基于改進Xgboost算法的多聯機空調系統故障診斷策略
2021-10-30 02:02:32朱波胡寬李正飛陳煥新
制冷技術 2021年4期
朱波,胡寬,李正飛,陳煥新
(華中科技大學能源與動力工程學院,湖北武漢 430074)
0 引言
多聯機空調系統也稱作“一拖多”空調系統,是指一臺室外機連接多臺室內機,室外機風冷換熱、室內機直接蒸發換熱的一次制冷劑空調系統。多聯機系統多用于中小型建筑和部分公共建筑,具有節約能源、控制先進和運行可靠等特點。機組適應性好、制冷制熱溫度范圍寬、設計自由度高、安裝和計費方便[1]。工作原理是通過控制制冷劑流量和壓縮機的制冷劑充注量來實現制冷與節能。制冷劑充注量是多聯機系統運行過程中重要的參數,一旦出現充注量故障,會導致一系列安全問題和經濟損失。因此對制冷劑充注量故障的檢測十分必要。目前,制冷系統故障診斷方法有3 種:經驗知識、模型分析和數據分析。數據分析方法不需要先驗知識,僅通過分析發現大量數據之間的聯系,因此在多聯機復雜系統故障檢測中有較好的應用前景[2-4]。
特征選擇是機器學習過程中重要的數據預處理過程,對現實任務的解決有兩點重要意義。一是避免維度災難。維度災難是由特征屬性過多引發的,若能從過多的屬性中挑選重要的屬性即可大大減輕計算量,從而避免維度災難。二是去除冗余特征以降低學習難度,可以把握重點[5-6]。李正飛等[7]結合ReliefF 和mRMR 特征選擇算法獲得特征后建立反向傳播算法模型進行故障診斷,結果表明:該方法可以提高多聯機制冷劑充注量故障診斷的精度與效率。陳逸杰等[8]對比了Boruta 算法和改進的Boruta 算法,結果表明改進的Boruta 算法不僅降低了樣本復雜度,而且提高了模型的預測性能。劉藝等[9]闡述了現有特征選擇穩定性提升方法,分析比較了各類方法的特點和適用范圍,總結了特征選擇穩定性中的相關評估工作,并通過實驗剖析穩定性度量指標的性能,對比了4 種集成方法的效用。石拓等[10]提出了SEFV_Bagging 算法,結果表明其具有良好的泛化性能與穩定性,在測試數據上表現出的預測精度理想。崔鴻雁等[11]總結了5 種特征選擇方法,通過對比各個方法的原理、實現過程和應用場景,得出不同算法適用的范圍和優缺點。徐廷喜等[12]提出一種基于支持向量數據描述的算法來檢測變頻空調系統制冷劑故障,利用主成分分析法進行降維,大幅提升診斷準確率。吳斌等[13]提出一種基于隨機森林的屋頂空調故障診斷策略,結果表明該方法對于膨脹閥類型相同,但制冷劑、壓縮機與系統冷量不同的屋頂機空調系統診斷效果良好。
以上研究對故障診斷的效率均有較大提升但他們的研究方法局限于單一特征選擇法,單一特征選擇容易得到局部最優解且抗干擾能力差、穩定性差。穩定性差的特征是不利于發現特征之間的相關性的[14]。為了解決這些問題,本文將集成策略與Xgboost 算法相結合,使用交叉驗證和網格搜索尋找最優參數,提出了改進Xgboost 算法,將單一特征選擇得到的變量重要性排序后集成,得到集成特征排序,以提高特征穩定性和預測準確率。
1 制冷劑充注量故障診斷實驗
1.1 實驗設計
本論文使用的數據是通過多聯機制冷劑充注量實驗獲取的,多聯機系統由一臺室內機和五臺室外機組成,室內機主要由風機和換熱器組成,室外機主要由氣液分離器、渦輪式壓縮機和過冷器組成,室內機和室外機同時配備了多種傳感器來采集相關數據。實驗中的室外換熱器采用的是U 型翅片換熱器,有效加快了與外界的換熱,同時室外機組還配備有相關安全設施來保證實驗的安全進行。實驗選擇R410A 作為制冷劑,制冷劑額定充注量為9.9 kg,室內機和室外機的額定功率分別為28.0 kW和7.1 kW。多聯機系統傳感器用于測量溫度、壓力等數據,制冷劑充注量水平由膨脹閥來調節。多聯機系統原理如圖1所示。
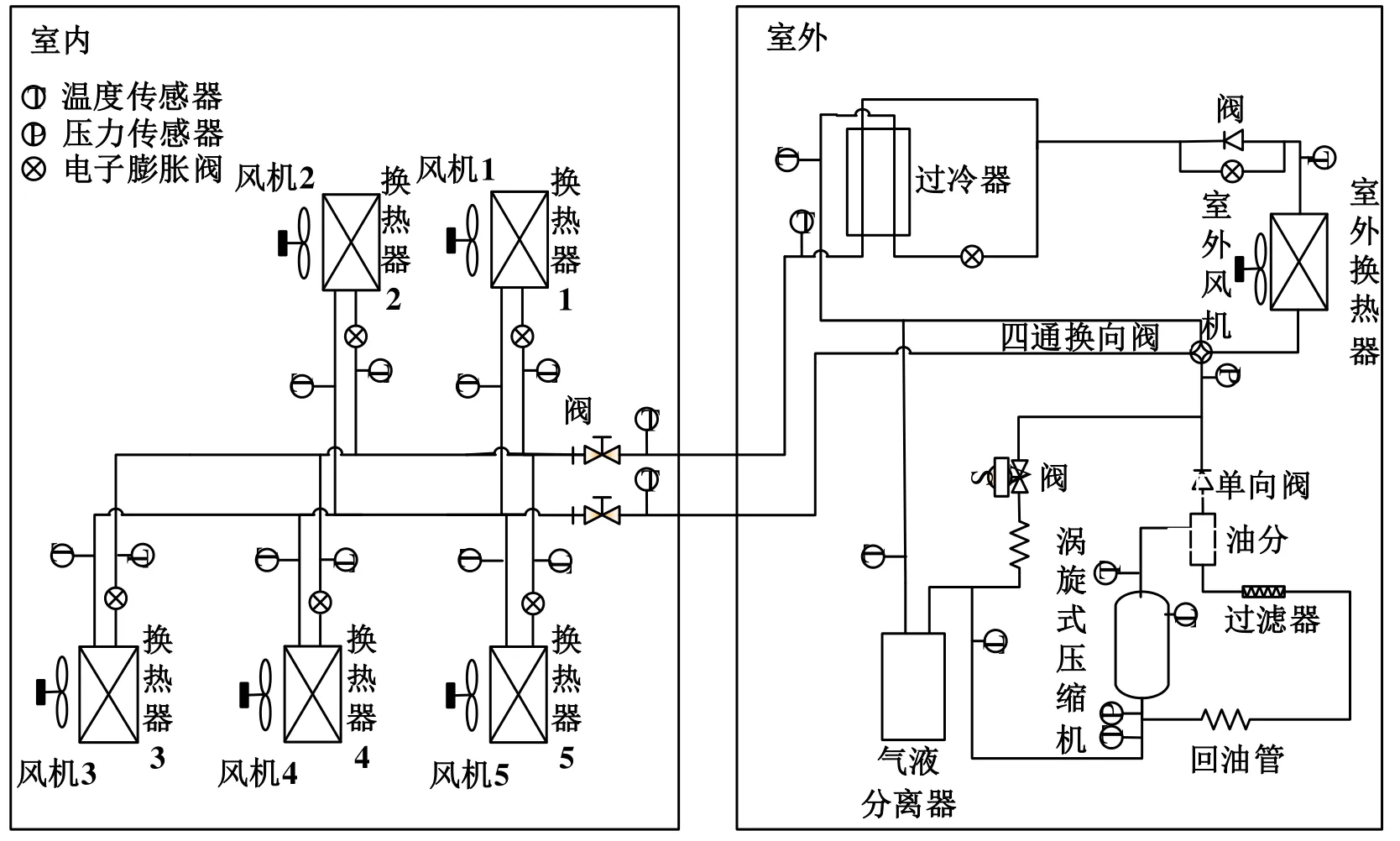
圖1 多聯機系統原理
1.2 數據采集
實驗共測試了10 種制冷劑充注量水平下機組的運行參數,充注量水平設定在63%~140%,制冷劑充注量水平劃分為不足、適量和過量3 種情況,實驗每隔15 s 記錄一次數據,充注量與充注程度的對應關系和類別情況如表1所示。實驗系統在室內溫度下進行,運行工況數據如表2所示。
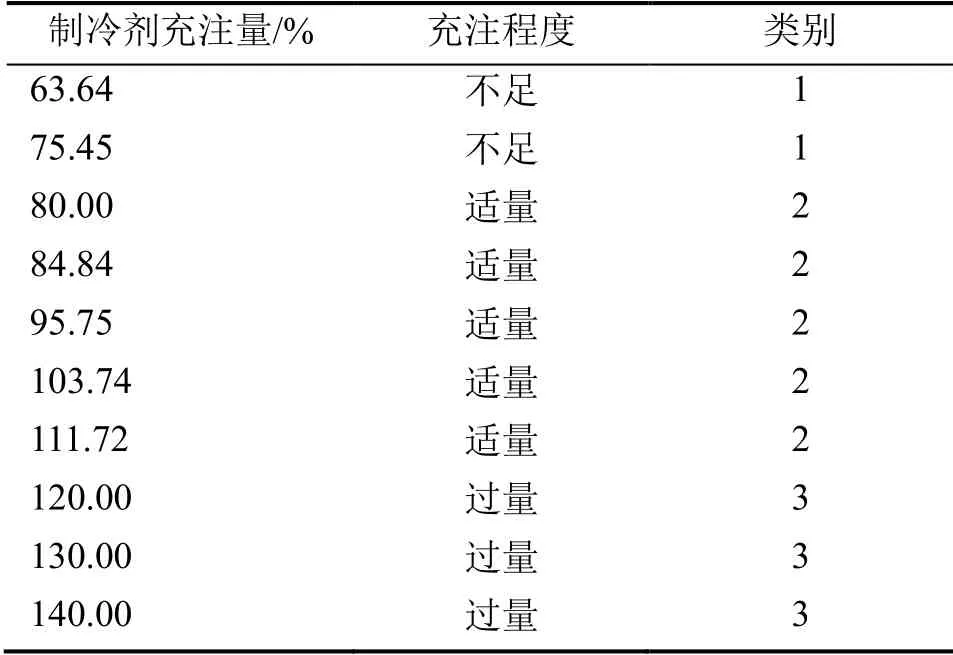
表1 制冷劑充注量與類別

表2 系統運行工況
2 Xgboost 算法及其參數設置
XgBoost 算法是陳天奇[15]開發的一個機器學習項目,它可以高效地實現GBDT 算法,在進行了算法和工程上的多次改進后,被廣泛應用于各種機器學習競賽中并取得了不錯的成績。Xgboost算法的核心思想是不斷地進行特征分裂來生長一棵樹,每生長一棵樹,就會得到一個新函數來擬合上次預測的殘差。訓練完成后,當我們要預測一個樣本時每個樣本會落到每棵樹中對應的葉子節點,每個葉子節點對應一個分數,最后只需要將每棵樹對用的分數加起來就是該樣本的預測值[16-17]。
Xgboost 算法目標函數為:
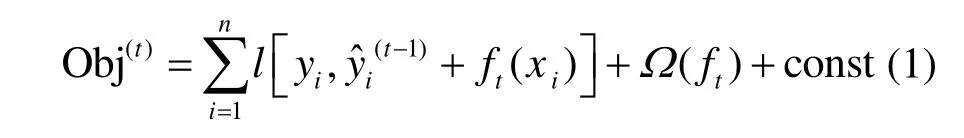
用泰勒公式展開得目標函數為:
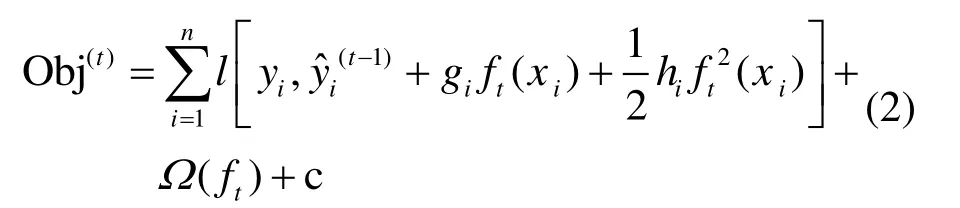
式中,l 為損失函數;Ω(ft)為正則項;c 為常數項。
Xgboost 算法參數較多,本文主要設置了max_depth、n_estimators 和learning_rate 三個參數。其中max_depth 控制樹的深度,深度越大越容易過擬合,n_estimators 控制弱學習器的數量,learning_rate 為學習率。
3 貪心搜索集成
貪心搜索是基于貪心算法的集成搜索過程。貪心算法的基本思路是首先建立起數學模型來描述所要求解的問題,然后把待求解的問題拆分成若干個子問題,再對每個子問題進行求解,獲得每個子問題的局部最優解,最后把每個子問題的局部最優解集成,得到原問題的解。貪心算法的使用有一定的限制,只能求解在約束范圍以內的可行解,并不能保證最優,也就不能求解極值問題。貪心算法以迭代的方式連續做出貪心選擇,每次貪心選擇都將使所求解問題簡化為更小的子問題[18-19]。
本文采用貪心搜索集成策略,貪心搜索集成的基本思路是將基特征選擇器得到的特征序列構成特征子集,將每個特征看作一個候選特征子集,然后對所有候選特征子集進行評價且保證每輪的選擇均為目前狀況下的最優選擇。對特征子集以預測準確率作為評價標準,每輪搜索都選擇預測準確率最大的變量,據此對特征進行排序。
4 改進Xgboost算法的制冷劑充注量故障診斷
4.1 數據預處理
實驗所得的數據量十分龐大,如果直接將如此龐大的數據量帶入模型進行故障檢測,不僅預測精度低、計算量龐大而且可能導致計算機崩潰。因此,數據的預處理十分重要。數據預處理就是剔除異常值、死值、無關變量和邏輯變量,降低數據維度,獲得較好的特征變量,最后對特征變量進行歸一化處理[20]。數據歸一化是將數據轉化為均值為0、方差為1的正態分布,這樣可以使不同數據處在同一數量級,消除量綱對模型的影響,保證了預測的穩定性,可表示為:

式中,E(xi)為變量xi的數學期望,var(xi)為方差。
數據預處理分為兩個步驟:1)數據清洗;2)選取特征變量。數據清洗時,時間記錄和異常值要首先剔除,然后去除與目標變量相關性強的特征變量,降低數據冗余。特征變量的選取主要基于專家先驗知識,最終選定18個變量作為最終的特征變量輸入到故障診斷模型,變量名及編號如表3所示。

表3 變量名及編號
4.2 算法參數尋優
在運行Xgboost 算法前,需要輸入數據矩陣,標簽向量和迭代次數等參數。本文使用十折交叉驗證和網格搜索來尋找最優參數。十折交叉驗證是將數據集平均分為10 份,每次拿出1 份作為測試集,其余作為訓練集,直到十個子集均作為測試集使用過,最后將10 個模型參數取平均值,作為最終指標。網格搜索是一種窮舉調參方法,即在所有候選的參數中循環遍歷,實驗每一種可能,將效果最好的參數作為最終結果[21-22]。
4.3 特征選擇優化
首先從原始數據集中抽取30,000 個數據作為樣本子集,樣本子集保留了原始數據集的所有特征。通過抽樣可以大大減少運算時間,同時通過形成數據擾動,保證了特征子集的多樣性和穩定性。抽樣后運行五次Xgboost 算法,得到5 個特征子集,然后將所得特征子集按照特定集成策略集成,得到集成后的特征子集。
然后再取30,000個樣本進行驗證過程。在驗證過程樣本中取80%的數據作為訓練集,20%的數據作為測試集。將5種單一特征排序和集成特征排序按照排名依次帶入Adaboost和Xgboost預測模型中,最終獲得6種變量排序對應的預測準確率。故障診斷準確率可以定義為:
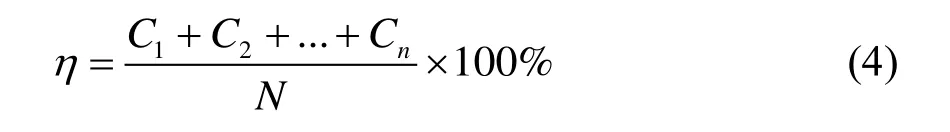
式中,C1、C2、Cn分別代表n種故障預測正確的樣本數;N為樣本總數。
數據處理與模型預測的過程如圖2所示。
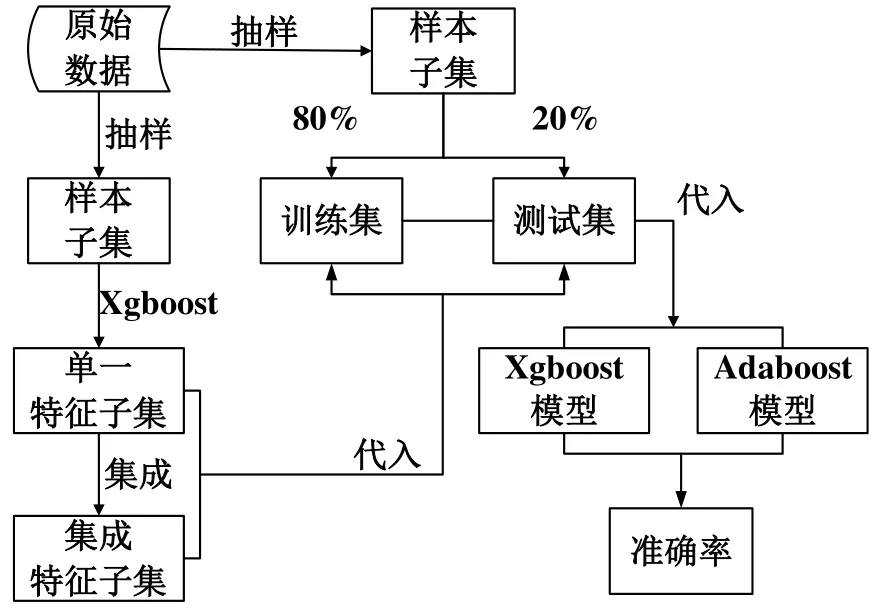
圖2 模型訓練流程
5 結果分析
5.1 準確率對比
圖3所示為Xgboost模型和Adaboost模型準確率對比。由圖3可知,在兩種模型中改進的Xgboost算法獲得的準確率基本都高于所有單一特征選擇算法,最差時也和單一特征選擇中的最高準確率持平,充分說明該算法的優越性,這也表明集成算法可以獲得更好的特征排序、更優的診斷性能。集成算法的準確率隨變量個數的增加呈現出先增再減最后趨于穩定的變化。準確率隨變量個數增加先增加,是因為變量數少時,模型預測能力低,變量較少時無法對制冷劑充注量進行準確預測。變量數達到15時,準確率達到峰值。當變量數大于15時,準確率開始略有下降,這是由于過多的變量造成特征的冗余程度變大,冗余變量降低了預測性能,同時增加了運算負荷。特征選擇的目的在于選擇合適數量的變量構成特征子集,在獲得較高準確率的同時降低運算量,因此,本論文選擇貪心搜索集成得到的前7個變量構成最優特征子集,按照排序依次為壓縮機排氣溫度、過冷器液出溫度、壓縮機模塊溫度、冷凝溫度、氣分進管溫度、EXV、室外環境溫度。這樣選擇既可以保證準確率,也可以保證較少的特征變量,盡可能減少計算復雜度。
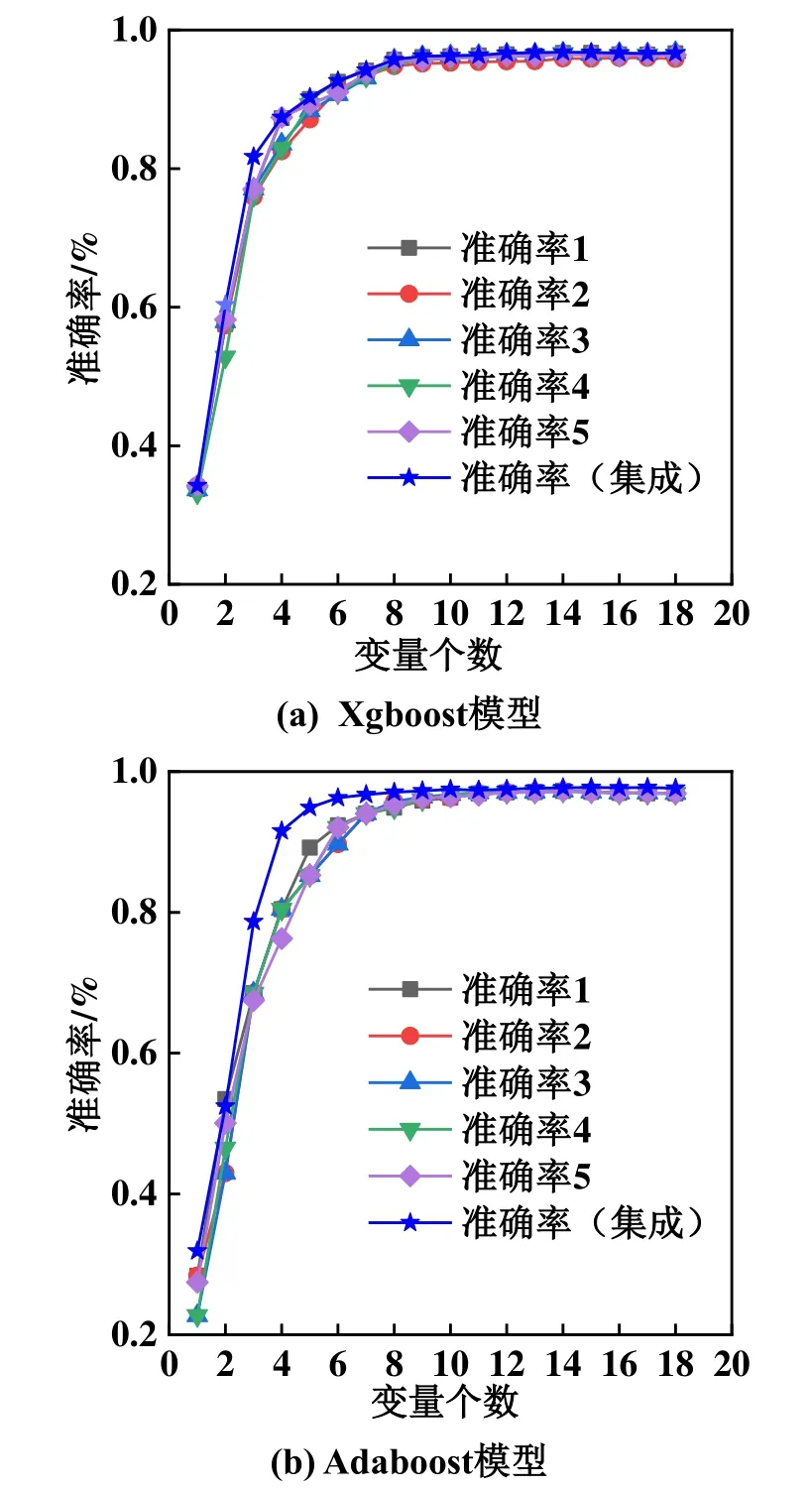
圖3 Xgboost模型和Adaboost模型準確率對比
5.2 泛化性能驗證
為了驗證改進Xgboost算法的泛化性能,再次從原始數據中抽取40,000組數據,代入兩種模型中進行驗證,結果如圖4所示,Xgboost模型部分準確率數值如表4所示。
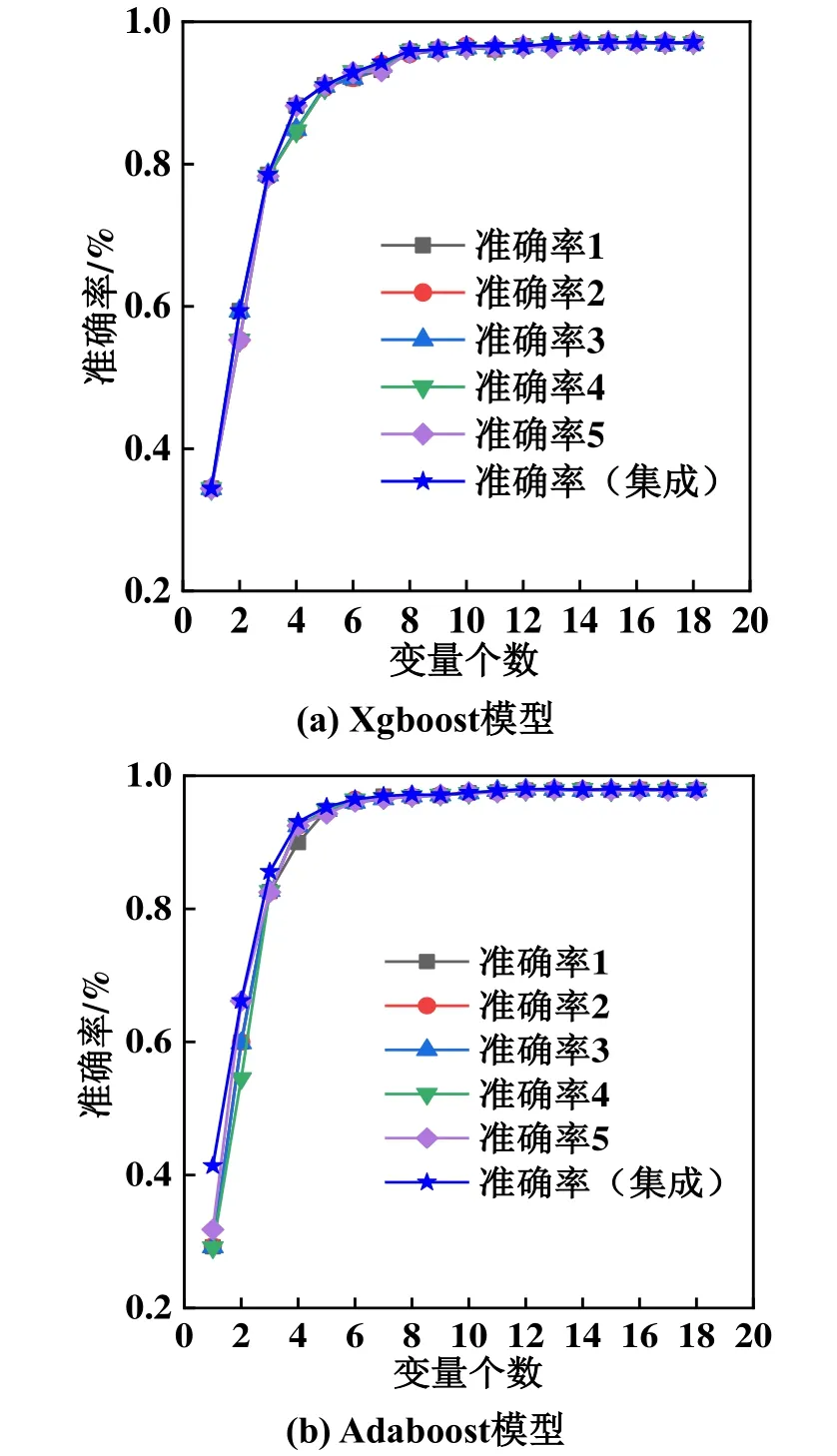
圖4 Xgboost模型和Adaboost模型部分數據準確率對比
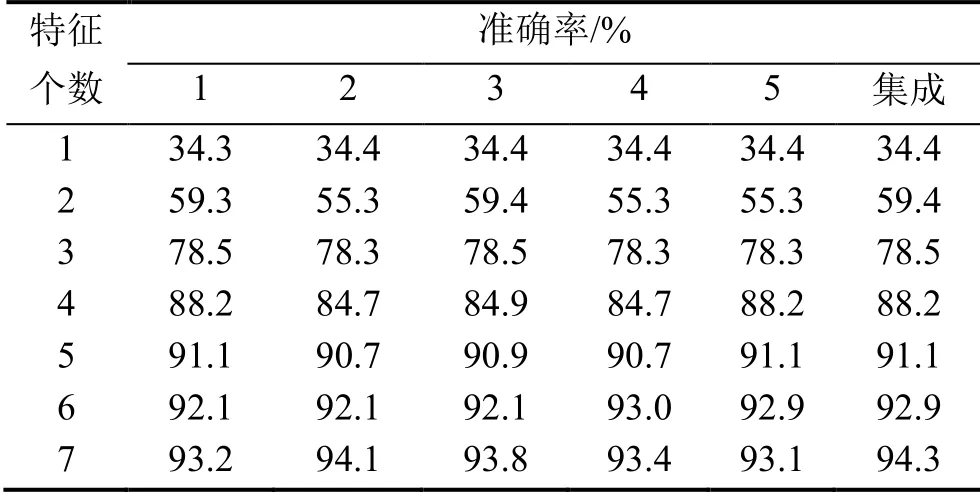
表4 Xgboost模型前七位特征準確率
圖4所示為所有18個特征的準確率。表4給出了在Xgboost模型中排在前7位的特征準確率,因為7位以后的準確率已經十分接近,原因是隨著特征變量的個數增加,準確率逐步提高,當變量個數達到一定數量時,基本接近了最高的準確率。由圖4和表4可知,改進Xgboost算法的準確率依然整體上高于所有的單一算法,證明該模型泛化性能良好。
6 結論
本文將集成思想運用到特征選擇上,將單一算法得到的特征順序集成,結合交叉驗證網格搜索等手段改進Xgboost算法,來提高模型預測的準確率,得出如下結論:
1)改進Xgboost算法的集成方法得到的特征子集能獲得比所有單一特征選擇方法更高的準確率,在Adaboost和Xgboost兩種模型上選擇特征數量較少時,準確率提升明顯,最優時分別提升了15.28%和4.68%;
2)使用交叉驗證、網格搜索和貪心搜索策略可以有效改進Xgboost算法,提高其特征選擇穩定性和預測準確率;
3)改進Xgboost算法具有良好的泛化性能,適用于更多其他復雜情況,具備一定的推廣能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
