基于機器學習的圍巖無側限抗壓強度預測困境
2021-09-30 08:52:04盛永清褚長海
建筑機械化 2021年9期
江 南,盛永清,褚長海
(1.盾構及掘進國家重點實驗室,河南 鄭州 450001;2.武漢地鐵集團有限公司,湖北 武漢 430000)
隨著國民經濟的快速發展,地鐵隧道,鐵路隧道更多地采用了隧道掘進機進行開挖。隧道開挖前,對施工隧道地區資料的獲取是必不可少的環節,結合地質資料,才能根據開挖隧道地層情況調節相應的掘進參數進行施工作業,但在實際施工中,地質情況復雜多變,地質資料只能提供局部區域有限地質情況,而實時監測和分析開挖面的地質情況可以幫助司機在不利地質條件下采取預防措施,保證安全高效掘進。由于掘進參數可以看作是圍巖與TBM 相互作用結果的動態反映,當前有許多利用掘進參數預測圍巖性質的工作。朱夢琦等提出基于集成CART 算法的圍巖等級預測模型,利用TBM 掘進過程中的參數預測圍巖等級并取得了較好的效果。張娜等分別采用分步回歸和聚類分析的方法建立巖機關系模型,該模型能利用監測 TBM 掘進參數對巖石抗壓強度、體積節理數和圍巖等級等參數進行實時感知。總體來說目前基于各種機器學習算法的圍巖性質預測工作均取得了一定的進展,但是預測模型通常在同一條線路上構建和測試,缺乏模型應用在其他線路的準確率數據而對于TBM 施工真正有效的模型是能運用在新施工線路的模型,這一情況阻礙了圍巖地質判別模型的實際應用與推廣。
1 工程項目與設備概況
青島地鐵1 號線是青島已經投入使用的一條跨海線路,其全長60.11km,總體大致呈南北走向,共設置41 座車站,全部為地下車站。
本文使用的數據為青島地鐵1 號線人民廣場站-衡山路站和衡山路-天目山站兩個區間的TBM 掘進數據,兩個區間內的圍巖主要成分為閃長巖,石英二長巖,花崗斑巖,風化程度為微風化到中風化。兩個區間使用的掘進設備分別為中船重工生產的DS6290-TBM-015 和DS6290--TBM-016。TBM 運行時數據每10s 采集一次,數據中心記錄了TBM 掘進過程中總推進力、刀盤扭矩、刀盤轉速、推進速度和撐靴壓力在內的195 類數據。
2 算法描述
本文使用神經網絡,隨機森林,支持向量機3 種機器學習模型分別對圍巖無側限抗壓強度進行預測,并比較不同算法的優勢,探究不同模型在跨線路應用上的性能優劣。
2.1 神經網絡算法
基于深度神經網絡的分類算法已經在自然語言處理,數字圖像處理,數據挖掘等任務和應用場景上取得了優良的效果,顯示出深度神經網絡的在大數據應用上巨大潛力。本文構造的神經網絡先對輸入按字段分別進行全連接,然后總體全連接的方式構建神經網絡,具體網絡結構如圖1所示。
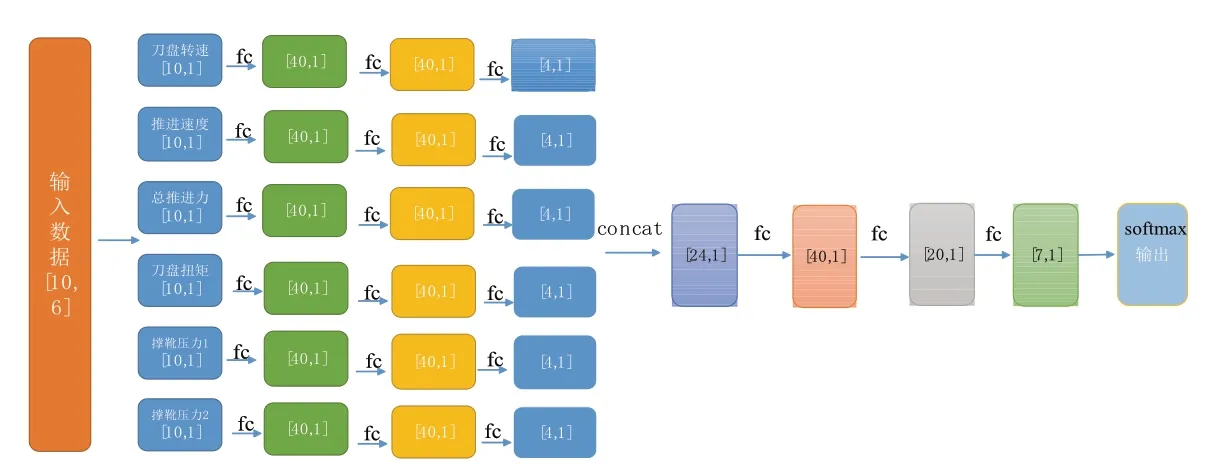
圖1 模型結構圖
其中,fc 表示全連接過程,concat 表示維度拼接過程,數字代表向量維度。本文使用先分組全連接,再進行融合全連接的方式相比于直接在整個輸入向量上做全連接操作的方式參數量和計算量均有一定的減小。
2.2 隨機森林算法
隨機森林就是通過集成學習的思想將多棵樹集成的一種算法,它的基本單元是決策樹,屬于機器學習的集成學習方法。在隨機森林中,每棵決策樹都是一個分類器,對于一個輸入樣本,每課樹都會產生一個分類結果。而隨機森林集成了所有的分類投票結果,將投票次數最多的類別指定為最終的輸出。在節點特征變量選擇上,本文使用Gini 不純度作為決策指標,避免了信息增益易偏向于取值較多的屬性的問題。
設數據集D={(x1,y1),(x2,y2),…,(xn,yn)}的屬性空間X?Rm中某一特征變量Xj,j=1,2,…,m有q個取值,則Gini不純度定義如下
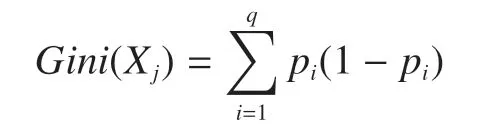
式中pi——特征變量值為i的概率。
2.3 支持向量機算法
本文將圍巖的無側限抗壓強度分成了7 個類別,屬于多分類問題,而標準的SVM 是基于二元分類問題設計的算法,無法直接處理多分類問題。利用標準SVM 的計算流程有序地構建多個決策邊界以實現樣本的多分類,通常的實現為“一對多(one-against-all)”和“一對一(oneagainst-one)”。一對多SVM 對m 個分類建立m個決策邊界,每個決策邊界判定一個分類對其余所有分類的歸屬;一對多SVM 通過對標準SVM的優化問題進行修改可以實現一次迭代計算所有決策邊界。
3 圍巖無側限抗壓強度模型
3.1 開發環境及超參數設置
本文使用的軟硬件環境如表1 所示。
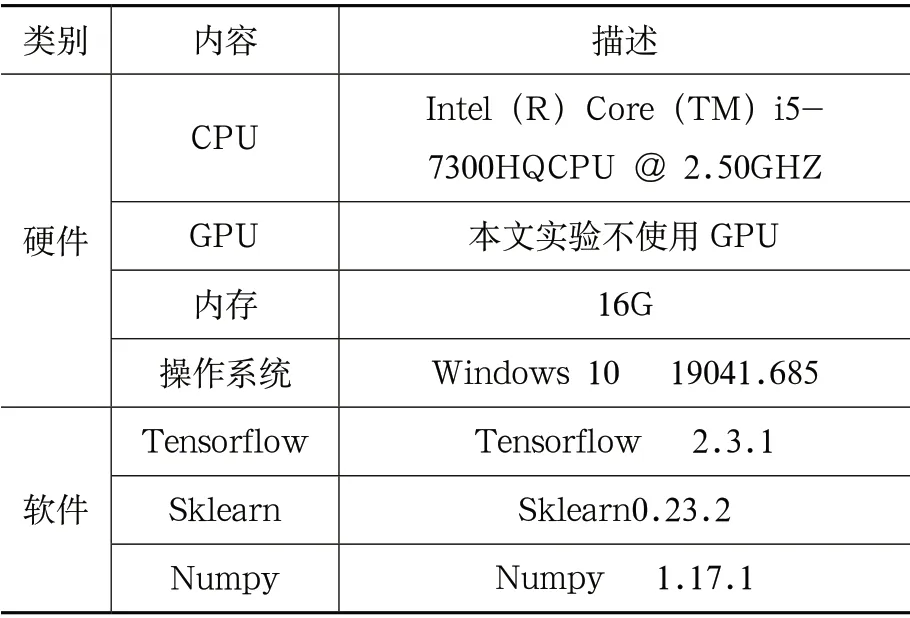
表1 模型使用硬件與軟件版本情況
3.2 模型評價指標
為了檢驗本文所提出算法有效性,本文采用正確率為評價指標,計算如下
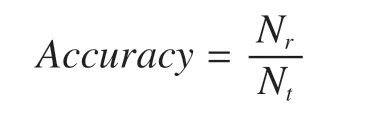
式中Nr——無側限抗壓輕度預測正確的樣本數;
Nt——無側限抗壓強度預測的總樣本數。
3.3 模型跨區間驗證
目前基于TBM 掘進參數的圍巖地質判別模型往往在同一條線路上訓練與測試,缺乏跨區間的模型研究與應用。本文使用3 種不同的機器學習算法對跨區間的模型研究與應用開展研究,如表2 所示。表2 的結果表明基于掘進參數的地質無側限抗壓強度的跨區間應用價值較低。
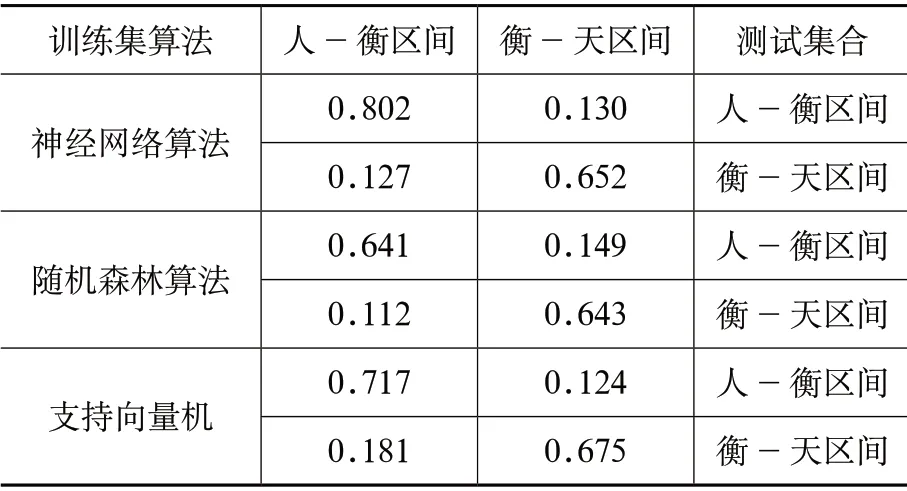
表2 模型在不同區間上的準確率
盡管基于掘進參數的圍巖抗壓強度預測模型在同一區間上達到了一定準確率,但想要將模型推廣到不同區間,則難以達到足以指導TBM 掘進工作的準確率。3 種不同的機器學習模型都出現了同樣的情況。原因在于本文選取的青島地鐵兩個區間雖然相鄰,但圍巖分布狀況仍然存在較大差異,這種地質上的差異造成掘進數據的差異,最終影響了模型的跨區間應用。這種模型跨區間應用能力弱的問題不能簡單歸于過擬合問題,因為模型準確率在訓練集和測試集差異較小,只在跨區間應用時準確率下降。
4 結論
本文分別使用了分組的全連接神經網絡算法、隨機森林算法、支持向量機算法構建圍巖的實時抗壓強度預測模型,并研究模型的跨線路,跨區間應用問題。有如下結論。
1)幾組實驗下的神經網絡模型表現對比隨機森林或支持向量機算法無明顯優勢。
2)本文構建的圍巖的無側限抗壓強度的預測模型僅在本區間能取得較好的預測準確率,難以跨區間使用。
綜上所述,基于機器學習模型的圍巖無側線抗壓強度預測模型目前是難以應用在不同區間,問題主要在于,未掘進區間的地質分布和掘進過區間的地質分布可能完全不同,即使這兩個區間相鄰,模型可能完全沒有訓練過這種地質,判別自然失準。在更長掘進線路上訓練模型是有可能會持續提升模型判別精度,但此時掘進機設計壽命也即將結束,模型的應用價值降低。研究人員不應僅僅滿足于追求預測模型在某一條線路上的預測準確率,畢竟能在不同地理位置、不同地質狀況的均取得較高預測準確度的模型才具有實際工程應用價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華建設(2019年12期)2019-12-31 06:47:58
江西建材(2018年4期)2018-04-10 12:37:22
光學精密工程(2016年6期)2016-11-07 09:07:19
煤炭學報(2015年10期)2015-12-21 01:55:09
山西煤炭(2015年4期)2015-12-20 11:36:18
江西煤炭科技(2015年1期)2015-11-07 03:06:32
核科學與工程(2015年4期)2015-09-26 11:59:03
