基于強化學習的組合優化綜述
2021-09-28 11:23:08顧一凡
軟件導刊 2021年9期
顧一凡
(南京航空航天大學計算機科學與技術學院,江蘇南京 210016)
0 引言
優化問題的主要重點在于在不同可能性中尋找當前問題的最優解或最佳配置。這一類問題通常被分成兩種:具有連續變量的問題和具有離散變量的問題[1]。例如:在凸優化問題中的一個可行解通常屬于實數空間,這樣的解被稱為一個連續優化的可行解,而查找一系列城市的游覽路徑則是離散的優化問題。一般而言,在離散空間中查找解的問題被稱為組合優化(CO)問題。
當前RL 與CO 結合有兩種不同方式:主體學習與聯合學習方式。主體學習方式可通過智能體直接作出決定,該方法直接通過RL 策略構造問題的解或完整解的一部分,而不需要求解器的反饋。例如,在TSP 問題中,神經網絡首先對智能體進行參數化處理,然后該神經網絡逐步構建路徑,將路徑長度作為獎勵來更新策略。聯合學習方式則是與現存的求解器聯合訓練RL,使其可提升CO 問題的解在不同性能度量指標上的表現。例如,在混合整數線性方程(Mixed-Integer Linear Program,MILP)中,常用方法是“分支限界”,其在每一步都選擇樹子節點的分支規則,該方法可能會對樹的整體大小及算法運行時間產生影響。另外,分支限界屬于啟發式方法,需要一些專家知識對參數進行調整。值得注意的是,可通過RL 智能體接收與運行時間成正比的獎勵訓練智能體學習節點選擇策略。
通常來說,使用RL 解決CO 問題可看作是學習解決此類問題的策略,而不是使用運籌學中人為設定的方法,在該層次上可將其分為學習構造啟發式以及改進啟發式方法。學習構造啟發式方法通過學習策略不斷構造解,而改進啟發式方法則是學習一種基于迭代的改進策略,該方法試圖解決在啟發式學習中遇到的一些問題,即需要使用一些額外過程以找到良好的解決方案,例如采樣等。
1 相關基礎知識
1.1 組合優化問題
首先給出關于組合優化問題的基本定義:
定義1(組合優化問題):假設Ω 是解的決策域,且F:Ω →R是一個決策域到目標域映射的目標函數。組合優化問題旨于找到目標域上的最優值,以及找到該最優值在決策域Ω 上對應解的結構。
通常來說,組合優化問題的決策域Ω 是有限的,且存在局部最優解,可通過比較所有可行解得到。但是,現實中的組合優化問題一般都是NP 難問題,找到一個最優解往往需要較高的時間成本,因此傳統方法是在一定時間內找到一個折中的解。
下面主要介紹使用RL 解決的一些特殊的組合優化問題,這些問題在現實中有著廣泛應用,例如最大分割問題、旅行商問題、財務投資組合管理問題等。
定義2(最大切割問題):給定一個圖G=(V,E),找到一個點集的子集S?V,且該子集最大化分割C(S,G)=∑i∈S,j∈VSwi,j,其中wi,j∈W是連接頂點i與邊j的權重。
定義3(旅行商問題(TSP)):給定一個完整的加權圖G=(V,E),其目標是找到一個最小權重的路徑,使得每個城市只被訪問一遍。
定義4(最大獨立集(MIS)):給定一個圖G=(V,E),找到一個點集的子集S?V,使S中沒有兩個頂點通過E的邊相連,且最小化目標為|S|。
1.2 強化學習
一般來說,RL 智能體通過馬爾可夫決策過程(MDP)指導智能體在環境中進行動作[2],并通過收集相關獎勵來更新模型。環境由狀態集合S 中的狀態組成,狀態集S 可以是離散的,也可以是連續的。智能體所有可能執行的動作都在動作集合A 中,智能體的主要目標是通過執行動作增加獲得的獎勵值R。從S 中每個狀態s 到最佳動作a 的映射函數被稱為策略,表示為π(s)。因此,為解決MDP 問題,需要找到最佳策略π*以最大化預期獎勵:
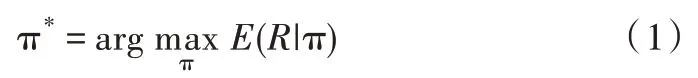
其中,獎勵值可表示為:

智能體在經過N 步之后重啟,如果N 趨向于∞,則表示智能體以一種無回合的形式進行訓練。一般來說,γ 體現智能體關注短期獎勵的程度,當γ<1 時,其會阻止累計獎勵被無限放大。
2 強化學習應用于組合優化分類
在過去幾十年中,科學家們研究了解決CO 問題的各種可能方法,因此也提出了許多CO 求解算法,包括基于機器學習的方法等。如文獻[3]從機器學習的角度總結了解決CO 問題的方法,并列出了幾個有效算法;文獻[4]致力于描述圖神經網絡(GNN)及其在CO 問題上的可能應用;文獻[5]通過調查研究,介紹了使用機器學習(ML)方法解決CO 問題的最新研究成果。
本文僅專注于使用RL 解決CO 問題,以下主要從兩個方向對RL 解決CO 問題的相關研究進行分類:①基于值函數的RL 方法;②基于策略的RL 方法,具體對應成果如表1所示。對于每一種方法,以下章節會進行詳細介紹,并給出相關工作的不足及需要改進的方向。
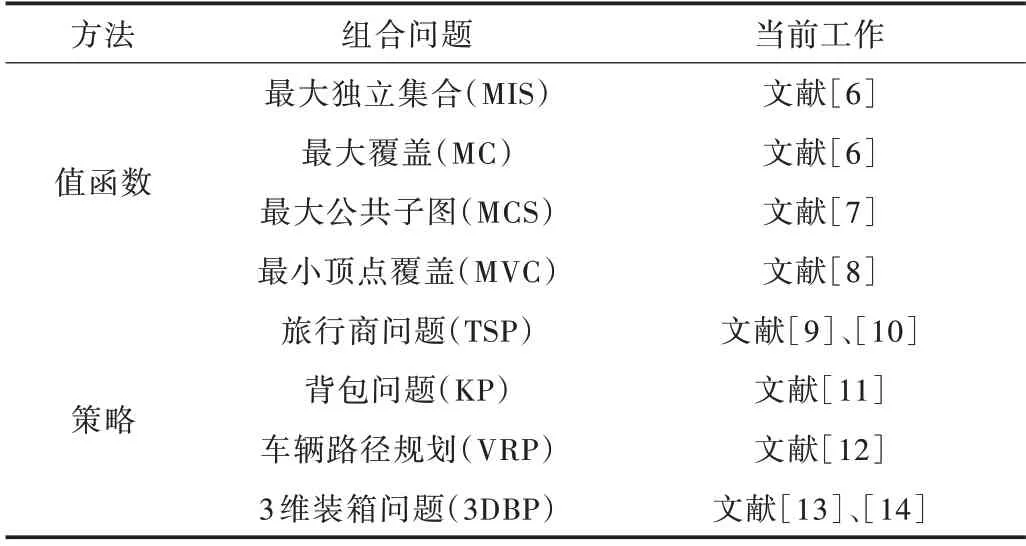
Table 1 RL methods for solving CO problems(value function,strategy)表1 用于解決CO 問題的RL 方法(值函數、策略)
3 強化學習應用于組合優化的方法
3.1 基于值函數的方法
Q-learning[15]是一個典型的基于值函數的RL 方法,但對于大部分實際問題而言,要找到最優解十分困難。NP 難問題因其對應的RL 狀態與動作空間連續或過大,使得傳統RL 方法無法得到有效使用。隨著深度學習的崛起,證明神經網絡(NN)對于高維輸入數據可以學習出有效的函數逼近方式,從而促進了深度Q 網絡(DQN)的發展[16]。由于結合了神經網絡(NN)與Q 學習的優點,DQN 已成為目前解決許多強化學習問題最受歡迎的方法之一。
對于大多數問題,如最大分割[17]、TSP 問題[18]等,現有研究使用了與DQN 相同的Q 值更新公式,即使用圖形嵌入網絡對Q 函數進行參數化。文獻[17]中使用圖注意力網絡[19]與一種transformer 結構[20]對CO 問題進行編碼;文獻[18]使用了structure2vec 圖神經網絡,這也是一種流行的圖編碼技術。
文獻[18]旨在解決TSP 問題,其主要通過DQN 學習良好的啟發式策略,然后將其直接集成到各種基于約束的算法中,如分支限界以及迭代的差分搜索等。在訓練中,從某些分布中隨機抽取測試用例Qi,計算其獎勵值函數為其中,UB(Qi)表示Qi在值函數中的上界,c 表示成本,ρ是一個比例因子。
最近有一些研究專注于解決最大公共子圖問題[7],其構建了一種聯合子圖節點的新型嵌入網絡,以便使用單個網絡嵌入兩個圖,網絡權重更新方法與DQN 一致。
上述工作都會遇到一個與DQN 共同的問題,即DQN依次構造最優解使得算法不能重新考慮次優解。為解決該問題,對DQN 的訓練過程進行了修改,形成了另外一組解決CO 問題的RL 方法[8],其使用在分類領域很受歡迎的協同訓練方法構建CO 問題的順序策略。本文介紹了針對最小頂點覆蓋問題的兩種策略學習方法:第一種方法復制文獻[18]中描述的策略,第二種方法利用分支限定法解決整數線性規劃問題。通過創建一種與模仿學習[21]相似的算法,根據兩種策略之間的信息交互識別出哪種方法更具有優勢,以此開展更新過程。
3.2 基于策略的方法
文獻[11]進行了將策略梯度算法應用于組合優化的首次嘗試,即使用有學習基線的強化學習算法解決TSP 與背包問題。文獻[22]提出指針網絡體系結構作為編碼的輸入網絡,該方法使用解碼器的指針機制,根據輸入的分布順序構造CO 問題的可行解,類似于文獻[23]的異步并行訓練。
文獻[11]中提出的方法由于其動態性質不能直接應用于車輛路徑規劃問題(VRP),即節點一旦被訪問,該節點則不能再次被訪問。文獻[12]對文獻[11]的方法進行拓展以找到VRP 的可行解。具體來說,其通過使用一維的卷積嵌入層替換LSTM 單元來簡化編碼器,從而使模型對輸入不敏感,因此不同的輸入順序不會影響模型性能,之后使 用RL 對TSP 與VRP 進行策略學習,而A3C[23]中使用隨機VRP 進行策略學習。
另一個重要的CO 問題是3D 裝箱問題。文獻[13]使用RL 方法制定策略,該策略代表物品的最佳包裝順序。在提供的入庫商品序列特征上進行算法訓練,通過計算包裝商品的表面積評估生成的策略,其中使用啟發式算法生成的結果作為訓練基準。為了進行推斷,使用貪婪的解碼方式以及一種通過波束搜索的方法進行采樣。文獻[14]將該方法進一步拓展到監督學習方向,采用RL 與監督學習相結合的方法。文獻[24]提出一種條件查詢學習(CQL)方法,使用注意機制調節裝箱過程中需要執行的3 個子動作,即盒子的選擇、旋轉與定位。
文獻[25]通過學習改進啟發式方法解決VRP 問題、在線作業調度問題等。該算法不斷重寫解的不同部分,直到收斂為止,而不是按順序構建解。狀態空間表示為問題所有解的集合,而動作集則由區域(圖中的節點)及其相應的重寫規則組成。文獻[25]通過Q-Actor-Critic 算法共同訓練區域選擇和規則選擇策略。
與之相似的是,文獻[26]提出通過學習改進啟發式方法,使用2-opt、交換與重定位方法解決CVRP 與TSP 問題。此外,還可以學習改進啟發式方法并使用2-opt 解決文獻[26]中的缺點,該缺點使得策略網絡體系結構很難拓展到k-opt[27-28]。為此,將圖形神經網絡與遞歸神經網絡一起作為解碼器,并在解碼器中使用指向策略,根據指向機制順序輸出k-opt 操作。文獻[29]進一步擴展了上述工作,使用通用的銷毀與維修操作改進啟發式算法。文獻[30]提出深度自動延遲策略(ADP),將圖卷積網絡編碼器與最近策略優化(PPO)算法結合使用,可通過回滾過程學習最大策略,排除無效解。
4 結語
本文介紹了幾種通過強化學習方法解決經典組合優化問題的算法,隨著相關研究的發展,各種新算法不斷被提出。這些問題都是從計算時間的角度處理大規模問題,這也使得計算時間成為相關算法與傳統算法性能對比時一個重要的考慮因素。此外,另一個需要解決的問題是提高算法策略的泛化能力,即在小規模CO 問題上訓練后得到的模型可用于大規模組合問題。在同一研究領域,將已有RL 模型遷移到其他具有不同分布特性的問題上也是一個具有前景的研究方向。最后,當前方法都是使用RL 方法的變體結合更高效、穩定的數據采樣方法,這種結合方式能夠有效地解決組合優化問題。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
