改進LDA 模型的短文本聚類方法
2021-09-28 11:22:46俞衛國
軟件導刊 2021年9期
孫 紅,俞衛國
(1.上海理工大學光電信息與計算機工程學院;2.上海現代光學系統重點實驗室,上海 200093)
0 引言
聚類是一種無監督的機器學習方法,文本聚類是依靠文檔特征將文本聚集為文檔簇。隨著互聯網及信息技術的飛速發展,社區平臺Twitter、新浪微博等普及,短文本呈爆炸式增長,對短文本聚類預處理具有重要價值。不同于傳統媒體平臺的文本信息,短文本具有以下特點:更新快速,存在大量不規范用語,吸收新詞匯多,數據具有稀疏性,這給短文本聚類增加了難度。
常用的文本聚類算法通過計算文本的相似度信息,如VSM(Vector Space Model)模型,通過計算空間向量之間的余弦值來衡量文本的相似度。目前文本聚類主要應用有文本分類、文本可視化、搜索引擎聚類、信息推薦等。
20 世紀中后期,Gerard 等[1]提出VSM 空間向量模型并成功應用,但這種模型在計算空間相似度時計算量比較大,而且沒有考慮詞與詞之間的內部聯系。主題模型(Top?ic Model)考慮了詞語與主題之間的內部聯系,劉金亮[2]提出了一種改進的LDA(Latent Dirichletalloc Allocation)主題模型,使得LDA 模型的主題分布向高頻詞傾斜,導致能夠代表主題的多數詞被少量的高頻詞淹沒,使主題表達能力降低;汪進祥[3]提出一種基于主題模型的微博話題挖掘,結合詞性標注進行話題提取;張志飛等[4]基于潛在狄利克雷分配的新方法,提出基于LDA 主題模型的短文本分類方法,生成的主題不僅可以區分常用詞的上下文并降低其權重,還可以通過連接區分詞并增加其權重來減少稀疏性;張蕓[5]結合在短文本建模方面具有優勢的BTM 主題模型對短文本進行特征擴展,將擴展后的特征矩陣進行相似度計算。
本文首先介紹了VSM(Vector Space Model)模型聚類、LTM(Lifelong Topic Modeling)模型聚類、LSA[6](Latent Se?mantic Analysis)模型聚類、PLSA[7](Probabilisticlatent Se?mantic Analysis)模型聚類,然后引出經典模型LDA(Latent Dirichlet Allocation),介紹了LDA 模型的優劣,最后針對經典的LDA 模型沒有考慮到文本與主題之間的聯系問題,提出一種具有判別學習能力的LDA-λ模型。將二項分布引入到LDA-λ基礎模型中,增加詞項的判別能力。最后經過對比聚類算法實驗,證明基于判別學習能力的LDA-λ模型聚類性能比VSM 和LDA 模型顯著提高。
1 基本模型與方法
1.1 VSM
VSM 是一種空間向量模型,出現在20 世紀中后期,由Gerard 等[8]提出,并成功應用于著名的SMART 文本檢索系統。VSM 模型簡單,易于理解。它的核心思想是把需要處理的文本內容轉化到空間向量中,并以向量運算的方式計算語義的相似度。當文本表示為空間向量時,文本的相似性就可以通過計算文本空間向量的度量值表示。通常將余弦距離作為度量值來比較相似性。
假如一篇文本D1 中有a、b、c、d、e 五個特征項,權值分別為30、20、20、10、10,文本D2 中有a、c、d、e、f 五個特征向量,權值分別為30、30、20、10、10,則對應文檔D(D1,D2)的總體特征為(a,b,c,d,e,f),D1 的向量表示為D1(30,20,20,10,10),D2 的向量表示為D2(30,30,20,10,10),根據夾角余弦公式:
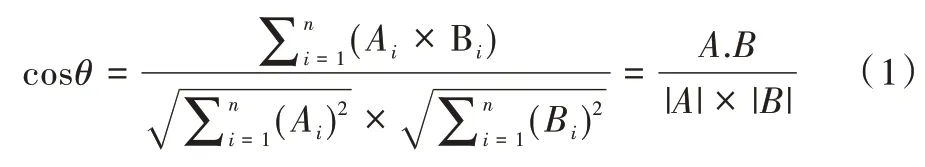
計算文本D1 與D2 的相似度是0.92。
從上述描述與計算可知VSM 模型用于聚類時的缺點:①在計算相似度時,相似度計算量較大,每次有新的文檔加入時必須重新計算詞的權值;②沒有考慮到詞與詞之間的聯系,語義相同但是使用不同詞語的特征詞沒有關聯起來。
1.2 LTM 模型
主題模型[9](Topic Model)是用在大量文檔中發現一種潛在主題的統計模型。與上述VSM 模型相反,主題模型考慮被處理文檔的語義信息以及與各個主題之間聯系,并將文本到詞項的分布轉化為文檔與主題之間的分布,有效降低了特征維度,利于短文本處理,但在提高性能的同時犧牲了時間。在主題模型中,假如一篇文章有一個中心思想,那么關于中心思想的詞語就會頻繁出現。在現實中一個文檔通常包含多個主題,并且每個主題所占的比例各不相同,那么這些主題相關關鍵字出現的頻率就與這些主題所占比例有關。
主題模型的特點是能夠自動分析文檔,統計文檔中的單詞時不需要考慮他們出現的順序,根據統計出的信息判斷文檔中的主題以及各個主題所占的比例。
傳統主題模型基本都是一種完全無監督模型,會產生許多不符合邏輯的Topic,針對該問題學者提出了許多關于先驗知識的主題模型。本文的LTM 主題模型不需要任何用戶輸入就能從大量主題中自動地和動態地挖掘先驗知識,這就是Lifelong 思想。
Lifelong 思想假設:問題:如何找到先驗知識并利用它完成新的主題建模任務?
數據:情緒分析背景下的產品評論。
算法如下:
(1)先驗topic 的生成,或者稱為proir-topic。給定來自n 個領域的一個文檔集合D={D1,…,Dn},使用Algorithm 1 PriorTopicsGenenration(D)對每個領域的文檔Di(Di∈D)運行算法,生成所有topic 的集合S,稱這個S 為proir-topic 集合。這些proir-topic 后續會用在LTM 模型上作為先驗知識。S 中的proir-topic 可以通過迭代來改善。上一輪迭代中的S 可以通過下一輪的LTM 過程從D 中生成更好的top?ic。LTM 從第二輪開始使用。
(2)測試文檔topic 的生成,或者稱為test-topic。給定一個測試文檔集合D(t)和第(1)步生成的proir-topics 集合S,利用Algorithm2(LTM)生成topics。區別第(1)步的topic稱為test-topics。注意測試文檔D(t)可以來自于D 或者新領域的一個文檔集合。LTM 算法偽代碼如下:

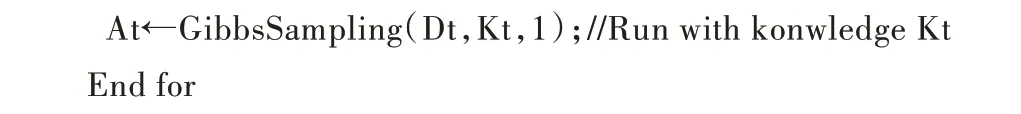
以上過程很自然地用上了Lifelong learning 思想。S 是系統生成的一個知識庫(proir-topic),而LTM 是學習算法。給定一個新的學習任務G(如主題建模)和它的數據(如Da?ta),lifelong learning 可以分為兩個階段:①Learning with pri?or knowledge。這對第(2)步至關重要,它需要解決兩個子問題(第(1)步是初始化)。②知識的保留和合并。如果G是一個新任務就簡單地把G 的topic 加進S 中。如果G 是一個舊任務就在S 中替換其topics。
LTM 模型主要包括潛在語義分析LSA(Latent Semantic Analysis)、概率潛在語義分析PLSA(Probability Latent Se?mantic Analysis)和潛在迪里克雷分布LDA(Latent Dirichlet Allocation),3 個模型分別描述如下。
1.2.1 LSA
在某些情況下,LSA 又稱作潛在語義索引(LSI),是一種非常有效的文本建模方法。正如其名稱,該方法意在分析文本語料所包含的潛在語義,然后將單詞和文檔映射到該語義空間。LSA 以矩陣奇異值分解(SVD)為基礎,在了解LSA 之前,需要先對奇異值分解[10]進行簡單介紹。
一個矩陣代表一個線性變換(旋轉,拉伸),可將一個線性變換過程分解多個子過程,矩陣奇異值分解就是將矩陣分解成若干個秩與矩陣的和。
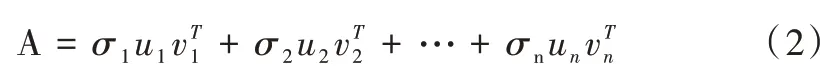
其中,σi是奇異值,是秩為的矩陣,表示一個線性變換子過程。奇異值σi反映了該子過程在該線性變換A 中的重要程度。對式(2)進行整理,將奇異值分解過程表示如下:

其中,U 是左奇異向量構成的矩陣,兩兩相互正交,S 是奇異值構成的對角矩陣,VT是右奇異向量構成的矩陣,兩兩相互正交。
奇異值分解具有如下數學性質:①一個m*n 的矩陣至多有p=min(m,n)個不同的奇異值;②矩陣的信息往往集中在較大的幾個奇異值中。
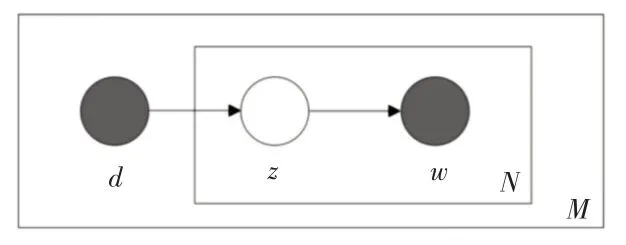
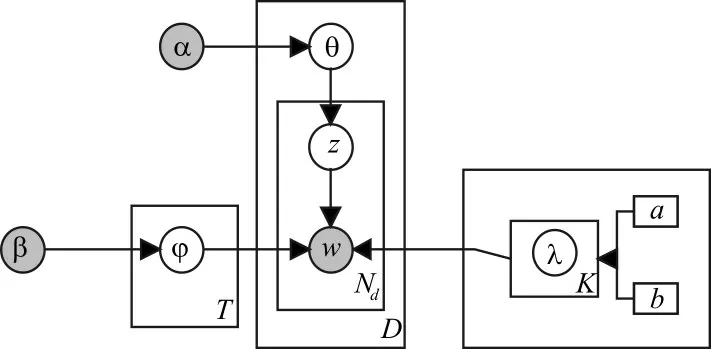
LSA 正是利用了奇異值分解的這兩個性質將原始的單詞—文檔矩陣映射到語義空間。在LSA 中不再將矩陣理解成變換,而是看作文本數據的集合。文本語料中所有單詞構成矩陣的行,每一列表示一篇文檔(詞袋模型表示)。假設A 是一個m*n 的文本數據矩陣(n< 依據奇異值分解性質①,矩陣A 可以分解出n 個特征值,然后依據性質②選取其中較大的r 個并排序,這樣USVT就可以近似表示為矩陣AA。對于矩陣U,每一列代表一個潛語義,這個潛語義的意義由m 個單詞按不同權重組合而成。因為U 中每一列相互獨立,所以r 個潛語義構成了一個語義空間。SS 中每一個奇異值表示該潛語義的重要度。VT中每一列仍然是一篇文檔,但此時文檔被映射了語義空間。VT的大小遠小于A。有了VT就相當于有了矩陣A 的另外一種表示,之后就可使用VT代替A 進行之后的工作。 Fig.1 Singular value decomposition圖1 奇異值分解 LSA 通過SVD 和低秩逼近,把原始向量空間映射到潛在語義空間,在潛在語義空間計算文檔相似性能夠解決部分一義多詞的問題,從該層面可知LSA 優點很明顯。但是低秩逼近后的矩陣中元素缺乏直觀解釋,甚至矩陣中會出現很多元素為負數的情況,特征向量的方向沒有對應的物理解釋,k 的選取會對結果產生很大影響,且k 不是計算出來的而是一個經驗值,所以很難選出合理的k 值,無法對應現實中的概念。 1.2.2 PLSA 盡管上述的LSA 模型取得了一定的成功,但是由于缺乏嚴謹的數學統計基礎,而且SVD 分解非常耗時,因此Hofmann 在SIGIR1999 上提出了基于概率統計的PLSA 模型,并且采用EM 算法學習模型參數。PLSA 模型是最接近LDA 的模型,所以理解PLSA 模型有助于理解LDA。PLSA模型如圖2 所示。 Fig.2 PLSA model圖2 PLSA 模型 PLSA 模型數學符號如表1 所示。 Table 1 Mathematical symbols of PLSA model表1 PLSA 模型數學符號 先從文檔集合中選擇一篇文檔di,選定后從主題分布中按照概率P(zk|di)選擇一個隱含的主題類別zk;選定主題zk后從詞分布中按照概率P(wj|zk)選擇一個詞wj。 根據大量已知的文檔—詞項信息P(wj|di)訓練出文檔—主題P(zk|di)和主題—詞項P(wj|zk),見式(5): 得到文檔中每個詞的生成概率為: 上述是完整的生成過程。事實上由于P(di)可事先計算求出,而P(wj|zk)、P(zk|di)未知,所以θ=(P(wj|zk),P(zk|di))就是要估計的參數值。一般要最大化這個θ,由參考文獻[6]求解出這兩個參數。 1.2.3 LDA 模型聚類 LDA 模型是一種文檔—主題生成模型,在2003 年由Blei 等[11]提出。LDA 模型是PLSA 模型的擴展,它能夠在一系列文檔中分析出文檔的主題概率分布,歸屬于統計模型。事實上,理解了PLSA 模型也就理解了LDA 模型,因為LDA就是在PLSA 的基礎上加上貝葉斯框架,即LDA 就是PLSA的貝葉斯版本(正因為LDA 被貝葉斯化了,所以才需要考慮歷史先驗知識加上兩個先驗參數),LDA 模型如圖3所示。 Fig.3 LDA model圖3 LDA 模型 在LDA 模型中,一篇文檔生成方式如下:①從迪利克雷分布α中取樣生成文檔i的主題分布θi;②從主題的多項式分布θi中取樣生成文檔i第j個詞的主題zij;③從迪利克雷分布β中取樣生成主題zij對應的詞語分布φzij;④從詞語的多項分布φzij中采樣最終生成詞語Wij。 和PLSA 模型一樣,文檔到主題服從多項式分布,主題到詞服從多項式分布,是一種完全的概率生成模型。生成文檔中每個詞出現的概率為: 聯合概率分布公式為: 詞wi在主題z 上的分布如下: 文檔d 在主題z 上的分布如下: 經過一系列的訓練推導過程求出吉布斯采樣公式如下: 基礎LDA 模型未考慮詞項的區分程度,如果一個詞項在大部分主題下都以高頻出現,那么這個詞項不能作為特征詞來代表主題。文本具有稀疏性,直接去除對主題沒有區分度的詞項會對模型產生一定的影響,為此提出新的模型[14],將二項分布引入到LDA 基礎模型之中,增加詞項的判別能力,并將其并行化。 對單詞進行采樣,將同一個單詞隸屬于不同話題看作是相互獨立的,用γ表示詞項的判別能力。如果話題z 含有詞項w,那么γw,z=1;如果不含有w,則γw,z=0。可以看出,γ是一個服從二項分布的參數: 其中,λw代表單詞w在所有話題上的分布。本文假設λw~Beta(a,b),因為α與β參數已被使用,所以本文中用a、b參數表示貝塔分布中的參數: 其中,Υ={Υw,1,Υw,2,…,Υw,K}。 可以推斷如下:如果某詞項w 在各個話題中均勻出現時,λw值較大時對話題的區分程度不大;相反,如果某詞項w僅集中在某一個或少部分話題中出現,則此詞項的λw值較小。因此,采用來表示詞項判別力,將更大的權重分派給判別力大的詞項以減小判別力小的詞對聚類的影響。使用ω∈[0,1]對ω進行正則化表示如下: 在引入λw后,改進LDA 的概率模型如圖4 所示。 Fig.4 Improved LDA probability model圖4 改進后的LDA 概率模型 改進LDA 模型采樣過程如下: 對話題分布進行采樣: 選擇文檔話題:zd~Multi(θd); 吉布斯采樣可以通過迭代對高維概率模型進行求解,每次迭代僅僅采樣當前維度的值,將其他維度的值固定。算法一直迭代直到收斂為止,最終輸出需要估計的參數。在LDA 算法中即輸出φ與θ。 經過一系列推導變換,可以得到新模型的吉布斯采樣更新后的公式: 初始時刻,為文檔的每個詞項進行主題zi的隨機分配。然后統計zi下的詞項w 的個數,以及文檔i下含有主題zi中詞項的個數。每一輪都根據公式估計每個詞對于每個主題分配到的概率,然后用此概率分布進行新主題采樣;同時對每個詞均采用同樣的方法進行詞的主題更新。如果各個主題中詞項的分布以及訓練文檔在各個主題下的分布更新收斂,就將模型中的參數輸出。 經過吉布斯采樣過程后求得θ參數與φ參數的表達式: 選用網上現有的API 就可以方便地進行數據分頁爬取,本文選用Jsoup 進行數據爬取,獲取的數據源是東方財富網。考慮到短文本限制,在數據選取上只爬取標題,選取對應的標簽,爬取約8 000 條數據。 爬取到的大量數據質量差別很大,有些短文本僅僅包含兩三個無用且沒有實際意義的詞匯,這樣的低質量數據對模型干擾很大,在數據預處理時應將其去掉,在去除了大量低質量數據后再選擇合適的算法。 在進行特征選擇之前要對訓練集中的每篇文檔進行分詞,采用的分詞工具是IKAnalyzer。IKAnalyzer 是一個開源的基于Java 語言開發的輕量級中文分詞工具包。分詞結果如圖5 所示。 Fig.5 Word segmentation results圖5 分詞結果 現有的特征抽取[16]方法很多,包括信息增益IG、局部文檔頻率和全局文檔頻率,對于文本分類選用局部DF 或者IG 都能達到良好的效果。 首先根據IG 或者局部DF 完成普通的特征選取,然后經過訓練得到基于LDA 的隱主題模型,對隱主題對應的高比重單詞進行特征加強,即對于原來特征選擇中沒有出現的單詞加入到LDA 主題模型中,完成LDA 拓展文本特征選取。 為了完成LDA 拓展的特征選取,先訓練LDA 得到隱藏的主題。找到每個主題下對應的關鍵詞項。LDA 模塊使用GitHub 上成熟的LdaGibbsSampler 的API 模塊。為了得到短文本的LDA 主題模型,需要將這上千條數據劃分為上千個單獨的短文本文檔。 本實驗采用精確度(ACC)、歸一化互信息(NMI)和成對F 測度值(PWF)[17]作為評價指標。精確度主要用來評價實驗中類標簽和真實標簽相比預測正確的概率。歸一化互信息是評價聚類效果常用的指標,用來表示預測的實驗結果與真實結果的相近程度。F 測度是評價分類器好壞的重要指標,是準確度(precision)和召回率(recall)的調和平均值。F 測度計算公式如式(19)所示。 在本文實驗中,所有數據集上都設置α=50/K,β=0.01,a=10,b=30。本文分別對比LDA 和改進的LDA 以及VSM模型,實驗結果如表2 所示。 Table 2 Clustering results表2 聚類結果 從實驗結果可以看出,LDA 在聚類效果上比SVM 效果好,具有判別學習能力的LDA 聚類效果比基礎LDA 模型有很大改善。 LDA 模型是一種基于概率分布的主題模型,本文對此模型進行改進,將不同詞項對于不同的話題區分程度融合進去。實驗表明,在聚類性能方面具有判別學習能力的LDA 比基礎的LDA 和VSM 模型都有提高。 上述模型都屬于機器學習模型,目前流行的深度學習在處理文本方面也有許多需要提高的地方。深度學習[18]最初之所以在圖像和語音領域取得巨大成功,一個很重要的原因是圖像和語音的原始數據都是連續和稠密的,都有局部相關性。應用深度學習解決大規模文本分類問題最重要的是解決文本表示[19],再利用CNN/RNN[20]等網絡結構自動獲取特征表達能力,去掉繁雜的人工特征,端到端地解決問題。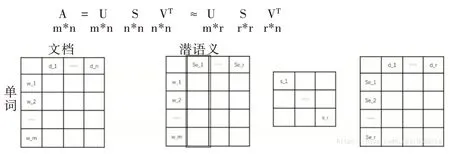


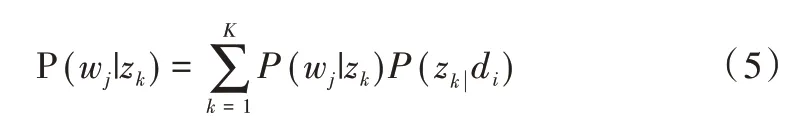



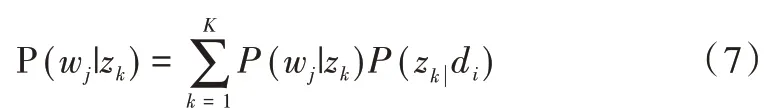
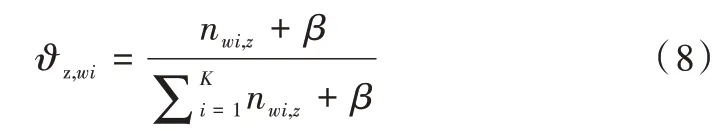
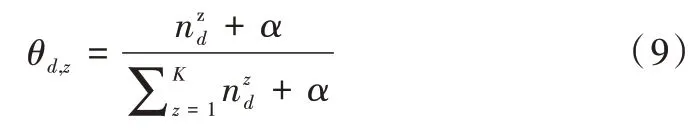
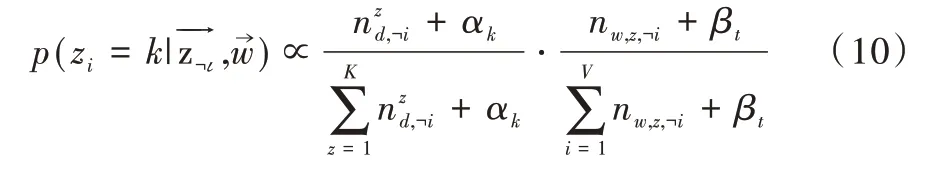
2 LDA 模型改進
2.1 模型改進過程


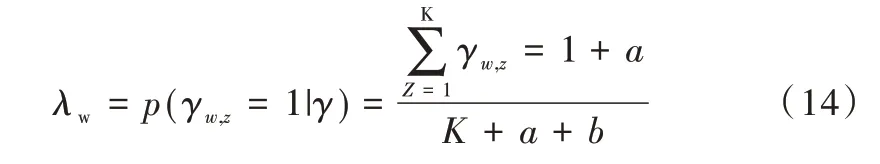

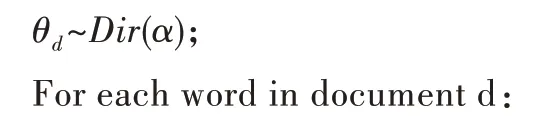
2.2 吉布斯采樣求解
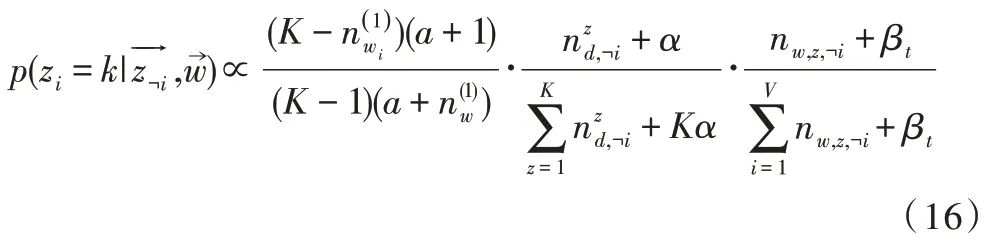
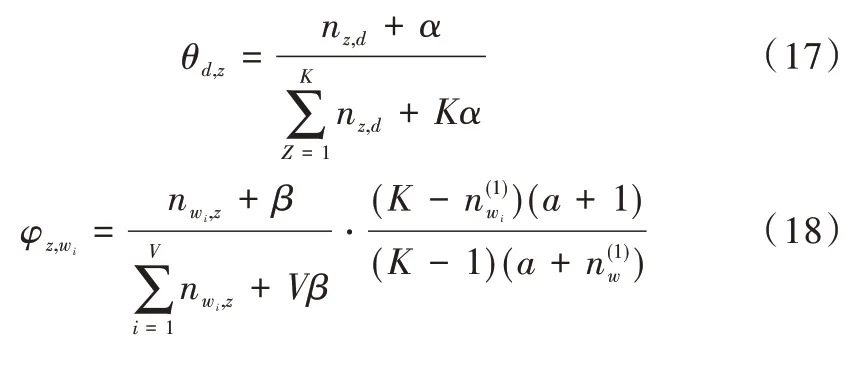
3 實驗
3.1 數據爬取
3.2 數據預處理
3.3 文本分詞

3.4 特征選取
3.5 LDA 隱主題抽取
3.6 評價指標
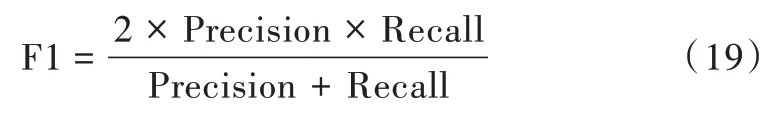

4 結語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
