基于時(shí)空自注意力轉(zhuǎn)換網(wǎng)絡(luò)的群組行為識(shí)別
2021-10-05 12:46:56張?zhí)煊?/span>江朝暉
智能計(jì)算機(jī)與應(yīng)用 2021年5期
張?zhí)煊辏S 飛,江朝暉
(合肥工業(yè)大學(xué) 計(jì)算機(jī)與信息學(xué)院,合肥230601)
0 引 言
群組行為識(shí)別是指對(duì)多個(gè)個(gè)體共同參與的活動(dòng)進(jìn)行識(shí)別,具有廣泛的應(yīng)用領(lǐng)域。如:體育視頻分析、智能視頻監(jiān)控、機(jī)器人視覺(jué)等。與傳統(tǒng)個(gè)體行為識(shí)別不同的是,群組行為識(shí)別需要理解個(gè)體之間的交互關(guān)系,而個(gè)體的位置、行為以及個(gè)體之間的交互關(guān)系隨時(shí)間不斷變化。
早期的方法使用概率圖模型處理手工提取的特征。近幾年,循環(huán)卷積神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)和長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(Long Short-Term Memory,LSTM)憑借其強(qiáng)大的序列信息處理能力,被許多學(xué)者用于群組行為識(shí)別。Ibrahim M S等人[1]設(shè)計(jì)了一個(gè)層次LSTM模型,其中一個(gè)LSTM提取成員個(gè)體行為動(dòng)態(tài)特征,另一個(gè)用于聚合個(gè)體層次信息作為場(chǎng)景表示,但在使用LSTM聚合個(gè)體層次信息時(shí)忽略了個(gè)體空間關(guān)系。Ibrahim M S等人[2]在之后的工作中引入一個(gè)關(guān)系層為每個(gè)人學(xué)習(xí)緊湊的關(guān)系表示,但這種關(guān)系層學(xué)習(xí)個(gè)體關(guān)系的方法不夠靈活。
為解決上述問(wèn)題,本文提出時(shí)空自注意力轉(zhuǎn)換網(wǎng)絡(luò)模型用于群組行為識(shí)別。首先使用空間自注意力轉(zhuǎn)換模塊,靈活地建模個(gè)體間的空間關(guān)系,其次使用時(shí)序自注意力轉(zhuǎn)換模塊進(jìn)行時(shí)序建模,最后將時(shí)空關(guān)系建模后的特征用于群組行為識(shí)別。
本文的主要貢獻(xiàn)是:提出了一種端到端的時(shí)空自注意力轉(zhuǎn)換模型,以及全局空間關(guān)注圖,改進(jìn)空間自注意力轉(zhuǎn)換模塊;使用時(shí)序掩膜策略,優(yōu)化時(shí)序自注意力轉(zhuǎn)換模塊。在兩個(gè)流行數(shù)據(jù)集上進(jìn)行驗(yàn)證,均取得了優(yōu)秀的表現(xiàn)。
1 相關(guān)工作
1.1 群組行為識(shí)別
早期的研究人員采用概率圖模型處理手工提取的特征[3-4]。近期,深度學(xué)習(xí)網(wǎng)絡(luò)在各個(gè)領(lǐng)域取得優(yōu)異的表現(xiàn),一些學(xué)者將RNN以及LSTM引入群組行為識(shí)別任務(wù)中。Ibrahim M S等人[1]提出了基于LSTM的層次模型,將卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)和LSTM作為骨干網(wǎng)絡(luò),其中LSTM可以捕捉每個(gè)個(gè)體的時(shí)間動(dòng)態(tài)特征。其后,許多基于CNN和RNN結(jié)合的群體活動(dòng)識(shí)別方法涌現(xiàn)出來(lái)。
例如,Shu T等人[5]提出了能量層和LSTM結(jié)合的CERN網(wǎng)絡(luò),能量層用于捕獲CERN內(nèi)所有LSTM預(yù)測(cè)之間的依賴關(guān)系,并以這種方式通過(guò)能量最小化實(shí)現(xiàn)更加可靠的識(shí)別;Li X等人[6]使用一個(gè)LSTM為每個(gè)視頻幀生成一個(gè)標(biāo)題,另一個(gè)LSTM根據(jù)這些生成的字幕,預(yù)測(cè)最終的活動(dòng)類別;Ibrahim M S等人引入一個(gè)關(guān)系層模塊,該模塊可以編碼個(gè)體與其他個(gè)體的關(guān)系信息;Tsunoda T等人[7]設(shè)計(jì)了一個(gè)層次LSTM,在LSTM中引入了保持狀態(tài)作為一種外部可控狀態(tài),并且擴(kuò)展了分層LSTM的集成機(jī)制。
此外,一些方法采用注意力機(jī)制來(lái)確定與群組活動(dòng)中的關(guān)鍵人物。例如Ramanathan V等人[8]結(jié)合雙向長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(Bi-directional Long Short-Term Memory,BLSTM)和注意力(Attention)機(jī)制,提出注意力模型,給予事件中關(guān)鍵參與者更高的權(quán)重。Qi M等人[9]還利用注意機(jī)制同時(shí)從視覺(jué)域和語(yǔ)義域?qū)ふ谊P(guān)鍵人物。本文基于自注意力機(jī)制,提出時(shí)空自注意力轉(zhuǎn)換網(wǎng)絡(luò)進(jìn)行群組行為識(shí)別。
1.2 自注意力機(jī)制(Self-Attention)
自注意力機(jī)制是自注意力轉(zhuǎn)換網(wǎng)絡(luò)(Transformer)的基礎(chǔ)模塊[10],用于為序列的所有實(shí)體之間的交互建模,在自然語(yǔ)言處理領(lǐng)域表現(xiàn)優(yōu)異。原理上,自注意力層通過(guò)聚合來(lái)自完整輸入序列的全局信息,來(lái)更新序列的每個(gè)組成部分。其輸入由一組查詢(Queries,Q)、維度為D的鍵(Keys,K),和值(Values,V)組成,將這些輸入打包成矩陣形式實(shí)現(xiàn)高效計(jì)算。首先將Q與K的轉(zhuǎn)置矩陣相乘并除以再使用softmax層進(jìn)行歸一化,以獲得注意力分?jǐn)?shù)。序列中每個(gè)實(shí)體更新為序列中所有實(shí)體的加權(quán)和,其中的權(quán)重由注意力分?jǐn)?shù)給出。其公式為:

這種自注意力機(jī)制被用于許多關(guān)系建模、目標(biāo)檢測(cè)等計(jì)算機(jī)視覺(jué)任務(wù)。本文工作中利用基于自注意力機(jī)制的Transformer用于時(shí)空關(guān)系建模。
2 模型框架
2.1 總體框架
網(wǎng)絡(luò)由個(gè)體特征提取、基于Transformer的時(shí)空特征融合模塊和殘差連接特征融合模塊3部分組成。網(wǎng)絡(luò)框架如圖1所示。網(wǎng)絡(luò)輸入為視頻幀序列以及個(gè)體邊界框B;使用2D CNN網(wǎng)絡(luò)提取輸入視頻幀的特征圖;RoiAlign層[11]根據(jù)個(gè)體邊界框B提取個(gè)體外觀特征;使用FC層將每個(gè)個(gè)體成員特征映射為維度1×1 024,將其稱為原始個(gè)體特征;將提取的個(gè)體特征輸入時(shí)空Transformer模塊,進(jìn)行時(shí)空信息建模。為了減少深度網(wǎng)絡(luò)退化問(wèn)題,采用殘差鏈接將原始特征與時(shí)空信息建模后的成員特征融合,最后使用分類層進(jìn)行分類。

圖1 時(shí)空自注意力轉(zhuǎn)換網(wǎng)絡(luò)結(jié)構(gòu)Fig.1 Structure of Spatio-Temporal Transformer Network
2.2 空間Transformer
在將原始特征輸入該模塊之前,需根據(jù)個(gè)體邊界框?yàn)樵继卣魈砑涌臻g位置信息。對(duì)于個(gè)體i,根據(jù)其邊界框中心點(diǎn)使用Vaswani A等人[13]提出的PE位置編碼函數(shù)對(duì)其進(jìn)行編碼。編碼得到的空間位置信息維度和個(gè)體i的特征維度相同,其前一半維度為xi的編碼,后一半為yi的編碼。編碼函數(shù)為:
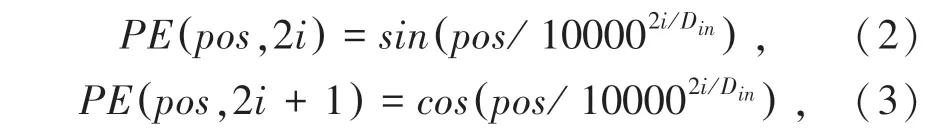
其中,pos為個(gè)體的位置;i為空間位置編碼向量的維度;Din的值等于個(gè)體特征維度大小的一半。空間位置信息xi和yi均使用上述編碼,編碼后將其使用concatenate方式進(jìn)行連接。空間位置編碼與個(gè)體特征具有相同的維度,將兩者相加得到具有空間位置信息的個(gè)體特征。
空間Transformer原理如圖2所示。Transformer由L層組成,每層有2個(gè)子層:一個(gè)多頭注意層和一個(gè)前饋層。其原始輸入為經(jīng)空間位置信息編碼后的特征矩陣X∈RN×D。其中,N代表節(jié)點(diǎn)數(shù)量,D表示通道數(shù)。對(duì)于H個(gè)注意頭的第j個(gè)頭的注意層,計(jì)算其輸出Xj∈RN×d,d=D/H:

圖2 空間Transformer原理Fig.2 Principle of Spatio-Transformer Network


2.3 全局空間注意圖
如上所述,使用空間Transformer中多頭注意力為每個(gè)時(shí)刻個(gè)體計(jì)算空間關(guān)注度,這是一種隨時(shí)間變化的空間關(guān)注度。由于每個(gè)個(gè)體在群組活動(dòng)中扮演特定的角色,可在整個(gè)群組活動(dòng)過(guò)程中設(shè)定一個(gè)時(shí)序共享的全局空間注意力模塊,來(lái)強(qiáng)制模型學(xué)習(xí)更多不同時(shí)刻的一般關(guān)注。
如圖2所示,在多頭注意力和前饋層之間加入K全局注意圖∈RN×N,在這里K取N值。所有數(shù)據(jù)樣本共享全局注意圖,代表整個(gè)群組活動(dòng)內(nèi)在關(guān)系模式,多個(gè)圖構(gòu)成全局注意圖增加網(wǎng)絡(luò)泛化能力。本文將其作為網(wǎng)絡(luò)的參數(shù),并與模型一起進(jìn)行優(yōu)化。該模塊結(jié)構(gòu)簡(jiǎn)單、參數(shù)少,但消融實(shí)驗(yàn)表明其效果顯著。全局空間關(guān)注度模塊使用殘差函數(shù),增加該模塊后計(jì)算公式表示為:

2.4 時(shí)序Transformer
時(shí)序Transformer和空間Transformer具有相同的原理,其不同之處在于輸入特征為時(shí)序特征以及多頭注意層的計(jì)算方式。輸入的時(shí)序特征由各時(shí)刻空間特征在個(gè)體維度最大池化獲得。在時(shí)序特征經(jīng)多頭注意層時(shí),對(duì)多頭注意層中計(jì)算出的關(guān)注圖矩陣后,增加一個(gè)掩膜矩陣M∈RN×N。M矩陣為:

其中,m1、m2為矩陣的行和列,γ為時(shí)間窗口大小,設(shè)置為輸入單個(gè)視頻序列幀數(shù)的一半。增加掩膜后的注意力層計(jì)算為:

其中,°表示Hadamard乘積。因此,當(dāng)為某個(gè)時(shí)序特征進(jìn)行時(shí)序建模時(shí),只考慮該時(shí)刻前后γ時(shí)刻內(nèi)的時(shí)序特征,其它時(shí)刻的注意分?jǐn)?shù)被設(shè)為零。采用這種策略,減少了時(shí)序建模時(shí)信息冗余,降低了時(shí)序建模難度。
2.5 損失函數(shù)
將時(shí)序Transformer的輸出與原始特征進(jìn)行求和融合,形成最終場(chǎng)景表示,將場(chǎng)景表示送入分類層進(jìn)行群組行為識(shí)別。使用空間Transformer的輸出特征與原始特征求和融合后計(jì)算個(gè)體損失。整個(gè)模型以反向傳播端到端方式訓(xùn)練,損失函數(shù)由個(gè)體損失和群組損失組成,其公式如下:

其中,L為交叉熵?fù)p失函數(shù);是群組行為和個(gè)體行為標(biāo)簽;yG和yP是預(yù)測(cè)值。
3 實(shí)驗(yàn)結(jié)果與分析
3.1 數(shù)據(jù)集
(1)Volleyball數(shù)據(jù)集。數(shù)據(jù)集由55個(gè)排球比賽視頻中截取的4 830個(gè)視頻片段組成[1]。每個(gè)視頻片段中間幀標(biāo)注了個(gè)體邊界框、個(gè)體行為標(biāo)簽以及群組行為標(biāo)簽。其中個(gè)體行為標(biāo)簽有9種,群組行為標(biāo)簽共有8種。對(duì)于每個(gè)帶標(biāo)注的幀,該幀周圍有多個(gè)未帶標(biāo)注的幀可用。實(shí)驗(yàn)中使用一個(gè)長(zhǎng)度為T(mén)=10的時(shí)間窗口,對(duì)應(yīng)于標(biāo)注幀的前5幀和后4幀。未被標(biāo)注的個(gè)體邊界框數(shù)據(jù)從該數(shù)據(jù)集提供的軌跡信息數(shù)據(jù)獲取。使用3 494個(gè)視頻片段作為訓(xùn)練集,1 337個(gè)視頻片段作為測(cè)試集。
(2)Collective Activity數(shù)據(jù)集。數(shù)據(jù)集由低分辨率相機(jī)拍攝的44個(gè)視頻片段組成,總共約2500幀[3]。每個(gè)視頻片段每10幀有一個(gè)標(biāo)注,標(biāo)注包含個(gè)體行為和群組行為標(biāo)簽,以及個(gè)體的邊界框。共5個(gè)群組活動(dòng)標(biāo)簽,6個(gè)個(gè)體行為標(biāo)簽。實(shí)驗(yàn)中2/3視頻用于訓(xùn)練,其余的用于測(cè)試。
3.2 實(shí)驗(yàn)細(xì)節(jié)及評(píng)價(jià)標(biāo)準(zhǔn)
對(duì)于Volleyball數(shù)據(jù)集,網(wǎng)絡(luò)超參設(shè)置如下:最小批量大小為8,Dropout參數(shù)為0.3,學(xué)習(xí)率初始設(shè)置為1E-4,網(wǎng)絡(luò)訓(xùn)練180個(gè)周期,每30個(gè)周期學(xué)習(xí)率將為之前的0.5倍,學(xué)習(xí)率在4次衰減后停止衰減。空間自注意力轉(zhuǎn)換模塊層數(shù)為1,注意頭數(shù)為2,時(shí)序自注意力轉(zhuǎn)換模塊層數(shù)和注意頭數(shù)均為1。實(shí)驗(yàn)采用ADAM(ADAptive Moment)優(yōu)化器。
在Collective Activity數(shù)據(jù)集上,網(wǎng)絡(luò)超參設(shè)置為:最小批數(shù)據(jù)大小為16,Dropout參數(shù)為0.5,初始學(xué)習(xí)率為1E-3,每10個(gè)周期學(xué)習(xí)率將為之前的0.1倍,學(xué)習(xí)率在四次衰減后停止衰減。網(wǎng)絡(luò)共訓(xùn)練80個(gè)周期。空間自注意力轉(zhuǎn)換模塊層數(shù)為1,注意頭數(shù)為2,時(shí)序自注意力轉(zhuǎn)換模塊層數(shù)和注意頭數(shù)均為1。實(shí)驗(yàn)采用ADAM優(yōu)化器。
3.3 消融實(shí)驗(yàn)
3.3.1 基線模型設(shè)計(jì)
為通過(guò)消融實(shí)驗(yàn)來(lái)證明本文模型中各個(gè)模塊的有效性,設(shè)計(jì)以下變體模型:
B1(Baseline):基于個(gè)體特征模型。在該模型中,采用Inception-v3來(lái)計(jì)算每個(gè)幀中個(gè)體的高維特征。將這些特征經(jīng)平均池化,計(jì)算出群組行為的特征。這些特征被送到Softmax分類器中,以預(yù)測(cè)每個(gè)幀中群組行為的標(biāo)簽。視頻的預(yù)測(cè)標(biāo)簽為所有視頻幀的預(yù)測(cè)標(biāo)簽,通過(guò)求和平均得到。
B2(Baseline+ST):該變體模 型 使用空間Transformer(Spatio-Transformer,ST)對(duì)Inception-v3提取的個(gè)體特征進(jìn)行空間關(guān)系推理。
B3(Baseline+ST+TT):該變體在B2的基礎(chǔ)上增加無(wú)掩膜優(yōu)化的時(shí)序(Temporal-Transformer,TT),對(duì)時(shí)序關(guān)系進(jìn)行推理。
B4(Baseline+ST_Enhance+TT):在B3的基礎(chǔ)上增加全局空間注意圖增強(qiáng),對(duì)空間關(guān)系的推理。
B5(Baseline+ST_Enhance+TT_Enhance):為本文的最優(yōu)模型,在B4的基礎(chǔ)上增加掩膜對(duì)TT進(jìn)行優(yōu)化。
3.3.2 實(shí)驗(yàn)結(jié)果分析
模型及其變體在Volleyball數(shù)據(jù)集上的識(shí)別準(zhǔn)確率結(jié)果見(jiàn)表1。本文提出的B5模型取得了最好的性能。其達(dá)到92.52%的最高準(zhǔn)確率,與基線模型B1相比準(zhǔn)確率提升了3.37%。與B1相比,變體模型B2通過(guò)探索個(gè)體之間的空間交互,識(shí)別準(zhǔn)確率提高了0.87%。B3被用來(lái)說(shuō)明在時(shí)間和空間領(lǐng)域捕捉個(gè)體空間交互關(guān)系以及時(shí)序關(guān)系的重要性,B4和B3相比提高了0.9%的準(zhǔn)確率,證明了全局空間注意圖這種不同時(shí)刻的一般關(guān)注對(duì)于識(shí)別群體活動(dòng)的有效性。B5和B4相比,驗(yàn)證了通過(guò)增加MASK減少在時(shí)序關(guān)系推理時(shí)的信息冗余,可以提高模型的性能。

表1 Volleyball數(shù)據(jù)集上的消融實(shí)驗(yàn)結(jié)果Tab.1 Ablation results on Volleyball dataset
3.4 與各方法的對(duì)比分析
表2顯示了本文的最佳模型與各方法在Volleyball數(shù)據(jù)集上的比較結(jié)果。由表2可知,本文方法在Volleyball數(shù)據(jù)集上達(dá)到最好的表現(xiàn)。和HRN模型相比,雖然其模型包括個(gè)體之間的關(guān)系信息,但其方法提取空間關(guān)系未充分利用空間信息。因此,本文模型優(yōu)于HRN模型。和ARG模型相比,雖然該模型充分探究了個(gè)體間空間位置和外觀關(guān)系,但在時(shí)序建模方面采用時(shí)序抽樣策略沒(méi)有完整利用時(shí)序信息,而本文模型采用了時(shí)序關(guān)系建模優(yōu)化,因此本文模型優(yōu)于ARG模型。

表2 各方法在Volleyball數(shù)據(jù)集上的準(zhǔn)確率Tab.2 Accuracies of different methods on Volleyball dataset
在Collective Activity數(shù)據(jù)集上與其它先進(jìn)方法進(jìn)一步比較結(jié)果見(jiàn)表3。本文模型表現(xiàn)優(yōu)于其它方法,達(dá)到91.24%的群體活動(dòng)識(shí)別準(zhǔn)確率。結(jié)果表明了該模型捕獲時(shí)空關(guān)系信息的有效性和通用性。

表3 各方法在Collective Activity數(shù)據(jù)集上的準(zhǔn)確率Tab.3 Accuracies of different methods on Collective Activity dataset
3.5 數(shù)據(jù)可視化
(1)空間注意力可視化。在圖3中可視化了本文模型在Volleyball數(shù)據(jù)集上兩個(gè)空間注意頭生成注意力圖的例子。根據(jù)注意力圖,在圖像中使用紅星標(biāo)出了關(guān)鍵個(gè)體。可視化結(jié)果表明本文模型能夠捕捉群體活動(dòng)中關(guān)鍵關(guān)系信息。

圖3 空間注意力可視化Fig.3 Spatial attention visualization
(2)t-SNE可視化。圖4顯示了t-SNE可視化不同模型變體在Volleyball數(shù)據(jù)集上學(xué)習(xí)的視頻表示。使用t-SNE將排球數(shù)據(jù)集的驗(yàn)證集上的視頻表示投射到二維空間。從圖上可以觀察到,本文的B5模型學(xué)習(xí)的群組場(chǎng)景表示具有較好的分離度,且全局空間注意力增強(qiáng)和時(shí)序掩膜優(yōu)化結(jié)合,可以更好地區(qū)分群體活動(dòng)。

圖4 不同變體模型視頻表示的t-SNE可視化Fig.4 t-SNE visualization of video representations of different variants of the model
4 結(jié)束語(yǔ)
本文提出一種靈活有效的方法對(duì)群組中個(gè)體進(jìn)行時(shí)空關(guān)系推理,基于自注意力機(jī)制的時(shí)空Transformer關(guān)系網(wǎng)絡(luò)獲得用于群組行為識(shí)別的視頻表示。在當(dāng)前流行數(shù)據(jù)集上的實(shí)驗(yàn)表明,本文方法和當(dāng)前優(yōu)秀方法相比準(zhǔn)確率更高。并可視化了部分網(wǎng)絡(luò),可以更加了解網(wǎng)絡(luò)的工作原理。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
