國產異構系統上HPL 的優化與分析?
2021-11-09 02:45:18水超洋于獻智王銀山譚光明
軟件學報 2021年8期
關鍵詞:模型
水超洋 ,于獻智 ,王銀山 ,譚光明
1(中國科學院 計算技術研究所,北京 100190)
2(中國科學院大學,北京 100190)
HPL(high performance linpack)是目前HPC 領域中最重要的基準測試程序之一,其性能被用作TOP500 的排名依據[1,2].HPL 可以從超級計算機的計算性能、訪存性能、網絡性能、可用性和穩定性等各個方面給予超級計算機綜合評價.HPL 的優化具有重要意義,在學界長期受到關注和研究.HPL 的優化可以為其他科學計算應用的并行優化提供有價值的參考.
自1993 年TOP500[3]排名開始,榜單中的超級計算機的體系結構一直在發生變化.圖1 展示了排名第一的計算機的體系結構的變化.從圖1 中我們可以看到超算的體系結構從早期的向量處理器和單核通用CPU 時代開始,然后演進到多核CPU 時代,超級計算機的計算能力也從GFLOPS 提升到TFLOPS.2008 年的超算Roadrunner[4]標志著異構架構的超級計算機體系結構的興起,隨后異構架構開始頻繁涌現,超級計算機進入了PFLOPS 的時代.各種加速器,如GPU、DSP、FPGA、MIC 等都作為加速卡出現在各種超算中,我國有也了自己的國產加速器和國產處理器.伴隨著超算體系結構的變化,HPL算法的設計與實現也應該適應新的體系結構.在這種背景下,本文建立了國產處理器-國產加速器異構架構上的HPL 性能模型,重點研究了國產處理器-國產加速器異構架構下的HPL算法的設計與實現.本文的主要貢獻如下:
?本文建立了一個HPL 性能模型.
?針對國產處理器-國產加速器異構架構,本文設計了一種多線程細粒度流水HPL算法,充分利用異構系統中的多種硬件,取得了超過同類系統其他實現的效率.
?本文實現了輕量級跨平臺的異構加速框架HPCX.
本文第1 節分析相關研究.第2 節介紹HPL 的性能模型.第3 節給出針對異構架構的多線程細粒度流水HPL算法及異構加速框架HPCX.第4 節呈現新HPL算法的性能以及分析.第5 節總結全文.
1 相關研究
HPL 是橫量超算性能最重要的基準測試程序之一,其性能作為TOP500 排名的依據.由于HPL 的重要地位,國內外有許多針對Linpack 的優化工作.這些工作主要集中在HPL算法優化,雙精度矩陣乘法效率優化和HPL性能模型3 個方面.
在Linpack算法優化方面,Dongarra 等人基于消息通信接口(message pass interface,簡稱MPI)和基本線性數學庫(basic linear arithmetic subroutine,簡稱BLAS)的Level 3 函數實現了分布式的HPL算法[1].在此基礎上,文獻[5]提出了一種單邊通信和動態look-ahead算法,通過重疊第i+1 輪迭代的panel 分解與第i輪迭代的尾矩陣更新來實現部分通信與計算的重疊.針對異構架構,Fatica 通過將尾矩陣劃分為固定比例的兩塊分別分配給加速器和CPU 以實現CPU 和加速器的協同計算[6].Yang 擴展了Fatica 的工作實現了動態的CPU 和加速器計算任務劃分,采取根據上一次計算的CPU/加速器性能比決定下一輪任務劃分比例的策略[7].文獻[8]實現了一種work-stealing 的策略來實現CPU 和加速器的計算任務動態平衡,并且利用有向無環圖來維護算法中的計算依賴關系.通過這種對依賴關系的分析,文獻[8]將行交換的過程分成幾個部分,通過行交換和尾矩陣更新的相互重疊探索了一種粗粒度的流水線算法.
作為HPL 的核心運算,雙精度矩陣乘法的優化在HPL 的優化中占有重要地位并且得到了全面而深入的研究.在傳統CPU 平臺上,文獻[9]給出了CPU 上的矩陣乘法的分層算法,通過對CPU 存儲層次的模擬設計出相應的多級分塊緩存策略,以盡可能地利用高速緩存中的數據.在包含加速器的異構架構上,李佳佳等提出了五階段流水的異構矩陣乘算法來掩蓋CPU 與加速器之間的PCIe 數據傳輸[10,11].MAGMA[12]通過細粒度的任務劃分并且靈活地在CPU 和加速器上調度這些任務來實現負載的動態平衡.為充分利用加速器如GPU 的計算能力,文獻[13]通過微基準測試來探測GPU 的體系結構,在匯編語言層面做了多種優化,以實現接近GPU 理論浮點峰值性能的雙精度矩陣乘效率[13].
關于HPL 的性能建模,文獻[14]以預測HPL 的擴展性為目的給出了HPL 在CPU 系統上的性能模型.HPL的求解時間被建模為panel 分解,panel 廣播,行交換和尾矩陣更新的時間之和,并給出了模型中一些常量系數的經驗值.王申等人在這個基礎上考慮了look-ahead算法中部分廣播開銷可以被尾矩陣的更新和行交換所掩蓋的情況[15],給出了更為精確的模型.文獻[16]認為上述模型的計算都不夠精確,因為模型中的常量值都是經驗值,而CPU 計算效率以及通信帶寬等模型常量都會受數據量大小的影響.他們主張將這些常量系數視為可變的,通過已有的測試結果去學習這些系數,用學習得到得系數建模預測大規模求解的性能.
已有文獻中對HPL 的優化主要集中在同構架構上的簡單算法優化和性能建模以及異構架構上的雙精度矩陣乘的優化上,而缺少異構架構上的HPL 的算法建模和算法流水層面的優化.本文在CPU 的HPL 性能模型的基礎上建立了國產處理器-國產加速器異構架構上的HPL 性能模型,并提出了多線程細粒度的HPL 流水線算法,以充分發揮異構系統中國產處理器的巨大計算能力.在實現上,我們實現了一個輕量級的跨平臺異構加速框架HPCX,并用生產者消費者模型來協調多線程和多流的協同計算.
2 HPL算法和性能模型
2.1 HPL算法簡介
HPL算法通過迭代法求解N 階線性方程組Ax=b.求解過程包含兩個步驟,首先通過帶行交換的高斯消元法對系數矩陣進行 LU 分解得到[Ab] =[[L,U]y],然后進行三角回帶求解x.其中 LU 分解的計算量為,三角回帶的計算量為2N2[1].給定系統的理論浮點峰值性能和HPL 的求解時間T,系統的實測浮點峰值性能Rmax可以表示為,HPL 的效率E=Rmax/Rpeak.
HPL 的兩個步驟中LU 分解的計算量為O(N3),三角回帶的計算量為O(N2),相比于LU 分解的時間,三角回帶的時間基本可以忽略[17],所以我們的優化也集中在LU 分解上.式(1)給出了LU 分解的符號表示,詳細的算法數學證明請參考文獻[1].在實現上,LU 分解以NB列為迭代步進行迭代求解,算法1 給出了LU 分解的詳細算法描述.每一輪迭代包含4 個子過程,分別是panel 分解、panel 廣播、行交換和尾矩陣更新.其中panel 分解(panel_factorization)通過遞歸高斯消元求解得到L11,U11和L21;panel 廣播(panel_bcast)將L11和L21廣播給同行的行進程;行交換(row_swap)根據panel 廣播收到的行交換信息做行交換;尾矩陣更新(update)首先執行雙精度三角矩陣求逆(DTRSM)得到U12,然后通過將L21和U12做雙精度矩陣乘(DGEMM)更新A22矩陣.

2.2 HPL性能模型.
在已有的CPU HPL 建模分析的基礎上[14,16?19],我們提出了適應于處理器-加速器異構架構的HPL 性能模型.在具體介紹我們的HPL 性能模型之前,我們先給出一些符號及其含義,大部分符號采取與文獻[17]中一致的名稱.矩陣A是N×(N+1)的系數矩陣,以NB×NB的塊大小均勻分布在P×Q的二維進程網格中,mp×nq表示每個進程處理的子矩陣的大小.ffact表示panel 分解中浮點操作的比例,Pcpu和Ecpu分別表示國產處理器雙精度浮點峰值性能和浮點操作的效率,Pacc表示國產加速器雙精度浮點峰值性能,Edgemm和Edtrsm分別表示國產加速器上DGEMM 和DTRSM 的效率,網絡延遲為Lats,帶寬為BWbyte/s.對于panel 分解子過程,我們通過估計子過程中矩陣乘的計算量乘以一個系數來估計整體的浮點計算量,式(2)給出了這一子過程的時間估計.其中需要特別指出的是,我們將panel分解中大矩陣放到國產加速器上進行計算,這在式(2)的分母中體現了出來.

對于panel 廣播算法的選擇,我們實現中采用的是HPL 軟件包中復雜度較低的Long算法.它的復雜度為log級別,體現在式(3)前半部分的系數.每次廣播,我們需要傳輸大小為NB×NB的L11和mp×NB的L12以及少量索引,這些數據均為雙精度類型(8 字節),公式的后半部分給出了每一跳(從一個節點傳往下一個節點)的時間估計.式(3)給出了對這一過程的時間估計.
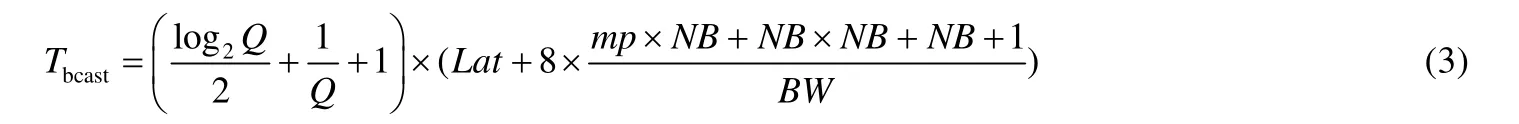
行交換時間的估計方式與panel 廣播的估計方式類似,區別在于采取的算法和傳輸的數據量不同.出于避免冗余數據傳輸的目的,行交換采用的是spread-roll算法[11],式(4)給出了這一子過程的時間估計.
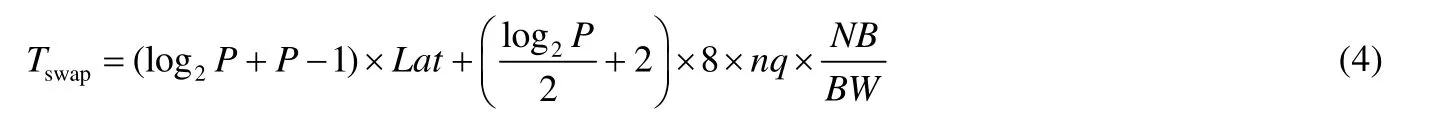
尾矩陣更新的過程主要是在國產加速器上執行兩個BLAS庫函數DGEMM 和DTRSM,其計算量分別是2×mp×nq×NB和nq×NB×NB.式(5)給出了尾矩陣更新的時間估計.
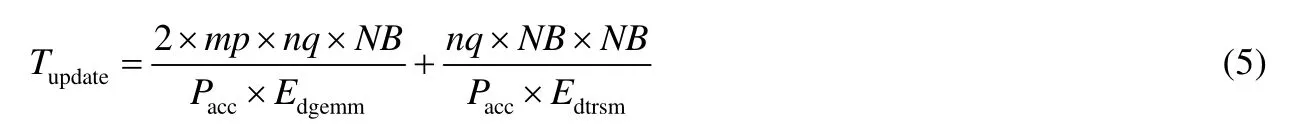
性能模型中參數的值,我們分為兩類.一類是可以預知的,比如問題的規模,分塊的大小以及硬件的峰值浮點性能等等,對于這一類參數,我們根據系統硬件以及求解問題的實際規模設定好對應的值;另一類是不可以預知的,比如雙精度矩陣乘的效率可能和矩陣的規模相關,網絡的實際帶寬和延遲可能受發送的數據量的影響等等,對于這一類參數,我們通過小規模實際測試給出其實測值.
我們用TOP500 榜單中排名靠前的與國產處理器-國產加速器類似的異構系統,如Summit[20]、Serria[21]、ABCI[22]以及曙光E 級超算原型機對上述HPL 性能預測模型進行了檢驗,結果見表1[17].在大規模系統HPL 性能預測的準確性上,最大誤差值不到5%.可以看到,我們建立的國產處理器-國產加速器異構HPL 性能模型較為準確,可以給將來E 級機的建造提供參考.
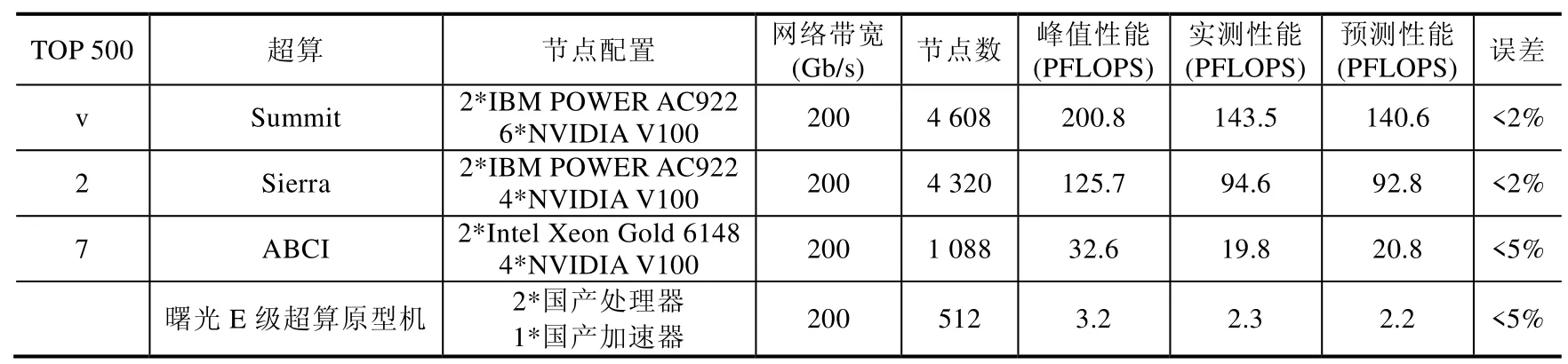
Table 1 TOP500 supercomputer performance prediction表1 TOP500 超級計算機性能預測
3 多線程細粒度HPL算法設計及實現
在已有的文獻中,LU 分解的4 個子過程,panel 分解,panel 廣播,行交換和尾矩陣的更新都是順序執行的.在過去純CPU 時代,由于尾矩陣更新占據了90%以上的時間,HPL 的效率主要由DGEMM 的效率決定,其他3 個子過程對性能的影響不大.此時這種順序執行4 個步驟,或者通過簡單的look-ahead算法[5]實現粗粒度流水的算法也能取得很好的效果.但是對于國產處理器-國產加速器異構架構,由于國產加速器計算能力與國產處理器的計算能力存在1~2 個數量級的差距,尾矩陣更新的時間占比減少到了50%左右,此時panel 分解,panel 廣播和行交換對性能的影響就不能忽略.在這樣的背景下,探索一個新的細粒度流水算法用update 的有用計算去掩蓋panel 分解、panel 廣播和行交換的開銷對于提升HPL 的效率,充分發揮國產加速器的強大計算能力顯得尤為重要.
3.1 多線程細粒度HPL算法的設計
HPL 耗時最多的計算是尾矩陣A22更新的矩陣乘法計算,異構HPL算法加速的核心是利用國產加速器加速矩陣乘法.傳統的CPU-加速器異構HPL算法通過把panel 分解的結果L11,U12,L21矩陣拷貝到加速器內存,同時將更新前的尾矩陣A22拷貝到加速器內存,利用加速器求解U12和更新尾矩陣,將更新后的尾矩陣~A22拷貝回CPU 內存[17].這種做法將系數矩陣放在CPU端內存中,每次調用加速器的DGEMM 都需要把數據通過PCIe 拷貝到加速器內存,在完成計算后又需要把結果矩陣拷貝回CPU 內存.在文獻[6]中通過三階段流水的辦法用加速器上的計算來掩蓋PCIe 數據傳輸的開銷,但是加速器算力增加的速度遠遠高于PCIe 帶寬的增加速度,它們之間越來越大的差距使得加速器計算的時間無法掩蓋PCIe 傳輸的時間.為了解決這個問題,我們將系數矩陣放在國產加速器的內存上,這樣就避免了國產處理器和國產加速器之間大量的數據交換.只需要在國產處理器做panel 分解之前,從國產加速器把panel 需要的NB列數據拷貝回來就可以了.假設當前迭代中剩余待求解系數矩陣大小為n× (n+1),原來粗粒度并行的算法中,我們需要通過PCIe 移動字節的數據,現在只需要移動字節數據,通過PCIe 的數據傳輸量大大減少了.這個版本的HPL算法我們稱為粗粒度HPL算法.
粗粒度HPL算法存在兩個問題導致其不能取得很高的性能.一個問題是由于尾矩陣更新時間占比減少,行交換的網絡傳輸的開銷顯得越來越大.另一個問題是通過簡單使用國產加速器的異步流機制讓國產處理器端的panel 分解和國產加速器端的update 并行,國產處理器與國產加速器只有很弱的并行工作的效果,大部分時間國產處理器與國產加速器都是串行執行,這造成了國產加速器大量的空閑等待時間.為了解決這兩個問題,我們設計了一種國產處理器-國產加速器異構多線程細粒度流水算法.我們通過對數據依賴的分析發現尾矩陣更新與行交換在列與列之間是沒有數據依賴的.受此啟發,我們在列方向上對尾矩陣進行分塊,如圖2 所示,將完整的尾矩陣行交換和更新劃分成一個個由若干NB列塊組成的單元進行行交換和更新.行交換主要利用PCIe 和網絡,對國產加速器的計算資源占用率不高,這樣就用尾矩陣更新的計算掩蓋了行交換的開銷[17].在上面細粒度任務劃分的基礎上,我們引入了多線程多流機制來協調國產處理器與國產加速器的計算.具體來說,我們引入了4個線程,如圖3 所示,thread 0 負責panel 分解和panel 廣播,thread 1 負責PCIe 的數據傳輸,thread 2 負責行交換,thread 3 負責尾矩陣更新.thread 1 和thread 2 兩個線程運行在同一個國產處理器物理核心上,thread 0 和thread 3 分別運行在其他兩個國產處理器物理核心上.除線程0 外,每個線程管理各自的異步流.通過利用線程間同步和流之間的同步來協調國產處理器與國產加速器的計算,最終實現了如圖3 所示的流水線.

Fig.2 HPL fine-grained parallel data splitting (K is a multiple of NB)圖2 HPL 細粒度并行數據劃分(K 是NB 的倍數)
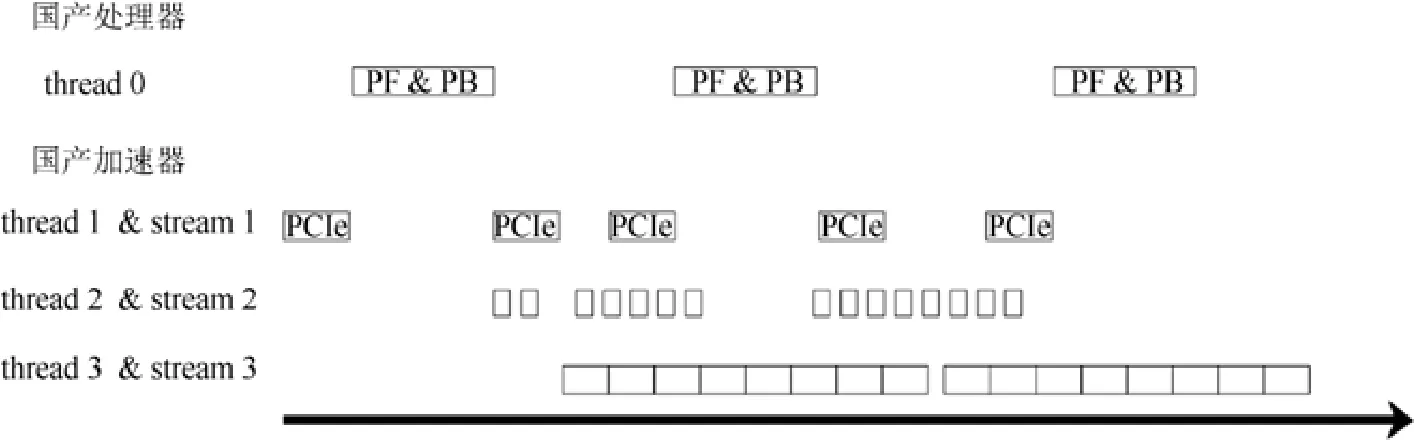
Fig.3 HPL multithread fine-grained parallel algorithm flow圖3 HPL 多線程細粒度并行算法流程圖
3.2 多線程細粒度HPL算法的實現
我們通過引入簡單的生產者消費者模式來維護細粒度算法的依賴關系,以降低多線程帶來的開銷,實現與文獻[17]中做法一致.如圖4 所示,行交換生產者做完一個列塊的行交換之后,生成一個更新任務放到更新任務隊列里邊;負責尾矩陣更新的線程作為消費者,取出更新隊列里面的任務并執行,同時尾矩陣更新線程還是傳輸任務的生產者,在執行完一個更新任務后,生成一個傳輸任務放到傳輸任務隊列里邊;負責傳輸的線程從傳輸隊列里取任務完成傳輸;負責panel分解的進程在等待自己需要的列塊數據更新完成之后就可以并行開始做下一輪的panel分解[17].各個線程間利用信號量實現等待和喚醒,當任務隊列為空的時候,相應線程就掛起,避免忙等待帶來的開銷.
異構系統的加速器有多種,比如GPU、MIC、FPGA、國產加速器等等.為了讓異構HPL算法具有可移植性,能夠運行在多種異構平臺上,我們完成了一個輕量級的異構加速框架HPCX[17].其實現與文獻[17]一致,如圖5 所示,我們抽象出了異構加速平臺的一些共有特性,比如內存管理,并行計算,數據傳輸,異步調用等等.同時我們對不同廠商的異構加速器編程模型和基礎數學庫進行總結,定義了一套統一的編程結構.在不同的加速器上,使用不同的編程模型(HIP、CUDA、C)實現,底層用不同的編譯器編譯成不同平臺上的二進制程序.目前HPCX 支持國產加速器、AMD GPU 和NVIDIA GPU 以及國產處理器、Intel CPU 和AMD CPU.對于其他異構加速器,結合硬件平臺給出HPCX 定義抽象接口的具體實現就可以方便整理到HPCX 框架中.異構并行HPL算法通過調用HPCX 提供的編程接口實現跨平臺加速.
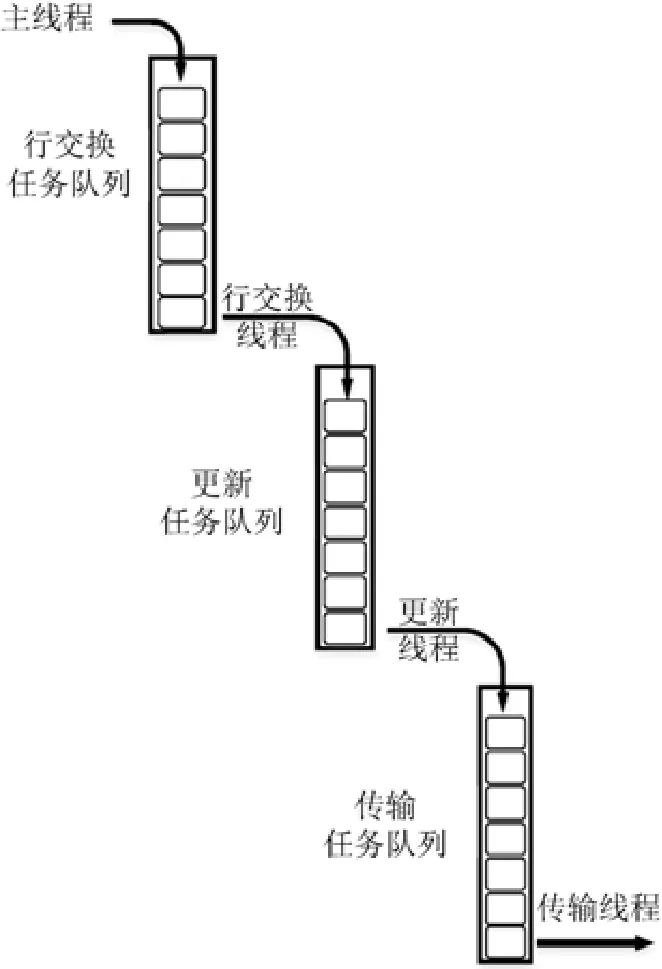
Fig.4 HPL producer-customer model圖4 HPL生產者消費者模型
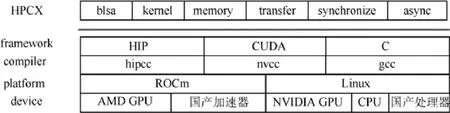
Fig.5 Heterogeneous acceleration framework HPCX圖5 異構加速框架HPCX
4 性能測試與分析
我們實現了包括國產加速器和NVIDIA GPU 兩種異構平臺上的粗粒度版本HPL 和多線程細粒度版本HPL,在國產加速器和NVIDIA 兩個平臺上進行了測試.在NVIDIA 平臺上,我們將我們實現的兩個版本的HPL與開源成果三階段流水線版本HPL 以及目前NVIDIA 平臺上效率最高的NVIDIA 官方非開源程序nvhpl 進行了對比.在國產加速器平臺上,我們在曙光E 級超算原型機的512 個節點上進行大規模擴展性測試.
4.1 實驗平臺簡介
表2 給出了我們實驗平臺的信息.在兩種平臺上,單個節點內處理器與加速器都通過PCIe 3.0 總線連接.NVIDIA 平臺上只有一個節點,配有兩張P100 顯卡.國產加速器平臺上有多個節點,每個節點上裝有一個國產加速器,節點之間采用100Gb/s 的EDR 網絡連接.

Table 2 Configuration of computing nodes表2 計算節點的配置
4.2 性能與分析
在NVIDIA 平臺上的單卡測試結果如圖6 所示.從圖6 中我們可以看到,隨著問題規模的變大,除了開源的3 階段流水線版本HPL 的性能沒有太大提高外,nvhpl 與我們實現的兩個版本HPL 均有明顯性能提升.出現這種情況是因為3 階段流水線版本的HPL 的矩陣位于CPU 上,而三階段流水線無法用加速器的計算掩蓋PCIe數據傳輸的開銷.我們可以看到,通過簡單地把矩陣放到加速器內存上,粗粒度HPL 就獲得了很大的性能提升,說明將矩陣置于加速器內存上是合理的.但是粗粒度HPL算法與nvhpl 相比還是有較大差距,原因是粗粒度HPL算法對加速器與處理器的并行度挖掘不夠,以及忽略了行交換中網絡通信開銷的優化.多線程細粒度HPL算法在做完上述優化之后,性能完全超越了nvhpl 的性能,平均領先nvhpl 達9%.圖7 展示了NVIDIA 平臺上多卡的測試結果.由于三階段流水線版本HPL 速度太慢,我們略去了它的多卡測試.從圖7 中我們可以發現,粗粒度HPL、多線程細粒度HPL 與nvhpl 都有較好的擴展性.在多卡測試上,我們的細粒度版本HPL 依然領先nvhpl.
如圖8 所示,在曙光E 級原型機的512 個節點上,我們進行了1~512 個節點的擴展性測試.從圖8 中可以看出,在不同測試進程規模下,HPL 的擴展性很好,隨著節點的增加HPL 的測試效率緩慢下降,從2 個節點約75%的效率下降到512 個節點約71%的效率.需要注意圖中單節點效率偏低是因為單節點測試采用的NN 格式(非轉置非轉置)的矩陣乘,而多節點采用的NT 格式(非轉置轉置)的矩陣乘,前者的效率低于后者.我們實現的多線程細粒度版本HPL 最終在512 個節點上實現了HPL 實測峰值性能2.3 PFLOPS,實測效率71.1%優秀測試結果.
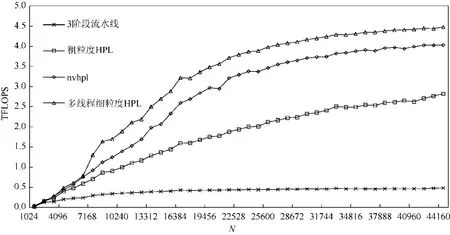
Fig.6 HPL performance on single NVIDIA GPU圖6 NVIDIA GPU 單卡HPL 性能
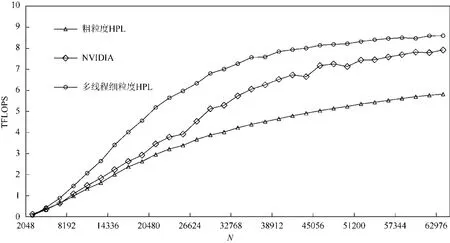
Fig.7 HPL performance on multiple NVIDIA GPUs圖7 NVIDIA GPU 多卡HPL 性能
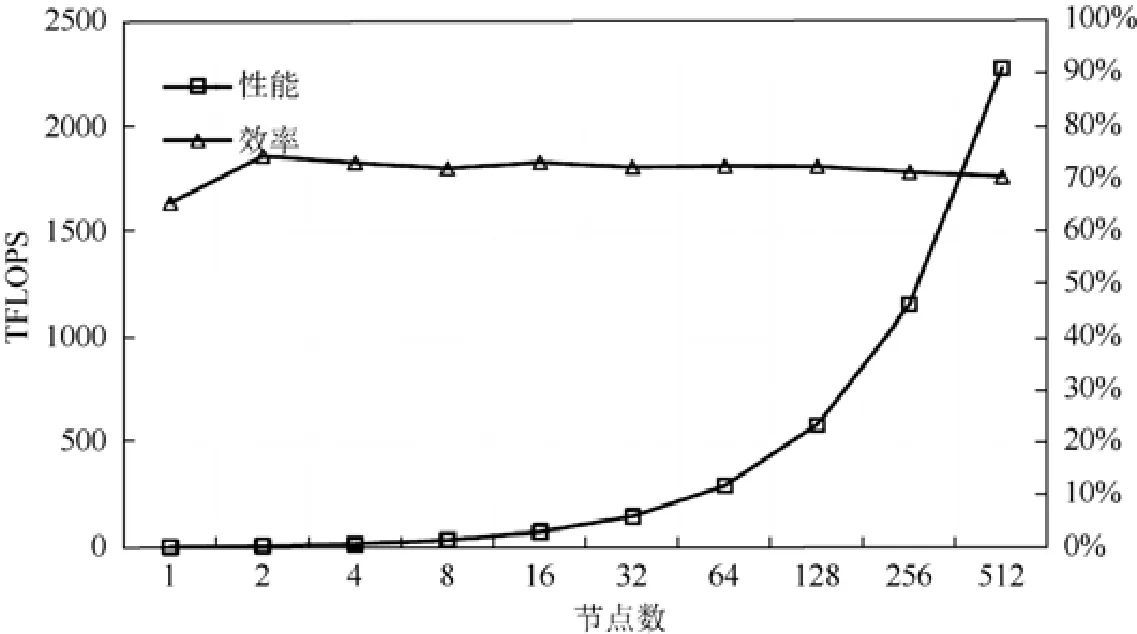
Fig.8 Sugon E-prototype supercomputer HPL performance圖8 曙光E 級超算原型機HPL 性能
5 結 論
本文提出的異構HPL算法通過將矩陣存儲于國產加速器的內存解決了數據傳輸瓶頸,通過多線程細粒度的算法軟流水實現了對通信開銷的掩蓋,通過一個輕量級異構加速框架HPCX 提供的對國產加速器的基本操作的抽象實現了跨平臺的異構HPL算法.在同類異構系統上,我們實現的算法性能遠遠超過開源的工作,并且優于NVIDIA 公司的非開源HPL 程序.我們的算法也展示了良好的擴展性,在曙光E 級超算原型機512 個節點HPL 測試中實現了71.1%的效率.同時,我們的性能模型也展示了較高的準確性,可以為未來E 級異構超算的HPL 性能預測提供參考.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
