Tri-net 半監督輻射源個體識別方法*
2021-10-03 04:12:48呂昊遠
通信技術 2021年9期
呂昊遠,俞 璐
(陸軍工程大學,江蘇 南京,210007)
0 引言
通信輻射源個體識別技術通過獲取到的輻射源信號樣本,檢測由于輻射源個體不同而導致的細微特征差異,提取所需的反映輻射源目標身份的信息,從而準確區分輻射源個體,針對性地把握目標屬性特征,并實施有效的監控。該技術在通信網絡結構分析和電子設備管制等方面發揮著巨大作用[1]。
深度學習具有強大表征能力,在多個領域中得以快速發展和應用,也為通信輻射源個體識別問題開辟了新的研究道路,即無需任何先驗知識的深度網絡可以直接在一個整體框架內端到端地對獲取的信號樣本進行特征提取和分類識別[2]。基于深度學習的通信輻射源個體識別方法不僅大大節約了科研成本,還有效地提升了識別準確率;因此,吸引了眾多科研人員的關注。但通信方式在多數情況下都是非合作的,所以實際的電磁環境中存在少量的有標簽信號樣本和大量的無標簽信號樣本,這嚴重阻礙了有監督深度學習個體識別方法的發展[3]。如何根據現有的信號數據研究出基于深度框架的半監督個體識別方法就顯得尤為重要。
偽標簽半監督通信輻射源個體識別方法在面對“小樣本”問題時取得了一定的效果,但此方法中深度模型性能會受偽標簽質量的影響而產生較大波動。本文提出基于協同訓練Tri-net 的半監督通信輻射源個體識別方法,增加深度網絡數目,并采取輪次標簽的偽標簽賦值有效提升信號樣本偽標簽的質量。實驗中在實際采集的通用軟件無線電外設(Universal Software Radio Peripheral,USRP)通信輻射源信號數據集上進行驗證,并和全監督方法、單一的偽標簽半監督方法以及改進前的Tri-net 半監督方法對比。實驗結果表明本文方法具有更高的識別準確率和更強的魯棒性。
1 協同訓練
協同訓練作為一種半監督訓練方法,可以有效緩解由于有標簽樣本數目過少帶來的網絡過擬合問題。本節內容介紹了協同訓練中多視圖學習的概念和Tri-net 模型的算法過程。
1.1 多視圖學習
作為協同訓練的前提思想,面對大量的無標記樣本時,多視圖學習假設可以從不同的視覺角度對每個數據進行學習[4],然后根據從不同角度訓練出的深度網絡再對無標記樣本進行分類,挑選出高置信度的無標記樣本以及其偽標簽作為新的有標簽樣本加入訓練集中[5]。協同訓練的目標就是學習獨特的預測函數為各個視圖下的數據建模,并共同優化所有用于提高泛化性能的功能,不同視圖的結果相互補充,達到不同網絡可以相互協作以提高彼此的性能[6]。
1.2 Tri-net
Tri-net 是一種擴展的協同訓練模型,它從3 個分類網絡的角度對樣本進行協同訓練,模型的訓練過程如圖1 所示。整個模型中網絡架構分為兩部分,其中共享模塊(Shared Module)為底層部分,3 個獨立個性模塊(Module1,Module2,Module3)為高層部分[7]。

圖1 Tri-net 模型訓練過程
Tri-net 在半監督協同訓練過程中,首先,對有標簽信號樣本進行隨機加噪,獲得3 個有標簽訓練集,通過對少量有標簽信號樣本預訓練從每個訓練集產生一個分類網絡;其次,每個網絡分別對無標簽信號樣本預測其標簽值,如果其中兩個網絡對同一個無標記信號樣本的預測標簽值相同,則該樣本及其偽標簽就被認為具有較高的標簽置信度,并作為有標簽樣本加入第3 個網絡的訓練集[8]。由此可見,Tri-net 中每個網絡所獲得新的有標簽信號樣本都由另外兩個網絡協作提供。
2 Tri-net 半監督個體識別方法
本文提出Tri-net 半監督通信輻射源個體識別方法,并且為提高偽標簽的質量而改進算法的訓練過程,在偽標簽賦值中加入加權平均的輪次標簽法。
如圖2 所示,Tri-net 半監督輻射源個體識別方法包括3 個步驟。
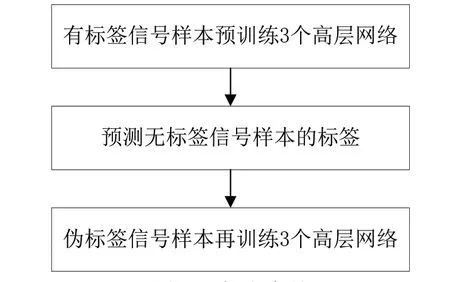
圖2 方法步驟
偽標簽賦值過程中使用加權平均的輪次標簽法,其中每個訓練周期迭代結束后得到的偽標簽是之前所有訓練周期得到預測值的加權平均和[9]。
網絡訓練前初始化設置Z=0[N×C]、=0[N×C],分別表示每個訓練周期的標簽預測值和最終經過輪次標簽法后得到的標簽預測值,其中:N表示樣本數目,C表示類別數(標簽采取one-hot 向量編碼)。標簽預測值的迭代計算方式為:

式中:t為訓練迭代周期數;B為每次迭代過程中的小批次信號樣本集;i是小批次中的每個信號樣本;j為3 個高層網絡的編號。
每個訓練周期結束后計算所有周期預測值的加權平均結果,計算方式為:

式中:α表示加權平均的平衡系數。為了避免訓練初期網絡的錯誤預測,就需要減弱初期的標簽影響力,所以在加權平均后通過偏差校正得到最終的本輪次標簽值。
在進行有標簽信號樣本初始化訓練Tri-net 前,通過在有標簽信號樣本中添加隨機噪聲為3 個高層網絡分別構建訓練集,使得高層網絡多樣化,從而代表了不同的視圖學習。為了防止網絡訓練趨于一致化,無標簽信號樣本訓練過程中,每3 個輪次為訓練集中的信號樣本添加隨機噪聲,繼續增強多樣化,結合原本Tri-net 模型中的多網絡投票機制,由此,Tri-net 半監督算法在增強偽標簽樣本的穩定度和可靠性方面發揮出了作用。
網絡訓練過程中,xl為無標簽信號樣本,表示其在每個高層網絡對應的偽標簽,Ly為交叉熵損失函數。將3 個高層網絡的損失值相加并取平均構建出的半監督總體訓練損失函數為:
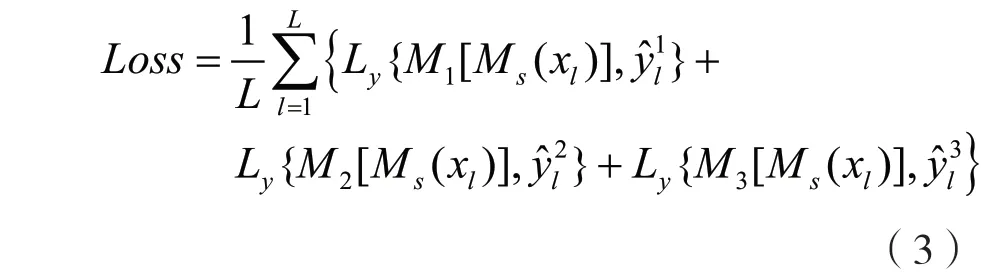
圖3 展示了Tri-net 半監督輻射源個體識別方法具體算法過程。
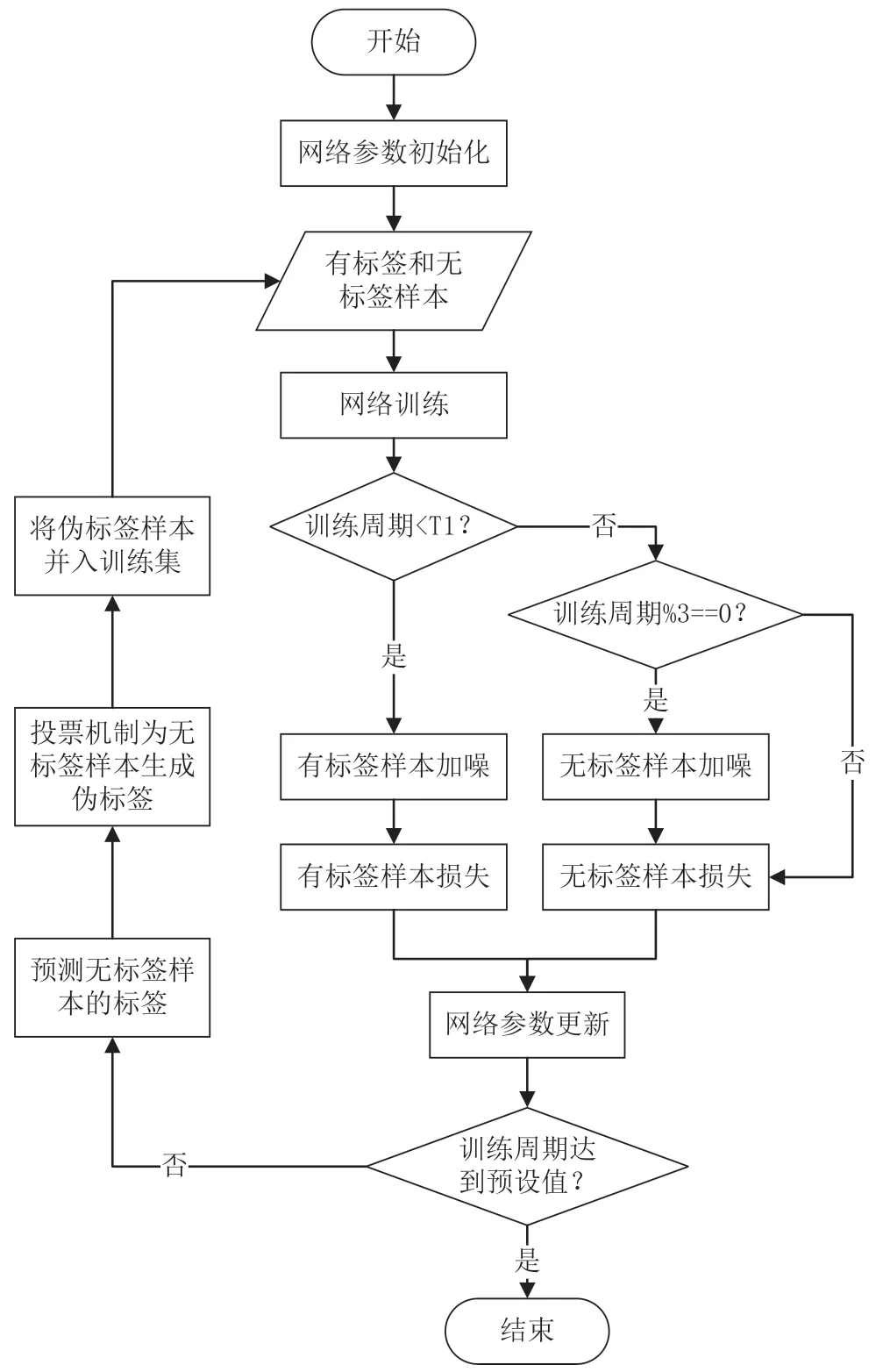
圖3 Tri-net 半監督算法過程
3 實驗與分析
3.1 樣本集準備
如圖4 所示,樣本集的準備工作包括前后3 個環節。

圖4 樣本集準備過程
實驗中使用LabVIEW 軟件平臺設計信號收發的程序,基于此,搭建采集環境,調整采樣參數,完成信號的發射與接收[11]。實際采集到5 臺USRP N210 通信設備的信號數據。在接收端經過解調得到同向、正交(In-phase、Quadrature,IQ)兩路載波信號數據后進行預處理操作,具體包括采用數據清洗的方式去除采樣初始階段幀間切換時產生的不穩定暫態信息,進行功率歸一化的比例變換。得到信號樣本的形式為二維數組,其中數組寬度為2 表示IQ 兩路載波數據,數組長度設置 為128。
對于5 臺USRP 輻射源通信設備,將輻射源個體進行類別編號,即所有的信號樣本設置5 類標簽值,接著將樣本集按照一定比例分為訓練集和測試集,其中訓練集中包括有標簽信號樣本和無標簽信號樣本兩部分,最終完成樣本集的構建。
本文實驗的硬件條件為i7 10870H 的CPU 和RTX 2070 Max-Q 的GPU,軟件條件為PyCharm+Anaconda(2020.02)+PyTorch(1.7.1)的開發環境。
3.2 網絡結構設計
本節根據實際的深度網絡需求關系,設計出適合于本文使用的USRP 信號樣本的Tri-net 網絡結構。MS、M1、M2、M3具體的網絡結構組成如表1 所示。

表1 不同網絡的結構組成
其中,MS包括一個卷積層,卷積核大小為(1×3);M1包括一個卷積層和兩個全連接層,卷積核大小為(2×3);M2包括兩個全連接層;M3包括兩個卷積層和兩個全連接層,卷積核大小為(1×1)和(1×3)。每次卷積或者全連接操作之后都有dropout 正則防止訓練過擬合,設置其參數值為0.3,每個高層網絡最后都連接softmax 分類層。實驗中選用Adam 優化器和交叉熵損失函數。
3.3 結果分析
實驗中將加入輪次標簽的Tri-net 半監督個體識別方法與全監督個體識別方法、單一的偽標簽半監督方法以及改進前的Tri-net 半監督個體識別方法進行對比。在包含900 個信號樣本的測試集上進行實驗,訓練集中設置不同的有標簽信號樣本數與無標簽信號樣本數的比例大小,通過100 次蒙特卡洛實驗得出4 種方法的識別準確率。表2 和表3 分別展示了當有1 000 和2 000 個標簽樣本數時,4 種方法的識別準確率,其中,帶*為加入輪次標簽的Tri-net 半監督個體識別方法。
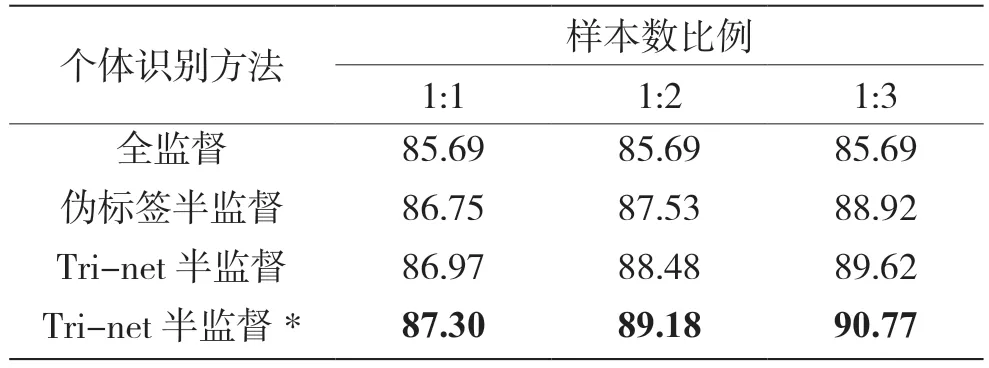
表2 識別準確率(1 000 個有標簽樣本) %
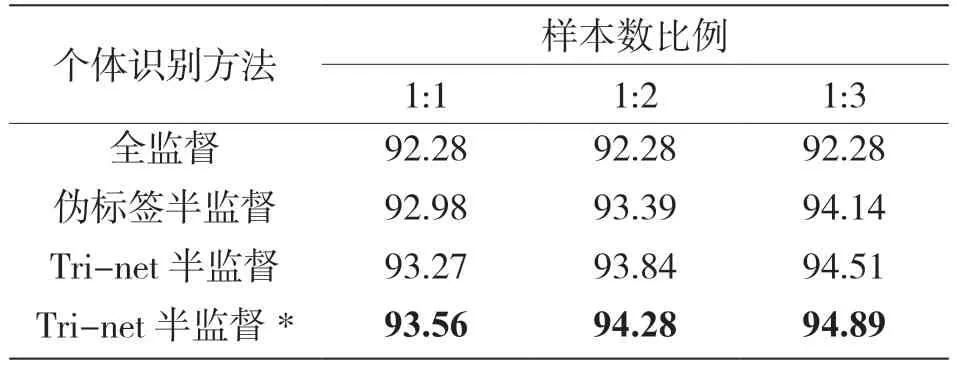
表3 識別準確率(2 000 個有標簽樣本) %
現對表中的一些數值進行解釋并分析。因為全監督方法不使用無標簽信號樣本,所以改變樣本數比例大小其識別準確率值不變;在一定范圍內增大無標簽信號樣本數的比例,半監督方法的識別準確率有所提升;相比之下Tri-net 半監督個體識別方法的效果更好。Tri-net 模型為無標簽信號樣本賦予了偽標簽,對作為訓練數據的有標簽信號樣本起到了擴充作用。此外,3 個網絡的協同訓練選擇高置信度的偽標簽信號樣本,也有效地避免了錯誤偽標簽對于網絡訓練的干擾,而加入輪次標簽之后達到了最好的性能表現,這是因為輪次標簽可以平滑掉訓練初始階段網絡的錯誤預測,增強模型對于錯誤預測的容忍,有效增強偽標簽的質量,最終加強Tri-net 模型的魯棒性。
比較表2 和表3 中的數據可以看出,表2 中添加輪次標簽的Tri-net 半監督方法相比于全監督方法的性能提升更為明顯。這也說明了Tri-net 半監督方法在標簽信號樣本數目較少的情況下性能提升更明顯。
在固定有標簽與無標簽的信號樣本數比例為1:3,分別計算標簽信號樣本數目為1 000 和2 000 個情況下,得到添加輪次標簽后Tri-net 半監督方法在測試集上的識別準確率的混淆矩陣,如圖5 和圖6 所示。

圖5 有標簽樣本數為1 000 的混淆矩陣
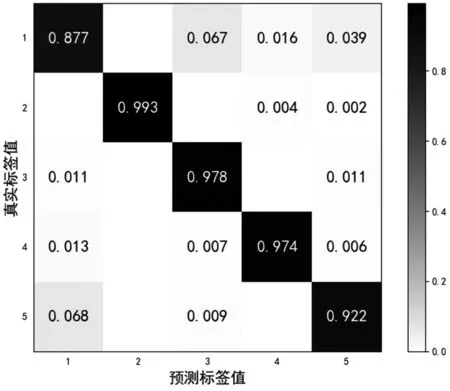
圖6 有標簽樣本數為2 000 的混淆矩陣
其中矩陣方格中的數值表示識別準確率,通過顏色深度可以更清晰地反映識別結果。對角線上的數值表示識別正確的概率,根據圖中數值看出第2個輻射源的類內聚集度最好,與其他輻射源的區別較大,即使當有標簽信號樣本數目較少時,也能達到很高的識別準確率。相比之下,第1 個輻射源識與其他輻射源的差別較小,有一定的區分難度,識別準確率最低。
由于相似的通信輻射源調制方式識別問題的數據集中經常設置樣本長度為128,因此,本文也借鑒這種設置方法。為探究樣本長度對實驗結果的影響,分別設置1 000 和2 000 個有標簽信號樣本,且無標簽信號樣本數目是有標簽樣本數目的3 倍,測試在不同樣本長度下添加輪次標簽前后Tri-net 半監督方法在測試集上的識別準確率,實驗結果如圖7 所示。實驗結果表明,較短的樣本長度劃分會割裂信號樣本的連續性,不利于特征提取,導致識別準確率較低;但隨著樣本長度的增加,在128 時識別準確率達到穩定。然而,長度繼續增長,識別率不會有明顯提升甚至有所降低,并且會伴隨著訓練時間增加,訓練過擬合泛化能力減弱,所以128 的樣本長度是最好的設置方式。
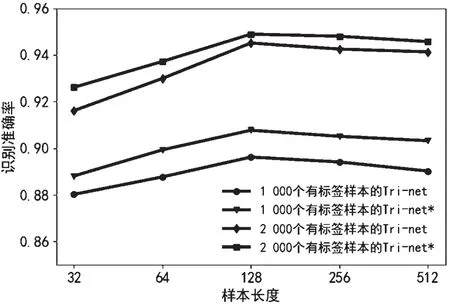
圖7 不同樣本長度下模型識別準確率
4 結語
深度學習方法在通信輻射源個體識別問題中經常面臨有標簽信號樣本數目不足而導致模型性能下降狀況,因此,本文提出了基于Tri-net 的半監督個體識別方法,介紹了協同訓練中多視圖學習的概念以及Tri-net 模型結構和訓練過程,并加入了輪次標簽進行方法改進。
實驗階段通過采集信號數據、預處理信號數據和劃分樣本集完成樣本的準備,并根據信號樣本的具體形式完成Tri-net中深度網絡的參數設置。然后,比較分析了添加輪次標簽前后Tri-net 半監督方法和全監督方法、偽標簽半監督方法在測試集上的識別準確率。實驗結果表明,添加輪次標簽的Tri-net半監督方法的識別性能明顯提升,當有標簽信號樣本數為1 000 和2 000,所占樣本總數的四分之一時,分別得到90.77%和94.89%的最高識別準確率。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
人大建設(2020年4期)2020-09-21 03:39:12
中國生殖健康(2019年3期)2019-02-01 06:12:26
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
浙江人大(2014年5期)2014-03-20 16:20:28
浙江人大(2014年4期)2014-03-20 16:20:16
