基于深度神經網絡的維語語音關鍵詞檢索
2021-11-20 00:32:43張偉濤米吉提·阿不里米提鄭方艾斯卡爾·艾木都拉
計算機時代 2021年11期
張偉濤 米吉提·阿不里米提 鄭方 艾斯卡爾·艾木都拉

DOI:10.16644/j.cnki.cn33-1094/tp.2021.11.006
摘? 要: 語音識別中的一個重要的分支就是關鍵詞檢索。雖然在英語上的關鍵詞檢索已經成熟,但是低資源的語音,比如維語的語音關鍵詞檢索研究緩慢,仍需要更深入的研究。文章在維吾爾語語數據集thuyg20上,先在GMM-HMM(Gaussian Mixture Model Hidden Markov Model)聲學模型,DNN-HMM(Hidden Markov Model Deep Neural Network)聲學模型,LSTM-HMM(Long Short-term Memory Hidden Markov Model)聲學模型解碼產生的網格lattice上捕捉關鍵詞,將DNN-HMM和LSTM-HMM解碼產生的網格進行融合,再在融合的網格lattice上進行關鍵詞檢索。實驗結果表明,融合后的結果在準確率和召回率方面要優于DNN-HMM和LSTM-HMM模型的檢索性能。
關鍵詞: 維吾爾語; 低資源; 語音關鍵詞檢索; 深度神經網絡
中圖分類號:TP391.1? ? ? ? ? 文獻標識碼:A? ? ?文章編號:1006-8228(2021)11-21-04
Uyghur speech keyword retrieval based on deep neural network
Zhang Weitao, Mijit Ablimit, Zheng Fang, Askar Hamdulla
(College of Information Science and Engineering, Xinjiang University, Urumqi, Xinjiang 830046, China)
Abstract: An important branch of speech recognition is keyword retrieval. Although keyword retrieval in English has become mature, the research on low-resource speech,such as Uyghur speech keyword retrieval, is slow and still needs more in-depth research. On the Uyghur language data set thuyg20, the keywords are captured on the lattice generated by decoding with the acoustic models of GMM-HMM (Gaussian Mixture Model Hidden Markov Model) acoustic model, DNN-HMM (Hidden Markov Model Deep Neural Network) acoustic model and LSTM-HMM (Long Short-term Memory Hidden Markov Model), merge the lattices generated by the DNN-HMM and LSTM-HMM decoding, and then perform keyword search on the merged lattice. The experimental results show that the fusion result is better than the retrieval performance of the DNN-HMM and LSTM-HMM models in terms of accuracy and recall.
Key words: Uyghur; low resources; speech keyword retrieval; deep neural network
0 引言
雖然在維吾爾語的語音識別ASR系統有了許多研究成果[1],但是關于維吾爾語的語音關鍵詞檢索卻比較緩慢,缺乏深入的研究。在如今移動終端以及多媒體信息爆炸性增長的年代,多語言語音信息的檢索研究在社會發展、網絡安全、輿情分析等多個領域有很重要的現實意義,所以應進一步推進低資源語言語音檢索的研究。
首先對維吾爾語語音聲學單元建模,進行連續語音識別,再在此基礎上進行維吾爾語語音關鍵詞的檢索。由識別和索引兩部分組成[2],關鍵詞檢索的方法通常都是用關鍵詞的模板,在連續語音流中進行匹配查找,比如DTW(Dynamic Time Warping)方法和DTW的不同變體等[3]。表示關鍵詞模板的方法有GMM模型[4-5]、HMM模型[6]、DNN[7-8]等,他們對各種特征進行匹配,這些特征包括Speech spectrum、MFCC、PLP、LPC[9]等等。但是這種用關鍵詞模板匹配的方法適用于較小的數據量進行關鍵詞檢索,并且用不同的模板去表示關鍵詞有很大的不同。影響關鍵詞檢索準確的因素有標記錯誤,噪聲,信道不同等[10]。隨著大詞匯量連續語音識別準確率和效率的不斷提高,可以在連續語音識別的基礎上進行語音關鍵詞檢索,通常比DTW模板匹配的結果較好,所以連續語音關鍵詞檢索具有很好的應用價值[11]。
漢語、英語等大語言相關研究很多,如漢語語音關鍵詞檢索,在文獻[12]里檢索達到了80.76%的準確率。由于在實際環境中,噪聲、個性化、情緒等眾多因素的影響,檢測正確率還會大幅降低。
1 系統總體框架
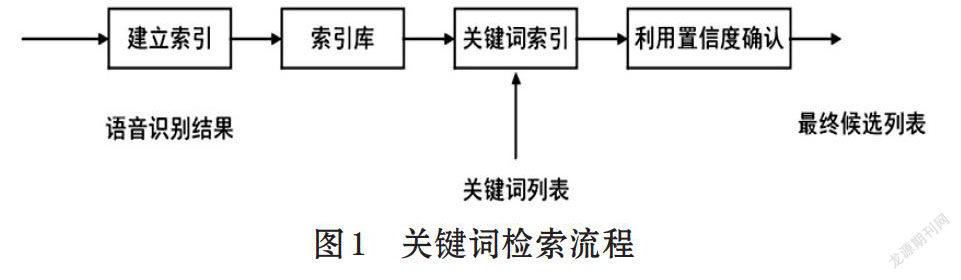
維語音關鍵詞檢索的總體流程是,首先進行維語語音識別,解碼產生相應的lattice,再進行語音關鍵詞檢索。其實lattice只是在語音識別的過程中產生的中間結果,是一個由測試集生成的網格,網格里面包含測試集的每條句子的每個候選詞;由每條測試集句子解碼并聯起來的一個龐大的網格;網格是以加權有限狀態轉換器形式的存在,檢索的時候也需要將檢索的關鍵詞轉換成加權有限狀態轉換器的形式在網格上進行索引,進而在lattice進行語音關鍵詞檢索,通過置信度判斷是否是關鍵詞,關鍵詞檢索的流程如圖1所示。
本文建立GMM,DNN,LSTM,HMM等各種LVCSR系統模型。GMM-HMM模型如圖2所示,DNN-HMM模型如圖3所示,LSTM-HMM模型如圖4所示。GMM,DNN,LSTM都在擬合同一個觀測序列的概率分布,然后作為HMM的觀測狀態概率矩陣;從HMM指向GMM,DNN,LSTM的箭頭是指HMM的某個狀態的觀測概率由某一個GMM,DNN,LSTM的某一個輸出節點決定;最主要的的差別是利用DNN和LSTM代替了GMM實現了狀態概率的輸出;后驗概率可以看作是有監督學習,根據觀測值去求狀態值,而DNN和LSTM是根據觀測值逆向傳播的過程,屬于有監督學習;另外經過softmax輸出,就能得到后驗概率了。
在圖2 GMM-HMM中,HMM的每一個狀態的概率分布由GMM擬合。一個狀態X由一個GMM表征,同時相鄰的GMM之間沒有很強的相關性;GMM模型輸出的似然概率就是HMM狀態的輸出的觀測概率P(Y|X)。
在圖3中,HMM的每一個狀態的概率分布由DNN擬合。DNN一個輸出節點對應一個狀態,為了考慮上下文相關信息,通常送入DNN的是2n+1幀;DNN作為判別模型是直接對給定的觀測序列Y后狀態的分布進行建模,也是監督學習,網絡的輸出P(X|Y)表示不同音素的后驗概率,根據貝葉斯公式需轉換為不同音素的似然概率P(Y|X)。
在圖4中,HMM的每一個狀態的概率分布由LSTM擬合。LSTM一個輸出節點對應一個狀態,為了考慮上下文相關信息,通常送入LSTM的是2n+1幀;LSTM作為判別模型是直接對給定的觀測序列Y后狀態的分布進行建模,也是監督學習,網絡的輸出P(X|Y)表示不同音素的后驗概率,根據貝葉斯公式需轉換為不同音素的似然概率P(Y|X)。
相同點,HMM的狀態初始概率和轉態轉移概率都不變,HMM仍然是對時序進行建模。
2 實驗數據準備
實驗中,維吾爾語語音關鍵詞檢索所使用的語音語料包括,訓練集有7600條音頻和文本句子,驗證集有400條音頻和文本句子,測試集有1468條音頻和文本句子[13]。語料庫的數據集如表1所示。
3 實驗結果及分析
維語語音識別詞錯誤率和維語的關鍵詞檢索結果,分別如表2和表3所示。維語語音在不同的聲學模型中識別詞錯率的情況和關鍵詞檢索性能。本文發現,維吾爾語DNN-HMM比mono識別率提升了28.54%;LSTM-HMM比mono識別率提升了31.24%,與DNN-HMM識別率相比提升了2.7%;LSTM-HMM模型對于維語的語音關鍵詞檢索準確率達到了90.53%。
3.1 基于DNN-HMM聲學模型
使用DNN-HMM聲學模型做語音關鍵詞檢索;維吾爾語實際總的關鍵詞詞數1602,用F4DE獲得,檢出正確的關鍵詞數為1444,檢索到的關鍵詞數為1616,虛警數為172,由關鍵詞檢索的評價的公式可得,召回率為90.14%,準確率為89.36%,虛警率為10.74%。
3.2 基于LSTM-HMM聲學模型
使用LSTM-HMM聲學模型做語音關鍵詞檢索,維語實際總的關鍵詞數為1602,使用F4DE獲得,檢出正確的關鍵詞數為1463,檢索出總的關鍵詞數為1616,虛警的關鍵詞數為153,根據關鍵詞檢索出系統性能評價指標得,準確率為90.53%,召回率91.32%,虛警率為9.55%。
通過實驗對別發現在不同的聲學模型上,維語的關鍵詞檢出的查準率,虛警率,召回率都有所不同,但是在LSTM-HMM模型上的性能最佳,維吾爾語達到了90.53%,相比于單音素而言提升34.28%。 相比于高斯混合模型而言,LSTM網絡更能擬合數據的分布,進而提高關鍵詞檢出的準確率。
4 基于系統融合的維語語音關鍵詞檢出
據文獻[14]所得,語音識別系統性能相近的結果,可以進行系統融合從而提高系統的識別性能,本文的LSTM-HMM和DNN-HMM語音識別系統性能較近且較好,借鑒文獻[15]的網格合并的方法融合系統。
網格融合是將兩個網格的開始節點合并到一個新的開始節點,從而可以將兩個網格合并到一個拓撲結構中,合并后的網格增大了對正確內容的覆蓋率。詞圖合并的方法如圖5所示。
在圖5中,詞圖網格L1用A表示,詞圖網格L2用B表示,詞圖網格L1和詞圖網格L2的融合用用A U B表示,不同網格單元之間的轉移關系可以用(x:y/w)表示,x為輸入,y為輸出,w為權重,eps為空符號。在網格A中,網格單元0到網格單元1的轉移中,輸入為b,輸出為p,權重為3,詞圖網格L1和詞圖網格L2的融合,就是將詞圖網格L1的起始節點和詞圖網格L2的起始節點合并成一個共同的起始節點0。不同網格之間的轉移關系可以用(eps:eps/0),其他的網格單元之間的轉移關系不變;然后按順序改變每個詞圖單元網格的編號,合并后的詞圖網格上部分為詞圖L1,下部分為詞圖L2,通過對比發現只是原始詞圖網格的編號發生了變化,網格單元之間的轉移關系沒有發生變化,合并后的詞圖網格,可以提高正確識別的概率。
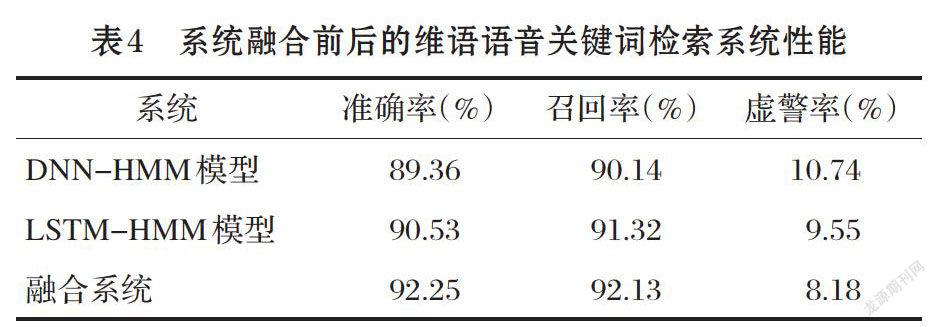
系統融合前后的維語語音關鍵詞檢索系統性能比較,如表4所示。將LSTM和DNN解碼產生的網格進行融合,融合后將會產生一個大的網格圖,可以增加對正確識別內容的覆蓋率,所以對于LSTM-HMM聲學模型的關鍵詞檢出系統,維語的準確率提高了1.72%;對于DNN-HMM聲學模型的關鍵詞檢出系統維語的準確率提高了2.89%,可將融合后的系統用于關鍵詞檢出準確率要求較高的應用場景。
5 結束語
本文在kaldi中搭建了完整的語音關鍵詞檢索系統,使用thuyg20數據集,使用了不同的聲學模型,在語音識別解碼產生的網格lattice上進行語音關鍵詞檢索。實驗結果表明,DNN-HMM和LSTM-HMM模型的檢索性能好于GMM-HMM檢索性能,與GMM相比DNN和LSTM更能準確的擬合語音數據的不同分布情況;為了增大對正確識別內容的覆蓋率,將DNN和LSTM的解碼網絡進行融合,產生更大的網格進行語音關鍵詞檢索,網格融合后的效果要好于DNN-HMM和LSTM-HMM模型的檢索性能。為了進一步驗證網格融合系統性能的有效性,可以將該方法用于哈薩克語,柯爾克孜語語音關鍵詞檢索。
參考文獻(References):
[1] 沙爾旦爾·帕爾哈提,米吉提·阿不里米提,艾斯卡爾·艾木都拉.基于詞干單元的維-哈語文本關鍵詞提取研究[J].計算機工程與科學,2020.42(1):131-137
[2] 李娜,葛萬成.語音關鍵詞識別系統的模型訓練及性能評價[J].信息通信,2020.3:8-10
[3] 侯靖勇,謝磊,楊鵬等.基于DTW的語音關鍵詞檢出[C].全國人機語音通訊學術會議,2015.
[4] Manish Gupta,Shambhu Shankar Bharti,Suneeta Agarwal.?Gender-based speaker recognition from speech signals using GMM model[J]. Modern Physics Letters B,2019.33(35).
[5] GMM Estimation of Non-Gaussian Structural Vector Autoregression[J]. Journal of Business & Economic Statistics,2021.39(1).
[6] 馮怡林.基于HMM和DNN混合模型研究的語音識別技術[D].河北科技大學,2020.
[7] Sun M, Snyder D, Gao Y, et al. Compressed Time Delay Neural Network for Small-Footprint Keyword Spotting[C].conference of the international speech communication association,2017:3607-3611
[8] Chen G, Parada C, Heigold G, et al. Small-footprint keyword spotting using deep neural networks[C].international conference on acoustics,speech,and signal processing,2014:4087-4091
[9] 羅元,吳承軍,張毅,黎小松,席兵.Mel頻率下于LPC的語音信號深度特征提取算法[J].重慶郵電大學學報(自然科學版),2016.28(2):174-179
[10] 張舸,張鵬遠,劉建,顏永紅.基于動態時間規整的語音關鍵詞檢索算法[J].網絡新媒體技術,2019.8(1):18-23
[11] 李寶祥.語音關鍵詞檢索若干問題的研究[D].北京郵電大學,2013.
[12] 侯云飛.中文語音關鍵詞檢出技術研究[D].南京理工大學,2017.
[13] 艾斯卡爾·肉孜,殷實,張之勇等.THUYG-20:免費的維吾爾語語音數據庫[J].清華大學學報:自然科學版,2017.57(2):182-187
[14] 李偉.基于內容的漢語語音檢索技術研究與系統實現[D].清華大學,2011.
[15] 李鵬,屈丹.基于得分歸一化和系統融合的語音關鍵詞檢測方法[J].數據采集與處理,2017.32(2):346-353
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
無線電工程(2020年11期)2020-10-29 01:25:46
現代出版(2020年3期)2020-06-20 07:10:34
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
