基于不相關性檢驗的大數(shù)據(jù)異常抽取算法
2021-11-17 03:12:40諶裕勇陸興華
計算機仿真 2021年3期
諶裕勇,陸興華
(廣東工業(yè)大學華立學院,廣東 廣州 511325)
1 引言
計算機與互聯(lián)網(wǎng)技術的廣泛應用,使得各行業(yè)數(shù)據(jù)均呈爆炸性增長,龐大數(shù)據(jù)量已成為互聯(lián)網(wǎng)重要研究目標之一[1]。數(shù)據(jù)抽取可實現(xiàn)海量數(shù)據(jù)內(nèi)高效獲取目標信息與知識,數(shù)據(jù)規(guī)模大、多樣化是大數(shù)據(jù)的基本特征。海量數(shù)據(jù)內(nèi)通常會存在少量數(shù)據(jù)對象與正常數(shù)據(jù)期望行為不同,通常將其稱為大數(shù)據(jù)的異常值[2],恰當處理此類異常數(shù)據(jù)是維護大數(shù)據(jù)正常應用的必要途徑。在此背景下,有許多專家對此問題進行研究,得到了一些較好成果。
文獻[3]按照異常網(wǎng)絡數(shù)據(jù)的混合分類屬性完成大數(shù)據(jù)之間的相似度分析,獲得數(shù)值屬性特征與分類屬性特征。運用聯(lián)合關聯(lián)規(guī)則對異常網(wǎng)絡數(shù)據(jù)完成模糊融合,建立異常網(wǎng)絡數(shù)據(jù)分類模糊集,在模糊數(shù)據(jù)集中完成數(shù)據(jù)混合加權(quán)與自適應分塊匹配,提取異常數(shù)據(jù)弱關聯(lián)化特征量,將提取的特征量輸入到模糊神經(jīng)網(wǎng)絡分類器中實行數(shù)據(jù)分類識別,達到異常大數(shù)據(jù)目標挖掘。但由于大數(shù)據(jù)具有較高隨機性,導致該方法的應用準確性不高。文獻[4]提出大數(shù)據(jù)集合中冗余特征排除的聚類算法。利用一致性聚類算法抽取各種子集樣本,完成大數(shù)據(jù)冗余特征排除,并得到排除冗余特征的大數(shù)據(jù)集聚類結(jié)果。采用特征聚類和隨機子空間的識別算法,聚類大數(shù)據(jù)集合冗余特征,實現(xiàn)大數(shù)據(jù)異常的抽取。但該方法存在計算開銷大及復雜度高等問題。
針對以上傳統(tǒng)方法存在的問題,提出大數(shù)據(jù)異常抽取算法。對大數(shù)據(jù)流量分流處理,利用預處理端與儲存端監(jiān)測異常數(shù)據(jù)風險,有效降低大數(shù)據(jù)異常抽取的耗時。基于此,構(gòu)建不相關性檢驗模型,引入模糊遺傳方法算出異常數(shù)據(jù)流匯聚于多層空間內(nèi)的模糊聚類中心,耦合關聯(lián)訓練集與所屬類型,大大增加大數(shù)據(jù)異常抽取的精度,最終實現(xiàn)高精度大數(shù)據(jù)異常抽取。實驗結(jié)果驗證了所提方法能夠低耗時、高精度的完成大數(shù)據(jù)的異常抽取。
2 大數(shù)據(jù)全局趨勢分析
在完成大數(shù)據(jù)異常抽取過程中,大數(shù)據(jù)全局風險趨勢分析是必要的[5],可有效估計大數(shù)據(jù)異常概率。建立基于Hadoop的大數(shù)據(jù)平臺異常風險監(jiān)測平臺,預判斷大數(shù)據(jù)是否存在異常問題,判別大數(shù)據(jù)安全等級,為不相關數(shù)據(jù)分析提供借鑒。
大數(shù)據(jù)具有體量龐大、類別復雜等特征,所以平臺在Hadoop操作原理前提下進行規(guī)劃,采用Map/Reduce分布式形態(tài)對大數(shù)據(jù)實時操作,過程如圖1所示。圖中將大數(shù)據(jù)內(nèi)的異常數(shù)據(jù)監(jiān)測任務劃分成多類子任務,各類子任務依次經(jīng)過一個節(jié)點,最終將結(jié)果傳輸至數(shù)據(jù)庫管理節(jié)點內(nèi),主管理節(jié)點融合所有結(jié)果后,所得數(shù)據(jù)即為異常風險數(shù)據(jù)監(jiān)測成果。
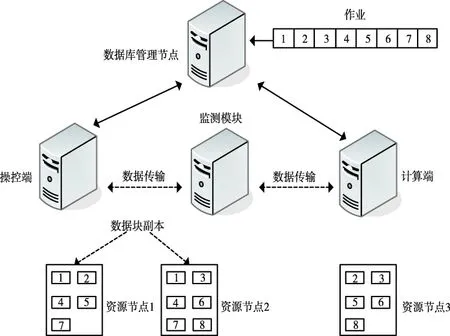
圖1 Hadoop操作示意圖
圖1中大數(shù)據(jù)平臺通過計算端與操控端構(gòu)成,利用接口1將其相連到同一個路徑,增強大數(shù)據(jù)傳輸適用性。接口2即為平臺作為操控端輸入網(wǎng)絡參變量重置標準,SDN控制器對大數(shù)據(jù)的控制就是將參變量重置后的大數(shù)據(jù)流進行分流,將大數(shù)據(jù)依次傳輸至監(jiān)測板塊,使得監(jiān)測板塊能實時精準的異常數(shù)據(jù)風險趨勢監(jiān)測。監(jiān)測板塊內(nèi)包含預處理端與儲存端,并設定預警電路與緩沖電路,增強系統(tǒng)對風險趨勢預測可靠性。本文運用最小二乘向量機監(jiān)測大數(shù)據(jù)平臺異常風險[6-7],設定大數(shù)據(jù)平臺內(nèi)的異常數(shù)據(jù)監(jiān)測樣本集合為
D={(xk,yk)|k=1,2,…,N}
(1)
徑向基函數(shù)為核函數(shù)ψ(·,·),運算過程為

(2)
其中,σ代表徑向基函數(shù)寬度參變量。
最小二乘支持向量機的最佳決策函數(shù)運算方程是
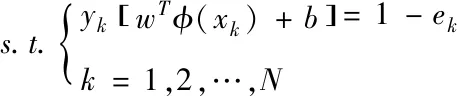
(3)
其中,γ表示內(nèi)正則化參變量。
在式(3)內(nèi)引入拉格朗日乘子方法,得到:
L(w,b,e,a)=φ(w,b,e)=akyk[wTφ(xk)+b]-1+ek
(4)
其中,ak∈R表示拉格朗日乘子。
按照Mercer定理可知Ω=ZZT,即:
Ωkl=yky1φT(xl)=yky1Ψ(xk,xl)
(5)
將最小二乘支持向量機最佳決策函數(shù)轉(zhuǎn)換為式(12),實現(xiàn)大數(shù)據(jù)風險趨勢計算全過程。
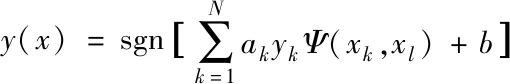
(6)
3 大數(shù)據(jù)異常抽取算法
3.1 構(gòu)建不相關性檢驗模型
通過上述過程計算出大數(shù)據(jù)具有異常風險狀態(tài)后,為獲得更加準確的大數(shù)據(jù)不相關數(shù)據(jù)特征,代入Fisher函數(shù)等價模式[8],構(gòu)建不相關性檢驗模型。若樣本類間散布矩陣是Sb,類內(nèi)散布矩陣是Sw,那么Fisher函數(shù)表達式為
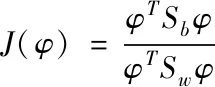
(7)
不相關性檢驗模型是為了探尋不相關檢驗向量而提出的,其目標是找出符合Si共軛正交條件,同時讓Fisher函數(shù)完成極值最佳檢驗向量φ1,φ2,…,φd。在真實操作中,第一個檢驗向量是Fisher最優(yōu)檢驗矢量。若現(xiàn)階段k個檢驗向量φ1,…,φk被求出后,則第k+1個不相關性檢驗向量φk+1可由式(8)進行求解
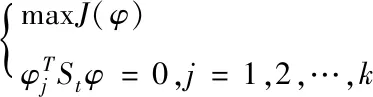
(8)
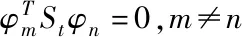
以式(8)為前提,可明確第k+1個不相關性檢驗向量是以下廣義特征方程最大特征值相對的特征矢量,記作
PSbφ=λSwφ
(9)
式中

(10)
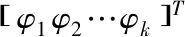
(11)
I=diag{1,1,…,1}
(12)
在不相關性檢驗向量的運算表達式中可知,各個檢驗向量相對的p的運算均牽涉數(shù)量較多的矩陣計算,中間還包含較多矩陣逆運算。在大數(shù)據(jù)不相關性檢驗向量數(shù)量較多時[9],求解全部檢驗向量的計算代價很高。下面改進不相關性檢驗模型,以便解決計算代價高的問題。
式(13)是Fisher函數(shù)表達式的等價模式,記作
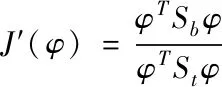
(13)
按照Fisher檢驗分析定理,應當計算出讓J′(φ)得到極值的φ,通常把J′(φ)模式的極值問題和以下廣義特征方程問題進行統(tǒng)一解決
Sbφ=λStφ
(14)
利用式(14)來描述Fisher函數(shù),那么不相關性檢驗向量集問題模型就變換成以下問題模型:首個檢驗向量是式(14)最大特征值相對的特征矢量,第r+1個不相關檢驗向量通過式(15)求解,呈現(xiàn)大數(shù)據(jù)中數(shù)據(jù)實時狀態(tài)
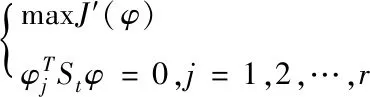
(15)
3.2 基于模糊遺傳的大數(shù)據(jù)異常抽取算法
不相關性檢驗模型為大數(shù)據(jù)異常抽取提供精準的數(shù)據(jù)特征依據(jù),下面采用模糊遺傳算法實現(xiàn)大數(shù)據(jù)異常抽取目標,為大數(shù)據(jù)安全及數(shù)據(jù)平穩(wěn)傳輸發(fā)揮積極作用。
傳統(tǒng)方法使用遺傳算法對大數(shù)據(jù)異常抽取的具體操作是設計一個種群適應度函數(shù)及各種遺傳操作,包含交叉變異、收斂條件等[10]。
如果在c個類型相對的樣本類型ωm是已知值,假設被求解的參數(shù)是Q,Xi是參數(shù)Q空間內(nèi)的解,針對各個Xi相對的函數(shù),fi為Xi的適應度函數(shù),所獲得的最佳解即為讓xm和函數(shù)值fm均是最大或最小的值。
遺傳算法內(nèi)的染色體被劃分成三個子模塊,分別是連接順序和網(wǎng)絡節(jié)點挑選、副本關聯(lián)挑選及網(wǎng)絡半連接控制。使用勻稱隨機方法生成二個交叉點,然后把二個交叉點交叉過程中涵蓋的區(qū)域設定成匹配范圍,將其記作
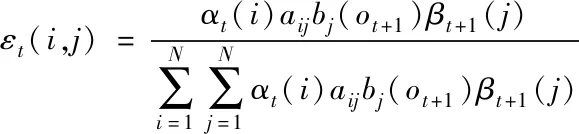
(16)
其中,αt(i)是大數(shù)據(jù)內(nèi)異常數(shù)據(jù)的監(jiān)測節(jié)點信道誤差,bj(ot+1)代表平均值是0,方差是1的復高斯過程。
設定異常數(shù)據(jù)節(jié)點數(shù)據(jù)融合濾波器系統(tǒng)函數(shù)是

(17)
其中,Sd(f)表示多普勒功率譜。
使用遺傳算法應用到異常數(shù)據(jù)特征迭代過程中,會產(chǎn)生一個種群,此時適應度強、遺傳性質(zhì)較優(yōu)的染色體變成算法的首要挑選目標[11]。本文設計一種模糊遺傳方式完成異常數(shù)據(jù)特征選擇,遺傳迭代查詢散布解析式為
pri(t)=p(t)*hi(t)+npi(t)
(18)
其中,hi(t)是p(t)在大數(shù)據(jù)異常特征抽取時的變異矢量。算出大數(shù)據(jù)內(nèi)異常數(shù)據(jù)特征響應函數(shù)為
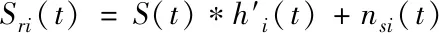
(19)

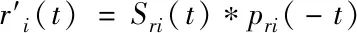
(20)
使用模糊遺傳方法算出異常數(shù)據(jù)流匯聚于多層空間內(nèi)的模糊聚類中心,那么j為i的激活因子,得到
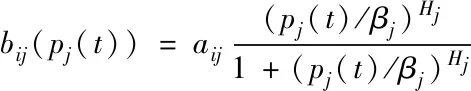
(21)
把訓練集和其所屬類型實時關聯(lián),獲得異常數(shù)據(jù)屬性集分類的信息增益解析式

(22)
通過式(22)可知,使用模糊遺傳算法完成大數(shù)據(jù)異常抽取時,能夠把隨機變異轉(zhuǎn)換為換位控制,兩個等位基因相互交換,數(shù)據(jù)染色體交叉之后無需修復。副本選擇基因與半連接基因全部運用勻稱雜交方法,增強異常數(shù)據(jù)抽取性能。
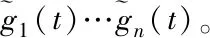
異常數(shù)據(jù)特征對最小二乘支持向量機性能影響較多,對其余特征影響較少,采取歸一化手段清除此類不良影響[12],具體過程為

(23)
其中,n代表訓練樣本數(shù)量,xstd代表標準差。
使用模糊數(shù)學隸屬函數(shù)值方法抽取大數(shù)據(jù)內(nèi)的異常數(shù)據(jù),隸屬函數(shù)值運算公式為
R(Xi)=(Xi-Xmin)/(Xmax-Xmin)
(24)
其中,Xi是指標檢測值,Xmax、Xmin依次是數(shù)據(jù)異常某項指標的最大值與最小值。
利用以上過程即可完成準確的大數(shù)據(jù)異常抽取,為數(shù)據(jù)流的正常使用提供有效解決途徑。
4 實驗分析
為檢驗所提方法性能,在Cslogs大數(shù)據(jù)集上對所提方法與文獻[3]、文獻[4]算法進行實驗對比。實驗在Windows 10環(huán)境中進行,計算機CPU是Pentium(R)DualCore T4300@2.10GHz,內(nèi)存2.0GB,硬盤是320GB。
4.1 不同算法的大數(shù)據(jù)異常抽取效率對比
在輸入數(shù)據(jù)量固定時,按照最小支持度改變量,對比三種方法性能。關于大數(shù)據(jù)異常抽取算法,支持度適應能力是一個關鍵指標。圖2是所提算法與文獻算法的大數(shù)據(jù)異常抽取運行效率對比。
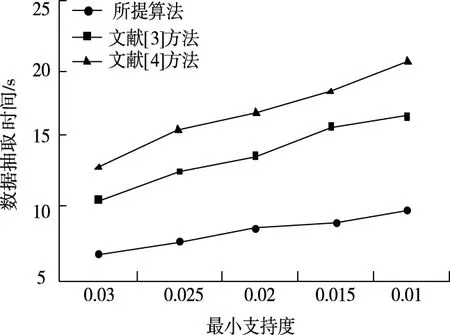
圖2 三種方法大數(shù)據(jù)異常抽取時間對比
從圖2中可知,最小支持度從0.03減少至0.01,以抽取效率角度而言,所提方法在大數(shù)據(jù)異常抽取時的消耗時長遠低于文獻[3]及文獻[4]方法,原因在于所提方法利用不相關性檢驗模型,很好地展現(xiàn)數(shù)據(jù)真實狀態(tài),有效提高大數(shù)據(jù)異常抽取速率。
4.2 不同算法的大數(shù)據(jù)異常抽取準確度對比
為驗證所提算法的大數(shù)據(jù)異常抽取準確性,隨機選取大數(shù)據(jù)集合(來源:caesar0301/awesome-public-datasets·GitHub),對大數(shù)據(jù)訓練集進行可視化區(qū)域劃分,利用思邁特軟件對大數(shù)據(jù)進行可視化處理,得到異常數(shù)據(jù)較多區(qū)域,以60cm×70cm網(wǎng)格為實驗區(qū)域,大數(shù)據(jù)中的異常數(shù)據(jù)用星狀表示,具體實驗結(jié)果如圖3。
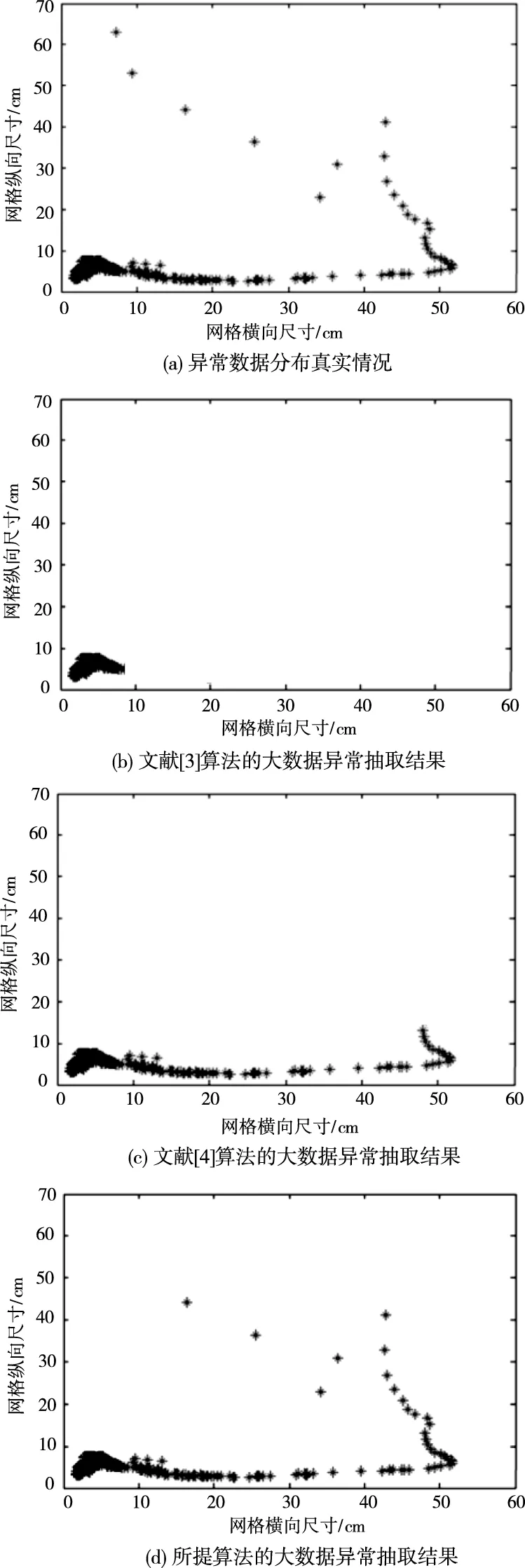
圖3 不同算法的大數(shù)據(jù)異常抽取對比測試
由圖3的實驗結(jié)果可知,在大數(shù)據(jù)的實驗測試區(qū)域內(nèi),文獻[3]算法和文獻[4]算法只能抽取出較為密集的異常數(shù)據(jù)區(qū)域,抽取結(jié)果與實際情況相差較大,說明傳統(tǒng)算法的異常數(shù)據(jù)抽取誤差偏大。相比之下,所提方法的大數(shù)據(jù)異常抽取結(jié)果與實際情況基本一致,進一步驗證了所提算法的應用有效性。
5 結(jié)論
1)為提升大數(shù)據(jù)異常抽取時效性與準確性,引入不相關性檢驗,設計新的大數(shù)據(jù)異常抽取算法。
2)實驗結(jié)果顯示:在最小支持度從0.03減少至0.01過程中,所提方法的耗時由7s增加到了9s,與傳統(tǒng)方法相比耗時有明顯下降。且所提方法的大數(shù)據(jù)異常抽取結(jié)果與實際情況基本一致。以上實驗結(jié)果驗證了所提方法能夠高速率、高精度的完成大數(shù)據(jù)異常抽取,應用魯棒性強,有效增強了大數(shù)據(jù)異常辨識能力。
3)但在本次研究中,對大數(shù)據(jù)異常風險產(chǎn)生原因研究不夠具體,不能從根源減少問題的發(fā)生,下一步會著重在此方面進行探究。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
