基于彈幕情感分析和主題模型的視頻推薦算法
2021-11-05 01:29:00朱思淼魏世偉魏思恒余敦輝
計(jì)算機(jī)應(yīng)用 2021年10期
朱思淼,魏世偉*,魏思恒,余敦輝,2
(1.湖北大學(xué)計(jì)算機(jī)與信息工程學(xué)院,武漢 430062;2.湖北省教育信息化工程技術(shù)研究中心(湖北大學(xué)),武漢 430062)
0 引言
隨著Web3.0 時(shí)代的到來,互聯(lián)網(wǎng)應(yīng)用技術(shù)越來越圍繞用戶個(gè)性化網(wǎng)絡(luò)而蓬勃發(fā)展,隨之而來的是海量數(shù)據(jù)下信息過載與數(shù)據(jù)篩選所帶來的挑戰(zhàn),因此,如何為用戶提供個(gè)性化推薦成為當(dāng)下研究熱點(diǎn)之一。
近幾年,一種新型的基于視頻時(shí)間軸且可顯示在視頻中的文本評論方式——“彈幕”迅速占領(lǐng)市場,并廣受網(wǎng)民喜愛。起初彈幕只是小范圍流行于一些動漫網(wǎng)站,伴隨彈幕良好的交互性與娛樂性,越來越多的主流視頻網(wǎng)站如騰訊視頻、愛奇藝視頻都增加了彈幕評論的功能,最初的動漫彈幕網(wǎng)站嗶哩嗶哩(Bilibili)視頻網(wǎng)如今也成為了國內(nèi)最大的互聯(lián)網(wǎng)自制視頻網(wǎng)站,而世界最大的視頻網(wǎng)站YouTube 也出現(xiàn)了彈幕評論插件。彈幕評論具有社交性和情感性兩方面特點(diǎn),可用來作為有效數(shù)據(jù)完成對視頻推薦系統(tǒng)的改進(jìn)與完善。
目前,針對彈幕評論數(shù)據(jù)的研究并不多,尤其在推薦系統(tǒng)中,彈幕數(shù)據(jù)價(jià)值尚未被充分挖掘,在當(dāng)下海量“短視頻+短評論”的視頻環(huán)境下,大量用戶的自制視頻缺少評分和分類,對于視頻的推薦仍然以傳統(tǒng)的協(xié)同過濾方法為主。彈幕不同于傳統(tǒng)的文本評論,其基于視頻時(shí)間軸的即時(shí)性,可以從一定程度上反映視頻的內(nèi)容,所以通過對于彈幕的信息挖掘后,可基于視頻內(nèi)容進(jìn)行推薦。通過對于彈幕的情感分析,可以更好地發(fā)揮彈幕自身的情感性,同時(shí)也為源源不斷的自制視頻在內(nèi)容上進(jìn)行了情感分類。
針對網(wǎng)絡(luò)上大量自制視頻缺少用戶評分、推薦準(zhǔn)確率不高和對彈幕數(shù)據(jù)情感性未充分利用的問題,本文提出了一種基于彈幕情感分析和主題模型的視頻推薦算法(Video Recommendation algorithm based on Danmaku Sentiment Analysis and topic model,VRDSA)。通過視頻間的相似度、視頻的播放量、收藏?cái)?shù)、點(diǎn)贊數(shù)等特征計(jì)算視頻的綜合認(rèn)可度,并結(jié)合用戶對視頻的偏好度來完成對視頻的推薦。實(shí)驗(yàn)結(jié)果表明,本文算法對彈幕進(jìn)行情感分析,并融合主題模型對視頻進(jìn)行推薦。算法充分挖掘了彈幕數(shù)據(jù)的情感性,使推薦結(jié)果更加準(zhǔn)確。
1 相關(guān)工作
1.1 中文彈幕
當(dāng)前,眾多學(xué)者對中文彈幕進(jìn)行了研究,并取得一系列成果:文獻(xiàn)[1]從傳播學(xué)角度研究了彈幕的作用與受眾,指出彈幕正以積極的態(tài)勢發(fā)展,并具有較強(qiáng)研究價(jià)值和商業(yè)價(jià)值;文獻(xiàn)[2]提出對視頻中的彈幕進(jìn)行情感分析,雖然主要針對視頻片段,但為彈幕的研究方式提供了新思路;文獻(xiàn)[3]通過對彈幕進(jìn)行分析,并根據(jù)彈幕數(shù)據(jù)提出了一種對用戶進(jìn)行聚類的算法,主要研究方向是用戶的分類;文獻(xiàn)[4]提出的融合協(xié)同過濾和主題模型的彈幕視頻推薦算法(Danmaku video Recommendation algorithm combing Collaborative Filtering and Topic model,DRCFT)融合了協(xié)同過濾和LDA(Latent Dirichlet Allocation)主題模型,基于彈幕對視頻進(jìn)行了推薦系統(tǒng)的完善,但未從情感維度對彈幕進(jìn)行分析,沒有充分利用彈幕的情感性。盡管中文彈幕有較強(qiáng)的研究意義,但目前仍存在一些研究難點(diǎn):1)彈幕文本過于簡短、口頭化;2)彈幕中容易出現(xiàn)大量網(wǎng)絡(luò)用語,難以使用傳統(tǒng)的情感詞典進(jìn)行分析;3)彈幕往往會出現(xiàn)與視頻相關(guān)度較低的內(nèi)容。因此,對彈幕數(shù)據(jù)的預(yù)處理是進(jìn)行彈幕研究過程中非常關(guān)鍵的步驟。
1.2 彈幕情感分析
彈幕的情感分析與傳統(tǒng)中文文本的情感分析緊密相關(guān),但其領(lǐng)域性更強(qiáng),且彈幕評論會隨著視頻內(nèi)容變化而不斷變化,因此不能像處理商品評論一般直接根據(jù)評論內(nèi)容判斷視頻的情感極性。目前針對彈幕文本情感分析的主要方法有基于情感詞典的方法和基于機(jī)器學(xué)習(xí)的方法。情感詞典可通過人工編寫、啟發(fā)式算法來構(gòu)建,且不同領(lǐng)域的情感詞典對文本情感分析結(jié)果也有較大的影響,文獻(xiàn)[5]提出了一種基于詞向量的情感詞典構(gòu)建方法,以多部已有中文情感詞典為基礎(chǔ),結(jié)合詞嵌入表示方法,構(gòu)建了一部面向彈幕領(lǐng)域的情感詞典。基于機(jī)器學(xué)習(xí)的方法需要大量的訓(xùn)練數(shù)據(jù)且依賴對數(shù)據(jù)一定規(guī)模的人工標(biāo)注,文獻(xiàn)[6]根據(jù)彈幕碎片化、口語化的特點(diǎn)提出了基于詞頻-逆文本頻率指數(shù)(Term Frequency-Inverse Document Frequency,TF-IDF)與支持向量機(jī)(Support Vector Machine,SVM)的情感極性分析模型,利用較少的已標(biāo)注樣本完成對大量未標(biāo)注彈幕評論樣本的情感極性分類。文獻(xiàn)[7]利用了彈幕包含時(shí)間序列的特點(diǎn),基于長短期記憶(Long Short-Term Memory,LSTM)網(wǎng)絡(luò)模型提取彈幕評論的深層特征,利用彈幕評論文本中的依賴關(guān)系突出關(guān)鍵情感詞的情感權(quán)重。由于彈幕區(qū)別于傳統(tǒng)評論的多種特性,對彈幕領(lǐng)域的情感分析研究仍有待發(fā)展。
1.3 LDA主題模型
LDA 主題模型是一種文檔主題生成模型,該模型假設(shè)每篇文章都是以一定概率選擇某個(gè)主題,然后從這個(gè)主題中以一定概率選擇一個(gè)詞語,最后由若干個(gè)選出的詞語構(gòu)成。LDA 主題模型在概率潛在語義分析(probabilistic Latent Semantic Analysis,pLSA)的基礎(chǔ)上利用Dirichlet 分布得到文檔主題和詞語的先驗(yàn)分布,并通過Gibbs 采樣來得到文檔中的文檔-主題分布和主題-詞語分布。LDA 主題模型的圖模型結(jié)構(gòu)如圖1所示。
圖1 中,α和β都是Dirichlet 分布,通過Gibbs 抽樣分別得到文檔i的主題分布θi和主題Zi,j的對應(yīng)詞語分布;通過主題分布θi得到文檔i中第j個(gè)詞的主題Zi,j;最后從詞語分布中采樣生成詞語Wi,j。
文獻(xiàn)[8]中提出了基于LDA 主題模型進(jìn)行文本相似度計(jì)算的方法,增強(qiáng)了文檔的向量表示,使相似度的準(zhǔn)確率更高;文獻(xiàn)[9-10]分別將LDA 主題模型用于推薦系統(tǒng)的改進(jìn),但都沒有對彈幕數(shù)據(jù)進(jìn)行研究。
2 基于彈幕情感分析和主題模型的視頻推薦算法
本文從視頻內(nèi)容的情感分布、視頻的主題和視頻的認(rèn)可度三方面入手,分別對視頻的彈幕、視頻的標(biāo)簽、視頻的播放數(shù)與收藏?cái)?shù)等用戶互動指標(biāo)進(jìn)行量化,提出了VRDSA。VRDSA 通過視頻彈幕得到視頻間情感向量的相似度,基于視頻標(biāo)簽得到視頻間主題分布的相似度,進(jìn)而得到視頻的綜合相似度,然后結(jié)合用戶的歷史記錄得到用戶對視頻的偏好度;接下來,基于視頻的播放數(shù)、收藏?cái)?shù)等指標(biāo)對視頻的大眾認(rèn)可度進(jìn)行量化,并結(jié)合用戶歷史記錄計(jì)算視頻的綜合認(rèn)可度;最后以用戶對視頻的偏好度為權(quán)重,預(yù)測用戶對視頻的認(rèn)可度,實(shí)現(xiàn)對用戶個(gè)性化的推薦。該算法解決了網(wǎng)絡(luò)自制視頻沒有用戶評分,且缺少情感標(biāo)簽因而難以針對視頻自身內(nèi)容進(jìn)行分析并推薦的問題。
VRDSA的步驟如下:
1)對視頻中的彈幕文檔進(jìn)行預(yù)處理,使用情感詞典進(jìn)行情感詞匹配,得到視頻的情感向量,并通過情感向量計(jì)算視頻間的情感相似度。
2)對視頻自帶標(biāo)簽進(jìn)行LDA 主題建模,得到每個(gè)視頻各自標(biāo)簽的主題分布,使用標(biāo)簽的主題分布計(jì)算視頻之間的主題相似度。
3)將視頻之間的情感相似度和主題相似度進(jìn)行融合,得到視頻之間的綜合相似度,并結(jié)合用戶的歷史記錄計(jì)算用戶對目標(biāo)視頻的偏好度。
4)對視頻的點(diǎn)贊量、播放量等指標(biāo)進(jìn)行量化,得到視頻的大眾認(rèn)可度。然后結(jié)合用戶的歷史記錄與視頻的綜合相似度計(jì)算視頻的綜合認(rèn)可度以調(diào)整目標(biāo)視頻的認(rèn)可度。
5)基于用戶偏好度和視頻的綜合認(rèn)可度,將用戶對視頻的偏好度作為權(quán)重來預(yù)測用戶對視頻的認(rèn)可度,最終通過用戶對視頻的認(rèn)可度來生成top-k推薦列表,完成推薦。
VRDSA的流程如圖2所示。
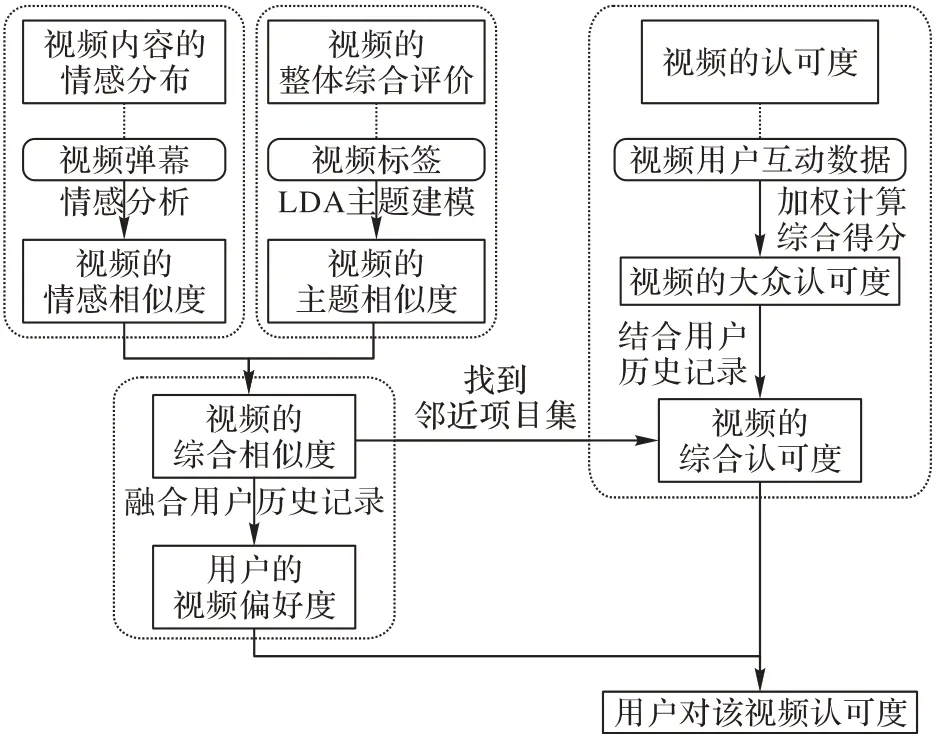
圖2 VRDSA流程Fig.2 Flowchart of VRDSA
2.1 視頻基于彈幕的情感分析
2.1.1 彈幕數(shù)據(jù)獲取和預(yù)處理
雖然目前大部分視頻網(wǎng)站和應(yīng)用都加入了彈幕評論的功能,但較早引入彈幕的Bilibili視頻網(wǎng)依然是國內(nèi)最大的彈幕視頻網(wǎng)站,它擁有著大量社區(qū)用戶和網(wǎng)絡(luò)自制視頻,并且有獨(dú)特的彈幕文化,是彈幕研究的首選網(wǎng)站。因此本文利用Python中的requests庫和bs4庫來爬取Bilibili 視頻網(wǎng)中的彈幕可擴(kuò)展標(biāo)記語言(eXtensible Markup Language,XML)文件,去除重復(fù)彈幕,利用Jieba庫并引入文獻(xiàn)[8]中構(gòu)建的彈幕文本情感詞典對彈幕文檔進(jìn)行分詞,使用停用詞表去除彈幕中無用詞匯。經(jīng)過預(yù)處理后的每條彈幕都相當(dāng)于一個(gè)詞語集合。
2.1.2 視頻情感向量計(jì)算
本文選用大連理工大學(xué)中文情感詞匯本體庫及文獻(xiàn)[9]中構(gòu)建的彈幕文本情感詞典來進(jìn)行視頻情感向量的計(jì)算,處理彈幕中的網(wǎng)絡(luò)語言時(shí),結(jié)合兩種情感詞典可以取得更好的效果。根據(jù)情感詞典中的詞語在7個(gè)情感大類中的情感強(qiáng)度對每個(gè)詞構(gòu)造一個(gè)7維的情感向量EW=,其中每個(gè)維度代表著一種感情,分別為:樂、好、怒、哀、懼、惡、驚。如“滑稽”一詞的情感向量EW=(3,0,0,0,0,3,0),表明它在“樂”與“惡”之間都有一定的感情傾向。通過對彈幕的預(yù)處理后,每條彈幕可看作是若干詞語的集合,將該集合中的詞與情感詞典進(jìn)行匹配,在匹配的過程中,彈幕的其他無關(guān)詞匯會被過濾,然后將匹配后的集合中各個(gè)詞語的情感向量相加且歸一化處理,得到每條彈幕的情感向量為:

其中:代表彈幕d中第i個(gè)情感詞的情感向量;M為情感詞的向量求和后7 個(gè)維度中的最大值,以此進(jìn)行歸一化處理。若經(jīng)過預(yù)處理后的彈幕沒有與情感詞典相匹配的詞,則不對該條彈幕進(jìn)行計(jì)算。
對視頻中所有彈幕的情感向量求平均值,得到視頻的情感向量:

其中:n為視頻中彈幕的數(shù)量為第k個(gè)彈幕的情感向量。
2.2 視頻相似度計(jì)算
2.2.1 視頻的情感相似度
在計(jì)算得到視頻的情感向量EV后,可通過余弦相似度(Cosine Similarity)來計(jì)算兩個(gè)視頻之間的情感相似度:

其中:是視頻i的情感向量是視頻j的情感向量是視頻i的情感向量中第k個(gè)維度的情感指數(shù)。通過情感向量的余弦相似度可計(jì)算視頻i與視頻j在情感維度的相似性。
2.2.2 視頻的主題相似度
現(xiàn)在大部分視頻網(wǎng)站在用戶上傳視頻時(shí),通常引導(dǎo)用戶為視頻添加標(biāo)簽以確定視頻的主題以便分類。標(biāo)簽一般由多個(gè)短詞語組成,可以從多個(gè)方面體現(xiàn)視頻的主題。這種由多個(gè)主題詞組成的標(biāo)簽可用來計(jì)算視頻之間的主題相似度。
針對視頻標(biāo)簽的處理,本文使用LDA 主題模型以多個(gè)視頻的標(biāo)簽詞語集合作為語料庫,采用Gibbs 采樣算法進(jìn)行建模,得到視頻的標(biāo)簽主題分布矩陣,并計(jì)算視頻標(biāo)簽之間的主題相似度,以此反映視頻之間的主題相似度:

其中:代表視頻i的主題分布,可將其視作一個(gè)m維的向量(m為LDA 主題的數(shù)量)代表視頻i的主題分布中第k個(gè)主題的權(quán)重。通過視頻標(biāo)簽主題分布的余弦相似度計(jì)算出視頻i和j之間的主題相似度。
計(jì)算出視頻的情感相似度和主題相似度后,通過加權(quán)求和的方式將兩種相似度融合得到視頻之間的綜合相似度:
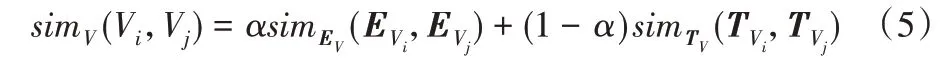
其中:simV(Vi,Vj)代表視頻i,j之間的綜合相似度;代表視頻i,j之間的情感相似度代表視頻i,j之間的主題相似度;α為權(quán)重系數(shù)。當(dāng)α=1 時(shí),視頻的綜合相似度等于視頻的情感相似度,此時(shí)視頻缺少視頻標(biāo)簽;當(dāng)α=0 時(shí),視頻的綜合相似度等于視頻的主題相似度,此時(shí)視頻缺少彈幕。
用戶對視頻的偏好度利用用戶的歷史觀看視頻集合Hu和集合中視頻與目標(biāo)視頻的相似度得到:
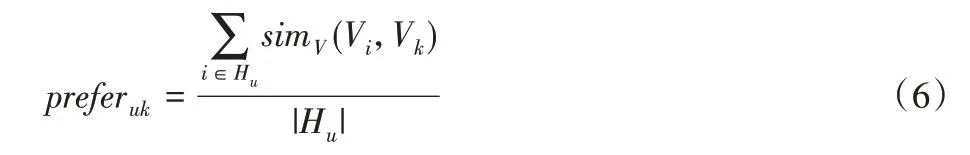
其中:simV(Vi,Vk)為用戶u歷史觀看視頻Vi與目標(biāo)視頻Vk的相似度;|Hu|為歷史觀看視頻集合的數(shù)量。
2.3 基于用戶偏好度和視頻認(rèn)可度的推薦
目前,類似于YouTube、Bilibili 這類綜合視頻網(wǎng)站平臺擁有大量網(wǎng)絡(luò)自制視頻,由于這些視頻數(shù)量多,主題雜,內(nèi)容、風(fēng)格差異大,難以像電影評分系統(tǒng)一樣來衡量視頻的認(rèn)可度,因此可以充分利用視頻的用戶互動數(shù)據(jù)如點(diǎn)贊數(shù)、收藏?cái)?shù)、分享數(shù)等來量化視頻的認(rèn)可度。本文提出了視頻的大眾認(rèn)可度和綜合認(rèn)可度兩個(gè)認(rèn)可度量化值。
Bilibili 視頻網(wǎng)站中的視頻用戶互動指標(biāo)如表1 所示,其中,投幣數(shù)是觀看視頻的用戶將自己的網(wǎng)站虛擬貨幣贈送給視頻創(chuàng)作者以此作為激勵,此虛擬貨幣無需充值。

表1 視頻用戶互動指標(biāo)Tab.1 Video user interaction metrics
基于Bilibili 視頻的用戶互動數(shù)據(jù)的設(shè)置方式,視頻k的大眾認(rèn)可度計(jì)算方式如下:

其中:β為各用戶互動數(shù)據(jù)指標(biāo)的權(quán)值,通過對Bilibili 視頻網(wǎng)視頻排行榜中視頻分?jǐn)?shù)的擬合,結(jié)合層次分析法(Analytic Hierarchy Process,AHP)和熵權(quán)法共同確定。考慮到評論對于視頻的評價(jià)有正向和反向,因此未將評論數(shù)replynum作為衡量視頻大眾認(rèn)可度的指標(biāo)。具體權(quán)重?cái)?shù)值如表2所示。
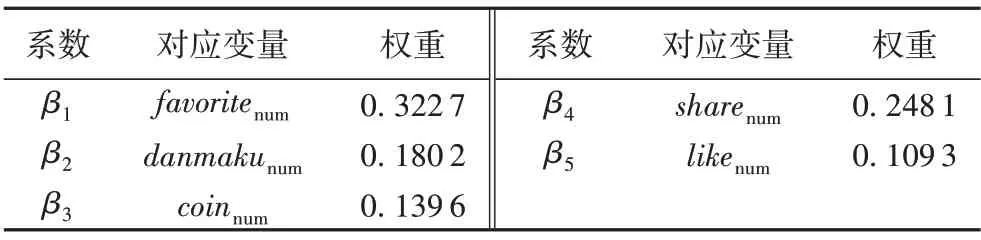
表2 視頻用戶互動指標(biāo)權(quán)重Tab.2 Weights of video user interaction metrics
接下來,對未經(jīng)過歸一化處理的大眾認(rèn)可度進(jìn)行歸一化處理,得到最終的大眾認(rèn)可度:

其中MAX代表未歸一化之前大眾認(rèn)可度的最大值。
為了避免部分視頻大眾認(rèn)可度過高對推薦結(jié)果造成的影響,使用綜合認(rèn)可度來調(diào)整目標(biāo)視頻的認(rèn)可度。通過視頻的綜合相似度得到視頻k的鄰近項(xiàng)目集Nk,結(jié)合用戶u的歷史記錄項(xiàng)目集Hu得到兩個(gè)集合的交集I,使用式(8)相同方法,可以計(jì)算出交集I中任意視頻i的大眾認(rèn)可度Recpi。最后,計(jì)算交集I中視頻和目標(biāo)視頻的大眾認(rèn)可度平均值,得到目標(biāo)視頻的綜合認(rèn)可度:

其中:Recpi為視頻k的鄰近項(xiàng)目集與用戶u的歷史記錄項(xiàng)目集Hu的交集I中視頻的大眾認(rèn)可度;Recpk為目標(biāo)視頻的大眾認(rèn)可度;|I|為交集元素個(gè)數(shù)。當(dāng)交集為空集時(shí),即視頻k的鄰近項(xiàng)目集與用戶u的歷史記錄項(xiàng)目集Hu沒有交集時(shí),目標(biāo)視頻k的綜合認(rèn)可度Recsk為自身的大眾認(rèn)可度Recpk。
基于用戶偏好度和視頻的綜合認(rèn)可度,將用戶對視頻的偏好度作為權(quán)重來預(yù)測用戶對視頻的認(rèn)可度:

其中:preferuk表示用戶u對視頻k的偏好度;Recsk表示視頻k的綜合認(rèn)可度。
通過式(10)可以針對用戶喜好對目標(biāo)視頻的認(rèn)可度進(jìn)行調(diào)整:如果用戶對目標(biāo)視頻的偏好度較高,則用戶對此視頻的認(rèn)可度也高;如果用戶對目標(biāo)視頻的偏好度不高,則即使該視頻的綜合認(rèn)可度較高,但對該用戶而言認(rèn)可度會降低。根據(jù)VRDSA 預(yù)測出的用戶對視頻的認(rèn)可度,可得到目標(biāo)用戶認(rèn)可度最高的top-k個(gè)視頻,最終形成推薦列表并推薦給用戶。
3 實(shí)驗(yàn)與結(jié)果分析
3.1 數(shù)據(jù)集
本文實(shí)驗(yàn)數(shù)據(jù)集來源于BiliBili 視頻網(wǎng)站,使用聚焦爬蟲從該視頻網(wǎng)站的Vlog 頻道爬取3 102 個(gè)視頻的所有相關(guān)用戶互動數(shù)據(jù),以及3 375 877 條彈幕,涉及用戶1 015 641 個(gè)。通過數(shù)據(jù)預(yù)處理進(jìn)行彈幕去重、刪除歷史記錄稀疏用戶、剔除部分?jǐn)?shù)據(jù)異常視頻后剩余視頻2 752 條,有效活躍用戶數(shù)量1 071個(gè),每個(gè)用戶平均約有60條歷史觀看記錄。為減小實(shí)驗(yàn)誤差,采用三折交叉驗(yàn)證的方式進(jìn)行實(shí)驗(yàn)。
3.2 評價(jià)指標(biāo)
本文使用準(zhǔn)確率(Precision,P)、召回率(Recall,R)及F值(F1)三個(gè)在推薦系統(tǒng)的評估中廣泛使用的實(shí)驗(yàn)評價(jià)指標(biāo)來對實(shí)驗(yàn)結(jié)果進(jìn)行分析和評價(jià)。
準(zhǔn)確率公式:
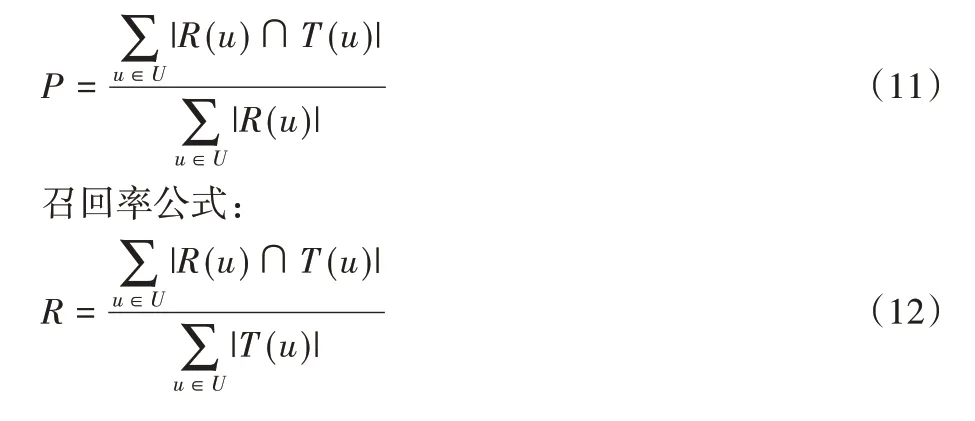
F值公式:

其中:R(u)為VRDSA 生成top-k推薦列表中的視頻項(xiàng)目;T(u)為測試集中用戶實(shí)際觀看過的視頻項(xiàng)目。
準(zhǔn)確率為成功推薦的視頻數(shù)量與top-k推薦列表中視頻數(shù)量的比值,用于衡量推薦算法的準(zhǔn)確程度;召回率為成功推薦的視頻數(shù)量與用戶觀看記錄數(shù)量的比值。隨著top-k推薦列表中視頻數(shù)量的增加,準(zhǔn)確率會降低,而召回率會增加,因而引入準(zhǔn)確率和召回率的加權(quán)調(diào)和平均值F1 來對推薦算法進(jìn)行綜合衡量。同等情況下,F(xiàn)1 越高,表明推薦算法的效果越好。
3.3 結(jié)果分析
實(shí)驗(yàn)硬件環(huán)境為Intel Core i5-7400 處理器,16 GB 內(nèi)存;軟件環(huán)境為Windows 10 x64 操作系統(tǒng),代碼使用Python3.7.0實(shí)現(xiàn)。實(shí)驗(yàn)數(shù)據(jù)參數(shù)如表3所示。

表3 實(shí)驗(yàn)數(shù)據(jù)參數(shù)Tab.3 Experimental data parameter
3.3.1 LDA相關(guān)參數(shù)確定
在LDA 主題模型的構(gòu)建中,需要確定主題的個(gè)數(shù)和詞語采樣迭代次數(shù)兩個(gè)參數(shù)。設(shè)定歷史記錄數(shù)據(jù)規(guī)模為20 000,推薦數(shù)量為10,融合參數(shù)α為0,即僅使用主題相似度探究主題個(gè)數(shù)和迭代次數(shù)對精確率、召回率和F 值的影響,得到最優(yōu)參數(shù),結(jié)果如圖3所示。
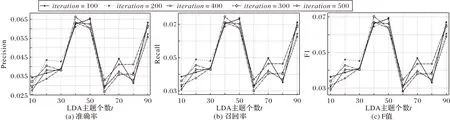
圖3 不同主題個(gè)數(shù)和迭代次數(shù)下的評價(jià)指標(biāo)Fig.3 Evaluation metrics at different numbers of topics and iterations
由圖3可知,隨著LDA主題數(shù)t增加,3個(gè)評價(jià)指標(biāo)先逐漸增大,再突然減小后出現(xiàn)波動,在t為40 或50 時(shí),3 個(gè)評價(jià)指標(biāo)取得了較高的值,且相較于t=90 在建模過程中更有效率。而迭代次數(shù)對評價(jià)指標(biāo)的影響并不大,從圖3可知,iteration=500 時(shí)算法有最好的效果,故確定LDA 主題個(gè)數(shù)t=40,迭代次數(shù)iteration=500。
3.3.2 數(shù)據(jù)規(guī)模和融合參數(shù)的確定
確定LDA 模型構(gòu)建的參數(shù)后,探究不同歷史推薦數(shù)量r和不同融合參數(shù)α的情況下評價(jià)指標(biāo)的變化。
1)歷史推薦數(shù)量r的確定。
確定LDA 主題個(gè)數(shù)t=40,迭代次數(shù)iteration=500,融合參數(shù)設(shè)置為0,探究不同歷史記錄數(shù)據(jù)規(guī)模r下準(zhǔn)確率、召回率、F值的變化,結(jié)果如圖4所示。
由圖4 可知,隨著歷史記錄數(shù)據(jù)規(guī)模的增加,準(zhǔn)確率、召回率、F 值都在逐漸增大,在r為70 000 時(shí)達(dá)到最大值,故確定實(shí)驗(yàn)所使用的歷史記錄數(shù)據(jù)規(guī)模r為70 000。
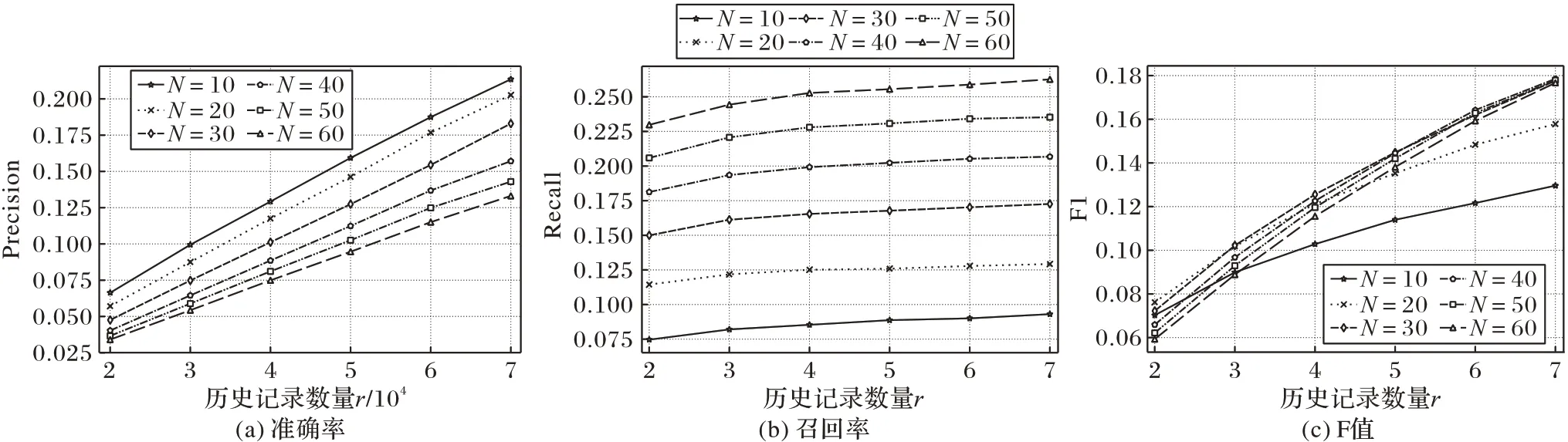
圖4 不同歷史記錄數(shù)據(jù)規(guī)模和推薦數(shù)量下的評價(jià)指標(biāo)Fig.4 Evaluation metrics at different history record data sizes and numbers of recommendations
2)融合參數(shù)α的確定。
得到使算法表現(xiàn)最佳的歷史記錄數(shù)據(jù)規(guī)模r后,在同樣的條件下探究不同的相似度融合參數(shù)α對準(zhǔn)確率、召回率、F值的影響,結(jié)果如圖5所示。
由圖5 可知,推薦數(shù)量對融合參數(shù)并無明顯影響,隨著α增加,3個(gè)評價(jià)指標(biāo)均先增加后降低。準(zhǔn)確率、召回率、F值在α取值為0.2~0.5 時(shí)相差不大,在α為0.3 時(shí)達(dá)到最大值,故α取0.3。僅使用主題相似度時(shí)效果較好,通過融合參數(shù)與情感相似度進(jìn)行融合后可達(dá)到最佳效果。
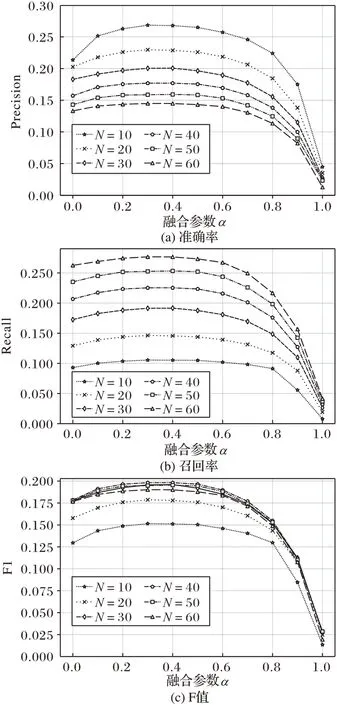
圖5 不同融合參數(shù)和推薦數(shù)量下的評價(jià)指標(biāo)Fig.5 Evaluation metrics at different fusion parameters and numbers of recommendations
由圖4和圖5可知,推薦個(gè)數(shù)對于歷史數(shù)量和融合參數(shù)的確定沒有明顯影響。由于隨著推薦個(gè)數(shù)增加,準(zhǔn)確率增加、召回率降低,故用F值確定最佳推薦個(gè)數(shù),從圖4~5中可知,N為30或40時(shí)算法的效果最佳。
3.3.3 算法的有效性驗(yàn)證
在確定LDA 主題個(gè)數(shù)t為40,迭代次數(shù)iteration為500,歷史記錄數(shù)據(jù)規(guī)模r為70 000,融合參數(shù)α為0.3后,將本文提出的VRDSA 與當(dāng)前主流的四種算法,即傳統(tǒng)基于物品的協(xié)同過濾算法(itembasedCF)、基于標(biāo)簽生成的主題模型tag-LDA 算法、嵌入LDA 主題模型的協(xié)同過濾算法(Unifying LDA and Ratings Collaborative Filtering,ULR-itemCF)[16]、融合協(xié)同過濾和主題模型的彈幕視頻推薦算法(DRCFT)[4],基于準(zhǔn)確率、召回率、F值進(jìn)行對比,驗(yàn)證在不同推薦數(shù)量N下VRDSA的有效性,結(jié)果如圖6所示。
由圖6 可知,隨著推薦數(shù)量的增加,本文算法的F 值先增加后緩慢下降,評價(jià)指標(biāo)均優(yōu)于其他四種算法,表明本文算法在不同推薦數(shù)量下推薦的效果均優(yōu)于目前主流的視頻推薦算法。在推薦數(shù)量N為10~40時(shí)均有較好的效果,算法的F值明顯高于其他算法;數(shù)值當(dāng)N超過40 時(shí),受實(shí)驗(yàn)數(shù)據(jù)集數(shù)據(jù)規(guī)模影響,推薦算法的F 值逐漸趨于平緩下降趨勢,當(dāng)推薦數(shù)量N為60 時(shí),本文算法的效果逐漸接近DRCFT 算法;后續(xù)若再次增大推薦數(shù)量N,所有算法的F 值均會緩慢下降。若需要進(jìn)一步凸顯本算法的優(yōu)勢,數(shù)據(jù)規(guī)模應(yīng)該進(jìn)行進(jìn)一步擴(kuò)充。
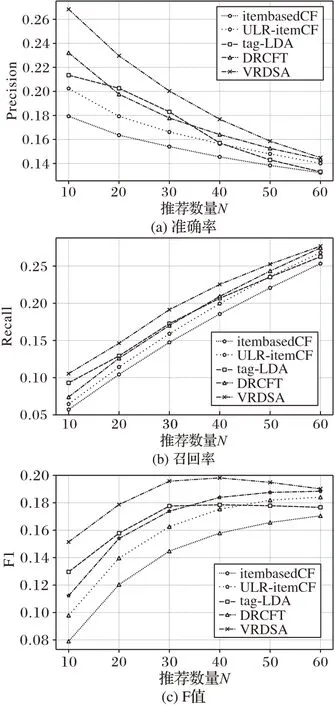
圖6 各算法不同推薦數(shù)量下的評價(jià)指標(biāo)Fig.6 Evaluation metrics of different algorithms at different numbers of recommendations
4 結(jié)語
本文提出了一種基于彈幕情感分析和主題模型的視頻推薦算法(VRDSA),對新興的彈幕評論進(jìn)行情感分析,結(jié)合視頻自帶標(biāo)簽對視頻的相似度進(jìn)行計(jì)算;并利用視頻的用戶互動數(shù)據(jù)對視頻的認(rèn)可度進(jìn)行量化,解決了網(wǎng)絡(luò)自制視頻缺少合理評分的問題,實(shí)現(xiàn)了基于用戶自身特征與視頻內(nèi)容的綜合推薦,且達(dá)到了較好的效果。針對冷啟動問題,一方面通過基于視頻標(biāo)簽的相似度計(jì)算,可解決因缺少彈幕而無法對視頻進(jìn)行情感分析的問題;另一方面對于缺少歷史播放記錄的新用戶,VRDSA將推薦綜合認(rèn)可度較高的視頻。
基于視頻內(nèi)容的視頻推薦相較于其他方面的推薦較有難度,而彈幕作為視頻中的實(shí)時(shí)評論還有很多內(nèi)容可以去挖掘。今后將進(jìn)一步完善彈幕的文本分析處理工作,并結(jié)合單個(gè)用戶的彈幕內(nèi)容和視頻互動行為刻畫用戶畫像,提高推薦的準(zhǔn)確率。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
家庭醫(yī)學(xué)(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(bào)(2019年10期)2019-11-04 02:57:59
中國生殖健康(2018年5期)2018-11-06 07:15:40
商用汽車(2016年11期)2016-12-19 01:20:16
發(fā)明與創(chuàng)新(2016年6期)2016-08-21 13:49:38
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
