動態融合社交信息的社會化推薦
2021-11-05 01:28:58任柯舟彭甫镕張曉靜
計算機應用 2021年10期
任柯舟,彭甫镕,郭 鑫,王 喆,張曉靜
(山西大學大數據科學與產業研究院,太原 030006)
0 引言
隨著互聯網的發展和電子商務的蓬勃發展,信息數據呈現爆炸式增長,導致人們面臨的選擇也越來越多,推薦系統逐漸成為一種普遍應用的技術。傳統的推薦系統大多是基于協同過濾或基于內容推薦[1],這類方法主要基于集體智慧,核心思想是給用戶推薦他們喜歡物品的相似物品,或者向用戶推薦與他們有相似行為的用戶喜歡的物品[2]。雖然這些傳統的方法有不錯的效果,但都忽視了用戶交互物品之間的結構關系,例如用戶的行為習慣、用戶偏好的發展及商品的流行時間等[3]。序列推薦系統能有效利用用戶與物品的交互序列來很好地包含這些結構信息,從而進行更加準確和動態的推薦[4]。序列推薦將用戶的交互物品按照時間順序來構建一個序列模型,通過捕獲物品之間的依賴關系獲得用戶的動態興趣特征,很好地解決了用戶的興趣遷移問題。受處理長度的影響,序列模型通常得到的是用戶的短期興趣特征。為了使用戶特征更加完整,研究人員通常使用矩陣分解模型來獲取用戶長期養成的喜好,即用戶的長期興趣。
每位用戶的交互物品相較于物品總量來說是很稀疏的,因此大多數的用戶-物品矩陣是稀疏矩陣,而數據的稀疏會導致推薦的效果下降[5];同時隨著各大社交網站的發展,越來越多的科研人員將社交數據作為緩解數據稀疏的輔助數據[6]。大多數社會化推薦都基于同質性和社交影響理論,即在社交網路中有聯系的用戶有相似的興趣愛好,同時具有相似愛好的人更容易建立聯系。由于矩陣分解良好的擴展性,研究人員在矩陣分解的基礎上提出了兩種融合方式[7]:1)用戶特征向量的共享表示,在原矩陣分解的基礎上通過共享用戶特征,使用戶-項目矩陣分解得到的用戶特征向量也可以應用在用戶社交矩陣中;2)用戶特征重表示,在用戶興趣與社交興趣相似的基礎上,增加社交約束項,保證用戶特征與社交特征盡可能相似。
用戶與項目交互是一個動態序列,用戶的興趣動態變化[3]在序列推薦算法中已被大量地關注,而在一般的社會化推薦算法忽略了用戶的短期興趣。除了用戶興趣的動態特性外,社會化推薦算法也忽略了社交影響的動態特性,將不同時刻的朋友行為同等對待。例如,表1展示了用戶u和其兩個朋友a、b在t-1到t+1的交互列表,圖1展示朋友a、b對用戶u可能的影響力。在t-1時刻用戶u和朋友a有相同的交互物品,因此朋友a的影響力要大于朋友b;在t時刻用戶u和朋友b有相同的交互物品,因此朋友b的影響力要大于朋友a;在t+1 時刻,雖然朋友a,b都交互過物品3,但朋友a的交互時刻要比朋友b更接近于用戶u,因此朋友a的影響力要大于朋友b。
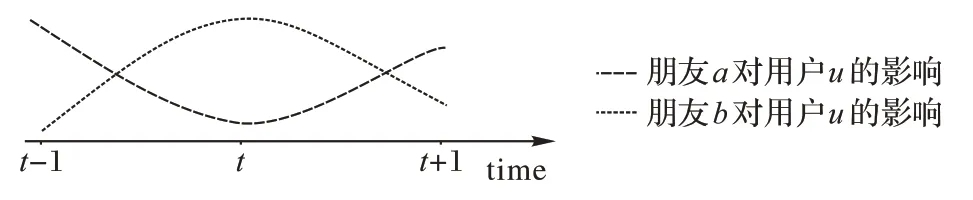
圖1 朋友對用戶的影響Fig.1 Influence of friends on a user
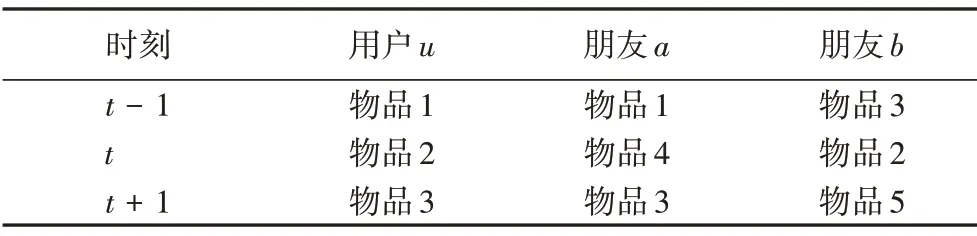
表1 用戶和朋友的交互列表Tab.1 Interactive list of a user and his friends
針對用戶的興趣動態變化和社交影響的動態特性,本文提出了一種社交信息動態融合的社會化推薦模型。首先,利用自注意力機制構建用戶交互物品的序列模型,捕獲用戶短期興趣;然后,利用具有時間遺忘的注意力機制構建社交短期影響,利用具有協同特性的注意力機制構建社交長期影響;最后,結合社交的長短期影響與用戶的短期興趣獲得用戶的最終興趣并產生下一項推薦。本文的主要貢獻如下:
1)在社交短期興趣建模過程中,提出具有遺忘機制的注意力融合方法,降低朋友在較遠時刻的行為的社交影響力;
2)在社交長期興趣建模過程中,提出具有協同特性的注意力融合方法,加強行為相似的朋友的社交影響力;
3)提出將用戶短期興趣、社交短期興趣與社交長期興趣進行融合,得到一種社交信息動態融合的推薦模型;
4)在兩個公開數據集上分別與最新的序列模型和社會化模型進行對比驗證提出模型的性能。
1 相關工作
與基于協同過濾的推薦系統的集體智慧相比,序列推薦將重點放在用戶交互序列之間的依賴關系上,考慮物品之間的順序結構關系,通過對用戶交互物品進行序列建模,獲取用戶的興趣遷移。傳統的序列推薦方法主要基于馬爾可夫鏈,例如Feng 等[8]在下一項興趣點推薦(Point Of Interest,POI)推薦問題上,提出了一種個性化排序度量嵌入方法(Personalized Ranking Metric Embedding,PRME)來建模個性化嵌入序列,首先將POI嵌入到高維空間中,然后用歐拉距離表示兩個POI之間的轉換概率,同時加入用戶的興趣偏好,最后利用馬爾可夫鏈來預測下一項新的POI,并在兩個真實數據集上驗證了該模型的優越性。隨著深度學習的發展,越來越多的學者將眼光放在了深度學習上。深度學習中的循環神經網絡(Recurrent Neural Network,RNN)和卷積神經網絡(Convolutional Neural Network,CNN)模型都可以用來處理序列數據。Tang等[9]將在時間和潛在空間中最近一組項目嵌入到“圖像”中,并使用卷積濾波器學習順序模式作為圖像的局部特征。針對用戶的長短期興趣,Li 等[10]提出了區分長短期興趣的用戶動態推薦模型。Ma 等[11]利用矩陣分解的思想得到用戶的長期興趣,然后利用分層門控網絡(Hierarchical Gated Network,HGN)獲取用戶短期興趣,最后在預測層聚合用戶的長短期興趣。
然而不管是傳統的馬爾可夫鏈還是基于深度學習的RNN 或者CNN 模型都無法很好地處理長距離依賴問題。文獻[12]發現在機器翻譯中注意力機制因其可處理長距離依賴關系和可并行化處理的優勢,被廣泛應用在各類自然語言處理(Nature Language Processing,NLP)問題中。Kang 等[13]利用自注意機制來構建序列模型,通過實驗驗證了該模型的有效性。Liu 等[14]提出了一種基于會話推薦的短期注意/記憶優先級模型,通過注意力機制來獲取用戶最后一次交互產生的短期記憶,并從用戶的上下文中捕獲用戶的長期興趣,在3 個基準數據集上驗證了模型的有效性。
因評分矩陣的稀疏性,人們引入社交信息作為額外信息來緩解數據稀疏的問題。Yang 等[15]在矩陣分解的基礎上,提出了一種基于用戶共享表示的特征融合方式。將用戶與物品交互矩陣分解為用戶特征和物品特征,并將用戶社交矩陣分解為用戶信任特征和被信任特征,通過共享用戶特征和用戶信任特征來融合社交信息。Jamali 等[16]認為用戶的個性化特征與其朋友的個性化特征類似,在矩陣分解的基礎上增加約束項使用戶朋友的個性化特征與用戶的個性特征類似。Sun等[17]提出了一種基于遞歸網絡的時間社會推薦方法,利用上一時刻的長短期記憶(Long Short-Term Memory,LSTM)神經網絡輸出,通過注意力機制捕獲用戶朋友的長期興趣,然后將當前時刻的輸入和得到的社交信息輸入到LSTM 中得到用戶的動態興趣,同時利用用戶的長期興趣通過注意力機制來再次聚合用戶朋友的長期興趣,最后通過加權聚合用戶的長短期興趣。
以上方法忽視用戶的短期興趣和社交影響的動態特性,本文針對這兩點提出了一種社交信息動態融合的社會化推薦模型。
2 社交信息動態融合的推薦方法
2.1 符號定義
假設有M個用戶組成的用戶集合U,N個物品組成的物品集合R。對于每一個用戶u交互過的物品集合,按時間順序進行重新排序,構建用戶的交互列表Ru=。用戶通常含蓄的表達喜好,而不是給予準確的評分值。因此本文考慮隱式反饋的問題:如果用戶u在t時刻交互(點擊或收藏、購買)了物品i,則=1;否則=0。為了統一表示,本文使用i,j表示物品,u表示用戶,a,b表示朋友。使用F∈RM×M表示用戶之間的有向社交矩陣:如果用戶u收藏或關注了用戶b,則Fu,b=1;否則Fu,b=0。因為是有向社交關系,因此Fu,b≠Fb,u,Fu表示用戶u的朋友集合。
下一項推薦問題是在給定用戶的交互物品序列Ru=和用戶之間的社交關系Fu前提下,預測用戶在t+1時刻的交互行為。
2.2 模型框架
針對序列推薦中的數據稀疏問題,提出了一種社交信息動態融合的社會化推薦,其整體框架如圖2所示。整體分為3層,從下到上分別為處理用戶序列信息的短期興趣層、融合社交信息的社交融合層和預測用戶評分的預測層。

圖2 模型框架Fig.2 Framework of the model
為了實現對用戶興趣的動態描述在短期興趣層,使用自注意機制針對用戶的歷史交互行為構建序列模型,得到用戶的短期興趣。
如果用戶u在t時刻對物品i有興趣,一般近期交互過物品i的朋友和長期接觸物品i的朋友可能對用戶當前興趣產生更大的影響,因此將社交融合層,分為左側的社交短期興趣和右側的社交長期興趣,并使用具有時間遺忘的注意力機制對社交短期興趣進行建模,使用具有協同特性的注意力機制對社交長期興趣進行建模。
在社交短期興趣部分,利用用戶t時刻的短期興趣通過注意力機制融合朋友的短期興趣,得到用戶動態興趣特征,并將朋友行為的遺忘曲線加入到注意力權重中。在社交長期興趣部分,利用用戶t時刻的短期興趣Aut通過注意力機制融合朋友的長期興趣Va,得到用戶靜態興趣特征,并將用戶與朋友的杰卡德相似度系數加入注意力權重中。最后在預測層通過權重參數α和β融合社交的長短期興趣與用戶的短期興趣獲得用戶在t+1時刻的最終興趣:
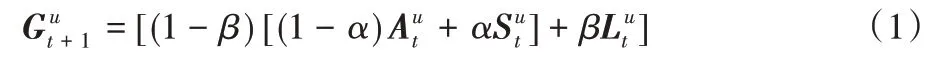
其中:表示用戶u在t+1 時預測的用戶興趣,α和β為自學習的權重參數。
下面分別從短期興趣層、社交融合層和預測層三部分詳細介紹本文的模型。
2.3 短期興趣層
因為自注意力機制在處理序列關系中可并行和處理長期依賴的優點,使用自注意力機制搭建用戶與物品的交互序列模型,通過短期興趣得到用戶u在t時刻的短期興趣特征。短期興趣層的整體結構如圖3 所示,分為特征嵌入層、位置嵌入層和自注意力層。
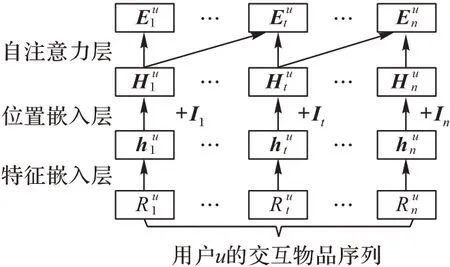
圖3 短期興趣層Fig.3 Short-term interest layer
隱式反饋只包含用戶id和物品id并不包含其它上下文及額外信息,為了豐富用戶表示,參照Word Embedding[18]思想,使用嵌入層將用戶和物品id 轉換為固定長度的向量,并通過神經網絡來學習潛在空間參數。
為了便于訓練,固定用戶交互物品的序列大小。取用戶交互物品序列中的最后n項物品作為模型的輸入,如果用戶交互個數小于n,則在序列的前端填充0。將用戶u的交互物品序列映射到d維的物品潛在空間得到固定長度的用戶交互物品嵌入特征,用戶id 映射到d維的用戶潛在空間得到用戶的長期興趣特征Vu。
因為自注意力機制平等的對待t時刻之前的每個交互物品,并不包含具體的位置信息,本文使用Vaswani 等[12]的固定位置嵌入方法:
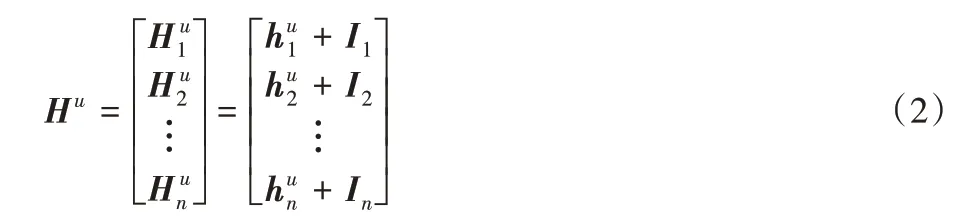
其中I=[I1,I2,…,In]表示位置信息嵌入矩陣。
注意力機制模仿人類眼睛的觀察行為,在機器翻譯任務等各類自然語言處理任務中證明自注意力機制的有效性,本文采用自注意力機制來構建序列模型[7],對于用戶t時刻的短期興趣具體定義如下:

通過對t時刻之前用戶交互物品的聚合,得到用戶在t時刻的短期興趣特征。為了賦予模型非線性并考慮不同潛在維度之間的相互作用,參照文獻[7]添加全連接層和多頭操作,并對自注意力和全連接層進行疊加,得到用戶的短期興趣Aut。全連接層定義如下:

2.4 社交融合層
2.4.1 社交短期興趣
當用戶u在t時刻對物品i感興趣時,若他的朋友a最近收藏或購買過類似于i的物品,那么朋友a可能對用戶u產生比其他未交互物品i的朋友更大的影響,并且朋友a的很久以前的行為與近期行為對用戶u的影響不同。基于以上考慮,提出了具有時間遺忘的注意力機制來對社交短期興趣進行建模。首先,利用2.3 節中的自注意層得到用戶朋友的短期興趣;然后,利用用戶的短期興趣在朋友的短期興趣中搜索那些與用戶當前興趣相似的朋友,并根據相似度賦予相應的權重,同時為了使不同時刻的朋友興趣對用戶的影響不同,在相似度權重中加入時間遺忘值,最后根據得到的權重聚合朋友的短期興趣。具體定義如下:

為了保持物品的有序性,將用戶朋友在t時刻之后交互的物品屏蔽掉;并且加入時間因素,當朋友短期興趣的時間ta距離當前時刻t越遠時對當前時刻的用戶影響越小。在注意力權重部分加入時間遺忘值,來減少距離當前時刻較遠的朋友興趣的影響,具體定義如下:

其中:時間t和ta的基本時間單位是周,為朋友a的行為對應的時間。
2.4.2 社交長期興趣
一般情況下,如果用戶u在t時刻喜歡物品i,那么長期與物品i交互的朋友能給用戶u提供更好的建議。在此基礎上提出了具有協同特性的注意力機制對社交長期興趣進行建模。利用用戶的短期興趣,通過注意力機制在朋友的長期興趣中查找與用戶當前興趣相似的用戶。同時通過杰卡德(Jaccard)相似度系數[19]進一步利用序列信息計算用戶與朋友的相似度,并將該相似度加入注意力權重中。具體定義如下:

同時考慮用戶與朋友之間的總體相似度,加入用戶與朋友之間的杰卡德相似度系數來加強那些與用戶相似度更近的朋友,杰卡德相似度系數定義如下:

其中:Ru表示用戶u交互物品的集合,∩和∪分別表示交和并操作。
為了穩定訓練過程并防止過擬合,加入layer Normalization 和dropout 操作[7]。針對2.3 和2.4 節中的任意網絡層(注意力層和全連接層),網絡層定義為z=y(x),增加層歸一化(layer Normalization)和dropout操作后的定義如下:

2.5 預測層
利用式(1)得到用戶的下一項推薦Gu t+1根據矩陣分解[20]的思想預測用戶在t+1時刻對物品i的喜好程度:

其中hi表示物品i在物品潛在空間的嵌入特征。
2.6 模型訓練
將t時刻之前的用戶交互物品作為模型輸入得到用戶在t+1 時刻下一項推薦,用二元交叉熵損失函數[7]作為目標函數,并將用戶的t+1 時刻的交互物品作為正樣本,用戶從未交互過的物品j作為負樣本:
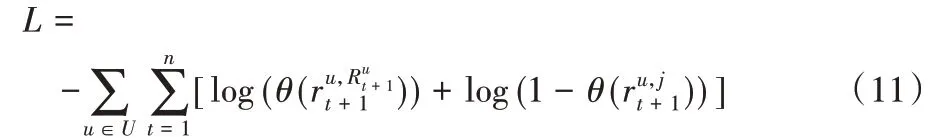
其中θ(x)=1/(1+e-x),將預測的喜好程度調整至(0,1)區間。
使用2014 年提出的Adam[21]優化算法,繼承了AdaGrad(Adaptive Gradient Algorithm)和RMSProp(Root Mean Square Prop)的優點,具有計算高效、方便實現和較好處理系數梯度等優點。整體算法流程如算法1所示。


3 實驗與結果分析
3.1 數據集
使用同時滿足序列信息和社交信息的兩個公開的隱式反饋數據集brightkite 和Last.FM,將兩個數據集的用戶交互物品序列按照時間戳進行排序來保證序列性。
brightkite 是一個基于位置的社交網絡數據集,用戶通過簽到來實時共享他們的位置。它包含了從2008年3月21日至2010年10月18日的用戶交互記錄及用戶之間的社交關系。Last.FM 是一個音樂數據集,記錄了從2005年8月1日到2011 年5 月9 日用戶對歌曲的評價及用戶之間的社交記錄,詳細的數據信息見表2。
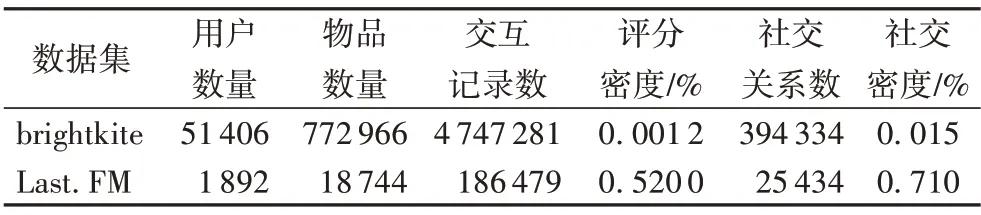
表2 數據集詳細信息Tab.2 Dataset detailed information
模型主要參數有:batch_lr表示每次訓練的用戶個數和學習率,maxlen 表示用戶的最大交互個數,dropout 表示丟失率,maxfriend表示最大的用戶朋友個數。兩個數據集的具體參數見表3。

表3 兩個數據集的參數Tab.3 Parameters of two datasets
3.2 評價指標
本文使用leave-one-out[7]來對數據集進行分類,將用戶的最后一個交互物品作為測試集來評估模型的最終性能,將剩余的交互物品作為訓練集。在評估推薦性能時,將測試集作為正樣本i,從未交互的物品集合中隨機抽取100 個物品作為負樣本,將正負樣本結合組成包含101 個物品的推薦物品列表,然后利用Top-N指標來評估模型性能。
本文使用的Top-N評價指標為HR@10[22]和NDCG@10[23]。
命中率(HR@10)評估在推薦列表的相似度排名中正樣本是否能排在前10,若排在前10則認為命中:

其中:U表示所有用戶的集合;lu,i表示正樣本i預測評分值在推薦列表中的排序位置;為指示函數表示正樣本i的排序位置是否在前10,是為1,不是為0。
NDCG@10 在HR 的基礎上加入了位置因素,當正樣本的排名越靠前時,推薦效果更好:

3.3 對比方法
為了驗證本文的模型,與使用了序列信息的序列推薦模型(BERT4Rec、SASRec)和使用了社交信息的社交推薦模型(DiffNet)進行對比驗證。
使用python 對數據進行預處理,利用tensorflow 實現SLSRec 模型,在高性能服務器(CPU 主頻2.20 GHz*24,內存126 GB,4 塊NVIDIA P100 的顯卡及2.7 TB 磁盤)上進行實驗。采用早停機制進行實驗,一次迭代200 次左右能達到最優推薦結果,訓練及評估運行時間在2 h左右。
SASRec[7]2018 年Kang 等提出的一種捕獲長期語義的自注意力序列推薦模型。
BERT4Rec[24]2019年Sun等提出的一種序列推薦模型,該模型首次將深度雙向順序模型和完形目標引入推薦系統領域,通過完形任務用雙向自注意網絡來建模用戶行為序列。
DiffNet[25]2019 年Wu 等提出的一種基于社會化推薦的深度影響傳播模型,設計了一個分層影響傳播結構,以模擬用戶的潛在嵌入是如何隨著社會擴散過程的繼續而演變的,以此來表示用戶如何受到遞歸社會擴散過程的影響。
3.4 實驗結果
3.4.1 SLSRec的性能測試
通過在兩個數據集上與所有的對比模型的比較來驗證本文模型的性能。3.3節中的對比模型都是用tensorflow 來實現的,并且針對兩個數據集對各個模型的參數進行了微調。針對DiffNet和BERT4Rec按照模型要求對數據集進行進一步處理,剔除了那些交互個數小于2 的用戶,并對剔除后的數據集進行了新的id 映射。因為BERT4Rec 對內存的要求很高,在數據量較大的brightkite 數據集上難以進行驗證。各模型在兩個數據集上的NDCG@10 和HR@10 的結果如表4 所示,其中最優的結果用加粗表示,次優的結果使用下劃線來表示,并在最后一行給出了SLSRec相較于次優結果的提升比率。

表4 不同模型在兩個數據集上的結果對比Tab.4 Comparison of results of various models on two datasets
從3.1 節數據集的分析中可以看出,brightkite 數據集中評分數據密度是遠遠小于Last.FM的,因此從表4可以看出在brightkite 數據集的所有模型的結果要小于在Last.FM 數據集上的結果。本文提出的SLSRec 在序列推薦的基礎上加入用戶的社交信息,來緩解數據稀疏問題。從表3 可以看出,針對數據密度較大的Last.FM 數據集,SLSRec 在HR 指標上有1.3%的提升,在NDCG 指標上有2.1%的提升,說明SLSRec的推薦結果的命中程度提升不大,但是命中物品的排名更高。相反,SLSRec 模型在數據密度較小的brightkite 數據集中HR指標有8.5%的提升,NDCG 指標有8.9%的提升,說明本文提出的SLSRec能有效緩解數據稀疏問題。
3.4.2 消融實驗
從圖2 中可以看出,社交融合層分為社交短期興趣和社交長期興趣兩個部分。同時分別在社交短期興趣部分加入時間遺忘值,在社交長期興趣部分加入杰卡德相似度系數。本文通過消融研究分析它們的影響,表5 顯示了SLSRec 的默認方法及其4 種結構在兩個數據集上的性能。下面分別介紹了變體并分析了它們的效果:
1)Short 結構:表示社交短期興趣部分,在序列推薦的基礎上僅僅加入用戶朋友的短期興趣,可以看出相對純粹的序列推薦模型該變體的推薦效果還是有所提升。
2)Short+time 結構:相對Short 結構加入了時間遺忘值Tt,ta,通過時間遺忘值來弱化那些相對當前時刻較遠物品的影響,從表4可以看出加入時間遺忘值之后推薦效果有所提升。
3)Long 結構:表示社交長期興趣部分,在序列推薦的基礎上僅僅加入用戶社交的長期興趣,相對于純粹的序列推薦模型有所提升并且提升幅度要大于加入社交的短期興趣。
4)Long+sim 結構:在Long結構的基礎上加入杰卡德相似度系數,在注意力權重的基礎上加強那些與用戶行為相似的朋友信息,相較于long結構效果有所提升。
5)SLSRec(Short+time+Long+sim)結構:利用α和β來融合Short+time結構和Long+sim 結構,從表5中看出總體效果有所提升。
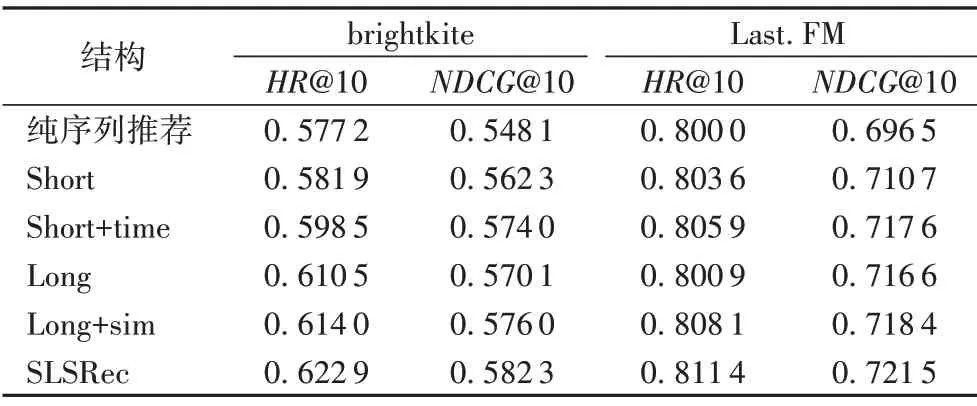
表5 兩個數據集上的消融實驗分析Tab.5 Ablation experiment analysis on two datasets
3.4.3 社交影響力分析
式(1)中的α和β通過自學習的方式來融合模型中各個因素的比例關系:α值可以反映模型中的用戶短期興趣和社交短期興趣的權重大小,如果α值越大則社交短期興趣的權重越大,否則用戶短期興趣的權重越大;β值表示社交長期興趣的的權重,越小則社交長期興趣的權重越小。
從圖4 可以看出,在數據較為密集的Last.FM 數據集中α都比較低,而在數據較為稀疏的brightkite 數據集中,α的值要遠大于Last.FM 數據集中的值,即:用戶行為數據越少,社交短期興趣對用戶最終興趣重構貢獻越大。β值在兩個數據集基本保持不變,說明社交長期興趣比較穩定,受到數據稀疏性的影響較弱。
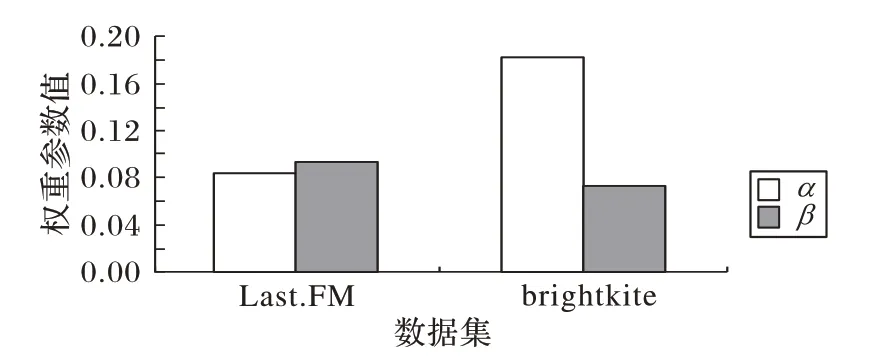
圖4 參數α和β的值Fig.4 Values of parameters α and β
3.4.4 最大朋友和最大交互物品的參數分析
圖5 展示了最大序列長度maxlen 和最大朋友個數maxfriend 對模型推薦性能的影響,maxlen 主要影響的是序列推薦的結果,maxfriend 主要影響的是社交融合的結果。因服務器內存的大小限制,無法運行maxlen 超過200 和maxfriend超過15的實驗。
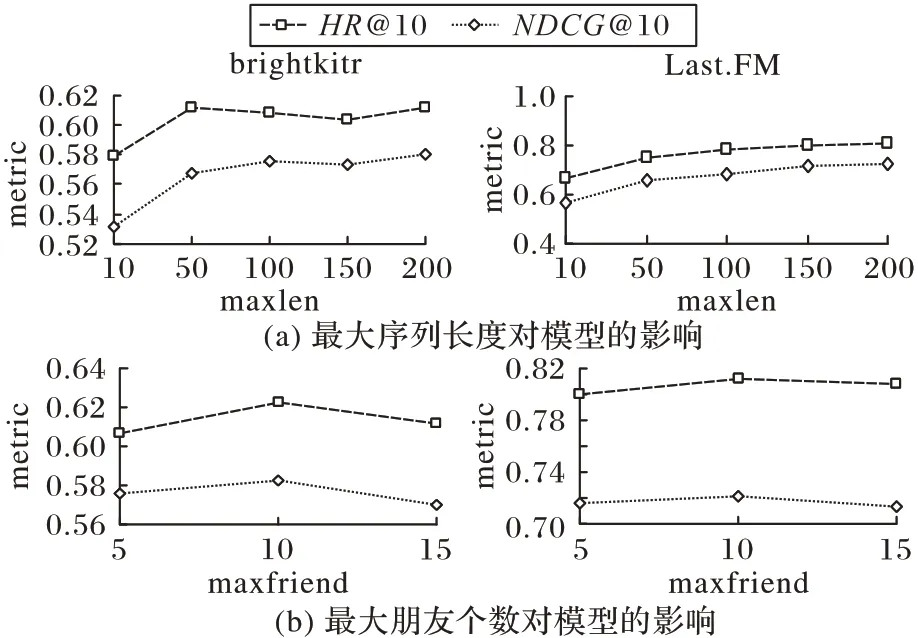
圖5 maxlen和maxfriend參數的影響Fig.5 Influence of maxlen and maxfriend parameters
從圖5 可以觀察到,maxlen 和maxfriend 對推薦結果的影響與數據的密度有關。對于數據密度較大的Last.FM 數據集,maxlen 影響較大,性能曲線呈現整體上升的趨勢;maxfriend 影響較小,性能曲線整體比較平穩。在數據較為稀疏的brightkite數據集中,maxlen影響較小,性能曲線整體比較平穩;maxfriend影響較大,性能曲線整體比較平穩。從兩個數據集的對比可以看出,本文提出的SLSRec模型在稀疏數據上能更有效地利用朋友興趣恢復用戶興趣進而提升推薦效果。
4 結語
針對社會化推薦模型忽視用戶動態興趣和朋友對用戶影響的動態變化的情況,提出一種社交信息動態融合的社會化推薦算法。首先,利用自注意力機制構建用戶短期興趣;然后,利用具有時間遺忘的注意力機制構建社交短期興趣,利用具有協同特性的注意力機制構建社交長期興趣;最后,融合社交的長短期興趣與用戶的短期興趣獲得用戶的最終興趣并產生下一項推薦。在實驗部分利用HR@10和NDCG@10指標對模型性能進行評估,結果表明SLSRec 算法在Last.FM 和brightkite數據集上相較于最新的推薦模型推薦效果都有所提升。本文主要利用朋友的一階關系,沒有進一步考慮社交網絡中的影響擴散,在下一步工作中將利用GCN 等網絡模型來捕獲不同時刻朋友興趣在社交網絡中的影響擴散。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
