基于形變卷積神經網絡的行為識別
2021-10-05 12:46:14李君君張彬彬江朝暉
智能計算機與應用 2021年5期
李君君,張彬彬,江朝暉
(合肥工業大學 計算機與信息學院,合肥230601)
0 引 言
行為識別技術是近年來計算機視覺研究領域被廣泛關注的技術,受到國內外專家學者的廣泛重視和深入研究,其相關技術在智慧監控、人機交互、視頻序列理解、醫療衛生等領域發揮著越來越重要的作用。目的是通過研究人體在視頻中的圖像幀或圖像序列的時空變化,利用計算機處理和分析視覺信息,自動識別出視頻中的行為模式。由于人體行為類別多樣,復雜多變的背景,視頻視角的差異性等問題,網絡模型難以魯棒、準確對真實的視頻行為動作進行辨別,因此行為識別亟待研究工作者深入地開展研究工作。
現有的深度學習模式對特征提取模型的訓練多采用端到端的模式,使用訓練好的神經網絡模型參數去學習視頻的顯著特征,對行為進行分類識別。一些早前的相關研究工作主要專注于利用卷積神經網絡(CNN)來學習視頻幀連續序列中蘊含的行為的深度特征。主流的CNN網絡模型包括雙流結構的一系列的模型和3DCNN模型。然而,卷積神經網絡通常有兩個缺點:
(1)假設卷積計算的幾何變換是固定的和已知的,一般是使用這些先驗知識,來做數據的增強工作并且設計特性和算法,但是這種默認的規則,會導致算法不能對未知幾何變換的新任務進行有效泛化,會導致任務建模的不正確或不恰當;
(2)相對更加復雜的變換來說,即使已經知道其固定的特征和算法,也難以用手工的方式進行設計[1]。
一般來說,對于卷積神經網絡,卷積核具有固定幾何會導致其對幾何形變建模能力有限,標準卷積中的規則格點采樣是網絡難以適應幾何變形和時間序列位移的根本原因。Dai提出變形卷積,可以通過在傳統卷積運算的基礎上增加一個并行網絡來預測傳統卷積采樣點的偏移量,使每個采樣點都有一定的偏移量,并學習自適應感受野,從而提高了對不同尺寸和形狀物體的特征提取能力[1]。本文針對標準卷積建模能力有限的問題,在殘差網絡的基礎上,提出了可變形卷積改進的殘差網絡,以提升網絡識別的準確性。
本文在CoST模塊的基礎上,構建了新穎的DSTC(Deformable Spatio-Temporal Convolution)模塊。該模塊可在視頻數據的3個正交視圖執行2D可形變卷積,可分別學習空間外觀和時間運動線索,增強了卷積核對感受野的適應能力,以適應不同特征圖感受野的形狀、大小等幾何形變;在殘差網絡模型結構的基礎上,提出了一種新網絡模型,該模型融合了DSTC可變形卷積模塊,并且能夠將端對端訓練的網絡用于行為分類;在UCF101和HMDB51數據集上的實驗結果,證明了本文方法在公開數據集測試中具有顯著的行為識別性能,優于當前先進的方法,并且相對于3D卷積,大大減少了參數量,并提升了識別的精度。
1 相關工作
早期的行為識別工作主要使用一些傳統方法,手工制作的行為表征被很好地用于視頻行為識別。許多二維的圖像特征描述符被推廣到三維時間域,例如時空興趣點(Space-Time Interest Points,STIP),SIFT-3D,時空SIFT(Space-Time SIFT)和3D梯度直方圖(3D Histogram of Gradient)。最成功的手工特征表征是稠密軌跡流(dense trajectories)和其改善版本,其通過光流引導的軌跡提取局部特征,是傳統方法中最為魯棒,效果最好的[2-3]。
在受到深度學習取得巨大成功的鼓舞下,特別是CNN模型在圖像理解任務的成功,涌現了許多開發行為分類的深度學習方法的嘗試。Karpathy等人提出在每幀上獨立應用2D CNN模型,并探討了幾種融合時序信息的策略,由于未考慮幀之間運動變化,性能不如基于手工特征的算法[4];Donahue等人利用LSTM,通過聚合2D CNN特征建模時序信息,高級別的2D CNN特征被用來學習時序關系[5]。現在通常利用兩種方法來提升時序建模能力,第一個是基于Simonyan和Zisserman提出的雙流體系結構,該體系包括一個空間2D CNN和時序2D CNN,可分別建模幀的靜止特征和幀間光流運動信息,并將其輸出分類分數融合為最終預測,許多后續工作是對這個框架的拓展,探索了2個流特征的融合策略[6];另一個典型方法是基于3D CNN和其(2+1)D變體,Tran等人設計了一個11層C3D模型,以聯合學習Sports-1M數據集上的時空特征,然而巨大的計算成本和C3D的密集參數使得深度模型難以訓練[7]。Qiu等人提出了偽3D(P3D)模型,將3×3×3的3D卷積分解成1×3×3的2D卷積和3×1×1的1D卷積[8];Tran等人在殘差網絡上分解3D卷積為(2+1)D卷積,取得了優于3DCNN的識別效果[9];Carreira等人提出膨脹三維卷積(Inflating 3D ConvNets,I3D),通過擴充預先訓練的C2D模型的參數進行初始化[10]。
CNN模型在行為任務領域已取得了許多優秀的成果,但大多將常規卷積作為先驗知識,沒有考慮到卷積計算的本質缺陷——卷積網絡對視頻行為目標的幾何變化是未知的,這會導致模型和數據容量的低效利用。近期一些相關的工作想要通過變形建模來解決問題,Worrall等人通過移位、旋轉和反射等變形的設計,在網絡中添加幾何不變量[11];另一種思路是通過圖像空間中的半參數化或完全自由形式采樣來學習重新組合數據。Jaderberg等人通過空間變換網絡(Spatial Transformers Network,STN)學習二維仿射變換[12];Rocco等人利用深度幾何匹配器(Deep Geometric Matchers)學習薄板樣條變換[13];Dai利用可變形卷積學習自由形式的轉換[1]。受到這些研究工作的引導和啟發,在模型參數幾乎不增加的前提下,本文的模型能夠充分利用時空信息,有效地提取特征圖中的重要特征。實驗結果表明,該網絡具有良好的識別精度。
2 模型框架
本文對ResNet-50網絡進行了改進,網絡框架如圖1所示。ResNet網絡是在VGG19網絡發展而來,在其網絡基礎上進行改進,添加了殘差單元,3D-ResNet-50網絡與本文的網絡對應替換的模塊示意如圖2所示,將卷積模塊和一致性模塊中的3×3×3的卷積層替換成DSTC模塊,形成了可變形卷積模塊和可變形一致性模塊。

圖1 本文網絡整體框架圖Fig.1 The overall framework of the network in this paper
如圖2(a)所示,在網絡層之間加入短路機制,可以有效地解決深層網絡的退化問題;將殘差卷積模塊和一致性模塊(圖2(a)和圖2(c))中的3D卷積層替換成了可變形卷積模塊(DSTC),進而構造可變形殘差卷積模塊和可變形一致性模塊(圖2(b)和圖2(d)),從而構建了改進版本的ResNet-50網絡。首先,將輸入的視頻幀堆疊的圖像序列裁剪成固定大小,通過三維卷積和最大池運算對數據進行初始化;其次,將初始化后的特征圖像依次發送到4個大的卷積模塊中(Layer1-Layer4),每個大模塊依次由3,4,6和3個可變形殘差模塊組成,每個可變形殘差模塊中包括對特征圖進行卷積運算,批量歸一化和激活函數運算操作;最后,將特征圖輸入到分類層中依次執行3D平均池化、全連接層和Softmax操作得到行為的標簽,得到的行為識別結果。
圖2是3D-ResNet-50網絡與本文的網絡對應替換的模塊示意圖,將卷積模塊和一致性模塊中的3×3×3的卷積層替換成DSTC模塊,形成了可變形卷積模塊和可變形一致性模塊。

圖2 引入可變形卷積的模塊Fig.2 Modules with deformable convolution
2.1 可形變卷積層
卷積網絡對大尺寸多形變目標的建模存在固有的缺陷,因為卷積網絡只對輸入特征圖的固定位置進行采樣。例如,在同一層特征圖中,所有特征點的感受野都是相同的,但不同的位置可能對應不同的尺度或變形對象,因此尺度或感受野大小的自適應學習是實現精確定位的必要條件。在模型中加入可變形卷積能夠有效提升對目標形變的建模能力,使用一個平行卷積層學習offset偏移,在輸入特征圖上對應的任一卷積核的采樣點位置上進行偏移,使得這些采樣點更加集中在興趣目標區域上,即增添一個偏移量在每個采樣點對應位置,就可以打破常規卷積的規則網格的約束,在采樣位置周邊進行隨意的采樣。
普通卷積和可變形卷積的計算過程如圖3所示。在普通卷積中,使用卷積核w對規則網格R(R={(-1,-1),(-1,0),…,(0,1),(1,1)})中的采樣點進行加權運算;在可變形卷積中,通過一個平行的卷積層,對輸入特征圖進行卷積,得到與輸出特征圖具有相同的分辨率的偏移量,輸出通道數為3N(N為卷積核采樣點個數),其中2N為預測的x,y2個維度上的偏移量;由于不同采樣點對特征有不同的貢獻,還要預測N個采樣點的權重。到目前為止,已經有了輸入特征圖以及輸入特征圖上每個點對應的偏移量和權重,于是可以執可變形卷積運算。

圖3 普通卷積和可變形卷積計算過程示意圖Fig.3 Calculation process of general convolution and deformable convolution
在可變形卷積的操作中,延續了卷積運算的一般計算過程,只是在采樣區域加入一個由能夠通過網絡自動學習的參數{Δpn|n=1,…,N},N=|R|,同時對每個采樣點預測一個權重Δmn,那么同樣的位置P0的值變為公式(1):

由于Δpn通常是小數,因此需要通過雙線性插值法計算x的值,公式(2)為:
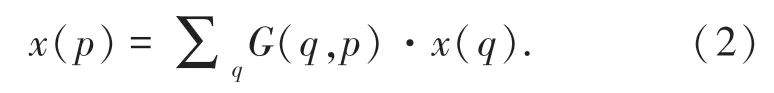
其中,p代表位置,也就是公式中的p0+pn+Δpn,列舉了輸入特征圖x的空間位置,其中G(.,.)表示雙線性插值算法中的核函數,是二維的,可以被分為2個一維核,式(3):

因為絕大部分的參數都為0,因此可以很快地計算出結果。
2.2 DSTC模塊
本文模塊在CoST模塊改進而來。C3D3×3×3卷積操作利用3×3的三維卷積聯合提取空間(沿H和W)和時間(沿T)特征。本文所提出的模塊中,沿T×H×W立體數據的3個視圖H-W、T-H和TW分別執行可變形2D3×3卷積。值得注意的是,模塊的三視圖卷積計算的參數是共享的,這使得參數的數量與單視圖二維卷積相同,這樣可以大大降低參數的數量。隨后,3個生成的特征圖依次加權求和,卷積計算的權值將在訓練過程中以端到端的方式學習。
圖4給出了DSCT模塊的示意圖,設x表示大小為T×H×W×C1的輸入特征映射,其中C1是輸入通道的數目。來自不同視圖的3組輸出特征映射的計算方法是公式(4):

圖4 可變形時空卷積模塊Fig.4 DeformableSpatial-Temporal Convolution Module

其中,?表示三維卷積,w是3個視圖之間共享的大小為3×3的卷積濾波器。為了將w應用于圖像幀的不同視圖,在不同的維度上插入一個尺寸為1的附加維度,由此產生的w的變體,即w1×3×3、w3×1×3和w3×3×1分別學習H-W、T-W和T-H視圖的特征,然后對3組特征映射加權求和,式(5):

其中,α=[αhw,αtw,αth]的維度為C2×3;C2為輸出通道數;3表示3個視圖。為了避免來自多個視圖的響應的大小爆發式增長,α沿每行用Softmax函數歸一化,α的系數由網絡乘以α的特征圖來學習得到,這種設計是受近來機器翻譯的注意力機制的啟發。在這種情況下,每個樣本的系數取決于樣本本身,可以用公式(6)表達:

虛線內的計算塊表示方程中的函數f。對于每個視圖,首先使用全局最大池化層將尺度為T×H×W×C2的特征映射沿著T,H,W3個維度減少到1×1×1×C2;然后,在池化特征上應用1×1×1卷積,其權重也由所有3個視圖共享,這種卷積將維數C2的特征仍然映射回C2,可以捕獲不同信道之間的上下文信息;這3組特征被連接并輸入到一個全連接(FC)層中。相對于1×1×1卷積,這個全連接(FC)層被應用于C2×3矩陣的每一行,它捕捉不同視圖之間的上下文信息;最后,通過Softmax函數對輸出進行歸一化,得到α,將歸一化后的參數α與[xhw,xtw,xth]相乘得到輸出特征值。
2.3 損失函數
本文用標準交叉熵損失函數來評價網絡性能。對于不同網絡分支來說,損失函數如式(7):

其中,yi是動作所屬類的真實標簽;p是訓練后的模型進行預測屬于不同的類別分數;i表示不同行為類別的種類數;計算得到的總損失L通過反向傳播算法將所有網絡參數不斷優化。為了驗證光流對行為識別準確率的影響,本文構建了雙流的結構進行試驗,將損失函數Lo表示光流的損失函數,LR表示RGB幀的損失函數,模型的損失函數表示為式(8):

3 實 驗
3.1 數據集
UCF101是于YouTube收集而來,包含大量真實動作視頻,用于動作識別任務,共101個動作類別。視頻的分辨率是320×240,數據集分成101個行為類別,這些動作類別又被分成25個小組,每個小組又分別包含4-7個動作視頻,一共包含13 320個視頻,占用存儲空間約為6.5G。101個動作類型由五類組成:人人間的互動、人物間的互動、人體做出的行為動作、樂器演奏表演和體育競技運動。UCF101的宗旨是對一些實際行動類別進行學習,并探索未知的行為類型,鼓勵推進行動識別工作的研究與發展,對研究視頻行為分類工作意義重大。
HMDB-51數據集共含51個人類行為動作,任一類別包含101個視頻段,共計6 766個拍攝視頻,對于每一個視頻,有平均3 s左右持續時長。每一個剪輯進行了多輪的手動注釋,剪輯多來自于電影中,小部分來自于一些公開數據集。廣泛的面部動作如微笑,咀嚼等;常規的身體動作,如散步,擺手;人物交互的動作,如打球,梳頭發,拔劍以及人類間的交互動作,如接吻,擁抱等。
3.2 實驗細節和評價標準
在實驗準備工作中,用FFmpeg工具將視頻數據按照設定的幀率分割成視頻幀,并記錄每個視頻的視頻幀數量。為了合理地挑選訓練樣本,采納了均勻采樣的提取方式,設定時間位置,在其周邊選取視頻中的視頻幀。為了滿足16幀的需求,有時候需要對視頻進行多次循環采樣。在設定時間位置連續地取若干個視頻幀以構成三維(H,W,T)視頻信息。緊接著對視頻幀進行時空裁剪操作,選取空間位置依照的規則是選取視頻提取幀的中心或四個邊角點位置之一。輸入的原始視頻幀尺寸為224×224,網絡將其裁剪成112×112的大小,訓練一次取16幀,由于訓練數據是RGB圖像,取信道數為3。
實驗中采用交叉熵損失函數,參數的微調工作將通過反向傳播算法來開展,將權重衰減參數和動量參數分別設置為0.9和0.001。訓練網絡起初,將學習率lr設定為0.2,當驗證損失趨于飽和后,將學習率減少到其十分之一大小;在網絡進入微調的階段時,學習率lr參數改變為0.01,權重衰減參數改變為1e-6。 本文在深度學習框架PyTorch上進行實驗設計,實驗工作站配置為i7 6800k酷睿6核、2塊NIVDIA GTX1080Ti 8GB顯卡、64G內存,256G固態硬盤。
Top-N準確率被采用來評價行為識別的性能。評判依據是:在測試視頻數據的前N大分類概率中,判斷正確的分類是否被包括其中,如果是,則認定為識別成功。
3.3 實驗結果分析
本文提出的可變形卷積模塊(DSTC)對行為識別性能產生的影響,見表1,可明顯看出,在引入可變形卷積模塊(DSTC)后,本文所提出的改進的網絡模型所取得的效果顯著,能夠有效地運用于行為分類任務。

表1 UCF101數據集上可變形卷積模塊對實驗性能的影響Tab.1 The impact of experiment result by deformable convolution factor on UCF101 dataset
在UCF101和HMDB51數據集上,分別觀察與對比模型的識別效果,將本文方法和當前一些優秀方法進行比較,見表2和表3。

表2 UCF101數據集上使用不同網絡模型的識別性能Tab.2 Recognition performance of different networks on UCF101 dataset

表3 HMDB51數據集上使用不同網絡模型的識別性能Tab.3 Recognition performance of different networks on HMDB51 dataset
表2和表3表明,相比于一些現有的效果良好的方法,本文提出方法最終得到了相對更高的識別正確率。實驗證明,通過對網絡設置并行支路來處理光流信息,可加強網絡的識別性能,進一步證明本文的方法有深遠的研究價值。
在UCF-101數據集上,DSTC方法訓練和驗證過程中交叉熵損失函數的緩慢變化,如圖5所示。隨著訓練和驗證過程的進行,交叉熵損失值逐漸減小,DSTC模型的識別效果逐漸變好。

圖5 訓練及驗證過程損失函數變化Fig.5 The loss function of Training and Validation process
為了能夠更直觀地觀察本文方法的細節效果,從UCF101和HMDB51數據集中選取了6個差異比較顯著的行為類別進行可視化研究,展示了DSTC方法在不同類別上的注意力熱圖,顏色越深代表該區域的特征顯著性越強,模型對其關注度更高。從圖中可以發現,我們的方法能夠更好的動態適應特征的形變,更加有效地關注視頻中更重要的特征區域,能夠捕獲到有效的時空信息進行學習,以提升行為識別的準確率,如圖6所示。

圖6 幾種類別的注意力熱圖可視化Fig.6 Visualization of heat maps of attention for several categories
4 結束語
本文提出一種基于可變形卷積的改進型3DResNet網絡,用于視頻中的行為識別,通過引入形變卷積,構建了一個可自適應地協同學習視頻三維信息的模塊,將該模塊替換3D-ResNet網絡中部分卷積模塊,提高行為識別效率。同時,融合了光流信息進行實驗,證明了光流信息的引入可進一步提升模型的準確率,說明方法仍具有深遠的研究價值。實驗結果表明,與現有的一些效果顯著的方法相比較而言,本文方法能擁有更準確的識別性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
中華詩詞(2020年1期)2020-09-21 09:24:52
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(中高年級適用)(2018年5期)2018-06-11 01:22:56
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中學生數理化·七年級數學人教版(2017年11期)2017-04-23 07:18:00
數學大王·中高年級(2016年12期)2016-12-26 21:37:36
