一種基于一維卷積殘差網的單通道信號源個數估計算法
2021-11-20 00:32:43朱炎民武欣嶸鄭翔陳美均皮磊
計算機時代 2021年11期
朱炎民 武欣嶸 鄭翔 陳美均 皮磊


DOI:10.16644/j.cnki.cn33-1094/tp.2021.11.008
摘? 要: 單通道信號源個數估計是單通道盲源分離問題的前提與難點,傳統方法無法直接進行估計且準確率較低。文章提出了一種基于深度網絡分類器的單通道信號源估計方法。該方法將源個數估計作為分類問題,在經典CNN的基礎上引入一維卷積網絡與殘差結構作為分類器,采用短時傅里葉變換和梅爾倒譜系數作為聯合特征輸入分類器。在Libricount數據集上的測試結果表明,該方法的源個數估計準確率明顯優于基準模型。
關鍵詞: 盲源分離; 單通道; 源個數估計; 卷積殘差網; 分類器
中圖分類號:TN912.3? ? ? ? ? 文獻標識碼:A? ? ?文章編號:1006-8228(2021)11-30-04
Algorithm for estimating the number of single channel signal sources based on
one-dimensional residual convolution neural network
Zhu Yanmin, Wu Xinrong, Zheng Xiang, Chen Meijun, Pi Lei
(College of Communication Engineering, Army Engineering University of PLA, Nanjing, Jiangsu 210007, China)
Abstract: Estimation of the number of single channel signal sources is the premise and difficulty of single channel blind source separation. Traditional methods cannot estimate the number of single channel signal sources directly and the accuracy is low. In this paper, a single channel signal source estimation method based on deep network classifier is proposed. In this method, the number estimating of sources is taken as a classification problem. Based on the classical CNN, a one-dimensional convolutional network and residual structure are introduced as the classifier, and Short-Time Fourier Transform and Mel-frequency Cepstral Coefficients are used as the joint feature input classifier. The test results on Libricount dataset show that the accuracy of source number estimation of the proposed method is obviously better than that of the baseline model.
Key words: blind source separation; single channel; source number estimation; residual convolution neural network; classifier
0 引言
近年來,基于深度學習的單通道語音分離技術得到了廣泛的關注與重視,逐漸成為語音分離領域的新熱點。大多數情況下,基于深度學習的單通道分離模型需要知道信號源個數。而在現實中,通常無法獲得混合中信號源個數,導致無法直接使用深度學習方法進行語音分離。因此,單通道混合信號源個數估計是進行語音分離的重要前提。
傳統源信號估計方法大多基于陣列信號,根據陣列信號的到達角DOA與時延,采用聚類等方法得出源信號的個數。而單通道的語音信號源個數估計問題,一般通過EMD等算法先將單通道信號轉化為虛擬陣列信號,再使用陣列信號個數估計方法進行估計[1-3],信噪比較低的情況下準確率較低。
鑒于深度學習方法在各種音頻相關任務的成功應用,在信號源個數估計的研究中也逐漸引入深度學習方法,并且獲得比傳統方法好的效果。文獻[5]將一維CNN引入源個數計數,得出深度模型的估計效果優于人類感知與傳統方法。文獻[6]將源個數估計作為基于RNN的分類或回歸問題,使用一個三層BLSTM進行估計,準確率較高。文獻[7]直接將時間信號作為輸入特征,輸入E2ECNN(End-to-End Convolutional Neural Network),實現端到端的源個數估計。文獻[8]采用多種深度模型進行源個數估計,在估計準確率與MAE(Mean Absolute Error)方面相較于文獻[6]有較大幅度的提高。
盡管基于深度學習的單通道信源個數估計相較傳統方法準確率明顯提高,但在以往研究中,使用的神經網絡模型結構較為簡單,輸入特征較為單一。本文通過改變網絡結構,將一維殘差卷積網作為分類器應用于源個數估計,用一維卷積代替傳統二維卷積,加快模型收斂速度,增加卷積層深度,嘗試提高輸入/輸出的映射能力,并通過殘差連接優化模型。該方法比以前的研究有更高的分類準確率,且縮短了訓練時間。同時,研究了不同特征對模型源估計效果的影響,采用聯合特征輸入,進一步提升了模型對信號的源個數的估計準確率。
1 相關工作
1.1 問題描述
單通道信源數估計問題是指從1個混合信號中估計出源信號的個數。如式⑴所示,在給定混合信號[Y(t)]的情況下估計出[Y(t)]中的源信號個數S,[X(t)]指源信號。
在混合信號[Y(t)]中,每個源信號活躍的時間不同,模型要估計的源數目指在混合信號中存在過的源信號的最大數目。假設用[Vi,t]來表示第i個源信號在時間t的狀態,1表示活躍,0表示不活躍。在時刻t同時活躍的源信號個數[Nt]可由[Vi,t]得出:
其中L表示源信號的總數,將[Vit]相加即得到時刻t上的說話者個數[Nt]。在時間軸上遍歷,取最大值就可得到整個信號中最大的說話者個數S,即信號源個數。
其中T表示混合信號的時間長度,S為估計的信號源個數。本文中設定的L默認與S相等,不存在L=2的情況下信號不混疊導致計算出的S=1。
從混合信號[Y(t)]估計得到源個數S,此任務可以表述為分類問題,每個類別對應一個信號源數量。本文將源個數S的估計作為基于神經網絡的混合信號多分類任務,以1DRCNN作為特征提取與分類器,完成從混合信號[Y(t)]到源個數S的映射。
1.2 基準模型
本文將文獻[7]中的E2ECNN模型作為基準模型,與本文提出的模型作對比。E2ECNN模型直接從原始波形中提取特征,實現端到端的信號源計數,E2ECNN在一個卷積池化層后堆疊三個連續的卷積模塊,每個卷積模塊包含三對二維卷積層與池化層,后連批次歸一化層與dropout層,最后依次連接三個全連接層與dropout層。盡管基準E2ECNN模型在信號源計數任務上產生了良好的性能,但是模型結構只是簡單的堆疊CNN,模型的性能還有提高的空間。因此本文使用殘差網優化模型結構,同時加深網絡深度,提出一維卷積殘差網(One-dimensional Residual Convolutional NeuralNetwork,1DRCNN)作為網絡主體對源信號個數進行估計。
2 算法描述
2.1 本文模型
殘差網(Residual Network,Resnet)于2015年被提出[10],用以解決由于網絡結構過深而導致的模型性能下降問題。殘差網通過跳躍連接實現恒等映射,如圖1(a)所示。殘差網的學習目標不再是完整的輸出,而是所謂的殘差,最后的訓練目標也就是將殘差結果逼近于0,將前一層輸出傳到后面,增加了網絡深度的同時不提升誤差,保證模型不因為堆疊而產生退化。
1DRCNN借鑒了Resnet的結構,在1DCNN的多個卷積塊提取特征的基礎上,引入Resnet的跳躍連接構建殘差單元。將一維殘差單元堆疊連接,在加深模型深度同時利用殘差網結構減少因深度加深帶來的梯度消失等影響,提高模型提取特征能力。
殘差單元結構如圖1(a)所示,每個殘差單元內包含三個卷積層后接批次歸一化層,size=7表示一維卷積核長度為7,stride=1表示步長為1,BN為Batch Normalization。殘差單元使用核長度為1,步長為3的卷積層完成跳躍連接。1DRCNN結構如圖1(b)所示,包含四個殘差單元作為神經網絡主體提取特征,殘差單元內Conv [3,1,128]表示卷積核長度為3,步長為1,通道數為128,padding=same表示進行填充。最后連接平均池化層,在平均池化層后加入dropout層,預防模型過擬合,全連接層與softmax層作為分類輸出。
本文提出的1DRCNN,相較于E2ECNN有以下幾點改進。
⑴ 網絡層數更深,1DRCNN能夠挖掘信號更深層的特征,發現不同信號的聯系與差別,提高信號與源個數估計的映射能力,提高模型的分類效果。
⑵ 使用一維卷積代替二維卷積,采用一維卷積更適用于序列數據,同時能減少模型參數,分類效果更好的同時使模型訓練時間更短。
⑶ 使用殘差結構,1DRCNN采用11層網絡結構,殘差結構使其在深度較深時能保持良好的性能,提高模型性能。
⑷ 使用批歸一化算法,在每個殘差單元內接批次歸一化,同時最后使用全局平均池化減少參數,避免模型出現過擬合的情況。
2.2 數據集與特征選擇
本文選用LibriSpeechdev-clean數據集中的Libricount數據集。LibriSpeech數據集是一個開源的自動語音識別的朗讀英文數據集,采樣率為16kHz。本文選擇Libricount數據集,該數據集包括10類數據,包括1至10個源信號的混合語音共5720條,每類數據572個樣本,樣本長度固定為5秒,訓練時80%的數據用于訓練,20%的數據用于測試。
本文選取不同特征作為神經網絡輸入,包括短時傅里葉變換、Fbank及梅爾倒譜系數。短時傅里葉變換(Short-Time Fourier Transform,STFT),即通過短時傅里葉變換后取幅度譜; Fbank(Filter Bank)是指經過梅爾濾波器組后提取到的特征,高度相關,本文中Fbank特征包括40維濾波器組特征及動態一階與二階差分特征;梅爾倒譜系數(Mel-frequency Cepstral Coefficients,MFCC)在Fbank的基礎上使用DCT變換得到,具有高度的判別性,本文中MFCC為40維濾波器特征及動態一階與二階差分特征。
2.3 訓練過程
以一個樣本為例進行說明。輸入混合信號長度為5s,采樣率為16kHz,輸入為80000*1,經過1024點fft,512點幀移的短時傅里葉變換后,變換成313*507的頻譜圖作為神經網絡的輸入。初始學習率設為0.0001,使用Adam優化器,batchsize為32,損失函數為正則化后的交叉熵函數,以減少過擬合的幾率。所有的模型通過150輪訓練后得出結果,取在測試集上取得最高準確率的模型,用于模型性能評估,訓練過程可視化結果由tensorboard得到。
3 仿真實驗
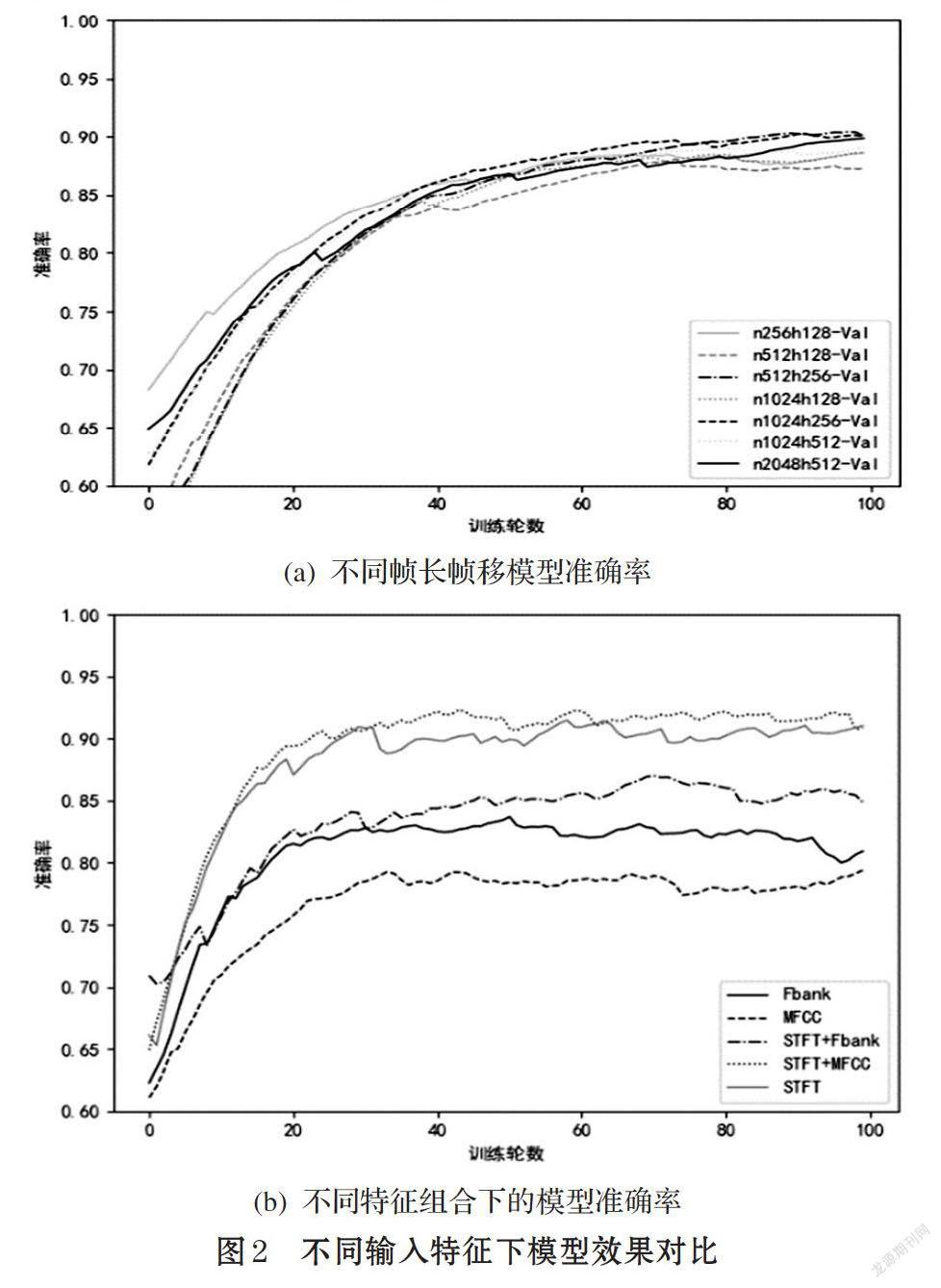
3.1 不同輸入特征下模型效果對比
本文從輸入特征的兩個不同角度對模型效果的影響進行了討論,一是以不同幀長與幀移提取時頻特征,二是將不同特征組合輸入,觀察實驗效果后選擇最佳特征作為本文模型輸入。
圖2(a)為不同幀長與幀移的輸入特征下的模型表現。實驗中分別選擇了fft點數為256、512、1024、2048以及幀移為1/2、1/4、1/8的情況,fft點數默認等于窗口長度。由圖2(a)可知,在幀長方面, fft點數為1024(時間64ms)的模型準確率較高。在幀移方面,1/4的幀移在保證幀之間關聯度的同時也不會使冗余度太高,實驗中準確率較高。在本文的實驗中,不同幀長與幀移的輸入特征所得到的模型效果相差4%左右,本文選用幀長1024點,幀移256點以提取時頻特征。
圖2(b)是將STFT,Fbank,MFCC及聯合作為輸入特征的模型表現,STFT+MFCC特征效果最佳,STFT特征次之,STFT+Fbank特征比STFT特征效果最差,表明Fbank特征中的某些特征與STFT聯合時對模型的判斷產生了負面的影響。STFT+MFCC準確率最高達到92%,較最低的MFCC準確率80%效果提升明顯。所以本文選擇使用STFT與MFCC的聯合特征作為模型特征輸入,以得到最好的實驗效果。
3.2 1DRCNN與E2ECNN實驗效果對比
圖3給出1DRCNN與的E2ECNN的效果圖比較,本文在兩個模型上分別訓練了9個分類器,對應估計2至10個語音信號混合的源個數。圖3(a)給出了本文模型與基準模型在5分類器訓練過程準確率的比較,即該模型能估計源個數小于等于5的混合信號;圖3(b)比較每個分類器在源個數估計上的準確率,數據由每個分類器三次實驗數據平均后得到,偶然性較低。
從圖3(a)中可以看出在5分類模型中,本文的一維卷積殘差網絡在驗證集最高能達到93%的準確率,而基準模型只能達到最高87%的準確率。從圖3(b)中可以看出在九個分類模型中,本文提出的1DRCNN模型的準確率都高于基準E2ECNN,證明了1DRCNN作為分類模型的有效性。
在1DRCNN與E2ECNN模型中,2類與3類分類器的準確率都很高,原因在于混合信號個數較少,1DRCNN與E2ECNN的復雜度足以支撐作為2類與3類分類器,但作為4,5,6,7類模型的1DRCNN的準確率都是高于E2ECNN,原因在于1DRCNN深度更深,殘差網學習的殘差則簡化了學習過程,增強了梯度傳播,網絡的泛化能力也更強。到了8,9,10分類器后,1DRCNN也出現了效果的下降,這是因為信號個數過多的情況下,所用數據集每類信號的數據量過少,或是模型深度復雜度不高。
4 結論
本文提出一種基于1DRCNN的單通道源信號個數估計的方法,該方法引入殘差結構與一維卷積網改進網絡結構,選用短時傅里葉變換和梅爾倒譜系數作為聯合特征輸入,在Libricount數據集上與E2ECNN方法進行比較,結果證明本文模型優于基準模型。在混合信號個數小于等于7時,本文模型具有較好的效果,精度最高可提高8%以上;當信號數量大于8時準確率有所下降,但仍高于E2ECNN方法。
參考文獻(References):
[1] 胡君朋,黃芝平,劉純武等.基于EMD的單通道信源數估計方法[J].計算機測量與控制,2015.23(12):4139-4140
[2] 劉邦,肖涵,易燦燦.基于核函數的二階盲辨識的單通道信號盲分離方法研究[J].機械強度,2018.40(5):1043-1049
[3] 張純,楊俊安,葉豐.高斯色噪聲背景下的單通道信源數目估計算法[J].信號處理,2012.28(7):994-999
[4] A Hannun?, C Case, Casper J, et al. Deep Speech: Scalingup end-to-end speech recognition[J].Computer Science,2014.
[5] Stoter F R, Chakrabarty S, Edler B, et al. Classification vs.Regression in Supervised Learning for Single Channel Speaker Count Estimation[C]// ICASSP 2018-2018 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). IEEE,2018.
[6] Andrei V, Cucu H, Burileanu C. Overlapped Speech Detection and Competing Speaker Counting-Humans Versus Deep Learning[J]. Selected Topics in Signal Processing, IEEE Journal of,2019.
[7] Zhang W, Sun M, Wang L, et al. End-to-End Overlapped Speech Detection and Speaker Counting with Raw Waveform[C]// ASRU,2019.
[8] Stoter F R, Chakrabarty S, Edler B, et al. CountNet:Estimating the Number of Concurrent Speakers Using Supervised Learning[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing,2018.99:1-1
[9] Wang W, Seraj F, NMeratnia, et al. Speaker Counting Model based on Transfer Learning from SincNet Bottleneck Layer[C]//2020 IEEE International Conference on Pervasive Computing and Communications (PerCom). IEEE,2020.
[10] Bai S, Kolter J Z, Koltun V. Convolutional Sequence Modeling Revisited,2018.
