基于強化學習的高速飛行器巡航段高度控制
2021-10-13 06:25:24池海紅于馥睿郭澤會
哈爾濱工程大學學報 2021年9期
池海紅, 于馥睿, 郭澤會
(1.哈爾濱工程大學 智能科學與工程學院,黑龍江 哈爾濱 150001; 2.北京空天技術研究所, 北京 100074)
高速飛行器是指飛行速度大于5Ma的飛行器,具有飛行速度快,突防能力強等特點[1]。近年,隨著航天技術的發展,高速飛行器成為研究的熱點,隨著研究的深入和不斷的實驗驗證,它在軍事和民用上的作用變得越來越重要。
然而,由于高速飛行器模型具有高度非線性,嚴重耦合以及參數不確定等特點,有效合理地設計高速飛行器的控制器是非常困難的。除此之外,由于高速飛行器跨介質飛行,其飛行包線大,因此其氣動參數呈現出強非線性特點以及明顯的不確定性,采用一些傳統的控制算法已經不能滿足其控制指標的要求。現代控制方法經過幾十年的蓬勃發展,已經形成一個完整的體系,將現代控制算法應用在高速飛行器上成為國內外許多學者研究的熱點。
文獻[2]對高速飛行器縱向模型設計了一種魯棒自適應Backstepping控制器,將高度子系統分解成彈道傾角回路、攻角回路以及俯仰角速度回路。文中對這幾個回路分別設計控制器,并且采用指令濾波方法防止微分爆炸,同時設計自適應律估計不確定參數。文獻[3]針對高速飛行器縱向模型設計了一種反饋線性化方法。通過狀態反饋,將飛行器高度子系統和速度子系統進行輸入輸出線性化,分別近似為四階積分系統和三階控制系統,最后在此基礎上進行滑模控制器的設計。文獻[4]針對高速飛行器具有外部擾動以及輸入舵偏角飽和的特點,設計了一種基于滑模干擾觀測器的抗飽和滑模控制器,對于系統中存在的擾動和不確定性,采用滑模干擾觀測器對其進行估計并在滑模控制器中進行補償。文獻[5-7]采用自抗擾控制算法對高超聲速飛行器進行控制,將飛行器的外部和內部擾動看作總擾動,設計擴張狀態觀測器對總擾動進行估計并進行補償。文獻[8]針對傳統的擴張狀態觀測器連續但非光滑的特性,改進了擴張狀態觀測器,構造了連續光滑的qin函數,在此基礎上設計高速飛行器姿態的自抗擾控制算法。由于高速飛行器具有模型階數高的特點,以上的控制算法中均或多或少地包含了模型信息。由于建模不確定性,這些模型信息有時很難準確獲得。
近年,隨著人工智能的快速發展,智能控制在飛行器上的應用引起了學者們的廣泛關注。由于神經網絡具有逼近任意非線性連續函數的能力,因此具有很強的泛化能力。文獻[9]將高速飛行器縱向模型轉換為嚴格反饋形式,針對模型的不確定性設計了單隱藏層反饋神經網絡對控制器進行學習,采用極限學習機對隱藏層的參數進行學習更新。文獻[10]針對高速飛行器外部擾動以及參數不確定的特點,將縱向模型基于歐拉法轉換為速度、高度、彈道傾角、俯仰角以及俯仰角速度這5個一階離散子系統,并對每個子系統設計反饋控制器。由于反饋控制器中包含了模型信息,所以采用神經網絡對其進行近似,最后構造李雅普諾夫函數證明系統的穩定性。文獻[11]對高速飛行器縱向模型并考慮彈性模態進行連續神經網絡控制器的設計。
強化學習作為機器學習的一個分支,由于其不同于以往監督學習的特點,智能體在與環境交互過程中,通過環境的獎勵反饋來判斷當前動作的品質,在這種與環境交互學習的過程中,控制策略收斂的方法不需要了解被控對象的內部模型信息,因而這種模擬人類學習過程的方法近幾年被廣泛關注。在強化學習控制中,由于因果性,普遍采用神經網絡來近似性能指標以及控制策略。文獻[12]對高速飛行器縱向模型進行強化學習與滑模結合控制,其中滑模控制器的作用是穩定系統,強化學習為輔助控制,用于在線估計擾動。文獻[13]采用強化學習方法對高速飛行器縱向模型的建模不對定性進行估計,并采用魯棒自適應控制進行系穩定以及對估計的建模不確定性進行補償。
以上文獻中提及高速的強化學習方法都是將強化學習作為輔助控制的,最核心的控制依然是現代控制。本文提出的基于強化學習的高速飛行器高度控制算法,不同于以上文獻,本文將強化學習作為核心控制,并且以強化學習控制作為系統唯一的穩定控制算法。本文提出的算法不包含任何模型信息,只需要輸入輸出量及其相應導數即可。對于模型不確定問題,在仿真試驗中,對氣動參數進行正負極限拉偏,從而驗證本方法對于模型不確定性依然有很好的控制效果。
1 高速飛行器高度縱向模型
高速飛行器高度縱向模型為:
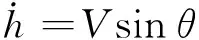
(1)
(2)
(3)
(4)
式中:h為飛行高度;θ為彈道傾角;α為攻角;ωz為俯仰角速度;V為飛行速度;L為升力;T為推力;m為飛行器質量;Mz為俯仰力矩;Jz為轉動慣量。L、T、Mz、r、q計算表達式為:
L=qSCL
(5)
T=qSCT
(6)
(7)
r=h+Re
(8)
(9)
式中:q為動壓;ρ為大氣密度;CL、CT和CM分別為升力系數、推力系數以及俯仰力矩系數;S為飛行器參考面積;r、Re分別為地心距和地球半徑。縱向氣動參數為:
CL=0.620 3α
(10)
CM(α)=-0.035α2+0.036 617α+5.326 1×10-6
(11)
CM(δe)=ce(δe-α)
(12)
(13)
由于高速飛行器采用的是超燃沖壓發動機,在飛行過程中攻角要保持在一定小的范圍內,因此式(2)中L+Tsinα≈L。在高速飛行器巡航飛行過程中,彈道傾角始終保持在較小值,即使做高度機動動作,變化的高度相對于飛行器所在高度仍然是可以忽略的,因此彈道傾角在飛行器做高度機動的過程中看做較小值也是合理的。因此式(1)可變為:
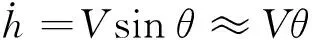
(14)
假設在高速飛行器做高度機動的過程中,速度保持為定值。對式(14)求導并將式(2)代入式(14)可得:
(15)
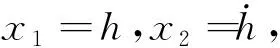
(16)
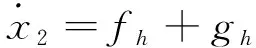
(17)
式中?為俯仰角。fh與gh表達式為:
(18)
(19)
根據幾何關系:?=α+θ。令x3=?,x4=ωz,則式(3)和(4)可寫成:
(20)
(21)
f?與g?表達式為:
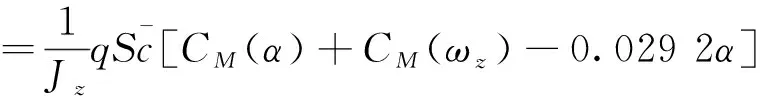
(22)
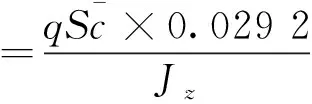
(23)
2 強化學習控制器設計
2.1 BP神經網絡逼近
在強化學習控制器中,BP神經網絡將被用于逼近控制策略和性能指標函數。BP神經網絡理論上在節點足夠多的情況下能夠以任意精度逼近定義在緊集Ω?Rn上的任何非線性連續函數。BP神經網絡在輸入量x=[x1x2…xn]T∈Ω?Rn與輸出量y∈Rn之間形成的映射定義為:
y=ωTφ(vTx)
式中:ω∈RN×1為隱藏層和輸出層之間的權值;N為隱藏層節點數;φ(·)為隱藏層的激活函數通常取為φ(·)=tanh(·);v∈Rn×N為輸入層和隱藏層之間的權值。對于一個未知連續非線性函數f(x),存在理想權值ω*∈RN×1使得:f(x)=ω*Tφ(vTx)+ε,|ε|≤εM。ε和εM分別為逼近誤差和逼近誤差的上界。
2.2 高度子系統強化學習控制器設計
高度子系統強化學習控制器設計的目的是使飛行器高度能夠以一定精度并且穩定地跟蹤期望高度指令hd。高度子系統的輸入是期望俯仰角?d。這里假設飛行器的高度、俯仰角能夠通過傳感器測量得到。
令x1d=hd,定義高度跟蹤誤差為:
eh=h-hd=x1-x1d
(24)
定義濾波誤差為:
(25)
式中λh>0,λh∈。
求導可得:
(26)
理想控制律可以設計為:
(27)
由于理想控制律中包含fh、gh等模型信息,因此在實際中不能應用。接下來,將采用強化學習來進行控制器設計,該控制器結構由動作網絡和評價網絡組成,評價網絡的作用是根據飛行器當前狀態來評價表現好壞,動作網絡則是根據評價網絡的評價輸出來產生相應的控制量。
2.2.1 評價網絡設計
定義性能指標函數為:
(28)
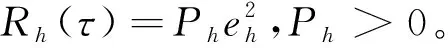
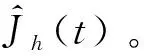
(29)
評價網絡的作用是通過當前飛行器的狀態信息從而輸出對性能指標函數的估計值。因此評價網絡設計為:
(30)
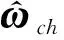
2.2.2 動作網絡設計
動作網絡的作用是根據評價網絡對性能指標函數的估計值來計算控制量。對于理想控制律(27),可以采用動作網絡來對其進行逼近。動作網絡設計為:
(31)
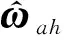
那么理想控制律(27)可表示為:
(32)
2.2.3 評價網絡權值更新
對于評價網絡,其權值更新的目標是最小化估計誤差ech。因此定義評價網絡的目標函數為:
(33)
根據梯度下降法,評價網絡更新律為:
(34)
式中σch為評價網絡的學習率,0<σch<1。
對式(34)進一步推導:
(35)
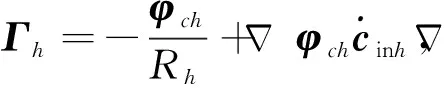
2.2.4 動作網絡權值更新
動作網絡的逼近誤差為:
(36)
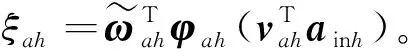
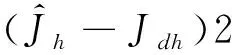
(37)
動作網絡權值更新的目標就是最小化目標函數。因此根據梯度下降法,評價網絡更新律為:
(38)
式中σah為動作網絡的學習率,0<σah<1。
對式(38)進一步推導:
(39)
由于在動作網絡權值更新律表達式中存在ξah項。因此無法將其獲得。接下來,根據濾波誤差表達式來將其求出。
由式(26)可得:
(40)
將式(31)和(32)代入式(40)可得:
gh(ξah-εah)-K1rdh
(41)
因為εah很小可忽略,所以可以求得:
(42)
將式(41)代入式(39)可得:
(43)
因此,經過一系列推導之后得出的動作網絡權值更新律中的所有項均可獲得,而且不包含任何模型信息。
2.3 姿態子系統強化學習控制器設計
姿態子系統強化學習控制器的設計目的是使飛行器的俯仰角能以一定精度并且穩定地跟蹤由高度子系統產生的期望角指令?d。姿態子系統的輸入是升降舵偏角δe。由于姿態子系統數學模型的形式與高度子系統一致,所以姿態子系統強化學習控制器設計步驟也與高度子系統相同。
令x3d=?d,定義俯仰角跟蹤誤差為:
e?=?-?d=x3-x3d
(44)
定義濾波誤差為:
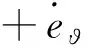
(45)
式中λ?>0,λ?∈R。
對濾波誤差求導可得:
(46)
理想控制律可以設計為:
(47)
2.3.1 評價網絡設計
定義性能指標函數為:
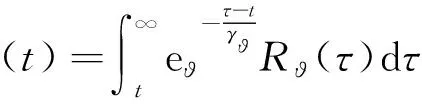
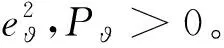
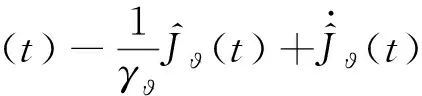
(48)
評價網絡設計為:
(49)
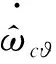
2.3.2 動作網絡設計
動作網絡設計為:
(50)
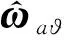
那么理想控制律(47)可表示為:
2.3.3 評價網絡權值更新
(51)
式中σc?為評價網絡的學習率,0<σc?<1。
對式(51)進一步推導:
(52)
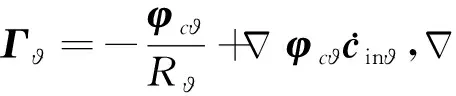
2.3.4 動作網絡權值更新
動作網絡的逼近誤差為:
(53)
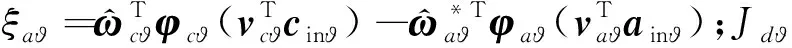
姿態子系統動作網絡權值更新律的推導步驟與高度子系統完全相同,這里直接給出動作網絡權值更新律表達式:
(54)
2.4 高速飛行器縱向高度強化學習控制算法結構圖
綜合前2部分的推導,基于強化學習的高速飛行器高度控制算法結構圖如圖1所示。
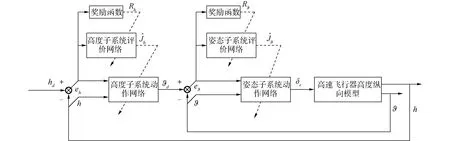
圖1 控制器結構Fig.1 Controller structure
3 仿真分析
本文采用數值仿真來驗證所設計的強化學習高度控制算法的有效性。飛行器的模型采用的是式(1)~(4)的非線性模型進行的數值仿真。飛行器的初始狀態為:V=4 590.3 m/s,h(0)=33 528 m,θ(0)=0°,α(0)=0°,ωz(0)=0°/s。機動后高度為h(∞)=34 028 m,機動爬升高度為500 m。期望高度變化參考模型為:
式中:hd為高度參考指令;hc為機動后高度;ω1=0.2,ω2=0.1,ζ=0.7。
強化學習控制器參數為:高度子系統與姿態子系統的動作網絡和評價網絡的隱藏層節點數均為20,即Nch=Nah=Nc?=Na?=20。
vch、vah、vc?、va?取(0,1)的隨機數并且保持不變。wch、wah、wc?、wa?初始值均為0。學習率σch=0.2,σah=0.2,σc?=0.2,σa?=0.2。λh=300,λ?=300,Ph=50,P?=50,K1=5,K2=15。
3.1 標稱狀態下仿真分析
在氣動參數無拉偏條件下仿真結果如圖2~6所示。由圖2可以看出,對于高度子系統來說,所設計的強化學習控制器能夠快速穩定地跟蹤高度參考指令。姿態子系統跟蹤曲線如圖3所示,俯仰角同樣能夠快速穩定地跟蹤高度子系統的俯仰角指令。圖4為升降舵偏角變化曲線,從圖4中可以看出,舵偏角始終保持在合理范圍內。圖5和圖6分別為評價網絡權值變化曲線和動作網絡的權值變化曲線,可以看出評價網絡的變化曲線逐漸趨于收斂且穩定,動作網絡權值曲線變化逐漸趨于平穩并收斂,因此控制策略也隨之收斂。
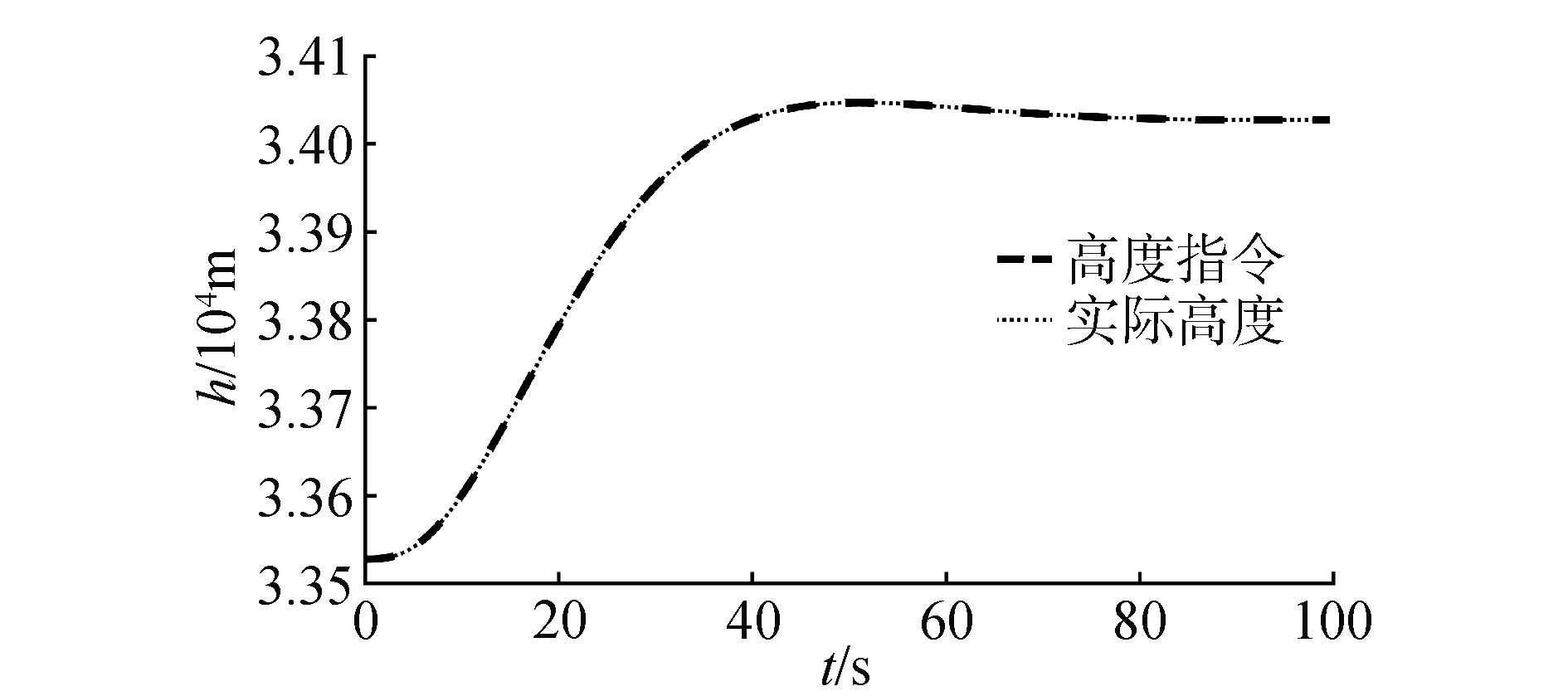
圖2 高度跟蹤曲線Fig.2 Altitude tracking
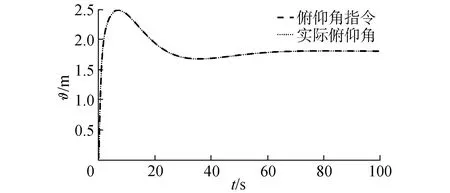
圖3 俯仰角跟蹤曲線Fig.3 Pitch angle tracking
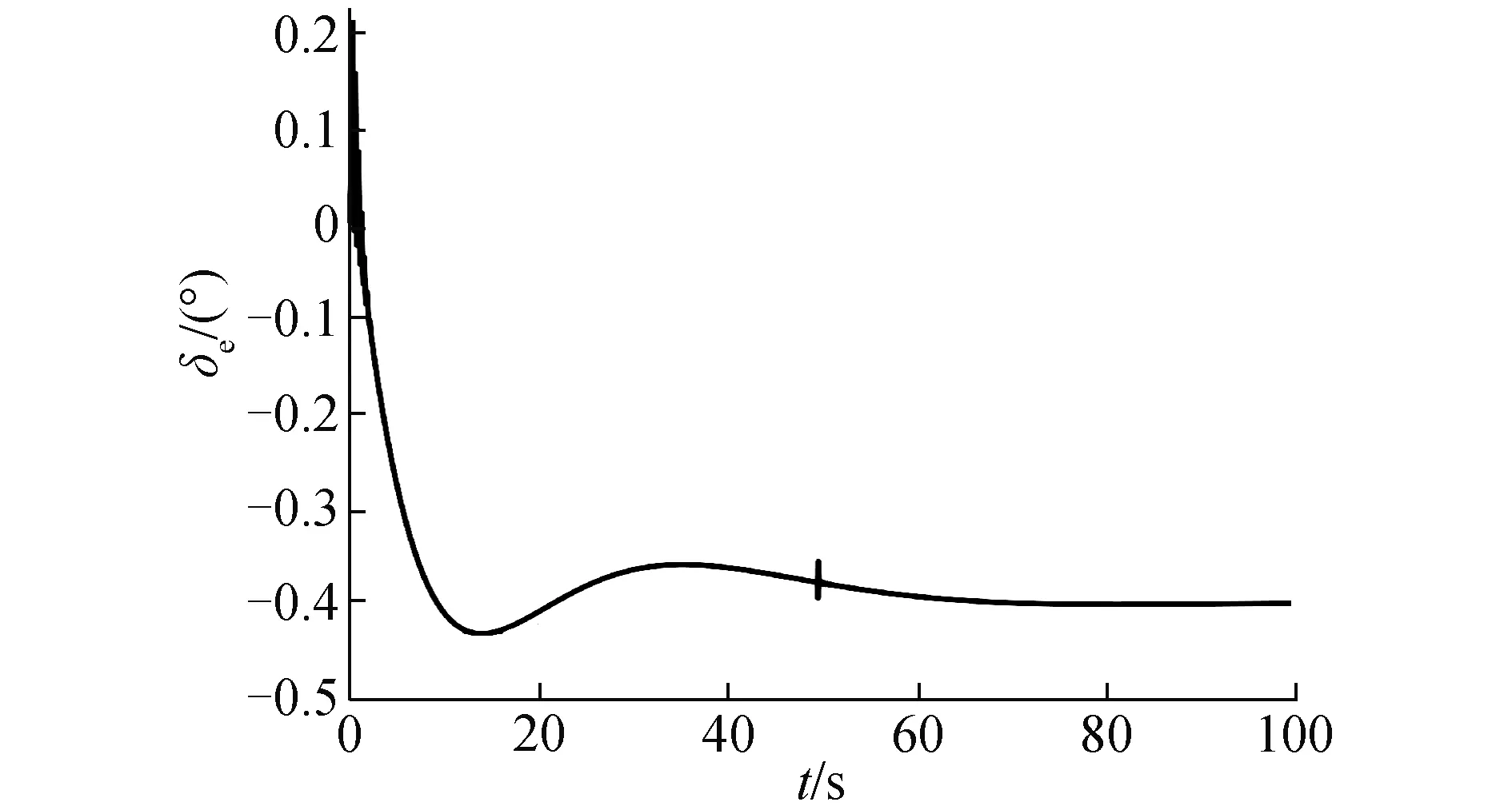
圖4 升降舵偏角變化曲線Fig.4 Elevator deflection
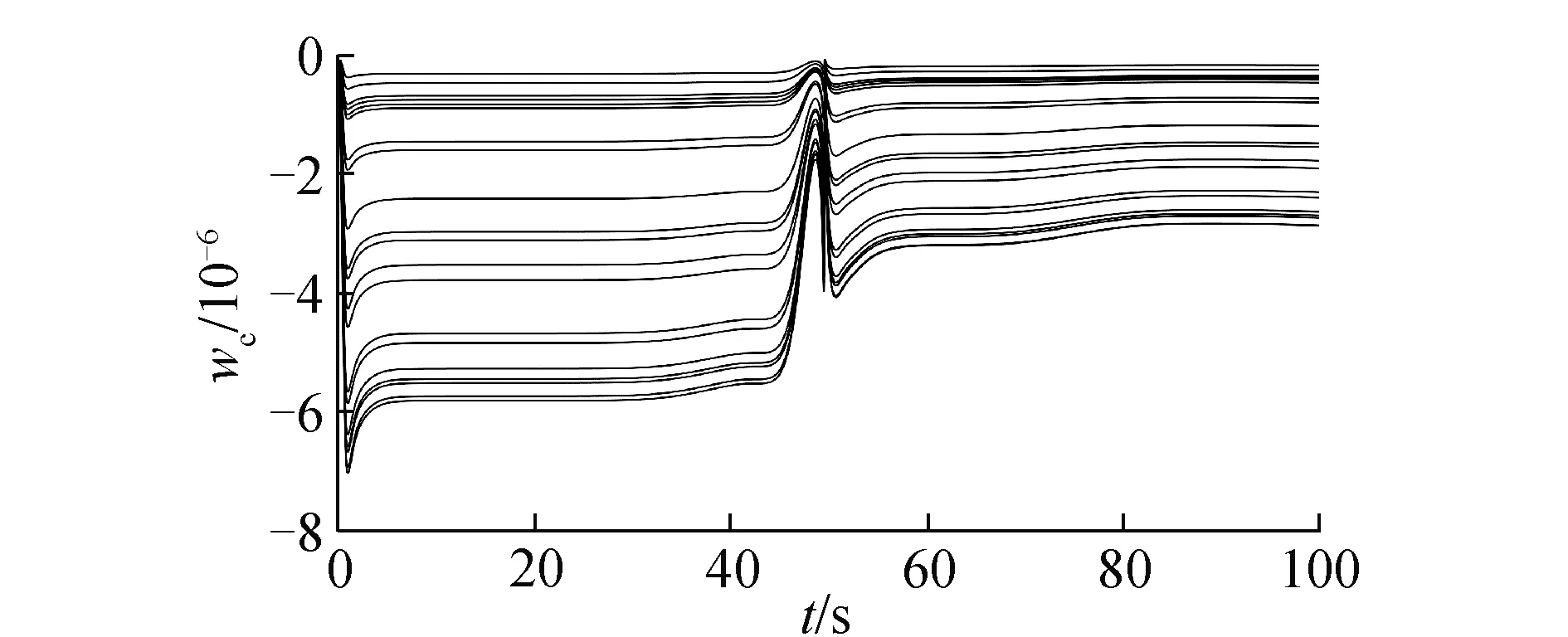
圖5 評價網絡權值變化曲線Fig.5 Critic NN weights
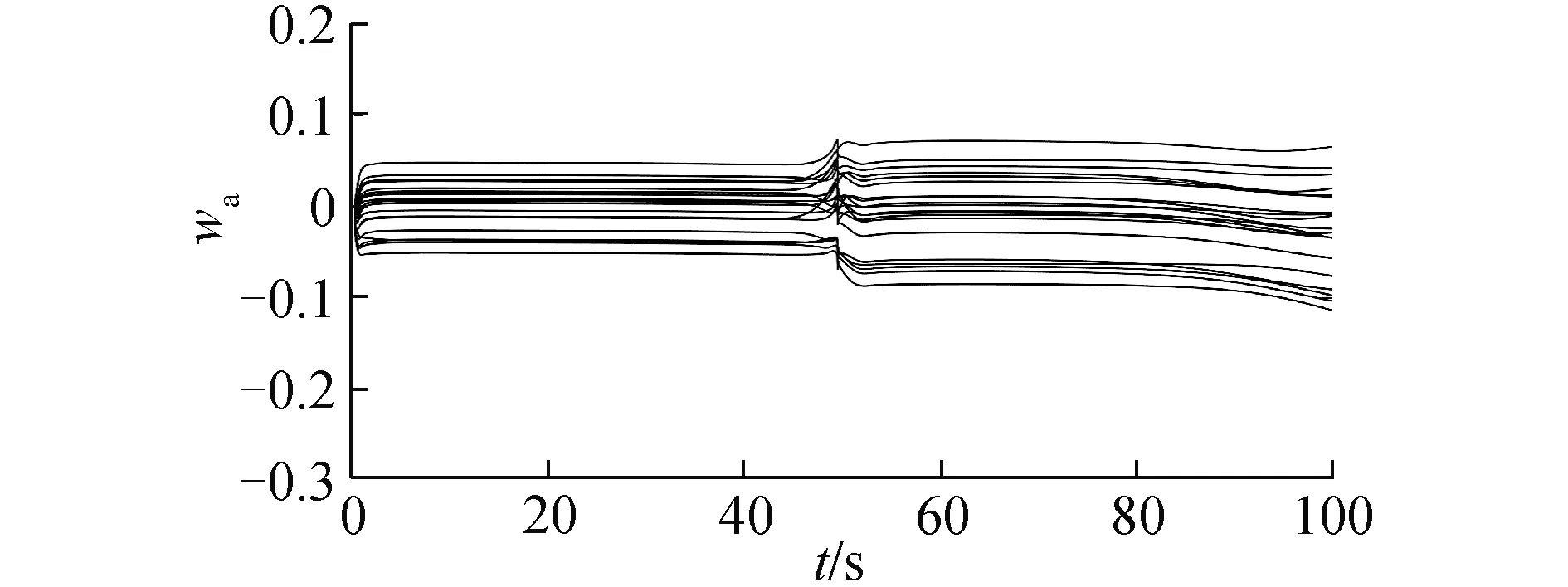
圖6 動作網絡權值變化曲線Fig.6 Actor NN weights
3.2 極限拉偏狀態下仿真分析
在建模具有參數不確定性時,通過仿真驗證所設計的強化學習控制器的控制性能。采用正反極限拉偏來驗證所設計的控制器的控制能力,拉偏條件I為:CL拉偏+10%,CM拉偏+30%,m拉偏+5%,Jz拉偏+5%,ρ拉偏+5%。拉偏條件II為:CL拉偏-10%,CM拉偏-30%,m拉偏-5%,Jz拉偏-5%,ρ拉偏-5%。
在氣動參數拉偏條件下仿真結果如圖7~10所示。在極限拉偏I和極限拉偏II條件下,所設計的強化學習控制算法依然能夠使高度快速、穩定地跟蹤高度參考指令。說明設計的強化學習控制算法對模型參數不確定依然具有很好的控制效果。
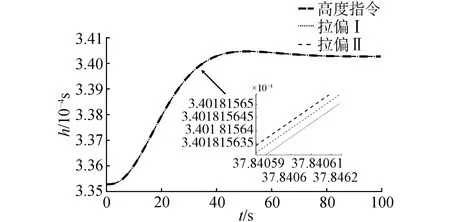
圖7 拉偏情況下高度變化曲線Fig.7 Altitude tracking with deviations
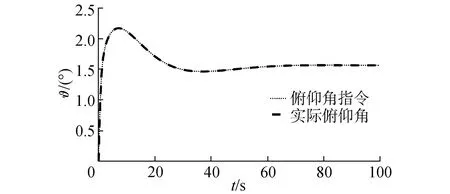
圖8 拉偏I情況下俯仰角變化曲線Fig.8 Pitch angle tracking with deviations I

圖9 拉偏II情況下俯仰角變化曲線Fig.9 Pitch angle tracking with deviations II
3.3 與PID控制算法相對比
將本文提出的算法與傳統PID相對比,姿態子系統分別采用內環俯仰角速度反饋的阻尼回路,外環采用PI控制,高度子系統采用PI控制。2種算法的對比結果如圖11、圖12所示。從圖中可以看出,對于穩態階段,2種控制算法的穩態誤差都在可接受范圍內,誤差大小沒有實質上的區別。但是在動態過程,PID控制算法響應要慢于本文提出的控制算法,本文提出的算法能快速跟蹤期望軌跡,但是PID控制算法要稍滯后于期望軌跡。從而驗證了本文提出的算法的有效性。
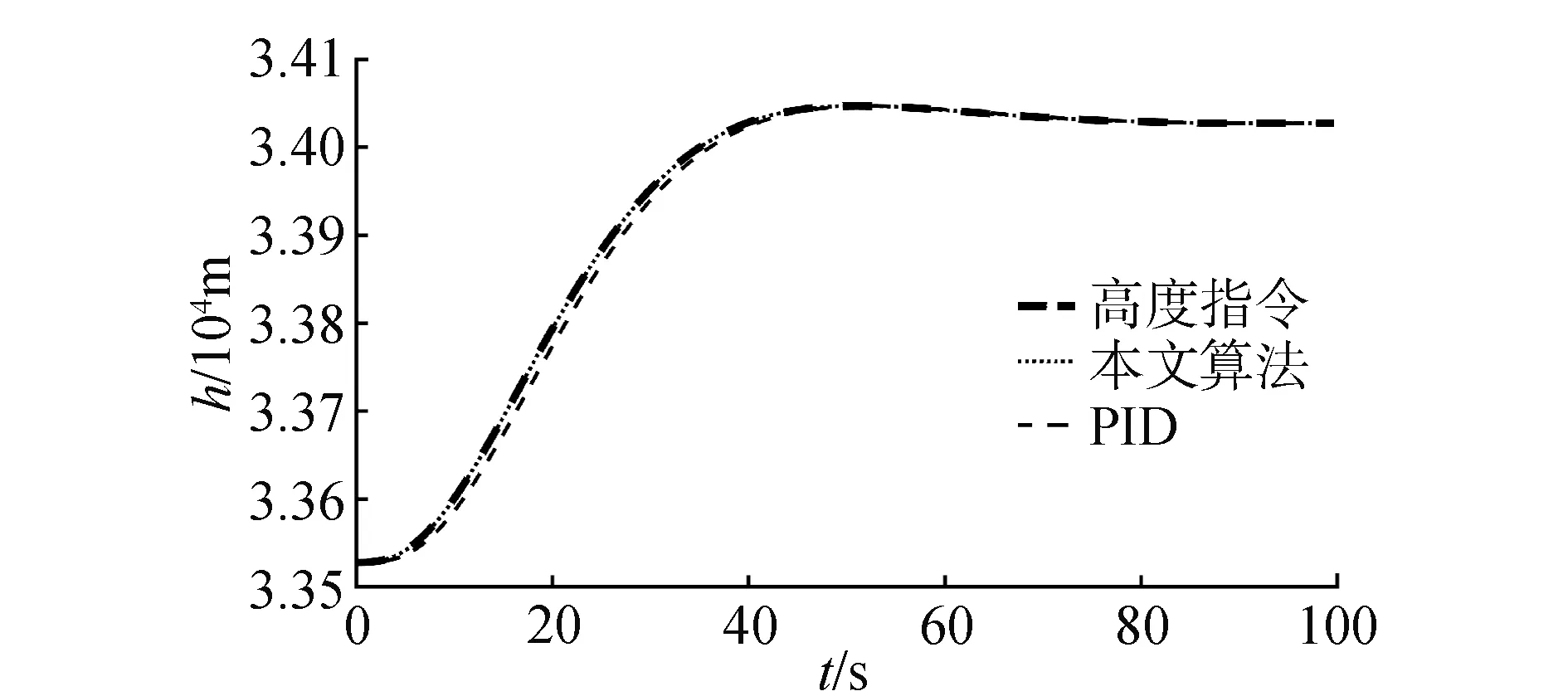
圖11 高度跟蹤曲線Fig.11 Altitude tracking
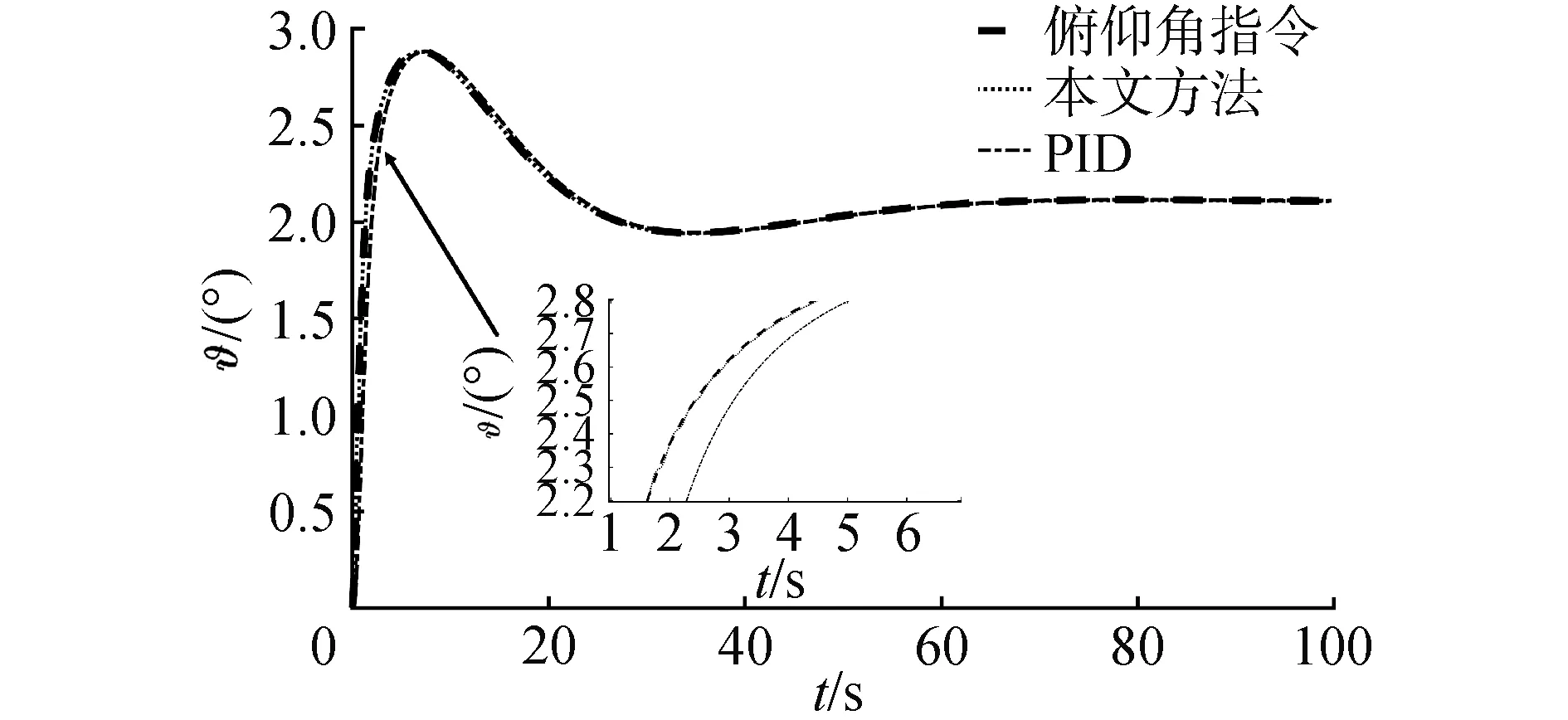
圖12 俯仰角跟蹤曲線Fig.12 Pitch angle tracking
4 結論
1)對飛行器參數標稱情況以及極限拉偏情況下均做了仿真試驗,同時將本文提出的算法與傳統PID控制算法進行對比,驗證了其有效性。仿真結果表明,本文提出的方法對高速飛行器參數不確定的情況下有很好地控制效果。
2)本文提出的控制器不需要精確了解飛行器的模型信息,因此減少了對模型的依賴,為高速飛行器高度控制系統設計提供了一種新的思路。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
石油瀝青(2021年4期)2021-10-14 08:50:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
光學精密工程(2016年6期)2016-11-07 09:07:19
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
俄羅斯問題研究(2012年1期)2012-03-25 09:54:51
