基于模糊向量機優化的信息分類優化模型設計
2021-11-17 08:37:30趙傳信
計算機仿真 2021年5期
趙 誠,趙傳信,夏 蕓
(安徽師范大學計算機與信息學院,安徽 蕪州 241000)
1 引言
分類即通過訓練樣本構建模型,將測試樣本分為一種或多種類的方法,傳統單標簽分類問題的所有實例都只存在一種單獨的類標,同時這個類標來自于互不相交的有限標簽集合。然而,在現實生活中,有很多問題都存在多種標簽[1]。例如,一首歌曲可能存在多種標簽,一則新聞可能同時涉及宗教與政治兩種不同的體系。除此之外,視頻與圖書的語義標注、功能基因組學、文本分類以及其他應用均具有多標簽特性。由于多標簽應用問題的不斷出現,對多標簽的研究吸引了眾多學者的關注,其成為了數據挖掘領域中一種新的研究熱點之一[2]。
肖琳[3]等提出基于標簽語義注意力的多標簽文本分類方法,該方法通過雙向長短時記憶得到不同單詞的隱性表示,并采用標簽語義注意力機制獲取每個單詞的權重,在此基礎上利用標簽的相關性,在文本數據集中實現文本分類。實驗結果表明,該方法能夠實現對不同類型文本信息的分類,但是分類結果中存在大量的重疊信息。李鋒和楊有龍[4]提出了基于標簽特征和相關性的多標簽分類算法,采用重采樣技術獲取正類實例,同時,利用特征映射函數轉換特征空間,以此得到標簽特征集,并尋找特征集中互為相關的標簽,從而實現多標簽分類。實驗結果證明,該算法可以改善類不平衡的問題,但是分類結果準確性不高。由于傳統的信息分類方法,大多只通過數據挖掘領域內的支持向量機對信息進行分類,但這類方法很容易會損傷信息標簽,導致分類效果不佳。
針對上述問題,設計了一個基于模糊向量機優化的信息分類優化模型,通過模糊C劃分方法與信息增益,提升需要分類標簽的特征,依靠模糊支持向量機與核聚類,實現信息分類優化的目的。
2 基于模糊向量機優化的信息分類優化模型
2.1 模糊C劃分
把模糊C均值使用在信息分類優化中,針對信息類型的多樣性,對多標簽信息進行分類,憑借隸屬度U描述一種標簽歸于某一標簽的程度。多標簽空間L={l1,l2,…,ll}的模糊C劃分目標函數是:

(1)

J(U,c1,…,cc,λ1,…,λj)

(2)
其中,λj=(j=1,…,q)代表q種約束式的拉格朗日乘子。對每一種輸入參量進行求導,獲得隸屬度[5]的更新方程為:

(3)
2.2 信息增益
信息增益可量化隨機標簽變量X與Y的關系程度,其值的運算方式如下所示:

(4)
其中,p(x)代表x的概率密度;p(x,y)代表x與y的聯合概率密度。
信息增益能夠通過聯合熵[6]與熵進行描述即:
IG(X,Y)=H(X)+H(Y)-H(X,Y)
(5)
信息增益可以有效地表示兩種或多種變量標簽之間的關系程度,信息增益越大,代表變量之間的關系程度越高。
2.3 雙標簽模糊向量機模型
模糊支持向量機會在所有信息樣本中添加一種隸屬度,對于多標簽信息,首先根據具體問題,選取一種合適的隸屬度函數,這個函數需要能夠映射所有信息樣本xi對其所屬類別yi的隸屬度。因此,把原始訓練集?={(x1,y1),(x2,y2),…,(xl,yl)}變換為模糊訓練集:
?′={(x1,y1,μ1),(x2,y2,μ2),…,(xl,yl,μl)}
(6)
其中,xi∈Rd(i=1,2,…,l)代表在d維空間內的第i種測試信息樣本。在多標簽分類問題中,yi∈{-1,1},0≤μi≤1代表訓練點(xiyiμi)隸屬于yi類的模糊隸屬度。
擬定參數ξi為測量錯分程度的度量,模糊隸屬度μi即訓練點(xiyiμi)歸屬于某種類的程度,因此,(μi,ξi)可以用于測試重要性不同的訓練點錯分程度。
針對模糊訓練集[7],把運算最優分配超平面的問題,轉化為下列運算優化問題:

(7)
其中,把xi∈Rd映射到高維特征空間,C>0即懲罰因子,該因子可以表示錯分的關鍵程度,ξi≥0為信息樣本的松弛向量,ξ=(ξ1,ξ2,…,ξl)T,w,b分別代表高維特征空間內線性評測函數的常數項與權向量。
將式(7)的優化問題對偶規劃成:

(8)
f(x)=sgn{(w*×x)+b*},x∈Rd
(9)
針對非線性問題,添加核函數K(xi,xj),能夠把式(8)轉換成:
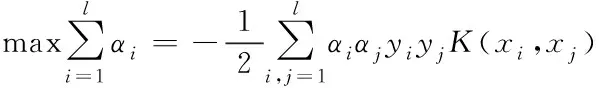
(10)
經過計算最優化問題,進一步得到最優分類函數[8]為:
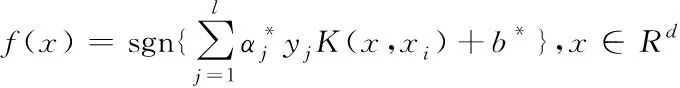
(11)
2.4 基于模糊向量機的多標簽信息分類
根據得到的最優分類函數,使用一對一分解策略將分類的初始問題分解成k(k-1)/2種子問題,所有子問題均存在多種類的信息,則所有信息樣本具有三種情況:只含有第一種標簽的信息樣本;只含有第二種信息標簽的樣本;同時含有第一、二種信息標簽的樣本。為了便于查找,在子問題里將含有第一種信息標簽的樣本表示為正類樣本,設定其輸出yi=1,把含有第二種信息標簽的樣本表示為負類樣本,設定其輸出yi=-1;將同時存在第一、第二種信息標簽的樣本描述成混合類樣本,擬定其輸出是yi=0。
通過搜索支持向量機[9]構建最優超平面,繼而把信息樣本分化成相互獨立的兩大類。然而在現實使用中,在某些特定狀態下,信息樣本并不能完全規劃至某一類內,即樣本和類別之間具有某種模糊隸屬關系,因此,通過模糊支持向量機[10]經過增添一種模糊隸屬關系,進而充分地利用信息樣本。
擬定子集為Xmn={(x1,y1,μ1),…,(xl,yl,μl)},其中,m∈[1,k],n∈(m,k],xi∈Rd(i=1,2,…,l)代表在d維空間內的第i種測試信息樣本;在多標簽分類問題中,yi∈{-1,0,1},其中,訓練子集信息樣本函數值為1、-1與0的信息樣本總量分別為l+,l-,l0(l++l-+l0=l),0≤μi≤1代表訓練點(xiyiμi)隸屬于某種類的模糊隸屬度。

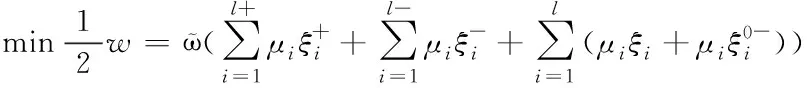
(12)
模糊支持向量機憑借訓練信息樣本對分類作用的不同,給不同的信息樣本添加不同的錯分懲罰,繼而克服噪聲對分類的干擾。模糊支持向量機在應用中的難點在于怎樣確定信息樣本的隸屬度,如果確定不當,會造成分類器精度的降低,因此,需要對模糊向量機進行優化,從而實現對信息的準確分類。
2.5 基于核聚類的模糊向量機優化
模糊支持向量機訓練效率較慢,其大部分運算在于查找支持向量,進而組建最優超平面。而通過研究發現,模糊支持向量通常會在特征空間的邊緣分布,位于類中心的向量大多都不是支持向量,對組建最優超界面沒有任何意義,其具體流程如圖1所示。

圖1 支持向量分布圖
圖1內,黑色正方形為一類信息,圓點為另外一類信息,H為最優分類超平面,其是經過一組支持向量位移確定的。但是信息樣本里一般會存在一些不存在合理解釋的樣本,比如圖內的噪聲點。這些噪聲點會對學習得到的最優超平面造成嚴重的負面影響。而通常來講,信息樣本只是訓練集中的一部分,因此較為現實的辦法就是刪除那些不可能是支持向量的點,再訓練支持向量機,這樣就可以最大程度地減少運算量,同時提升最優超平面獲取結果。
由于核聚類算法具有收斂效率高的特點,而模糊聚類對初始化問題不會過于敏感,同時其中的隸屬度函數還能夠將信息樣本之間的相近信息進行映射,因此,通過將半模糊劃分方法引入核聚類內,獲取半模糊核聚類算法來解決問題。
擬定核映射Φ(xi)為將信息樣本xi映射到高維特征空間H的非線性映射,模糊劃分矩陣為U={μji},1≤j≤C,1≤i≤n,vj代表第j種簇的聚類中心,m∈(1,∞)代表模糊加權指數,那么兩點xi,xj在特征空間內的尺寸d(xi,xj)為:

=Φ2(xi)-2Φ(xi)·Φ(xj)+Φ2(xj)
=K(xi,xi)-2K(xi,xj)+K(xj,xj)
(13)
半模糊核聚類方法的具體實現過程如下所示:
1)挑選迭代終止條件ε∈(0,1),最大迭代次數為T;
2)初始化類中心v1,v2,…,vc;
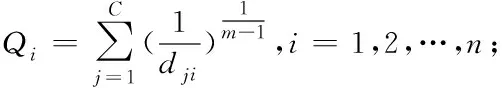
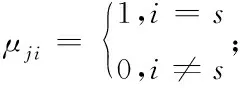
5)運算K(xi,vj),K(vi,vj);


算法中m代表超過1的參數,B為超過0的參數,其值越大,評測信息樣本隸屬度達到1的標準就越困難,經過測驗,其取值達到0.65時,能夠獲得期望中的聚類效果。經過核聚類,信息樣本被分類為若干個模糊類,其形式為(xi,μji)。
依靠μji的值,信息樣本可以被分成兩類:信息樣本完全歸于某一類,該類樣本對其他類的隸屬度為0,這種信息樣本一般都比較靠近某一類的中心,并且和其他類相距較遠,通常不會變成支持向量;另外一種即信息樣本至其他類的距離相差不大,其位于不同交界坐標,該類樣本存在一定幾率成為支持向量。對于前者,可以直接將其分類到最接近的類內,不需要考慮和其他類的關聯,不需要再進入到下一步支持向量機的訓練內。對于后者,需要憑借訓練學習對其進行評價,然后將其分類到某一類內。
3 實驗證明
為了證明所提方法的實用性,擬定不同的信息數據集,并選取三個評價標準即:漢明損失、準確性以及信息重疊率,對基于標簽語義注意力的多標簽文本分類方法(方法1)、基于標簽特征和相關性的多標簽分類算法(方法2)以及所提方法的分類結果進行評測,具體的實驗數據集如表1所示。
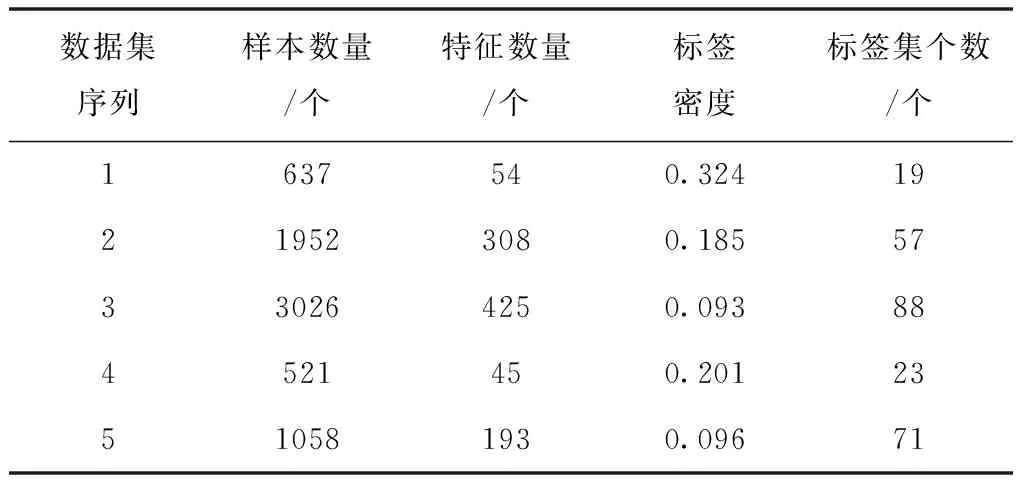
表1 實驗數據集
以上述數據集中包含的樣本為實驗對象,進行信息分類,對比不同方法在分類過程中造成的漢明損失,結果如表2所示。

表2 漢明損失對比
從表2能夠看出,所提方法在五種信息數據集的兩種評價標準中,其評價結果都較為優秀,這就證明,所提方法能夠較為精確地劃分多標簽信息,且不會丟失太多的漢明信息。這是因為該方法通過模糊C劃分與信息增益,來提高需要分類信息的特征度,進而能夠更為精確地搜索需要分類的信息。
以分類結果準確性為指標,對比不同方法的分類效果,結果如圖2所示。

圖2 分類準確率對比
分析圖2可知,所提方法在多標簽信息分類過程中,能夠獲取更加準確的分類結果,其準確率最高值達到了80%以上,說明分類結果更加可靠。這是由于該方法利用模糊支持向量機給不同的信息樣本添加不同的錯分懲罰,克服了噪聲對分類的干擾,從而提升了準確率。
信息重疊率過高影響分類效果,以其為實驗指標,對比不同方法的分類效果,結果如圖3所示。
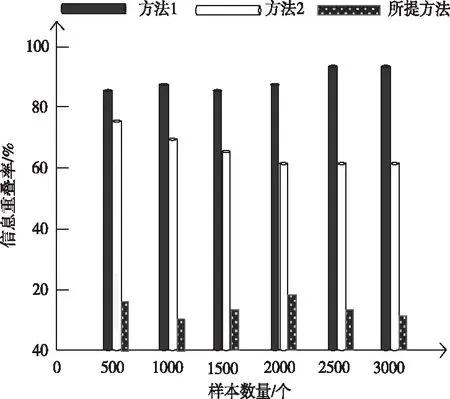
圖3 信息重疊率對比
分析圖3可知,所提方法分類后信息重疊率均低于20%,與現有方法相比,具有明顯的優勢性,說明該方法的分類效果能夠滿足實際需求,具有一定的使用價值。
4 結束語
為了解決信息分類時出現的準確度低與信息重疊的問題,設計一種基于模糊向量機優化的信息分類優化模型,依靠模糊支持向量機與核聚類完成對多標簽信息的分類。雖然所提方法能夠有效地分類多標簽信息,但隨著研究的深入,也發現了一些弊端,因此下一步需要研究的課題即:擴展、優化所提方法,使方法的計算能力提升,同時還需要增加其算法容量。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
