基于雙遷移度量學習和注意力機制的跨域推薦
2021-10-21 08:15:56普洪飛邵劍飛
電視技術 2021年8期
普洪飛,邵劍飛
(昆明理工大學 信息工程與自動化學院,云南 昆明 650500)
0 引 言
隨著互聯網技術的發展,人們對于網絡資源的依賴和需求不斷增長,如何為用戶推薦其感興趣的項目,成為重要的研究課題,因此推薦系統被提出并應用[1]。從傳統的內容推薦系統和協同過濾域到現在的深度學習推薦系統,盡管其簡單有效[2],卻存在評分數據稀疏和用戶冷啟動問題[3]。為了解決推薦系統中的冷啟動和稀疏性問題,研究人員提出了跨領域推薦系統[4]。
跨領域推薦的目標是利用其他領域的用戶偏好信息和項目特征等各種輔助信息,來提高目標領域的推薦性能,有效緩解目標領域的數據稀疏性和冷啟動。例如,喜歡武俠書籍的人,也會比較喜愛武俠片,因此即使在不同的領域也可能有相同 的愛好。
但是,大多數現有方法只關注提高目標域推薦的性能,即利用來自源域的信息來改進目標域的推薦性能。這種方法忽略了源域的信息可以提高目標域、同時目標域也可以提高源域的推薦性能。例如,一旦知道用戶想要閱讀的書籍類型,就可以推薦相關主題的電影,形成一個循環,以便在兩個域中同時提高推薦性能。
以前的研究顯示,雙遷移學習模型[5]能夠高效地提高源域和目標域的推薦性能。基于此,研究人員提出將雙遷移學習機制應用于跨域推薦,通過提取每個域中的偏好信息并雙向傳輸不同域之間的用戶偏好,來同時提高不同域的推薦性能。
現有的跨域推薦模型通常需要不同域的大量重疊用戶作為“樞軸”,以便學習用戶偏好的關系,并產生令人滿意的推薦性能[6]。這些重疊用戶在兩個域類別中消耗了商品,如觀看電影和讀書。然而,收集足夠多的重疊用戶,在許多應用中實現起來比較困難。例如,可能只有有限數量的用戶在亞馬遜上購買了書籍和數字音樂。因此,重要的是要克服這個問題,并最大限度地減少跨域推薦中兩個域所需的重疊用戶數量。
為了解決這個問題,可以采用基于重疊用戶構建跨域推薦系統的解決方案。假設兩個用戶在某個域中具有相似的偏好,那么這兩個用戶的偏好在其他域中也是相似的。潘等人提出了將度量學習和雙學習集合起來,通過度量學習減少兩個域的重疊用戶,同時提高源域和目標域的推薦性能,潘等人[7]將這種方法命名為雙遷移度量學習模型(Dual Metric Learning,DML)。
但是雙遷移度量學習模型(DML)是以普通的多層感知機(MLP)為基礎推薦系統,不能更好地提取用戶和項目之間的非線性交互特征。注意力機制是一種人腦模擬模型,能夠通過計算概率分布來突出輸入的關鍵信息對模型輸出結果的影響,從而優化模型。注意力機制能夠充分地利用句子的全局和局部特征,給重要的特征賦予更高的權重,從而提高特征抽取的準確性。因此,本文提出基于雙度量學習(DML)和注意力機制的跨域推薦系統,命名為DML-A模型。實驗證明,此方法可以同時提高源域和目標域的推薦性能,而且模型準確性更高。
1 模型介紹
1.1 度量學習
由于用戶偏好在不同域中的差異性,每個域中的用戶嵌入的分布也應該是不同的。做一個假設:如果兩個用戶對某個域具有相似的興趣,那么這兩個用戶也會對其他域具有相似的興趣。本文的目標是解決這個假設,利用這些重疊用戶作為“樞軸”,以學習不同域中的用戶偏好與行為的關系。
DML模型利用雙遷移學習機制同時提升兩個域的推薦性能。源域的用戶向量經過度量學習后,作為目標域推薦系統的輸入。相同地,使用目標域中經過度量學習輸出,作為源域的輸入。通過這種方式,可以迭代提高兩個域的推薦性能。通過迭代地重復學習過程,每次都會獲得更好的度量映射和推薦系統,直到學習過程滿足收斂標準。因此,度量學習[8]可以更好地捕獲用戶偏好,從而提供更好的推薦性能。
將A域和B域的用戶向量表示為WUA、WUB,將兩個域的重疊用戶表示為ouA=ouB,重疊用戶向量表示為WouA、WouB。模型的目標是在相同的重疊用戶下,找到最佳映射矩陣X,來最小化映射矩陣乘A域用戶重疊向量XWouA和B域目標用戶重疊向量之間的距離:
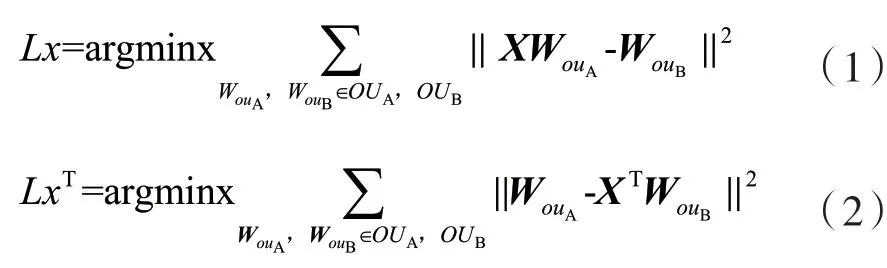
將映射矩陣X限制為正交映射(即XTX=I),其用于強制保持每個域用戶偏好的結構不變性。優化式(1)和式(2)以學習正交度量映射矩陣X。
1.2 雙遷移學習
遷移學習[9]將已訓練好的模型參數遷移到新的模型來幫助新模型訓練。考慮到大部分數據或任務存在相關性,因此通過遷移學習可以將已經學到的模型參數通過某種方式來分享給新模型,從而加快并優化模型的學習效率。用于跨域推薦的現有遷移學習方法包括協作DualplSA[10]、聯合子空間非負矩陣分解JDA[11]。
此外,為了同時提升兩個學習任務的性能,研究人員提出了雙遷移學習機制[12],同時學習邊緣和條件分布。最近,研究人員通過雙遷移學習機制實現了對機器翻譯的良好表現[13],這證明雙遷移學習在研究中具有重要的研究意義。
本文利用前階段中學到的度量映射矩陣X來模擬跨域用戶偏好,對源域和目標域(A域,B域)進行用戶評級,如下所示:

式中:WUA、WUB、WiA、WiB分別表示為A域和B域的用戶特征向量和項目特征向量,RSA、RSB分別表示為A域和B域的推薦系統,rA*和rB*分別表示為A域和B域的評分輸出。雙遷移學習需要跨兩個域進行傳輸循環,并且學習過程通過循環迭代。
1.3 DML-A模型
在度量學習中所做的潛在假設是:如果兩個用戶對一個域具有相似的興趣,那么這兩個用戶對其他域也會具有相似的興趣。本文的目標就是驗證這個假設,所以本文需要在相同的用戶重疊中找到最佳映射矩陣X,用X來模擬重疊用戶的跨域偏好,其中度量映射X是通過式(1)和式(2)不停地迭代直到收斂而來。
整個DML-A模型分為三個部分,如圖1所示,分別為推薦系統A、推薦系統B、潛在正交度量 矩陣。
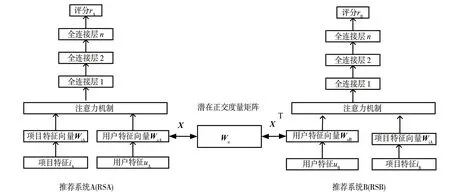
圖1 DML-A模型

(14)更新參數RSA和RSB
(15)End for
(16)直到收斂結束
整個算法分為三個部分,首先輸入項目和用戶特征,然后轉換成用戶和項目特征向量,讓它們經過推薦系統(RSA和RSB),得到預測評分,然后通過反向傳播預測評分和真實評分之間的損失值,然后更新RSA和RSB的參數,一直不停地循環來更新模型參數,直到收斂為止。輸入A域和B域的重疊用戶向量和映射矩陣X,通過后向傳播映射X和用戶重疊向量XWouA和WouB之間的損失值,然后更新映射矩陣X,一直循環更新映射矩陣X,直到收斂為止。第三部分最為重要,在第二部分得到了映射矩陣X來模擬重疊用戶的跨域偏好,如公式所示將XWuA,WiA作為RSA的輸入,XTWuB,WiB作為RSB的輸入,輸出預測評分r*A和r*B,后向傳播預測評分和真實傳播的損失值,更新參數,一直循環到收斂。
2 實驗介紹
2.1 實驗數據
本文采取了Amazon數據集進行評估,該數據集主要包含用戶對網站商品的評價信息及商品元數據,由從亞馬遜平臺收集的用戶購買行為和評級信息組成。本文選擇具有足夠多重疊用戶的兩個域來進行實驗,分別選擇名為Movie and TV的數據集和Book數據集,作為源域和目標域數據。簡單描述這兩個數據集如下:每行數據由用戶id、項目id及用戶對項目的評分組成,由多行數據構成一個數 據集。
2.2 評價指標
均方根誤差RMSE(Root Mean Squared Error,RMSE)通過計算預測評分與真實評分之間的誤差來衡量推薦結果的準確性。RMSE為:
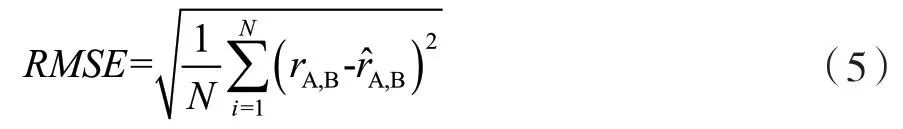
式中:N表示測試數據的數量,rA,B表示為真實的評分,r^A,B表示經過DML-A模型的評分預測值。RMSE的值越小,表示推薦準確性越高。
2.3 數據集和實驗結果分析
將目標域數據隨機分為訓練集和測試集,其中80%的數據用于訓練,20%用于測試。實驗采用Pytorch作為實驗框架,實驗配置為:Intel Core i5-10200H處理器、8 GB內存、NVIDIA GTX 1050 TI顯卡。學習率設置為0.01,Dropout設置為0.5,批次設置為1 024,訓練批次為32,優化函數為Adam,特征嵌入維度為16,全連接層設置為8。
為了驗證模型的推薦準確度,對本文所提出的DML-A模型和沒有添加注意力機制的DML模型進行對比,分別在兩個實驗數據Movie and TV的數據集和Book數據集進行實驗。實驗結果如圖2和圖3所示。
如圖2和圖3所示,采用的訓練批次為32批次。在Book數據集中,DML模型和改進的DML-A模型在前10個批次,RMSE的值不斷下降,在10批次之后趨向于平衡。在Book數據集中可以清晰地看到,經過本文改進的注意力機制DML-A模型的RMSE值一直都比DML模型小,證明本文的模型推薦性能更優。在Movie數據集中,在15個批次之前,DML和DML-A模型RMSE的值不斷下降,在15批次之后趨向于平衡。可以清晰地看到,經過本文改進的注意力機制DML-A模型的RMSE值一直都比DML模型小,同樣證明本文的模型推薦性能更優。綜上所述,改進后的DML-A模型可以同時提高Movie域和Book域的推薦性能。
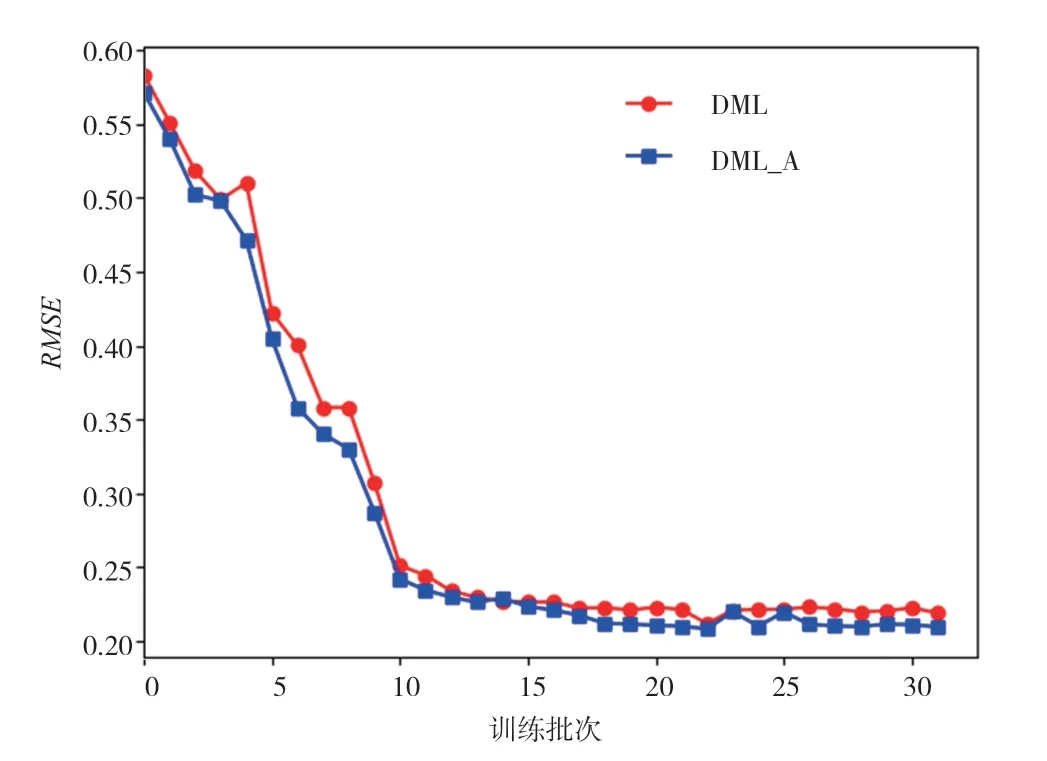
圖2 Book數據集的RMSE值
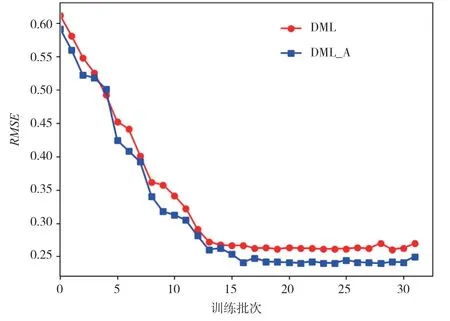
圖3 Movie數據集的RMSE值
3 結 語
本文提出了一種基于注意力機制和雙度量學習的跨領域推薦模型DML-A,將注意力機制應用和雙遷移度量學習結合,通過減少源域和目標域之間的重疊用戶,利用源域和目標域的信息來實現雙方性能的提升。在未來的研究中將會對注意力機制進行改進,同時將增加數據集和評價指標來豐 富實驗。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
