基于可分離金字塔的輕量級實時語義分割算法
2021-11-05 01:29:44高世偉張長柱王祝萍
計算機應用 2021年10期
高世偉,張長柱,王祝萍
(同濟大學電子與信息工程學院,上海 201804)
0 引言
圖像語義分割是計算機視覺領域的核心問題之一,可被視作像素級別的分類問題。近些年來,隨著深度卷積神經網絡的顯著發展,圖像語義分割的預測準確度達到了一定高度;然而自動駕駛、機器人感應和增強現實設備等極具潛力的現實應用[1-2],對語義分割算法的實時性提出了更高的要求。受計算和存儲成本的限制,現有的擁有較大網絡規模的算法模型很難在保證高預測準確度的同時達到較高的圖像分割速度。輕量的網絡模型能夠以較高的速度完成圖像分割,但是缺少對高級特征語義信息的提取,模型分割精度得不到很好的保證。如何同時保持高分辨率圖像的高預測準確度和高推理速度是研究人員當前階段最為關心的重要問題。
本文從輕量級圖像實時語義分割算法的關鍵技術[3]出發,提出了一種可分離金字塔特征提取單元用于編碼部分獲取語義信息,并構建不同模塊應用在不同下采樣階段;解碼部分采取基于通道注意力機制的方法,利用深層語義修改淺層特征圖的通道權重,彌補淺層特征關于高級語義信息的不足,優化分割效果。本文的主要工作如下:
1)本文以構建輕量級圖像實時語義分割模型為目的,探究了深度可分離卷積、瓶頸結構和分解卷積的應用潛力,提出可分離金字塔模塊(Separable Pyramid Module,SPM),有效地獲取多尺度特征和圖像上下文信息。在此基礎上,出于對復雜網絡參數量、計算量大的問題的規避,本文構建了輕量的整體算法模型,在準確度和實時性表現之間取得較好的平衡。
2)針對計算機視覺中注意力機制具有對相關特征權重分布學習能力的考慮,本文設計了利用深層語義修改淺層特征圖通道權重的上下文通道注意力(Context Channel Attention,CCA)模塊,并用于上采樣進一步提高實時圖像語義分割的準確度,對于目標空間位置和物體邊緣恢復具有積極作用。
3)在公開數據集Cityscapes 和CamVid 上進行消融實驗和全局實驗,并與其他現有算法對比分析,驗證了本文算法的有效性。
1 相關工作
基于深度學習的圖像語義分割作為計算機視覺中的一項基本任務,旨在估計給定輸入圖像中所有像素的類別標簽,并呈現出不同顏色區域掩模的分割結果。
圖像分割最初較為流行的方法是圖像塊分類(patch classification),其基本思想是利用像素周圍的像素塊對每個像素進行獨立的分類。但是這種方法存在較為明顯的缺點:一方面,劃分像素塊必然意味著特征感受野將受到限制,每個子塊只能在固定大小的區域提取特征,全局信息的關聯性沒有得到處理;另一方面,圖像中每個像素點在參與計算時都需要使用到一個子塊,在處理高分辨率輸入圖像的任務時,這種計算方式會極大地消耗計算資源,給硬件存儲和運算帶來負擔。此外,在當時流行的分類網絡只能處理固定尺寸的圖像,在實際應用中仍然存在很大的局限性。
2014 年,Long 等[4]提出全卷積網絡(Fully Convolution Network,FCN),圖像分割正式進入一個全新的發展階段。FCN 是深度學習首次應用于圖像語義分割的算法,與之前所有圖像分割算法最大的不同在于,FCN 丟棄了分類網絡中所有的全連接層,并用卷積層作相應替換,以學習像素到像素的映射。考慮到卷積神經網絡中的池化操作在擴大感受野、聚合語境的同時造成空間信息丟失、導致分辨率恢復所產生的分割圖過于粗糙的問題,FCN 提出了在上采樣階段聯合不同池化層的結果優化最終輸出的方法。但是FCN 得到的分割結果仍然不夠準確,目標空間位置信息的丟失問題也未得到很好的解決。
Badrinarayanan 等[5]為了解決下采樣導致信息丟失的問題,采取了帶有坐標(index)的池化操作。在最大池化的過程中,網絡記錄下了所選擇的最大像素在特征圖上的位置,并在反池化時根據記錄的坐標,復原最大值至對應的位置,更好地恢復了圖像分割細節。
Chen 等[6]基于擴張卷積提出了深度卷積網絡(Deep Convolutional Net,DeepLab)系列語義分割算法,并分為4 個版本:DeepLabv1 基于VGG-16 網絡改寫,去掉了最后的全連接層和最后兩個池化層,加入了擴張卷積來擴大感受野,條件隨機場(Conditional Random Field,CRF)也被使用在網絡中用于提高分類精度;DeepLabv2[7]以更復雜的、表達能力更強的殘差網絡-101(ResNet-101)[8]為基礎網絡,并提出了空洞空間金字塔池化(Atrous Spatial Pyramid Pooling,ASPP),以多比例捕捉上下文信息,解決圖像中存在的目標多尺度問題;DeepLabv3[9]在DeepLabv2基礎上舍棄了CRF,同時在ASPP中加入1×1 卷積防止擴張率太高導致的卷積退化問題,另外增加了全局池化來補充全局特征;DeepLabv3+[10]是該系列最后一個版本,其采用Xception 模型作為主干網絡并做針對性改進,簡單的解碼結構被用于恢復精細的物體邊緣;祖朋達等[11]在DeepLabv2 的基礎上通過優化擴張卷積,調整其擴張率并添加預處理卷積,更為充分地融合局部和全局特征;2018 年,Yang 等[12]認為ASPP 提取到的特征仍然不夠密集,提出了稠密ASPP(DenseASPP)算法,其用更密集、復雜的連接方式將每個擴張卷積的輸出集合到一起,覆蓋了大范圍的語義信息并做特征提取;喻根等[13]設計一種通過主體網絡特征共享層學習多尺度特征的圖像分割方法,進一步約束和優化目標邊界,得到準確度更高的分割結果。
隨著注意力機制在計算機視覺領域的發展,圖像語義分割開始引入軟注意力用于學習特征權重分布。Fu等[2]提出對偶注意力網絡(Dual Attention Network,DANet),綜合了通道注意力和空間注意力的思想,加入兩種類型的注意力模塊分別模擬空間和通道維度的語義依賴,并對輸出進一步融合增強特征表示,顯著改善了分割效果。
近年來,基于深度學習的圖像語義分割方法取得了很大的進展,在增強現實、自動駕駛、圖像搜索、人機交互等領域有著很大的應用潛力,但縱觀上述方法和近階段其他算法模型[13],大多更關注對圖像分割準確率的提升,其計算成本和內存占用較高,網絡的實時性得不到保證。本文所設計的基于可分離金字塔單元的語義分割算法,在保證圖像分割準確度的同時兼顧網絡模型的輕量性和實時性。首先,針對擴張卷積有效擴大特征提取感受野但內存占用較高的問題,采用深度可分離卷積結構縮減計算量,并構建瓶頸式特征金字塔進行多尺度信息處理;其次,構建三階式的編碼網絡,最多下采樣至輸入圖像1/8分辨率的特征層,保證模型參數較少;最后,通過上下文通道注意力模塊對深層特征圖每個通道的特征權重進行計算,利用所有通道之間的相互聯系加權至淺層特征圖,最終得到通道權重修改后的淺層特征圖,增強淺層通道依賴性并與深層特征圖融合,優化目標邊緣分割效果,提高語義分割準確度。
2 本文方法
2.1 可分離金字塔特征提取單元
在深度學習發展早期,He 等[8]為了減少網絡模型的計算量和參數量以加快神經網絡的訓練,在ResNet 算法中提出了深度瓶頸結構(Deeper Bottleneck Architecture,DBA),如圖1(a)所示。DBA 是殘差結構的變形,其利用1×1 卷積降低輸入特征圖的通道數,之后的3×3 卷積部分會由于維度下降使需要計算的參數量降低,縮短了訓練時間,在提取特征后再利用1×1 卷積恢復輸出特征圖的通道數,殘差連接也被采用以允許之前的網絡層保留一定比例輸出的結構。Romera等[14]提出一維非瓶頸(Non-bottleneck-1D)結構,如圖1(b)所示,其本質是將3×3卷積分解為3×1卷積和1×3卷積級聯的卷積分解方法,可以在降低參數量、加快網絡訓練的同時不影響感受野的變化。

圖1 深度瓶頸結構與一維非瓶頸結構Fig.1 Deeper bottleneck structure and non-bottleneck-1D structure
本文結合DBA 模塊中的瓶頸結構和分解卷積,提出SPM特征提取單元,如圖2所示,N表示特征圖通道數,D表示深度可分離卷積(Depthwise Separable Convolution),R表示擴張卷積的擴張率(Dilation Rate),其中,不同分支擴張卷積的擴張率R1、R2、R3 設置采用依次增大的參數序列,并行進行特征提取,不同參數序列設置方法的有效性將在實驗部分詳細論證。每個SPM 單元首先將輸入特征圖的通道數減為原來的1/2,通過最后的逐點卷積恢復通道數量。考慮到盡管1×1 卷積的參數少于3×3 卷積,但ResNet 的目的是建立一個足夠深的網絡模型(100 層以上)以擴大感受野并捕捉更多更復雜的高級語義信息,然而層數的增加通常伴隨著更多的運行時間和極高的內存需求。為了構建輕量的、快速的語義分割網絡模型,同時保證分割準確率,本文改用3×3卷積縮減通道數至輸入的一半,提取更多圖像全局特征。為了在較淺的網絡中獲取足夠的多尺度信息,本文采用分支結構構造SPM 單元,每個分支的卷積形式更改為深度可分離卷積[14]以進一步減少參數量提高算法效率。
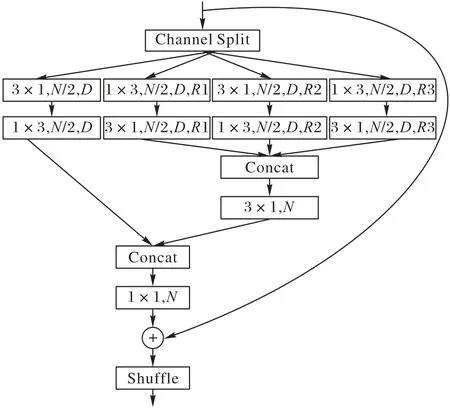
圖2 所提出的SPM特征提取單元Fig.2 The proposed SPM feature extraction unit
本文在第一個分支中使用分解的3×3 深度卷積,即級聯的3×1 卷積和1×3 卷積,在保持同樣大小感受野的前提下有效降低計算參數量,以H×W的同分辨率輸入輸出特征圖為例,當卷積核尺寸為k、輸入通道數為m時,應用深度分解卷積后的參數量與深度可分離卷積的參數量之比為:
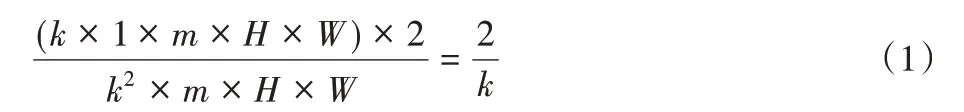
當卷積核大小為3×3 時,深度分解卷積的參數量相較于深度可分離卷積減少了33%;對其他3 個分支采用擴張卷積,在不降低特征圖像分辨率的同時擴大特征提取的感受野,其構造方式同樣為深度分解卷積。不同擴張率的擴張卷積建立了一個特征金字塔,具有較大擴張率的卷積核能夠提取復雜或具有空間信息的長跨度特征,其需要較多的圖像參數,而具有較小擴張率的卷積核可以處理簡單或包含小尺度信息的短跨度特征,其需要的參數較少,可分離的特征金字塔結構能夠有效提取多尺度特征和上下文信息。與DeepLab 系列的ASPP相比,本文提出的特征金字塔單元參數量和計算量都大幅度減少。特征金字塔輸出的特征圖像在合并之后經過逐點卷積使通道數量減為最初輸入特征圖的一半,并再與第一個分支融合,融合后的特征圖通過逐點卷積加強通道交互,增強輸出非線性。由于殘差連接的存在,SPM 單元輸出最終特征圖前需要再次經過通道隨機混合操作提升特征通道之間的信息交互。
SPM 單元的構建本質目的是能夠在較淺的特征層級上獲取足夠豐富的語義信息用于像素預測。與ResNet 等復雜的、深的(100 層以上)網絡相比,SPM 單元能夠在只具有較少層數的輕量網絡中發揮強大的特征提取能力,在盡可能保證語義分割準確率的同時優化算法的實時性表現。
2.2 上下文通道注意力模塊
對于圖像語義分割任務,深層高級語義信息和淺層空間位置信息的融合十分重要,但是由于深層的特征圖中包含著高度抽象的語義信息,而淺層特征更多的是點、線、邊緣等存在大量噪聲的信息,簡單地將深淺層信息合并所生成的分割效果實際上并不理想。本文認為深層特征中的語義信息能夠通過通道注意力在不帶來過多額外參數的情況下引導低級特征,利用深層語義修改淺層特征的通道權重,彌補淺層信息缺少的高級語義,修改后的淺層特征圖再與深層特征圖融合能夠帶來更好地分割效果,因此本文提出上下文通道注意力(Context Channel Attention,CCA)模塊,其結構如圖3所示。

圖3 CCA模塊Fig.3 CCA module
對于維度為A∈RC×H×W的深層特征圖,首先通過reshape 矩陣維度變換操作將圖像變成RC×N(N=H×W),其與自身的轉置進行乘積運算,通過softmax 計算得到通道注意力映射結果X∈RC×C。由于矩陣相乘的內部實質是通道對應的特征向量與其他所有通道的特征向量的乘積,因此通道之間的聯系通過點積相似度成功建模,其公式表述為:

其中:xji表示第i個通道對第j個通道的影響;Ai∈RC×N;Aj為Ai的轉置,Aj∈RN×C。隨后,為了獲取全局依賴關系的特征,將通道特征圖的轉置與經過reshape 操作降維的淺層特征圖Bi∈RC×N作矩陣乘法,在乘以尺度系數?后再次reshape 升維變成與輸入同維度的結果RC×H×W,即淺層特征圖在深層指導下的通道權重修改結果。本文提出的網絡所有卷積層輸出的最大通道數為128,因此不需要參考擠壓和激勵網絡(Squeeze-and-Excitation Network,SENet)[15]等縮減通道數(例如512、1 024)以減少計算參數的設計。淺層特征圖通道之間的注意力加權后生成全局關聯,與輸入深層特征圖像合并得到更強的語義響應特征輸出E∈RC×H×W:

其中:由于注意力機制在最初訓練時表現并不理想,?初始設置為0,在訓練過程中通過學習得到更大的權重,使CCA 模塊發揮作用。CCA模塊對深層特征圖每個通道的特征權重進行計算,利用所有通道之間的相互聯系,加權至淺層特征,最終得到通道權重修改后的淺層特征,提高了淺層通道依賴性。指導后的淺層特征與深層特征合并能更好地在融入空間信息的同時維護編碼部分的預測分類,提升最終的圖像分割效果。
2.3 整體網絡模型
為了更好地在準確度和實時性表現之間取得平衡,本文僅在所提出的網絡模型中采用三次下采樣操作,最深層獲取1/8初始分辨率的特征圖,整體網絡結構如圖4所示。
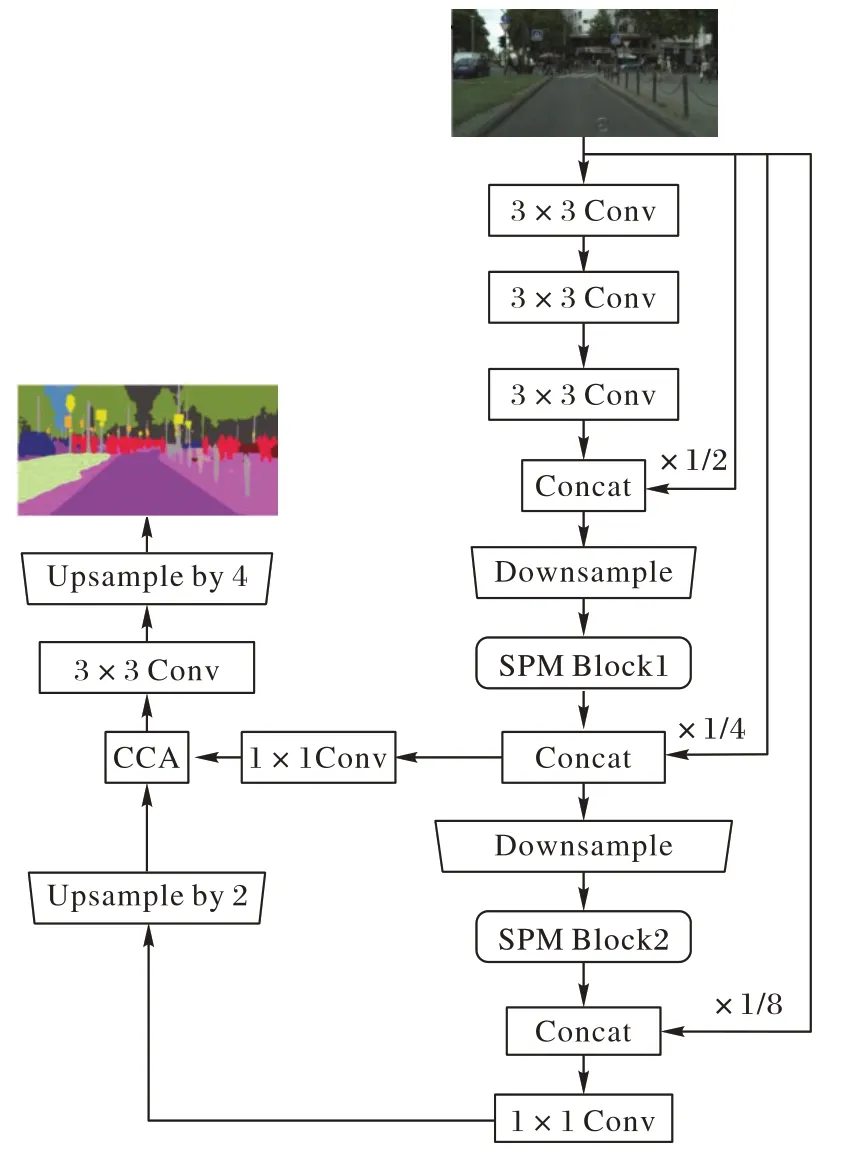
圖4 本文所提算法的網絡模型Fig.4 Network model of the proposed algorithm
本文首先利用3 個連續的3×3 卷積提取輸入圖像初始特征,其中第1個3×3卷積步長為2,第2、3個3×3卷積步長為1,隨后緊跟一個以步長為2 的3×3 卷積和2×2 最大池化級聯的下采樣層,這之后的下采樣層是一個步長為2的3×3卷積。考慮到淺層特征圖中包含的語義信息不豐富且分辨率較高,添加SPM 單元的好處不足以補償參數和計算量增加帶來的損失,因此本文不考慮在1/2 分辨率的特征圖上應用SPM 單元。在隨后兩次下采樣操作之后,將分辨率為初始輸入圖像分辨率1/4 和1/8 的特征圖分別輸入到本文設計的SPM Block 1 和SPM Block 2中提取密集特征。
在SPM Block 1 中,本文首先對SPM 單元進行一些簡化。SPM單元在1/4原始分辨率的特征圖上進行采樣時,由于特征圖尺寸較大、待處理的特征點過多,其特征金字塔的結構會產生大量的運算,這一情況對于追求實時性的算法網絡而言是應當避免的。因此,在SPM Block 1 中采用的SPM 單元,其四分支結構被縮減為兩分支,去除了特征金字塔,僅保留一個分支的擴張卷積。簡化后的SPM單元稱為SPM-s,如圖5所示。
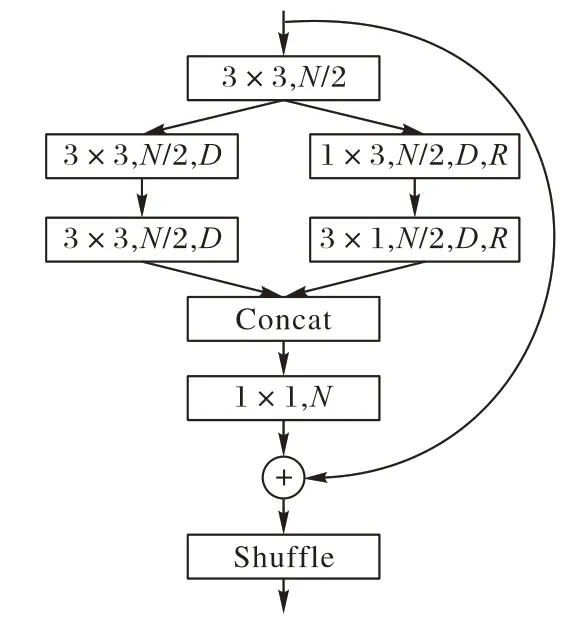
圖5 簡化的SPM-s單元Fig.5 Simplified SPM-s unit
SPM-s 單元能夠以較少的參數量和計算量獲取特征信息,其被用于網絡較淺層時更關注特征圖中的邊緣和細節信息。本文在SPM Block 1 中插入3 個連續的SPM-s 單元,由于SPM Block 2 能夠以不同的特征感受野對輸入特征圖進行多尺度信息處理,因此在SPM Block 1 所處的1/4 原始分辨率特征圖上只需要完成相對初步的特征提取,所有SPM-s 單元的擴張卷積分支擴張率都設置為2。為了加強空間聯系和特征聚合,第1 個和最后1 個單元之間加入了殘差連接,如圖6(a)所示。相似的,在SPM Block 2 中,本文設置了級聯的SPM 單元對1/8原始輸入圖像分辨率的特征圖進行特征提取,結構展示在圖6(b)。
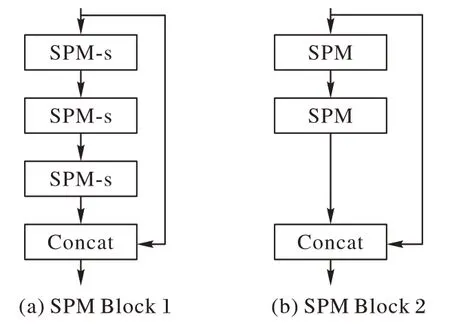
圖6 SPM Block 1和SPM Block 2Fig.6 SPM Block 1 and SPM Block 2
本文在下采樣階段加入了長殘差連接,補償分辨率降低造成的信息損失。為了追求更強的網絡實時性,避免額外參數和計算導致訓練速度降低,本文在上采樣階段參考DeepLabv3+[9]的解碼思想,保留了SPM Block 1 的輸出特征圖,在分辨率恢復的過程中作為淺層信息引入CCA 模塊并與兩倍雙線性插值上采樣的最深層特征圖融合,經過3×3 卷積調整通道數和第2 次上采樣后得到最終的圖像分割結果。整體網絡結構的參數細節展示在表1中。
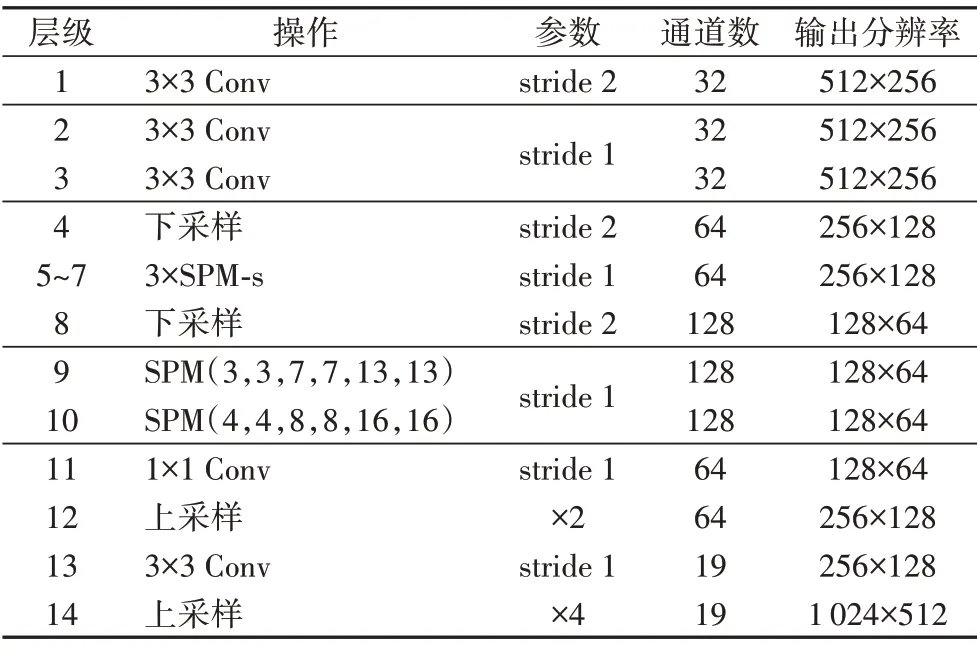
表1 基于SPM單元的整體網絡的詳細結構Tab.1 Detailed structure of entire network based on SPM unit
3 實驗結果及分析
3.1 實驗環境和參數設置
本文實驗的硬件平臺是Intel i7-9700K CPU,軟件環境是Ubuntu16.04系統,利用單張GeForce GTX 1080Ti GPU 顯卡完成網絡模型的訓練和測試,編程語言使用Python3.6,深度學習框架使用PyTorch 1.0,運算平臺使用CUDA 9.0。
在數據集的選擇上,本文以Cityscapes數據集[16]為主進行消融實驗,評價所提算法的有效性。Cityscapes 數據集由包括戴姆勒股份公司在內的三家德國單位聯合提供,包含來自50個城市的5 000張城市駕駛場景的高質量像素級注釋圖像,其中分為2 975 張訓練集圖像、500 張驗證集圖像、1 525 張測試集圖像。該數據集一共有19 個目標類別,包括人、地面、車輛、建筑等,有1 024×2 048 的高分辨率,同一張圖像中多類別、多目標和同一類物體互相遮擋的情況,對于圖像語義分割任務而言都是嚴峻的挑戰。為了便于訓練和對比,本文將原始圖像下采樣至512×1 024的分辨率用于算法實驗。
在Cityscapes數據集的訓練過程中,本文采用帶動量的隨機梯度下降法(Stochastic Gradient Descent,SGD)用于模型訓練,并使用poly學習策略,其公式為:

其中:lrbase為初始學習率,為了能夠在保證模型學習有效性的同時加快收斂,提高模型運算效率[7],本文將初始學習率在訓練中設定為0.045;iter為當前迭代次數;total_iter為最大迭代次數;power采用默認值0.9。由于本文提出的整體網絡并未使用任何預訓練模型,因此訓練中最大迭代次數設定為370 000,每次迭代的樣本數量為8。實驗中采用了隨機翻轉、均值消減和隨機尺度縮放的數據增強方法提升算法的泛化性,在全局實驗上,除了在Cityscapes數據集上測試算法性能,在CamVid 數據集[17]上同樣也進行了實驗,并與其他算法作對比。
本文的準確度評價采用語義分割的標準度量平均交并比(mean Intersection over Union,mIoU),給出所有類別預測結果和真實值兩個集合交集與并集的比值的平均,計算如下:

其中pij表示真實值為i、被預測為j的像素數量。
算法效率用運算時間和速度(單位:幀每秒(Frames Per Second,FPS))來衡量,其中:運算時間是指網絡完成單張圖像分割所需時間,FPS 表示網絡每秒完成語義分割的圖像數量。
3.2 消融實驗結果對比
本文提出的SPM 單元在降低網絡參數和運算量的基礎上,采取了多尺度感受野提取特征的方法,對SPM 結構中的多分支深度可分離擴張卷積設定依次增大的擴張率。
表2展示了SPM Block 2的SPM單元設計。

表2 SPM Block 2不同參數設定的對比Tab.2 Comparison of different parameter settings of SPM Block 2
方法1 為僅使用一個SPM 單元進行1/8 分辨率圖像輸入的特征提取,其參數為{4,4,8,8,16,16}(每單個擴張卷積分支被分解為兩個一維的卷積以降低計算量,因此有兩個擴張率為4的擴張卷積,以此類推)。
方法2 在方法1 的基礎上設計了兩個連續的SPM 單元,其參數相同,且加入了短殘差連接。與方法1 相比,方法2 雖然因為參數的增加使得網絡實時性略有下降,但在準確率上提升了2.52個百分點。
方法3 同樣采用兩個SPM 單元,但與方法2 的參數設定不同,兩個SPM 單元的其中一個依然采用{4,4,8,8,16,16}的增長序列,另一參數序列考慮到相同或等比的擴張率可能因“棋盤效應”導致采樣時丟失大量信息,而互質的、鋸齒波形的擴張率在不改變任何參數量的情況下,覆蓋的感受野在疊加時能夠提取更多不同的細節信息,且提取到的特征更具有泛化性,卷積的表征能力更強[18],因此選擇了互質的{3,3,7,7,13,13}參數序列。綜合方法2和方法3的實驗結果可見,采取等比和互質參數序列相結合的設計方法更有利于提高圖像分割精度,在參數量相等、實時性不變的情況下,方法3 相比方法2在準確率上提升了0.46個百分點。
方法4中,本文嘗試選擇兩組參數互質的SPM 單元,但相比方法2 準確率反而下降了,這可能是由于在該層特征圖尺寸相對較大,擴張率減小后失去了較大的感受野,對于特征提取不利。
方法5 考慮級聯連續3 個SPM 單元,結果顯示mIoU 略微上升,但是與方法3 相比在速度方面下降了24 FPS。綜上所述,方法3帶來的準確度與速度的平衡效果最好。
CCA 模塊有助于改善深淺層信息的融合效果,本文將CCA模塊加入到SPMNet上采樣部分訓練并測試模型的性能變化。為了便于對比,本文選取了高效殘差分解卷積網絡(Efficient Residual Factorized ConvNet,ERFNet)和高效多尺度上下文聚合和特征空間超分辨率實時語義分割網絡(real-time semantic segmentation Network by efficient multi-scale context aggregation and Feature Space Super-resolution,FarSeeNet)[19]的解碼方法,對SPMNet的最深層輸出特征圖進行解碼,實驗結果如表3所示。
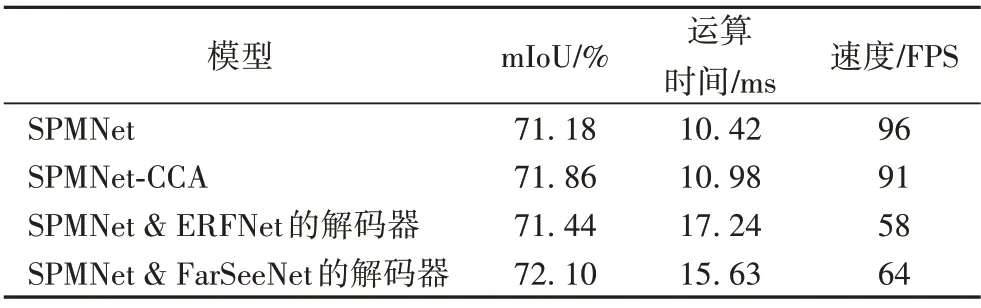
表3 不同解碼設計對于SPMNet性能影響的對比Tab.3 Comparison of the impacts of different decoding designs on SPMNet performance
ERFNet的核心操作是殘差連接和分解卷積,其解碼部分采用步長為2 的轉置卷積進行依次、有序的分辨率恢復;FarSeeNet 是由商湯科技和東京大學共同提出的用于實時語義分割網絡的算法,其構建了一個稱為級聯分解空洞空間金字塔池化(Cascaded Factorized Atrous Spatial Pyramid Pooling,CF-ASPP)的解碼模塊,該模塊以任意成熟的網絡模型(如FCN、ResNet 等)特征提取后輸出的低分辨率圖像作為輸入,利用級聯的分解式ASPP 給出預測結果。從表3 中可以看到,相較于簡單解碼設計的SPMNet,加入ERFNet 和FarSeeNet 解碼器的SPMNet在準確率上分別有0.26和0.92個百分點的提升,但是模型的處理速度卻下降到58 FPS 和64 FPS。相比而言,加入CCA 模塊后SPMNet-CCA 的準確率提升到71.86%,而實時性僅下降了5 FPS。SPMNet網絡所有特征層的最大通道數僅有128,通道的加權計算并不會引入很多的參數和計算量,因此CCA模塊對于網絡的實時性影響是十分微小的。
圖7 展示了加入CCA 模塊前后的算法分割圖對比情況。每一行分別為Cityscapes驗證集中的原始圖像、人工精細標注的標簽圖像、SPMNet的分割結果和使用了CCA模塊用于上采樣的SPMNet-CCA 的分割結果。圖中用黑色邊框標注了分割前后Cityscapes 數據集中差距較大的部分,例如,從圖7(a)中每張圖像左上角對于交通標志(traffic sign)類別像素的預測結果可以發現,使用CCA 模塊的SPMNet 分割圖像的邊緣明顯更為精細;圖7(c)原始圖像包含人(person)和摩托車(motorcycle)相互遮擋的場景,SPMNet 的分割結果中出現了摩托車的像素部分被錯誤地分類為人(person)的情況,而圖7(d)中SPMNet-CCA 的分割較好地將道路占據的像素區分開來,帶來了更好的可視化效果。此外,對于其他類別如道路(road)、汽車(car)、樹(tree)等,利用深層語義對淺層特征圖通道權重進行修改的注意力機制對于圖像目標邊緣的恢復效果同樣有顯著作用。

圖7 加入CCA模塊前后的SPMNet分割可視化效果Fig.7 Visualization effect of SPMNet segmentation before and after adding CCA module
綜上所述,本文所提出的基于SPM 單元的輕量級網絡模型和上下文通道注意力模塊CCA是十分有效的。
3.3 全局實驗
為了進一步驗證本文提出的輕量級圖像實時語義分割算法的有效性和泛化性,在輸入圖像尺寸、準確度和速度方面將SPMNet 和加入CCA 模塊后的模型與其他現有語義分割算法進行比較,包括深度卷積網絡(DeepLab)、用于圖像分割的深度卷積編解碼器架構(deep convolutional encoder-decoder architecture for image Segmentation,SegNet)、高效殘差分解卷積網絡(Efficient Residual Factorized ConvNet,ERFNet)、雙邊分割網絡(Bilateral segmentation Network,BiseNet)[20]、高效多尺度上下文聚合和特征空間超分辨率實時語義分割網絡(FarSeeNet)、深度特征聚合網絡(Deep Feature Aggregation Network,DFANet)[21]、非局部高效實時算法(Light-weighted Network with efficient Reduced non-local operation for real-time semantic segmentation,LRNNet)、圖像級聯網絡(Image Cascade Network,ICNet)[22]。BiseNet 通過對細節特征和語義特征進行拼接整合全局語義信息,DFANet利用特征聚合的方式進一步細化特征,ICNet利用低分辨率圖的語義信息和高分辨率圖的細節信息進行像素分類。這些都是目前十分優秀的實時語義分割算法。實驗在Cityscapes 數據集和CamVid數據集上進行,對比結果展示在表4 和表5 中,“—”表示該數據并未在論文中提供或未由開源模型得到。
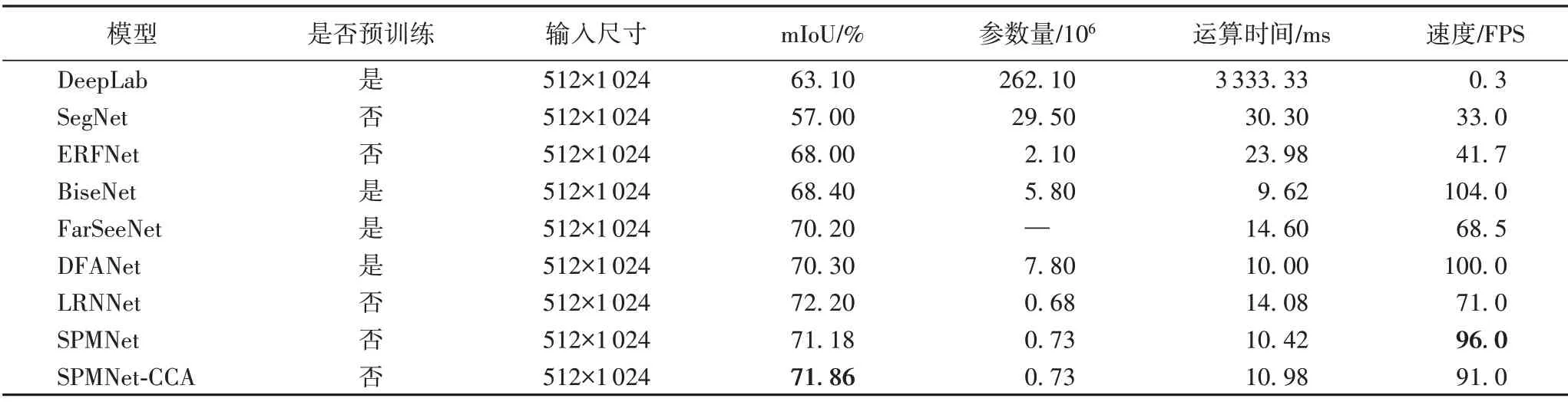
表4 SPMNet與其他語義分割算法在Cityscapes測試集上的性能對比Tab.4 Performance comparison of SPMNet and other semantic segmentation algorithms on Cityscapes test set

表5 SPMNet與其他語義分割算法在CamVid測試集上的性能對比Tab.5 Performance comparison of SPMNet and other semantic segmentation algorithms on CamVid test set
本文的SPMNet 在Cityscapes 精細標注的測試集上以96 FPS 的速度達到了71.18%mIoU 的準確度,而插入CCA 模塊后的速度和準確度分別為91 FPS和71.86%,展現了更好的平衡效果。與ERFNet 相比,SPMNet-CCA 的分割準確率提高了3.86個百分點,處理速度是其2.2倍;與BiseNet相比,速度比其慢13 FPS,但準確度比其高3.46 個百分點;與最新的實時語義分割算法LRNNet 相比,SPMNet-CCA 的準確度略低0.34 個百分點,但處理速度上升了20 FPS。本文算法沒有使用任何預訓練模型,同分辨率輸入下,SPMNet-CCA 的速度和準確度相較于其他算法有著更好的平衡性。在CamVid 測試集上,本文算法同樣取得了較好的結果。
圖8 展示了本文SPMNet-CCA 模型與ERFNet 在Cityscapes驗證集上的分割可視化效果對比。

圖8 SPMNet-CCA與ERFNet的分割可視化效果對比Fig.8 Comparison of segmentation visualization effects between SPMNet-CCA and ERFNet
總的來說,經過全局實驗的對比分析可知,本文提出的SPM單元和SPMNet網絡模型,以及基于通道注意力的CCA模塊,對于實現輕量的圖像實時語義分割都是十分有效的方法,能夠在提升分割效率的同時仍然保證圖像分割的準確度。
4 結語
本文對語義分割算法的準確度和實時性表現進行深入分析,提出了一種基于可分離金字塔特征提取單元的圖像實時語義分割算法,在保證圖像分割準確度的同時兼顧算法模型的輕量性和實時性,上下文通道注意力模塊用于引導淺層特征與深層高級語義信息融合,進一步優化分割效果。實驗證明,本文算法的精度和速度平衡表現優于其他對比算法,所構建的特征提取模塊、注意力方法以及輕量級網絡模型對于其他研究者具有參考意義。由于本文算法僅基于兩種數據集進行深入測試,對于特定的目標類別缺乏針對性,在后續研究中,會考慮結合具體圖像分割目標進行網絡設計,進一步提升模型的實用性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
