面向語言障礙篩查的漢語兒童言語交際水平評估系統研發
2021-10-30 17:25:37陸爍丘國新錢思宇高樂妍
語言戰略研究 2021年6期
關鍵詞:數據庫
陸爍 丘國新 錢思宇 高樂妍

提 要 中山大學中文系神經語言學教學實驗室面向語言障礙篩查開發的漢語兒童言語交際水平評估系統,以一套固定程序作為引導,能在短時間內快速采集兒童的言語數據。基于這個評估范式,實驗室采集了大量2~14歲兒童言語交際過程中的言語數據,從語音、能產性、流暢度、語法、語義、邏輯六大語言維度出發,細分為16項指標對語料進行人工標注和機器識別,建立起一個應用于語言能力評估和語言障礙篩查的漢語兒童言語數據庫,可以精準評估漢語兒童的言語交際水平。目前該語料庫儲存了966名漢語兒童的言語數據,并對638名兒童的語料進行了標注。該語料庫可以對兒童語言障礙的智能化篩查提供機器學習訓練數據,也可以為研究漢語兒童語言習得和各類兒童語言障礙提供數據資源支持。
關鍵詞 兒童語言障礙;語言評估;言語交際;數據庫;語料庫
中圖分類號 H002 文獻標識碼 A 文章編號 2096-1014(2021)06-0045-14
DOI 10.19689/j.cnki.cn10-1361/h.20210604
Developing a Speech Communication Ability Evaluation System
for Screening Language Disorders in Chinese-Speaking Children
Lu Shuo, Qiu Guoxin, Qian Siyu and Gao Leyan
Abstract Language is an indispensable communication tool for human beings, and language ability is an essential skill that children must acquire in their development. Oriented to the language disorders in Chinese-speaking children, an evaluation system has been developed by the Neurolinguistics teaching laboratory at Sun Yat-sen University to measure Chinese childrens speech communication ability and screen language-related disabilities. Using a fixed procedure as a guide, the system can collect childrens speech communication data in a very short time. Based on this evaluation paradigm, a speech corpus of Chinese-speaking children for language disorder screening was established, and up to now data of 996 children aged between 2-14 have been collected. The data are evaluated from six linguistic aspects (including phonology, productivity, fluency, grammar, semantics, and logic) with 16 indicators recognized by both manual annotation and machine recognition. Currently, the data of 638 Chinese-speaking children have been processed and annotated. Such a corpus can offer an affluent training set for automatic screening of childrens language disorders, and provide resource for studies on language acquisition and language disorders.
Keywords Childrens language disorder; language evaluation; speech communication; data base; corpus
一、引 言
語言是人類必不可少的溝通交流工具,也是兒童發育過程中需要習得的核心能力。兒童在母語習得過程中常常會發生語言理解、加工、整合、產出的水平低于同齡兒童的現象,如發音困難、發音不準確、詞匯匱乏、話語過于簡單、不愿意說話等等,即出現兒童語言障礙的現象。據統計,6%~8%的學前兒童無法達到預期的語言發展目標(Tomblin et al. 1997;Collisson et al. 2016;Norbury et al. 2016)。本研究采用廣義上的兒童語言障礙概念,既包括由于聽力或其他感官損傷、神經功能發育異常等疾病引起的語言障礙,也包括原發性而非其他疾病衍生的發展性語言障礙(Developmental Language Disorder,DLD)。
兒童語言障礙往往難以與語言發育遲緩完全區分開來,許多身體正常發育的兒童都會出現語言發育遲緩的現象,尤其常見于兒童發育早期。有的兒童隨著年齡的增長會逐漸達到同齡正常語言水平,有的則可能發展為語言障礙。倘若兒童的語言發育問題得不到有效的識別和干預,則不僅會阻礙兒童語言理解和語言表達能力的發展,還將對兒童的身心健康、學業以及未來的職業發展產生不良影響(Whitehurst et al. 1991;Bishop 2000;Rescorla 2009)。因此,在漢語兒童群體中廣泛開展語言能力評估,盡早準確地篩查出兒童語言障礙,應是兒童語言工作的重中之重。
語言的基本功能就在于交際,因此在兒童語言障礙篩查過程中,要側重對兒童言語交際能力的評估,即將兒童在言語交際過程中的行為作為評估其語言水平的核心內容。但由于兒童的配合度低、專注力差,在短時間內充分觀測到兒童的言語交際水平極為困難,因此目前國內外都缺乏通行而有效的兒童言語交際能力評估方案,國內大多數兒童語言障礙診斷都基于監護人報告或長時間的測評,且以引進西方量表為主,對漢語的特性考慮不足,往往只是對某方面語言能力的評估(如詞匯理解),尤其欠缺對言語交際能力的評估。要直接評估兒童言語交際水平,對兒童的言語進行分析評估是最為直接和可觀的。近些年來語料庫成為語言學研究領域常用的數據庫形式之一,國內外基于兒童語料庫建設對語言障礙診斷與語言發展測評進行了一定的探索,取得了顯著的成績。數據庫,尤其是語料庫的建設,在語言障礙篩查領域有著廣闊的應用空間。
本研究設計了一套面向語言障礙篩查的漢語兒童言語交際水平評估范式,能在短時間內快速評估兒童的言語交際水平。基于這個評估范式,我們采集了大量2~14歲兒童言語交際過程中的言語數據,對數據進行了六大語言維度、16項細分指標的語料分析標注,建立起一個可應用于語言能力評估和語言障礙篩查的漢語兒童言語數據庫。
(一)兒童語言能力評估概況
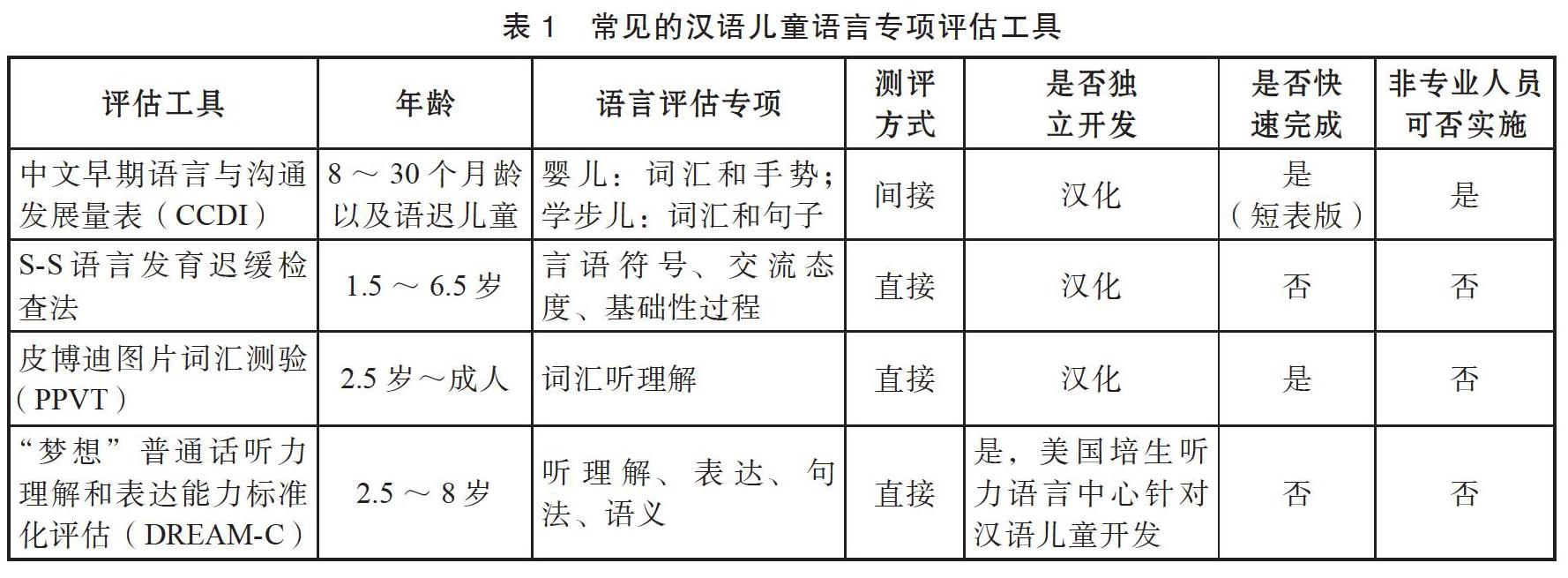
目前國內外兒童語言能力測評工具類型包括調查問卷、訪談照顧者、環境觀察、標準化評量工具、語言樣本分析等(锜寶香2006)。大多數語言測評都選擇使用標準化的評估工具,以便實現良好的信度和效度水平。按照評估對象劃分,可以分為直接評估和間接評估兩種:前者直接對兒童的語言表現進行測評;后者則通過監護人填寫問卷等方式間接測評,往往用于低齡幼兒。按照評估內容劃分,標準化評估方法又可分為綜合發育評估和語言專項評估。
中國對兒童語言問題的認識起步較晚,較為成熟的漢語兒童語言能力測評量表相對欠缺。在專門針對兒童語言能力進行評估的工具中,既有基于西方國家的語言量表進行漢化的評估工具,也有少數針對漢語獨立開發的語言評估量表。常見評估量表情況如表1所示。
從中不難發現,當前漢語兒童語言能力評估方法具有以下問題:
一是廣泛引進西方的標準化評估量表,缺乏自主研發的、可行性和科學性較高的評估工具。毋庸置疑,對漢語兒童直接使用從外語翻譯為漢語的量表是不夠科學的。因此,在借鑒西方量表時要考慮語言文化背景,并建立不同地區、年齡和年級兒童語言能力的常模。同時,當前亟待開發出具有漢語特色、推廣性強的語言功能評估工具。在這一方面,臺灣地區做出了較好的示范,從早期翻譯國外量表走向開發本土化評估工具,如“國小兒童語言能力評量工具”(林寶貴,锜寶香2000)、“話語學齡兒童溝通及語言能力測驗”(黃瑞珍,等2014)等。考慮到大陸地區各省不同的語言環境,語言評估工具的開發和推行則更具挑戰性。
二是偏重低齡兒童,對于學齡期兒童關注不足。這是國內外兒童語言發育進程評估方法的共同問題。對低齡兒童的語言關注較多,并在此基礎上進行早期的指導與干預;但這也導致了大齡兒童的語言評估存在缺口,社會對兒童語言的持續發育情況不夠重視,以至于許多學齡兒童的語言障礙得不到識別。
三是全面性弱、精細化程度低,尤其欠缺對言語交際能力的評估。已有的兒童語言發育評估大多關注兒童某方面的語言能力,其中詞匯評估占據了很大的比重,而其他語言能力的評估則十分缺乏(黃文橋2020)。許多量表屬于綜合性發育評估量表,語言只是綜合評估的一部分,因此不夠全面。另外,語言是交際的工具,習得語言的目的就在于在交際中運用語言,因此對言語交際能力的評估應是兒童語言發展評估的重要內容。
四是測評時間普遍較長,需要專業人員輔助實施。由于兒童注意力容易分散,耗時較長的測評方案實際上難以精確地測量兒童的語言能力,因為兒童常常因對測試內容缺乏興趣或于測試后期出現倦怠心理而放棄繼續測評。中國是人口大國,現有的醫療資源也難以保障對兒童進行長時間的一對一測評。因此,開發一套快速且高效、易于執行的兒童語言測評工具至關重要。
(二)基于語料庫建設的兒童語言發展評估
近年來,隨著計算機科學與人工智能技術的發展,語料庫和大數據分析成為語言學研究熱門路線,基于兒童語料庫建設的語言研究和語言能力評估、語言障礙診斷也不斷涌現。
目前國外兒童語料庫建設最成熟的成果是兒童語言數據交流系統CHILDES(Child Language Data Exchange System),它是目前世界范圍內使用最廣、規模最大的兒童語料庫,包括三大部分——兒童語言數據庫、錄寫賦碼系統、自動分析系統。目前,DATA數據庫收錄了全世界包括漢語普通話和粵方言在內的28種語言的兒童語料,支持產出了超過3000篇研究論文(詳見溫志軍,胡瑰玲2001)。截至2020年12月,在CHILDES系統數據庫中,漢語普通話兒童語料庫包含19個涉及不同話語場景的子語料庫,以3~6歲兒童言語數據為主。另外,國內也建成了一些出于特定研究目的的小型語料庫,如中國社會科學院語言研究所基于對23名兒童3年左右的縱向觀察建立的漢語普通話兒童語音庫(高軍2012);張廷香(2010)建立的3~6歲漢語兒童語料庫;胡亞娟(2015)、楊金煥(2016)先后建立的3~4歲、4~5歲漢語兒童語料庫,分別探究幼兒語言的性別差異和會話能力發展情況。這類語料庫通常規模較小,標注內容服務于特定研究目的。
在語料庫的應用方面,華東師范大學兒童語言研究中心團隊基于341名3~6歲漢語兒童自由游戲語料,參考CHILDES中的KIDEVAL指令,初步構建了漢語兒童詞匯和語法發展常模與指標體系,并依此探索可預測兒童語言障礙的指標,因而可應用于語言障礙診斷與語言發展測評(張義賓2019;周兢,張義賓2020)。這是探究漢語兒童語言發展規律及篩查語言障礙的有益探索,但一方面仍需進一步拓展兒童常模的年齡范圍,另一方面所觀測的指標也不應僅限于詞匯和語法。
總體而言,目前漢語兒童語料庫建設及研究仍存在以下不足:(1)語料標注不充分。考慮到漢語語言學個性特征,照搬其他語言的標注經驗不可取,而且現有的兒童語料標注側重詞匯、語法等有限維度,缺乏對兒童語料和語言能力研究的全局視角。(2)語料庫建設發展不平衡,單個語料庫所涉及的兒童人口學特征(如年齡、民族、居住地等)單一。(3)語料庫的應用價值亟待開發。豐富完善的兒童語料庫在語言障礙和相關疾病篩查、人工智能等領域有廣闊的應用潛力。(4)亟待應用大數據機器學習方法。無論是國際兒童語料庫,還是漢語兒童語料庫,都已經由單純的語料共享向兒童語言發展測評、語言障礙診斷系統建設轉變,初步印證了基于大數據語料分析這一非標準化評估方法在漢語兒童語言測評中的可行性。面對現有兒童語言發展評估工具不足的困境,迫切需要通過人工智能的方法來自動、定量地衡量兒童語言發育的情況(Leit?to et al. 1997)。
二、面向語言障礙篩查的漢語兒童言語交際評估方案
(一)設計思路
我們設計的面向語言障礙篩查的漢語兒童言語交際水平評估范式首先全部采用圖片、視頻、音頻形式來向兒童呈現評估任務,趣味性較強,過程中采集兒童的言語錄音。其次,為了實現語言障礙的篩查、分類、定級,需要對不同說話人的語料進行橫向對比,因而全套評估以一套固定程式為引導,以實現多個兒童言語樣本具備可供比較的特征。再者,考慮到兒童容易出現注意力分散的問題,我們在題量上進行了控制,可以在大約10分鐘內快速、充分引導出兒童的最優言語表現。
評估所用的固定引導程序涵蓋重復跟讀、重述、自主發言等多種言語模式,不同題型的題目內部在語言學特征(如詞頻、句長、語法和語義復雜度等)存在難度差異,遵循由易到難的階梯分布,能采集到兒童真實且豐富的言語數據,進而評估兒童的綜合言語交際能力。
(二)固定引導程序
測試分為3種題型,分別為圖片內容復述、視頻內容復述和自主發言,一共7道題目。下文舉例介紹3類題目的內容。
1.圖片內容復述
這一類又分為聽錄音復述和看圖說話兩種。聽錄音復述題目的測試程序會自動播放關于圖片內容的指導語錄音,兒童需要在此基礎上自己復述圖片的內容。本組共3道題目,難度依次提升,測試形式如圖1所示。看圖說話部分無指導語,兒童直接看圖描述故事內容,測試形式如圖2所示。
2.視頻內容復述
兒童需要認真觀看兩個短視頻,第一個有指導語,第二個無指導語,觀看完成后復述看到的內容。測試形式如圖3所示。
3.自由發言
從3道自主發言題目中任選一道回答。兒童無須按照回答“提示”一一回答,只要所講內容與題目相關即可。以題目1“自我介紹”為例,向兒童提問:“請談談你自己,比如你和你的爸爸媽媽是哪里人,你今年幾歲了,你有沒有兄弟姐妹,你平時有什么興趣愛好,喜歡吃什么東西,等等。”
(三)數據采集方法
為了實現漢語兒童言語交際水平的評估,要保質保量地完成兒童言語數據的采集,即利用固定程序引導兒童發音并儲存語音數據。我們通過中山大學中文系神經語言學教學實驗室開發的數據采集軟件進行一對一的兒童語言數據采集。在采集數據時,需保證環境安靜、無明顯噪音,最好在單獨的封閉房間內進行。對于低齡幼兒,父母或老師可在一旁陪同以穩定兒童情緒,但避免對兒童進行過度提示(如直接告訴兒童如何作答)。在評估過程中,兒童的語音數據將以題目為單位進行儲存,相關數據將直接傳送到后臺。另外考慮到兒童單次錄音可能失敗,如意外錄入他人的說話聲、環境噪音,或兒童拒絕發言等情況,每道題目允許重復錄音2次,以最終次為準。
三、面向語言障礙篩查的漢語兒童言語交際水平數據庫建設
在獲取兒童的原始語料后,首先對數據歸檔,分別以被試和題型為單位,分類儲存原始音頻數據,建立起漢語兒童言語交際數據庫;其次,通過全面和詳細的語料標注實現數據的對齊。由于兒童的語言尚在發展期,對語言障礙的篩查應當涉及語言的多個維度和層次,如基礎層級上的發音準確性和高級層次上的表達邏輯性等,因此我們設定的言語標注項為語音、語義、語法、能產性、流暢性、邏輯性六大維度,可細分為16項指標。
(一)數據標注方法
1.標注的前期處理及標注軟件
數據處理由3名具有語言學專業背景的研究生進行,在語料標注環節進行3輪標注,以確保標注的可靠性。一般質量良好的數據可直接進行語料標注。但在以下情況下需要對音頻進行剪輯和降噪
處理:
①若音頻中有測試人員的說話內容,需全部剪切;
②若音頻含有背景噪音,與人聲相混,應降噪至能聽清人聲的標準。
若經過預處理后,音頻質量仍然不合格,如環境噪音過大、降噪后過于失真等,則舍棄這部分不合格音頻。本研究所涵蓋的510名被試均完成了語言測評,且音頻質量良好。
經過預處理后的音頻數據,使用獨立開發的面向特殊人群的語料標注軟件系統(見圖4)進行語料轉寫,并輔以語料標注。該系統包含以下功能:音頻信息顯示、標注音頻的自動播放切換、調整音頻播放進度、機器自動輔助標注、人工標注自動合并、多輪標注計算沖突項目、自動生成沖突音頻數據庫。標注完成可保存該段音頻的詳細標注信息(.json格式),同時得到一個自動生成的標注數據表(.csv格式)。
2.標注項目
由于兒童語言障礙具有不同的類型,如聽理解障礙、構音障礙、語用障礙等,對兒童言語數據的標注和評分也應該覆蓋多個方面,才能實現對兒童語言障礙的有效分類和定級。在數據庫建設方面,相較于儲存原始兒童言語數據的生語料庫,經過細致專業標注的熟語料庫無疑更具研究價值。因此,我們采用獨立開發的轉寫標注軟件對語料進行轉寫以及多維度的語言學人工標注分析,并通過機器自動識別提取一些言語指標(如停頓次數和時長等),包含語音、能產性、流暢度、語法、語義、邏輯六大語言維度,共細分為16個指標,從而實現了兒童言語交際水平的精細評估。詳細標注項目如表2所示。
在標注指標的設計方面,大多數兒童語言障礙的篩查量表僅對兒童的詞匯理解和表達能力進行量化評估。而對于言語交際水平的評估而言,發音清晰度和表達能產性作為言語交際的基礎應被納入考量。兒童要能與他人進行良好的溝通,首先其言語應當具有較高的可懂度和能產性,即兒童產出的話語內容能被他人識別和理解,因此語音、能產性兩類指標是兒童的基礎層級能力。其次,言語的語法和流暢度也應納入評估,詳細標注兒童在話語中語法錯誤的數量以及出現長時間停頓、重復、改述等減損流暢度的情況,這兩類指標屬于中等層級能力。我們還設計了語義、邏輯兩類高階能力指標,主要考查語篇中的表意完整性和話語組織能力。
為保證所有語料標注的可靠性和準確性,我們采用3輪標注的方式。首先讓兩位具有語言學專業知識背景的標注員對同一語料分別標注,直覺打分應做到完全一致,除直覺打分外的各個指標均設置10%的容錯率。接著選取兩輪標注后存在沖突的語料進行第三次標注,由3位標注員對每段語料同時標注,在商議后3位標注員的意見仍不一致的情況下采取投票制,最終得出所有指標得分情況。根據標注后自動生成的數據結果(csv格式文件),進一步對數據結果進行歸一化(normalization)處理。對于語音、流暢性、語法和邏輯相關的負邏輯指標,分數歸一化的方法為:
x' = max{X} - x
max{X} - min{X}
x∈X?RN,X代表以往數據庫收集所有被試表達數據的單項指標分數,N為被試數量。對于能產性、語義相關的正邏輯指標,分數歸一化的方法為:
x' = x - min{X}
max{X} - min{X}
歸一化后的分數能較好地代表各項指標的能力水平,分數越高意味著能力越強。標注數據分類分層儲存在語料數據庫中,可用于后續進一步的數據挖掘,如大數據分析和機器學習等。
3.語音維度的標注
語音維度包括輔音聲母、韻母和聲調3項指標。對兒童語料進行聲母、韻母、聲調錯誤的數量標注,即在音節單位內部對語音準確度進行考察。我們僅對音位層次的語音錯誤進行標注,即“讀錯一個字的聲母、韻母或聲調”(劉照雄1996)。對聽感上發音不夠飽滿的語音缺陷(如撮口呼的韻母圓唇度不夠、去聲下降不到位等),則不作語音錯誤標注,只在最后的直覺打分處適度扣分。語音維度標注示例如下:
(1)我不喜歡吃蘿卜,我喜歡吃糖果。(自我介紹,3:6男)
→,。
4.語義維度的標注
語義維度僅語義點覆蓋情況一個指標。在圖片描述和視頻復述兩類題型中,相應設定了每道題的語義信息點,說出某個語義點,就在標注軟件內打“√”。倘若兒童答非所問,則勾選“語義冗余”這一項。語義維度標注示例如下:
(2)正在 看各個國家的地址和各個國家的名字。(李老師正在教小朋友們看地球儀,8:6女)
→目標語義信息點包括:(李)老師 教 小朋友/學生 ?看地球儀;
5.能產性維度的標注
能產性維度包括實際音節數、發音時長、語速3項指標。我們所定義的“能產性”是指被試在單位時間產出有意義的話語的能力。所有標注項目都基于實際音節數這一指標,發音時長由計算機自動識別得出,累加非停頓區域的時長即為發音時長。語速則為實際音節數與總發音時長、停頓時長之和的比值,即每秒產出實際音節的數量,在人工標注實際音節數后,計算機結合發音時長、停頓時長的標注可自動生成語速。能產性維度標注示例如下:
(3)兔子跑得很快,烏龜卻慢吞吞的。兔子跑到樹旁邊睡了一個懶覺,結果烏龜先到終點了。(龜兔賽跑,4:1男)
→人工轉寫后計得;機器標注發音時長10.643秒,語速1.854個音節/秒。
6.流暢性維度的標注
流暢性維度包括冗贅獨立語、冗贅語氣詞、語音改述、內容改述、重復、停頓次數和停頓時長共7項指標。由于口語表達的隨意性,說話人常常會在語言思維受阻時出現無意義停頓,或增加多余成分,如冗贅語、重復,或通過改述來修正不當之處,而這些都會減損語言表達的流暢性和完整性。對于停頓指標,我們參考Raupach(1980)、張文忠和吳旭東(2001)對停頓的定義,即0.3秒及以上時間閾值為停頓的下限,并通過計算機自動識別停頓次數與時長。流暢性維度標注示例如下:
(4)烏龜和兔子比,兔子跑得快。然后呢,烏龜跑得慢。呃,,,兔子就很累了。烏龜呢,就,呃,,,兔子睡醒了。然后飛來一個小鳥。,睡醒了以后,我看到烏龜就跑到終點線了。然后,就沒啦!(龜兔賽跑,5:9女)
→人工標注(然后/然后呢),冗贅語氣詞2(呃),內容改述1,重復4;機器標注停頓次數19,停頓時長19.235秒。對于“然后”的判定采取較寬容的態度,若“然后”可視為表時間或事理邏輯上的承接性連詞,就不計入冗贅獨立語。對于連續重復出現的“然后(呢)”,第二個通常直接判定為冗贅獨立語。
7.語法維度的標注
語法維度僅語法錯誤一個指標。在語法標注時,考慮到兒童語言習得進程的特殊性,我們采取較寬松的標注原則,主要考慮明顯影響交際的語法錯誤:①句內語序錯誤,如主語、謂語、賓語的位置顛倒;②成分殘缺,如缺少必要的謂語動詞、時態助詞等句法成分導致不成句;③句式雜糅,結構混亂;④虛詞使用不當。語法維度標注示例如下:
(5)然后它就得了第一名,(龜兔賽跑,6:1女)
→(語序錯誤),兒童實際要表達“然后烏龜它就得了第一名”。
(6)兔子跑快,烏龜跑慢(龜兔賽跑,3:4男)
→(成分殘缺),缺少結構助詞“得”,應為“跑得快”“跑得慢”。
(7)最后,小兔子離開跑道(龜兔賽跑,4:3女)
→(虛詞使用錯誤),結構助詞“的”可改為動態助詞“了”。
8.邏輯維度的標注
邏輯維度僅邏輯錯誤一個指標。若兒童在篇章表達時前后邏輯矛盾、時間順序錯誤,或句間缺少必要的銜接詞以及銜接詞誤用(如關聯詞誤用)等,均屬于言語邏輯錯誤。邏輯維度標注示例如下:
(8)小豬、小豬佩奇,還有、還有、還有豬爸爸,他們在跳,他們在跳泥坑。媽媽說:(小豬佩奇,6:7男)
→(時間順序錯誤),“下雨”這一事件是跳泥坑之前發生的,應作為敘事背景先講述。
(二)漢語兒童言語交際水平數據庫
通過兒童語料的采集和標注,我們建立起一個2~14歲漢語兒童言語交際水平數據庫。數據庫目前已經儲存了966名漢語兒童在固定程序引導下的言語數據,這些兒童來自廣東、廣西、貴州等不同經濟發展水平的地區,除漢族兒童外,還包括約200名壯族、侗族、瑤族、苗族等少數民族兒童,漢族兒童又包含約200名掌握母語方言(以粵方言、客家話、西南官話為主)的被試,約100名存在語言障礙及相關疾病(如聽障、視障、孤獨癥、神經發育異常等)的兒童,數據較為豐富。對于這些數據,我們分別按照被試和題型進行分類歸檔,并進行了統一的文本轉寫。其中,對638名兒童的語料進行了標注,并輸出言語交際能力得分。數據庫目前概況見表3。
四、漢語兒童言語交際水平評估系統應用前景
本數據庫具有廣闊的語言學、教育學、醫學研究價值,如可以根據兒童語料文本對兒童習得語言過程中的語法偏誤、篇章組織能力進行探究,對比不同地域漢語兒童的語言發展能力差異等。我們已初步使用該數據庫內容進行了多項關于兒童語言障礙研究和服務的開發探索,簡要介紹如下。
(一)結合機器深度學習的漢語兒童語言障礙智能快速篩查
該數據庫結合機器學習技術可用于漢語兒童語言障礙的智能化自動篩查,基于固定程序引導的語料具有較高的可比性,因而適合利用機器學習相關技術建模訓練數據,實現語言障礙的自動篩查。Zhang et al.(2020)基于本數據庫中的284名漢語兒童言語交際水平音頻數據和標注數據,通過雙通路(two-stream encoder)深度學習算法,同時提取語音流和內容流兩個維度上的特征,從而建立起漢語兒童語言音頻特征、各項標注指標與語言能力等級之間的相關模型,篩查語言障礙的準確率高達92.6%。
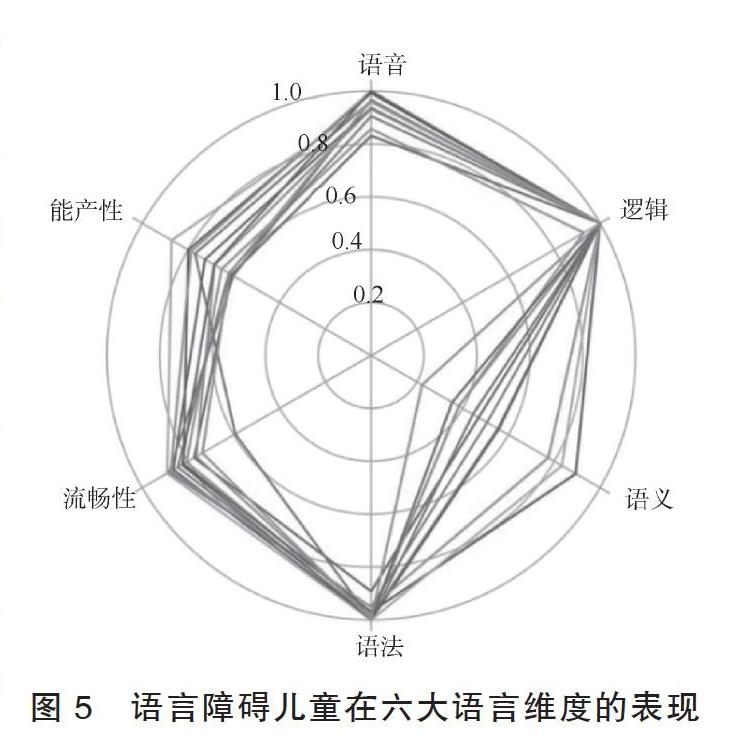
除此之外,還可從語言學角度進一步探索漢語兒童語言障礙的特點,語言障礙兒童在言語交際中的各個維度表現如圖5所示,不同線條代表不同被試的言語表現得分。
六大語言維度對于兒童語言障礙篩查的貢獻率也存在差異,如表4所示。其中排在前三的是流暢性、語音、能產性,貢獻率分別為27.6%、23.7%和17.3%。
各個語言指標對于言語交際得分的貢獻率也存在差異。其中排在前五的語言指標為語義、輔音聲母、冗贅語、內容改述、語法,如表5所示。
目前,此漢語兒童言語交際水平數據庫仍在擴大建設當中。一方面,標注的數據結果可以作為模型的訓練集進一步提升智能化篩查語言障礙的準確率;另一方面,隨著不同年齡段兒童言語數據量的提升,我們有望建立起漢語兒童言語交際能力發展數據的常模,從而更精準地評估兒童綜合言語能力的發展,如測得兒童的語言發育年齡、明確語言障礙的具體分型等等,這對于兒童語言障礙的篩查診斷以及言語矯正訓練都具有重要意義。
(二)人工耳蝸植入兒童綜合語言能力研究
1.人工耳蝸植入兒童綜合語言能力發展研究
漢語兒童言語交際評估系統還可以應用于特殊兒童的語言能力研究,如人工耳蝸植入兒童。通過精細全面的語言能力評估,我們不僅可以了解特殊兒童的言語能力發展情況,判定人工耳蝸的有效性,還能將特殊兒童的各語言維度與正常兒童進行對比,有針對性地為他們設計言語提升方案。本數據庫已收入40名人工耳蝸植入(cochlear implant,CI)兒童的標注數據,并將這40名CI兒童被試按照實際年齡分為3組:2.5~4歲、5~6歲、7~10歲,對其進行ANOVA單因素分析,結果發現3個年齡組之間的綜合語言能力分數和六大語言維度分數均不存在顯著差異(P > 0.05),即年齡因素對CI兒童語言能力的影響不顯著。這些兒童的綜合語言能力分數分布較為分散,說明其語言能力的個體差異性較大,具體分布情況如圖6所示。
另一方面,我們參考了各個年齡段城市兒童的語言分數均值,發現3~9歲城市兒童的綜合語言能力分數達到平均值的比率為58%。我們將35名3~9歲的CI兒童與同齡城市兒童的語言分數進行比較,發現僅有40%的CI兒童達到了同齡兒童的平均語言水平,被界定為語言發展水平達標,具體數據如表6所示。
與正常兒童有別,CI兒童的綜合語言能力并不隨著年齡增長而顯著提升。這35名CI兒童中,4歲年齡組的語言表現最佳,有55.6%能達到同齡兒童的平均語言水平;而4歲以后,相較于同齡兒童,CI組的表現反而出現相對下滑——達標率隨著年齡的增長越來越低。我們推測,在幼年早期(3歲以前),這些兒童由于聽力障礙錯過了言語感知與聽理解能力的最佳發展時機,而3歲以前也是大多數聽力障礙兒童CI植入的階段,本研究中有75%的兒童都在3歲前完成CI植入,需要一定的時間來調節適應,因此3歲CI兒童的語言發展普遍落后,4歲CI組的整體語言表現才有了明顯提升。但隨著年齡的進一步增長,CI組和正常同齡兒童的語言能力差距越來越大,可見人工耳蝸的植入雖然促進了患兒的聽覺言語功能發展,但仍無法彌補他們與正常兒童的差距。
既然年齡因素在CI兒童的語言發展過程中并不產生顯著影響,我們推測CI植入的影響可能更為關鍵,因此進一步探究CI兒童的植入年齡與其綜合語言能力分數之間的關系。我們將40名被試按照耳蝸植入年齡進行分組,分為1.5歲前植入、1.5~3歲植入和3歲后植入組,以植入年齡為因子、綜合語言能力分數為因變量進行了方差分析。結果發現,CI植入年齡顯著影響兒童的語言發展水平(F = 3.484,P = 0.041 < 0.05)。3組CI兒童的綜合語言能力得分情況如表7所示。
事后檢驗結果表明,只有植入年齡早于1.5歲的患兒在語言發展上顯著好于1.5~3歲組(P = 0.019 < 0.05),而植入年齡在3歲以上的兒童與其余兩組之間差異不顯著(P > 0.05),這可能與植入年齡在3歲以上的兒童普遍實際年齡較大、相應地獲得較高的語言分數有關。但無論如何,在1.5歲以前植入人工耳蝸對于聽力障礙兒童的語言發展是有益的,這與前人研究基本一致(周惠群,殷善開2010;Craddock et al. 2016)。因此,對于聽障兒童,如有條件,應當盡早進行人工耳蝸植入手術,促進患兒的語言發展。
2.人工耳蝸植入兒童六大語言維度發展情況
這35名3~9歲的CI兒童與同齡正常兒童相比,在綜合語言能力分數上具有顯著差異(t = 2.689, P = 0.010)。如表8所示,兩者在語音、能產性、流暢性、語法、邏輯五大維度上同樣具有顯著差異(P < 0.05),僅在語義維度差異不顯著,且均為CI兒童得分低于正常兒童。可見,CI兒童在多個語言維度的發展均顯著區別于同齡正常兒童,低于同齡正常兒童的發展水平。
其次,由于目前對于聽障兒童的語言障礙診斷標準尚未達成一致,因此我們在參考正常兒童語言均分的前提下,先將CI兒童劃分為語言發展達標(14人)與未達標(21人)兩組,探究未達標CI兒童的語言障礙特征。結果發現兩組兒童不僅在綜合語言能力分數具有顯著差異(t = 6.535, P < 0.001),在語音、能產性和語義三大維度上也存在顯著差異(P < 0.05),具體數據如表9所示。由此可見,在CI兒童群體內部,達標組在發音準確性、表意完整性和言語能產性方面都具有優勢,而未達標組通常發音含混,表意不清晰,言語能產性也較差。
綜上,CI兒童的整體語言發展低于正常兒童的平均水平,且這種語言發展的落后體現在語音、語法、邏輯、言語能產性和流暢性五大方面,這提示我們需要重點關注CI兒童在各個語言維度上的發展情況,必要時介入語言干預措施。在語言障礙的評估方面,與單純性語言障礙的篩查一致,CI兒童在語音、能產性兩大維度的分數也具有顯著的指示意義。需要說明的是,在語義方面,CI兒童內部存在差異——達標組表意能力良好,與正常兒童相當;而未達標組表意能力則很差。因此,我們推測,在聽力障礙兒童群體的語言障礙篩查中,語義維度或許是一項極為顯著的篩查指標,能較好地篩選出語言發育障礙的CI兒童,這有待進一步的研究與驗證。
五、總 結
兒童是祖國的未來、民族的希望,要為億萬兒童的健康成長保駕護航,就必須要做好兒童語言工作。本研究致力于構建一個全面有效的漢語兒童言語交際水平評估系統,包括一套固定引導程序和精準數據標注指標,基于該系統廣泛收集正常兒童和語言異常兒童的語言發展數據建立數據庫,并利用機器學習技術以實現對兒童言語交際能力的自動化評估,填補漢語兒童言語評估領域的空白。
該系統具有廣闊的應用前景。在語言學理論層面上,可以探究漢語兒童語言習得的一般規律,把握當今漢語兒童的整體語言發展概況和各方面語言能力的發展特征;在語言應用層面上,基于對漢語兒童語言發展進程的把握,通過比較分析可以找出兒童語言發育障礙的特征,探索特殊群體的言語能力發展路徑,并提出語言發育障礙的精準評估方案,這對于今后兒童語言障礙評估工作的具體開展具有提示意義。
參考文獻
高 軍 2012 《中國社會科學院語言所普通話兒童語音庫——CASS Mandarin Child Speech Corpus》,上海:第十屆中國語音學學術會議論文。
胡亞娟 2015 《基于語料庫的漢語兒童指稱發展研究》,《當代外語》第1期。
黃瑞珍,蔡昀純,林佳蓉,等 2014 《華語學齡兒童溝通及語言能力測驗》,臺北:心理出版社。
黃文橋 2020 《漢語兒童語言能力評估的系統評價》,《語言戰略研究》第4期。
林寶貴,锜寶香 2000 《國小兒童語言能力評量工具之發展》,《“中華民國”聽力語言學會雜志》第15期。
劉照雄 1996 《普通話水平測試大綱》,長春:吉林人民出版社。
锜寶香 2006 《兒童語言障礙——理論、評量與教學》,臺北:心理出版社股份有限公司。
溫志軍,胡瑰玲 2001 《開發利用世界上最大的兒童語料庫——CHILDES》,《外語教學與研究》第5期。
楊金煥 2016 《4—5歲兒童會話能力研究——基于“兒童—成人”與“兒童—同伴”比較視角》,南京師范大學碩士學位論文。
張廷香 2010 《基于語料庫的3—6歲漢語兒童詞匯研究》,山東大學博士學位論文。
張文忠,吳旭東 2001 《第二語言口語流利性發展定量研究》,《現代外語》第4期。
張義賓 2019 《基于漢語兒童語料庫的語言障礙診斷系統研究》,華東師范大學博士學位論文。
周惠群,殷善開 2010 《耳蝸植入術后兒童聽覺及語言發展的研究現狀》,《實用醫院臨床雜志》第5期。
周 兢,張義賓 2020 《基于漢語兒童語料庫構建的兒童語言發展測評系統》,《學前教育研究》第6期。
Bishop, D. M. 2000. Pragmatic language impairment: A correlate of SLI, a distinct subgroup, or part of the autistic continuum. In D. M. Bishop & L. B. Leonard (Eds.), Speech and Language Impairments in Children: Causes, Characteristics, Intervention and Outcome, 115?130. New York: Psychology Press.
Collisson, B. A., S. A. Graham, J. L. Preston, et al. 2016. Risk and protective factors for late talking: An epidemiologic investigation. The Journal of Pediatrics 172, 168?174.
Craddock, L., H. Cooper, A. Riley, et al. 2016. Cochlear implants for pre-lingually profoundly deaf adults. Cochlear Implants International 17, 26?30.
Leit?to, S., J. Hogben & J. Fletcher. 1997. Phonological processing skills in speech and language impaired children. International Journal of Language & Communication Disorders 32(2s), 91?111.
Norbury, C. F., D. Gooch, C. Wray, et al. 2016. The impact of nonverbal ability on prevalence and clinical presentation of language disorder: Evidence from a population study. Journal of Child Psychology and Psychiatry 57(11), 1247?1257.
Raupach, M. 1980. Temporal variables in first and second language speech production. In D. Dechert & M. Raupach (Eds.), Temporal Variables in Speech. New York: Mouton.
Rescorla, L. 2009. Age 17 language and reading outcomes in late-talking toddlers: Support for a dimensional perspective on language delay. Journal of Speech, Language, and Hearing Research 52(1), 16?30.
Tomblin, J. B., N. Records, L. Buckwalter, et al. 1997. Prevalence of specific language impairment in kindergarten children. Journal of Speech, Language, and Hearing Research 40(6), 1245?1260.
Whitehurst, G. J., A. S. Arnold, M. Smith, et al. 1991. Family history in developmental expressive language delay. Journal of Speech, Language, and Hearing Research 34(5), 1150?1157.
Zhang, X., F. Qin, Z. Chen, et al. 2020. Fast screening for childrens developmental language disorders via comprehensive speech ability evaluation—Using a novel deep learning framework. Annals of Translational Medicine 8(11), 707.
責任編輯:王 飆
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
