異構HPL算法中CPU端高性能BLAS庫優化?
2021-11-09 02:45:12孫成國杜朝暉劉子行康夢博李雙雙
軟件學報 2021年8期
蔡 雨,孫成國,杜朝暉,劉子行,康夢博,李雙雙
(信息技術有限公司,江蘇 蘇州 215000)
BLAS(basic linear algebra subprograms)是基本線性代數子程序的縮寫,是目前應用廣泛的核心線性代數數學庫.隨著不斷的發展完善,BLAS 在高性能計算、科學和工程領域都得到了廣泛的應用.由于不同廠商、不同體系結構下的CPU 差異較大,通用BLAS 函數庫不能達到很好的性能.因此,在大規模矩陣運算時,針對不同CPU 的架構特點來優化BLAS,可以充分發揮處理器的計算性能,從而使計算效率大大提升.目前主流的BLAS分為專用和通用兩種.專用型BLAS 是由特定的CPU 公司開發,針對特定平臺芯片進行代碼優化,極大地提高了性能,Intel 的MKL 和AMD 的ACML 就是此種類型.通用BLAS 由非盈利機構開發,不同平臺都可以對開源代碼進行優化,最具代表性的是ATLAS[1]、GotoBLAS[2,3]和OpenBLAS[4,5].
BLIS(BLAS-like library instantiation software)數學庫是美國Texas 大學超算中心高性能組開發的開源架構,是在GotoBLAS 的基礎上進行了改寫和優化,具有可移植性、易用性和模塊化設計易于開發的特點,支持混合類型矩陣存儲和多線程[6].文獻[7]提出了BLIS 架構,并做了全面的介紹;文獻[8]研究了如何使用BLIS 在通用、低功耗和多核架構中實現高效的level-3 級BLAS 函數;文獻[9]系統地探討了矩陣乘法算法在BLIS 五層循環中并行化的機會.BLIS 具有的這些特性使其更容易針對具體平臺進行BLAS 優化開發.BLAS 包含三級函數,分別為第1 級向量與向量計算,第2 級向量與矩陣計算,第3 級矩陣與矩陣的計算,其中第3 級函數DGEMM 計算量最大,可以達到理論計算量的95%以上[10],因此三級函數的優化是性能提升的關鍵.
高性能計算系統可以分為同構或異構兩類,同構系統是由大量CPU 構建,計算和數據處理都在CPU 上進行;異構系統是CPU 和加速部件組成,加速部件一般由Cell(cell broadband engine architecture)、FPGA(Field programmable gate array)和GPU(graphic processing unit)等為代表,集成大量的浮點計算單元的同時舍棄了一些CPU 上復雜的控制單元.異構系統中CPU 負責任務調度和簡單計算,主要計算在加速部件上進行,計算能力更強.國際上對高性能系統的評測標準程序是HPL(high performance Linpack),由美國田納西大學教授Dongarra 設計提出[11],是在高性能計算系統中使用高斯消元法求解一個隨機的N 元一次線性方程組問題,用以評價高性能計算機的浮點性能.
異構HPL 浮點計算在CPU端是通過BLAS 函數完成的,BLAS庫的性能會影響整體系統性能.本文異構系統計算單元由CPU+協處理器(co-processor)組成(如圖1 所示).CPU 計算核心之間和協處理器通過高速互聯進行數據交換和通信.協處理器的計算能力一般都比通用CPU 強大很多,往往造成計算負載嚴重不均衡,損失性能.因此在CPU端利用更高效的數學庫,能夠充分地發揮CPU 性能,使負載更均衡,是提高計算能力的可行方式之一.文獻[12?15]分別針對ARM 架構處理器以及異構平臺的GEMM 優化做了深入研究.文獻[16,17]研究了在申威眾核處理器上,1 級、2 級和3 級BLAS 的優化方法,文獻[18]對異構多核平臺上的數學庫寄存器分配優化方法進行了研究.
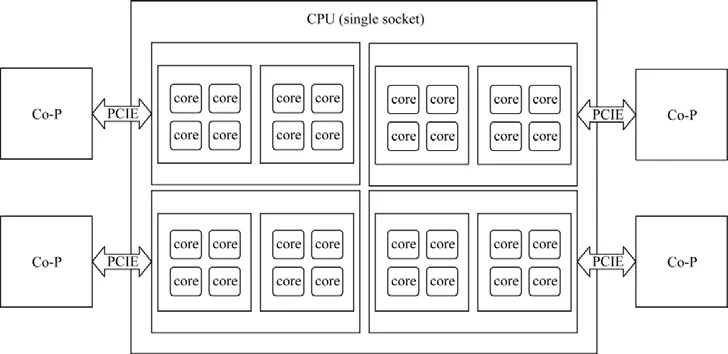
Fig.1 Heterogeneous computing node architecture圖1 異構計算節點架構
本文在BLIS算法庫基礎上,分析異構HPL算法中調用的各級BLAS 函數,針對體系結構特點,利用訪存優化、指令集優化和多線程并行等技術手段形成了優化的HBLIS庫,提高了異構系統中CPU端的計算效率,后文詳細分析了優化策略和方法.本文第1 節首先對異構HPL 的BLIS庫進行分析,特別是異構環境的HPL 特點以及各個數學庫函數調用關系.第2 節~第4 節對高性能BLIS庫的優化策略做詳細的分析和介紹,優化HPL 中涉及的各級BLAS 函數,實現高性能的HBLIS算法庫.第5 節在異構平臺上做詳細的性能測試與分析,通過性能對比,驗證優化的HBLIS庫性能有大幅度的提高.第6 節對全文進行總結和展望.
1 算法分析和CPU 微體系結構
1.1 HPL算法與BLAS函數
HPL算法核心計算公式如式(1)所示,其求解過程實際是對系數矩陣[A,b]使用高斯消元法進行LU 分解,變成[A,b]=[[L,U],Y],其中L是下三角矩陣,U為上三角矩陣,隨著因式分解的進行,方程等價于求解Ux=Y.LU 分解過程中每一次迭代計算都要經過panel 分解、panel 廣播、行交換和尾矩陣更新.HPL 程序在進程通信和矩陣計算上需要MPI[19]庫和BLAS 或VSIPL[20]庫的支持,除基本算法不可以改變外,可以通過配置文件調節問題規模N(矩陣大小)、進程數等測試參數,以及使用各種優化方法來執行HPL 程序,以獲取最佳的性能.當求解問題規模為N時,浮點運算次數為2/3×N3–2×N2.因此,給出問題規模N,測得系統計算時間T,計算系統的浮點計算能力=計算量(2/3×N3–2×N2)/計算時間(T),測試結果以每秒浮點運算次數(FLOPS)為單位.

HPL算法過程分為LU 分解和回代過程.異構HPL 環境下,LU 分解過程中大量計算要在CPU 和協處理器之間進行任務分配,CPU 負責調度和適當的輔助計算,而主要計算要在加速部件上進行.當問題規模N非常大時,HPL 的最大計算量是更新尾矩陣的計算,包括雙精度的三角矩陣求解和稠密矩陣乘 DGEMM,因此將DGEMM 放在協處理器上計算,CPU 負責計算量不大的panel 分解、panel 廣播和行交換.異構高性能計算系統優化的難點主要是在主從芯片對計算任務的劃分和通信開銷這兩個方面,一些學者從任務靜態劃分和動態劃分實現負載均衡[12,21?23],還有學者在數據重用、存儲優化、軟件流水和應用雙緩沖等方面深入研究[24?26],達到實現更高效的通信隱藏的目的.異構HPL 主程序算法中任務分配調用加速部件專用編程接口進行計算,CPU端則調用BLAS庫進行選主元、panel 分解計算.
本文針對的異構HPL算法由中國科學院軟件研究所開發[27],其LU 分解過程會將panel 的一部分矩陣(N×NBMIN)分解為單位下三角L1、上三角U和L2,這3 個部分的運算在CPU 上進行,主要涉及一級BLAS 函數中的DCOPY、IDMAX、DSCAL;二級BLAS 函數中的DTRSM、DTRSV、DGEMV;三級BLAS 函數中的DGEMM.各個BLAS 函數作用如下:
(1) DCOPY 執行數據拷貝操作,將一個向量拷貝到另一個向量.
(2) IDMAX 用于選主元操作,在一列元素中選擇最大的元素.
(3) DSCAL 用于向量更新,用一個標量乘以一個向量.
(4) DTRSM 用于三角矩陣求解操作.
(5) DTRSV 用于求解三角方程操作.
(6) DGEMV 用于計算向量矩陣乘法.
(7) DGEMM 用于每個進程上剩余矩陣數據更新.
同時,panel 分解的遞歸部分也會調用三級BLAS 函數DGEMM 加速panel 分解過程.因此DGEMM 的效率極大地影響了panel 分解的效率.在異構HPL算法中,參數NBMIN表示遞歸分解算法可以分解到的最小方陣大小,隨著它的增大,一級BLAS 在整體過程中的操作次數與規模不變,二級BLAS 操作次數保持不變,而運算規模將增加,導致panel 分解非遞歸部分的整體時間延長.當NBMIN減小時,HPL_pdpanllN[28]函數的耗時將減少,但是也會增加外層非遞歸部分對三級BLAS 的調用次數.因此需要通過權衡三級與二級BLAS 的調用次數與效率來調整NBMIN的大小,獲得更好的性能.另一方面,通過DGEMV 的優化可以增大NBMIN來減少三級BLAS 的調用次數.針對這些函數,本文應用多種優化策略對BLIS庫中的各級BLAS 函數進行了優化,獲得了性能的大幅度提升,提高了異構HPL 的效率,更好地發揮了異構系統的性能.
1.2 異構單元處理器概述
異構計算單元CPU 是64 位X86 架構的通用服務器芯片,采用14nm 工藝制造.從圖1 中可以簡單地了解CPU 架構,共32 個計算核心.其基本的微體系結構如下:
(1) 支持所有標準X86 指令集,如AVX、AVX2、SMEP、SSE 和SSE2 等.
(2) 每4 個核心組成一組,每個核心獨享L1 和L2 級緩存,共享L3 級緩存,支持SMT 技術,每個物理核心支持同步2 線程.
(3) 三級緩存結構如圖2 所示,L1 cache 由64K 指令緩存和32K 數據緩存組成,其中L2 cache 大小為512K,共享L3 cache 大小為8M.所有Cache line 大小為64 字節.
(4) X86 處理器有三級指令TLB 和兩級數據TLB.訪存頁面大小為4KB,映射的物理地址空間最大可以達到1GB.
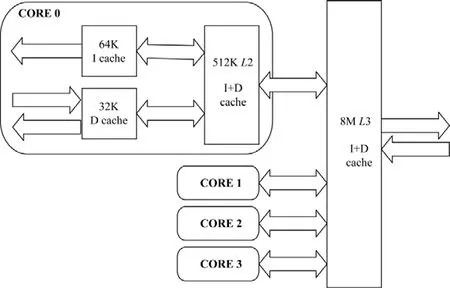
Fig.2 CPU cache hierarchy圖2 CPU 緩存層次結構
2 訪存優化
HPL算法中DGEMM 運算占據了BLAS 運算中最大的計算量和訪存耗時.優化的HBLIS 通過實現互補的兩類GEMM kernels 優化了DGEMM 性能,即大kernel 和小kernel.大kernel 用于處理矩陣A和B的規模都相對較大的情況,而小kernel 用于處理矩陣A更加“高窄”和矩陣B規模較小的情況.在DGEMM 函數接口內根據矩陣規模切換兩類kernel.同時引入Auto-tuning 自適應調優技術對矩陣分塊參數進行優化,優化后的分塊參數可以更充分地利用CPU 緩存,提高cache 命中率,從而提高DGEMM 訪存性能.
2.1 矩陣分塊
GEMM 大kernel 采用經典高效的GEMM 分塊算法[8],如圖3 左側的6 層循環偽代碼所示;GEMM 小kernel的算法如圖3 右側的偽代碼所示.

Fig.3 High performance GEMM algorithm of big and little kernels圖3 高性能GEMM 的大kernel算法和小kernel算法
大kernel算法描述如下:
? 最外層Loop1 遍歷n維度(以jc索引),以寬度nc為單位,對矩陣C和矩陣B進行分塊,形成列向panels.
? 第2 層Loop2 遍歷k維度(以pc索引),以高度kc為單位,將矩陣A劃分成列向panels,同時將Loop1 中劃分出的矩陣B的列向panel 進一步劃分成block;Loop2 中,還會將Bblock(B(pc:pc+kc–1,jc+nc–1)表示)進行打包(packing).關于大kernel 中的packing 操作見第2.2 節.
? 第3 層Loop3 遍歷m維度(以ic索引),以高度mc為單位,將Loop1 中劃分出的矩陣C的列向panel 進一步劃分出block,以Cc表示(未進行packing 操作),將Loop2 中劃分出的矩陣A的列向panel 也進一步劃分成block.同樣地,Loop3 中,還會將Ablock 進行打包,以Ac表示打包后的矩陣塊.
? 第4 層Loop4 再次遍歷n維度(以jr索引),以寬度nr為單位,將packed blockBc和blockCc再次進一步劃分成micro-panels.
? 第5 層Loop5 再次遍歷m維度(以ir索引),以高度mr為單位,將packed blockAc劃分成micro-panels,將Loop4 中Cc中的micro-panel 進一步劃分成micro-tiles.
? 最內層Loop6 再次遍歷k維度(以pr索引),以1 為單位,計算Ac中的micro-panel 與Bc中的micro-panel的點積(dot product),并將結果累加到Cc中的micro-panel,即所謂的“rank-1 update”.
小kernel算法描述如下:
? 前兩次loops 的作用在于將小矩陣B進行打包,其目的是便于inner-loops 中最內層kernel 對B矩陣的連續、對齊訪問,關于小kernel 中的packingB操作見第2.2 節.
? inner-loops 中的3 層循環類似于大kernel 中的實現,只是此時循環操作的上限不再是大kernel 中分塊后的nc、mc和kc,而直接是整個矩陣的大小.
與大kernel算法相比,小kernel算法有如下優點:
(1) 省去了對矩陣A的packing 操作.
異構HPL 中的矩陣A往往是“高窄陣”,其規模比矩陣B大非常多,對矩陣A進行打包操作的耗時占整個GEMM 操作的比例非常高.
(2) 極大地避免了大kernel 中out-loops 的循環次數.
大kernel算法與小kernel算法間的動態切換,主要依據輸入矩陣的規模,即計算量的大小.但并不存在完美的切換閾值(threshold),因為3 個矩陣A、B和C的行、列維度千變萬化,某一個特定的切換閾值無法做到全面適用于所有的使用場景,需要在具體的應用中實際測試來找到比較合適的閾值設置.根據本文系統平臺實測,切換進入小kernel 的閾值條件滿足下面兩者之一即可:
(1)C矩陣的面積,即M×N≤700×700 時.
(2) 維數M≤160 同時維數K≤128 時.
2.2 Auto-tuning自適應分塊參數調優
DGEMM 計算量大,計算訪存比高,除上述kernel算法層面的優化外,對BLIS 框架內矩陣分塊參數進行優化還可以提高cache 命中率,提高性能.矩陣乘法循環分塊的大小是通過BLIS庫中DGEMM 的分塊參數來決定的,分塊參數的選擇可以影響cache 命中率,不合適的參數可能導致流水線停頓,從而使DGEMM 性能下降.因此,DGEMM 分塊參數的選擇至關重要.BLIS 中DGEMM 分塊是通過開發人員的經驗和測試選擇的一組數值,手動測試不能保證測試覆蓋率,也不能保證得到的是最優解.因此本文采用了Auto-tuning 遺傳算法自適應調優技術,更高效地優化DGEMM 分塊參數.
遺傳算法基本算法思想是從可能具有潛在解集的一個種群開始的,種群是基因編碼后形成的一組個體集合,在這個種群基礎上通過選擇(selection)、交叉(crossover)和變異(mutation)操作,優勝劣汰,不斷地進化出最優的個體.Auto-tuning 自適應調優就是應用遺傳算法對DGEMM 分塊參數進行智能優化選擇,將分塊參數作為個體,一定范圍內的多個個體形成一個種群進行自適應迭代進化,從而針對具體平臺體系結構產生最優的DGEMM 矩陣分塊參數.文獻[29]在Intel 平臺上對遺傳算法在DGEMM 的分塊參數智能優化選擇上的實現做了詳細介紹.如圖4 所示是遺傳算法的基本流程.
? 首先初始化種群,以分塊參數[mc,kc,nc]為一個個體,隨機生成一組個體的集合.
? 然后計算種群每個個體的適應度,適應度大小決定遺傳概率.
? 接著判斷迭代次數,如果沒有達到預設的最大值,則進行selection、crossover 和mutation 的遺傳算法進化步驟.
? 最后,經過selection、crossover 和mutation 這3 個步驟后生成一個新的種群,與原始種群大小一致,但個體都經過優勝劣汰,進化到了更好的水平.重復上述步驟,直到滿足終止條件退出.
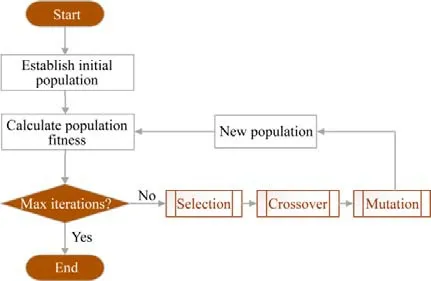
Fig.4 Generic algorithm flow chart圖4 遺傳算法流程圖
根據上述遺傳算法的介紹,自適應程序的實現需要經過編碼個體、建立種群、計算適應度、選擇(selection)、交叉(crossover)、變異(mutation)和終止條件判斷這幾個步驟.
(1) 個體編碼
編碼方法有二進制編碼、格雷編碼、浮點數編碼和符號編碼等多種方式,根據DGEMM 分塊參數特點,采取浮點數編碼更適合.也就是將分塊參數[mc,kc,nc]這3 個浮點數直接作為參數傳入.
(2) 建立種群(population)
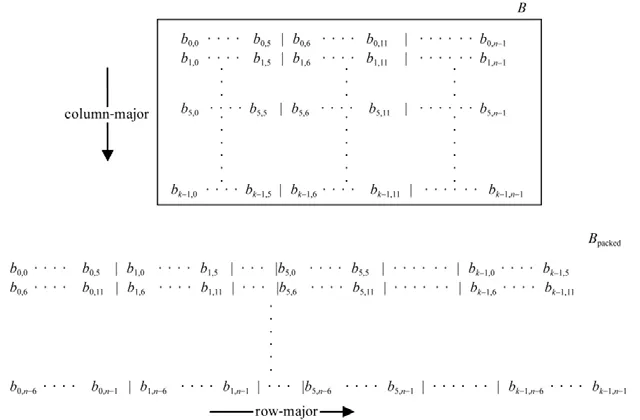
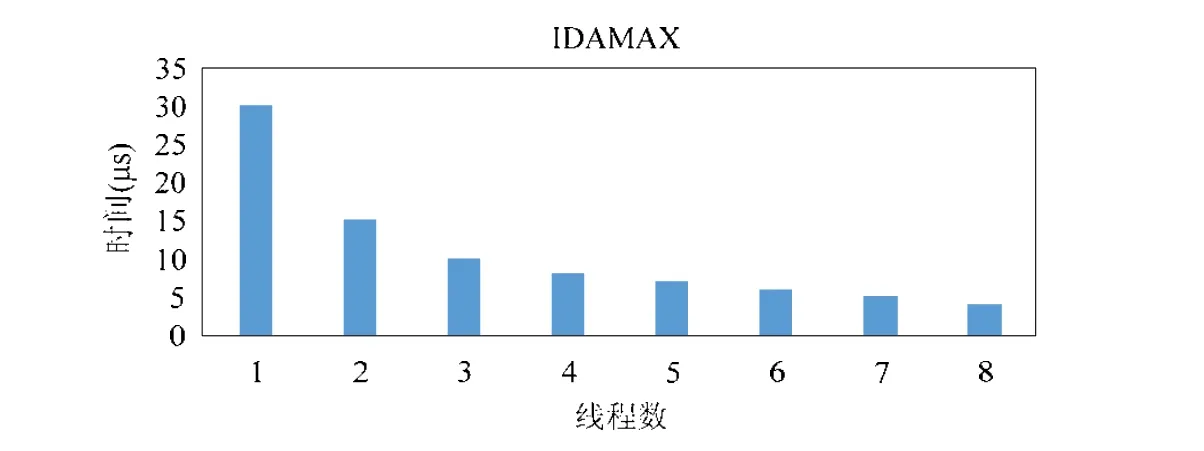
個體集合的建立過程就是要在一個確定范圍內去隨機生成一定數量的個體.種群范圍的確定可以根據cache 的大小進行理論計算得出[7],HBLIS 分塊參數原始值是[1080,120,8600],在原始參數值的基礎上擴大范圍至[512 (3) 計算適應度(fitness) 適應度函數就是DGEMM 測試程序,其性能作為判斷適應度高低的標準.性能高的分塊參數會遺傳給下一代種群,性能低的分塊參數就會被淘汰. (4) 選擇(selection) 基本遺傳算法僅僅使用selection、crossover 和mutation 這3 種算子是沒有辦法收斂于全局最優解的,因為簡單地進行雜交,可能反而會把較好的組合破壞掉.本文采用精英保留策略,也就是把目前最優個體不進行任何操作直接復制到下一代種群中.選擇方法有很多種,包括比例選擇法、排序選擇等.本文采用比例選擇法和精英保留策略結合,種群中每一個個體的適應度占總適應度的比例越大,其被選擇的概率就越大,同時這一代種群最優秀個體無條件復制到下一代. (5) 交叉(crossover) 單點交叉、雙點交叉、均勻交叉等都適合二進制編碼和浮點數編碼,根據GEMM 分塊參數只有3 個,選擇單點交叉,按某一概率將兩個個體的某一位置參數互換.交叉率設置越大,新個體產生越快,其全局搜索能力就會越強,但是優秀個體被破壞的可能性也就越高,綜合考慮,設置交叉概率為0.8. (6) 變異(mutation) 變異的主要目的是改善局部搜索能力以及維持種群個體的多樣性,變異方法采用均勻變異,按某一概率在一個范圍內隨機生成一個數替換原來個體中某一位置的參數.變異概率不宜設置過大,導致丟失優秀個體而變成隨機搜索.考慮設置參數范圍已經在合理范圍內,本文按0.1 的概率對每一個個體的某一參數進行變異. (7) 終止條件判斷(iteration) 種群中所有的個體適應度計算完成后要判斷設置的終止條件是否滿足,以判斷程序是否結束退出.如果不滿足終止條件就進行selection、crossover 和mutation 操作,形成下一個同等規模的個體集合(種群). Auto-tuning 自適應調優算法完成后,需要進行DGEMM 測試,BLIS庫中config 目錄是存放不同平臺kernel的配置信息,其中DGEMM 分塊參數通過bli_kernel.h 頭文件中的BLIS_DEFAULT_MC_D、BLIS_DEFAULT_KC_D 和BLIS_DEFAULT_NC_D 這3 個宏定義配置. Auto-tuning 的具體測試流程如下: (1) 在包含初始分塊的更大的范圍內隨機生成一組滿足遺傳算法個體要求的分塊參數[mc,kc,nc],并用其替換掉blis_kernel.h 中的分塊參數. (2) 自動編譯BLIS庫,生成此分塊參數下的動態鏈接庫libblis.so. (3) 調用libblis.so 執行測試程序DGEMM,主程序將性能值記錄并返回. 通過Auto-tuning 的不斷迭代,根據算法模型,我們會得到一個全局最優解,這組參數就是性能更高的DGEMM分塊參數,實測數據分塊參數由[1080,120,8400]優化為[792,822,8628],將這組參數替換進BLIS中,并使用高性能計算標準測試程序HPL 和單獨的DGEMM 測試程序進行測試,具體測試對比數據參考第5 節性能分析. 連續的內存訪問比非連續的內存訪問要快.異構HPL 中傳給DGEMM 的矩陣A、B和C的索引是初始化矩陣的某個位置指針,矩陣元素通過leading-dimension 索引,leading-dimension 表示列優先存儲方式的矩陣同一行(或行優先存儲方式的矩陣同一列)中兩相鄰元素的距離,也就是實際存儲矩陣的二維數組的第1 維(或第2維)的大小.矩陣A、B和C的行或列間跨度通過LDA、LDB和LDC表示,這3 個數值可能會非常大.比如異構HPL 求解問題Ax=b,其矩陣規模N的最大取值可以使矩陣A的存儲空間占用內存80%左右,則LDA不能小于N.在算法實現中,大kernel算法會不斷地對A和B的不同分塊進行打包,形成Ac和Bc;而小kernel算法只將原始矩陣B進行一次打包,形成行優先存儲(row-major)的Bpacked.如圖5 所示,其中假設nr等于6,矩陣B是以列優先存儲(column-major)方式存儲數據,且行數k和列數n都是nr的整數倍. Fig.5 Packing matrix B in little GEMM kernel圖5 GEMM 小kernel 中矩陣B 的打包操作 Packing 數據打包操作的優點有3 個. (1) 創造連續的內存訪問方式. BLAS 接口傳入的矩陣存儲方式是不確定的,可能是row-major,也可能是column-major,且矩陣的行或列間的跨度會非常大,最內層的kernel 為了適應不同的數據存儲方式以及不連續的數據分布,需要通過packing 制造統一的、連續的內存布局視圖. (2) 數據對齊. 對于大多數CPU 微架構實現而言,對齊到寄存器寬度,cache 邊界和頁邊界的數據訪問往往比非對齊的數據訪問方式更快. (3) 提前load 數據到cache. 通過packing 操作,最內層kernel 可以在盡可能接近CPU 寄存器的cache 上獲取到需要進行運算的操作數,這比直接從內存中獲取數據要快很多. X86 CPU 提供了硬件取功能和符合X86 ISA 的軟件預取指令.其中硬件預取對開發者是透明的,軟件預取指令PREFETCHn 指示處理器將后續需要訪問的數據提前讀入到指定的某級緩存中,當程序使用這些數據時,可以直接讀取緩存.PREFETCHn 指令格式見表1. Table 1 X86 software prefetch instructions表1 X86 軟件預取指令 軟件預取指令不要求數據行對齊,如果預取數據行已經存在于比指定的n更低的某層cache 中,那么指令將被當作NOP 空指令處理. 在最內層的核心匯編代碼中,PREFETCHn 指令的使用主要考慮兩點: (1) 何處插入PREFETCHn 指令. (2) 預取的地址跨度設置. X86 CPU 的cache line 大小為64B,一個緩存行可以存放8 個雙精度浮點數據.如圖6 所示的匯編代碼第1行的軟件預取操作,表示把Ac的第9 個雙精度數據開始的一個緩存行預取到L1 緩存中.此處的預取操作是為第22 行的load 指令準備數據.第5 行的load 操作會在L1 緩存發生cache miss,但是因為對A進行了packing 操作,理論上能夠在L2 cache 命中.同理,第9 行、第14 行和第18 行處的load 操作會在L1 中命中,第11 行預取操作將Ac的第17 個數據預取到內存. Fig.6 Code segment of inner-most DGEMM kernel圖6 DGEMM 核心匯編代碼片段 軟件預取指令的插入位置需要綜合考慮體系結構特點,合理安排匯編指令.X86 CPU 的L2 load-to-use 的latency 至少是12 個core cycles,而每時鐘周期只可以執行一條FMA 指令,在CPU 流水線能夠連續retire FMA指令的理想狀態下,預取指令和后續load 指令之間至少插入12 條FMA 指令. 高效BLAS kernel 的實現方法具有通用性,不同于其他數學庫大部分代碼通過匯編實現優化,BLIS 只在最內層的kernel 核心代碼處使用了匯編代碼,框架內的其他代碼使用C 實現.這給可移植性帶來了極大的便利,在適配不同架構的CPU 時,開發者可以將主要精力集中在最內層kernel 的匯編代碼的優化上. 不同架構的CPU 大多會提供高效的SIMD(single instruction multiple data)指令,X86 CPU 支持AVX2 指令集,可以使用128 位的XMM 寄存器和256 位的YMM 寄存器,但由于浮點運算部件的數據路徑寬度是128 位,每個時鐘周期最多可以同時處理2 個雙精度浮點數,單核理論雙精度浮點性能是(128/64)×2=4 DP-FLOPs/cycle,實際測試結果表明,使用XMM 寄存器的效率要優于YMM 寄存器.AVX2 指令集中主要有兩類指令:數據傳輸類指令和數據操作類指令.其中,VMOVDDUP、VMOVAPD、VMOVUPD、VMULPD 和VFMADD231PD 是在X86 架構CPU 平臺上高效BLAS kernels 的實現中使用頻率非常高的幾條指令. HPL算法中傳遞給BLAS 函數的參數會有固定值的情況,可以通過適當的指令替換來精簡指令,舉例如下. (1) 對于Level-3 級函數DGEMM 系數Alpha 固定為–1.0,Beta 固定為1.0.此時的DGEMM 計算公式由C:=α·AB+β·C變成了C:=C?AB可以在packingB(見第2.3 節)的過程中使用xorpd 指令進行符號位翻轉,精簡了對系數Alpha 的乘法操作.矩陣C不變,精簡了對系數Beta 的乘法操作.精簡指令后,原來需要4 個core cycle 的乘法操作和5 個core cycle 的乘加指令只需3 個core cycle 的加法指令即可完成.在矩陣規模較大,最內層kernel 被循環多次的情況下,指令時鐘周期的減少可以優化整體性能. (2) 對于Level-2 級函數DGEMV 轉置參數TransA 固定為NoTrans,可以省略對矩陣A進行轉置操作的代碼,提高CPU 流水線分支預測的準確率,避免分支預測失敗的懲罰.Alpha 固定為–1.0,Beta 固定為 1.0,則可以在內層 kernel 中使用一條VFNMADD231PD 指令取代VMULPD 和VFMADD231PD 兩條指令. (3) 對于Level-1 級函數DSCAL IncX 固定為1,可以省去對數據成員間隔較大時所需的軟件預取操作的指令(見第2.4 節). 異構HPL 傳遞給BLAS 接口的參數還有其他的固定值情況存在,這些固定值的存在可以起到精簡指令的作用,為BLAS庫提供了優化空間. 循環展開是編譯器常用的優化方式之一,可以減少分支預測失敗帶來的開銷,提高指令級的并行度.但高級語言通過編譯器循環展開后的匯編代碼在BLAS 這種訪存密集型的程序特征下,往往性能表現較差.因此BLAS的核心循環代碼通常采用手寫匯編的方式進行展開. 手寫BLAS 核心匯編代碼,不僅需要考慮底層CPU 架構層面的架構寄存器的數量和復用方式,而且需要考慮底層CPU 的微架構特點,比如浮點部件的寬度、存儲層級的大小和層級間的延遲等.這些CPU 特性共同決定了手寫匯編循環展開的程度,也就是“循環展開因子”.本文第2.1 節中提到的5 個參數nc、kc、mc、nr和mr,其中內核參數nr和mr與匯編代碼循環展開直接相關,而矩陣分塊參數nc,kc和mc則與CPU 存儲層級特性直接相關.針對具體平臺體系結構可以理論計算出這5 個參數的大致取值[30],但實際代碼測試中發現,理論數據往往并不是最優設置,X86 CPU 有16 個128 位的向量寄存器XMM0~XMM15,內核參數nr,mr取值的首要策略是最大化利用架構寄存器,因此綜合考慮,nr和mr分別取值為6 和4.同時矩陣參數[nc,kc,mc]依據第2.2 節中的自動調優技術同樣獲得了比理論值更好的參數設置. 如圖6 所示,通用寄存器RAX 用于索引Ac的micro-panel 中的數據,不斷獲取一個雙精度數據然后復制成兩份填充到XMM0 中;RBX 用于索引Bc的micro-panel 中的數據,一次獲取并存儲6 個雙精度數據到XMM1~XMM3 中.XMM4~XMM15 用于存儲不斷累加的中間結果.在此過程中,向量寄存器XMM0 實際共存儲過4 個Ac數據,XMM1~XMM3 共存儲過6 個Bc數據. 常用的多線程并行手段有OpenMP[31]和POSIX Threads(pthread)[32].BLIS 同時支持兩種并行方式,且當前只在Level-3 實現了并行.與OpenMP 相比,Pthreads 技術在實際編程中需要考慮臨界區、線程同步原語等非常底層的操作,故我們在GEMM 以及TRSM 等小kernel 和Level-1 與Level-2 的并行化實現中,選擇使用更加便利的OpenMP 進行并行化. 針對Level-3 級BLAS 的并行實現方式,BLIS 提出了新穎的“control-tree”結構[7].該結構以統一的方式實現了如圖3 所示的GEMM 大kernel算法的并行以及HERK、TRMM 和TRSM 運算的并行.Control-tree 結構最突出的優點是可以在任意層loop 內分別使用環境變量BLIS_JC_NT、BLIS_IC_NT、BLIS_JR_NT和BLIS_IR_NT進行多線程并行的控制,甚至是多個維度同時并行.這種統一結構的便利性的代價就是在所有能夠發生并行的地方設置同步屏障(barrier),以便在當前loop 的下層所有操作全部返回后才能繼續回溯.雖然文獻[7]中的性能測試結果表明control-tree 結構的開銷是非常小的,但在異構HPL 環境中,control-tree 的開銷變得尤為突出.BLIS原生control-tree 的結構大致如圖7 所示. Fig.7 Original BLIS GEMM control-tree圖7 BLIS 原生GEMM control-tree 對于異構HPL 中的GEMM 運算,我們選擇只在loop3 處(Mc維度)實現并行,當各個線程的Acpacking 打包操作和后續操作都完成后,需要在loop3 的Icbarrier 處進行第1 次同步,隨后的Pcbarrier 和global barrier 處再次進行同步,才可以保證最終GEMM 運算的正確性.可以看到,Pcbarrier 和global barrier 的同步開銷其實是可以避免的,只需將loop3 放到算法的最前端,然后使用OpenMP 自身的同步操作實現各個線程的同步即可.基于此分析,對GEMM 運算的control-tree 結構做出了如圖8 所示的調整. 通過異構HPL 的實際測試,未優化control-tree 時DGEMM 和DTRSM 運算的同步barrier 等待的時間開銷為2.29s,約占CPU端計算總時間的20%.優化control-tree 結構后,GEMM 函數同步barrier 的等待時間減少為1.49s,TRSM 運算應用類似于優化思路,同步barrier 的等待時間減少到基本可以忽略不計. Fig.8 Optimized HBLIS GEMM control-tree圖8 優化后的HBLIS GEMM control-tree 原BLIS庫沒有實現Level-1 級和Level-2 級BLAS 函數運算的并行化.本文使用如下相似的策略實現了DGEMV、DTRSV、DSCAL、DAXPY 以及IDAMAX 運算的并行化: (1) 通過運行腳本中設置的環境變量“OMP_NUM_THREADS”獲取當前MPI 進程中的線程數. (2) 將矩陣或向量中的某個維度按設置的線程數進行切分. (3) 最后使用OpenMP 的Pragma(編譯指示)啟動多線程,在不同的線程空間中復用同一段匯編kernel 來處理不同的數據.在Pragma 包裹的并行域(parallel region)中需要合理而準確地為每個線程劃分任務空間.可以通過omp_get_thread_num()函數獲得當前線程的線程編號(TID)劃分任務,避免計算沖突. 多線程并行對于BLAS 運算的性能提升是非常顯著的,矩陣或向量計算達到一定規模后,性能往往隨著線程數的增加而提升,但提升并不會完全是線性的,通常是計算越密集的運算,提升的線性程度越高,因此計算量最大的Level-3 級BLAS 運算通過多線程并行會大大提升性能.如圖9 所示,在N=43776 時的Level-1 運算IDMAX 隨著線程數的增加表現出性能的提升. Fig.9 Performance improvement by multi-threading of IDAMAX圖9 多線程對IDAMAX 的性能提升 多線程并行化并不是總會對計算帶來幫助,為了進一步提高性能,需要綜合考慮以下問題. (1) 動態多線程 創建和啟動多線程的開銷在計算量很小的情況下會變得突出,從而導致程序性能下降.所以需要設置一個或多個特定的閾值來進行線程數的切換.具體是設置一個閾值將多線程直接切換到單線程,還是設置多個閾值將線程數分段遞減,需要具體的BLAS 函數結合特定的輸入數據進行大量的測試歸納(profiling).在DGEMM 的多線程優化中,我們設計了精確的運算量模型.DGEMM 需要計算一個m×k階矩陣A和k×n階矩陣B的乘積,其主要計算量和乘積mkn成正比.考慮到矩陣A的規模m·k,矩陣B的規模k·n等都對最終運算性能造成影響,我們使用最小二乘法擬合矩陣計算的性能公式,假設不同線程數目下運算時間根據式(2)計算. 于是對于輸入參數為mi、ki和ni,運行時間為ti的測試數據,對應擬合數據中的一行如式(3)所示. 所有這些擬合數據組成N×8 階矩陣P,其中N是采樣數,而所有的采集時間構成對應的列向量b,于是構成式(4)的擬合方程. 解方程得出的8 階變量x的各分量就是a1,a2,…,a8的最小二乘擬合結果.分別對單線程、4 線程、8 線程和32 線程測試擬合公式,在運行中根據擬合結果動態切換線程數據,得到如圖10 所示的性能結果. Fig.10 Performance speedup of DGEMM in 32 threads圖10 DGEMM 在32 個線程中的性能加速比 實踐中還發現,不同的kernel 實現方式以及硬件設置等因素也會影響到閾值的選取.比如,在異構HPL 的DGEMV 函數的優化過程中,根據不同的“OMP_NUM_THREADS”、不同的CPU 主頻以及矩陣A的列數N(M方向做并行)設置不同的多個閾值. (2) 均衡余量(remainder)處理 當使用多線程將求解問題切分成多塊后,往往會遇到不能均分的情況.所謂不能“均分”,是指整體的運算量不能均勻地分配到每個線程中去.此時有兩個選擇:或者將所有多出的運算量全部放到某一個線程中,比如最后一個線程;或者將余量再次均分到所有線程中.Remainder 處理的問題在線程數較少時(比如6 個線程)不會那么關鍵,但在線程數較多時(比如32 個線程)會變得突出.因為此時的木桶效應更加明顯,整體運算的同步結束取決于擁有最大余量的那個線程.根據本文HPL算法測試分析后,采取了將remainder 分配給每個線程處理,得到的性能結果最優. (3) 循環展開與多線程的均衡 循環展開的程度和線程的數量需要均衡考慮.在使用動態多線程去加速運算的過程中,往往會有多種求解方法去完成同一個運算.考慮以下場景:異構HPL 中的DGEMM 運算在M較小時,比如M=28,此時可以使用4個線程各處理6 個M維度的行,然后使用1 個線程處理剩下的4 個M行;或者使用5 個線程各處理5 個M維度的行,然后使用3 個線程處理各處理一個M行,如式(5)所示. 不同的求解方法涉及同一個函數的不同kernel 函數編寫以及動態多線程threshold 的選取.通過實際測試發現:DGEMM 運算在M較小時,更多的循環展開比更多的線程性能要好,如圖11 所示. Fig.11 In the case that B matrix is square matrix (dimension N=K),more unrolling is better performance than more threading in small DGEMM圖11 B 矩陣是方陣(維數N=K)的情況下,在小規模的DGEMM 中,更多的循環展開比更多的線程性能更優 異構HPL算法中綜合使用了以上介紹的訪存優化、指令集優化和多線程并行等優化技術,對算法中調用的7 個BLAS 函數進行了針對性優化,并與OpenBLAS 0.3.6 和MKL(Intel Math Kernel Library 2018.0.128)進行了對比測試.實驗測試平臺是高性能計算集群系統中的單個計算節點,其配置是如圖1 所示的32 核X86 CPU 與4 個協處理組成的異構計算單元.在測試平臺上分別進行了單核DGEMM 和多核心并行DGEMM 測試,最后測試了異構HPL 程序. 通過系統性能分析工具讀取CPU 中各種計數器的數值,可以分析應用程序的各項指標.X86 處理器支持非常多的性能監控計數器,包括浮點、訪存、指令等CPU 各種資源的監控.如表2 所示為Auto-tuning 優化后的矩陣分塊參數與初始分塊參數進行DGEMM 計算時的cache miss 對比情況,分析得出分塊參數[mc,kc,nc]從[1080,120,8400]優化為[792,822,8628],kc和nc的增大導致矩陣打包到L1 緩存時,因L1 容量小而發生更多的cache miss.但是,L2 和L3 緩存容量比L1 大得多,其命中率的提高可以掩蓋L1 的性能損失并提高整體DGEMM的性能. Table 2 Cache miss rate of HPL counted by performance monitor unit表2 通過性能監控單元統計HPL 的緩存失效率 如圖12 和圖13 所示分別為單核和32 核情況下不同數學庫的DGEMM 性能對比.因為Intel MKL 只有在Intel 平臺上才能發揮最佳效果,在X86 異構平臺上效率不是最好,僅作為參考;而Netlib 為未經過任何優化的Fortran 語言實現的通用標準數學庫.可以看到,HBLIS 的DGEMM 實現無論是在單核心還是在32 核心下,其性能均超過了其他BLAS庫,單核DGEMM 最高效率達到了98%,32 核最高效率達到了96.9%.與未優化前的BLIS和MKL 相比,單核性能分別提升了19.2%和33.3%,32 核性能分別提升了42.1%和33.6%. Fig.12 DGEMM efficiency comparison of single-core圖12 單核DGEMM 效率對比 Fig.13 DGEMM efficiency comparison of 32 cores圖13 32 核DGEMM 效率對比 HPL 實測性能值是最終評價標準,分別統計每個BLAS 函數的時間作為BLAS 優化的評價標準.為避免網絡通信的干擾,本文基于單節點進行異構HPL 測試,對比包括panel 分解中pfact 時間以及HPL算法中使用的7 個BLAS 函數DGEMM、DGEMV、DTRSM、DTRSV、IDMAX、DSCAL 和DCOPY 的計算時間. 異構HPL算法panel 分解部分主要在CPU端進行計算.如圖14 左側所示為HPL 程序panel 分解中的pfact總時間統計,調用HBLIS 的pfact 與調用MKL 的相比,計算時間節省了53%.如圖14 右側所示為DGEMM 函數計算時間統計,可以看到,HBLIS 的DGEMM 性能比MKL 的DGEMM 性能提升了約25%. Fig.14 Performance comparison of pfact and DGEMM calling different math libraries in heterogeneous HPL圖14 異構HPL 中調用不同數學庫的pfact 和DGEMM 的性能對比 如圖15 所示為DGEMV 和DTRSV 函數性能對比.DGEMV 在panel 分解中時間占比僅次于DGEMM,因此DGEMV 性能對整體性能的影響也僅次于DGEMM.圖15 左側為DGEMV 性能,優化的HBLIS 比MKL 提升了約62%,比原BLIS 提升了約65%.圖15 右側為DTRSV 函數時間統計,原BLIS 性能與MKL 差距較大,經過優化后的BLIS 性能超過了MKL.因為DTRSV 計算量較小,在總時間中占比也相對很小. Fig.15 Performance comparison of DGEMV and DTRSV calling different math libraries in heterogeneous HPL圖15 異構HPL 中調用不同數學庫的DGEMV 和DTRSV 的性能對比 如圖16 所示為DTRSM 和IDMAX 函數性能對比.原生BLIS算法庫中的三角矩陣求解DTRSM 性能較差,優化后的DTRSM 性能與MKL 基本一致.在pfact 第106 步~第141 步的性能是超過MKL 的,而在panel 分解最后段,MKL 運算更快,原因是DTRSM 在切換到小kernel 的threshold 和動態多線程的threshold 時,需要做進一步的調整,以適應運算量的變化.IDMAX 函數主要是用于選主元操作,計算量可以忽略不計. Fig.16 Performance comparison of DTRSM and IDAMAX calling different math libraries in heterogeneous HPL圖16 異構HPL 中調用不同數學庫的DTRSM 和IDAMAX 的性能對比 如圖17 所示,Level-1 級BLAS 函數DSCAL 和DCOPY 優化后的性能基本與Intel MKL 一致.其中,DSCAL優化后的性能比原生BLIS 有大幅度提升,但在panel 分解后段的性能還是略低于MKL,原因是MKL 使用的多線程庫IOMP 比開源的GOMP 在多線程啟動、調度和動態多線程的切換上更加高效.而DCOPY 代碼實現簡單,優化空間非常有限,硬件平臺性能直接決定了其時間開銷,故可以看到三者DCOPY 的性能基本一致.DAXPY 運算只在回代(back substitution)過程中調用一次,性能影響可以忽略,故未列出詳細對比. Fig.17 Performance comparison of DSCAL and DCOPY calling different math libraries in heterogeneous HPL圖17 異構HPL 中調用不同數學庫的DSCAL 和DCOPY 的性能對比 本文針對CPU 平臺系統架構的特點,在開源BLIS算法庫的基礎上開發了優化的HBLIS 數學庫,詳細介紹了HPL 調用的各級BLAS 函數優化方法.通過訪存優化、指令集優化和多線程并行優化,HPL 調用的各級BLAS函數的計算性能與MKL 的相應函數相比有著普遍和顯著的提升,個別計算量小的函數性能基本與MKL 相應函數性能一致,其中最重要的DGEMM 函數提升了約25%,DGEMV 函數性能提升了約62%.在異構單節點HPL測試中,與調用MKL庫的HPL 相比,采用HBLIS 的HPL 整體效率值提升了11.8%,更好地發揮了異構高性能平臺的計算能力.同時本文也有不足之處,雖然HBLIS庫性能測試發現DGEMM、DGEMV、DTRSV 和IDMAX有著很好的優化效果,其性能與MKL 和開源BLIS庫相應函數相比都有大幅度提升,但是DTRSM 和DSCAL優化后性能并沒有優于Intel MKL,這可能與計算量、多線程庫支持和編譯器優化支持都有密切關聯.底層子例程庫優化是一個系統工程,不僅需要硬件架構的優化設計,而且需要編譯器和線程庫等底層軟件的優化.本文未涉及的其他BLAS 函數的優化將是HBLIS庫下一步優化工作的方向.2.3 矩陣打包
2.4 數據預取


3 指令集優化
3.1 X86向量指令
3.2 循環展開
4 多線程并行
4.1 Control-tree優化
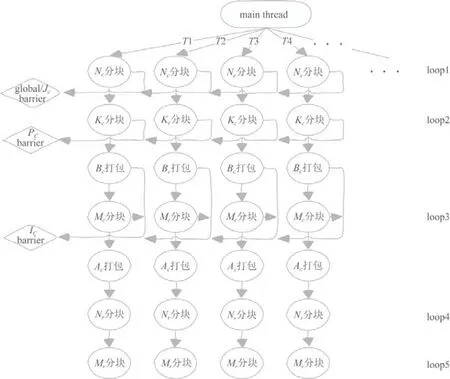
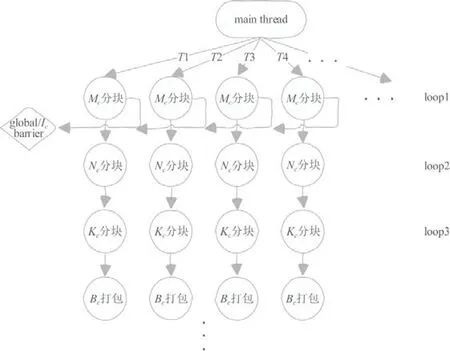
4.2 Level-1和Level-2級BLAS并行優化
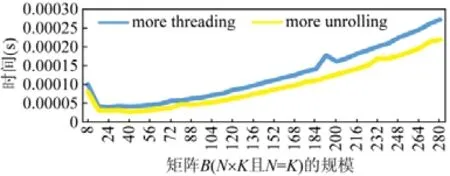
4.3 并行化問題
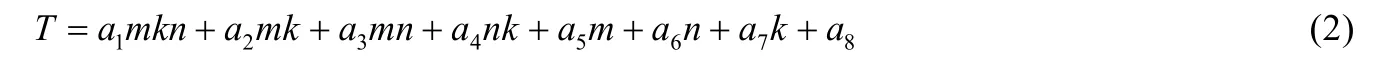


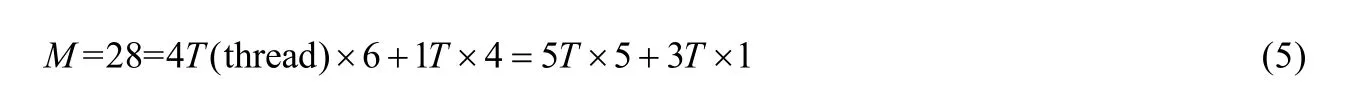
5 性能測試與分析
5.1 Cache性能分析

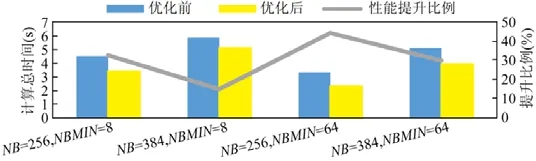
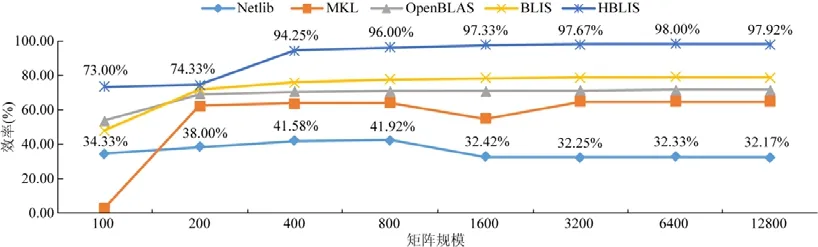
5.2 DGEMM效率

5.3 異構HPL測試
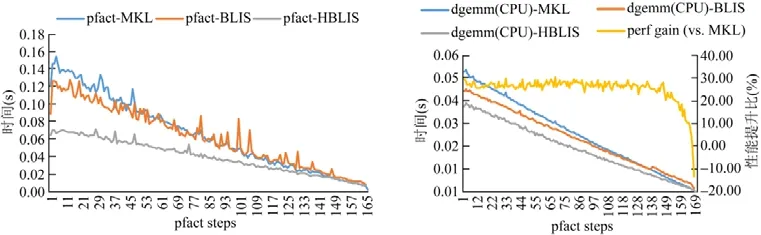
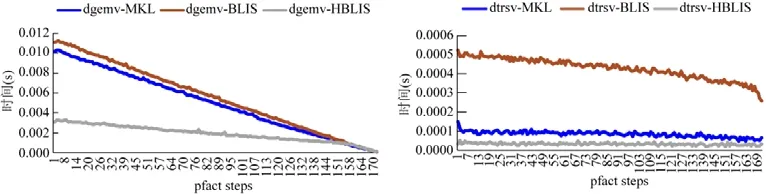
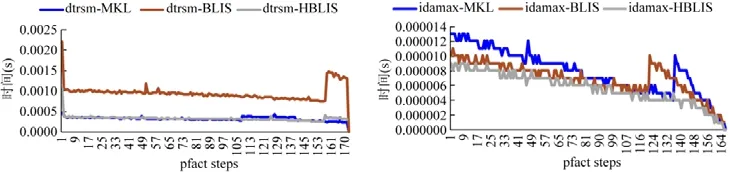
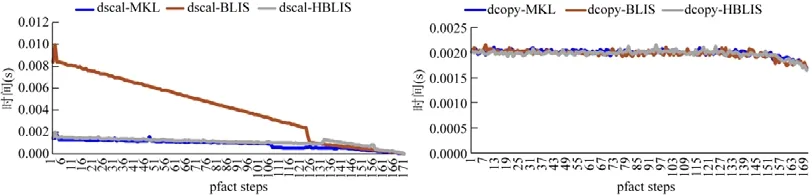
6 總結與展望
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
現代企業(2015年2期)2015-02-28 18:45:09
