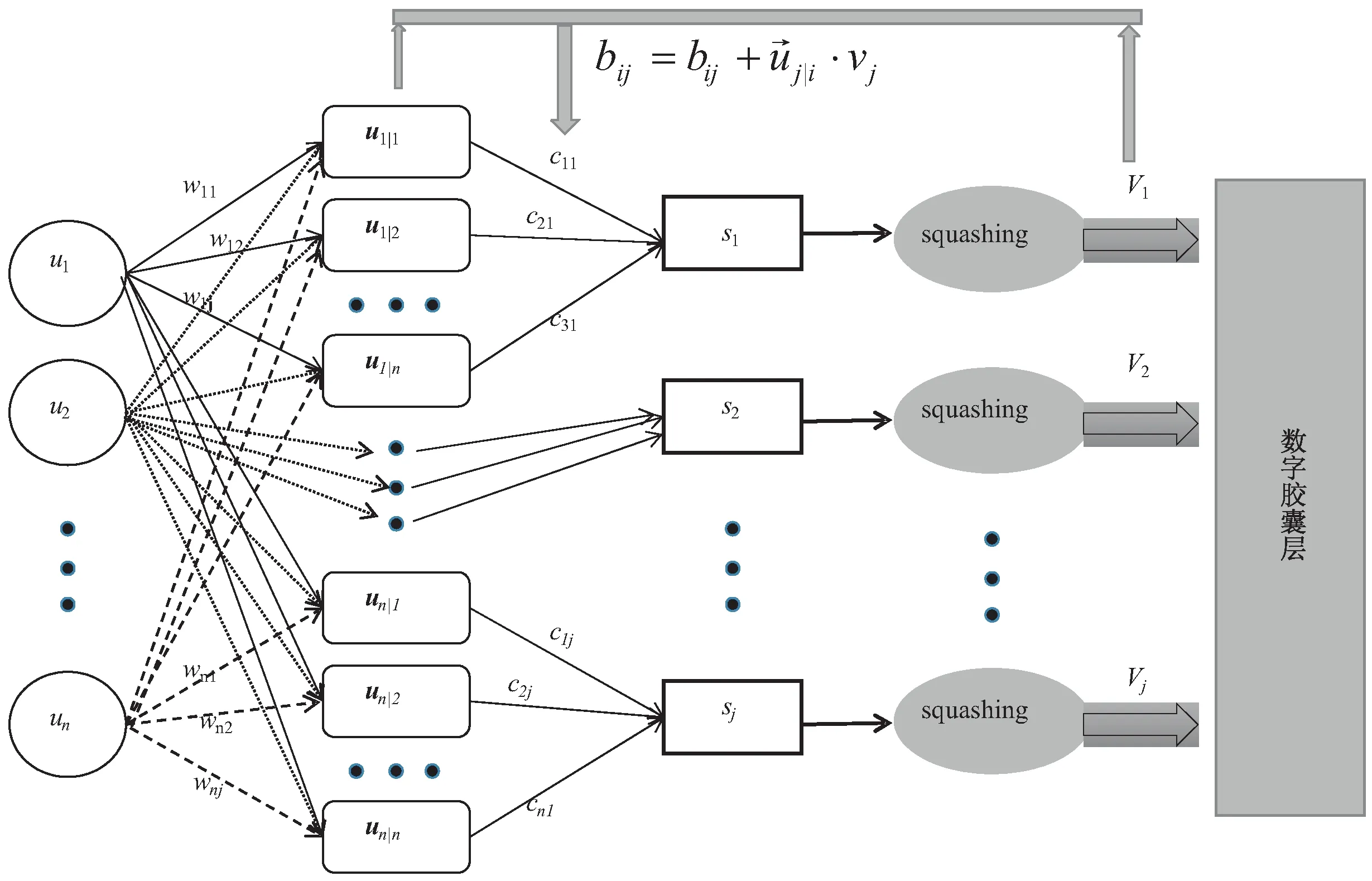
圖2 動態路由算法結構
通過該函數,短向量就被壓縮到接近0,而長向量就被壓縮到接近1。
最后,膠囊網絡的更新其實就是在計算耦合系數,而耦合系數的計算通過在每次迭代中更新bij的值,表達式如下:
(5)
相對于卷積神經網絡的池化操作,使用動態路由算法不僅縮短了模型訓練時間,而且保留了數據之間的相對位置關系。
2.3 CapsNet抑郁癥預測模型
文中提出的CapsNet抑郁癥預測模型如圖3所示。
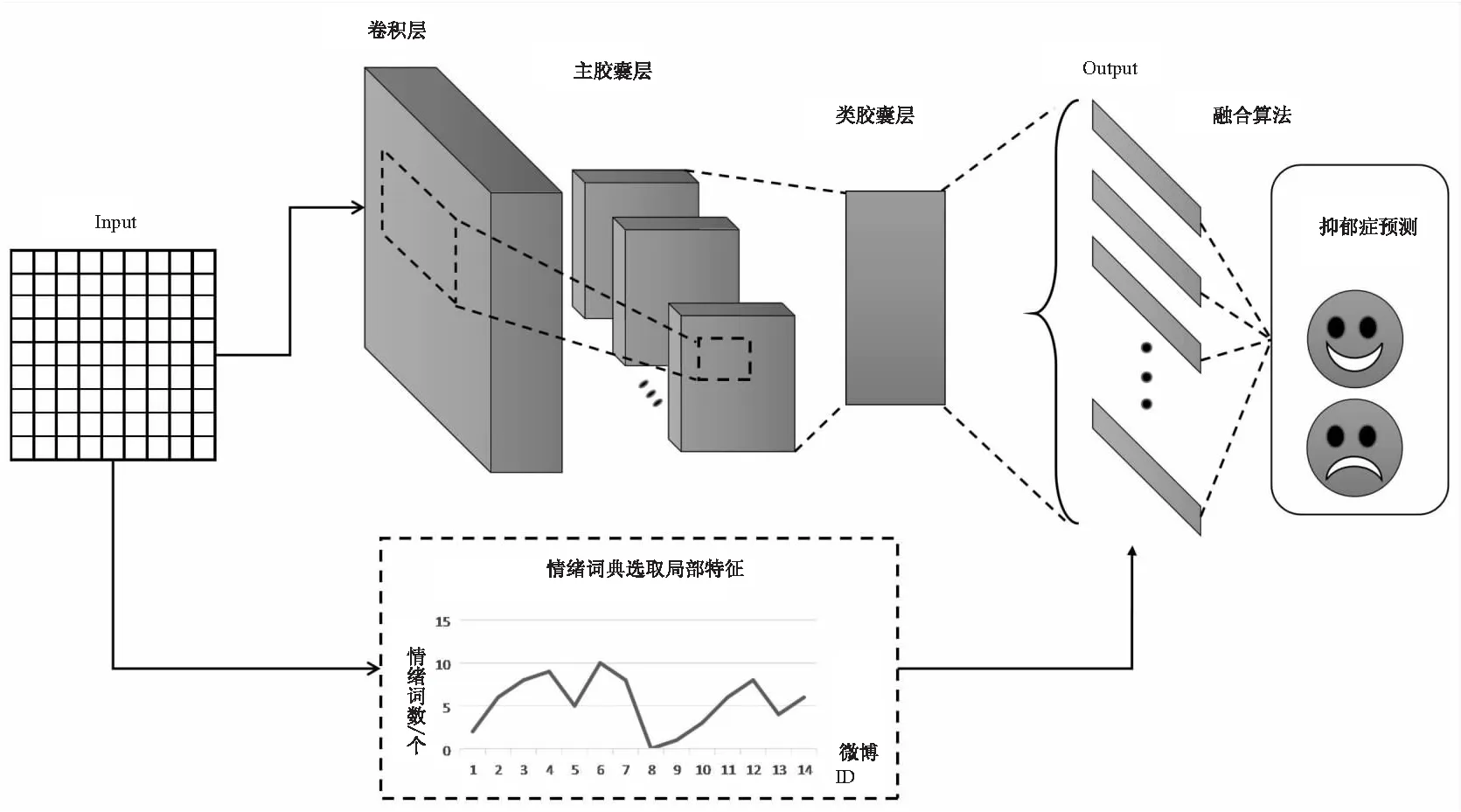
圖3 CapsNet抑郁癥預測模型
模型中輸入數據為已經處理好的一條微博文本,是一個N*50的二維張量,N表示輸入文本詞向量的數量,50是詞向量的維度。
模型分為了整體特征提取和局部特征選擇,其中整體特征提取使用CapsNet模型,在模型中第一層是卷積層,使用256個9×9卷積核,這樣的卷積核可以彌補模型層數較低,充分學習輸入文本數據的特征。卷積核的步幅為1,且卷積層中使用RELU激活函數。之后,主膠囊層使用第一層卷積層得到的張量,將卷積層數據作為輸入,使用相同的卷積核進行8次卷積操作,從而產生8個張量組成一組膠囊神經元。第三層為類膠囊層,在第二層輸出向量的基礎上進行傳播和動態路由更新,得到最后的預測向量,通過預測向量的模長得出類別概率。每一條微博數據都可以通過模型獲得情緒預測概率,將一個用戶的所有微博數據作為一個整體,最后取所有預測概率的平均就可以得到一個用戶數據的整體特征。
在局部特征選擇中,局部特征的選擇是通過使用情緒詞典統計微博文本的情緒詞來進行抑郁識別。但是,在不同語言中有不同的情緒詞典,例如,作為一種英語情緒詞典,LIWC詞典[20]已經得到了很好的驗證,并被廣泛應用于情緒分析中;作為中文情緒詞典,可供文中使用的有HowNet[21]、NTUSD[22]和Chinese Affective Lexicon Ontology (CALO)[23]情緒詞典等。HowNet和NTUSD主要用于粗粒度情緒分析,如積極情緒或消極情緒,而CALO主要用于細粒度情緒分析。所有這些情緒詞典都不適合用于特殊的情緒識別,比如文中的抑郁情緒識別。文中參考了Zhichao Peng[24]等人的研究,制作了自己的情緒詞典來進行局部特征提取,該情緒詞典綜合了基礎情緒詞典和網絡用語情緒詞典,如表1所示。

表1 情緒詞典
文中使用情緒詞典對處理好的微博文本數據進行情緒詞數計算,得出每條微博文本數據中的情緒詞數,將一個用戶的所有微博以情緒詞數進行排序,找出并標記情緒詞數多的微博,之后將其對應的序號輸入到輸出層,由模型得到對應微博的情緒預測概率,作為整個微博數據的局部特征。
由于整體特征和局部特征都是由CapsNet模型產生的二維預測結果,文中將兩個特征融合到最終預測中,考慮兩個策略,分別是max pooling和sum pooling。
在max pooling中,整體特征和概率大的局部特征被保留,忽略了概率小的局部特征,最終的預測概率Y的表達式為:
(6)
其中,YGlobal表示整體的預測概率,YPartj表示第j個局部的預測概率。文中根據情緒詞典選取了排在前K個的局部特征。Y,YGlobal,YPartj都具有一致的向量結構(ypos,yneg),二維向量中的ypos和yneg分別表示積極情緒預測概率以及消極情緒預測概率。
在sum pooling中,所有的局部特征都被使用,文中添加參數β來權衡整體預測概率和局部預測概率,表達式如下:
(7)
3 實 驗
3.1 數據集獲取
文中的數據來自新浪微博,分為兩部分數據,一部分是抑郁癥用戶的微博數據,另一部分是非抑郁癥用戶的微博數據。其中,抑郁癥用戶的數據來自于一家專門做抑郁癥監測的公司,帖子的抑郁特征較為明顯,例如,“也不是真的崩潰,也不太想活,也不敢去死”、“壓死駱駝的不是最后一根稻草,而是所有稻草”、“真不知道自己接下來的人生要怎么辦了,很迷茫很迷茫”等。對于非抑郁癥用戶的微博數據,為了使該部分數據對于模型的訓練有明顯效果,由筆者團隊對網上獲取的微博帖子進行嚴格的篩選,剔除了所有具有負面情緒的數據,保留情感趨向積極的用戶數據,內容包括用戶基本信息和用戶發布的所有微博數據,根據實驗需求,選取了自2019年1月到2019年12月的用戶微博數據。
繪本的形象也就是繪本的主人公,他既是整個故事的主體,也是情感傳達的載體,同時也表現了作者內心索要表達的一些思想。通常治愈系繪本的形象可以分為三大類:第一類是作者的思想載體,作者通過自己塑造的人物形象或者是動物形象來表達作者的內心世界。第二類是對著這本人進行夸張處理,這種繪本的形象通常是作者本身,作者通過自己的日常生活,或者是自己的一些經歷通過繪本的形式呈現給讀者。第三類是人物形象并不是故事的主角,而是作為一個情節的需要,也會隨著故事的改變而改變,這類繪本讀者容易跟著作者的節奏一步一步慢慢進入正題,這樣也更容易是讀者有探索性。
3.2 數據集預處理
從獲得的數據中,實驗只使用到用戶的帖子數據,所以除去了個人簡介以及轉發數評論數等信息。微博設置的帖子限制符號數為150,由于微博的帖子長短不一,加上含有許多表情符號,為了與文中框架模型的輸入數據格式一致,避免高維稀疏向量影響實驗的準確率,經過剔除標點符號、表情符號、數字和字母等,從剩下的帖子中選取字數在15以上的帖子。對每個用戶的微博數據進行處理后,選取了剩余帖子在150條以上的用戶。
如表2所示,根據實驗需求,選取了120個抑郁用戶和200個非抑郁用戶。其中抑郁用戶總共發布了24 785條帖子,非抑郁用戶發布了62 456條帖子。
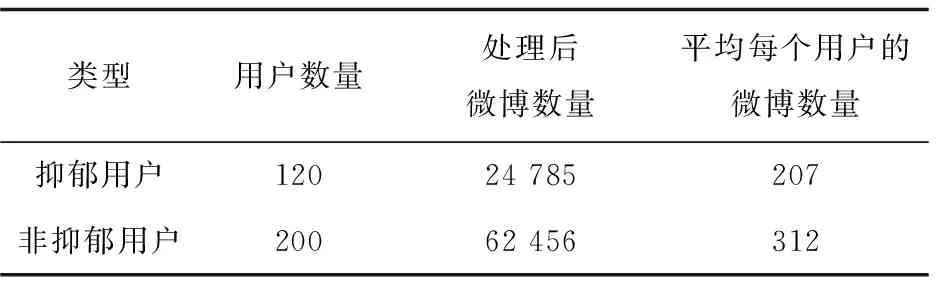
表2 實驗數據的組成及數量
3.3 詞向量的生成
神經網絡模型通過接收文本的向量化輸入來學習輸入句子的特征信息,在文本分類任務中,句子中詞語的內容隱含著句子最重要的特征信息。文中以詞為單位來表示句子,通過jieba分詞工具將上文中處理得到的單一文本數據(不含有標點符號、表情符號、數字和字母等)劃分為詞,之后將每一個詞映射為一個多維的連續值向量,將詞向量逐行排列為矩陣,用補齊的方式統一矩陣大小,最終每段文本被表示為長為最大句長、寬為詞向量維度的稠密矩陣,可以得到整個數據集詞集合的詞向量矩陣E∈Rm×|V|,其中m為每個詞的向量維度,|V|為數據集的詞條集合大小。對于長度為n的句子,句子中每一個詞語wi都可以映射為一個m維向量,一個文本的詞向量形式如圖4所示。
實驗中,對句子的輸入設定一個最大長度maxlen,對于長度小于maxlen的句子用0向量補全,為了有效降低高維稀疏向量對實驗的影響,在數據預處理階段就已經刪去了大量的不合適文本。對詞向量的生成,使用的是Word2Vec工具的CBOW模型,未登錄詞使用均勻分布U(-0.01,0.01)來進行隨機初始化,為了降低模型的學習時間,實驗中訓練的詞向量維度為50維。
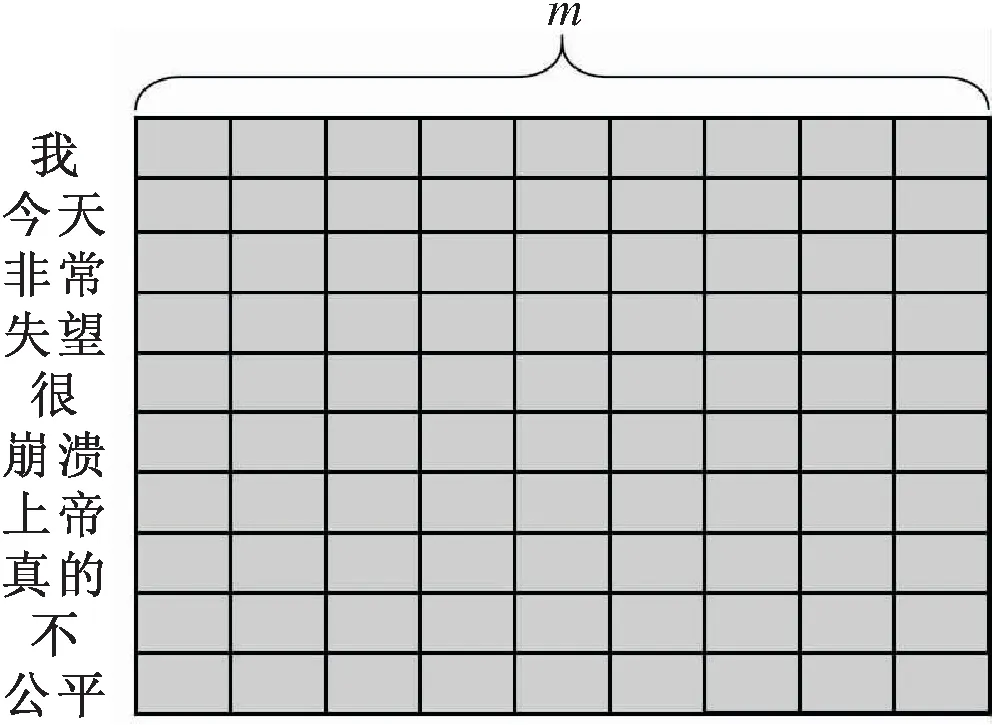
圖4 輸入詞向量形式
3.4 實驗過程和評價指標
通常,較大部分的數據用于訓練,較小部分的數據用于測試,文中采用5折交叉驗證來進行實驗。因此,以用戶為單位將實驗數據分成5份相同大小的互斥子集,使用4份數據進行訓練,1份數據用于測試,最后選擇損失函數評估最優的模型參數。
將提出的模型和傳統的機器學習模型進行實驗對比,驗證文中提出的基于局部和整體的膠囊網絡模型的有效性。對比的機器學習模型有KNN、DNN、TextCNN和BiRNN等模型。其中,輸入數據使用的詞向量維度均為50,KNN模型中K取10;DNN模型使用3個隱藏層,維度分別為100、50、25,第一個和第三個隱藏層均使用RELU激活函數;TextCNN模型中含有一個卷積層、一個池化層和一個全連接層,卷積核大小為9×9;BiRNN模型為含有兩個隱藏層的雙向循環神經網絡;以上模型的學習速率均為0.01。
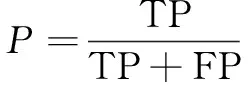
(8)
(9)
(10)
(11)
其中,TP表示正確分類到該類的文本數,FP表示錯誤分類到該類的文本數,FN表示屬于該類但未被分類到該類的文本數。
3.5 實驗結果與分析
在該模型中,輸出最后預測時使用max pooling和sum pooling兩種融合策略,其中含有兩個超參數K和β。首先對于sum pooling策略使用不同的β進行對比,如圖5所示,在測試集中,設置β=0.4達到抑郁癥預測的最佳總體精度。
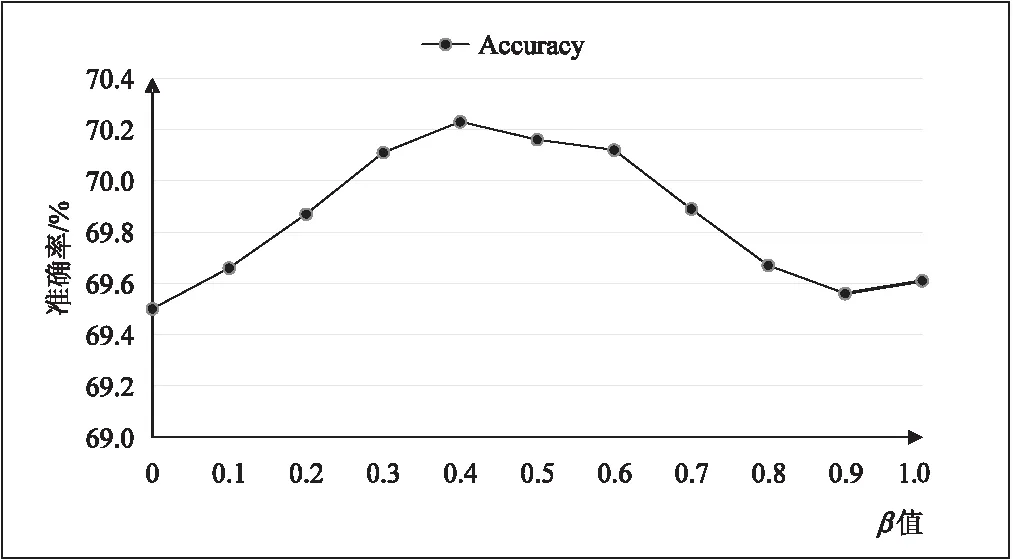
圖5 模型準確率-β參數
之后再對兩個策略都要使用的局部特征K進行不同值的對比,如圖6所示,可以發現在K=7時max pooling策略達到最佳精度,K=8時sum pooling策略達到最佳精度。還可以發現sum pooling策略在效果上要明顯好于max pooling策略,因此在之后的對比實驗中,均采用sum pooling策略進行對比。
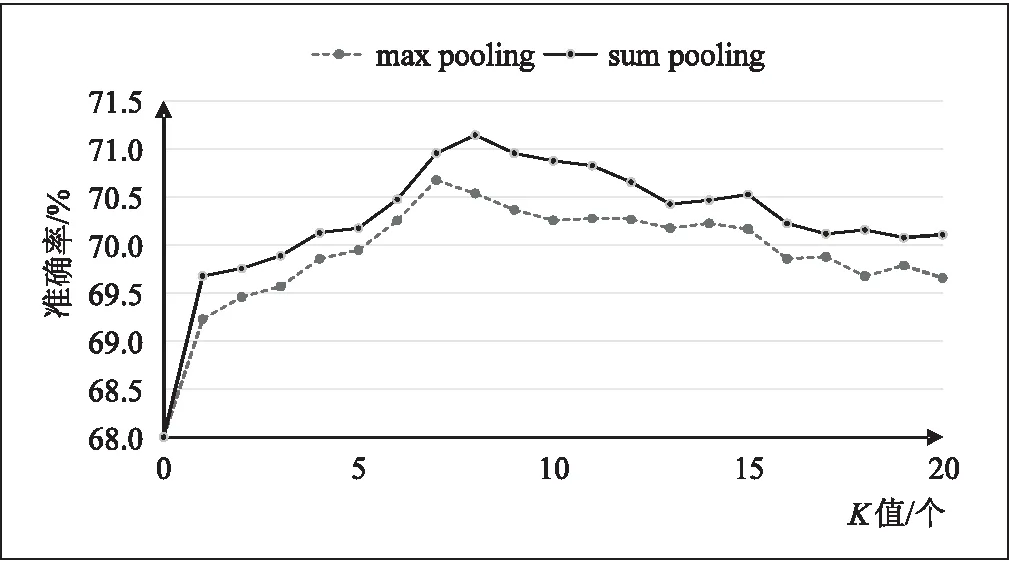
圖6 模型準確率-K值
在處理好的數據集上,運行了不同的模型,將實驗結果的精確率、召回率、綜合評價指標和準確率進行對比,實驗結果如表3所示。
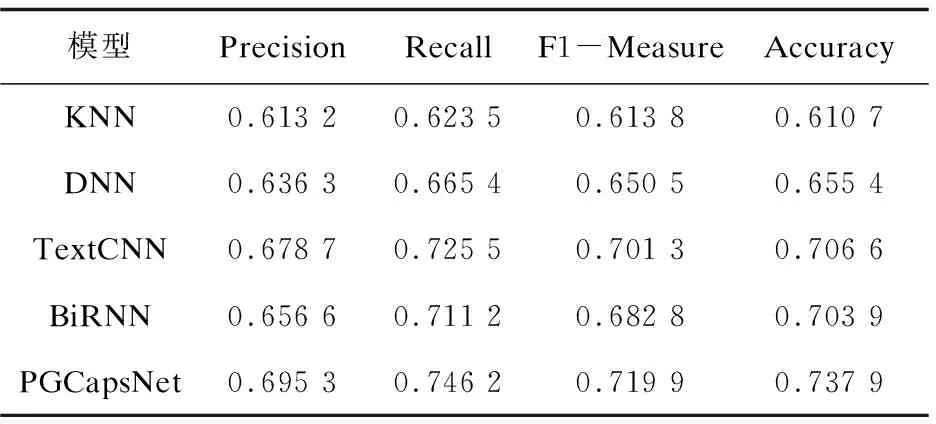
表3 實驗結果
實驗結果中,PGCapsNet模型得到了比其他模型更好的精確率、召回率和綜合評價指標,除此以外,PGCapsNet模型獲得了73.79%的準確率,而傳統的文本分類模型KNN和DNN的準確率分別為61.07%和65.54%,此外TextCNN和BiRNN模型的準確率要高一點,分別為70.66%和70.39%。實驗結果證明,提出的PGCapsNet模型對于抑郁情緒分類的性能要優于其他模型。
4 結束語
隨著互聯網的發展,社交媒體提供了新的方法去識別潛在的抑郁癥患者,由此提出了面向微博文本的抑郁癥預測模型。模型中,首先將文本特征劃分為局部特征和整體特征,之后使用情緒詞典選取局部特征,以及CapsNet模型學習整體特征,最后在輸出層將兩部分特征進行融合得到用戶的抑郁癥預測概率。實驗證明,提出的模型在基于微博文本的抑郁癥預測方面具有不錯的效果。
在今后的研究中,將嘗試使用BERT(bidirectional encoder representation from transformers)模型與膠囊網絡模型相結合,進一步提高模型對于抑郁情緒預測的準確率。此外,文中實驗數據集并不豐富,未來的研究中將使用樣本量足夠大的數據來訓練復雜的模型,使得模型可以取得更好的性能。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
風流一代·青春(2018年2期)2018-02-26 15:27:06
風流一代·青春(2017年6期)2018-02-14 19:28:55
風流一代·青春(2017年5期)2018-02-14 09:32:37
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
商業評論(2014年6期)2015-02-28 04:44:25
