基于嵌入式設備應用的CNN 加速器的設計研究*
2021-10-26 12:26:26王紅亮程佳風
電子器件 2021年4期
關鍵詞:設計
王紅亮,程佳風
(中北大學電子測量技術國家重點實驗室,山西 太原 030051)
近年來,卷積神經網絡的使用領域越來越普遍,其模型復雜度不斷提升。然而卷積神經網絡的運算過程具有高度并行性和重復性的特點,隨著網絡層數的不斷深入,卷積神經網絡的計算密集和存儲密集特性日益凸顯,成為實現快速高效CNN 網絡的限制。于是為了提升CNN 的設計性能[1-5],基于GPU,ASIC,FPGA 的不同加速器被相繼提出。
基于GPU[6-7]的CNN 加速器能夠很好地實現軟硬件的結合,促進神經網絡訓練時的加速效果。然而GPU 的能耗巨大,其硬件結構固定,限制了卷積神經網絡在嵌入式設備的應用。與GPU 相比較,ASIC 芯片[8]具有功耗低,體積小,計算性能高的特點,也可以實現對CNN 的加速訓練。但ASIC 芯片靈活性極低,開發周期較長,研發成本極高,使得它不適用于結構靈活多變的卷積神經網絡。FPGA[9]具備高性能,低功耗,可靈活配置的特點,已有的基于FPGA 的CNN 加速器的研究表明,FPGA 比GPU和CPU 不僅具有更好的加速效果,而且能耗方面也遠遠低于GPU,但由于FPGA 靈活性差且Verilog HDL 開發門檻較高,開發周期長,在一定程度上限制了FPGA 在人工智能領域運用的普及。因此Xilinx 推出了一種基于高級語言進行FPGA 設計的綜合工具。通過引入高層次綜合(High-Level Synthesis tool,HLS)工具,在代碼生成時可以快速優化FPGA 硬件結構,提高執行效率,降低開發難度,在開發過程中可以快速驗證和修改算法,及時查看算法的實際效果,縮短開發周期。
以實現CNN 在嵌入式應用場景下的快速高效部署為目的,設計并實現了一種基于FPGA 的高性能、低功耗、可配置的CNN 加速器。該加速器充分利用FPGA 良好的計算性能和并行性特征,使其獲得更好地實時性,同時由于FPGA 實現的加速器能夠降低系統功耗,使得卷積神經網絡更好地應用到移動設備上。
1 典型的卷積神經網絡
采用一種典型的手寫數字識別網絡CNN LeNet5[10]模型對系統進行測試,模型結構如圖1 所示,總共包含6 層網絡結構,其中卷積層有2 個,池化層有2 個,全連接層有2 個。網絡的輸入為28 pixel×28 pixel×1 pixel 大小圖片,輸入圖像依次經過conv1、pool1、conv2、pool2、inner1、relu1、inner2 層后,得到10 個特征值,然后在softmax 分類層中將10 個特征值概率歸一化得出最大概率值即為分類結果。網絡中的各種參數設置如表1 所示。
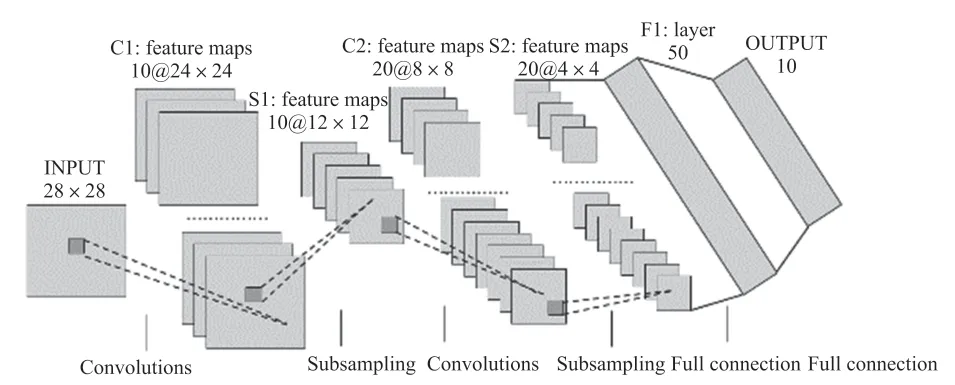
圖1 典型的手寫數字識別網絡結構
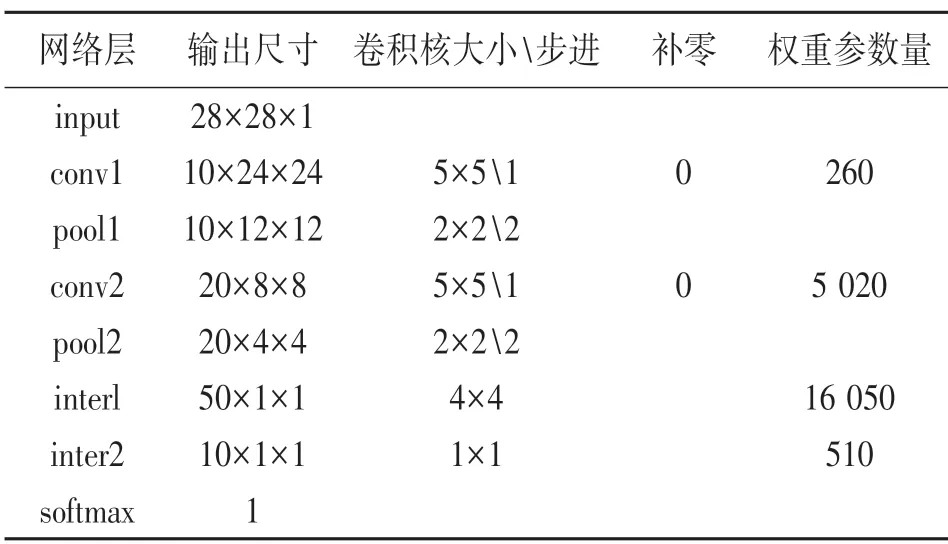
表1 網絡參數表
由表1 可以計算出,該CNN 網絡總共的權重參數量為260+5 020+16 050+510=21 840 個變量,接下來會對輸入特征參數和權重參數等都將進行定點量化,將32 bit 的浮點數定點量化為16 bit 的定點數,因此這21 840 個變量都將用ap_int(16)來存儲,將大約消耗43 kB 的存儲資源,采用的PYNQZ2 有足夠的存儲空間用于存放這些變量。
2 高層次綜合技術
2.1 HLS 基本原理
高層次綜合工具[11](High-Level Synthesis tool,HLS)是Xilinx 在2012 年發布的一套集成于Vivado開發環境的開發工具[12-13],主要目的是用于可編程邏輯器件(比如FPGA)的設計和開發。用戶可以通過使用HLS 高層次設計工具來選擇多種不同的高級語言(如C,C++,System C)來進行FPGA 的設計,通過仿真、優化及綜合等步驟就可以以RTL 代碼的形式輸出,既可以是網表形式,也可以導出為Xilinx 的IP 核。引入HLS 設計工具,在代碼生成時可以快速優化FPGA 硬件結構,提高執行效率,降低開發難度,在開發過程中可以快速驗證和修改算法,及時查看算法的實際效果,縮短開發周期。采用HLS 設計的硬件電路具有良好的擴展性,并且開發過程簡單,系統的設計使用C 語言就能實現,HLS的開發過程如圖2 所示。
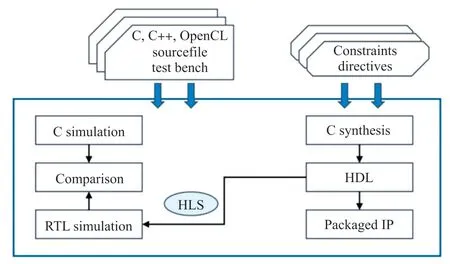
圖2 HLS 的開發流程圖
2.2 特征、權重參數的定點量化
神經網絡的數據量主要集中在卷積層的輸入輸出以及卷積核的參數,巨大的數據量會占用大量的硬件資源,且FPGA 不擅長浮點運算,為了節約傳輸成本,依據HLS 工具特有的自定義定點數ap_fixed,只要確定小數點的位置,就可以對數據實現量化。將32 bit 的浮點數量化成16 bit 的定點數,只需要在利用tensorflow 框架訓練完整個網絡時,對訓練完的weights 參數進行最大值量化,計算出小數點的位置。對于特征參數的量化是在測試集中計算出小數點的位置,輸出結果如圖3 所示。
圖3 權重特征的小數點位置
3 加速電路的設計與優化
3.1 卷積運算模塊的設計
采用HLS 進行加速器的設計與實現,與傳統的硬件電路設計思想不同,HLS 支持以高層次語言進行算法功能的描述,因此設計加速電路的首要任務就是采用軟件語言(C/C++)對卷積神經網絡各層的計算模型進行實現。卷積層的計算過程已經在前文進行了深入分析,因此基于高層次綜合工具設計了一種卷積運算模塊,通過C 語言配置CNN 的超參數,如圖4 所示:

圖4 卷積運算模塊的超參數配置
對于不同的CNN 網絡只需要輸入對應的超參數的值即可完成不同CNN 網絡的卷積rule 運算,由此可見此卷積運算模塊適用于各種網絡結構大小的卷積神經網絡運算。
卷積層的計算主要包含4 層循環結構,如圖5所示,最內層循環是完成Kx×Ky大小的單層卷積核與輸入特征圖像相應區域的乘累加運算,第2 層循環是將卷積窗口在整個Hin×Win大小的輸入特征圖中滑動以提取單層輸入圖像中的所有特征,第3 層循環遍歷所有CHin 個輸入通道,第4 層循環遍歷不同輸入特征通道輸出CHout 個輸出特征圖像。

圖5 卷積層計算偽代碼
由此設計出的卷積運算通路的過程如圖6所示。
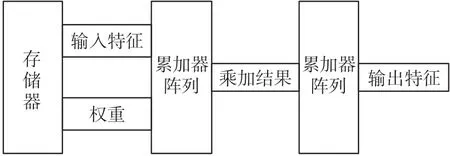
圖6 卷積運算通路
3.2 卷積運算模塊的優化
3.2.1 卷積運算的分解
由于特征、權重參數都是多維的空間變量,無法在計算機中讀取,因此我們要將其展開為一維變量。如下圖7 所示,對于特征參數,它在空間中的排布方式為三維變量,因此需要將其展開為一維變量,考慮到FPGA 優秀的并行運算能力,所以在空間中沿輸入特征的通道C 將其切割為C/K 個通道,每一個通道可以實現K 路并行的計算且需要的特征存儲空間減少,大大提高了加速電路的運算效率和節約了FPGA的存儲資源。特征參數經過切割后,它在內存中的排布方式變為了一維變量:[C/K][H][W][K]。
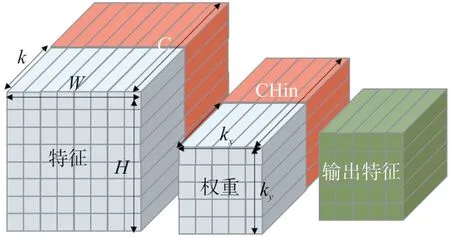
圖7 卷積運算的分解
權重參數在空間中的排布方式為四維變量,要將它展開為一維變量,也是對其輸入通道CHin 切割為CHin/K 個通道,實現每一個通道的K 路并行,它在內存中的排布方式變為一維變量:[CHout][Ky][Kx][CHin/K][K]。
4 卷積神經網絡加速器系統測試與實驗結果
4.1 實驗測試平臺
本設計采用Xilinx 公司推出的PYNQ-Z2 開發板作為測試平臺。PYNQ-Z2 采用的是ZYNQ-7020的芯片并且繼承了ZYNQ 開發平臺的優秀性能。同時,用戶可以通過Python 編寫代碼進行板上開發和測試。
4.2 手寫數字識別網絡測試
本設計采用圖1 所示的手寫數字識別網絡對設計的通用加速器進行驗證和測試,實驗分別為CPU軟件實現和調用FPGA 硬件加速器進行實現,通過兩者對比,分析FPGA 加速器的加速效果和計算精度,同時對加速器的功耗性能進行分析。
4.2.1 手寫數字識別網絡與MNIST 數據集
本設計所使用的手寫數字識別網絡是在LeNet-5網絡基礎上優化改進而來的,其網絡規模比LeNet-5略小,以28 pixel×28 pixel 單位大小的灰度圖像為輸入。本設計在主機端基于Tensorflow 框架采用MNIST 訓練集對該網絡進行訓練,訓練完的網絡模型在MNIST 數據集上的測試準確率達到98.42%。
4.2.2 實驗結果分析
本設計將從識別準確率,加速效果,資源消耗與功耗效率3 個方面對加速器運行手寫數字識別網絡的結果進行分析,在加速器中一律采用8 重并行運算,即K=8。
(1)識別準確率
為了測試加速器的計算精度,本實驗分別記錄了基于ARM 純軟件和基于FPGA 硬件加速器實現的手寫識別網絡在MNIST 測試集上的識別準確率,表2 給出了兩者準確率的對比結果。

表2 不同平臺的手寫數字識別準確率
從表2 中可以發現FPGA 平臺實現的手寫數字識別準確率要略微低于ARM 軟件平臺的手寫數字識別,這是由于本設計的加速器采用的定點量化的數據格式,因此在準確率方面有略微的下降,這一點點的損失可以忽略不計。
利用Jupyter-notebook 打印部分被正確或錯誤識別的圖片來驗證該網絡的識別效果。圖8 所示的是測試集中被正確識別的圖片樣例,可以看出這些圖片字跡清晰,易于辨認。圖9 所示的為被錯誤識別的樣例,可以看出這些被錯誤識別的圖片均字跡潦草,十分容易被混淆。

圖8 正確識別的圖片樣例

圖9 錯誤識別的圖片樣例
(1)加速效果
為了對比加速器的加速效果,本設計首先在ARM 處理器利用Tensorflow 框架運行手寫數字識別網絡,然后基于本文所設計的CNN 加速器運行該網絡,并記錄兩種方式識別不同數量手寫數字圖片所用的時間,運行時間的記錄通過調用time.time()函數實現。圖10 所示為本設計采用的手寫數字識別網絡在兩種實現方式下的耗時對比情況。
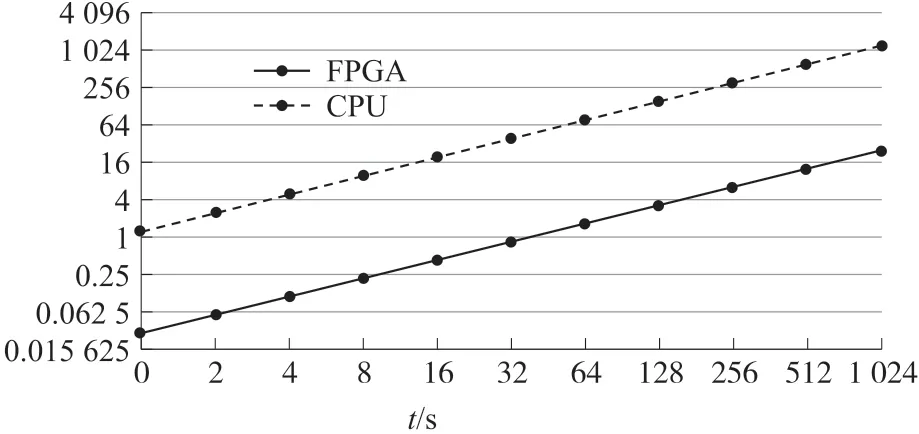
圖10 手寫數字識別網絡耗時情況
從圖10 中可以看出,基于FPGA 運行的MNIST網絡單張圖片耗時約為0.029 s,基于AMR 處理器運行的同一網絡單張圖片的識別耗時為1.22 s,在單幀圖片的處理速度上,本設計實現的通用加速器相對于CPU 純軟件計算實現了42.1 倍的加速效果。加速器實際能夠達到的計算速度可通過單位時間內處理的圖片幀數(Frame Per Second,FPS)來衡量,其計算方式如式(1)所示。
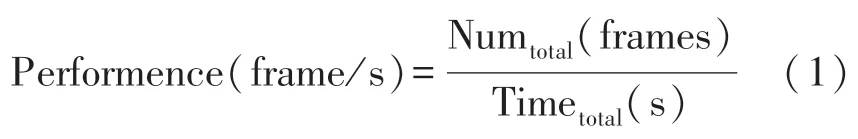
根據通用加速器處理1 024 張圖片所用時間,計算可知該加速器計算速度約為37.63 FPS,該計算速度滿足實時性要求。
(2)資源利用率與功耗效率
本設計根據Vivado 提供的綜合報告對資源利用率與功耗效率進行分析。表3 所示為CNN 加速器在PYNQ-Z2 開發板上實現后占用的資源情況。本設計采用對權重值和特征圖像值進行定點量化的方法,因此對BRAM 資源的消耗減少了很多,占用率只有9%。由于卷積網絡運算的過程中涉及到了大量的乘法加法運算,因此對FPGA 片上的乘加器陣列計算資源使用率較高,達到了39%,總體看來,所有的資源消耗都是在理想范圍之內的。
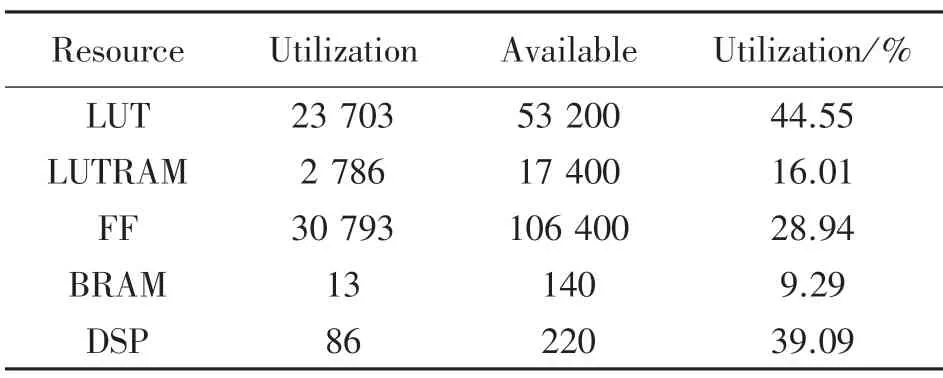
表3 PYNQ-Z2 資源利用情況
圖11 為Vivado 提供的功耗分析報告。可以看出,加速器運行時的平均功率約為1.825 W,其中系統動態功耗為1.684 W,約占系統總功耗的92%,靜態功耗為0.141 W,約占系統總功耗的8%。PYNQZ2 開發板中ARM 處理器的動態功耗相對更大,約占系統動態功耗的91%,而FPGA 端的加速電路的運行功率只有0.155 W,功耗相對較低。
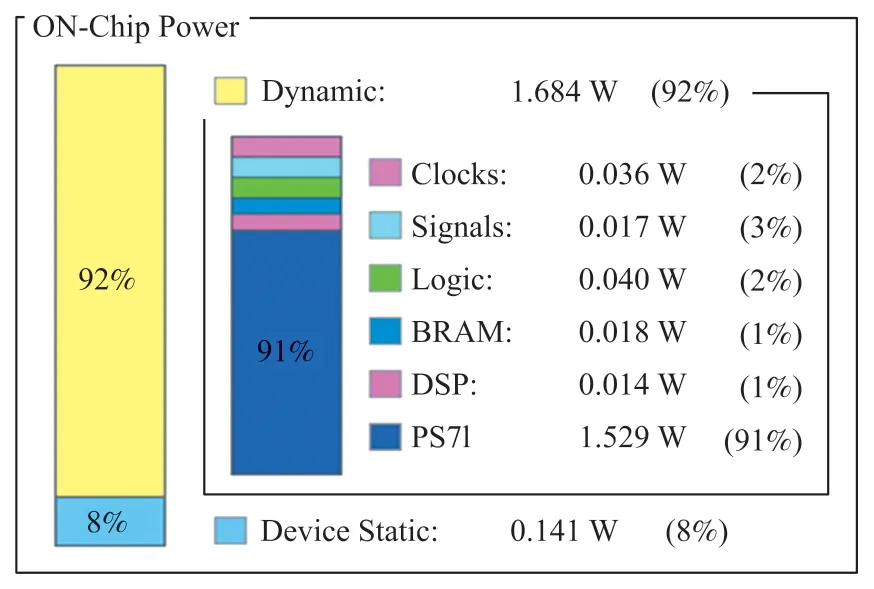
圖11 加速器功耗分布
加速器運行的功耗效率可通過單位功耗處理的MNIST 圖像幀數來衡量,其計算公式如式(2)所示。
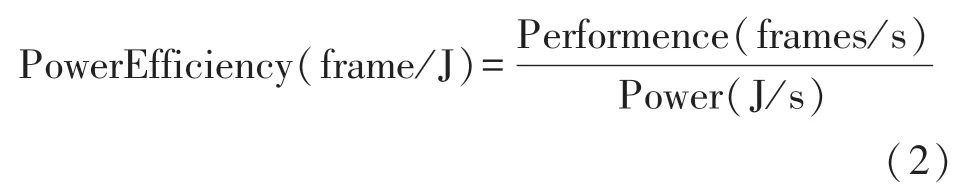
前文提到加速器的處理速度為37.63 FPS,結合加速器運行時的平均功率為1.825 W,換算可知加速器的功耗效率為20.6 frames/J,該功耗效率完全滿足嵌入式應用場景下的低功耗設計要求。
5 結束語
提出了一種基于FPGA 的高效可配置的CNN加速器,其中所有層以流水線方式同時工作,以提高系統的吞吐量和性能。為了利用CNN 的并行性,在卷積層采用了多種硬件優化策略,在速度,資源使用和功耗之間取得了良好的平衡。用手寫數字識別網絡模型進行測試,實驗結果表明,在PYNQ-Z2 FPGA 上實現了37.63 FPS 和20.6 frames/J的性能。該設計和驗證實驗表明,高效可配置的CNN 加速器是CNN 應用在嵌入式設備或移動終端上的最佳選擇。
猜你喜歡
河北畫報(2020年8期)2020-10-27 02:54:06
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
電子制作(2019年19期)2019-11-23 08:41:36
電子制作(2019年15期)2019-08-27 01:11:50
電子制作(2019年7期)2019-04-25 13:18:16
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
商周刊(2017年26期)2017-04-25 08:13:04
