基于CBAM的深度序數回歸方法
2021-10-05 12:44:22高永彬王慧星
智能計算機與應用 2021年5期
高永彬,王慧星,黃 勃
(上海工程技術大學 電子電氣工程學院,上海201620)
0 引 言
單目深度估計對三維場景理解任務具有重要意義,在三維重建、自動駕駛、視覺跟蹤、三維目標檢測、增強現實等領域有著廣泛的應用。隨著深度學習的迅速發展,利用有監督學習方法進行單目深度估計的研究大量涌現,這些方法通常將深度估計建模作為一個回歸問題,使用深度卷積神經網絡獲取圖像的層次信息和層次特征,并通過最小化均方誤差來訓練回歸網絡。然而,這些方法往往存在缺點:一方面,使用最小化均方誤差來訓練回歸網絡,往往會導致網絡收斂慢和局部解不理想的問題;另一方面,為了獲得高分辨率的深度圖,需要使用跳躍連接或多層反卷積網絡結構,這使網絡訓練更加復雜,計算量大大增加;最后,利用多尺度網絡對圖像進行特征提取,往往會丟失像素的特征信息和位置信息,對較小目標的深度估計效果較差。為此,Fu等人提出了用于單目深度估計的深度序數回歸網絡(Deep Ordinal Regression Network),使 用ASPP(Atrous Spatial Pyramid Pooling)獲取不同尺度的特征,并通過全圖像編碼器捕獲全局上下文信息[1]。采用離散策略對深度值進行離散,將深度估計轉化為序數回歸問題,通過一個普通回歸損失函數訓練網絡,提高網絡訓練效率。
本文主要對深度序數回歸網絡深度序數回歸算法進行研究,主要貢獻如下:
(1)提出了一種基于CBAM(convolutional block attention module)的深度序數回歸方法,通過CBAM代替深度序數回歸算法中的全圖像編碼器,獲取更完整的像素特征信息和位置信息,提高全局上下文信息的表示能力;
(2)將CBAM中的通道注意力機制和空間注意力機制以不同的順序融入到網絡中,以發現注意力機制的順序與網絡結構的相適應性,探索出最佳的網絡模型;
(3)實驗結果證明,本文提出的網絡模型可以有效地提高深度估計的精度,在KITTI數據集上進行測試,效果比當前最佳方法提高1%左右。
1 單目深度估計研究現狀
近年來,深度學習被廣泛應用于計算機視覺領域,并在單目深度估計方面取得了顯著的成就。Eigen等首次將深度學習應用于單目深度估計研究中,提出了一種多尺度神經網絡用于深度估計的思想,首先使用粗尺度網絡預測圖像的全局深度,然后使用細尺度網絡優化局部細節,最終獲得像素級別的深度信息[2];在此方法的基礎之上,他們又提出了一種用于多任務的多尺度網絡框架,使用了更深層次的網絡結構,利用3個細尺度的網絡進一步增添細節信息,使用不同的損失函數和數據集分別對深度預測、表面法向量估計和語義分割任務進行訓練,最終獲得了良好的效果[3];由于多尺度網絡只是使用幾個串聯的淺層網絡對圖像進行分層細化,因此最終得到的深度圖分辨率是偏低的,為了提高深度圖的分辨率,Li等在多尺度網絡之間加入跳躍連接,在第一個網絡中使用跳躍連接,對池化后的特征圖進行上采樣,進而與第二個網絡中的特征圖進行拼接,同樣地,第二個網絡中的特征圖與第三個網絡中的特征圖進行拼接,使網絡同時將較深層的低空間分辨率深度圖與較低層的高空間分辨率深度圖融合,提高了深度圖的分辨率[4];Laina等提出了一種殘差學習的全卷積網絡,用于單幅圖像的深度估計,網絡結構更深,提高輸出分辨率的同時又優化了效率[5];Liu等提出了將條件隨機場(conditional random field,CRF)與CNN相結合來估計單幅圖像深度的方法,使用CRF的一階項和二階項綜合訓練2個CNN,然后將這兩個網絡通過CRF能量函數統一于一個訓練框架中,這種方式可以提供更多的約束[6];同樣使用CRF方法,Xu等提出了一種結構化注意力模型,它可以自動調節不同尺度下對應特征之間傳遞的信息量,并且可以無縫集成到CRF中,允許對整個架構進行端到端訓練[7];Cao等把深度估計問題看作像素分類問題,首先將深度值進行離散,然后使用殘差網絡來預測每個像素對應的類別,最終使用CRF模型進行優化[8];Chang等提出了使用金字塔池化模塊來捕捉更多的全局信息,使單幅圖像的深度估計精度得到提高[9]。
以上方法雖然都利用了有監督學習的方法對單幅圖像進行深度估計,但使用多尺度網絡結構往往會丟失像素的特征信息和位置信息,對深度估計精度造成影響。通過最小化均方誤差訓練網絡,存在收斂慢和局部解不理想的缺點。加入跳躍連接等結構,使網絡訓練復雜,計算量增加。
目前還有一些使用無監督學習進行深度估計的方法,Chen等提出了一種場景網絡來對物體的幾何結構進行建模,通過增強立體圖像對之間的語義一致性來執行區域感知深度估計[10];Lee等提出了一種利用相對深度圖進行單目深度估計的方法,使用CNN在不同的尺度上估計區域對之間的相對深度和普通深度,進而將普通深度圖和相對深度圖分解,并對分解之后的深度圖進行優化重組,以重建最終的深度圖[11]。雖然無監督學習方法在一定程度上克服了數據標注工作量大的問題,但是始終達不到有監督學習的方法的精度。
針對以上問題,本文對有監督學習的單目深度估計模型深度序數回歸算法進行了研究,發現深度序數回歸算法中使用的全圖像編碼器存在易丟失較大特征值像素特征信息和位置信息的缺點。本文引入CBAM,提出了一種CBAM的深度序數回歸方法。使用全局最大池化和全局平均池化替代局部平均池化,解決較大特征值像素特征信息易丟失的問題。使用空間注意力機制生成的注意力特征圖與原始特征圖相乘替代簡單的復制操作,解決像素位置信息易丟失的問題。
2 網絡框架
本文方法的整體網絡框架如圖1所示。主要由3部分組成,特征提取網絡、場景理解模塊和序數回歸模塊。

圖1 整體網絡結構Fig.1 Overall network structure
首先將單幅圖像輸入到特征提取網絡中進行初步的特征提取,特征提取網絡采用ResNet-101,通過在ImageNet數據集上預訓練好的模型對其進行初始化。由于前幾層的特征只包含一般的低級信息,在初始化后固定ResNet-101前2個卷積層的參數,且在訓練過程中為BN(Batch Normalization)層直接進行初始化;然后將得到的特征送入場景理解模塊,場景理解模塊包括全圖像編碼器、空洞空間卷積池化金字塔模塊ASPP和跨通道信息學習器。全圖像編碼器主要作用是捕獲全局特征的上下文信息,在這里使用CBAM取代全圖像編碼器結構,依次使用通道注意力機制和空間注意力機制捕獲像素更好的特征信息和位置信息;ASPP模塊主要使用采樣率分別為6、12和18的空洞卷積對輸入的特征圖進行并行采樣,進而得到多尺度融合特征,來表征不同大小區域的圖像特征;跨通道信息學習器主要使用1×1的卷積對各個通道之間的相互作用進行學習。進一步地將全圖像編碼器、ASPP模塊和跨通道信息學習器輸出的特征圖分別經過一個1×1的卷積,進而將3個模塊的所有輸出進行合并,再經過一個1×1的卷積,輸入到序數回歸模塊。最后根據深度值的序數相關性,使用間隔遞增離散化策略(spacing-increasing discretization,SID)在對數空間中對深度值進行離散,以降低深度值較大區域的訓練損失。使用普通的序數回歸損失來學習網絡參數,獲得更高的精度。
2.1 全圖像編碼器
深度序數回歸算法中的全圖像編碼器結構如圖2所示。為了從尺寸為C×h×w的F中獲得相同尺寸的全局特征F'',首先要通過局部平均池化對原始特征進行降維,將降維之后的特征通過全連接層得到一個C維的特征向量;將特征向量視為空間維數為1×1特征圖的C通道,并添加一個核尺寸為1×1的卷積層作為特征向量跨通道參數池化結構;最后,將特征向量復制到F'',使F''的每個位置對整個圖像有相同的理解。通過研究發現全圖像編碼器存在以下缺點:

圖2 全圖像編碼器Fig.2 Full image encoder
(1)只使用平均池化存在2個弊端:一方面,由于圖像中感興趣的對象往往會產生較大的像素值,因此只使用平均池化會丟失較大特征值像素的特征信息;另一方面,局部的平均池化只是使用小尺寸的卷積核在圖像中進行局部卷積,難以很好地整合圖像的全局信息;
(2)針對圖像每個位置的信息,只將特征圖簡單地復制到整個圖像,會丟失重要像素的位置信息。基于以上全圖像編碼器的缺點,本文使用CBAM替代全圖像編碼器,通過全局最大池化和全局平均池化更好地捕獲較大特征值像素的特征信息。通過空間注意力機制生成的注意力圖與原始特征圖相乘替代簡單的復制操作,保留完整的位置信息。
2.2 CBAM(Convolutional Block Attention Module)
如圖1中的綠色部分所示,CBAM依次通過通道注意力機制和空間注意力機制,下面分別對通道注意力機制和空間注意力機制進行詳細介紹。
通道注意力機制如圖3所示。首先在空間維度上使用全局最大池化和全局平均池化操作對輸入特征F∈RC×H×W進行壓縮,生成2個不同的特征描述符;將2個描述符分別送入一個由多層感知機(multi-layer perceptron,MLP)構成的共享網絡進行計算,進一步將共享網絡輸出的最大池化特征向量和平均池化特征向量以元素求和的方式進行合并;最終使用sigmoid函數將合并之后的特征向量映射到[0,1],進而得到通道注意力圖。通道注意力圖Mc∈RC×1×1的計算過程如式(1):

其中,σ代表sigmoid函數。
空間注意力機制如圖4所示。首先在通道維度上對經過通道注意圖提煉之后的特征F'∈RC×H×W使用全局最大池化和全局平均池化操作,得到2個不同的特征描述符;使用卷積層對它們進行連接合并;最終使用sigmoid函數將合并之后的特征向量映射到[0,1],進而得到空間注意力圖。空間注意力圖Ms∈RH×W的計算過程如式(2):

圖4 空間注意力機制Fig.4 Spatial attention module

其中,f7×7代表卷積核尺寸為7×7的卷積運算。
得到通道注意力圖和空間注意力圖后,將通道注意力圖與輸入特征相乘得到F',然后計算F'的空間注意力圖,并將二者相乘得到最終的特征F''。 該過程可表示為式(3)和式(4):

其中,?代表逐元素相乘。
將原始特征依次經過通道注意力圖和空間注意力圖的調整,使最終特征圖中的較大特征值像素特征信息和位置信息更加完整。
2.3 損失函數和離散策略
總的序數損失被表示為每個像素的序數損失的平均值。每個像素的序數損失函數為式(5)和式(6):

其中,l(w,h)∈{0,1,…,K-1}代表在空間位置(w,h)通過使用SID離散策略得到的離散標簽;代表預測的離散深度值;通過softmax函數計算。
總的序數損失函數為式(7):
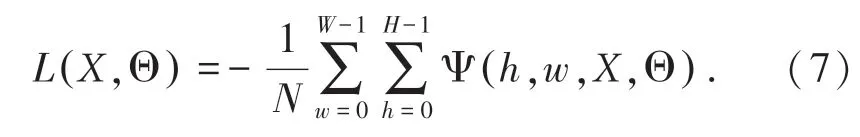
其中,N=W×H。
由于隨著深度值的增大,用于深度估計的信息會逐漸減少,進而導致較大深度值的估計誤差通常較大。因此使用SID策略進行離散化,該策略在對數空間中統一離散給定深度區間,以降低大深度值區域的訓練損失,合理估計大深度值。假設深度區間[α,β]需要離散為M個子段,SID策略可表示為式(8):

其中,si∈{s0,s1,…,sM}代表離散閾值。
最終預測的深度值為式(9):

其中,ε為偏移值,α+ε=1。
3 實驗過程及結果
3.1 實驗設置
KITTI數據集主要包含室外場景,數據由裝載在行駛汽車上的相機和深度傳感器捕獲,圖像大小為375×1241像素[12]。本文算法在KITTI數據集上進行訓練和測試,數據切分方式從29個場景中切分出697幅圖像進行測試,其余的32個場景中的23 488幅圖像用于訓練和交叉驗證,其中22 600幅用于訓練,剩余的圖像用于驗證。實驗中,網絡結構使用Pytorch框架實現,訓練時將輸入圖像大小調整為385×513。網絡使用SGD優化器進行優化,動量縮減參數設置為0.9,權重縮減參數設置為0.0005,初始學習率設置為0.000 1,mini-batch尺寸設置為4。
將訓練模型的實驗結果與其它相關方法進行對比,采用常用的評價指標來評估結果,其中di表示真實深度;表示預測深度;N表示圖像的像素總數。指標表達式為:
·絕 對 相 對 誤 差(absolute relative error,AbsRel),式(10):

·平方相對誤差(squared relative error,SqRel),式(11):

·均 方 根 誤 差(root mean squared error,RMSE),式(12):

·準確率:滿足如下條件的像素占總像素的百分比,式(13):

其中,thr=1.25,1.252,1.253。
3.2 實驗結果與分析
本文方法與幾個先進的單目深度估計方法的對比結果見表1,這些方法中包括了有基于監督學習的 方 法(Eigen et al.[2]、Liu et al.[13]和Gan et al.[14])、半監督學習的方法(Kuznietsov et al.[15])和無監督學習的方法(Garg et al.[16]和Yin et al.[17])。從實驗結果可以看出,本文算法的深度估計效果明顯優于無監督學習方法的效果,同時也達到甚至超過了有監督學習方法的效果,這主要得益于在訓練過程中,通過使用通道注意力機制和空間注意力機制提高了全局信息的表示能力。為了證明算法改進部分的有效性,在表1中還提供了在KITTI數據集上的消融實驗結果,各項指標的結果證明了改進部分的有效性。
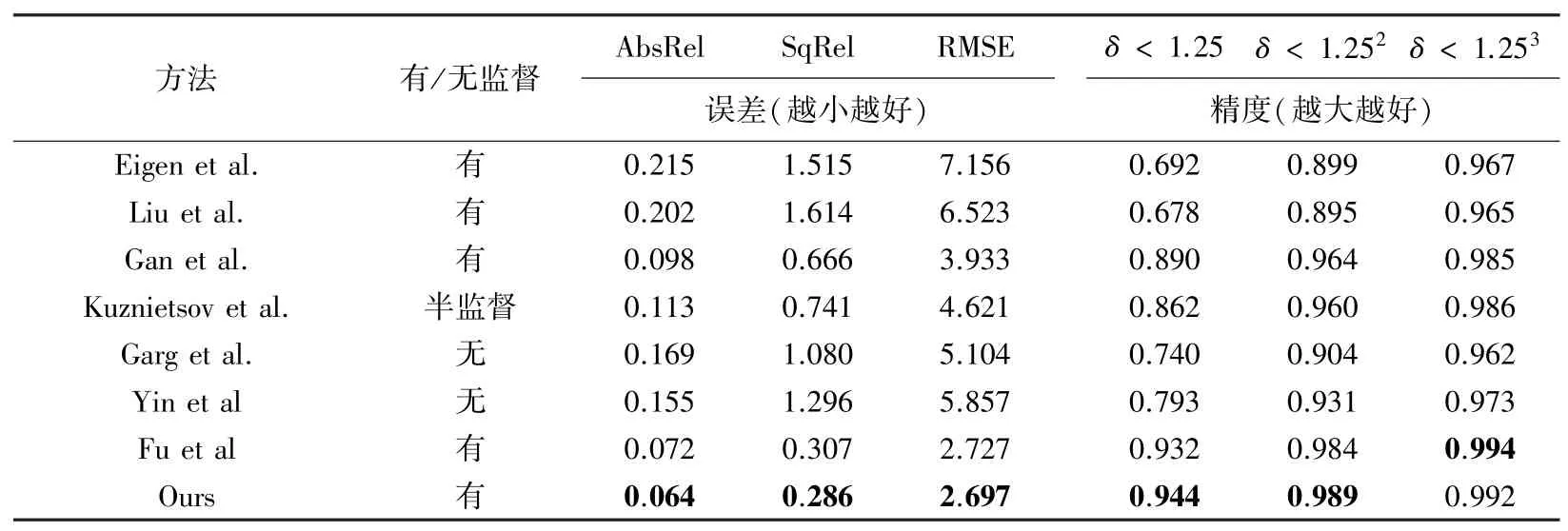
表1 KITTI數據集上的實驗結果對比Tab.1 Comparison of experimental results on the KITTI dataset
3.3 消融實驗
消融實驗的結果見表2。主要對網絡中CBAM中通道注意力和空間注意力機制的使用順序進行了分析。在只使用通道注意力機制、先空間注意力機制后通道注意力機制和先通道注意力機制后空間注意力機制3個方面進行實驗。通過分析表2可知,先通道注意力機制后空間注意力機制的精度比只使用通道注意力機制和先使用空間注意力機制后使用通道注意力機制的效果都高,說明先通道注意力機制后空間注意力機制的順序結構可以捕獲像素更完整的特征信息和位置信息。

表2 消融實驗結果Tab.2 Results of ablation experiment
KITTI數據集上的深度估計的效果圖如圖5所示。與其它方法相比,該模型在細節處理方面具有更強大的能力,主要表現在小物體、行人以及樹木等區域保留了更為豐富的紋理信息,細節處理更加平滑,且前景和背景分離效果更好。

圖5 各模型深度預測結果Fig.5 Depth prediction results of each model
為了評估本文方法的泛化能力,本文還在Cityscapes數據集做了測試實驗,效果如圖6所示。該方法只使用KITTI數據集進行訓練和評估,而沒有使用Cityscapes數據集。雖然兩個數據集的場景類型存在一定差異,但是該方法仍然可以輸出效果很好的深度圖像。

圖6 在Cityscapes數據集上的測試效果圖Fig.6 Test effect diagram on Cityscapes dataset
4 結束語
針對有監督學習的單目深度估計模型深度序數回歸算法中全圖像編碼器易丟失較大像素特征信息和位置信息的問題,本文提出一種基于CBAM的深度序數回歸方法。通過一系列的對比試驗和消融實驗,展示出了該方法的優異性和合理性。對比基礎網絡,該方法的網絡模型捕獲了更多目標的特征信息和位置信息,更加完整地保留了圖像中較小目標或其他細節的特征。通過利用KITTI數據集和Cityscapes數據集對該方法進行驗證,表明其高于現有的大部分深度估計方法。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
