基于March算法的網絡多維數據優化存儲方法
2021-10-24 12:37:46胡茂美
吉林化工學院學報 2021年9期
胡茂美
(合肥濱湖職業技術學院 機電與汽車工程學院,安徽 合肥 230601)
數據庫技術的迅速發展,導致各行各業積攢過多的數據量,信息存儲在企業發展過程中具有重要意義.數據庫的主要應用范圍是決策與分析,為這兩個應用提供優越的工作平臺[1],數據庫內數據存儲形式均是多維的.提升在數據庫內搜索有價值信息的效率,可幫助企業快速了解其自身情況[2].OLAP技術為用戶提供了一種決策支持的有效方法[3],該技術可提升用戶查詢數據速度,方便用戶使用,操作簡單.多維數據集屬于OLAP數據查詢的核心,通過Data Cube多維分析實現OLAP查詢.在Data Cube內包含數據的全部細節信息,也包含不同粒度中的聚集值.聚集記錄會浪費存儲空間,延長計算時間[4],降低OLAP分析效率,因此提升多維數據存儲效率是目前數據庫的主要研究方向.趙亞楠等人針對小文件存儲問題,提出大數據分布式存儲方法,提升存儲效率[5];陳波等人針對大量數據管理方式存在的缺陷,提出GeoSOT剖分網格的數據存儲方法,集中存儲大量數據,提升存儲效率[6].這兩種方法的缺點是未考慮多維數據存儲空間較大問題,嚴重浪費存儲空間.March算法為存儲器中常用的功能測試與地址解碼等測試向量,具備較優的故障與存儲時間測量性能[7].為此研究基于March算法的網絡多維數據優化存儲方法,節約存儲空間,提升存儲效率.
1 基于March算法的網絡多維數據優化存儲方法
1.1 網絡多維數據存儲結構
網絡多維數據的組織方式共有兩種,分別是維數據與度量數據組織,前者通過多維數據結構與存儲維的結構信息完成數據組織[8],后者通過加快聚集查詢效率完成數據組織.
1.1.1 存儲組織多維數據
組織維數據的步驟如下:
步驟1:存儲組織數據特征提取;
步驟2:映射特征點數據,使其變成多維數據組的坐標值.
維層次的偏序存在一定關系,該關系的表達形式是格,通過這些格構建一個無環圖,該圖具備方向性,這就說明能夠由鄰接表描繪并組織維的層次結構及成員間的關系[9].建立一個在全部層次以上的層次all,以all為起始點,建立一棵樹,all代表其根節點,all的孩子節點為其下層的全部成員.組織維成員可完成多維數據處理技術的Roll up與Drill down操作[10].然后,需對其實施編碼,具體步驟如下:
步驟1:整數編碼,在網絡多維數據組內,各維中的坐標均是整數,因此需將維護成員變更為整數.令多維數據集Gα的一個層次h中的成員是p1,…,pn,整數編碼的步驟為:
a.建立映射函數f;
b.針對h中的成員p1的f是f(p1)=0;
c.如果pα,1≤α≤n與pβ,1≤β≤n屬于鄰近,且pα≤pβ,那么f(pβ)=f(pα)+1.
令多維數據空間是(G1,G2,…,Gn,F1,F2,…,Fp),每個維的尺寸一致,由Gα表示,利用上述操作完成整數編碼,編碼后的多維數組是(g1,g2,…,gn,f1,f2,…,fp),那么多維數據位置是pos=(…((g1*G2+g2)*G3+…+gn-2)*Gn-1+gn-1)*Gn+gn.
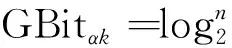
1.1.2 存儲組織度量數據
令(G1,G2,…,Gn,F1,F2,…,Fp),多維數據集Gα組建的數組是G1×G2×…×Gn,順序存儲過程中,依據G1,G2,…,Gn順序排列度量元素的位置[12].
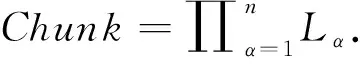
1.2 March算法
March算法屬于常用的存儲器測試方法,即對存儲器內的存儲方法展開測試,優化網絡多維數據存儲方法.該算法存在高故障覆蓋率與低時間復雜度的優勢.測試步驟如下:
步驟1:在全部存儲器內寫入所有是零的背景;
步驟2:讀取首個存儲單元,其正確讀取結果是0;
步驟3:將一個1錄入首個存儲單元,隨后讀取該單元,正確讀取結果是1;
步驟4:同理,剩余存儲單元執行步驟2與3,以全部存儲單元完成操作為止[13];
步驟5:所有單元的內容都是1,代表全部單元的背景均是1;
步驟6:讀取首個存儲單元[14],正確讀取結果是1;
步驟7:將一個0錄入首個存儲單元,隨后讀取該單元,正確讀取結果是0;
步驟8:同理,剩余存儲單元執行步驟6與7,以全部存儲單元完成操作為止.
步驟6能夠執行反操作,代表能夠以最后一個單元為起始點,按照順序執行讀取操作[15],結束條件是首個單元完成操作,以公式的形式表達如下:
(1)
其中,第i行第j列的存儲單元是Bij;讀取Bij的操作是RBij;將1錄入Bij內的操作是W(1)Bij;將0錄入內的操作是W(0)Bij;所有Bij的集合是?ij;集合?ij中的總和是∑;公式中全部操作過程中的分隔符是“,”;背景0與1是下標0與1.
利用公式(1)能夠計算獲取存儲方法的復雜度是2(1+1)N+N=5N,N代表單元數量.測試的操作次數由5N描繪,5N乘上完成各操作的時間就是總測試時間.5N的大小與測試時間成正比.
通過增加March算法的測試向量,加強其測試效率與故障覆蓋率,增加后的數據叫作數據背景(Data Back-ground).在March算法內讀取與錄入數據是1與0的情況下,便需將正向與逆向的數據背景用于相應的存儲方法中.
2 實驗分析
首先構建一個P2P網絡,在該網絡內各塑造一個Web服務器與Tracker Server服務器,剩余節點是OLAP網絡節點,在該網絡節點內建立一個虛擬的多維數據庫,該數據庫內共包含50 000個文件夾,利用方法對該數據庫內的多維數據實施優化存儲,驗證本文方法的有效性.
選取大數據分布式存儲方法[5],GeoSOT剖分網格數據存儲方法[6]作為本文的對比方法,測試本文方法在優化前后存儲不同文件夾數量時的各項性能,共實施5次實驗,記錄每次實驗的優化前后的數據存儲時間,取5次記錄時間的均值,測試結果如表1所示.
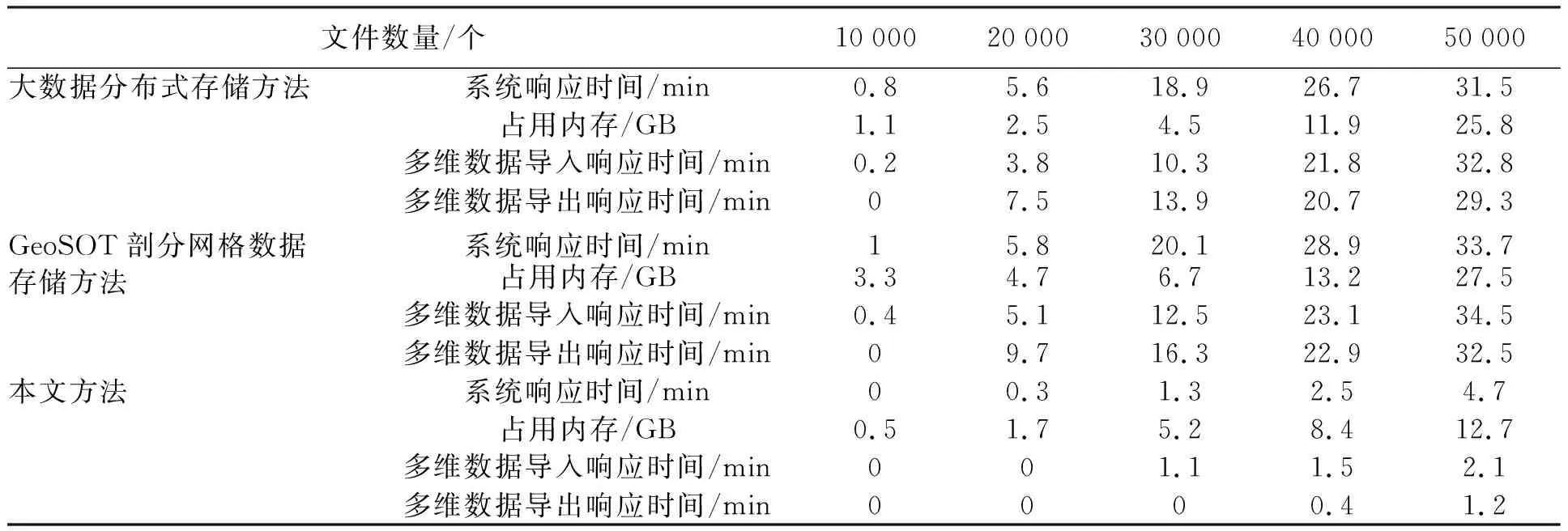
表1 3種方法的各項性能對比結果
根據表1可知,在存儲不同文件夾數量時,本文方法的系統響應時間在文件夾數量較少時優勢不明顯,當文件夾數量超過20000時,本文方法的系統響應時間顯著低于其余兩種方法;其余兩種方法在存儲多維數據時所占內存較大,本文方法存儲多維數據時的占用內存較小,原因是本文方法中包含壓縮存儲過程,有效減小內存占用空間;在文件夾數量較少時,其余兩種方法存儲多維數據時的導入與導出響應時間較短,與本文方法的多維數據導入與導出響應時間差距不大,當文件夾數量較多時,其余兩種方法的多維數據導入與導出響應時間明顯增長,響應速度顯著下降,本文方法的多維數據導入與導出響應時間無明顯變化,僅有小幅度增長現象,響應速度較快.實驗證明:在存儲不同文件夾數量時,本文方法的響應速度較快即存儲效率高,內存占用空間最小,具備較優的數據存儲性能.
測試3種方法分別存儲文件夾數量為5 000與50 000個時的數據存儲信噪比,測試在不同壓縮比時3種方法在數據存儲過程中的信噪比,測試結果如圖1與圖2所示.
根據圖1與圖2可知,文件夾數量為5 000時,壓縮比逐漸提升,本文方法在存儲多維數據時的信噪比無明顯變化,平均信噪比為94.5 dB;其余兩種方法的信噪比前期下降幅度較小,當壓縮比超過50后,其信噪比下降幅度均較大,平均信噪比分別為67.9 dB與69.9 dB;文件數量為50 000時,壓縮比逐漸提升,本文方法在存儲多維數據時的信噪比出現小幅度下降趨勢,平均信噪比為85.3 dB;其余兩種方法的信噪比下降幅度較大,當壓縮比為80時,兩種方法均出現數據存儲失真情況,平均信噪比為38.1 dB與39.3 dB.
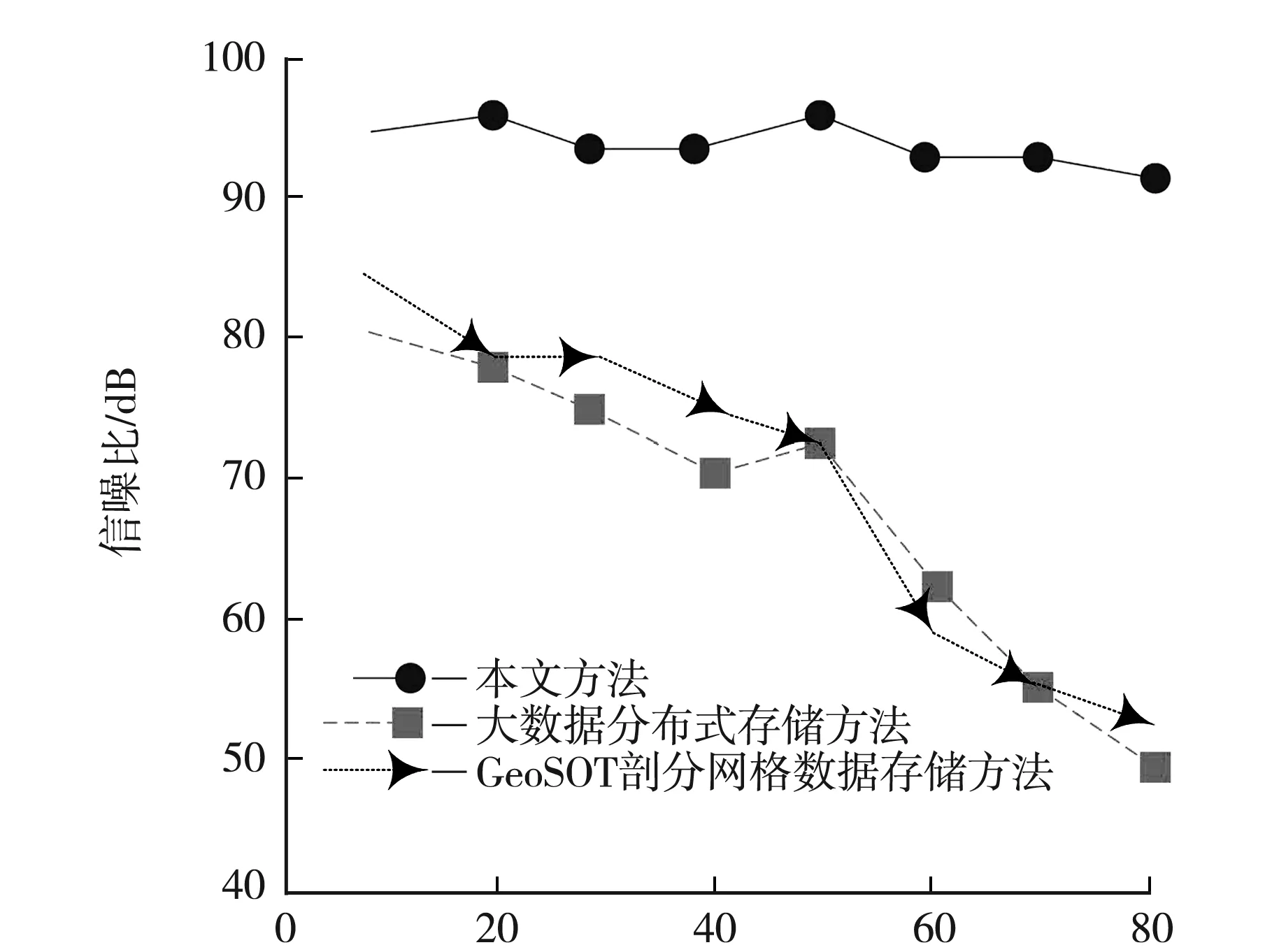
壓縮比圖1 文件夾數量為5 000時的信噪比
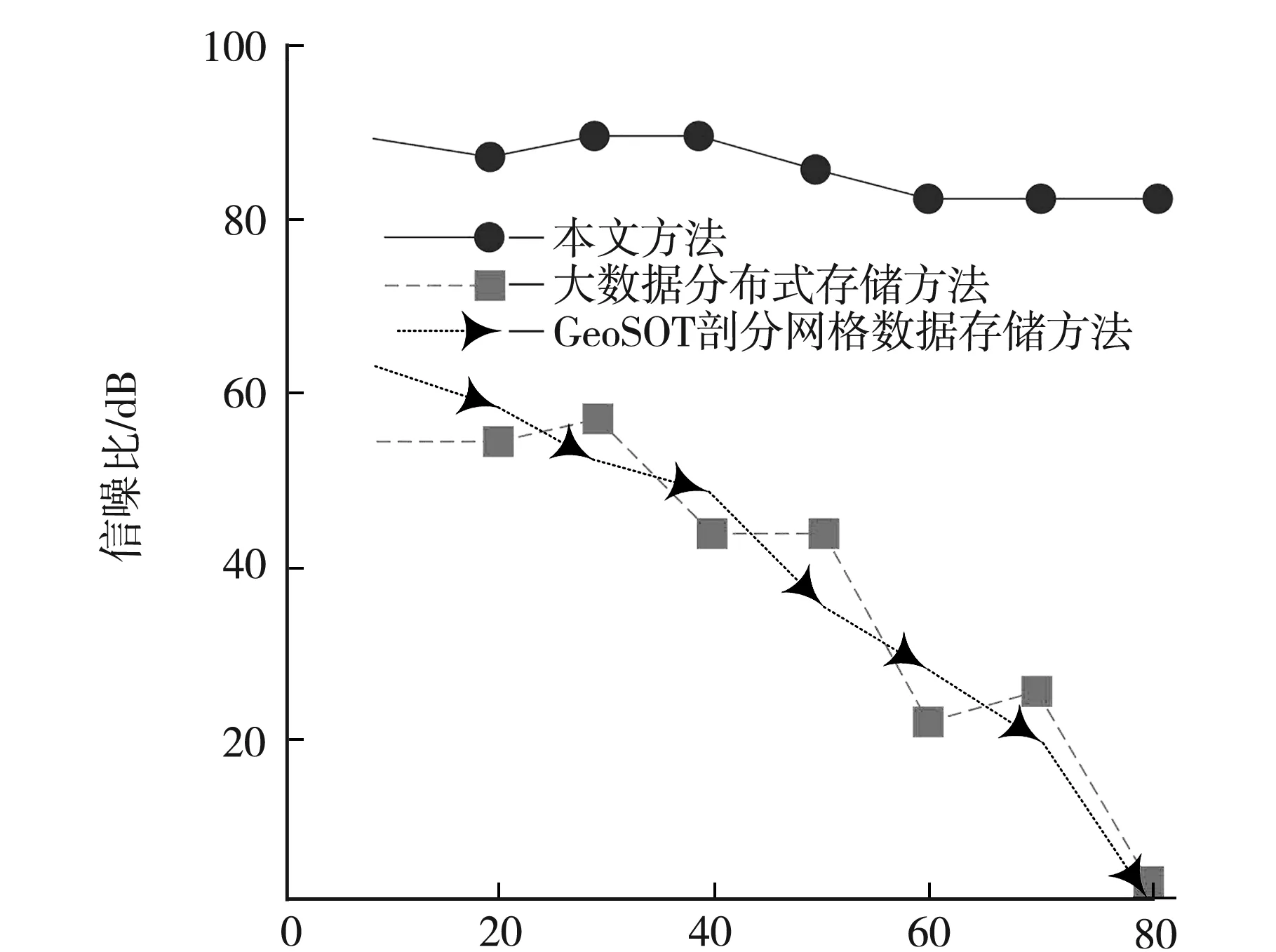
壓縮比圖2 文件夾數量為50 000時的信噪比
實驗證明:文件夾數量較大時,本文方法在存儲多維數據過程中的信噪比有所降低,但依舊高于其余兩種方法,在不同壓縮比時,本文方法在數據存儲過程中的信噪比最高.
文件夾數量為50 000時,3種方法的各項性能差距最為明顯,因此測試3種方法在存儲文件夾數量為50 000時且不同稀疏度情況下的數據存儲信噪比,數據稀疏度越高,所需存儲的字數越少,在不同稀疏度時的數據存儲過程中的信噪比測試結果如圖3所示.

稀疏度圖3 不同稀疏度時的信噪比測試結果
根據圖3可知,隨著稀疏度的不斷提升,3種方法數據存儲過程中的信噪比均有所增長,其余兩種方法的信噪比增長幅度較小,當稀疏度達到10時,大數據分布式存儲方法的信噪比不再發生改變,穩定在25 dB左右;當稀疏度達到12時,GeoSOT剖分網格數據存儲方法的信噪比不再發生改變,穩定在30 dB左右;本文方法的信噪比在前期增長速度較為緩慢,當稀疏度超過8時,信噪比增長速度較快.實驗證明:在不同稀疏度時,本文方法的多維數據存儲性能最優.
3 結 論
數據庫在各大領域的廣泛應用,導致各領域的網絡多維數據累積量顯著增長,造成傳統的多維數據存儲方法不足以滿足用戶對數據庫的高要求.因此提出基于March算法的網絡多維數據優化存儲方法,提升數據優化存儲性能,更好地符合MOLAP快速性的要求.
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
財經(2016年15期)2016-06-03 07:38:02
Coco薇(2016年2期)2016-03-22 02:42:52
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
