融合意圖列表查詢機制的門控槽模型
2021-09-28 11:23:02胡光敏
軟件導刊 2021年9期
胡光敏,姜 黎
(湘潭大學物理與光電工程學院,湖南湘潭 411100)
0 引言
口語理解技術(Natural Language Understanding,NLU)是任務型對話系統(tǒng)的重要組件,旨在構建一個語義框架模型檢測用戶意圖,以及對用戶的輸入進行語義成分分析。如表1 所示,給定一個與電影相關的話語“watch suspense movie ”作為輸入,話語中的每個單詞都有不同槽值,并且具有一個針對整個話語的特定意圖。
槽填充通常可視為序列標注任務,輸入序列為x=(x1,x2,…,xT),則輸出對應槽標簽序列常用的槽填充方法包括CNN[1]、LSTM[2]、attention-based CNN[3]。意圖可視為一個文本分類任務,輸入序列為x則輸出對應的意圖標簽yi。常用的意圖分類方法包括CNN[4]、deep LSTM[5]、encoder-labeler deep LSTM[6]。

Table 1 An example of user query and semantic framework表1 用戶查詢及語義框架示例
由于槽值往往與意圖類別關系緊密,因此提出了槽填充與意圖識別共同建模的方法[7]。Xu 等[8]采用triangular-CRF 和CNN 共同建模,將意圖識別與槽填充任務進行聯(lián)合訓練。但在實際應用中,人們通常更關注于槽和意圖聯(lián)合準確率,于是Hakkani-Tur 等[9]將槽和意圖聯(lián)合準確率加入模型進行聯(lián)合訓練。與此同時,注意力機制的提出有效增強了文本上下文向量之間的關聯(lián)[10]。注意力機制是按照序列結構,利用模型提供的精確焦點,從序列中學習每一個元素的重要程度。Liu 等[11]提出基于注意力機制的RNN模型,該方法僅通過損失函數(shù)將意圖與槽進行關聯(lián),但不能有效將兩者信息進行融合,于是Goo 等[12]提出Slot-Gat?ed 模型,Slot-Gated 模型可利用上下文注意力機制顯式地建模槽值與意圖的關系。同時為解決數(shù)據(jù)稀疏性問題,提出采用自監(jiān)督訓練的通用語言表示模型,例如ELMO[13]和BERT[14]。通過預訓練詞嵌入模型對NLP 任務進行微調,從而達到更好的效果。Chen 等[15]將BERT 模型用于聯(lián)合意圖檢測與槽填充任務,該方法相比針對特定任務的帶注釋數(shù)據(jù)訓練,改進效果十分顯著。
傳統(tǒng)的Slot-Gated 模型旨在將意圖特征融入槽位識別中,但未能將文本標簽信息作為模型先驗知識傳入模型參與訓練。而在模型中加入預訓練詞向量模型又會極大地增加模型占用內存大小,不利于在硬件中嵌入模型。通過加入先驗知識,使模型獲得更好的語義理解,如在語義關系抽取模型中對輸入序列加入文本位置信息[16],以及在情感分析任務中融入情感符號信息[17]。本文提出一種新方法來提升意圖準確率和意圖與槽填充聯(lián)合準確率。首先采用預訓練詞向量模型對標簽信息進行編碼,且不參與訓練,其次將編碼的標簽信息作為先驗知識,通過構建的注意力機制融入模型參與訓練。
1 實驗方法
本節(jié)首先說明雙向長短期記憶(Bidirectional Long Short-Term Memory,BLSTM)模型,然后介紹本文提出的新方法,即意圖列表查詢機制,最后介紹意圖與槽的自注意力機制以及門控槽模型。模型架構如圖1 所示,有兩種不同模型,一種是基于意圖列表查詢機制的意圖關注門控槽模型,另一種是基于意圖列表查詢機制的全局關注門控槽模型。
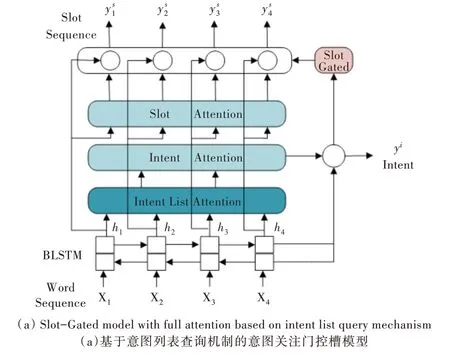
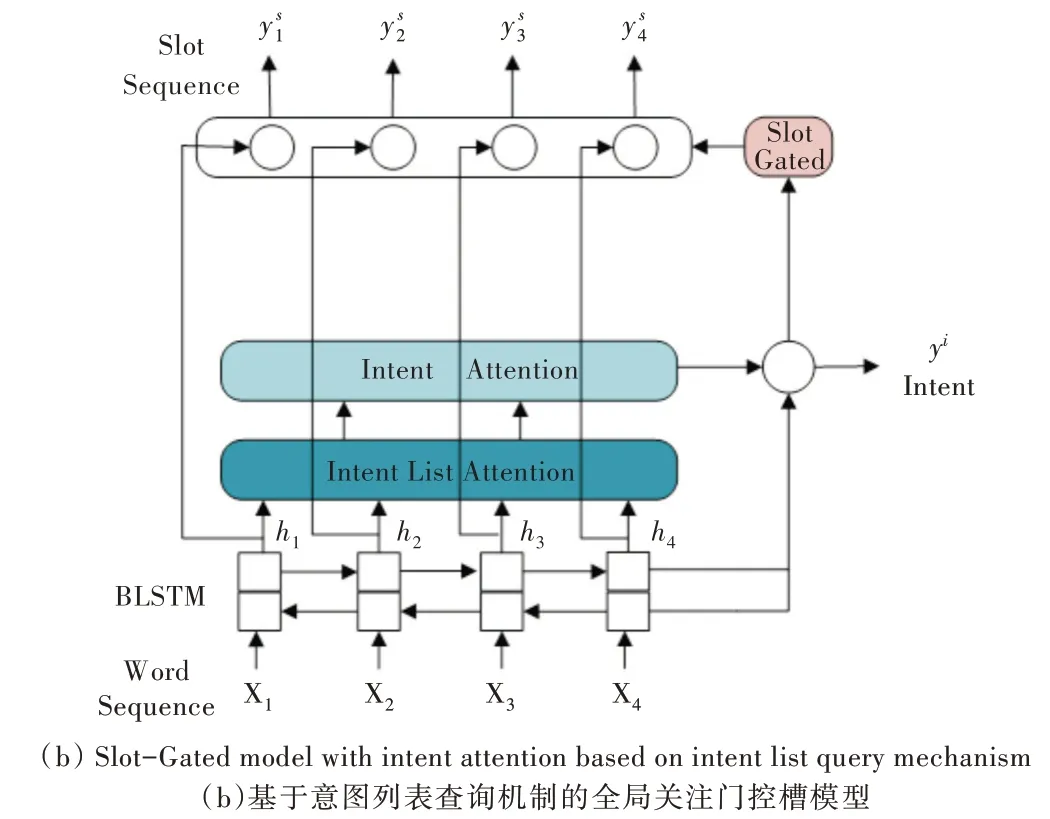
Fig.1 Architecture of the gated slot model based on the intent list query mechanism圖1 基于意圖列表查詢機制的門控槽模型整體架構
1.1 雙向RNN 模型
雙向長短期記憶模型的提出是為了更好地對序列化數(shù)據(jù)進行表達。對于許多序列化數(shù)據(jù),如聲音和文本數(shù)據(jù),其上下文之間存在密切關聯(lián)。基本的LSTM 模型不能有效結合數(shù)據(jù)前后向信息,因此本文采用雙向長短期記憶模型。

1.2 意圖列表查詢機制
本節(jié)介紹意圖列表查詢機制,意圖列表查詢機制總體架構如下:首先通過預訓練詞向量模型提取意圖標簽信息,其次通過構建的注意力機制顯示建模標簽與隱向量hT的關系。從訓練集中提取出所有意圖類別后,將BERTBase 預訓練詞向量導入bert-as-service 服務中,并通過bert-as-service 服務編碼出各類意圖的詞向量表示。
傳入模型的先驗知識為通過bert-as-service 服務構建的意圖詞向量矩陣D,詞向量矩陣D 參數(shù)固定且不參與訓練。隱向量h 通過注意力機制從意圖矩陣中學習到每一個意圖的重要程度,并按照其重要程度對信息進行融合。
基于意圖列表構建的注意力機制如下:式(1)表示隱向量基于查詢矩陣中各項意圖相乘的積,求出fd后,需將fd最后兩維向量進行展平處理,從而將意圖與文本向量的結合信息整合在同一維度中;式(2)表示通過softmax 求出hT與各項意圖的相關度。其中,tanh 為激活函數(shù),Wd為可學習的意圖列表注意力權重,hT為隱向量,D 為意圖查詢矩陣。

式(3)為聯(lián)合各項意圖向量的加權特征,具體公式如下:

1.3 意圖與槽自注意力機制

1.4 Slot-Gated 機制
本節(jié)介紹Slot-Gated 機制,Slot-Gated 模型引入一個額外的門機制,利用上下文注意力機制建模槽值與意圖的關系,從而提升槽填充的性能。首先組合槽上下文向量和意圖上下文向量cI,Slot Gate 示意圖如圖2 所示。
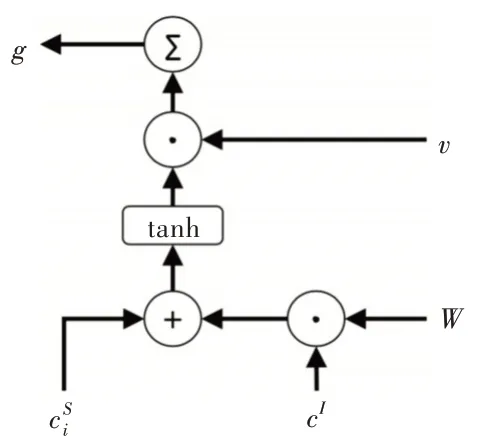
Fig.2 Illustration of the Slot Gate圖2 Slot Gate 示意圖
其中,v、W 分別是可訓練的矩陣向量。對同一時間步中的元素進行求和,g 可看作聯(lián)合上下文向量的加權特征。
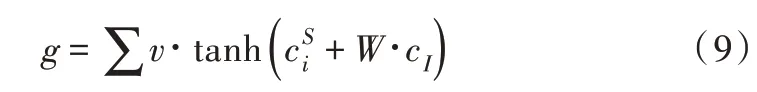
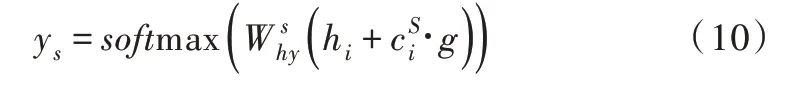
以上提出一種僅專注于意圖的縫隙內控模型,組合隱向量h和意圖上下文向量,通過時隙門求得g。
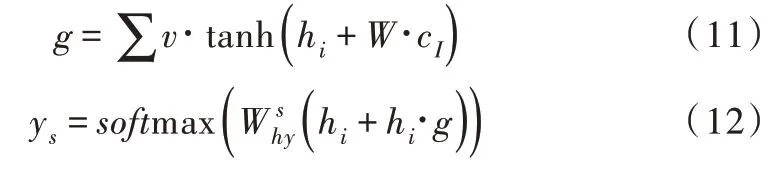
2 實驗與分析
2.1 數(shù)據(jù)集統(tǒng)計
為評價所提出方法的有效性,本文采用基準數(shù)據(jù)集ATIS(航空旅行信息系統(tǒng))[18]與數(shù)據(jù)集Snips[19]進行對比實驗。ATIS 數(shù)據(jù)集中訓練集、驗證集及測試集分別包含4 478、500 和893 條話語,并具有120 個槽標簽和21 個意圖標簽。與ATIS 相比,Snips 數(shù)據(jù)集詞匯量更大,且語義環(huán)境更為復雜。Snips 數(shù)據(jù)集中訓練集、驗證集及測試集分別包含13 084、700 和700 條話語,并具有72 個槽標簽和7 個意圖標簽。各數(shù)據(jù)集統(tǒng)計結果如表2 所示。
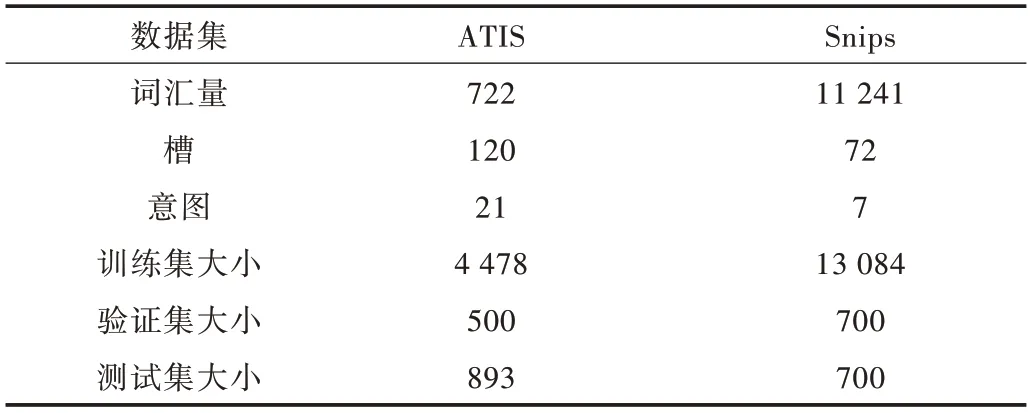
Table 2 Statistics of ATIS and Snips datasets表2 各數(shù)據(jù)集統(tǒng)計結果
2.2 結果分析
所有實驗在Linux 系統(tǒng)的tensorflow1.14 環(huán)境下進行,設置批次大小為32、隱藏向量大小為64,損失函數(shù)采用交叉熵損失函數(shù),優(yōu)化器為Adam[20],損失函數(shù)采用聯(lián)合優(yōu)化損失函數(shù),迭代訓練100 次。
實驗中除在意圖識別模塊中加入意圖列表查詢機制外,其他參數(shù)設置和模型搭建與原Slot-Gated 模型相同,該方法排除了其他因素對本實驗的干擾。本文使用F1 得分評估插槽填充性能,使用準確率評估意圖識別和語義框架的整體性能。在ATIS 數(shù)據(jù)集上的實驗結果如圖3、圖4 所示(彩圖掃OSID 碼可見,下同)。圖3 展示了全局關注和僅意圖關注模型在ATIS 數(shù)據(jù)集上的損失值,圖4 為全局關注和僅意圖關注模型在ATIS 數(shù)據(jù)集上槽值的F1 得分,以及意圖準確率和意圖與槽聯(lián)合準確率。
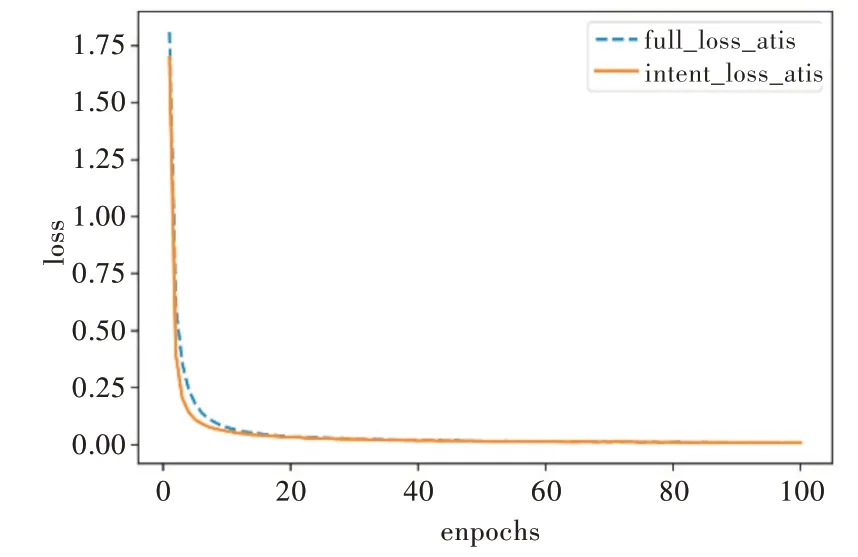
Fig.3 Loss value of the proposed model on ATIS圖3 本文模型在ATIS 上的損失值
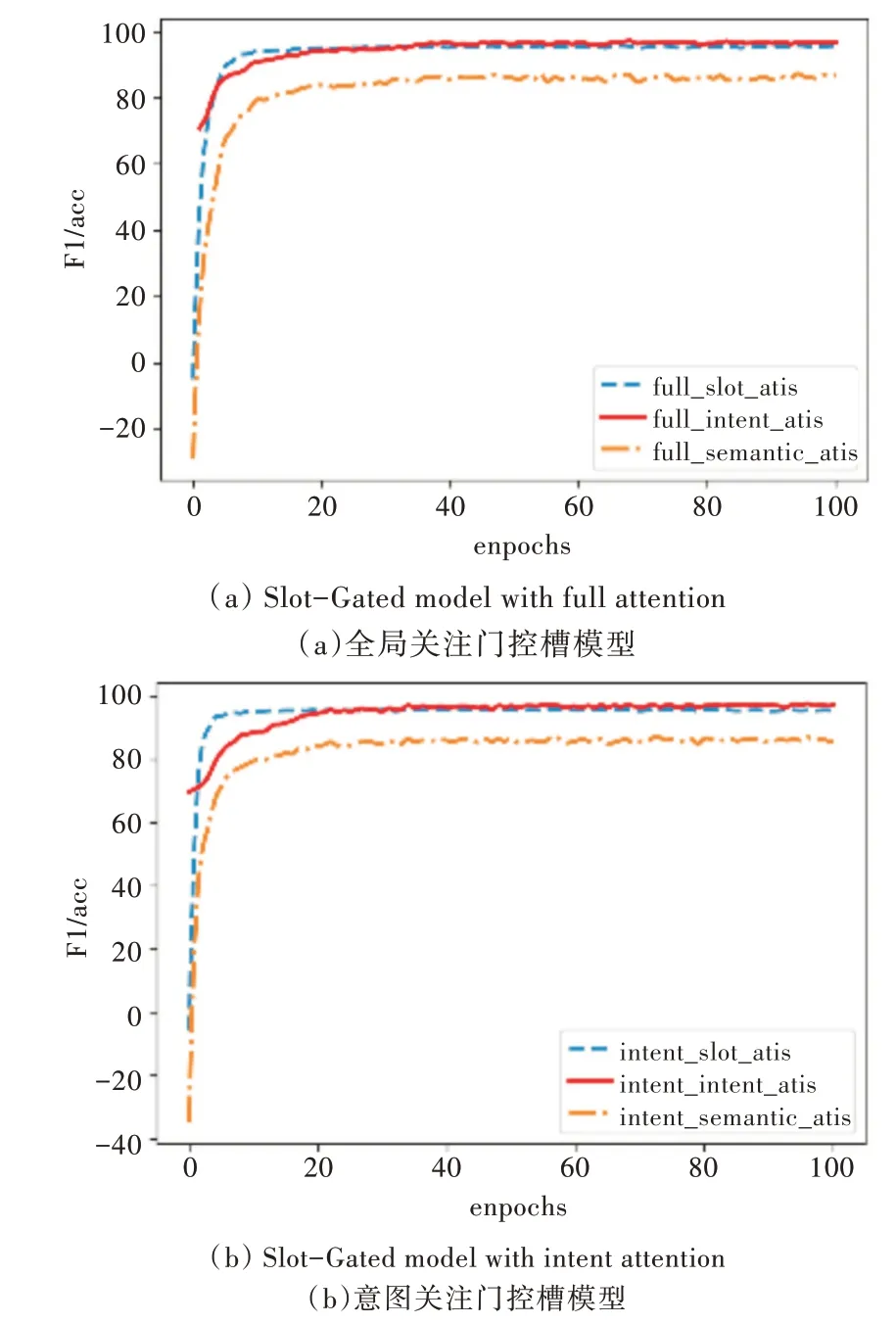
Fig.4 Performance of the proposed model on ATIS圖4 本文模型在ATIS 上的性能
為了說明模型的有效性,在Snips 數(shù)據(jù)集上對模型進行測試,實驗結果如圖5、圖6 所示。
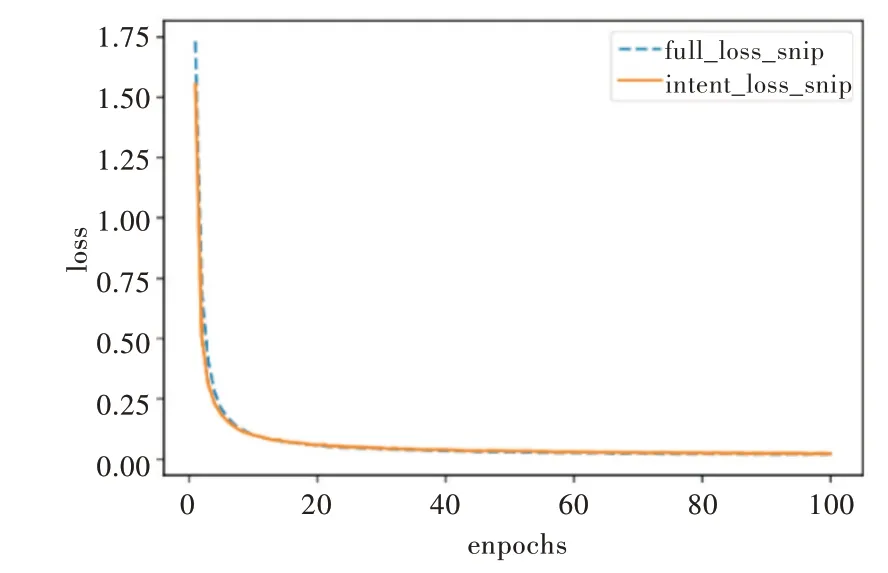
Fig.5 Loss value of the proposed model on Snip圖5 本文模型在Snip 上的損失值
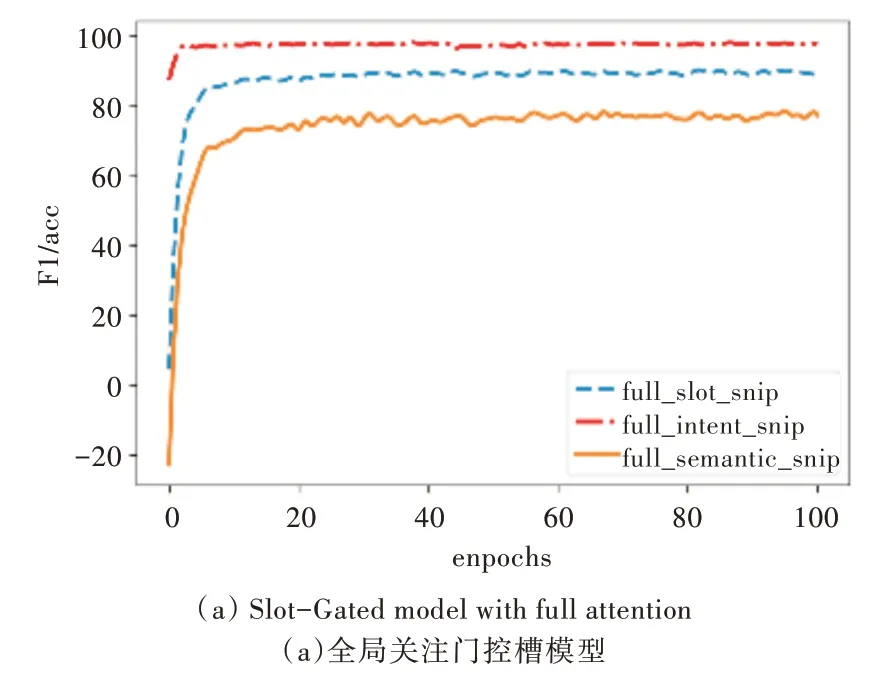
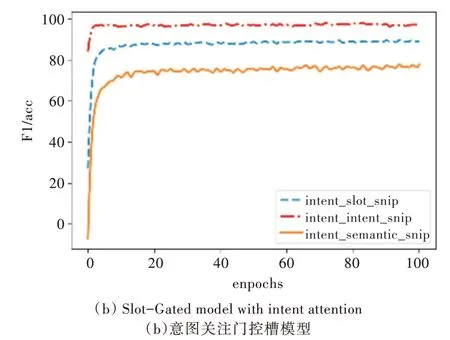
Fig.6 Performance of the proposed model on Snips圖6 本文模型在Snips 上的性能
Slot-Gated 原文獻中提出的各項指標為前20 輪的平均值,所展示的模型效果并未達到Slot-Gated 模型的最佳效果。本文實驗進行100 輪次訓練,將Slot-Gated 模型與本文方法的實驗結果進行對比,如表3 所示。
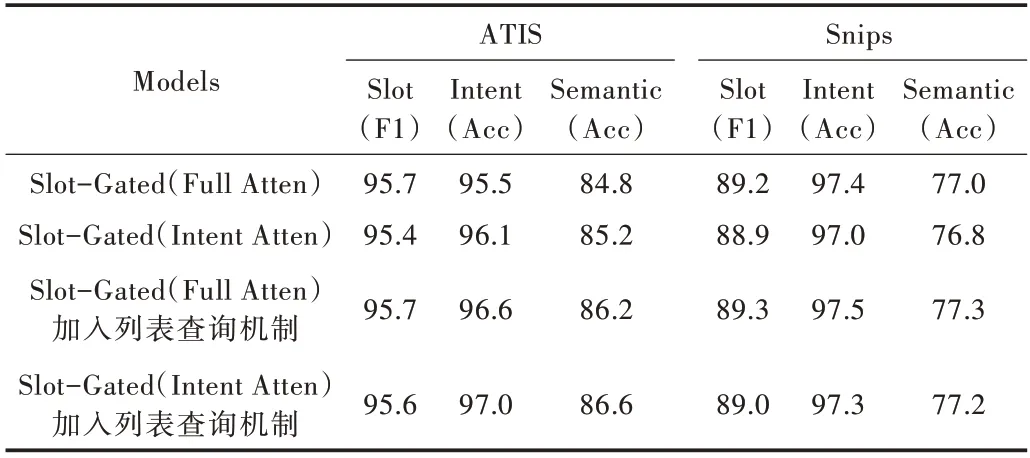
Table 3 Performance of NLU on ATIS and Snips datasets表3 NLU 在ATIS 與Snips 數(shù)據(jù)集上的性能
從表3 可以看出,針對ATIS 數(shù)據(jù)集,采用全局注意機制,意圖準確率和意圖與槽聯(lián)合準確率分別提升了1.1%和1.5%;僅采用意圖注意機制,意圖準確率和意圖與槽聯(lián)合準確率分別提升了0.9%和1.2%。在Snips 數(shù)據(jù)集上,由于意圖種類較少且訓練數(shù)據(jù)充足,意圖分類任務較為簡單,模型能很好地擬合數(shù)據(jù),加入列表查詢機制未對模型產(chǎn)生明顯改善效果。針對Snips 數(shù)據(jù)集,采用全局注意機制,意圖準確率和意圖與槽聯(lián)合準確率分別提升了0.1% 和0.3%;僅采用意圖注意機制,意圖準確率和意圖與槽聯(lián)合準確率分別提升了0.3%和0.4%。實驗結果表明,在Slot-Gated 模型中加入基于意圖的列表查詢機制對意圖識別以及意圖與槽聯(lián)合準確率的提升具有積極意義。
3 結語
本文通過構建意圖列表查詢機制,給予模型在意圖領域的先驗知識。通過注意力機制將意圖先驗知識與輸入句向量兩者進行有效關聯(lián),并傳入后續(xù)的意圖識別網(wǎng)絡進行訓練,以實現(xiàn)更好的語義理解,從而提升模型意圖識別以及意圖與槽聯(lián)合準確率。相比Slot-Gated 模型,本文方法在意圖識別以及意圖與槽聯(lián)合準確率上均有所提升,并驗證了將標簽轉換為先驗知識對模型具有積極意義。當然本文方法在原模型的基礎上增加了參數(shù)量,會耗費更多計算和存儲成本。在今后的研究中,將致力于將先驗知識與模型進行更有效融合,以提高神經(jīng)網(wǎng)絡的可解釋性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
四川勞動保障(2021年9期)2022-01-18 05:11:08
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
中國衛(wèi)生(2016年9期)2016-11-12 13:28:08
光學精密工程(2016年6期)2016-11-07 09:07:19
中國衛(wèi)生(2015年9期)2015-11-10 03:11:12
核科學與工程(2015年4期)2015-09-26 11:59:03
中國衛(wèi)生(2014年3期)2014-11-12 13:18:12
