基于改進(jìn)KNN-DPC算法的科技創(chuàng)新人才分類研究*
2021-10-08 13:54:56張文宇朱鈺婷
計(jì)算機(jī)與數(shù)字工程 2021年9期
張文宇 劉 嘉 楊 媛 朱鈺婷 于 瑞
(1.西安郵電大學(xué)經(jīng)濟(jì)與管理學(xué)院 西安710061)(2.中國(guó)航天系統(tǒng)科學(xué)與工程研究院 北京 100081)
1 引言
黨的十九大報(bào)告提出,人才是實(shí)現(xiàn)民族振興、贏得國(guó)際競(jìng)爭(zhēng)主動(dòng)的戰(zhàn)略資源。科技創(chuàng)新人才作為從事系統(tǒng)性科學(xué)和技術(shù)知識(shí)的發(fā)現(xiàn)、生產(chǎn)和應(yīng)用活動(dòng)的創(chuàng)造性人力資源,是科學(xué)技術(shù)這一先進(jìn)生產(chǎn)力的集中體現(xiàn)。對(duì)于各個(gè)領(lǐng)域存在的科技創(chuàng)新人才,要充分發(fā)揮其具備的能力和素質(zhì),就要對(duì)科技創(chuàng)新人才進(jìn)行精準(zhǔn)分類。因此,研究科技創(chuàng)新人才的分類問(wèn)題對(duì)我國(guó)科技創(chuàng)新人才的發(fā)展、社會(huì)化建設(shè)有著十分重要的作用。目前,科技創(chuàng)新人才的理論研究大多集中在培養(yǎng)階段,楊穎[1]基于新的時(shí)代背景構(gòu)建出科技創(chuàng)新人才的培養(yǎng)機(jī)制。彭干三[2]在產(chǎn)學(xué)研融合視角下對(duì)我國(guó)科技創(chuàng)新人才培養(yǎng)過(guò)程中存在的問(wèn)題提出意見(jiàn)。然而,科技創(chuàng)新人才的分類問(wèn)題研究相對(duì)較少,陸一[3]等提出了三種選拔與培養(yǎng)類型的二維分類體系,以此來(lái)探究高校背景下創(chuàng)新人才的培養(yǎng)分類模式。邴浩[4]提出了一種政策分類的新方法來(lái)提升高校創(chuàng)新人才分類過(guò)程中政策的實(shí)施效果。以上的相關(guān)研究大部分是基于理論的定性研究階段,相關(guān)的定量研究很少,這導(dǎo)致科技創(chuàng)新人才分類研究的量化和精細(xì)化不足,不能充分挖掘科技創(chuàng)新人才的數(shù)據(jù)信息,從而對(duì)實(shí)際中科技創(chuàng)新人才的分類指導(dǎo)性不強(qiáng)。
在大數(shù)據(jù)背景下,充分利用海量數(shù)據(jù)資源,突出量化分析是科技創(chuàng)新人才分類研究的重要發(fā)展方向。因此,通過(guò)對(duì)科技創(chuàng)新人才數(shù)據(jù)的收集,從而對(duì)樣本數(shù)據(jù)進(jìn)行數(shù)據(jù)挖掘與分析是提高人才分類效果的重要途徑。已有的研究表明聚類算法是數(shù)據(jù)挖掘中研究分類問(wèn)題的有效方法,傳統(tǒng)聚類算法可被劃分為分割聚類、密度聚類,以及基于傳播的方法等[5~7]。Alex Rodriguez和Alessandro Laio[8]提出的一種密度峰值聚類算法DPC,該聚類算法具有計(jì)算速度快,無(wú)需迭代等特點(diǎn),可以很好地描述數(shù)據(jù)分布,同時(shí)在算法復(fù)雜度上也比一般的K-means算法的復(fù)雜度低。盡管DPC算法優(yōu)勢(shì)明顯,但其對(duì)高維數(shù)據(jù)的處理以及非中心點(diǎn)的歸類仍存在一些局限,針對(duì)DPC算法的缺點(diǎn),近兩年許多學(xué)者都對(duì)DPC算法進(jìn)行改進(jìn)。張偉[9]將DPC算法和Chame-leon算法的優(yōu)點(diǎn)相結(jié)合提出了E_CFSFDP算法,雖避免了將包含多個(gè)密度峰值的一個(gè)類聚成多類,但其計(jì)算量大且不利于處理高維數(shù)據(jù)。謝娟英[10]提出兩種基于K近鄰的樣本分配策略的快速密度峰值算法KNN-DPC,其算法對(duì)噪聲數(shù)據(jù)具有非常好的魯棒性,但由于該算法的聚類過(guò)程與DPC相同,故DPC算法的缺陷在該算法中仍存在。
針對(duì)上述問(wèn)題,本文提出的結(jié)合主成分的改進(jìn)K近鄰優(yōu)化的密度峰值聚類算法IKDPC將主成分分析法融入聚類算法中對(duì)高維數(shù)據(jù)降維,克服了聚類算法中高維數(shù)據(jù)對(duì)聚類結(jié)果的影響,為了更好地描述每個(gè)樣本在空間中的分布情況給出了新的局部密度的計(jì)算方法,并對(duì)原有樣本點(diǎn)的分配過(guò)程進(jìn)行了改進(jìn),有效提高了算法的聚類結(jié)果,使該算法能更好地應(yīng)用于實(shí)際分類領(lǐng)域。首先,本文在闡述科技創(chuàng)新人才的定義及內(nèi)涵的基礎(chǔ)上,定性分析出科技創(chuàng)新人才的特點(diǎn)并構(gòu)建出科學(xué)合理的評(píng)價(jià)指標(biāo)體系;然后,通過(guò)IKDPC算法對(duì)科技創(chuàng)新人才進(jìn)行量化分類研究,根據(jù)收集資料和調(diào)研獲得的樣本評(píng)價(jià)指標(biāo)數(shù)據(jù),對(duì)科技創(chuàng)新人才進(jìn)行實(shí)例驗(yàn)證并分析其結(jié)果,并通過(guò)IKDPC算法與其他算法的分析比較表明IKDPC算法的優(yōu)勢(shì),從而為提高科技創(chuàng)新人才培養(yǎng)過(guò)程中人才層次分類的效果提供依據(jù)。
2 科技創(chuàng)新人才及其評(píng)價(jià)指標(biāo)體系
2.1 科技創(chuàng)新人才的定義及內(nèi)涵
科技創(chuàng)新人才是從事系統(tǒng)性科學(xué)和技術(shù)知識(shí)的生產(chǎn)、促進(jìn)、傳播和應(yīng)用活動(dòng)的創(chuàng)造性人力資源[11]。根據(jù)科技創(chuàng)新人才的定義可知科技創(chuàng)新人才具體應(yīng)包括以下五部分內(nèi)涵。
1)具有較高的知識(shí)修養(yǎng)水平;
2)具有積極的創(chuàng)新實(shí)踐能力;
3)具有良好的環(huán)境適應(yīng)能力;
4)具有健康的身體狀況;
5)具有健全的心理與人格素質(zhì)。
2.2 科技創(chuàng)新人才的評(píng)價(jià)指標(biāo)體系
本文對(duì)科技創(chuàng)新人才的素質(zhì)從知識(shí)修養(yǎng)水平、創(chuàng)新實(shí)踐能力、環(huán)境適應(yīng)能力、身體狀況和心理與人格素質(zhì)五個(gè)部分構(gòu)建評(píng)價(jià)指標(biāo)體系,再根據(jù)對(duì)相關(guān)文獻(xiàn)和資料的研究,確定這五個(gè)部分的三級(jí)指標(biāo)[12]。科技創(chuàng)新人才評(píng)價(jià)指標(biāo)體系如表1所示。

表1 科技創(chuàng)新人才評(píng)價(jià)指標(biāo)體系
3 DPC算法
DPC算法通過(guò)搜索合適的局部密度較大的點(diǎn)作為類簇中心,再將類簇的標(biāo)簽從高密度點(diǎn)向低密度點(diǎn)依次傳播來(lái)實(shí)現(xiàn)數(shù)據(jù)樣本的聚類劃分。該算法能夠快速發(fā)現(xiàn)任意形狀數(shù)據(jù)集的密度峰值,并高效進(jìn)行樣本點(diǎn)分配和離群點(diǎn)剔除[11]。DPC算法引入了樣本數(shù)據(jù)點(diǎn)xi的局部密度ρi和數(shù)據(jù)點(diǎn)xi到局部密度比它大且距離它最近的樣本數(shù)據(jù)點(diǎn)xj的距離δi,其定義如式(1)和(2)所示:
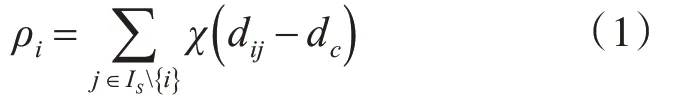
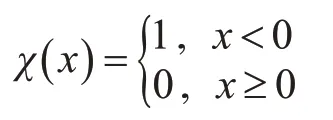
數(shù)據(jù)集,IS={1,2,…,N},為相應(yīng)指標(biāo)集,dij=dist(xi,xj)表示數(shù)據(jù)點(diǎn)xi和xj之間的歐式距離。參數(shù)dc>0為截?cái)嗑嚯x。
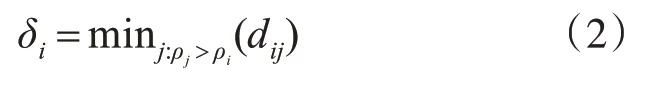
對(duì)于ρi最大的樣本數(shù)據(jù)點(diǎn)xi,其δi=minjdij。
對(duì)于較小的數(shù)據(jù)集,由式(1)估計(jì)的密度可能會(huì)受統(tǒng)計(jì)誤差的影響,此時(shí)采用式(3)來(lái)估計(jì)其局部密度[9]。
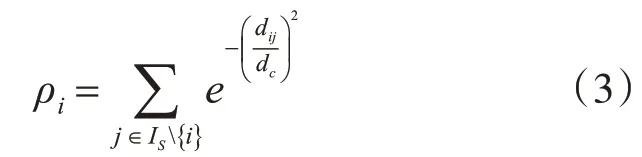
為了獲取數(shù)據(jù)的聚類中心,DPC算法首先將每個(gè)點(diǎn)的ρ值和δ值于坐標(biāo)平面內(nèi)繪制出,然后將ρ值和δ值都較大的點(diǎn)作為聚類中心[8]。然而,對(duì)于分布稀疏的數(shù)據(jù),通過(guò)ρ值和δ值難以確定其聚類中心,此時(shí)DPC算法使用γ=ρ×δ來(lái)獲取,其中,γi值越大,xi越有可能成為聚類中心。將所有點(diǎn)的γ值降序排列,并與坐標(biāo)平面上繪出。由于聚類中心的γ值較大,而其他點(diǎn)的γ值較小且呈平滑趨勢(shì),故可以使用一條平行于橫線的直線將其分開(kāi),使得直線上方的γ值所對(duì)應(yīng)的點(diǎn)即為聚類中心。當(dāng)聚類中心找出后,將剩余點(diǎn)分配到其高密度最近領(lǐng)所屬的類中。
4 IKDPC算法
4.1 IKDPC算法思想
高維數(shù)據(jù)的聚類分析存在著很多困難,重點(diǎn)表現(xiàn)在:1)高維數(shù)據(jù)稀疏性對(duì)于信息的識(shí)別造成一定的困難;2)隨著維數(shù)升高,計(jì)算量呈現(xiàn)指數(shù)型增長(zhǎng),這導(dǎo)致了對(duì)于聚類分析的結(jié)果計(jì)算更加困難[13]。因此,本文在聚類分析中融入了降維思想,選取已廣泛應(yīng)用的主成分分析方法,對(duì)科技創(chuàng)新人才樣本數(shù)據(jù)進(jìn)行降維后再聚類,可以獲得良好的聚類效果。
主成分分析(PCA)是模式識(shí)別過(guò)程中廣泛應(yīng)用的特征生成和降低維數(shù)的方法,它是在數(shù)據(jù)信息丟失最少的原則下,對(duì)高維變量空間進(jìn)行降維處理,同時(shí),使得高維數(shù)據(jù)點(diǎn)的可見(jiàn)性成為可能[14]。本文通過(guò)對(duì)科技創(chuàng)新人才評(píng)價(jià)指標(biāo)體系的樣本數(shù)據(jù)集進(jìn)行主成分分析,計(jì)算出相關(guān)系數(shù)指標(biāo),得出主成分對(duì)原始指標(biāo)數(shù)據(jù)的方差貢獻(xiàn)率及累計(jì)方差貢獻(xiàn)率,當(dāng)累計(jì)方差貢獻(xiàn)率達(dá)到或者超過(guò)85%,即m滿足:≥85%,且特征值大于1,從而求出科技創(chuàng)新人才評(píng)價(jià)指標(biāo)體系的主成分指標(biāo)m(m<p),然后對(duì)所求出的m個(gè)主成分指標(biāo)數(shù)據(jù)進(jìn)行聚類分析。
為了克服克服傳統(tǒng)DPC算法的缺陷,本文引入相似性系數(shù)來(lái)調(diào)節(jié)個(gè)點(diǎn)對(duì)當(dāng)前點(diǎn)的密度貢獻(xiàn)權(quán)重,提出帶有相似性系數(shù)的高斯核函數(shù)來(lái)計(jì)算其局部密度[15]。對(duì)于每個(gè)樣本數(shù)據(jù)點(diǎn)xi,其局部密度ρi定義如下:
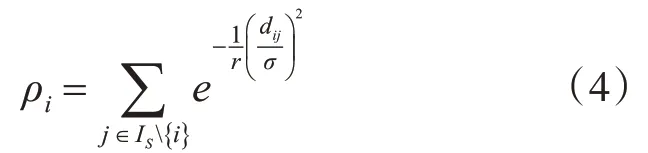
其中,σ取數(shù)據(jù)量的2%[9],r為相似性系數(shù),表示密度函數(shù)與數(shù)據(jù)點(diǎn)相似度的關(guān)系程度,該值越大,距離點(diǎn)xi越近的點(diǎn)對(duì)其密度ρi的貢獻(xiàn)權(quán)重越大。樣本數(shù)據(jù)點(diǎn)xi的距離δi計(jì)算方式與DPC算法相同。對(duì)于聚類中心的選取,考慮到ρ和δ值可能處于不同的數(shù)量級(jí),因此,對(duì)兩者進(jìn)行歸一化處理以有效獲得聚類中心γi,γi定義如下:
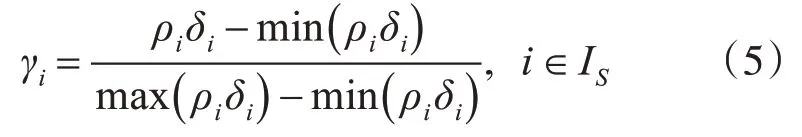
利用式(4)、式(2)計(jì)算出個(gè)點(diǎn)的ρ和δ值,式(5)計(jì)算出相應(yīng)的γi值,然后通過(guò)γ值決策圖選取較大的前M個(gè)γ值對(duì)應(yīng)的點(diǎn)獲得聚類中心。
由于聚類中心往往出現(xiàn)在高密度區(qū)域,故將各聚類中心某鄰域內(nèi)的點(diǎn)看作核心點(diǎn),而將其他點(diǎn)看作非核心點(diǎn)。核心點(diǎn)的獲取方法為先將剩余點(diǎn)分配到距其最近的聚類中心所在的類中,然后計(jì)算各局部類Cm中所有點(diǎn)與其類中心cenm間的平均距離um,若xi以下式(7),即xi∈Cm在cenm的θum鄰域內(nèi),則xi為核心點(diǎn)。
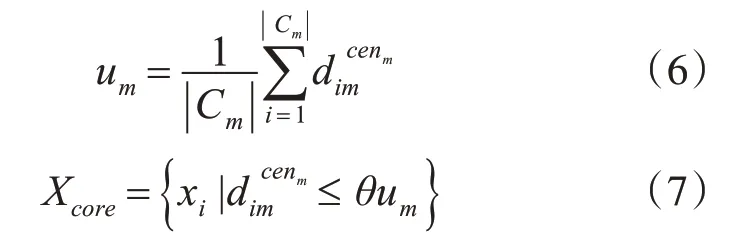
其中,|Cm|為第m個(gè)局部類Cm中的所有數(shù)據(jù)點(diǎn)的數(shù)目,為點(diǎn)xi∈Cm與cenm間的距離;θ與數(shù)據(jù)集大小N有關(guān),取N‰;Xcore為核心點(diǎn)集合。
對(duì)于剩余各點(diǎn),本文設(shè)計(jì)了兩種全新的分配策略,策略一是以核心點(diǎn)集合Xcore中每個(gè)點(diǎn)為中心,不斷地搜索未分配的KNN并將之分配到該點(diǎn)所在的局部類中。策略二則是根據(jù)式(8)計(jì)算xi和xj的相似度sij,表示兩點(diǎn)距離大小,距離越近,sij越高。每個(gè)點(diǎn)的歸屬由其KNN分布決定,若xi的KNN中屬于Cm的點(diǎn)越多且與xi的距離越近,則sij值越大,此時(shí)xi被分配到到Cm的概率Pim也越大。的計(jì)算如式(9):
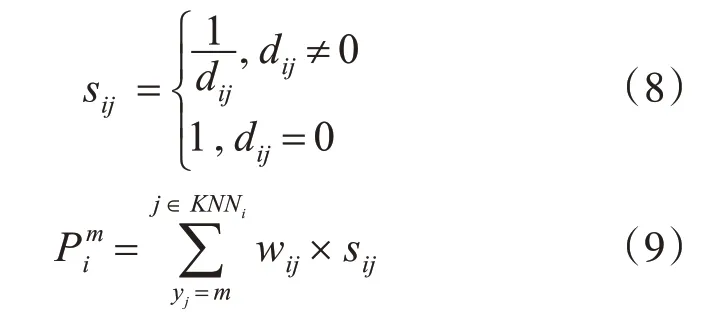
綜上所述,本文提出的IKDPC算法首先在聚類分析中融入了主成分分析法對(duì)高維數(shù)據(jù)進(jìn)行降維處理,進(jìn)而在傳統(tǒng)DPC算法中引入相似性系數(shù)來(lái)調(diào)節(jié)樣本數(shù)據(jù)點(diǎn)的密度貢獻(xiàn)權(quán)重以計(jì)算其局部密度,最后設(shè)計(jì)了全新的兩種樣本數(shù)據(jù)點(diǎn)的分配策略,有效提高了數(shù)據(jù)的聚類效率和聚類質(zhì)量。
4.2 具體算法步驟
IKDPC算法步驟如下。
輸入:數(shù)據(jù)集S,樣本近鄰數(shù)K,相似性系數(shù)r。
輸出:聚類結(jié)果。
Step1:對(duì)樣本評(píng)價(jià)指標(biāo)數(shù)據(jù)集S使用主成分分析方法,選取前m個(gè)主成分指標(biāo),該選取滿足累計(jì)貢獻(xiàn)率在[8 5%,100%]區(qū)間;
Step2:對(duì)選取的m個(gè)主成分指標(biāo)新數(shù)據(jù)集應(yīng)用改進(jìn)的DPC算法進(jìn)行聚類;
Step2.1:計(jì)算新數(shù)據(jù)集中各個(gè)數(shù)據(jù)點(diǎn)間的歐式距離dij,根據(jù)式(4)和式(2)計(jì)算每個(gè)數(shù)據(jù)點(diǎn)的ρ和δ值;
Step2.2:通過(guò)對(duì)計(jì)算的ρ和δ進(jìn)行歸一化處理,得到γ,進(jìn)而構(gòu)建決策圖獲得聚類中心;
Step3:使用式(6)和式(7)提取核心點(diǎn),并采用策略一將待分類點(diǎn)歸類:
Step3.1:將核心點(diǎn)集合Xcore至于隊(duì)列Q;
Step3.2:取隊(duì)列頭xa,將其從Q刪除,然后查找其K個(gè)最近鄰KNNa;
Step3.3:若x′∈KNNa未被分配,Step4則將x′分配到xa所在的類中,并將x′添加至Q尾;否則轉(zhuǎn)Step3.2;
Step3.4:若Q=?,終止該策略;
Step4:根據(jù)策略二分配剩余k個(gè)點(diǎn):
Step4.1:依式(8)和式(9)計(jì)算每個(gè)點(diǎn)的Pim(i=1,2,…,k),
將該結(jié)果存入矩陣Pk×M,同時(shí)將的值以及類別號(hào)m分別存至向量MP和MI;
Step4.2:若MP中有非零值,則將值最大點(diǎn)xo歸入MI(0)所表示的類中,轉(zhuǎn)到Step4.3,否則終止該策略;
Step4.3:更新P、MP、MI,令MI(0)=0。對(duì)于未分配的點(diǎn)xp∈KNNo,更新P[p][m]、MP(p)、MI(p)。
Step4.4:若MP中所有元素均為0,則終止;否則轉(zhuǎn)Step4.3;
Step5:若仍然沒(méi)有被處理的點(diǎn)可以看作噪聲點(diǎn),將其歸入到最近鄰所在的類中去。
5 實(shí)證研究
5.1 數(shù)據(jù)收集及整理
本文通過(guò)閱讀相關(guān)研究文獻(xiàn)、人物傳記提取杰出科技創(chuàng)新人才的評(píng)價(jià)指標(biāo),然后設(shè)計(jì)發(fā)放科技創(chuàng)新人才評(píng)價(jià)調(diào)研問(wèn)卷,整個(gè)過(guò)程符合調(diào)查抽樣隨機(jī)性的原則,問(wèn)卷發(fā)放的對(duì)象主要是科研院所及高校人員,調(diào)研的結(jié)果能反映科技創(chuàng)新人才素質(zhì)的真實(shí)情況。最后將調(diào)研問(wèn)卷的結(jié)果進(jìn)行整理打分,以科技創(chuàng)新人才評(píng)價(jià)指標(biāo)體系中的24個(gè)評(píng)價(jià)指標(biāo)反映出樣本人員所對(duì)應(yīng)的指標(biāo)得分(分?jǐn)?shù)越高代表對(duì)應(yīng)的素質(zhì)越高,每個(gè)指標(biāo)的滿分為5分)。經(jīng)過(guò)去噪、去除不合理樣本等預(yù)處理,最終共收集科技創(chuàng)新人才有效樣本指標(biāo)數(shù)據(jù)352例,科技創(chuàng)新人才樣本指標(biāo)數(shù)據(jù)如下表2。
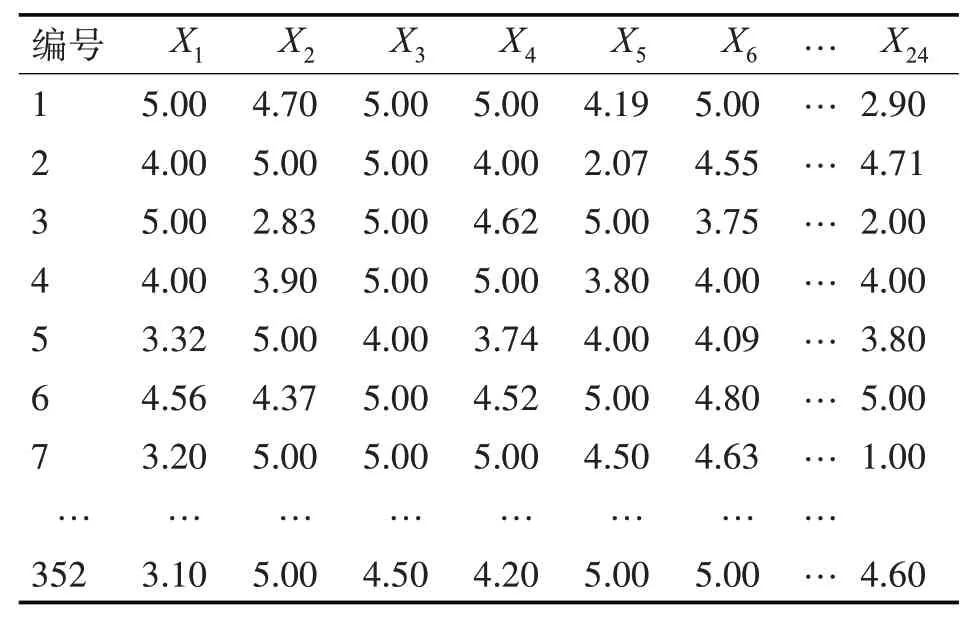
表2 科技創(chuàng)新人才評(píng)價(jià)指標(biāo)數(shù)據(jù)
5.2 實(shí)證結(jié)果分析
首先把整理好的352例科技創(chuàng)新人才的24項(xiàng)評(píng)價(jià)指標(biāo)數(shù)據(jù)導(dǎo)入SPSS中進(jìn)行主成分分析,結(jié)果見(jiàn)表3。
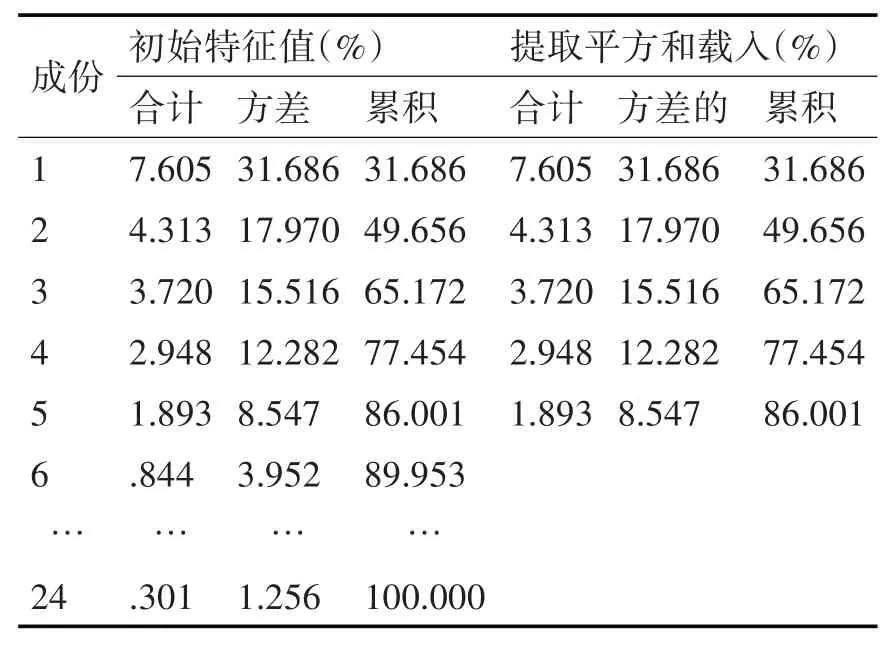
表3 主成分分析解釋總差異
從表3中可以看出,第一成分到第五成分特征值都大于1,并且累計(jì)方差貢獻(xiàn)率達(dá)到86.001%,可知這5個(gè)成分包含原始24個(gè)成分信息量的86.001%,可以反映原始數(shù)據(jù)的主要信息。因此,本文提取前5個(gè)成分作為主成分指標(biāo)進(jìn)行接下來(lái)的聚類分析。聚類結(jié)果以表4展示如下。
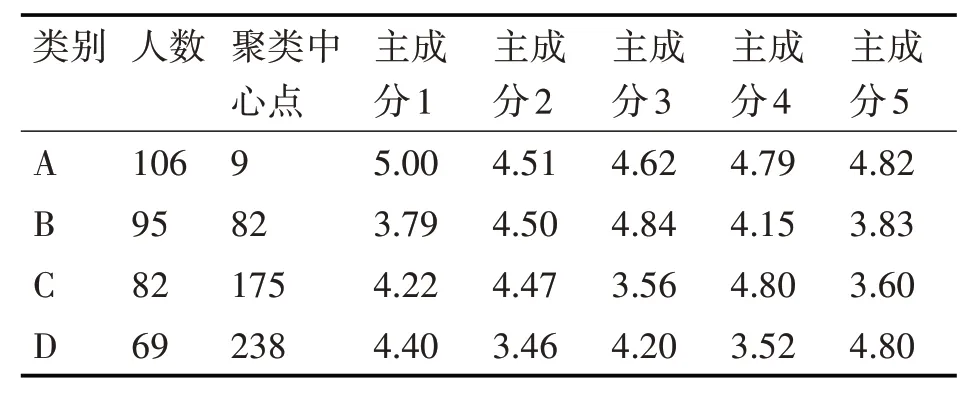
表4 科技創(chuàng)新人才主成分指標(biāo)聚類結(jié)果
根據(jù)表4可以看出A類樣本人數(shù)為106人,聚類中心點(diǎn)為9號(hào)樣本點(diǎn),分析其主成分指標(biāo)得分情況可知此樣本人員各個(gè)主成分指標(biāo)分?jǐn)?shù)都較高,因此A類樣本代表的是綜合全面型的科技創(chuàng)新人才;B類樣本人數(shù)為95人,聚類中心點(diǎn)為82號(hào)樣本點(diǎn),分析其主成分指標(biāo)得分情況可知此樣本人員主成分2和3分?jǐn)?shù)顯著,即他的受教育程度較高且知識(shí)運(yùn)用能力強(qiáng),因此B類樣本代表的是具有良好教育背景的知識(shí)應(yīng)用型科技創(chuàng)新人才;C類樣本人數(shù)為82人,聚類中心點(diǎn)為175號(hào)樣本點(diǎn),分析其主成分指標(biāo)得分情況可知此樣本人員主成分4分?jǐn)?shù)顯著,即他擁有豐富的知識(shí)存儲(chǔ)量,因此C類樣本代表的是擁有知識(shí)積累型的科技創(chuàng)新人才;D類樣本人數(shù)為69人,聚類中心點(diǎn)為175號(hào)樣本點(diǎn),分析其主成分指標(biāo)得分情況可知此樣本人員主成分5分?jǐn)?shù)顯著,即他具有較強(qiáng)的想象力,因此D類樣本代表的是創(chuàng)新思維型的科技創(chuàng)新人才。結(jié)合以上分析可知本文算法能夠得到較好的科技創(chuàng)新人才分類結(jié)果。
5.3 算法實(shí)例分析
為了驗(yàn)證數(shù)據(jù)降維對(duì)聚類效果的提升,分別將DPC算法和IKDPC算法在1~24個(gè)科技創(chuàng)新人才評(píng)價(jià)指標(biāo)成分張成的數(shù)據(jù)集中進(jìn)行聚類,使用分錯(cuò)率(CER)、ERRORRATE和調(diào)整Rand系數(shù)(Adjusted Rand Index,ARI)三個(gè)指標(biāo)綜合衡量聚類效果,結(jié)果如表5所示,科技創(chuàng)新人才在降維過(guò)程中維數(shù)超過(guò)5時(shí)各項(xiàng)指標(biāo)都產(chǎn)生了大幅度變化,各個(gè)指標(biāo)均不理想。
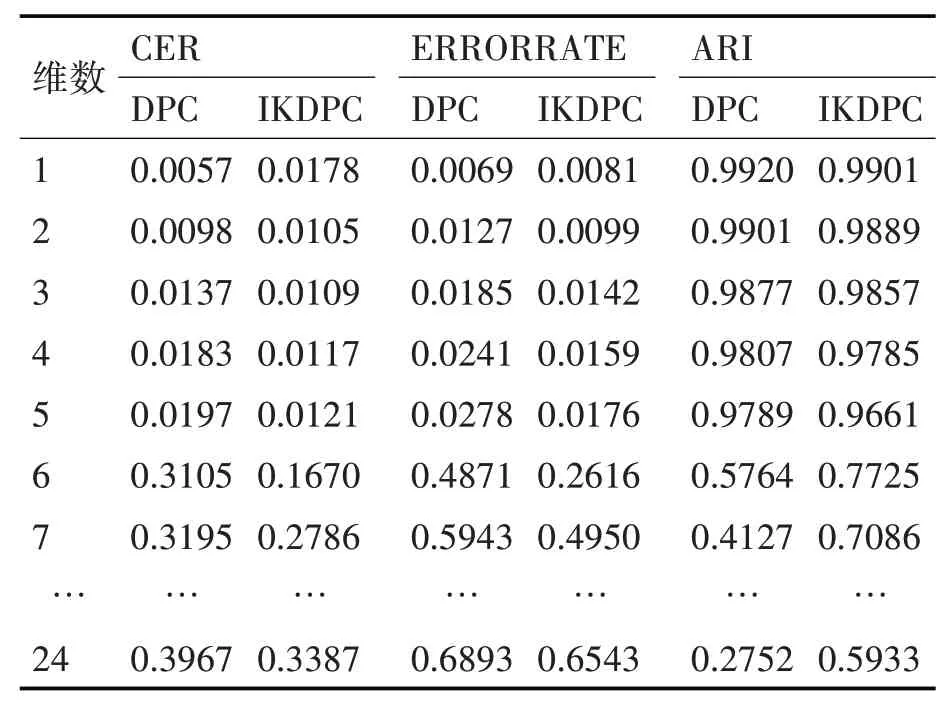
表5 DPC和IKDPC的樣本指標(biāo)數(shù)據(jù)聚類對(duì)比
最后,為了對(duì)比本文提出的IKDPC算法的有效性,本文將聚類算法研究中廣為采用的聚類精度(Clustering Accuracy,ACC)、調(diào)整互信息系數(shù)(Adjusted Mutual Information,AMI)、ARI這三個(gè)指標(biāo)作為聚類算法性能度量評(píng)價(jià)標(biāo)準(zhǔn)[16~17]。其中,ACC與AMI的取值范圍均為[0,1],ARI的 取值范圍為[- 1,1],各指標(biāo)值越大,越表示聚類質(zhì)量越高。本論文算法與其他算法對(duì)樣本數(shù)據(jù)進(jìn)行驗(yàn)證,三個(gè)指標(biāo)的比較結(jié)果見(jiàn)表6。
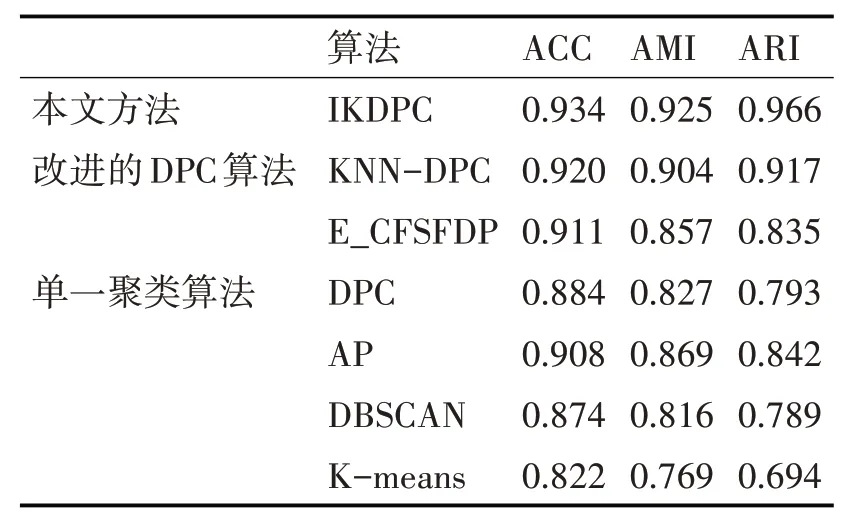
表6 各算法有效性比較
綜上所述,本文算法能夠克服高維數(shù)據(jù)對(duì)聚類過(guò)程的不利影響,聚類結(jié)果區(qū)分性強(qiáng)且聚類有效性高,能夠應(yīng)用于科技創(chuàng)新人才的實(shí)際分類問(wèn)題。
6 結(jié)語(yǔ)
本文針對(duì)科技創(chuàng)新人才分類問(wèn)題,運(yùn)用定性與定量相結(jié)合的方法,先通過(guò)資料收集和調(diào)研問(wèn)卷的方式整理制定出相關(guān)科技創(chuàng)新人才的評(píng)價(jià)指標(biāo)體系,然后提出IKDPC算法對(duì)樣本指標(biāo)進(jìn)行聚類分析,與傳統(tǒng)聚類方法相比,該方法能夠?qū)Ω呔S數(shù)據(jù)降維,提取指標(biāo)維數(shù)中的主成分指標(biāo),并且給出了新的適用于任意數(shù)據(jù)集的局部密度計(jì)算方法,以及兩種不同的剩余點(diǎn)分配策略。采用本文方法對(duì)科技創(chuàng)新人員進(jìn)行聚類分析,充分挖掘聚類信息,客觀合理地將科技創(chuàng)新人才進(jìn)行分類,對(duì)不同類別的科技創(chuàng)新人才制定不同的培養(yǎng)計(jì)劃,能夠?yàn)榭萍紕?chuàng)新人才培養(yǎng)過(guò)程中的分類提供科學(xué)化的決策支持。本文方法具有一定的通用性,也可以用于其他類似人員的分類問(wèn)題,例如醫(yī)學(xué)人才分類、軍事人才分類等。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
學(xué)苑創(chuàng)造·B版(2021年2期)2021-03-15 05:50:49
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
少兒科學(xué)周刊·兒童版(2017年9期)2018-03-15 15:00:11
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
兒童故事畫報(bào)·發(fā)現(xiàn)號(hào)趣味百科(2017年4期)2017-06-30 12:41:53
兒童故事畫報(bào)·發(fā)現(xiàn)號(hào)趣味百科(2016年6期)2016-08-19 06:35:19
兒童故事畫報(bào)·發(fā)現(xiàn)號(hào)趣味百科(2015年10期)2016-01-20 00:47:36
