基于多時期蒸餾網絡的隨訪數據知識提取方法
2021-11-05 01:29:18魏淳武趙涓涓唐笑先
計算機應用 2021年10期
魏淳武,趙涓涓*,唐笑先,強 彥
(1.太原理工大學信息與計算機學院,山西晉中 030600;2.山西省人民醫院影像科,太原 030012)
0 引言
由于低劑量計算機斷層掃描(Computed Tomography,CT)的出現和應用以及肺癌高風險人群對于大量隨訪篩查CT 工作的需求,基于低劑量CT的肺部基線以及隨訪篩查相比過去更加重要。盡管研究者Alberle等[1]通過實驗和統計證明低劑量CT對于降低肺癌致死率的作用,但大量的篩查工作仍然會增加那些無法確認的低風險病人的致死率,同時會帶來不必要的醫療負擔。近期在《柳葉刀》和Nature子刊上發表的關于基于低劑量CT的隨訪篩查研究表明,使用深度學習方法進行肺癌風險預測可以有效減少這種不必要的篩查工作。此外,國際醫學圖像頂級會議(Medical Image Computing and Computer Assisted Intervention,MICCAI)也在2019 年的總結展望中指出,利用隨訪數據和深度學習方法挖掘出更多信息的工作是目前醫學圖像研究的一大重點。
基于以上兩點可以看出,合理利用隨訪數據進行分類預測的工作具有重要意義,但是,目前有關肺結節的公開數據集中,僅有美國國家肺部篩查實驗(National Lung Screening Trial,NLST)作為公開數據提供包括3 年的隨訪信息的低劑量CT數據,同時也有相關研究者在此數據的基礎上做肺癌預測工作。文獻[2]中研究者聯合了三家機構(約翰霍普金斯大學、英國哥倫比亞癌癥研究機構、美國國家癌癥研究機構)分別以雙盲方式進行了數據再標注和模型驗證,證明了利用長時期的數據可以有效預測基線年下肺結節的變化。類似的,Google 研究者[3]借助至少6個放射學專家對NLST的數據進行了再標注和驗證。盡管兩者已經能夠在NLST 使用深度學習模型實現較高的良惡性概率預測水平,但是對于普通研究者來說,花費如此多的資源進行精確的數據標注是非常困難且幾乎無法實現的。實際上,無論是通用圖像還是醫學圖像,大部分研究也都存在樣本標準困難導致數據不足的問題,標注良好的數據可以在穩定的模型中展現出優越的效果,但是往往實際求解過程中遇到的都是數據信息不完整、標注缺失等類似的問題。
對于解決這類問題,在通用圖像下,目前的大多研究工作可以分為兩大類:對于有標記的數據量少且存在大量無標記數據的場景,研究者往往會結合一些小樣本學習方法解決問題。Sung 等[4]提出一種基于關系的小樣本學習,該方法在幾個基準(Baseline)數據集上取得了不錯的效果;Snell 等[5]提出基于原型網絡的小樣本學習,該方法有效提升了同類樣本的分布差異計算能力,但是并未考慮區分異類樣本的分布邊界問題;Santoro 等[6]則提出基于模型的小樣本學習,將計算機原理和深度學習進行了結合。上述方法均為小樣本學習的經典理論方法,后續也有研究基于其思路不斷擴展,但是此類方法僅從樣本多樣性較為單一的角度進行設計,并不適用于樣本多樣性較復雜的醫學圖像問題。對于兩種有標記數據一類數據量小、另一類數據量大的場景,則有改進的元學習方法[7]、遷移學習[8]、領域自適應[9]為代表的一些方向。對于醫學圖像尤其肺結節分類這一領域,出現最多的研究工作基于第一類場景,因為醫學圖像數據的采樣過程并不困難,但是進行合理的標注則需要放射學家參與且耗費資源很大。所以存在大量未標注的數據和少量已標注的數據,Wang 等[10]基于NLST 數據提出了一種半監督的三維模型且取得了不錯的效果,由于NLST 并非三維數據,其僅將其作為未標注的數據集使用,實際上使用的已標注數據來源于私人數據集,并且沒有利用到相關隨訪信息。而本文研究的實際問題從隨訪信息出發:首先,長時期數據本身具有一定特征,以NLST為例,它由三年數據組成,但是基線年的數據與第2、3 年也有所不同,相較于基線年,隨訪兩年的數據存在很大的不平衡。其次,不同年份間序列對應的切片可能因為外在因素沒有掃描到應該有的結節信息(如圖1),這類數據無法作為樣本使用。類似的信息導致本文研究收集到的838 例隨訪三年的數據中僅有399 例可以作為有效數據集。同時,就NLST本身而言并沒有獨立同分布的其他大量標記過的相關數據集輔助訓練。

圖1 隨訪年無效數據示例Fig.1 Example of invalid data in follow-up year
此外,目前的研究中大多使用隨訪數據輔助分類預測任務,但是這些研究并沒有充分利用到隨訪指南中的領域知識。在長時期數據中,隨訪指南具有重要作用,醫學領域方面,Pinsky 等[11]首次提出基于肺成像報告數據系統(Lung imaging Reporting And Data system,Lung-RADs)指導下隨訪的效果優于一般分期標準,Martin 等[12]認為Lung-RADs 解決了以往隨訪過程中隨訪指導信息結構不完整導致醫生漏診、錯診的問題,楊健等[13]則詳細說明了Lung-RADs系統的價值,同時解讀了它所具備的一些領域知識。Veasey等[14]在Lung-RADs分級系統下結合NLST數據集實現了肺結節良惡性任務,但是并沒有考慮隨訪時間等在實現對長時期數據分類時應注意的領域知識(如對隨訪少于2 年且CT 中實性結節的判斷如果隨訪2年后無顯著變化可以將類別歸為良性結節,具體問題模型以及相關領域知識如圖2所示)。

圖2 隨訪知識示意圖Fig.2 Schematic diagram of follow-up knowledge
基于上述問題,本文在缺少一定隨訪數據標注信息的情況下,提出了一種基于知識蒸餾技術的遷移學習方法,并將其應用于多時期下少量樣本的結節分類訓練。本文具體工作如下:
1)首先,和傳統的肺結節分類與長時期良惡性預測不同,本文提出了一種從多時期數據中提取知識的方法用于引導模型訓練,通過引入領域自適應參數改善最終的網絡損失,并在網絡輸出前利用領域信息微調最終網絡參數使網絡能夠有效學習到隨訪信息的領域知識。
2)本文從數據規模小、基線數據與隨訪數據存在不平衡的問題出發,提出了一種用于肺結節隨訪數據增強的基于元學習思想的多時期數據訓練方法。該方法可以有效改善肺部CT隨訪數據量不足的問題。
1 相關工作
1.1 長時期肺結節良惡性預測
長時期肺結節預測工作來源于肺癌病人的實際篩查流程。病人進行了基線篩查后,原本醫生會根據CT情況指導病人的隨訪篩查工作,后續研究者發現利用深度學習方法可以預測到隨訪篩查的結果,從而避免了一些不必要的隨訪篩查工作,降低了醫療負擔。早期的長時期肺結節檢測研究大多基于私有數據集,且沒有公開有效的實驗評估標準,條件上的困難阻礙了大部分研究者的工作,但由于隨訪篩查的必要性,對此的研究卻從未停止。
在2019 年Huang 等[2]于的Lancet上提出了一種深度學習方法用于對至少有兩年隨訪數據下肺癌的良惡性概率預測,該研究基于NLST 以及Pan Can(Pan-Canadian Early Detection of Lung Cancer)兩大公共數據。實驗的分類標準基于Lung-RADs,該研究表明了基于目前的一些公開數據信息,利用兩年隨訪數據可以有效完成肺結節良惡性預測。與Huang 等[2]的工作相同,Ardila等[3]則提出了一種端到端的三維肺結節良惡性預測模型,同時在NLST 上的表現要優于6 個放射學家,達到了96%的預測精度。當前研究者們對于長時期肺結節良惡性的預測工作大多在于如何利用特征融合方法[15]、三維技術[16]、循環神經網絡[17]或者其他方法去改進預測效果。本文工作參考了這些研究的問題模型與求解問題的思路,并且提出了基于當前研究方向的一個新的任務:如何在基線數據與隨訪數據不平衡的情況下提升訓練效果。
1.2 知識引導醫學圖像分類
分類任務一直以來作為肺部相關乃至整個醫學圖像研究者的基本問題。隨著深度學習技術的不斷發展,研究者不斷利用傳統醫學圖像處理方法與深度學習方法結合的方式來提高病灶分類精度或者解決更細粒度的分類問題。通常情況下,一些根據專家既定的經驗手工提取的特征在深度模型中又叫作知識,研究者利用這種知識來引導深度模型的訓練往往能取得不錯的效果。Xie等[18]提出了基于知識的協同模型,從多視圖的角度出發,分別結合深度模型表征了肺結節的整體外觀、體素屬性、異質性,最終以9種視圖訓練出9個子模型有效降低了肺結節分類假陽性概率。在2018 年,Xie 等[19]提出了在決策層融合紋理、形狀、深度特征的模型,在LIDC數據集上實現高效肺結節分類。本文研究參考了以上研究對于知識引導模型學習更深層特征表示的方法,同時也提出了一種知識引導模型訓練的方法,不同之處在于之前的研究大多局限于圖像本身所帶來的特征與信息,而忽略了診斷過程中圖像外的一些信息(如隨訪過程中,醫生對于隨訪數據所提出的一些經驗性思路)。基于這一點,本文模型充分考慮到了隨訪信息作為知識來輔助訓練與隨訪相關的低劑量CT 數據以獲得性能上的提升。
1.3 知識蒸餾網絡研究
知識蒸餾的概念最初由Hinton 等[20]于2015 年提出,它是一種從網絡參數較多的教師網絡提取暗知識到參數較少的學生網絡的方法,并被應用于模型壓縮的任務場景。從2015 年至今,不斷有研究者對知識蒸餾進行方法上的改進,Romero等[21]從Hint-based training 的角度先提取教師網絡的知識,利用hint-based損失進行監督訓練,誘導學生網絡學習到與教師相似的表達,該方法將原本蒸餾過程中直接學習教師網絡輸出結果的思想轉變為學習中間層的特征。這一思想后來在知識蒸餾領域也被稱為從中間層提取知識。到2017 年,Yim等[22]拓展了這一思想,指出利用從中間層提取知識的方法,不僅可以完成網絡壓縮的任務,甚至可以將中間知識作為遷移學習方法來實現更多場景下的任務,而Zagoruyko 等[23]則實現了注意力機制和知識蒸餾的結合并應用于模型遷移。后續研究中,知識蒸餾用于模型遷移的思想得到了更多應用與改進,Chen 等[24]利用知識蒸餾方法實現了圖像像素級的域遷移,Gupta等[25]首次提出了交叉模態數據進行知識蒸餾的思想,該思想擴展了知識蒸餾在模型遷移方向的應用范圍。Zhao等[26]參考MetaDistiller[27]和MetaReg 方法[28]提出了一種交叉模態知識蒸餾的應用方法,具體將元學習和知識蒸餾方法進行結合并用于將一種模態的知識遷移到另一種模態當中,該方法有效解決了多模態數據中某一模態下數據量不足的問題。受此研究的啟發,本文將不同模態的數據下信息遷移的問題轉變為長時期醫學數據下基線數據與隨訪數據的信息遷移,同樣彌補了隨訪數據信息不足對肺結節分類判斷的影響。
2 長時期知識蒸餾網絡
2.1 多時期數據知識蒸餾網絡
假設輸入圖像數據x為基線數據,對應之后第1 年和第2年的隨訪數據為。訓練過程中,每個分支的網絡分別對應一種數據,基線類數據的標簽信息為y,該標簽主要參考基線的分類標注標準得到,而隨訪第1年和第2年的標簽則會參考到前一年或者前兩年的標注分別記為。基于最終得到的基線年數據(x,y)訓練出教師網絡模型f,對應圖3 的第1個分支結構,其中將教師網絡參數表示為ω,訓練教師網絡過程使用損失函數為七分類問題的交叉熵損失表示為LT。訓練得到教師網絡后,本文進一步構建了知識蒸餾網絡(網絡結構如圖3,Group 結構如圖4),并通過該網絡從教師網絡中提取中間特征到學生網絡。此處教師網絡和學生網絡分別代表基線年下數據訓練得到的肺結節分類模型與利用隨訪年下數據和教師網絡監督訓練得到的帶隨訪知識的肺結節分類模型。

圖3 多時期知識蒸餾網絡結構Fig.3 Structure of multi-term knowledge distillation network
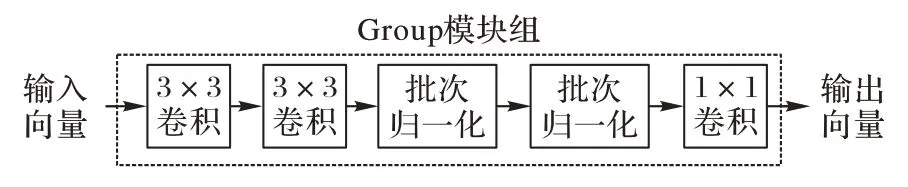
圖4 Group塊結構Fig.4 Structure of Group block
其中,教師網絡的知識主要指來自基線數據的結節信息。用以增強性指導學生網絡中隨訪數據標簽訓練。本文的知識蒸餾網絡同時提取了教師網絡中間層和輸出層的激活信息作為引導對象,假設網絡總層數均為d層,其中第j層的激活圖表示為Aj,則輸出層用于引導知識蒸餾網絡訓練的損失為式(1):
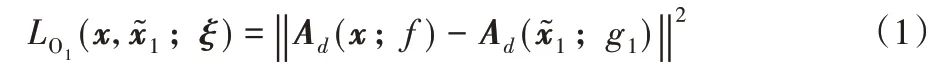
其中:學生網絡g1的網絡參數表示為ξ,對應隨訪第1 年數據訓練得到的模型。引入該損失的目的是通過教師模型輸出結果的概率值差異引導學生模型的訓練,但是實際訓練時,由于不同年份間的數據本身存在的誤差與標簽的不統一,無法僅通過輸出層約束學生網絡收斂得到有效模型,所以本文引入基于Group 塊的注意力損失項,該部分的工作受到文獻[23]工作的啟發,具體損失定義如式(2):

不同于LO,LI的作用更偏向于讓學生網絡學習教師網絡樣本本身的像素級的差異,這樣更有利于模型學習從外形、輪廓到結節宏觀大小等變化。
同時,因為輸入數據結節的圖像特征可能存在較大的變化,導致兩年的結節信息在圖像層完全不同。這會使得教師網絡模型對標簽的引導與隨訪數據的引導產生較大分歧,所以本文引入約束因子來降低這種情況對損失的影響,具體模型增加了中間層的激活信息作為損失項,并且在設計三年數據蒸餾損失的時候考慮到了隨訪第1 年數據對隨訪第2 年數據在模型學習時的引導作用要大于基線年對隨訪第2 年的作用。故本文引入平衡系數λ來控制兩者對蒸餾損失的影響。對應于輸出層和中間層的蒸餾損失項改進為式(3)、(4):
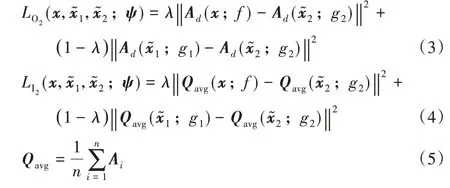
其中:Qavg為當前網絡每個Group 塊的激活圖的均值,學生網絡g2的網絡參數為ψ,對應隨訪第2 年數據訓練得到的模型。最終的蒸餾損失函數如下:

其中:μ用于平衡兩損失間的量級,在實驗過程中最終將其賦值為1E-3。
則多時期蒸餾網絡的目標函數可以定義為式(7):

2.2 Group結構塊
對于Group 的實現,本文工作基本上沿用文獻[23]的思想,不同點在于本文使用的Group 塊的數量以及卷積核的參數與其不同,文獻[23]中網絡輸入數據的大小為32×32,而本文模型的數據輸入為64×64,所以整體網絡結構有所調整且網絡卷積層的padding 均設置為1。具體每個Group 塊的具體結構與ResNet的殘差塊結構相對應。
2.3 不平衡數據知識遷移
本文提出的多時期蒸餾網絡可以在基線數據與隨訪數據配對的情況下,通過遷移知識輔助訓練。但是實際情況下,長時期的配對數據量非常少,實驗數據大多為不平衡狀態的數據,即隨訪數據量相對基線數據較少。在這種情況下,如果直接使用網絡進行訓練,那么利用僅有的配對數據訓練的模型極易造成過擬合問題,網絡也無法利用到非配對的數據。因此,本文在原有模型基礎上提出了一種針對數據不平衡問題的解決方法。
首先在2.1 節提出的模型中,通過蒸餾網絡將基線數據訓練的模型f的知識遷移到模型g1,g2中。當隨訪數據不足以完整地和基線數據進行匹配時,使用現有配對數據訓練出一個正則化項l,用于代替缺失年數據與當前訓練對應年數據之間的蒸餾損失項。假設正則化項參數代表與目標缺失數據擬訓練模型相同網絡結構的參數δ,則具體訓練的正則化項如式(8):

其中:μ為控制正則項量級的訓練參數;ξ對應為相應少量的已配對缺失年的其他數據訓練得到的參數。這里以隨訪第1年缺失為例,則對應于多時期網絡目標函數式(7)的由正則項替換后函數表示為式(9):

如果缺失隨訪第2年數據,而可獲取基線年與隨訪第1年的數據,則正則項學習的目標對應為式(3)、(4)對應的蒸餾損失。具體對應算法1步驟中的17)~22)行。
在這部分方法中,假設NLST的數據樣本之間是獨立同分布的,且基線數據與隨訪數據的樣本數據分布與標簽分布映射關系相同,則使用元學習思想進行知識學習的算法步驟如算法1 所示,算法以基線年和隨訪第1 年配對為例,在每輪迭代的每個批次下首先利用配對的基線-隨訪數據,這里定義為數據A,訓練出一個教師網絡以及學生網絡,得到參數ω,ξ。然后利用配對數據得到的參數和已有的非配對數據,這里只有基線年數據,定義為數據B,結合目標函數M和正則項參數δ對θ進行訓練。這里算法1將數據A訓練得到的參數作為數據B 要訓練的學生網絡的初始參數使用,同時模型也利用了數據B 對其進行微調訓練,這部分目的是得到數據A 中隨訪類數據以及數據B 中基線數據的分布差異信息,從而訓練得到與數據B相關的學生網絡模型用于對其隨訪第一年數據進行分類。在更新正則項的時候,算法選擇與數據B 同源的數據C進行訓練,以避免其發生過擬合現象。
算法1 用于知識遷移的元學習方法。
輸入 學習率α、β,樣本批次K,迭代次數N,訓練數據隨訪時期參數Y;
輸出 正則參數δ。


3 實驗結果與分析
本文研究實驗環境為pytorch 1.2,實驗設備顯卡為Nvidia TITAN XP,顯存16 GB。實驗訓練數據來自美國癌癥研究機構(National Cancer Institute,NCI)的研究項目NLST,NLST 的數據最初用來比較兩種檢測肺癌的方式即低劑量CT和標準胸部X 光對人造成的影響,該實驗對53 454 個55~74歲的吸煙者進行了調查并且證明了低劑量CT 相較于標準胸部X光會降低患者的致死率。但是該數據集存在大量的未標注結節,本文實驗從利用隨訪信息輔助訓練角度出發,結合NLST 官方已有的標注信息以及合作醫院的兩名放射科醫師幫助,對少量實驗數據進行了標注。實際使用到的標注數據為838 例隨訪三年的病例,以及399 例隨訪兩年的病例,篩選后總共標記約有400組隨訪三年的配對數據,以及800例非配對數據。
實驗的部分測試數據來自合作醫院,該數據由42 例病人的多個時間段CT序列組成,這部分數據被加入到模型測試階段用于驗證模型魯棒性。
根據Lung-RADs 規定的分級標準,本文數據標簽有7 類,其含義分別為:1 對應CT 中無結節,2 對應有良性結節,3S 對應隨訪少于5年的亞實性結節或者隨訪少于2年的實性結節,3L 對應有炎癥表現的10 mm 以上結節,4A 對應10~25 mm 的實性結節,4B 對應隨訪后持續存在的大于10 mm 的亞實性結節,4C 對應短期隨訪(本文從驗證方法有效性方向將此定義為2 年)下,病灶無明顯改善,且基線病變大于等于10 mm 的結節。數據統計過程實際單個病例以三年病例為統計標準,將得到用于分類的三例數據。最終統計在NLST 數據集中1、2、3S、3L、4A、4B、4C 的樣本比例為5∶20∶12∶22∶3∶4∶14,合作醫院的42例病例數據樣本比例為1∶2∶9∶10∶5∶4∶11。
3.1 數據集構建與數據預處理
原始的NLST、合作醫院數據均為512 像素×512 像素左右的大小,本實驗在預處理環節首先提取到了肺結節的感興趣區域,且將其調整大小到64 像素×64 像素并統一進行了灰度化處理(實際情況下,大部分結節在切取感興趣區域(Region Of Interest,ROI)的過程中表現為64 像素大小以內如圖5(a)所示,所以本文采用64 像素截取樣本以涵蓋絕大部分結節信息)。
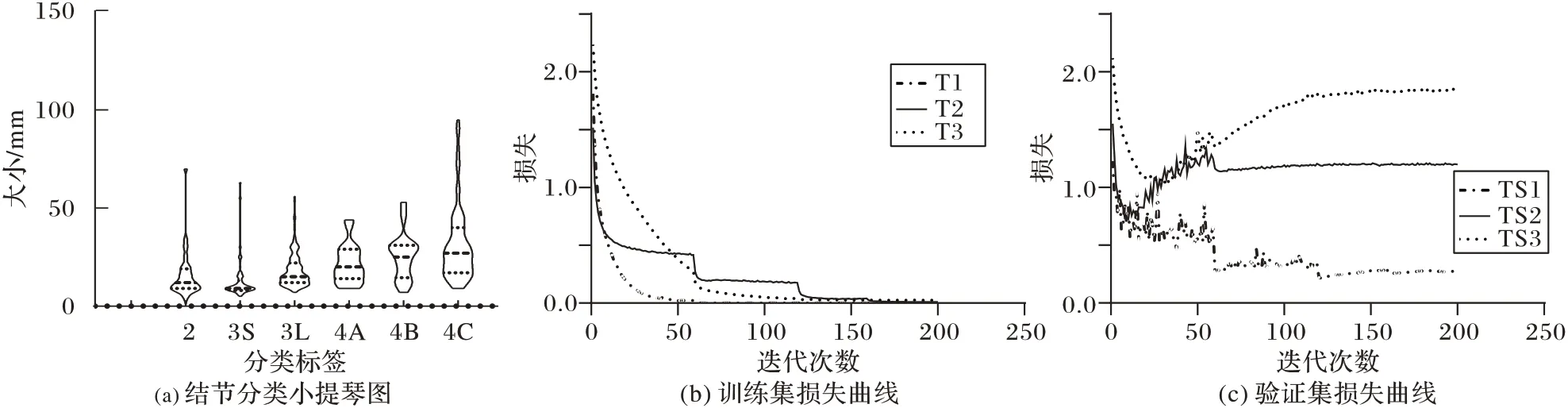
圖5 按類型統計結節的小提琴圖與損失函數的迭代曲線Fig.5 Nodule category statistical violin chart and iterative curves of loss functions
3.2 網絡訓練與參數選擇
3.2.1 多時期數據知識蒸餾網絡參數
在多時期網絡結構中本文使用ResNet的Basic block 作為基本結構,并且按Group 塊的方式組織起來,訓練過程中,輸入數據首先會經過均值方差歸一化處理,訓練集和測試集按照8∶2 的比例進行劃分。圖6 得到的向量會經過全連接層對應到七分類結果,并通過交叉熵損失訓練產生標簽信息。關于損失函數,對于式(3)、(4)中的λ=0.1,對于式(6)中的μ=0.01。模型優化器使用了隨機梯度下降法(Stochastic Gradient Descent,SGD),學習率設置為1.0×10-3。訓練教師網絡與學生網絡均使用了200 次迭代,其中學生網絡先通過交叉熵損失進行100次迭代訓練再結合蒸餾損失訓練100次。關于超參數選擇問題上,以λ為例,本文在學習率選擇上進行了實驗驗證,圖5(b)、(c)為三種量級的學習率下損失函數的迭代過程,其中T1、T2、T3 分別代表訓練集下λ=0.1、λ=0.01,、λ=0.001 下的損失迭代曲線,TS1~TS3 則對應于驗證集,由圖可知,200 次迭代內3 個超參數下訓練集損失均可收斂但是對于驗證集TS2,TS3 損失反而上升,說明TS1 設置下的超參數較優。
3.2.2 元學習算法模型參數
本文的不平衡數據知識遷移方法基于元學習思想,其中對于算法1,在訓練時的訓練參數與多時期知識蒸餾網絡相同。算法1 中涉及不同兩個迭代過程中的學習率α=1×10-3,β=2.5×10-4。相對于第1 次迭代,第2 次訓練正則項的收斂過程應適當減慢以完成良好收斂效果,所以β的設置相對較低。
3.3 多時期蒸餾網絡模型評估
本文模型評價指標使用準確率(MAcro?Precision,MAP)、召回率(MAcro?Recall,MAR)、F1分數(Macro?F1,MF1),實驗結果獨立運行10 次取平均值得到。由于本文的任務是多分類問題,在計算各評價指標時,考慮到了樣本均衡性問題,并且在按類別求平均值時加入與樣本類別比例因子,使各參數計算結果均衡、合理。本文將二分類問題的一個混淆矩陣轉變為七分類問題產生的多個混淆矩陣的評價指標并將其求平均。具體每個指標表達式如式(10)~(12):

針對2.1 節和2.3 節的兩個模型本文設計了不同實驗策略并給出了分析,如圖6 所示,首先展示了原數據與以及分別使用ResNet50、本文不采用MKD 模型訓練的網絡結構(對應網絡框架圖3 的第一分支)以及采用MKD 模型進行訓練的結構提取到的特征的t分布效果圖。從實驗結果可以看出,通過MKD 模型學習到的特征分布邊界更加明確,尤其對比單獨使用教師網絡模型情況下,對于3S和2這兩類標簽的效果更好。這也表明利用MKD模型對于隨訪知識的學習是有效的。
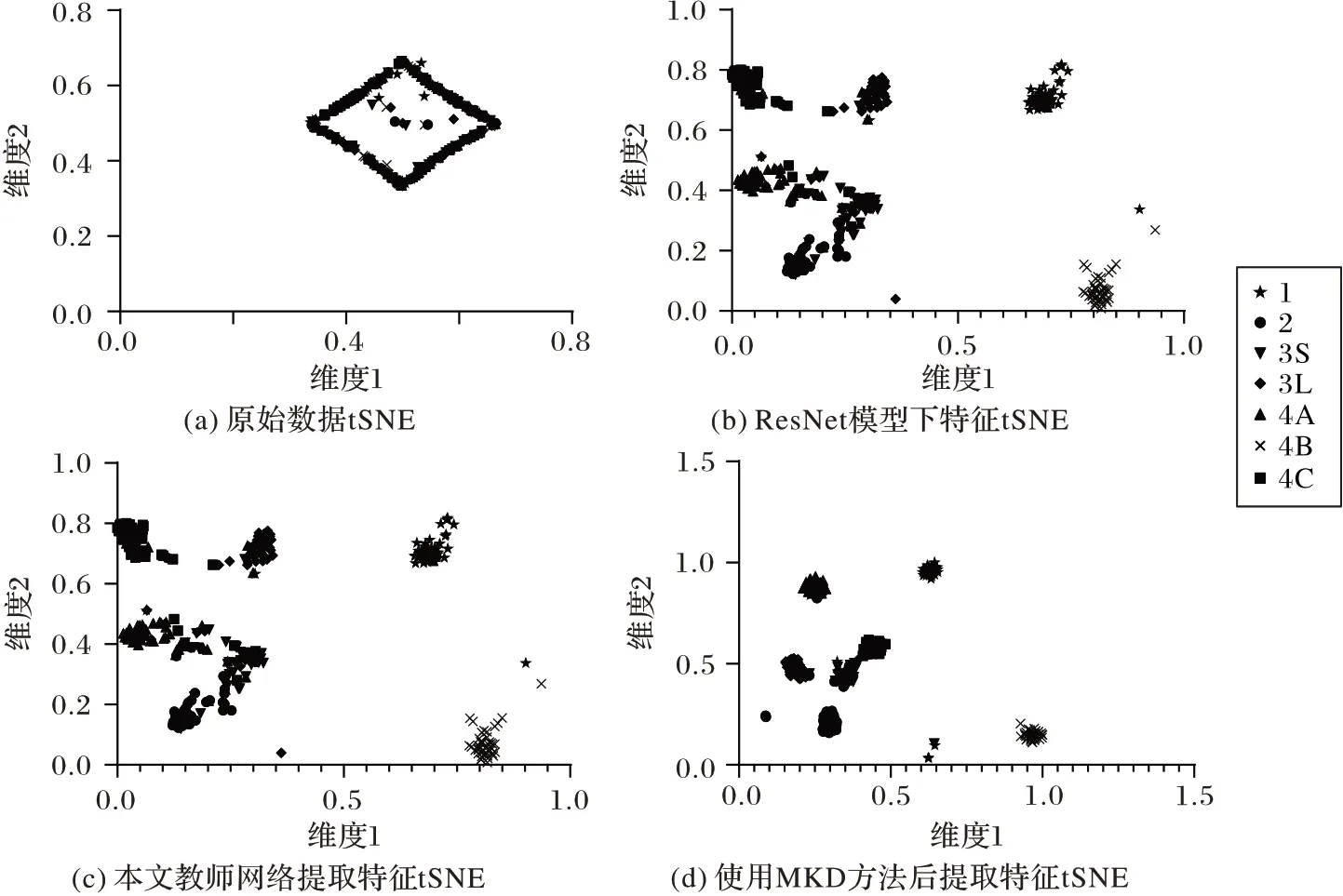
圖6 各種方法提取特征的t分布圖Fig.6 t distribution charts of features extracted by various methods
圖7 對比了一些典型的深度學習模型和肺結節分類模型的AUC(Area Under ROC Curve)值,從實驗結果可以看出,不同方法下ROC曲線覆蓋范圍均有所差異,而本文提出MKD模型總體覆蓋面積最大,可見模型效果最優。大部分優異的肺結節分類模型雖對結節的圖像特征學習有不錯的學習效果,且基本上具備診斷價值,但其并不能有效學習到隨訪信息,對于多時期分類任務學習能力欠佳。
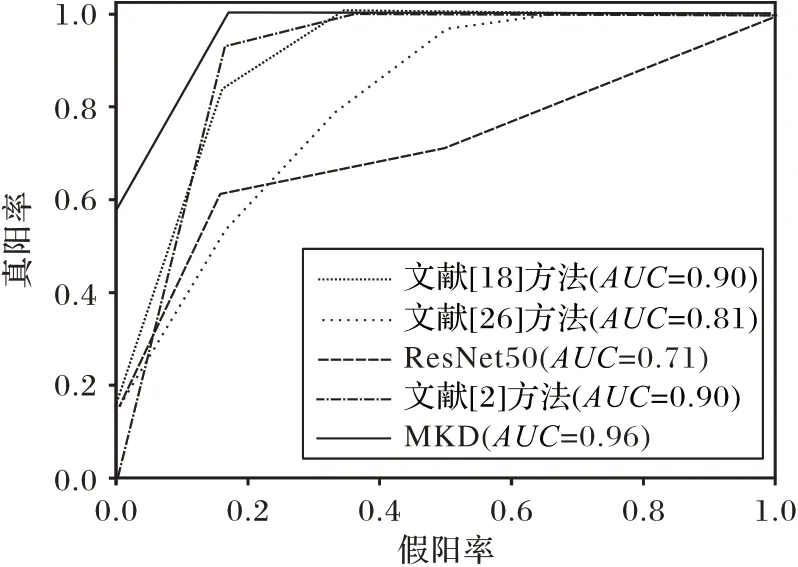
圖7 測試集上各方法的分類ROC曲線Fig.7 Classification ROC curve of each method on test set
表1 將不同深度學習模型與本文模型分類結果按類標簽對測試數據進行了統計(對于1 標簽無結節情況下,各類算法效果差異較小不予對比)。為了證明本文模型對長時期樣本的識別效果,實驗引入ResNet50 與GoogleNet 作為對比方法,兩者是深度學習分類領域的代表性模型且其基本結構與本文Group 模塊組相似,以此對比可以有效證明本文設計的Group模塊組對于本文模型的適配性,而文獻[2]方法是目前精度提升最明顯的長時期肺結節深度分類模型之一,文獻[18]利用知識提升非長時期肺結節分類精度并取得最優的效果。統計過程使用一定的測試樣本,其數量對應表1 末行,各方法僅統計測試樣本中真陽性的樣本數量。
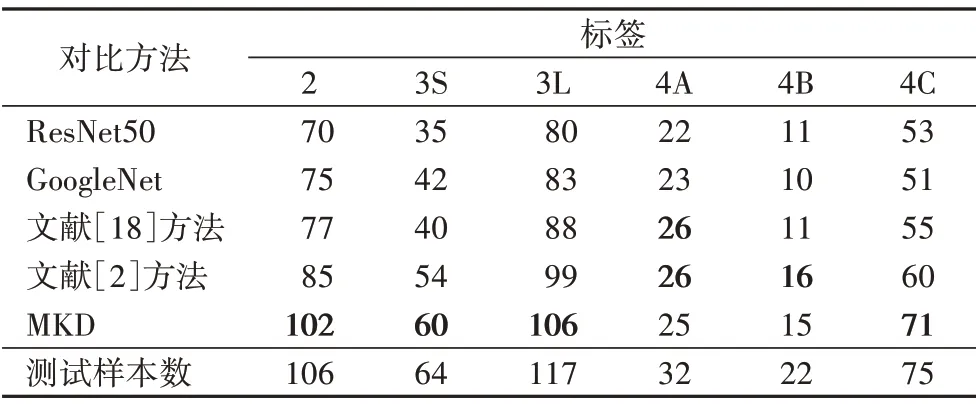
表1 按類標簽統計各深度學習方法正確識別的測試樣本數Tab.1 Class label based statistics on the number of test samples correctly identified by each deep learning method
結果顯示,在2、3S、3L、4C 標簽下,本文方法分類效果較好,其中對2 與4C 類數據的識別效果更好,這是由于2 與3S,3L與4C類結節在圖像特征上容易發生混淆,其涵蓋一定隨訪信息的特征,所以不適用于一般的分類模型。對于4A、4B 類標簽,由于樣本量較少,訓練得到的模型沒有明顯差異。
對比結果表明,ResNet、GoogleNet 這些常見深度學習模型,在本文數據集分類效果一般,此類模型僅從圖像角度出發,沒有考慮到醫學圖像的相關特征,分類效果對于數據要求較高。而加入對比的文獻[2]與文獻[18]中提出的肺結節分類方法雖然考慮到一些醫學征象,對于此部分圖像分類較好,但相較于MKD,其并未考慮到隨訪過程造成的標簽變化,因而在本文研究的數據集上表現與本文方法相比略差。通過此部分對比表明本文方法更適用于隨訪條件下的肺結節分類任務。
3.4 消融實驗
為了評估多時期網絡的有效性,本文設計了消融實驗,通過對比使用單年數據訓練的教師網絡模型,使用兩年配對的隨訪數據訓練雙分支的網絡模型(對應MKD 的前兩個分支)和三年配對數據訓練MKD 模型,驗證MKD 模型的學習效果。同時,為了驗證元學習方法解決不平衡數據問題的有效性,實驗在400組配對數據的基礎上,添加了800例非配對數據對比不使用正則學習缺失數據,使用L1 正則學習和L2 正則學習缺失數據的效果,其中非配對數據表示為假設兩年時期數據中有一年缺失但是仍作為兩年數據訓練模型,三年數據中第1或者第2年數據缺失仍作為三年數據。
表2 的結果顯示對于單時期的教師網絡結構,兩年隨訪訓練的雙分支網絡均不如MKD 模型,通過對比MAP指標得出,本文設計的知識蒸餾網絡有一定增強模型分類能力的效果。同時對于不平衡數據的研究,本文對比了MKD 和不同正則方法的組合,得出使用L2 正則的效果更好,通過MF1 指標的對比結果顯示,L2 正則對于提升模型擬合過程穩定性具有一定效果,R 表示正則化項(Regularizer),對應MKD 損失部分使用的正則化函數。

表2 MKD與不平衡知識遷移方法的消融實驗對比結果 單位:%Tab.2 Comparison results of ablation experiment between MKD and unbalanced knowledge transfer methods unit:%
3.5 不平衡數據下模型評估
表3 展示了在不同程度不平衡數據的情況下利用正則化項進行模型遷移的效果,其中MAR部分為假陽性率為1/8、1/4、1/2、1、2、4、8 時的平均召回率值。實驗對比了在三年長時期數據下配對數據量分別達到100、200 和400 時不平衡數據知識遷移方法的訓練效果。對于存在400 組配對數據以及800 例非配對數據時,使用本文正則化方法,在綜合評價指標MF1 上達到93.2%的分類效果,并且相比不使用該方法提升了7 個百分點。同時本文研究者發現在使用800 非配對數據輔助配對數據訓練可以近似達到雙倍配對數據單獨訓練的效果。通過此部分結果可以看出,使用知識作為先驗數據可以有效引導多時期數據訓練。

表3 不平衡數據下的模型遷移在不同配對數據方案下的評估結果Tab.3 Evaluation results of model transfer under different paired data schemes with imbalanced data
4 結語
本文提出了一種多時期數據知識蒸餾模型,該模型用于將不同年份數據訓練模型產生的知識遷移到缺失年份的模型中。具體模型從隨訪數據出發實現了長時期下的肺結節分類,同時針對長時期數據中的一些不平衡問題,本文進一步改進了MKD 模型使其能夠在缺失數據的情況下提升訓練效果。實驗結果表明,相比當前較好的肺結節分類模型,MKD 模型有著更好的分類效果并且改進后的MKD 模型對樣本需求更小,訓練精度更高;但是,受研究環境、現實數據的限制,模型實驗僅使用二維切片作為輸入數據,其信息量的缺失削弱了多時期數據互相學習分布差異的過程,在面對數據分布更為復雜的情況下,本文模型可能會出現坍塌現象,我們認為使用三維體向量作為單期輸入數據結合三維深度模型進行訓練的效果會優于多時期蒸餾網絡模型,在后續工作中將會收集更多三維數據作為樣本,并且嘗試改進多時期蒸餾網絡為三維模型,同時進一步降低模型對于數據的依賴性,實現更穩定、更高精度的長時期肺結節分類。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
意林原創版(2016年10期)2016-11-25 10:28:30
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
