Python在短臨氣象預報檢驗中的應用
2021-11-02 01:36:26何佳惠建忠何險峰王曙東高金兵
氣象科技 2021年5期
何佳 惠建忠* 何險峰 王曙東 高金兵
(1 中國氣象局公共氣象服務中心, 北京 100081; 2 華風氣象傳媒集團有限責任公司, 北京 100081)
引言
氣象服務的核心競爭力是不斷提升的預報質量。通過檢驗評估給出客觀結果,一方面便于管理人員進行考核,另一方面便于研發人員對比不同方法帶來的預報性能改變,促進產品不斷改進完善。
國家氣象中心建設開發的基于Web的國家級天氣預報檢驗分析系統[1],實現了涵蓋國家級省級智能網格預報、全國城鎮天氣預報等數十項檢驗業務產品的檢驗評估。用戶可以通過瀏覽器查看相應產品的檢驗反饋信息,為各省以及國家級預報業務考核提供了信息支撐。萬夫敬[2]等分析了ECMWF模式氣溫預報在青島地區的預報性能,根據模式誤差特點,給出主觀訂正參考值,提高了氣溫預報正確率。劉麗敏[3]等通過對中央臺精細化溫度預報在伊春市的檢驗和誤差分析,掌握其預報性能,在實際工作中有針對性加以訂正,為本地釋用提供依據。趙平偉[4]等開展了GPM IMAGE、ERA5降水數據在云南的適用性評估和對比。蔡曉杰[5]等利用上海沿岸海域19個站點風場資料使用平均誤差、預報準確率等指標對風速、風向、大風過程進行檢驗。吳瑞姣[6]等運用兩分類TS評分、鄰域法FSS評分方法對安徽省WRF模式短時強降水開展檢驗。鄭琳琳[7]等采用均方誤差、TS評分等方法對改進的降水臨近外推預報技術方法進行效果檢驗,得出新方法更具優勢的結論。劉湊華[8]等研究了基于目標的降水檢驗方法并對其改進后進行業務應用。可見檢驗在業務中發揮著重要作用。目前檢驗針對的產品在時次、時效上主要是天或小時量級,少有針對分鐘級這樣高頻次發布,高時間分辨率產品的檢驗。產品在時間維度精細化的提升意味著檢驗計算時間復雜度的增加。
Python是近幾年越來越受到開發人員關注和使用的編程語言。其簡潔、易于理解、功能豐富的特點無論是專業編程人員還是普通用戶都能夠快速上手。在氣象領域,推出了很多易用工具包。如標簽化多維數組和數據集xarray[9]——在吸收用于實現科學數據自我描述的通用數據模型(Common Data Model)基礎上,建立類似pandas的工具,使分析多維數組變得簡單、高效、不易出錯。國家氣象中心預報技術研發室使用Python研發了全流程檢驗程序庫[10],在數據層提供了數據讀寫、轉換等基礎函數;在檢驗算法層提供有無預報、多分類、概率預報等檢驗算法;在檢驗產品制作層提供了數值型、表格型、圖片型、誤差序列分析等函數,成為國內第一款專門用于氣象預報檢驗的python程序庫。本文在檢驗結果可視化階段使用了該庫提供的功能。
基于機器學習方法的短臨多要素氣象預報系統(Weather Elements Nowcasting based on machine learning, 簡稱WEN),每10 min滾動更新發布未來2 h多氣象要素,覆蓋中國區域的短時臨近預報,具有高更新頻次、高時空分辨率特點。系統在分布式計算環境下,建立72候(1年)×12時辰(1天每2 h為1個時辰)多預報時段復雜預報模型。如何快速獲得檢驗結果是本項工作面臨的挑戰。
如圖1所示,WEN檢驗子系統主要分為數據準備、檢驗計算和檢驗分析3個階段。第1階段進行數據讀取、合并,目標是設計通用的數據模型。第2階段進行檢驗計算,包括連續型數值預報檢驗、晴雨檢驗和降水分級檢驗3類檢驗方法,全部要素共計10個檢驗指標。第3階段分要素、區域對WEN模型進行性能評估。
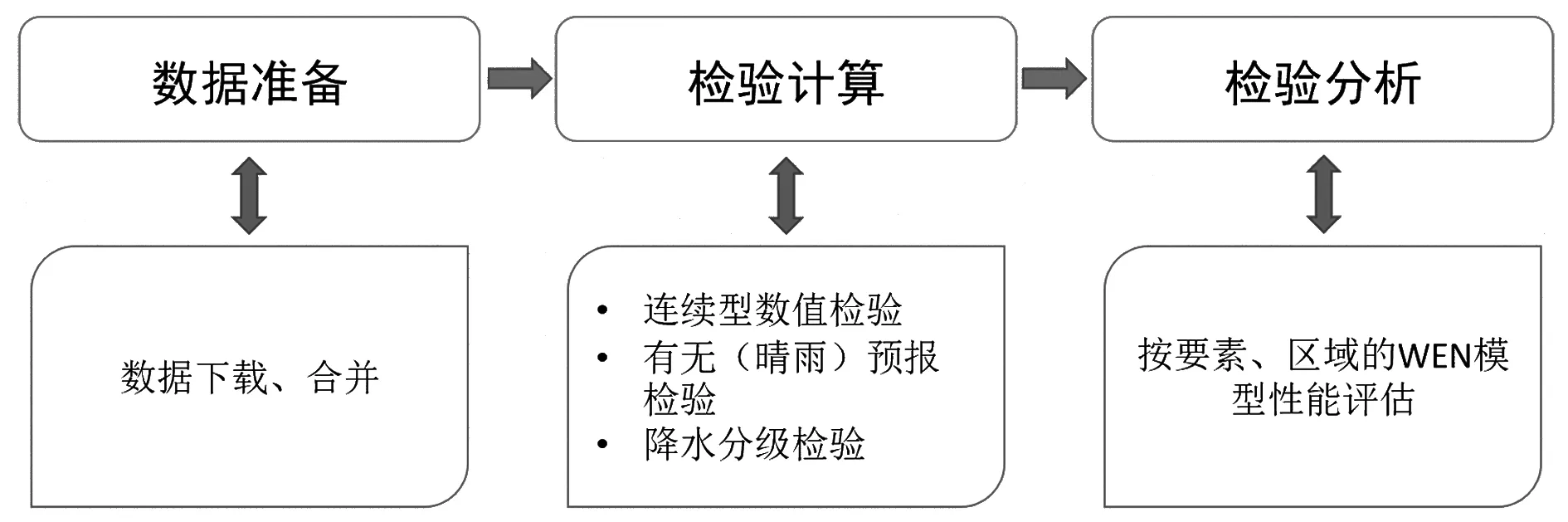
圖1 WEN檢驗業務流程
1 數據模型
1.1 檢驗數據
多維數組(又稱n維,ND ,有時稱為張量)是計算科學的一個重要部分,在很多領域都有應用,包括物理、天文學、地球科學、生物信息學、工程、金融和深度學習。在Python中,NumPy為處理原始ND數組提供了基本的數據結構和API。然而,真實的數據集通常不僅僅是原始的數字,它們有標簽來編碼關于數組值如何映射到空間、時間等位置的信息。Xarray在原始的與Numpy類似的多維數組上引入了維度、坐標和屬性形式的標簽,使得開發更直觀、簡潔、更少出錯。其核心數據結構Dataset被設計為NetCDF文件格式的數據模型的內存表示。
WEN系統采用網絡通用數據格式(Network Common Data Form,NetCDF),使用TDS工具(THREDDS Data Server,TDS)管理文件并提供數據訪問服務。預報和觀測數據(以下統稱檢驗數據)均為每10 min發布一次。每個時次發布的站點預報數據包括預報時刻、站點、氣象要素3個維度,觀測數據包括站點和氣象要素2個維度。
為避免每次在線獲取耗時缺點,同時提高處理和共享能力,采用地球科學科研領域元數據標準CF(Climate and Forecast Metadata Conventions)[11],將檢驗數據按天合并后保存到本地。數據模型構建分析如下:①檢驗用的站點數據屬于離散采樣幾何類型(Discrete Sampling Geometries);②一天多個時次更新發布,構成了時間序列(Time Series)。基于此,檢驗數據采用正交多維數組的時間序列數據表示方法,站點預報數據模型如圖2所示。預測數據模型去掉“預報時效”維度即為觀測數據模型。在計算機內存中對應Xarray的Dataset。在預測和觀測數據匹配時,通過表示位置的“station”和表示時間的“time”兩個“標簽”即可實現檢驗數據配對,體現了xarray直觀、簡潔的優點。

圖2 WEN檢驗數據模型(按天合并的站點預報)
1.2 結果數據
檢驗方法不同對應指標、要素不同。如晴雨檢驗和降水分級檢驗僅針對降水要素,包括TS評分、空報率等指標。連續型預報數值型檢驗包括平均誤差、均方根誤差等指標。WEN規定按候輸出檢驗結果。基于此,檢驗結果按檢驗方法分類生成,在時間維度包括時效、時辰等。
1.3 站點數據
傳統檢驗方法基于點對點的對比,即在一個時間點上參與檢驗的樣本數為該區域的站點數。WEN系統包括105567個站點。考慮觀測數據質量,選取包括國家級氣象站(基準站、基本站、一般站)和質控后的部分區域自動站,共計10656個站點。在此基礎上將全國分成8個區域,分區范圍見圖3,各分區站點數見表1。
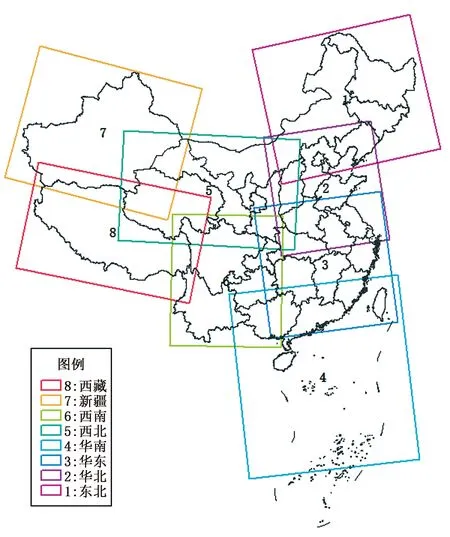
圖3 檢驗分區示意

表1 分區站點數
2 檢驗計算
WEN采用連續型預報數值檢驗、有無預報檢驗(晴雨預報檢驗)和多分類檢驗(降雨分級檢驗)等3類檢驗算法。后兩類屬于分類問題,前者是常見的二分類,后者是類別數大于2的分類。在分類算法的實現中應用混淆矩陣獲得分類樣本統計。針對耗時任務給出了并行解決方案。
2.1 檢驗方法
連續型預報檢驗采用平均誤差、平均絕對誤差、均方根誤差、偏差4種統計方法,檢驗變量包括氣壓、溫度、相對濕度、風速等近地面要素。降水采用技巧評分(TS)、相當技巧評分(ETS)、空報率、漏報率、預報偏差、準確率6種檢驗方法。上述方法已在業務中廣泛應用,在此不做詳細介紹。計算公式主要參考由陳昊明等[12]的高分辨率區域數值預報業務檢驗評估指標及算法。降水分級檢驗主要參考關于下發中短期天氣預報質量檢驗辦法(試行)的通知(氣發〔2005〕109號)中中短期天氣預報質量檢驗辦法(試行)解釋說明(表2)和短時氣象服務降雨量等級劃分[13](表3)。
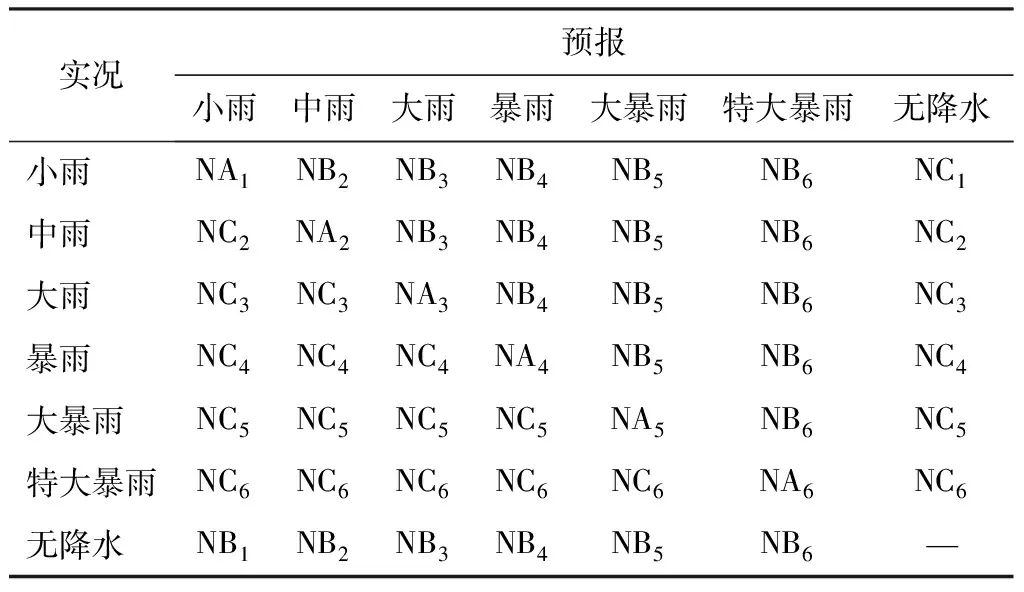
表2 降水分級檢驗評定簡表
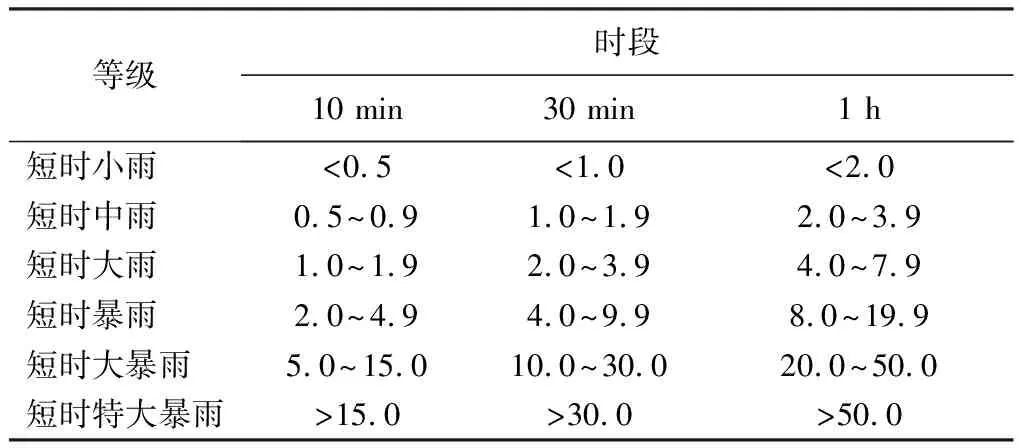
表3 短時氣象服務降雨量劃分 mm
2.2 數據缺失處理
為保證檢驗結果的正確性及連續性,缺失數據的處理是必不可少的關鍵步驟。數據缺失有兩種表現,一是數據文件缺失,二是數據文件中存在空數據。第1種情況表明某時次沒有可用于檢驗的數據,可將檢驗結果置為一個約定值,例如-999。第2種情況則需要將空數據去除,從而保證統計樣本的有效性。需要注意的是空數據并非一一對應,可應用公共掩碼矩陣對檢驗數據進行剔除。技術實現的關鍵代碼見圖4。
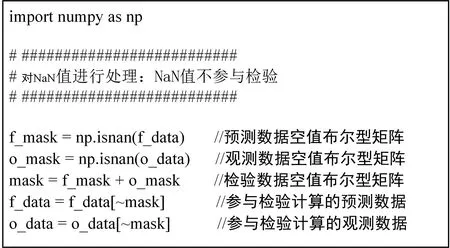
圖4 缺失值處理關鍵代碼
2.3 混淆矩陣
混淆矩陣是機器學習中總結分類模型預測結果的情形分析表,以矩陣形式將數據集中的記錄按照真實的類別與分類模型預測的類別進行判斷匯總。其中矩陣的行表示真實值,矩陣的列表示預測值。基于Python語言的機器學習工具scikit-learn的metrics模塊的混淆矩陣函數confusion_matrix實現了混淆矩陣的計算。通過傳遞真實類別和預測類別樣本,返回一個n階矩陣C(n表示類別數,如二分類n=2),Ci,j表示真實類別為i預測類別為j的樣本數量。以二分類晴雨檢驗為例,C0,0表示真反例即命中否的樣本數,對應表2中ND;C1,0表示假反例即漏報的樣本數,對應表2中NC;C0,1表示假正例即空報的樣本數,對應表2中NB;C1,1表示真正例即命中的樣本數,對應表2中NA。二分類混淆矩陣與晴雨判定對應關系見表4。通過將氣象領域分類檢驗的判定表與機器學習領域分類模型評估分析表即混淆矩陣建立對應關系,應用混淆矩陣函數實現分類檢驗計算公式中各參量,再根據公式最終獲得檢驗計算結果。晴雨檢驗計算實現的關鍵代碼見圖5。

表4 混淆矩陣晴雨檢驗對應關系

圖5 晴雨檢驗計算實現代碼
2.4 并行計算
2.4.1 并行計算概念、方式、環境
從計算復雜性的角度來看,一個算法的復雜性可表示為空間復雜性和時間復雜性兩個方面。并行計算(Parallel Computing)的基本思想是用多個處理器來協同求解同一個問題,即將被求解的問題分解成若干個部分,各部分均由一個獨立的處理器或處理機來并行計算。并行計算的目標就是盡量減少時間復雜性,通常這是通過增加空間復雜性來實現的。并行計算可分為時間上的并行和空間上并行。時間上的并行就是指流水線技術。空間上的并行則是指多個處理器并發的執行計算。并行環境多為MPP(Massively Parallel Processing,大規模并行處理)并行機。不同于普通PC機,通常并行機有特定的系統結構,支持指定的并行環境(常見的有MPI(Message Passing Interface)),硬件價格昂貴,同時并行計算的實現也是一項復雜而艱巨的工作。
曹曉鐘等[14]針對大量神經網絡訓練、預報的需求,在SP2并行機上實現了基于主從計算模式,采用粗粒度任務劃分的并行方案。趙軍等[15]在多核高性能計算機上使用MPI/OpenMP混合并行計算編程,以增量方式和較小的并行化代價實現了對AREM模式并行化改進,取得了較好的并行計算效果。二者均是在特定并行機環境下實現的并行化。周欽強等[16]采用Java語言基于Eclispes平臺開發實現了基于TCP多連接通信實時并發數據處理系統,滿足對周期性大批量浪涌數據進行實時快速處理的要求。系統運行于單處理機上。其主要利用線程池化技術和并發管理機制,實現過程不僅需要對不同線程進行詳細的程序流程分析,還要處理復雜的線程安全問題,開發成本相對較大。韓帥[17]等利用多節點分塊并行與模式并行結合的計算方案,解決了系統文件大小受限、計算資源和計算時效等問題。是一種時間和空間二維并行的方案。
2.4.2 DASK并行計算框架
DASK是一款開源免費、與現有科學計算項目Numpy、Pandas、Scikit-Learn高度協同的基于python語言的并行計算框架[18]。它以一種更方便簡潔的方式處理大數據量,能夠在普通單機或集群中進行分布式并行計算。DASK由兩個部分組成,動態任務調度和“大數據”集合。動態任務調度包括單機調度器和分布式調度器,分布式調度器可以在單機上運行,提供了比單機調度器更豐富的功能,如診斷面板。在單機中通過scheduler參數設置線程或者進程來并行處理,也稱為偽分布式。“大數據”集合提供的3種基本數據結構分別是arrays、dataframes、bags。Arrays是對Numpy中的ndarray的部分接口進行了改進,從而方便處理大數據量。Dataframes是基于Pandas DataFrame改進的一個可以并行處理大數據量的數據結構。以上兩者通過對大數據量進行分塊處理,提供了大于內存數據的解決方案。Bags主要用于半結構化的數據集,比如日志或者博客等。DASK提出的延遲計算是在一個普通的Python函數上面通過dask.delayed函數進行封裝,得到一個delayed對象。該對象只是構建一個任務圖(Task Graph),并沒有進行實際的計算,只有調用cumpute的時候才開始進行計算。延遲計算非常適合當面對的問題是可并行的但是不適合高度抽象如Dask Array或Dask Dataframe的場景。下面給出一段在單機上使用分布式調度器、延遲計算、多進程實現并進行化的代碼示例,見圖6。

圖6 一種DASK并行化示例代碼
2.4.3 WEN檢驗并行化實現
并行計算首先是一種解決計算問題的思想。分析WEN檢驗,以數據準備環節為例,處理過程分為兩個步驟:①讀取數據,這個操作對每個文件是相同的;②所有文件讀取結束后進行合并操作。讀取一個文件是一個獨立動作,互相之間無依耐關系,可同時執行。利用dask.delayed將讀取文件進行并行化改造。以處理156個觀測文件(1 d+2 h)為例,程序分別在兩臺具備不同核數的普通PC機上運行。考慮網絡帶寬時間維度不均勻性,為使測試結果更客觀,選取2020年9月1—5日,每個日期在不同時間分3次運行,分別記錄每次的運行時間,再計算平均用時。并行前后程序執行時間見表5。以平均數衡量,56核處理機效率提升11倍,96核處理機效率提升9倍。進行并行化改造增加的代碼不超過10行。
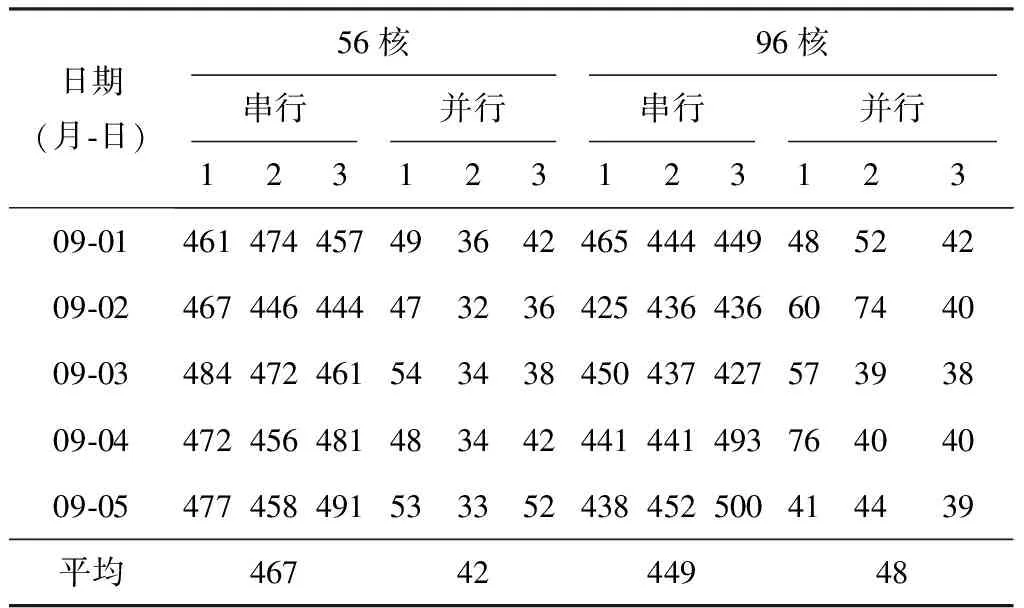
表5 觀測數據采集合并運行時間測試結果 s
運用相同思路,對檢驗計算環節代碼進行并行化改造。以計算1天數據每個時次每個時效數值型預報檢驗為例(僅9月1日數據缺失36個時次,其它日期完整),時次和時效兩個維度同時并行,即并行任務有144×12=1728個,測試結果見表6。并行后,56核環境效率提升20倍,96核環境提升51倍。改造后的關鍵代碼見圖7。

圖7 WEN數值型檢驗方法并行化實現關鍵代碼

表6 連續型數值型預報檢驗(每時次每時效)運行時間 s
從測試結果來看,效率提升并非與CPU核數成線性遞增。首先,該測試結果采用單機多進程并行方案,且并行任務數大于核數,即并行任務與CPU并非一次分配到位,而是進行了多次分配。其次,當進程間傳輸數據較大時,會產生性能損失。從表5和表6并行方案測試結果來看,96核環境耗時均高于56核環境。但總體上計算效率并行方案都遠高于串行方案。
對于串行方案,表5測試結果顯示,56核環境略高于96核,但相差不大。主要原因是表5對應的業務屬于IO密集型,主要受實時網絡流量影響,受CPU型號差異帶來的性能影響較小。表6測試結果,96核環境耗時是56核環境的3倍左右。表6對應的業務屬于計算密集型,主要受CPU性能影響。56核環境CPU型號高于96核環境。兩者的型號分別是56 Intel(R) Xeon(R) Gold 5120 CPU @ 2.20 GHz和96 Intel(R) Xeon(R) CPU E7-8850 v2 @ 2.30 GHz。
3 檢驗分析
圖8是2021年3月1~6候模型的全國區域氣溫要素檢驗結果(篇幅有限僅以氣溫要素均方根誤差指標為例進行說明)。圖中橫軸表示一個候的預報模型,每個刻度代表一個模型(即每天12個時辰之一,世界時)。從圖中可以看出,①3月WEN模型氣溫均方根誤差最大4.77 ℃(第1候第11時辰),最小1.13 ℃(第4候第5時辰);②每候總的趨勢表現為:后5個時辰較前7個時辰大,即夜間(北京時晚10:00至次日早08:00)誤差較白天大。對比了21年3—5月的檢驗結果,發現不同月份表現差的模型均集中在夜間。
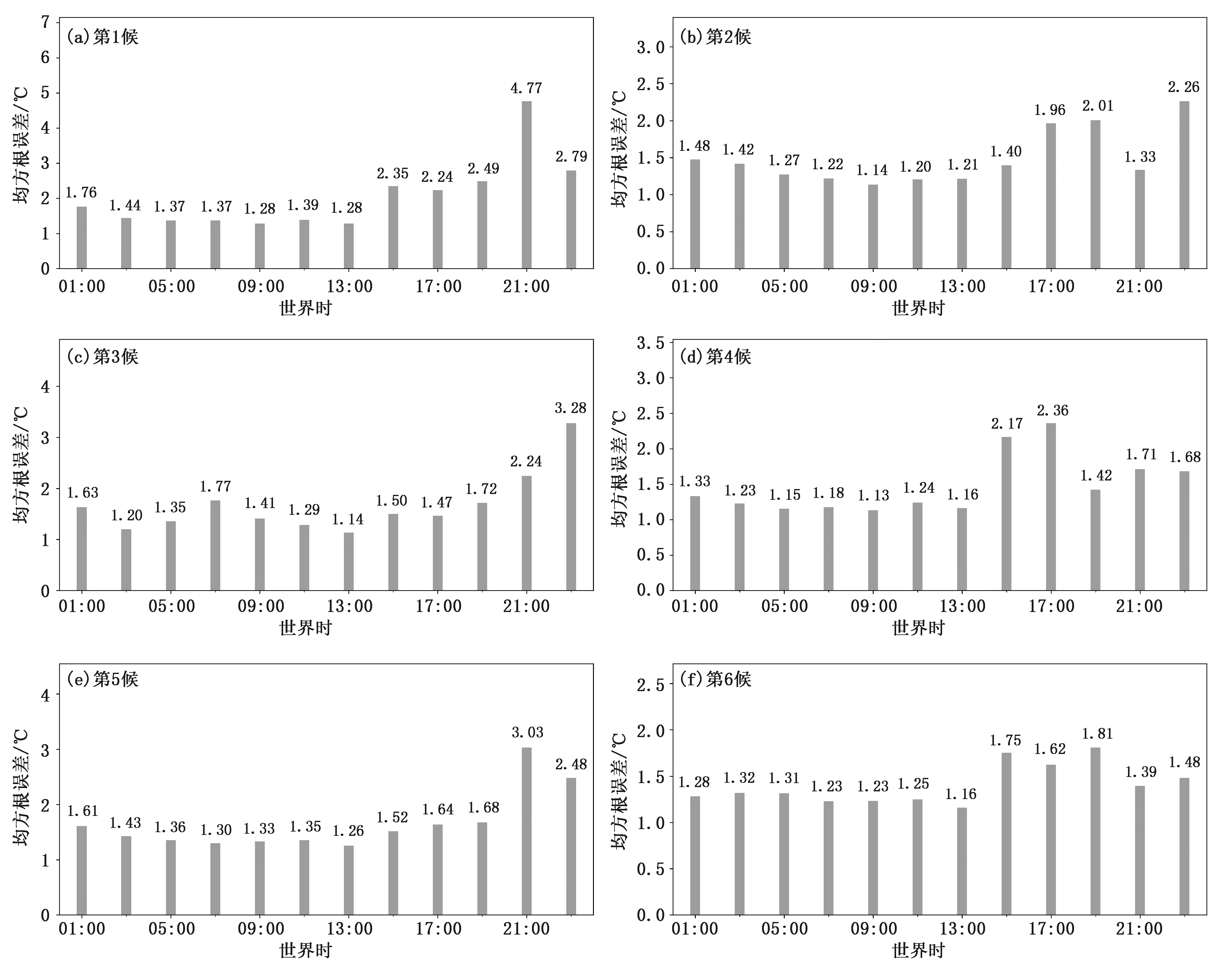
圖8 2021年3月第1~6候WEN模型全國氣溫均方根誤差
4 結論
本文在分析業務需求的基礎上,設定快速計算為目標,重點圍繞氣象領域檢驗分類問題和應用并行計算改善時效性兩個方面,設計并實現了針對高頻次、高時間分辨率短臨氣象預報產品的檢驗系統。今后將圍繞檢驗報告自動生成、容器化部署等開展工作,推動公共氣象服務中心產品檢驗業務常態運行,為實現氣象服務高質量發展貢獻力量。
