Audio2Face基于音頻文件智能生成虛擬角色面部動畫
2021-09-27 07:43:40蔡國鑫
現代電影技術
2021年9期
近日英偉達 (Nvidia)公司發布了一款基于人工智能 (AI)的Audio2Face應用程序,根據音頻源生成3D 虛擬角色面部動畫并實現唇音同步,可用于實時交互應用或作為內容創作通道。傳統虛擬角色面部動畫制作需進行建模、綁定、動畫等一系列處理,而Audio2Face以.wav或.mp3音頻文件為輸入,直接生成角色面部動畫或幾何緩存,制作人員只需根據應用需求進行調整定制即可使用。
1 Audio2Face技術難點與解決方案
僅由音頻源生成虛擬角色面部動畫和實現唇音同步的難點在于基于同一音頻源可能生成多種不同的面部動畫。盡管深度卷積神經網絡 (DCNN)在各種推理和分類任務中非常有效,但如果訓練數據中存在歧義,其往往會向均值回歸,因此基于深度卷積神經網絡為虛擬角色生成逼真且一致的面部動畫尚存在一定困難。
針對技術難點,Audio2Face提出了以下解決方案:
(1)設計一種深度卷積網絡,用于有效處理人類語音并在不同的虛擬角色上實施模型泛化。
(2)采用一種新穎方法,使網絡能夠發現訓練數據中不能由音頻單獨解釋的變化,即明顯的情緒狀態。
(3)構建具有三個損失項的損失函數 (Loss Function),確保在數據高度模糊的情況下,網絡依然能夠具有時間穩定性和快速響應能力。
2 Audio2Face網絡結構
按照功能劃分,Audio2Face網絡由頻率分析網絡(Formant Analysis Network)、發音網絡 (Articulation Network)和輸出網絡 (Output Network)組成,網絡結構如圖1所示。
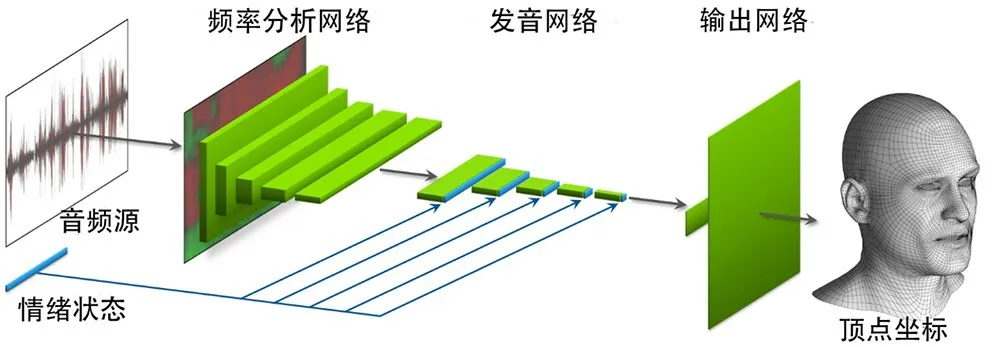
圖1 Audio2Face網絡結構
頻率分析網絡 (Formant Analysis Network)包括一個固定功能的自相關分析層 (Fixed-Function Autocorrelation Analysis Layer)和5 個卷積層。自相關分析層使用線性預測編碼 (Linear Predictive Coding,LPC),以提取音頻的自相關系數。……
登錄APP查看全文
猜你喜歡
小哥白尼(趣味科學)(2021年12期)2021-03-16 05:40:38
小學科學(學生版)(2020年10期)2020-10-28 07:52:18
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
文苑(2019年22期)2019-12-07 05:28:56
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年3期)2018-05-30 07:01:39
學生天地(2016年9期)2016-05-17 05:45:06
河南科技(2014年23期)2014-02-27 14:19:15
計算機應用文摘(2009年26期)2009-04-29 23:03:52
