基于外觀和動作特征雙預測模型的視頻異常行為檢測
2021-11-05 01:29:58李自強王正勇陳洪剛李林怡何小海
計算機應用 2021年10期
李自強,王正勇,陳洪剛*,李林怡,何小海
(1.四川大學電子信息學院,成都 610065;2.中國民航局第二研究所,成都 610041)
0 引言
視頻的異常行為檢測是計算機視覺領域極具挑戰性的問題,其中一個主要原因在于對異常沒有一個通用的定義,其判定通常依賴于所處的特定場景。例如一輛汽車行駛在步行街上是一個異常行為,而在公路上則是正常的。這種非常依賴于場景前后關系的行為識別是當前異常行為檢測所面臨的重大挑戰。為了應對這個問題,一個典型的方法就是將與正常視頻差異過大或未出現過的行為作為異常行為,但是這一方法可能將未在訓練集中出現的正常行為當作異常。一方面,異常行為發生頻率較低,而監控視頻數據量大且多以正常行為為主,因此對視頻進行人工標注成本太高;另一方面,實際獲取的數據集只是真實場景下正常行為和異常行為的子集,故無法囊括所有發生的行為[1]。這種數據不平衡和異常樣本缺乏的問題使得當前大多數研究都采用弱監督學習和半監督學習方法。
當前提出的弱監督學習方法[2-3]多是采用基于多示例學習(Multiple Instance Learning,MIL)的異常檢測方法,將訓練集中的每個視頻當作一個包,視頻的每一幀當作一個實例,把含有異常幀的視頻標記為正包,全是正常幀的記為負包。這類方法是在已經獲知一個視頻是否含有異常事件的假設下來研究異常檢測問題,只是不知道異常的時序位置和類型,但真實情況下這種先驗知識是不存在的。因此當前研究多采用基于重建或預測的半監督學習方法。對于基于重建的方法[4-6],其通常使用卷積自編碼器或者生成對抗網絡(Generative Adversarial Network,GAN)來學習以較小的重建誤差來重建正常樣本,并希望當重建異常樣本時,訓練好的模型能夠產生較大的誤差。而對于基于預測的方法[7-9],研究者們認為異常事件是意料之外的,難以被預測,故在正常視頻上訓練的網絡能夠在異常幀上產生更大的預測誤差。然而這兩種方法并未達到理想的效果,主要在于這些方法只關注視頻幀外觀上的重建和預測,而忽略了異常事件的區分是通過外觀、動作或兩者兼之來判斷,比如:步行街上行駛的汽車與正常場景的區別在于外觀;而打架、游蕩等行為需要通過動作判定,拋擲物品需要兩者共同判定。考慮到動作信息對于異常檢測的重要作用,很多基于重建或預測的方法采用預訓練模型來提取動作信息,例如:Liu 等[9]和Nguyen 等[10]采用光流網絡來提取動作特征,Morais等[7]使用姿態估計網絡提取人體關節點表征動作信息。然而這些方法會使得網絡更加復雜,且容易受預訓練模型本身的影響。
為了解決上述問題,更好地學習視頻表征,本文提出了一種對動作和外觀進行聯合預測的孿生網絡。該網絡的兩個分支采用相同結構的自編碼器,每個分支網絡由編碼器、記憶增強模塊和解碼器組成,其中編碼器和解碼器采用殘差結構的上下采樣層用于更好地提取特征和預測幀圖。兩個子網絡的輸入不同,外觀子網絡輸入RGB 視頻幀預測未來幀,而動作子網絡則使用相同長度且更容易獲得的RGB 幀差圖代替光流圖作為輸入預測未來幀差圖,最后將兩個分支網絡的預測幀圖再融合相加得到預測幀的下一幀,即預測未來兩幀。
1 相關工作
視頻異常檢測方法大致可以分為基于傳統機器學習的方法和深度學習的方法兩類。傳統方法主要是通過手動提取的動作和外觀特征來檢測異常,比如定向光流直方圖[11]、定向梯度直方圖[12]和3D梯度特征[13]等,例如:Kim等[14]為了能更好地捕捉局部運動特征,利用混合概率主成分分析來建模光流;Mahadevan 等[15]使用混合動態紋理(Mixture of Dynamic Texture,MDT)來檢測時間上的異常;胡學敏等[16]提出使用運動特征圖來檢測人群異常行為。這些傳統方法所提取的特征有限,而視頻中包含豐富的高維特征難以通過傳統方法提取。
近些年來,由于深度學習在異常檢測領域的顯著表現,大量的研究都采用基于神經網絡的方法[5-10,17-21]。由于視頻中的異常一般被定義為與正常行為差異較大或很少發生的行為,加上其異常數據獲取困難、人工標注成本高等因素的影響,絕大部分研究采用半監督學習方法,即只使用正常樣本進行訓練。Hasan 等[19]采用卷積自編碼器進行重建幀圖像,通過重建誤差的大小檢測視頻幀的異常。在此基礎上,Luo 等[20]在自編碼網絡中加入卷積長短記憶(Convolutional Long Short-Term Memory,ConvLSTM)網絡捕捉正常樣本的時間信息。考慮到基于重建模型的方法無法充分提取視頻中豐富的動作特征,而異常行為又多包含大量的動作特征,為此Liu 等[9]提出基于GAN 的未來幀預測模型,使用連續幾幀圖像預測下一幀圖像,同時通過加入光流約束來提取動作特征。Morias等[7]認為視頻中異常多與行人相關,而基于像素的特征對噪聲比較敏感,會將場景[9]中的重要信息掩蓋,故提出一個預測行人關節點軌跡的異常檢測網絡,但該方法適合處理與行人相關的異常,而其他類型的異常(如汽車)無法檢測,此外人體骨架的檢測對遠鏡頭處的行人效果較差。為了更好地提取動作和外觀特征,許多研究[10,21]使用雙流網絡結構分別提取動作和外觀特征進行異常檢測,并取得了較好的效果。
盡管基于卷積神經網絡(Convolutional Neural Network,CNN)的方法很大程度上優于傳統方法,但是由于CNN 強大的表征和“生成”能力,使得一些異常樣本也能被重建或預測得很好。為了降低CNN 的“生成”能力,更好地建模正常樣本的深層特征的分布,Abati 等[5]在自編碼器的瓶頸層(Bottleneck)加入自回歸模塊;Fan 等[21]則訓練兩個高斯混合變分自編碼器,通過高斯混合模型學習正常樣本的表征;Gong等[4]通過在編碼器后級聯一個內存尋址的記憶模塊來使得自編碼器在重建樣本時更加關注正常樣本的特有特征。
受到上述研究的啟發,本文提出將預測模型應用在外觀和動作的孿生網絡結構中,期望其更好地對動作和外觀信息進行預測,同時為了更好地提取特征和重建圖像,在編解碼器中采用殘差結構的上下采樣模塊。此外本文不再使用許多方法廣泛使用的光流法來提取動作特征,而是使用不需額外計算的視頻幀差圖,最后通過引入記憶增強模塊來應對正常樣本多樣性和CNN的“生成”能力過強的問題。
2 異常行為檢測方法
為了更好地實現基于視頻的異常檢測,本文提出了一個能同時對動作和外觀進行預測的半監督異常檢測方法,其網絡框架如圖1所示。
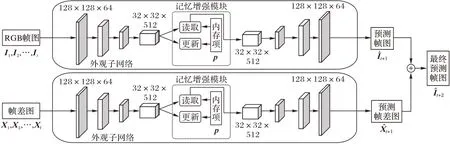
圖1 視頻異常行為檢測方法的網絡框架Fig.1 Network framework of video abnormal behavior detection method
本文網絡框架由上下兩個外觀和動作子網絡組成雙流結構,兩個子網絡分別由編碼器、記憶增強模塊以及解碼器依次級聯組成。兩個子網絡的輸入為長度都為t的RGB 幀圖和幀差圖,而最終兩子網絡輸出結果融合相加得到預測的t+2 幀視頻圖像。
2.1 外觀自編碼器
外觀自編碼器的作用是提取視頻中靜態場景和所關注目標的外觀特征,通過連續幾幀RGB 圖來預測下一幀。該子網絡結構借鑒廣泛用于圖像重建和預測的U-Net,如圖1 所示。在編碼器和與解碼器相同分辨率的高維特征層和低維特征層加入跳連接(skip-connection)來抑制梯度爆炸和每層的信息不平衡,從而保證較高的圖像預測質量。
對于編解碼器部分,以 Conv-AE(Convolutional AutoEncoder)[19]為基礎,對編碼器的下采樣層和解碼器的上采樣層進行改進,將原有的單流結構調整為圖2 所示的殘差結構來鼓勵網絡更好地提取特征和提高幀圖的預測質量。編碼器由1個預處理模塊和3個殘差結構的下采樣模塊組成,該下采樣模塊的兩個分支分別采用卷積和池化來壓縮特征,如圖2(a)。同理,解碼器由3個殘差結構的上采樣模塊和1個生成模塊組成,而上采樣模塊采用不同大小的卷積核的反卷積來實現,如圖2(b)。編碼器與解碼器形成對稱結構,編碼器的預處理模塊通過連續兩次卷積操作將輸入的幾幀視頻提取為64維的低維特征,而解碼器的生成模塊與之相反,通過3個卷積層將低維特征轉為3維的圖像。
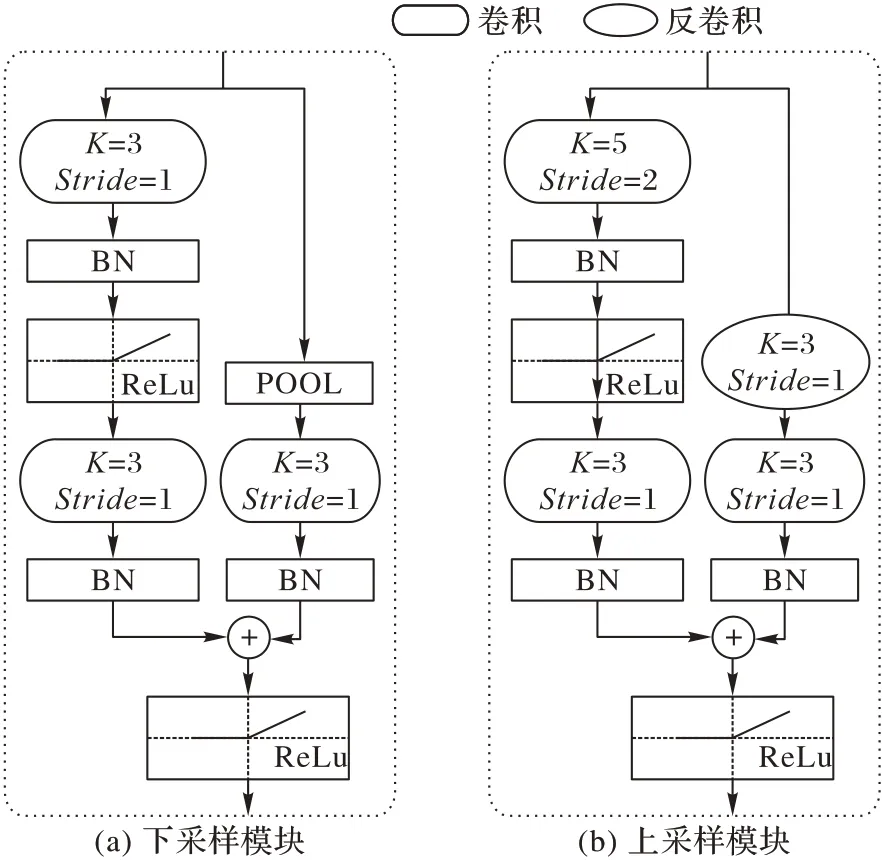
圖2 下采樣及上采樣模塊網絡結構Fig.2 Network architecture of down-sampling and up-sampling modules
給定連續輸入視頻幀I1,I2,…,It,經過編碼器Ea下采樣提取關于圖像場景、目標外觀信息等深層特征后,解碼器Da通過Za預測得到第t+1幀


2.2 動作自編碼器
除了較大的目標外觀變化外,不尋常的目標動作也可以作為衡量視頻幀是否異常的重要條件,而動作自編碼器被鼓勵學習連續視頻幀間的動作關系。為了簡化網絡的設計,動作自編碼子網絡采用與外觀自編碼器相同的網絡結構,只有輸入數據不同。當前大部分研究提取動作特征采用的是光流估計法[22],提取的目標光流可以很好地表示目標的運動變化;但是其需要通過額外的神經網絡生成,故計算量較大,不適合在實際應用環境中使用。此外光流估計本身并不是專門為檢測異常行為而設計的網絡,直接將其嵌入到圖1 中所設計的網絡中,實際效果并不理想,這一點將在實驗部分說明。受到Wang 等[23]和Ionescu 等[24]采用了連續視頻幀的幀差圖來提取動作特征的啟發,本文提出使用幀差圖代替光流圖,從而達到不使用預訓練模型、減少計算量的目的。故動作自編碼器輸入與外觀子網絡相同長度的連續幀差圖來預測下一幀幀差圖。
與式(1)類似,定義輸入的連續幀差圖為X1,X2,…,Xt,該t張幀差圖通過連續t+1 張視頻幀I1,I2,…,It,It+1前后幀相減處理獲得,其中,Zm表示編碼器Em輸出的動作特征向量,然后解碼器Dm重建得到最終的幀差圖

2.3 記憶增強模塊
在半監督的異常檢測研究中,如何使得設計的網絡更好地學習到正常樣本的特征,盡可能降低與異常行為無關的背景噪聲影響是富有挑戰性的問題。在使用自編碼器實現重建和預測任務時,由于神經網絡極強的學習能力,使得部分異常樣本也能重建得和正常樣本一樣好,導致最終的異常分數差異不明顯,出現較高的誤檢率。參照Gong 等[4]和Park 等[17]所提方法,本文方法引入記憶增強模塊旨在學習最能表征所有正常樣本的有限個原型特征,并保存在內存項中,在預測時給與內存項相似度高的特征分配更高的權重,從而期望異常樣本獲得較大的重建誤差。
如圖1 所示,外觀和動作自編碼子網絡都嵌入了記憶增強模塊。定義記憶增強模塊的輸入和輸出為z和,大小為H×W×C,其中H、W、C分別表示特征向量的高、寬和通道數。定義zk(k=1,2,…,K),其表示z中大小為1×1×C的一項,其中K=H×W。記憶增強模塊中還包含存儲M個正常樣本特征的內存項,同理定義每個內存項為pm(m=1,2,…,M),大小為1×1×C。在訓練過程中會不斷更新和讀取內存項。
對于讀取操作,首先計算每個z與所有pm的余弦相似度,生成一個大小為M×K的二維的相似度矩陣,之后在M維度上對該相似度矩陣應用softmax 函數,獲得相應的匹配概率ωk,m,計算式如下:
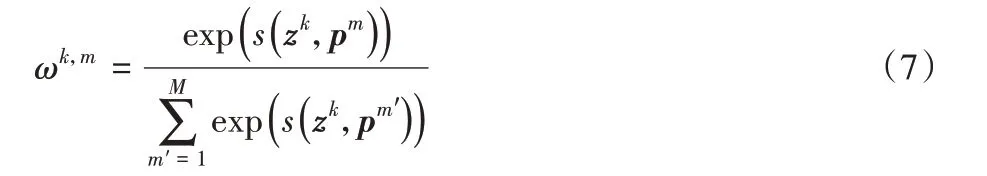
式中:s(?,?)代表余弦相似度計算,如式(8)所示:

對于每個zk,該模塊將讀取內存項中所有pm,計算相應的權重ωk,m,即zk與內存項中的特征越相似,其權重ωk,m越大。最后在原輸入特征zk的基礎上,將內存項中保存的正常特征通過對應權重ωk,m加到zk上,對正常特征起到增強效果,從而解碼器將更加關注正常特征的重建預測。增強后的特征如式(9)所示:

從圖1 所示的記憶增強模塊網絡結構可知,更新操作與讀取操作的前期都要計算余弦相似度和應用softmax 函數。故對應的權重νk,m計算如下:
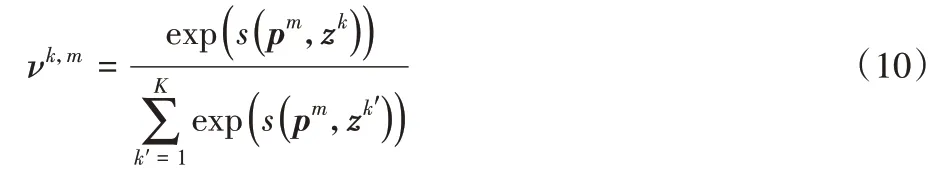
更新后的特征計算與式(9)的過程相反。在訓練階段,輸入都為正常視頻,內存項在不斷更新的過程中,期望學習到正常樣本廣泛具有的正常特征,故在迭代過程中,通過相似度計算,不斷將與pm相似度高的特征通過權重νk,m加入原有特征pm中。更新每個內存項如式(11)所示:

式中l2(?,?)表示L2正則化。
為了使內存項真正記住正常樣本的特征,該模塊使用特征壓縮損失Lc和特征分離損失Ls兩個損失函數來保證網絡的收斂。Lc希望輸入特征zk與內存中與其最相似的一項的相似度更加接近。如式(12)所示,引入L2范數懲罰它們之間的差異。

式中:pτ表示所有內存項與zk相似度最高的一項,即固定k時,式(7)中ωk,m取得最大值時的m定義為τ。
網絡原本的目的是希望每個內存項都能學習到不同的正常樣本特征,僅僅使用Lc可能會使得內存中所有項都越來越相似,這會完全背離該設計的初衷。因此,引入特征分離損失函數來鼓勵內存項間差異更大,降低相似度,從而學習到不同的特征,損失函數定義如下:
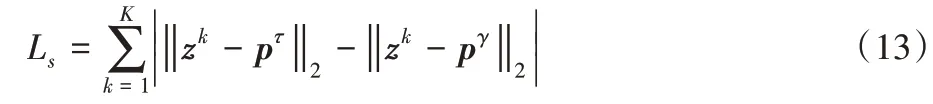
式中:τ和γ分別表示式(7)中ωk,m取得最大值和第二大值時的索引m的值。
2.4 總損失函數
根據圖1 所示,外觀自編碼網絡被鼓勵預測好It+1,而動作自編碼網絡被鼓勵預測Xt+1,同時為了聯合利用到外觀特征與動作特征,保證預測的It+1和Xt+1真實有效,將It+1與Xt+1相加獲得預測的It+2。因此總損失函數由三部分組成:外觀損失La、動作損失Lm和預測損失Lp,其中,Lp是第t+2幀的真實圖It+2與預測圖的密度損失函數,計算方法可參照式(3)。通過超參數λa、λm和λp來平衡3 個損失函數,如式(14)所示:

其中:La是由外觀自編碼器網絡的密度損失和對應的特征壓縮損失和特征分離損失構成。La如式(15)所示:

同理Lm定義如下:

式中αc、αs為超參數。
2.5 異常評價分數
在測試階段,本文將給定連續t+1 幀視頻,前t幀圖直接送入外觀子網絡預測第t+1幀RGB圖,同時這t+1幀計算得到t張連續幀差圖后送入動作子網絡預測第t+1幀與第t+2幀真實視頻間的幀差圖,最終兩子網絡預測結果相加得到第t+2幀的預測圖。對于基于預測思想的異常檢測網絡來說,預測的圖與真實圖的差異大小決定該幀是否異常,而本文采用動作和外觀雙預測的孿生網絡,外觀方面的異常會使得的預測效果較差,動作層面的異常會導致的預測效果較差,而外觀和外觀兼有的異常則會導致的預測效果都不理想。為了更全面地評價所有的異常情況,同時簡化異常分數的計算,本文網絡將t+2幀的預測圖質量作為評估依據,這是因為上述三種異常情況都會導致t+2幀的預測效果下降。峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)是一種比較常用的圖像質量評價方法,廣泛用于基于重建或預測的異常檢測模型。參考Liu等[9]的方法,計算的PSNR:
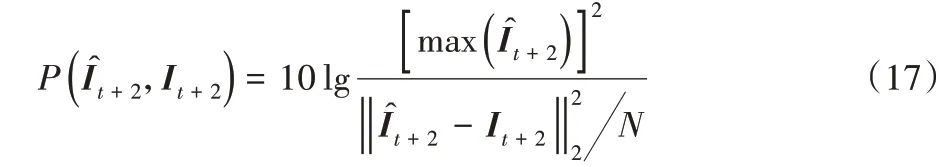
式中N表示視頻幀中的像素數量。的值越小,代表圖像預測的質量越差,就越可能是異常幀。此外,由于內存增強模塊中的內存單元存儲了正常樣本的原型特征,在測試階段,當輸入的是正常視頻幀時,其深層特征zk與內存項pm的相似度較高,而輸入異常樣本則相反,故可以計算zk和與之最相近的pτ之間的L2距離:

因此最終的分數由三部分構成:P和Dm(z,p),其中Da(z,p)和Dm(z,p)是D(z,p)分別在外觀和動作子網絡的分數表示。為了將這3 個分數進行融合,將式(17)、(18)的值歸一化到[0,1]得到和。然后通過超參數β來平衡三個分數得到最終的異常評價分數S:
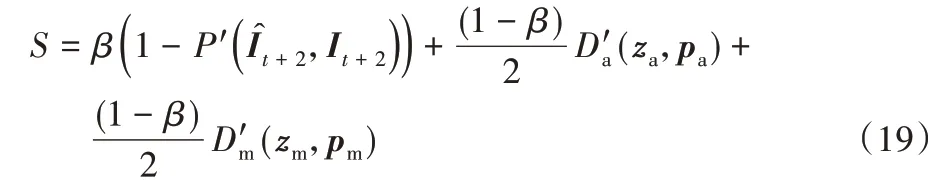
3 實驗與結果分析
3.1 數據集
實驗在3 個公共的異常檢測數據集UCSD-ped2[15]、Avenue[13]和ShanghaiTech[25]上進行。UCSD-ped2 包含16 個正常視頻和14 個異常視頻,正常視頻中主要是攝像頭拍攝的人行道上的正常行走的行人,而異常視頻內包括在人行道上騎自行車、溜冰、開小汽車、橫穿馬路等行為。測試集提供幀級別和像素級的標簽,所有視頻分辨率為320×240。Avenue 數據集包含15 個正常視頻和21 個異常視頻,分辨率為640×360,其使用固定攝像頭拍攝學校走廊的場景,提供矩形框標記異常對象的標簽。異常視頻則涵蓋行人奔跑、拋擲物品和穿越草坪等行為。ShanghaiTech 數據集是當前最具挑戰和難度的異常檢測公共數據集之一,它包含來自13 個攝像頭下的330 個訓練視頻和107 個測試視頻,每個視頻分辨率為480×856。圖3 展示在3 個數據集中的正常與異常樣本示例,紅色矩形框標注出正在發生的異常行為。

圖3 三個數據集中的一些正常和異常樣本Fig.3 Some normal and abnormal samples in three datasets
3.2 評估機制與實驗細節
當前常用的評估方法就是采用受試者操作特征(Receiver Operating Characteristic,ROC)曲線,然后取曲線下面積(Area Under Curve,AUC)作為最終的評價指標,AUC 越高,代表異常檢測效果越好,本文將計算幀級別AUC 來評估模型的檢測效果。整個實驗在Ubuntu 20.04、NVIDIA GeForce RTX 2080 Ti、Intel Core i7-9700 CPU 3.00 GHz的平臺上進行,采用的深度學習框架為pytorch1.1。網絡輸入圖片尺寸將修改為256×256,使用Adam 優化器優化訓練損失,初始學習率lr設為1E-4,其中記憶增強模塊的內存項個數M=15,超參數λa=λm=1.0,λp=0.4,αc=0.1,αs=0.4,β=0.65。網絡訓練50個epoch后損失收斂。
3.3 結果分析
3.3.1 與其他方法的比較
表1 展示了本文所提方法與其他方法的比較。從表1 實驗結果可以看出,所提方法與手動提取特征的經典方法MDT相比在UCSD-ped2 上AUC 提升了17.6%。AMC(Appearance-Motion Correspondence)[10]和TWD(TWo-stream Decoder)[26]都采用光流提取動作特征的雙流網絡結構,與這兩種方法相比,本文方法在UCSD-Ped2和Avenue上AUC提升明顯,而且本文方法還未采用光流估計的預訓練網絡,極大降低了網絡復雜度。與作為預測方法基準線(Baseline)的FFP(Future Frame Prediction)[9]比較可以看出,本文所提的雙分支預測的網絡有效。MemAE(Memory-augmented deep AutoEncoder)[4]和Mem-GN(Memory-Guided Normality)[17]都采用記憶增強的方法。與Mem-GN相比,本文方法在UCSD-ped2和ShanghaiTech數據集上取得了較好的結果,而在Avenue上略低于Mem-GN。從圖3可以看出,Avenue數據集的場景為校園內的走廊,其背景走廊內光線較暗,離攝像頭距離較遠導致行人目標過小等問題會使得通過視頻幀提取的幀差圖含有較多噪聲,從而對提取到的動作特征產生影響。而當前極具挑戰的ShanghaiTech 數據集來源于13 個不同攝像頭,對類似于Mem-GN等只對外觀進行預測或重建的方法,其對場景變化的魯棒性較差。而本文方法通過幀差提取動作特征則極大降低了背景的影響,從而使網絡更加關注于前景的變化。
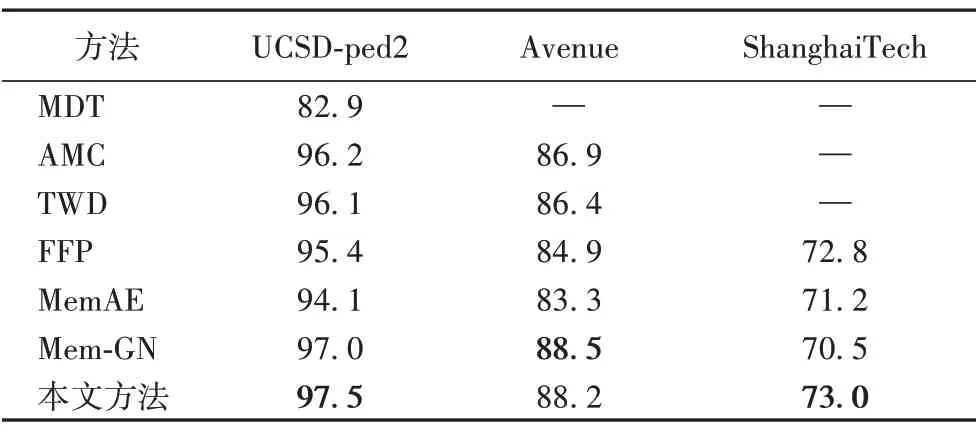
表1 不同方法在不同數據集上的AUC對比 單位:%Tab.1 AUC comparison of different methods on different datasets unit:%
3.3.2 時間性能
為了評估所提方法的時間性能,通過在UCSD-ped2 數據集上使用不同分辨率的輸入幀來測試網絡的實時性。在分別采用128×128、256×256 和400×400 分辨率時,本文方法的時間性能為93 frame/s、40 frame/s 和16 frame/s。當分辨率為256×256 時,FFP 和Mem-GN 的時間性能分別為25 frame/s 和67 frame/s。故本文方法的時間性能可滿足實時性要求。
圖4 分別展示了文中所提方法在Avenue、UCSD-ped2 和ShanghaiTech數據集中測試視頻上的檢測結果。
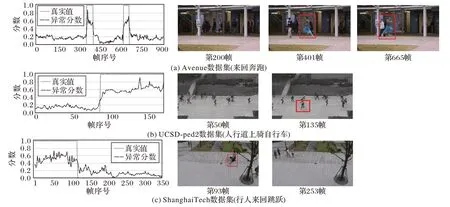
圖4 本文方法在三個數據集的測試視頻上的異常檢測結果Fig.4 Abnormal detection results of the proposed method on test videos of three datasets
從圖4 中可以清楚看出,異常發生時異常分數迅速升高,故可通過設置一個分數閾值將異常幀與正常幀區分出來。
3.4 網絡分析
為了進一步證明所提出網絡各部分模塊的作用,本節將各部分模塊依次加入網絡中來測試異常檢測性能。
表2中,幀差代表動作子網絡采用幀差還是光流;Memory表示是否采用記憶增強模塊;而殘差采樣模塊表示自編碼器網絡中編碼器和解碼器是否采用殘差結構的上下采樣層。
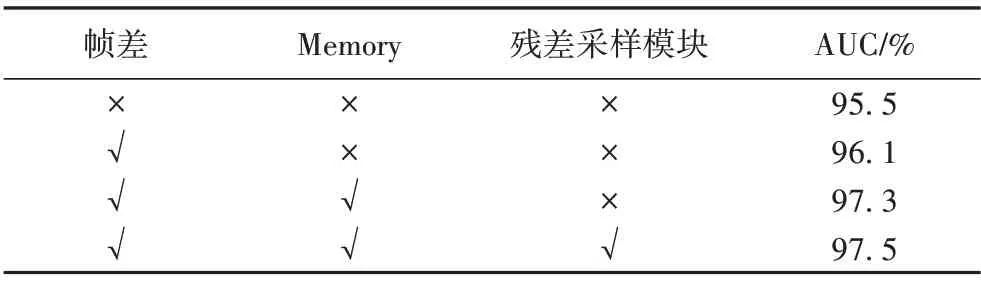
表2 評估本文網絡中不同模塊的作用Tab.2 Function evaluation of different modules in the proposed network
從表2 可以看出,在本網絡中幀差比光流具有更佳的表現;記憶增強模塊的加入使AUC具有較大提升;將圖1中自編碼器網絡中上下采樣層從單流結構改為殘差的雙流結構后,其AUC 有一定程度提升,故該結構更利于編碼器提取外觀和動作特征并改善解碼器預測圖的質量。
本文所提方法損失函數中共設置了5 個超參數,考慮到超參數對最終的檢測結果有較大影響,故表3對式(14)中3個參數λa、λm和λp對AUC 的影響。3 個超參數分別用于確定外觀損失La、動作損失Lm和預測損失Lp的權重。表3 顯示3 個參數設定不同比重時,檢測結果AUC的變化情況。
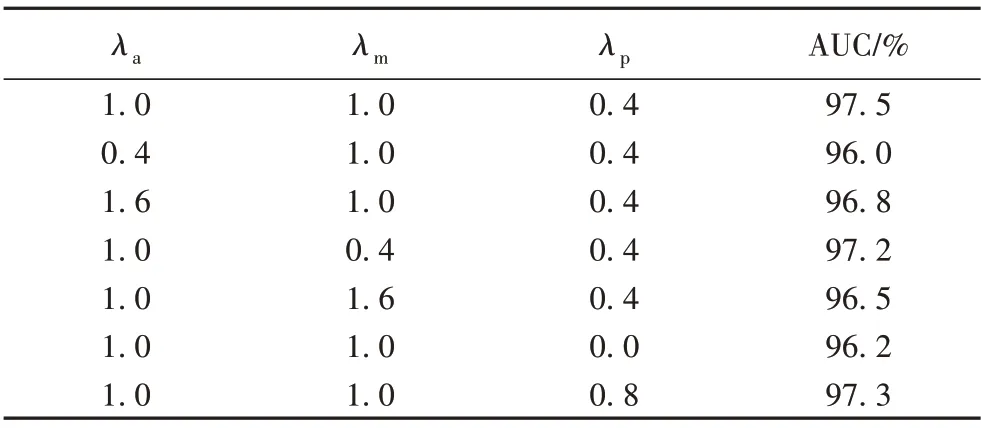
表3 損失函數中主要超參數對AUC的影響Tab.3 Influence of main hyperparameters in loss function on AUC
從表3 可知,總體來說,La相較Lm對AUC 的影響更大,Lp的目的是讓由融合相加得到的更接近真實幀It+2,而此幀的PSNR作為異常分數的重要部分。
如表4 所示,輸入視頻幀序列長度t的長度較小時,無法達到預測的目的,其更接近于重建網絡;但是,當t的長度逐漸增大時,網絡并不能因此學到更多的時序特征,反而會增加網絡參數。
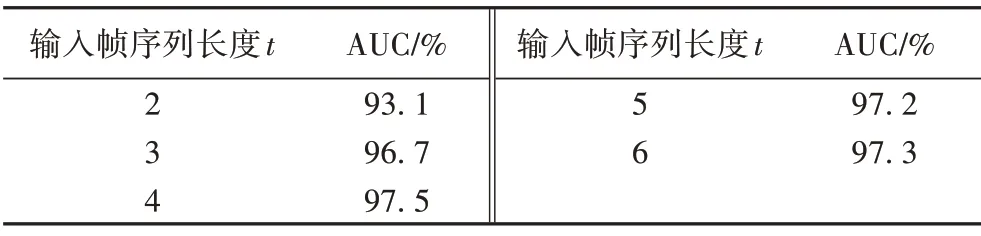
表4 不同長度幀序列下的AUCTab.4 AUC under frame sequences with different lengths
4 結語
本文提出了一種基于外觀和動作特征雙預測的視頻異常行為檢測方法。該孿生網絡同時使用RGB 圖和幀差圖來提取動作和外觀特征,并進行預測。通過在自編碼器瓶頸層級聯了記憶增強模塊,促使網絡更好地學習正常樣本的特征,降低對異常樣本的預測效果。實驗結果表明,所提方法提升了視頻異常行為的準確率,提高了其在3 個數據集上的AUC 指標。本文方法對提取正常行為的外觀和動作特征進行了部分優化,降低預測網絡對異常視頻的預測效果,但仍未充分提取到正常樣本的特征,且網絡對背景噪聲的魯棒性欠佳,故在未來工作中,將進一步對該問題進行研究,提高網絡對異常行為檢測的準確性和穩定性。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
海峽科技與產業(2016年3期)2016-05-17 04:32:12
