面向圖像語義分割任務的多級注意力蒸餾學習
2021-10-05 12:44:04劉佳琦王龍志
智能計算機與應用 2021年5期
劉佳琦,楊 璐,王龍志
(1天津理工大學 天津市先進機電系統設計與智能控制重點實驗室,天津300384;2天津理工大學機電工程國家級實驗教學示范中心,天津300384;3奧特貝睿(天津)科技有限公司,天津300300)
0 引 言
知識蒸餾是深度學習領域一項重要的模型壓縮技術。傳統的蒸餾學習思想是通過提前訓練好的大網絡對輕量網絡進行知識傳遞,從而使輕量網絡能達到大網絡的表達能力,實現知識遷移。基于傳統蒸餾學習的模型訓練主要分為兩個步驟:首先充分訓練一個結構復雜、學習能力強的教師網絡,使其具有優秀的表達能力;其次在教師網絡的基礎上設計一個結構簡單、參數量小的學生網絡,使用教師網絡的特征約束作為軟標簽進行監督,使學生網絡通過軟標簽對真實標簽輔助訓練,逐漸逼近教師網絡的表達水平。從模型推理方面分析,教師網絡只在訓練階段對學生網絡起到約束作用,不參與學生網絡的獨立推理過程的計算與部署,因此知識蒸餾在神經網絡模型輕量化領域有著重要的意義。
由于傳統蒸餾學習中的教師網絡對學生網絡的知識傳遞是單向的,難以從學生網絡的學習狀態中得到反饋信息,來對訓練過程進行優化調整,從而對學生網絡的訓練產生負影響;其次,采取教師網絡產生軟標簽結合真實標簽進行監督的形式,當軟標簽權重過高時,學生網絡會過于模仿教師網絡,從而限制學生網絡的特征表達能力;由于針對不同困難程度的數據集任務,所需要的教師網絡的軟標簽監督權重也有所不同,因此增加了訓練過程的難度。
近年來,人們嘗試將網絡自身的特征作為軟標簽,不需要訓練教師網絡,實現了輕量網絡模型自身的監督優化。SAD嘗試使用兩個相鄰層級間的上下文信息,使得淺層特征學習高層特征,從而實現網絡性能的整體提升。但是,以相鄰層級信息進行約束不能對上下文信息進行充分的利用。本文借鑒了Densenet對Resnet的優化改進思想,使得上下文特征信息可以在整個網絡中被充分利用,進而保證每一層級學習的特征約束,都能作用到網絡之后的所有層級。
綜上所述,針對已有研究工作的不足本文提出了一種自適應多級注意力蒸餾學習方法(MAD)。該方法使用網絡自身的高層特征對淺層逐級進行約束,以自身的深層單元來約束淺層單元,以此實現模型知識由深層向淺層的傳遞。在充分利用上下文信息的基礎上,對各層級間的表達能力進行提升。
1 相關工作
1.1 知識蒸餾
知識蒸餾的提出,是為了實現知識遷移。Hinton[1]系統的詮釋了知識蒸餾的概念,并以教師網絡的輸出作為軟標簽來監督學生網絡訓練,從而驗證了知識遷移的可行性。在后續的大量研究中,探究了提高知識遷移效率的方法。FITNETS[2]提出添加教師網絡中間層的特征,作為學生網絡學習的軟標簽,使得學生網絡在關注教師模型輸出的同時,實現了中間層的特征約束。文獻[3]認為硬標簽會導致模型在訓練過程中發生過擬合,而使用軟標簽更能提高模型的泛化能力,在訓練任務中選擇幾個具有最高置信度分數的類,可以作為軟標簽來計算損失。為了更好的表征神經網絡中間層的特征,文獻[4-5]認為,可以優化中間層特征的表征編碼方式;文獻[6]認為,神經網絡層與層之間的特征關系更能作為特征提取能力的指標,因此讓學生網絡學習到教師網絡的層級之間的特征關系更為重要;文獻[7]認為,以特征圖作為軟標簽進行傳遞效果不佳,提出使用注意力圖代替特征圖,最小化教師網絡與學生網絡之間注意力圖的歐氏距離,可以獲得更好的效果;文獻[8]中認為,基于激活的注意力蒸餾會產生明顯的性能提高,而基于梯度的注意力蒸餾提升相對較小。
1.2 語義分割
語義分割屬于像素級別的分類任務,通過對每個像素進行密集的預測來實現細粒度的推理。語義分割體系結構被廣泛認為是編解碼結構(Encoder-Decoder)。其中編碼器通常為特征提取網絡,典型的編 碼 特 征 提 取 網 絡 有:Resnet[9]、GoogleNet[10]、VGGNet[11]。解碼器將編碼器學習提取到的語義特征投影到像素空間上得到密集的分類。
FCN[12]作為經典的編解碼語義分割結構,取得了矚目的成就,使用反卷積對卷積特征進行上采樣,對每個像素類別進行預測,實現圖像語義分割。U-Net[13]在FCN的基礎上,通過加入更多的底層特征,實現了對小物體細節分割質量的提升,PSPNet[14]通過利用空間金字塔池化模塊進行編碼,實現了對多尺度信息進行特征融合。同時,DeepLab_V3[15]在DeepLab_V2[16]的基礎上,對空間金字塔模塊進行改進,取得了分割精確性的提升。ENet[17]使用下卷積層并行池化層來進行下采樣,解碼階段使用空洞卷積,在獲得大感受野的同時獲得豐富的上下文信息。ERFNet[18]在ENet的基礎上進行改進,使用非對稱卷積,實現了網絡準確性與實時性的提升。
2 多級注意力蒸餾學習
2.1 多級蒸餾
將卷積神經網絡劃分為幾個單元,使得前一單元可以從后續的各個單元中提取有用的上下文信息。本文以ERFNet網絡結構為例,將網絡的Encoder部分拆分成6個單元,如圖1所示,以自身的深層單元來約束淺層單元,以實現模型知識由深層向淺層的傳遞,提高淺層的表達能力,從而提升模型整體的表達能力。

圖1 MAD算法結構圖Fig.1 Structure of MAD algorithm
對于一個共有L個單元的網絡,如圖2所示,共包含N級蒸餾。將各級蒸餾中每個分支進行加和,各級蒸餾損失函數如下:

圖2 多級注意力蒸餾示意圖Fig.2 Multi-Res Distillation

式中,n為蒸餾級別,i代表了當前級別下的序數。
將總蒸餾損失函數設為各級蒸餾加權損失之和,計算公式如下:

式中,an為一個自適應的權重系數,與初設的單元數量有關。設定相鄰層級蒸餾可獲得高權重,蒸餾層級跨度越大獲得權重越低,因此自適應權重系數αn為:
如公式(5)所示,通過計算加權的分割損失與蒸餾損失,可得到總的損失函數。本文使用一個權重系數β來平衡分割損失與蒸餾損失對最終任務的影響。(權重系數β將在3.3節進行討論)

所有蒸餾部分只在訓練期間進行計算,因此在測試推理過程中不增加計算量。
2.2 激活注意力
注意力圖主要可以分為兩類:基于激活的注意力圖與基于梯度的注意力圖。文獻[7]的研究發現,基于激活的注意力蒸餾可顯著提高性能;基于梯度的注意力蒸餾,提升效果不明顯。因此,本文使用基于激活的注意力蒸餾方法。
為了定義一個空間注意力映射,可以將隱藏神經元激活的絕對值,作為該神經元相對于輸入的注意力。因此,通過計算這些值在通道維度上的統計,來構建空間注意力圖。生成注意力圖時,在特征經過softmax操作之前,使用雙線性上采樣,使不同層輸出的特征圖尺寸保持統一。注意力圖生成過程如圖3所示。
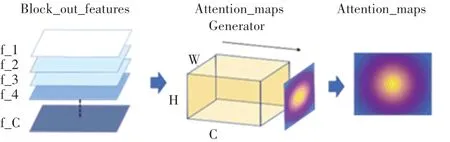
圖3 注意力圖生成過程Fig.3 The generating process of attention maps
針對不同的任務,注意力圖的計算方式會有所不同,這主要與任務中特征的種類、數量、復雜程度有關。對于車道線檢測任務,計算注意力圖使用A∈RC×RH×RW表示網絡卷積層的激活輸出,其中C、H和W分別表示通道、高度和寬度。通過計算通道維度上的統計來表征注意力圖,有以下2種有效操作[7]可以作為映射函數:

針對車道線檢測任務,希望網絡注意力集中在車道線附近的區域,本文可視化了2種映射函數提取得到的注意力圖,如圖4所示。通過對比兩種映射函數發現:作為映射函數,可以使注意力圖更加集中在特征區域。其中p越大,特征區域的激活程度越高。根據對比分析,當p取2時,會使注意力圖的偏差更小。

圖4 不同映射方法結果Fig.4 Results of different mapping methods
因此,本文注意力圖計算公式為:

式中,C為卷積層的通道數,即特征圖的數量。注意力圖即為當前單元各通道特征圖的平方和,從而可以計算出每個層級單元間注意力蒸餾損失函數:

3 實 驗
使用輕量級網絡ERFNet、DeepLab_V3在2個不同難度任務的分割數據集CULane、VOC2012上進行驗證。
3.1 數據集
3.1.1 CULane
CULane數據集[19]是一個大規模車道檢測數據集,包含了許多具有挑戰性的駕駛場景。如,擁擠的道路條件或照明不足的道路。其是由安裝在北京不同司機駕駛的6輛不同車輛上的攝像頭采集而得。收集了超過55 h的視頻,提取了133 235幀。將數據集分成88 880個訓練集、9 675個驗證集、34 680個測試集。測試集分為正常和8個挑戰性類別,對應于表1中的9個示例。
3.1.2 PASCAL VOC
PASCAL VOC 2O12數據集[20]是常用語義分割的數據集。該數據集擁有1 464張訓練圖片、1 449張驗證圖片和1 456張測試圖片。其中包括20個前景類別和一個背景類別共21個語義分類,該數據集中的大部分圖像的分辨率接近500×500。
3.2 評價指標
實驗中采用3個評價指標來衡量車道線檢測算法的 性 能,分 別 是 精 確 度(precision)、召 回 率(recall)、F1度量(F1-measure)。其中,精確度表示正確預測為真的正樣本占全部預測為真的樣本的比例,即正確檢測為道路的像素占全部檢測為道路像素的百分比;召回率表示正確預測為真的正樣本占全部正樣本的比例,即正確檢測為道路的像素占全部道路像素的百分比;F1-measure作為綜合指標,是精確率和召回率的加權調和平均,受平衡準確率和召回率的影響。其計算公式如下:

同時,針對VOC數據集的語義分割性能評估,以mIoU的值作為評價指標,來說明MAD方法對語義分割任務性能的提升。分別計算每個類別的IoU(Intersection over Union)值再求平均來計算。評估過程還包括整體準確度(Acc)、分類準確度(Acc_class)和帶權重交并比(fwavacc)。
3.3 ERFNet
為驗證MAD方法的有效性,進行了對比試驗。以ERFNet網絡為baseline,使用MAD多級注意力蒸餾進行優化,設置僅使用第一級蒸餾損失優化作為單級注意力蒸餾(SAD)方法作為對比試驗。使用SGD優化器,學習率為5e-2;在訓練階段使用了預訓練權重,對模型訓練了12個epoch;設置batch_size為12,共優化88K次迭代數。通過在數據集CULane上進行訓練,并使用CULane的驗證集對9個場景任務進行測試,分別計算出3個指標值,并結合訓練過程的驗證信息進行綜合評價。
針對不同類別的測試結果,進行了詳細的實驗結果分析。在表1、表2中,對比了在不使用優化方法下模型訓練后的測試結果(baselines),與使用單級(SAD)、多級(MAD)注意力不同蒸餾權重β={100,200}的結果。
見表1,針對9種類別場景中的車道線分割任務,無論是基于單級(SAD)還是多級(MAD)注意力蒸餾的結果,均較原始網絡有了明顯的提升。根據表2所展示綜合評價結果,在不同的權重因子下,通過比較兩種方法可以發現,多級(MAD)蒸餾優化都要高于單級(SAD)蒸餾優化。同時,本實驗可視化了單級(SAD)、多級(MAD)注意力蒸餾優化方法的驗證結果與不同蒸餾權重的對比結果(β={10,50,100,200,500}),如圖5所示。

圖5 對比結果Fig.5 Comparison results

表1 基于單級(SAD)、多級(MAD)注意力蒸餾的9種場景結果Tab.1 Results of 9 scenarios based on single level(SAD)and multi-level(MAD)attention distillation

表2 基于單級(SAD)、多級(MAD)注意力蒸餾的綜合評價結果Tab.2 Comprehensive evaluation results based on single level(SAD)and multi-level(MAD)attention distillation
圖5(a)為β=200的訓練過程評估。在隨機初始化后,以同樣的參數訓練5個epoch,在第6個epoch時引入優化方法。圖中可以證明,在第6個循環周期(epoch)后,多級(藍線)方法始終優于單級(紅線)。圖5(b)所示為本文探索不同權重因子的兩種蒸餾優化結果對比。從圖中可以看出,不同權重因子下多級(藍色)方法較單級(紅色)方法仍有明顯的優勢。
圖6所示為β=200的訓練過程損失曲線。在實驗中,設置第6個循環周期(epoch)后加入優化。MAD優化方法在不同級別的蒸餾分支中,加入之前模型收斂速度慢,加入之后實現快速的收斂。相對整體的模型收斂狀態,并不會產生震蕩的后果。具體測試結果如圖7所示。

圖6 各級蒸餾損失函數Fig.6 Distillation loss function of each stage

圖7 ERFNet的檢測結果Fig.7 ERFNet predict results
3.4 DeepLab_V3
為探索多級自適應蒸餾學習(MAD)的普適性,即是否可以應用于多種類別的分割任務,本文將實驗擴展為基于DeepLab_V3網絡在VOC2012數據集上訓練20類別的語義分割實驗。使用DeepLab_V3為基礎網絡,將網絡特征提取部分分為4個單元,在PASCL VOC上訓練了200個循環,在訓練80次循環后加入MAD模塊。batch_size=16,學習率為0.01。實驗訓練結果見表3,驗證結果見表4。

表3 DeepLab_V3在VOC2012數據集上的訓練結果Tab.3 Training results of Deeplab_V3 on VOC2012 datasets

表4 DeepLab_V3在VOC2012數據集上的測試結果Tab.4 Testing results of Deeplab_V3 on VOC2012 datasets
根據表3、表4中結果可以看出,MAD方法針對20類別的語義分割具有明顯的提升效果。其中Acc為整體準確度,Acc_class為分類準確度,fwavacc為帶權重交并比。在訓練集mIoU指標中MAD方法在原網絡的基礎上提升0.4,在驗證集mIoU指標中本文方法提升1.5。
4 結束語
本文提出了一種多級注意力蒸餾學習方法(MAD),以自身網絡的淺層特征學習高層特征的表達。實驗證明,該方法可普遍提高網絡中不同層次的視覺注意力,使ERFNet在CULane任務的F1-measure指標提升2.13,DeepLab_V3在VOC2012任務的mIoU指標提升1.5,在提升網絡特征提取能力方面具有重要意義。
選擇合適的不同層級之間的權重,對訓練時間與收斂具有一定影響,在后續的工作中,可以考慮探究每個蒸餾級別中不同層之間的權重,從而實現模型收斂性能的提高。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
