卷積神經網絡圖像識別算法的FPGA加速優化研究
2021-11-06 01:00:28馬曉光蔣占軍
蘭州交通大學學報 2021年5期
關鍵詞:優化
馬曉光,蔣占軍
(蘭州交通大學 電子與信息工程學院,蘭州 730070)
隨著人工智能技術的飛速發展,深度學習技術已日漸普及,卷積神經網絡(convolutional neural network,CNN)作為深度學習中的一個重要算法,已廣泛地應用于計算機圖像處理、自然語言識別和文檔分析等領域[1-3].
早期的卷積神經網絡多是由CPU執行的,但隨著應用需求越來越復雜,CPU計算顯得緩慢低效.目前實現CNN加速的平臺主要有圖形處理器(graphics processing unit,GPU)、專用集成電路(application-specific integrated circuit,ASIC)、現場可編程邏輯門陣列(field-programmable gate array,FPGA)三類,其中FPGA平臺因為體積小、功耗低、靈活性高等特點,已逐漸成為卷積神經網絡硬件加速常用的研究平臺[4].
卷積神經網絡的FPGA加速研究主要集中在并行計算和內存帶寬優化兩方面,其中并行計算主要通過設計卷積層間并行、卷積內計算并行和輸出通道并行3種方式來實現加速.例如文獻[5]提出了一種全并行乘法-加法樹模塊加速卷積運算等,此類單純的硬件并行加速方法資源占用較多、帶寬需求較大,實際應用中仍需做相應的改進.內存帶寬優化通常采用一些優化算法定量分析計算吞吐量和所需內存的帶寬,確定最佳性能進而解決資源占用量大的問題,例如基于天花板模型(roofline model)的設計方案等[6].但是此類方案在不同層間需要重新配置,靈活性稍顯不足.在加速算法設計方面,一般采用通用矩陣乘法算法(general matrix multiplication,GEMM)將矩陣轉換為向量,并對每個向量一對一計算,最后將向量計算結果用in2col函數輸出并轉換為矩陣[7].但并未減少計算量,同時又產生大量的讀寫需求和內存需求.為此,本文采用軟硬件協同并行優化的機制,在CNN參數定點量化的基礎上設計全并行的加法-乘法模塊和高效的流水線操作,進一步優化CNN在FPGA上計算的效率.
1 CNN模型參數分析
1.1 CNN加速優化網絡模型
卷積神經網絡是一種多層的監督學習神經網絡,一般包含輸入層、卷積層、激活層、池化層和全連接層[8].而每一層的參數更新都會使上一層的輸入參數分布逐步偏移,導致網絡收斂速度緩慢.為了解決這一問題,Google在2015年提出了一種批量規范化(batch normalization,BN)算法,通過對偏移參數做規范化處理使其達到標準分布,避免梯度消失,從而可加快網絡收斂,防止過擬合[9].
本文將識別圖形作為輸入,經過卷積層、批量規范化層、激活函數層和池化層處理后得到識別結果.其中,卷積層通常是大量數據的乘加運算來實現,假設卷積層共有L個,則第l層的第n個特征圖為x(l,n),其表達式為
(1)
其中:M為輸入特征圖的總數;N為經過卷積運算后得到的特征圖的總數;ωl,n為第l層的第n卷積核;*表示卷積運算.
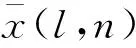
(2)
式中:n=1,2,…,N;μ為卷積參數均值;σ2為卷積參數方差;ε是一個很小的常數,用來排除分母為零的情況;β為偏置;γ為縮放因子.
激活層本文采用ReLU函數,其收斂速度比sigmoid和tanh函數快[10].激活函數主要是為此網絡提供非線性建模能力,有效提高網絡對于復雜問題的表達能力.池化層本文采用全局平均池化層,有效減少CNN參數規模以及計算量[11].
1.2 卷積參數權值預處理
BN層在網絡訓練中有很大的優勢,在每層卷積后加上BN層代替原來的局部歸一化(local response normalization,LRN).由于直接加入BN層會導致網絡模型增大,所以將BN層計算和卷積層計算合并,用于提高前向推理的運算速度,同時壓縮網絡模型[12].由公式(1)和(2)可得
(3)
將公式展開得
(4)
(5)
從而將BN層規范化和卷積計算合并,在每次計算中減少一層運算,能夠在一定程度上減少資源占用,并且提高計算速度.
2 CNN模型參數定點化處理
卷積參數預處理是將訓練網絡簡化為卷積層、激活層和池化層.其方式是將卷積層和BN層合并為一層,計算量主要集中在卷積層.文獻[13]提出了定點量化與網絡準確率平衡的方式,但是在圖像識別應用場景中未做分析研究,針對此問題本文提出對卷積層的特征參數動態定點化處理,將浮點計算轉換為高效的定點計算.
2.1 浮點數動態定點量化
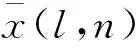
(6)
(7)
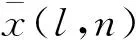
(8)
根據式(8)可得出一個量化誤差.在數學概念中,只要誤差小于最小精度誤差的一半,可視為無損.所以將量化誤差與誤差精度比較,以查找表的形式選擇一個合適的量化范圍使用Q格式表示.Q格式是二進制的定點數格式,相對于浮點數,Q格式指定了相應的小數位數和整數位數,在FPGA硬件運算的平臺上,可以更快地對數據進行處理,定點數的Q值表示精度見表1.量化的精度決定了卷積運算數據的準確性,對于浮點數使用Q15格式轉換定點數,可以保留最高精度,但保留精度越高其精度范圍非常小,若超出精度范圍會損失全部的有效數據[15].通過這種動態的Q值數據設置,可調整量化后的定點數據精度達到最優,以此來減少定點量化所帶來的誤差損失.
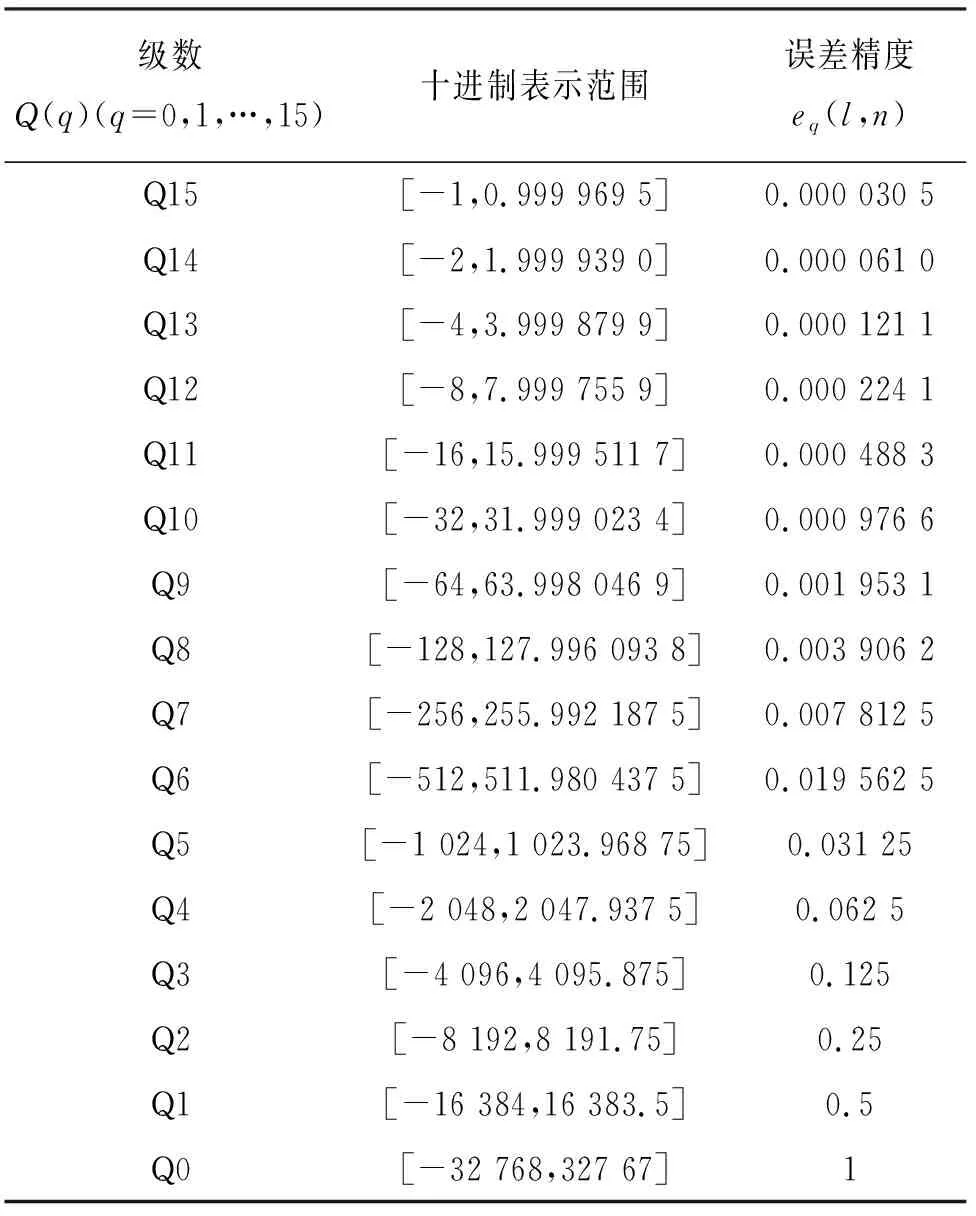
表1 16位定點數Q格式十進制數值范圍及精度誤差Tab.1 Decimal value range and precision error in 16-bit fixed-point number Q format
2.2 定點量化的取舍
在數據量化過程中,為了進一步提高定點數計算效率,本文采用就近取舍.假設2.1節定點量化后得到一個定點數X,在?X」和「X?之間的數據取值是一個概率問題,將X舍入到?X」的概率與X到「X?的接近度成正比:
(9)
3 面向CNN并行優化方式
面向CNN軟硬件協同設計是針對開發軟件HLS工具和C/C++ 語言相結合的方式所提出的[16].由于FPGA資源受限,不能移植龐大的卷積神經網絡實現卷積加速.針對此問題本文提出一種FPGA的并行優化方式.
3.1 軟硬件協同設計
軟硬件協同是目前卷積神經網絡加速研究的一個重要方向,是將整個系統設計集成在一個片上系統(system on chip,SoC)中,片上系統是由可編程邏輯(PL)和ARM處理器(PS)組成,如圖1硬件結構設計.ARM處理器通過IP網絡接口從PC端獲得特征參數和權值并存入DDR存儲模塊中,然后驅動AXI_DMA控制模塊將參數傳輸到片上存儲器(random access memory,RAM)中.ARM會控制CNN硬件加速計算單元將特征參數和權值依次從片上存儲系統中傳輸到CNN加速模塊中進行計算.整個運算結束后,ARM驅動AXI_DMA模塊,將運算結果返回到DDR,通過IP網絡接口傳輸到PC.
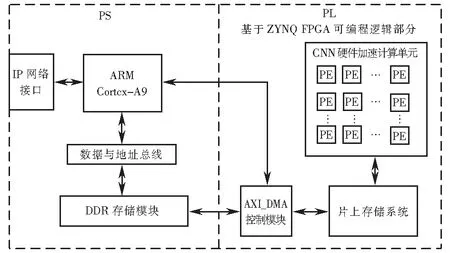
圖1 FPGA硬件結構圖Fig.1 FPGA hardware structure
3.2 FPGA實現動態定點量化
針對3.1節提出的浮點數動態定點量化方法,設計了基于FPGA的動態定點量化模型.文中提出的定點計算主要分為兩個模塊:參數量化模塊和誤差優化模塊,如圖2所示.參數量化模塊主要是對特征圖參數和卷積核權值進行定點量化,如圖2中左部分,量化器的主要功能是使用3.1節中的方法,對參數和權值做量化和反量化的計算過程.經過定點量化后計算出特征參數誤差eq_x和權值誤差eq_w.第二部分是誤差優化,如圖2中右部分,將誤差精度數據存儲在硬件內部,利用查找表的形式對特征參數誤差和權值誤差比較,若誤差小于最小誤差精度的一半,可視為無損量化,然后將量化后的參數存儲進行下一步的卷積計算,反之,返回到量化器中重新量化比較,直到參數達到最優為止.
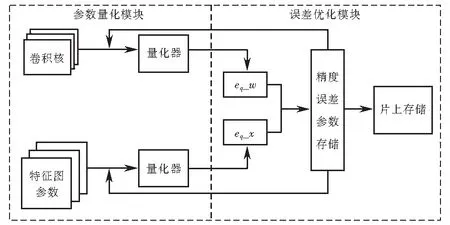
圖2 定點量化計算模型Fig.2 Fixed-point quantization calculation model
3.3 卷積層硬件加速設計
為了提高計算效率和減少訪問存儲器延時,本文提出了并行交錯的計算方式,如圖3所示,其中FIFO為存儲器,buffer為緩沖器,這兩部分稱為數據通道,后面的卷積運算實質上是乘法運算.為了實現運算加速效果,將特征圖中數據和卷積核的矩陣形式轉換為數據流形式.提取特征圖中的每行數據存儲到存儲器(FIFO_1),并且提取卷積核每行權重值存儲到下一個存儲器(FIFO_2),以此方式提取每組數據存儲到后面的存儲器,將每個存儲器中的權值和卷積參數串行輸入到寄存器Ai_buffer和Bi_buffer中依次做乘法運算,最后做累加運算.如此方式在有限的設計單元中實現了卷積并行運算.并且在FPGA中每個階段的計算都是由寄存器來完成,所以不需要等待當前計算執行完成后再將數據提取到Ai_buffer和Bi_buffer中,而是在每個時鐘周期內同時進行輸入、輸出和計算操作,有效地提高了運算效率.
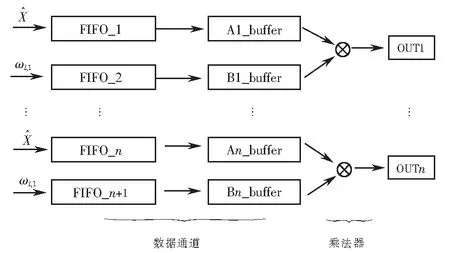
圖3 FPGA矩陣乘法原理Fig.3 FPGA matrix multiplication schematic diagram
根據FPGA矩陣乘法原理,本文設計了如圖4所示的卷積計算單元,實現卷積層運算在硬件內部的并行加速計算.圖4中,I(z,s)表示輸入特征圖第z行第s列的參數,Wzs表示卷積核內第z行第s列權值參數.在每個時鐘周期內每行依次輸入一個特征參數與卷積核的權值運算,經過3個時鐘周期后可得到一個卷積窗口的運算值.例如,第一個時鐘周期輸入第z行第一個參數I(z,0),并與卷積核中W00計算得到I(z,0)W00,結果傳輸到下一級加法器中;第二個時鐘周期累加I(z,1)W01的結果,并且得到I(z,1)W00的結果;第三個時鐘周期得到I(z,0)W00+I(z,1)W01+I(z,2)W02,同時得到I(z,1)W00+I(z,2)W01的結果,相當于卷積窗口的滑動操作.同時,第z+1行和z+2分別得出結果,累加后得到一個卷積窗口的和.當計算完所有輸入特征圖后可得出最終的卷積結果.

圖4 卷積運算硬件結構設計Fig.4 Design of hardware structure of convolution operation
3.4 數據傳輸優化
由于卷積網絡中數據龐大,考慮到將特征圖參數全部存儲到FPGA內部存儲器中計算是不現實的,而在FPGA數據傳輸過程中,外部訪問數據時延較大.針對這一問題,本文將PL端與PS端使用HLS工具中流數據傳輸減少傳輸時延.數據傳輸的相關偽代碼如下:
#pragma SDS data access_pattern(
in_A:SEQUENTIAL,
in_B:SEQUENTIAL,
out_C:SEQUENTIAL
);
int i,j,x,y;
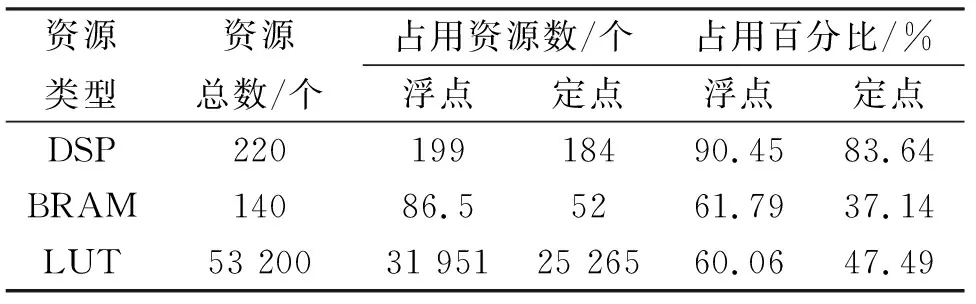
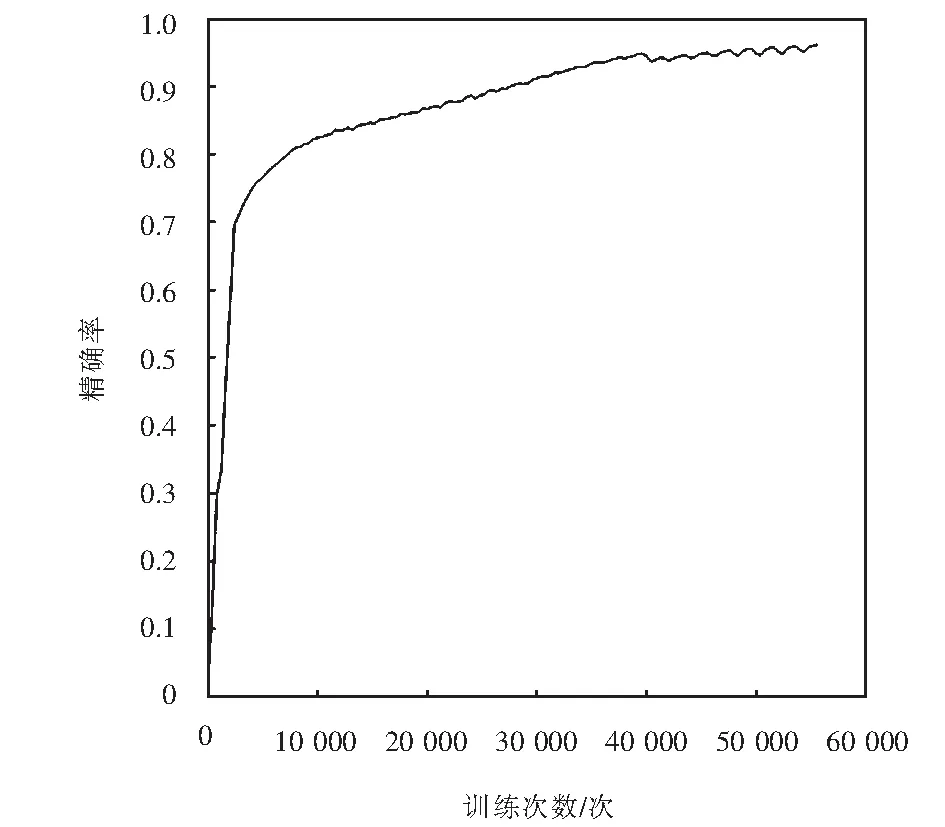
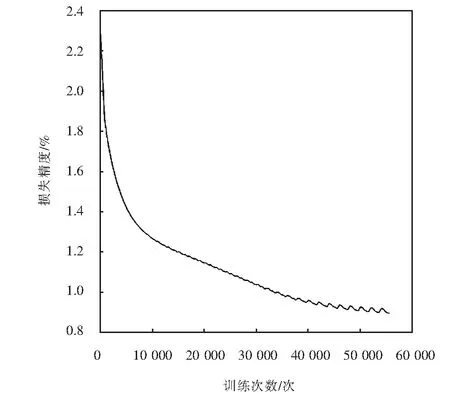
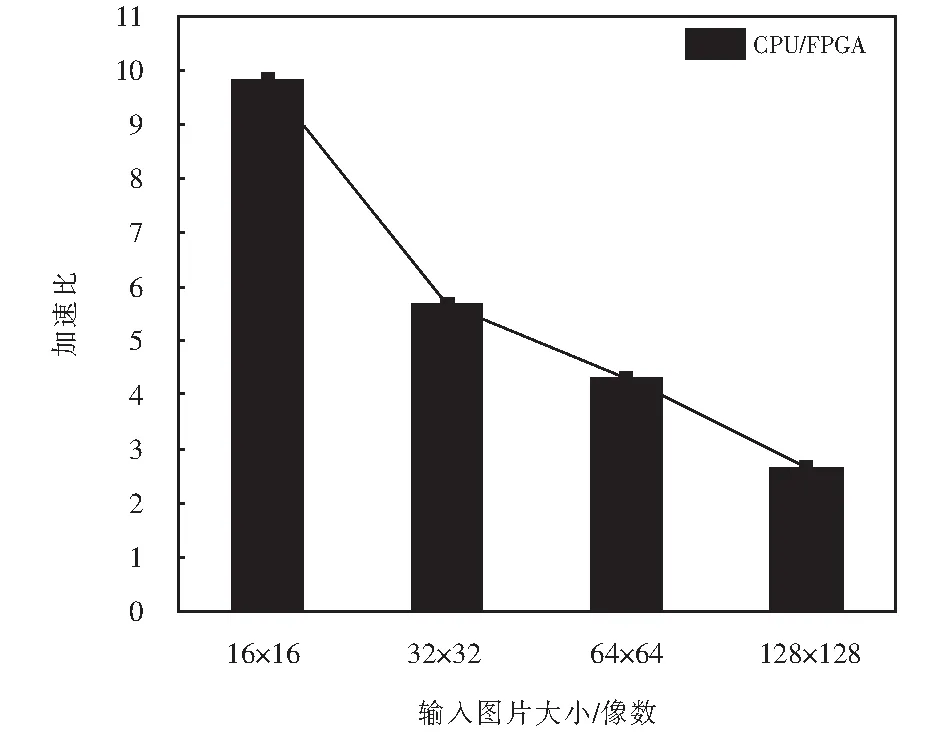
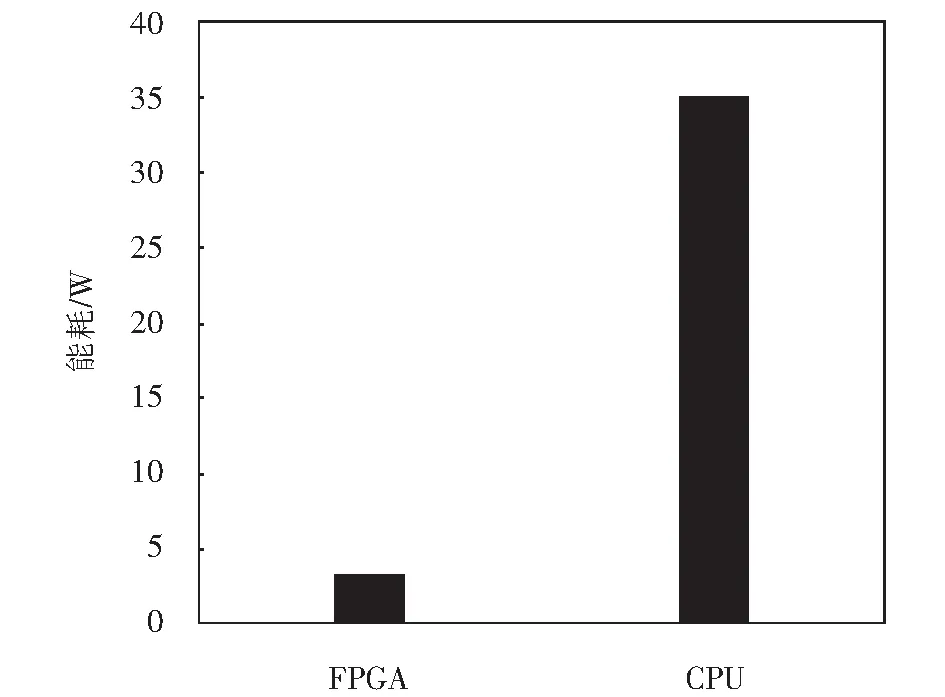
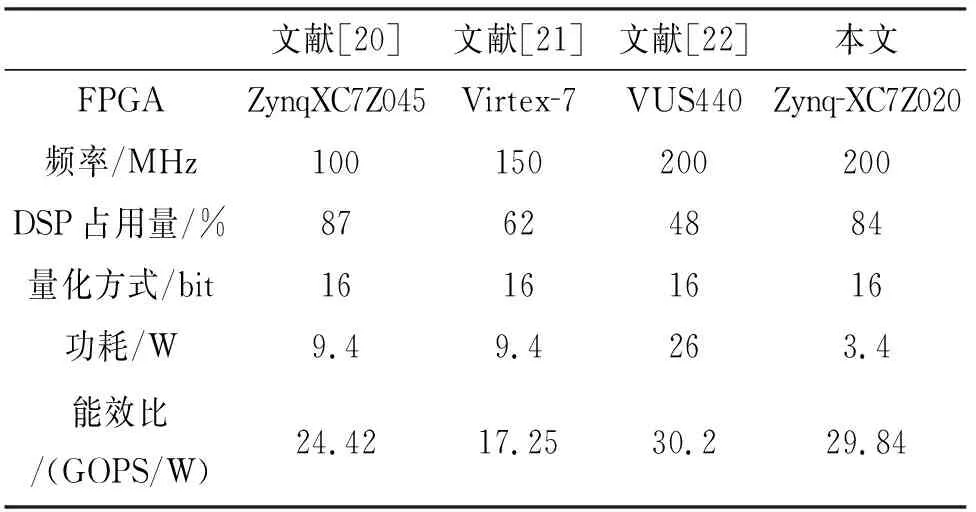
for(i=0;i for(j=0;j #pragma HLS PIPELINE result=0; for(x=0;x #pragma HLS UNROLL for(y=0;y product_term=in_A[x][y]*in_B[x+i][y+j]; result+=product_term; }} out_C[i*N+j]=result; }}} 偽代碼中,SDS data access_pattern指令用于規定SDSoC編譯器中數據訪問的模式,由于在卷積神經網絡計算中,數據訪問的模式必須是流式訪問而不是隨機訪問,所以將訪問模式設置為SEQUENTIAL,則會被綜合成流接口(如ap_fifo);否則,將綜合為RANDOM,系統可隨機訪問數組.考慮到卷積計算的流水線操作,卷積計算采用PIPELINE,將卷積特征圖矩陣循環展開并使用流水線計算. 實驗采用Xilinx XC7Z020嵌入式平臺,實驗將卷積神經網絡已訓練的權值移植到FPGA中實現硬件加速,并對數據結果進行分析.首先對比數據定點量化前后FPGA資源占用情況,資源占用見表2.由于本文采用定點數據格式,所以計算資源DSP和內存占用資源BRAM分別減少約6%和24%.查找表(look-up-table,LUT)使用量減少是因為定點數乘加不消耗LUT資源,但本文在Q格式定點量化中以查找表方式確定無損量化需要大量的LUT資源,所以無明顯減少. 表2 浮點數及定點數卷積層資源消耗對比Tab.2 Comparison of resource consumption between floating points and fixed points convolutional layer 將硬件資源占用率情況與文獻[17-18]中的結果進行對比,見表3.DSP利用率達到83%,相較于文獻[17]和文獻[18],本文對FPGA內部計算資源高效利用,BRAM占用率相較于其他兩種方案都有所減少,LUT相較于文獻[17]有所增加,是因為本文采用Q格式動態定點量化,使用FPGA內部查找表資源. 表3 資源利用對比Tab.3 Comparison of resource consumption % 實驗以圖像種類識別作為具體實驗的應用背景,采用caffe深度學習框架,利用cifar-10數據集做為測試,其中包含50 000個樣本的訓練集和10 000個樣本的測試集.對浮點數定點量化后對網絡重新訓練,當訓練次數達到40 000次后,由圖5中可看出,識別率達到90%以上且趨于穩定,說明定點優化后網絡精度沒有明顯的降低;同時損失曲線收斂,擬合度較好,說明網絡不存在過擬合問題,見圖6. 圖5 訓練識別率結果Fig.5 Training recognition rate result 圖6 訓練損失收斂曲線Fig.6 Training loss convergence curve 針對不同平臺卷積計算速度對比如圖7所示.FPGA的工作頻率為200 MHz,CPU采用Inter Core i5-3337U處理器,主頻為1.8 GHz.圖7中加速比η=tc/tf,tc為CPU處理圖片時間,tf為FPGA處理圖片時間.隨著輸入圖片大小的增加,FPGA處理速度明顯高于CPU處理速度,且功耗很低,見圖8.但當圖片大小增加時,加速比明顯下降,因為數據的增多會使FPGA內部數據傳輸速度有時延,導致處理速度有明顯的下降. 圖7 FPGA與CPU加速性能對比Fig.7 Comparison of FPGA and CPU acceleration 圖8 FPGA與CPU功耗對比Fig.8 FPGA and CPU power comparison performance 本文以AlexNet[19]網絡模型為基礎,FPGA底層運算代碼采用C++ ,設計卷積前向推理加速器.表4是與其他FPGA加速方案結果進行對比,由于各方案選用的FPGA硬件平臺不同,為了進行有效對比增加了能效比參數.從表4中結果可看出,本文DSP利用率相對較高,說明本設計充分利用FPGA內部計算資源且功耗相較于其他三種方案最低.能效比達到了29.84 GOPS/W,但相較于文獻[22]還有一些差距. 表4 FPGA硬件加速對比Tab.4 FPGA hardware acceleration comparison 本文針對卷積神經網絡可并行提出了基于FPGA的卷積神經網絡圖像識別算法加速優化研究,將卷積層與BN層合并計算,壓縮網絡模型,在此基礎上針對卷積運算中的浮點數設計了Q格式動態定點量化,有效地提升了前行推理的計算速度,并且在有限資源的FPGA中減少了資源的占用.在硬件方面針對CNN可并行性設計了全并行乘法-加法結構,利用高效的流水線傳輸方式對卷積窗口進行緩存和計算,相比于CPU串行計算有大幅的提升.而本文只是針對卷積層進行優化,未考慮到其他網絡層的優化,后續工作為了提高FPGA加速性能,將深入研究網絡結構,改進其他層的網絡結構,并且在FPGA并行計算的基礎上優化硬件結構.4 實驗結果與分析

5 結論
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14能源工程(2022年1期)2022-03-29 01:06:28建材發展導向(2021年12期)2021-07-22 08:06:48建材發展導向(2021年7期)2021-07-16 07:07:52中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50今日農業(2020年16期)2020-12-14 15:04:59消費導刊(2018年8期)2018-05-25 13:20:08家庭影院技術(2018年4期)2018-05-09 07:07:41電子制作(2017年20期)2017-04-26 06:57:45
