脈沖神經網絡算法及其在撲克游戲中的應用
2021-09-16 01:51:50董麗亞王麒淋
計算機工程與設計 2021年9期
關鍵詞:規則
董麗亞,何 虎+,王麒淋,楊 旭
(1.清華大學 微電子與納電子學系,北京 100084;2.北京理工大學 軟件學院,北京 100084)
0 引 言
脈沖神經網絡(spiking neural network,SNN)[1]是一種極具生物可解釋性的仿生型人工神經網絡,不同于現在主流神經網絡采用的“統計+計算”的方式,脈沖神經網絡通過擬合生物神經元機制,模擬生物神經網絡的結構和信息加工過程來進行計算[2]。SNN使用脈沖(發生在某個時間點的事件的離散值)來傳遞信息,不僅傳遞空間信息,還加入了時間信息的傳遞,計算能力更強。但目前關于SNN的研究剛剛起步,缺乏有效的SNN網絡結構和學習算法,嚴重限制SNN的發展。目前已有的SNN算法有STDP(spike timing dependent plasticity)、ReSuMe(remote supervised method)和SpikeProp等,在現有算法的基礎上,本文提出了基于STDP規則的權值學習算法,通過調整引導神經元的激發時間來間接調整目標權值,在網絡結構方面,利用生物學的條件反射原理結合Hebb規則提出了脈沖神經網絡突觸的生長算法,通過該算法可以實現網絡的自生長和自適應,同時提出了具有普適性的四層脈沖神經網絡結構。為了驗證網絡結構和算法的可行性,本文將算法應于不完美信息博弈[3]中,撲克游戲是一種典型的不完美信息博弈,本文將會以斗地主撲克游戲為例,通過SNN網絡結構和算法來學習一個人的打牌能力,實現一個擬人化的斗地主機器人。
1 脈沖神經網絡理論基礎
1.1 脈沖神經元模型
傳統神經網絡的神經元通過乘加運算和激活函數,從數學角度使用“統計+計算”的方式對數據進行處理[4,5];而脈沖神經元通過復現生物神經元工作狀態及狀態變化過程,建立具有仿生型的模型,結合神經形態學和神經動力學角度對生物神經元進行模擬。目前廣泛認可的脈沖神經元模型[6]有:Integrate-and-fire模型、Hodgkin-Huxley模型、Fractional-Order Leaky integrate-and-fire模型、泄漏積分放電(leaky integrate-and-fire,LIF)模型等。為了同時兼顧模型參數復雜度和生物學仿生精確度,本文采用LIF模型。
LIF神經元等效為一個帶有電壓源偏置的電阻與電容并聯的模型,通過電容的充放電實現改變神經元的膜電位。如果神經元膜電位上升到激活閾值,那么就會導致神經元的激發,從而在輸出端產生一個脈沖信號,神經元膜電位會迅速下降到靜息電位。
圖1為LIF神經元等效電路。

圖1 LIF神經元等效電路
根據膜電位的變化,將LIF神經元的活動狀態分為3種:電荷泄漏、電荷積累和脈沖發射。且神經元的電荷泄漏和電荷積累過程可以使用數學公式進行表示,如式(1)所示
(1)
其中,Vm(t),Cm,Rm,I(t)分別為神經元膜電位、膜電容、膜電阻和充電電流;Vret為偏置電壓源,為神經元提供靜息電位。input1和input2,w1和w2分別為神經元的輸入的脈沖信號和對應權值,output輸出脈沖信號。
1.2 STDP規則
Spiking-timing-dependent-plasticity(STDP)[7]稱為突觸可塑性規則,是一種對生物神經元突觸變化規律的描述,來源于生物實驗的因果學習的規則。圖2是算法。

圖2 STDP規則
當滿足因果關系時,即:突觸前神經元(Npre)激活時間早于突觸后神經元(Npost)激活時間的時候,增加兩個神經元之間的連接權值;反之不滿足因果關系時,減弱連接權值。權值變化幅度與連接前后神經元激活時間的函數關系,如式(2)和式(3)所示
Δt=t2-t1
(2)
(3)
其中,t2,t1分別為Npost,Npre激活時間;τ為衰減速率;α為對稱度調整參數;μ為控制指數曲率的因子;λ為權值的學習率;w為突觸連接權值,如果w取值范圍不為區間[0,1],需要先進行歸一化。根據w與t的函數關系,可以得到STDP規則函數曲線,如圖3所示。

圖3 STDP規則函數曲線
2 脈沖神經網絡算法
2.1 基于STDP規則的權值學習算法
STDP是基于生物學因果關系的無監督學習[8],為了設計監督式學習算法,本文參考STDP規則[9],并對算法進行改進。通過添加一個“引導”神經元,調整激活時間t3,即可改變Npost神經元的激發時間t2,再根據STDP規則,從而達到了間接調整Npre與Npost的權值w1的目標。監督式學習算法實現方式如圖4所示。
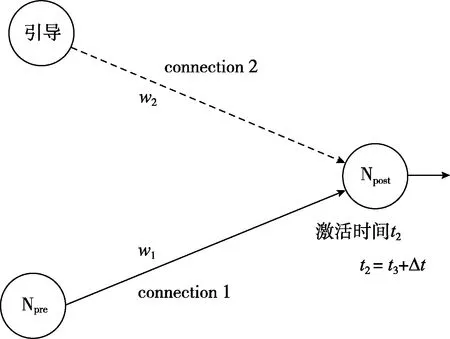
圖4 基于STDP規則的權值學習算法
監督式學習算法通過對引導神經元激活時間的控制,能夠達到對Npost神經元激活時間的調整,最終實現對connection1的增強或者抑制,圖5是權值增強和權值減弱的實驗。
首先,進行了權值增強實驗,采用引導神經元對兩個神經元之間的連接進行權值增強的訓練,如圖5(a)所示,通過引導神經元對連接后端神經元Npost的作用,能對神經元之間的連接起到明顯的增強效果,連接權值w1增長速度隨著迭代次數的增加而逐漸趨于穩定。
與權值增強實驗類似,采用抑制性引導神經元對兩個神經元之間的連接進行權值減弱的訓練,如圖所示,連接權值w1減弱速度也會隨著迭代次數的增加而趨于穩定,如圖5(b)所示。

圖5 權值增強實驗和權值減弱實驗
2.2 基于Hebb規則的結構學習算法
文章基于Hebb規則的基本原理[10,11],提出了基于Hebb規則的神經元連接算法。算法中規定,在同一輪仿真迭代周期內,如果兩個神經元的激活時間相近,時間差小于某一閾值,并且兩者之間未存在連接,則在這兩個神經元中間建立一條連接,連接的方向從先激活的神經元指向后激活的神經元。基于Hebb規則的神經元連接算法,如圖6所示。

圖6 基于Hebb規則的神經元連接
同時,在算法中規定神經元新連接的產生需要考慮位置因素,當兩個神經元位置超出距離閾值后,即便神經元活動存在一定的相關性,也不建立連接。而在結構學習算法中,也在網絡中添加了神經元的坐標信息,用于衡量神經元之間的位置關系。Hebb規則具體算法流程見表1。

表1 Hebb規則具體算法流程
3 非完美信息博弈——斗地主游戲
目前,人工智能在游戲方面取得了里程碑式的突破[12],但這些游戲的基本特征是游戲中玩家能夠獲得完美信息,在非完美信息的應用場景[13],目前仍是挑戰性課題,撲克游戲是典型的非完美信息博弈,本文將以斗地主游戲為例來驗證算法的可行性。
不同于傳統神經網絡,提前考慮了所有可能出現的狀態并制定對應策略[14],本文不是事先制定策略,而是通過根據SNN的特性生成仿生型網絡結構,通過SNN算法訓練網絡權值。在面對博弈時,考慮當前的游戲狀態,輸入到SNN網絡中,再每一步重新計算策略。通過這樣的仿生型網絡學習一個人的打牌能力,且最終結果是以擬人化程度作為評判網絡性能的標準,而非像傳統神經網絡采用勝率作為評判標準。
為此,本文提出了具有普適性的四層神經網絡結構,一種基于脈沖神經網絡在非完美信息條件下決策的方法。建立輸入層,對非完美信息條件下的信息進行預處理,將輸入信息轉換為脈沖信號,產生并激發輸入層神經元;建立規則層,將所有可能發生的事件劃分為樣本點,每個樣本點對應產生一個規則層神經元,將所有可以激發樣本點的輸入層神經元與該樣本點對應的規則層神經元全連接;建立決策層,在決策層生成神經元,決策層神經元個數和規則層神經元個數相等,將規則層神經元和決策層神經元一一對應,并根據脈沖神經網絡算法建立決策層層內連接;建立輸出層,根據決策層的網絡結構和權值輸出信號。如圖7所示,這種四層網絡結構簡單,不涉及大量計算,提高了非完美信息條件下決策的效率且準確度更高。
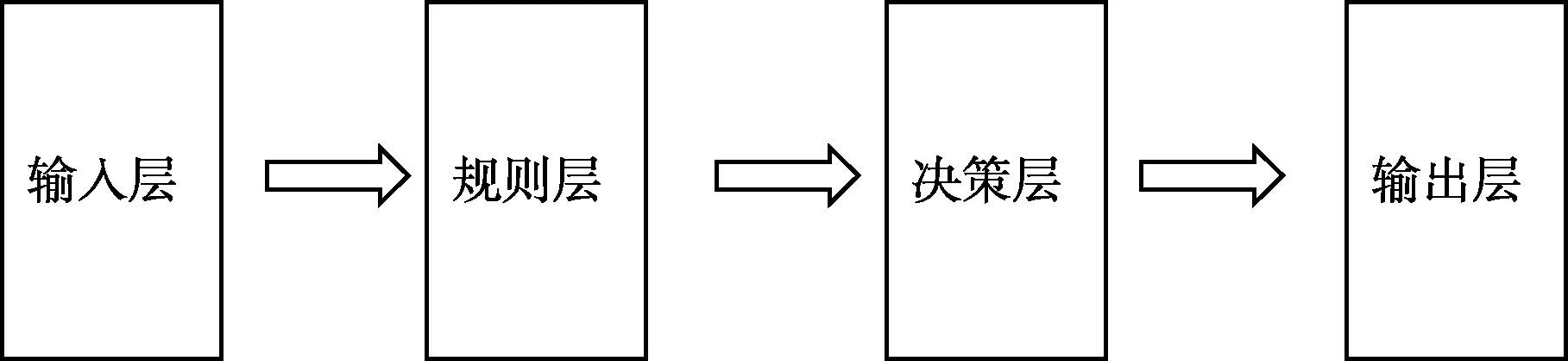
圖7 基于非完美信息條件下的四層脈沖神經網絡結構
3.1 基于脈沖神經網絡的斗地主叫牌
斗地主叫牌輸入信息為17張手牌,輸出信息為是否叫牌。根據上文提出的普適性四層網絡結構,整個叫牌網絡分為四層結構,如圖8所示。
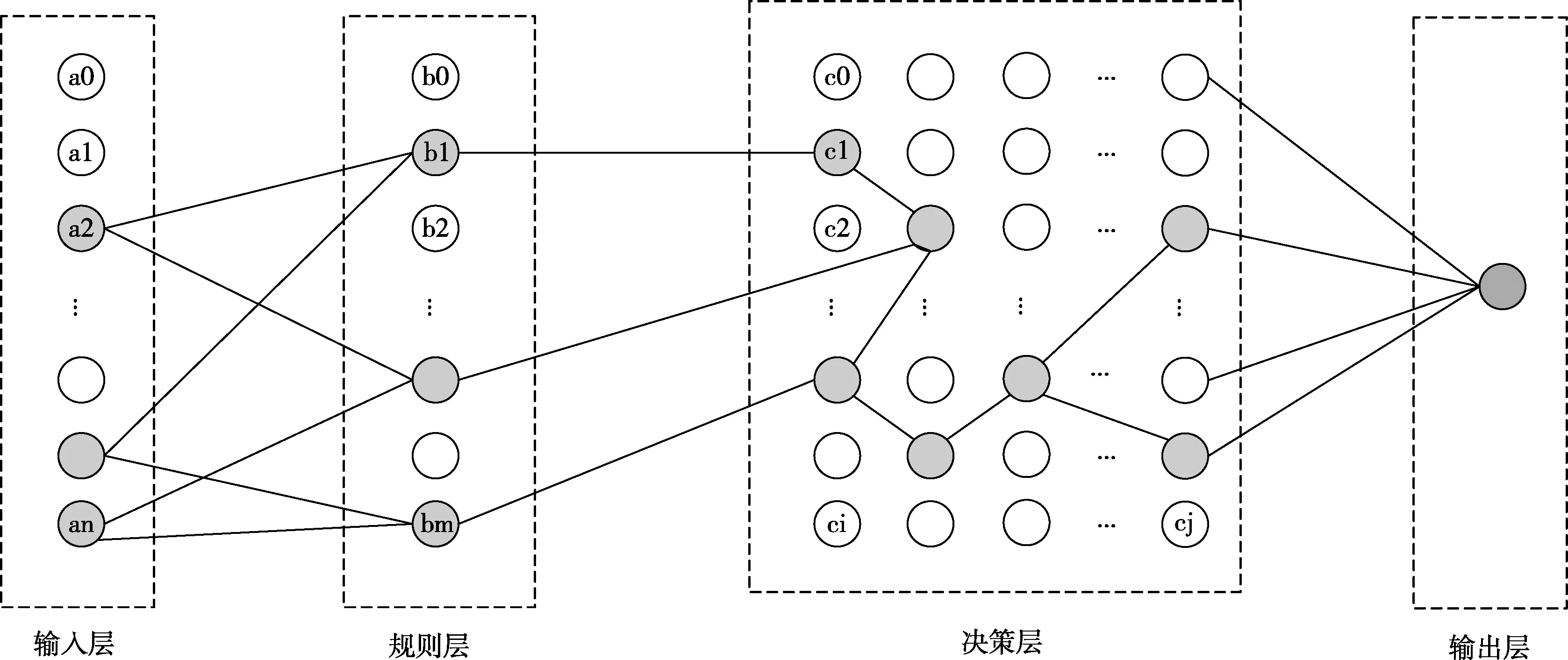
圖8 斗地主叫牌的四層網絡結構
網絡分為4層:
輸入層:載入原始數據,并對數據進行預處理,將卡牌轉換為脈沖序列。輸入層神經元個數54個。將54張牌進行數據處理,根據脈沖轉換規則,將每一種牌轉換為對應的神經元脈沖發射時間。
規則記憶層:將斗地主里的所有規則進行了定義。單張、雙王、炸彈、對子、三張、三帶一、三帶二、四帶一、四帶二、三連對、四連對、五連對、六連對、七連對、八連對、九連對、十連對、五張順子、六張順子、七張順子、八張順子、九張順子、十張順子、十一張順子、十二張順子、二連飛機、飛機帶翅膀、三連飛機、飛機帶兩對、四連飛機、三連飛機帶翅膀、五連飛機、三連飛機帶三對、四連飛機帶翅膀、六連飛機、四連飛機帶四對、五連飛機帶翅膀,共277個規則,對應277個神經元,并按照相應的規則連接輸入層和規則層。
決策層:也可以稱為推理層,對現有的牌進行組合,形成類似生物體的腦結構。在決策層中生成277個神經元,并以二維空間分布。神經元在空間位置分布上按照牌型優先級分布,如圖8的layer3所示,優先級是對斗地主規則牌型大小的排序等級。對叫牌貢獻大的牌型規則優先級為高,依次至對叫牌貢獻最小的牌型規則優先級為低。將規則層神經元和決策層神經元采用“one-to-one”的連接方式。
輸出層:一個輸出(1/0)。決策層神經元全連接至輸出層神經元。
網絡形成的決策層類似于生物體的大腦結構,具體決策層的形成方法是在網絡訓練過程運用基于STDP的權值學習算法和Hebb連接算法調整決策層內部的突觸連接關系和權值大小。具體為:在決策層中,運用Hebb規則,獲取兩個獨立神經元的位置,判斷兩個神經元的相對位置是否小于2,若大于2,神經元之間不建立連接,反之小于2時,獲取兩個獨立神經元的脈沖激發時間,計算激活時間差值是否小于時間閾值(1.0 ms),若是兩個神經元建立連接,并設置其權值為1180.0,反之不建立連接。在時間和空間的連接規則下,形成了決策層的層內連接關系。
通過STDP規則,訓練網絡的權值大小。在訓練過程中,設置決策層中優先級高的神經元連接到輸出層神經元的初始權值較大,反之優先級低對應的初始權值較小。根據輸出信號即是否叫牌來對決策層到輸出層的連接權值進行權值調整,若此輪訓練過程中叫牌,則增加引導神經元至輸出神經元的連接權值,根據本文改進的STDP規則,會增大決策層內神經元至輸出神經元的連接權值;不叫牌則反之減小權值,權值調節的大小如式(2)、式(3)所示。訓練完成后形成的網絡即可以實現斗地主叫牌功能。表2為斗地主叫牌算法流程。

表2 斗地主叫牌算法訓練流程
3.2 基于脈沖神經網絡的斗地主出牌
斗地主出牌相對于斗地主叫牌有更多的不確定性因素。根據游戲規則,玩家出牌有兩方面的影響:一是玩家手中的牌;二是上家的出牌情況。上文提出的普適性的脈沖神經網絡的四層網絡結構同樣適用于斗地主出牌階段,圖9是基于四層脈沖神經網絡設計的斗地主出牌框架。
輸入層:斗地主出牌受兩方面的影響,一是玩家手中的牌;二是上家的出牌情況。所以輸入層有兩個,為了方便區分,我們將上圖的網絡分為本家出牌網絡,其輸入信號是玩家手牌信息,以及上家網絡,其輸入信號是上家的出牌。
規則層:將斗地主里的所有規則進行了定義。單張、雙王、炸彈、對子、三張、三帶一、三帶二、四帶一、四帶二、三連對、四連對、五連對、六連對、七連對、八連對、九連對、十連對、五張順子、六張順子、七張順子、八張順子、九張順子、十張順子、十一張順子、十二張順子、二連飛機、飛機帶翅膀、三連飛機、飛機帶兩對、四連飛機、三連飛機帶翅膀、五連飛機、三連飛機帶三對、四連飛機帶翅膀、六連飛機、四連飛機帶四對、五連飛機帶翅膀,共277個規則。本家出牌網絡和上家網絡的規則層分別對應各自的規則層,如圖9所示。且由于本家出牌時,要考慮不同情況將本家的規則層layer2分為3個通道,不同的游戲場景下激活相應通道的規則層,3種場景分別是:
其次是或將影響行業復蘇。在集運市場,班輪公司在經過整合后對投放市場的運力達成更多共識,一直偏離價值的運價也終將向正常范圍靠近。如果中美貿易戰全面升級,美國將征收關稅對象的產品清單向低附加值貨物擴展,將給班輪公司帶來運量和運價的雙重壓力,這將打破集運市場周期復蘇的勢頭。隨著下降趨勢持續推進,將從集運市場波及散運以及油運市場,從而進一步影響整個航運市場。
(1)本輪游戲,本家玩家主動出牌,沒有上家出牌。
(2)本輪游戲中,本家屬于跟牌,且出牌的上家是敵方。
(3)本輪游戲中,本家屬于跟牌,且出牌的上家是友方。
決策層:將符合上家出牌規則的本家網絡layer2中的神經元輸出至決策層。
輸出層:輸出出牌結果。
其中輸入層和輸出層的處理比較簡單,不做介紹,將主要介紹規則層和決策層。
3.2.1 斗地主出牌網絡的規則層
斗地主的出牌規則層是對輸入數據規則的判定,由于輸入層分為了本家和上家兩個輸入模塊,所以對于規則層也需要兩個規則層模塊分別對兩個輸入進行規則的劃分判定,如圖9所示。

圖9 基于脈沖神經網絡的斗地主出牌框架
對上家網絡的分析,根據規則層判斷出上家出牌的大類規則即可,所以上家網絡規則層與叫牌階段的規則層分析及規則的劃分一致。
(2)本家網絡的規則層
由于本家網絡在出牌的時候,針對不同的情況有不同的處理方法,本文對情景進行劃分,分為以下3種場景:本輪游戲,本家玩家主動出牌,沒有上家出牌;本輪游戲中,本家屬于被動跟牌,且出牌的上家是敵方;本輪游戲中,本家屬于被動跟牌,且出牌的上家是友方。
對于以上的3張出牌情況將本家網絡的規則層分成3個通道,每一種通道對應一種出牌情況,輸入層與每一個通道的規則的連接關系與叫牌階段的一致,即每一個通道都與本家網絡的輸入層建立連接關系,輸入層至規則層的連接情況和權值與斗地主叫牌時的連接一致。3個通道分別代表的是3種場景,所以規則層的不同通道的神經元不建立連接關系。
且本家出牌的規則層受到上家出牌規則的限制,所以本家的layer2激發情況受到上家網絡layer2的限制,只有和其規則保持一致,且牌型比上家的大的神經元才能被激發傳遞到下一層網絡。
3.2.2 斗地主出牌網絡的決策層
本家規則層的3個通道分別與決策層連接,連接方式為“one-to-one”的形式,初始狀態決策層內部無連接關系,通過脈沖神經網絡的學習算法,在決策層內部生長出新的突觸,形成類似生物體的腦結構。通過生成的決策網絡學習輸入數據的出牌能力。在決策層中生成277個神經元,并以二維空間分布,神經元在空間位置分布上按照牌型優先級分布,優先級是對斗地主規則牌型大小的排序等級。對叫牌貢獻大的牌型規則優先級為高,依次至對叫牌貢獻最小的牌型規則優先級為低,和叫牌的決策層的優先級分布一致。
通過網絡的結構和權值訓練形成類腦的出牌決策層。
訓練的過程是:初始化出牌網絡結構。輸入玩家的手牌和上家的出牌情況,將信號依次輸入至規則層,然后至決策層,在決策層內部根據Hebb生長算法,生成決策層內部的突觸連接,根據Hebb的突觸修正公式調整決策層內部的連接權值。再通過STDP規則,訓練決策層至輸出層網絡的權值大小。在訓練過程中,設置決策層中優先級高的神經元連接到輸出層神經元的初始權值較大,反之優先級低對應的初始權值較小。根據輸出信號即數據集的出牌神經元id找到其對決策層的神經元,增大該神經元至輸出層的連接權值,減小與其它決策層神經元的連接權值。訓練完成后形成的網絡即可以實現斗地主出牌功能。
4 斗地主實驗結果
4.1 斗地主叫牌實驗結果
在斗地主實驗中,我們以生成決策層的層內連接及調整決策層到輸出層的連接權值為主要目標,通過斗地主叫牌網絡實現對一個人叫牌能力的學習。
實驗采用的是一名真人的叫牌數據,共計1700組叫牌數據,將其中1500組數據作為訓練集數據,200組數據作為測試集。實驗以擬人化程度作為評判標準,如式(4)所示

(4)
圖10是訓練生成的決策網絡,決策層最初沒有內部連接。在圖中,當訓練集為10、100和1500時,分別獲得決策層中的連接關系。可以看出,在Hebb規則的作用下,連接的數量正在增加,體現出了決策層的學習過程,其中每個網格點代表一個神經元。

圖10 訓練生成的叫牌決策網絡
可以看到,決策層的層內連接主要在網絡的上方部分,即網絡優先級高的神經元建立的內部連接較多,對叫牌貢獻大。優先級低的神經元極少建立內部連接,對叫牌貢獻小。與理論分析一致。
我們以一組數據為例,對實驗進行測試模擬。測試集為2KKKKJJJJ55553333。
圖11為輸入層神經元的整體激發情況,輸入層對輸入數據進行預處理并將輸入數據轉換為脈沖信號,從圖中可以看到此輪游戲中,輸入層神經元膜電位隨時間的變化曲線,統計膜電位超過閾值電壓的神經元id,得到輸入層被激發的神經元id。
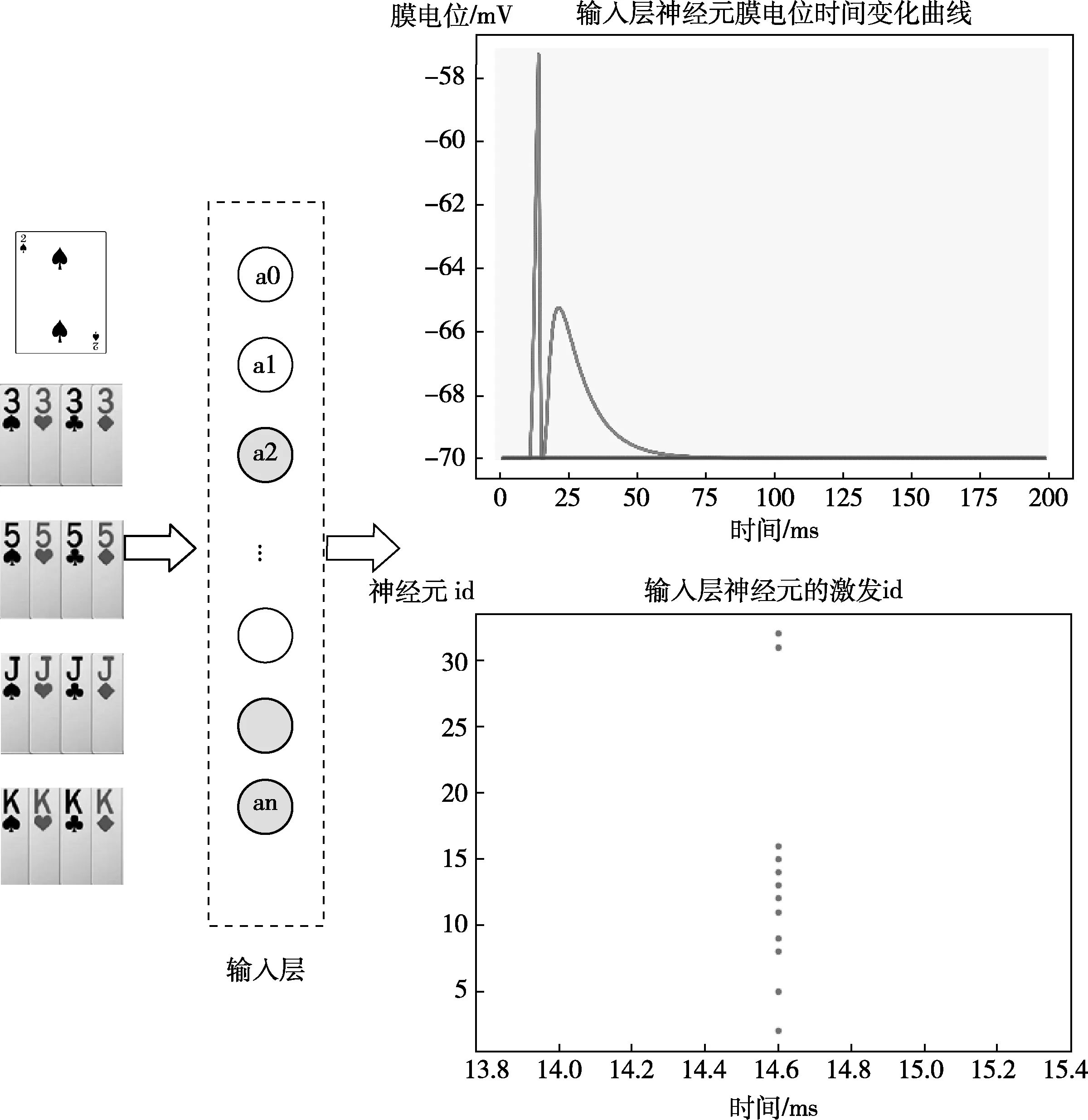
圖11 輸入層神經元的整體激發情況
通過斗地主叫牌網絡,脈沖信號依次被傳入規則層、決策層和輸出層。
脈沖信號被傳入規則層,規則層神經元的激活情況如圖12所示,規則層神經元的膜電位隨時間的變化曲線如圖12(a)所示,規則層被激發的神經元id如圖12(b)所示,通過激發神經元的id可以得到在此次游戲中被激發的規則有3,33,333,3333,5,55,555,5555,J,JJ,JJJ,JJJJ,K,KK,KKK,KKKK,2,此輪規則層共13個神經元被激發。

圖12 規則層神經元的激活情況
通過圖10中的決策層網絡,輸出層神經元被激發,即該輪游戲中,斗地主機器人輸出是叫牌,和測試集數據一致。
通過200個測試數據的測試,測試過程見表3。

表3 斗地主測試算法
最終得到擬人化程度為85%,實驗結果見表4。

表4 斗地主叫牌實驗數據
4.2 斗地主出牌實驗結果
出牌階段主要以訓練玩家本家網絡的決策層內部突觸連接和訓練連接權值為主,以及訓練決策層與輸出層的連接權值。通過網絡的自生長和自適應算法生成一個可以學習人類打牌的智能體。隨著輸入數據的訓練量增大,決策層內部建立的連接關系變多。圖13是對網絡進行2500組出牌數據訓練得到的網絡結構。

圖13 出牌決策層網絡結構
斗地主出牌測試階段,網絡出牌不具有唯一性,由于網絡會對過去已知知識進行學習,所以,會隨著輸入數據量的增大而發生動態變化。因此出牌的測試僅進行功能性測試,沒有量化指標。
以一組數據為例進行功能驗證。以此輪游戲玩家主動出牌,且以手牌為4 5 5 6 6 6 7 10 J K A 2 小王 大王為例,沒有上家出牌。得到的規則層神經元的膜電位隨時間的變化情況如圖14所示。將規則層中被激發的神經元將信息傳遞到決策網絡,最終得到的輸出結果如圖15所示。可以看到輸出層的227個神經元僅有一個神經元被激發,且該神經元的id代表的信息是輸出結果是4,出牌網絡的功能性正常。

圖14 出牌規則層神經元的膜電位隨時間的變化
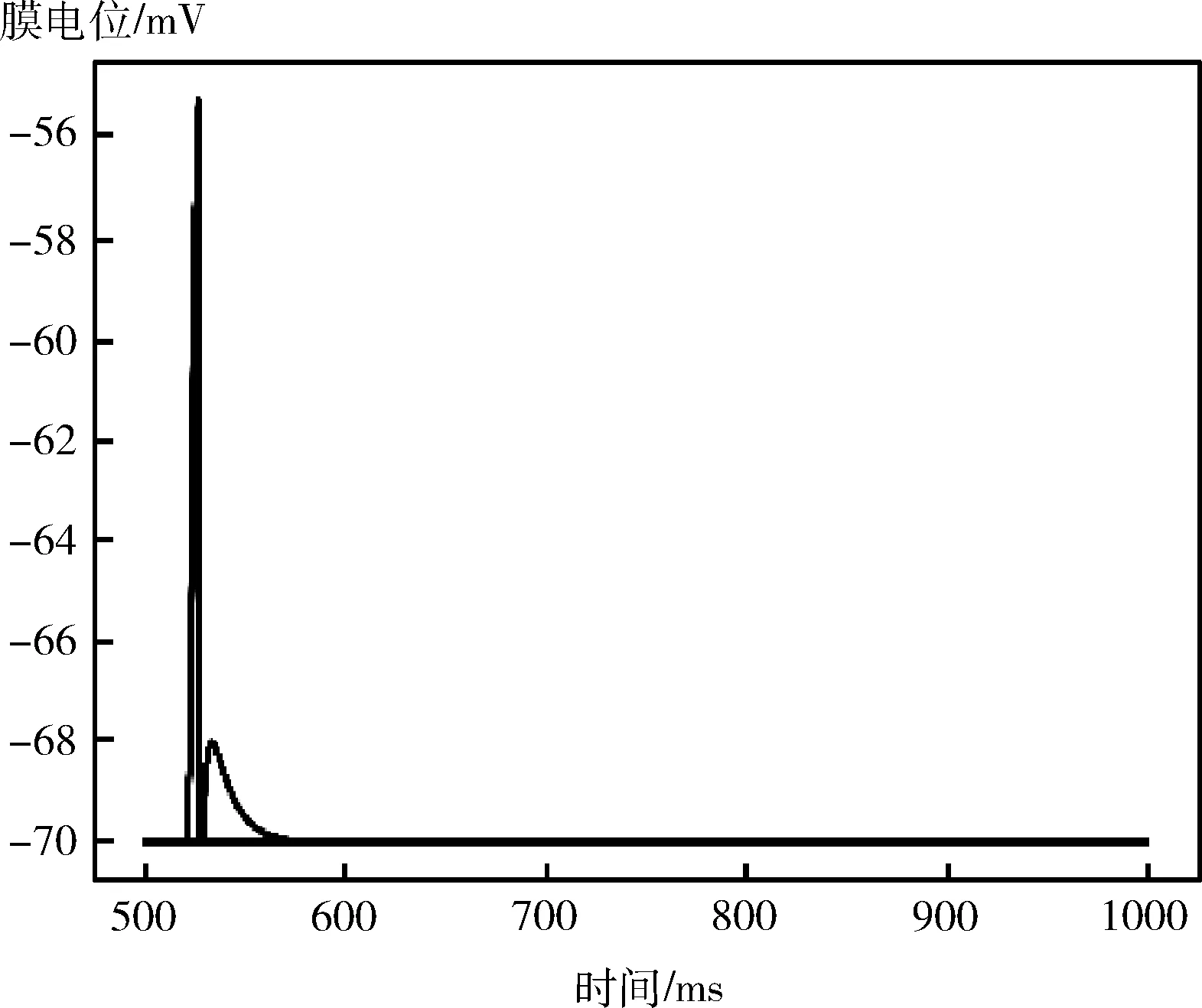
圖15 輸出層的神經元激發情況
與傳統神經網絡進行對比,不同于傳統神經網絡,提前考慮了所有可能出現的狀態并制定對應策略,本文不是事先制定策略,而是通過根據SNN的特性生成仿生型網絡結構,通過SNN算法訓練網絡權值。在面對博弈時,考慮當前的游戲狀態,輸入到SNN網絡中,再每一步重新計算策略。傳統AI通過所有的牌型評分,每一種牌型都有其對應的出牌結果,選擇最優結果,是確定性的數據分析和運算,不具備智能性。而SNN網絡的斗地主:通過形成類似人腦結構的決策層網絡,建立網絡內部的連接關系和權值,具有動態學習能力,且智能程度很高。
5 結束語
綜上,創新性點在于提出了一種基于STDP規則的權值學習算法和基于Hebb規則的結構學習算法,這些算法解決了目前脈沖神經網絡的學習算法的不完備性。結合SNN特性,將算法引入不完美信息博弈中,以斗地主撲克游戲為例,實現了一個擬人化的斗地主機器人,該機器人相對于傳統AI,更加的智能,并非事先制定策略,而是學習一個人的斗地主能力,生成叫牌決策網絡,最終的擬人程度為85%,在出牌網絡中,訓練出的網絡的功能性是正常的,下一步工作會在當前算法的基礎上,加入增強學習的算法,繼續完善斗地主叫牌和出牌網絡,使得其智能化程度更高。
猜你喜歡
作文周刊·小學一年級版(2022年28期)2022-05-30 10:48:04
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
法律方法(2019年3期)2019-09-11 06:26:16
中國外匯(2019年7期)2019-07-13 05:44:52
幸福(2018年33期)2018-12-05 05:22:42
環球飛行(2018年7期)2018-06-27 07:26:14
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
運動(2016年6期)2016-12-01 06:33:42
