基于機器學習的源程序自動標注方法
2021-09-15 11:20:00吳軍華
計算機應用與軟件 2021年9期
王 瑞 吳軍華
(南京工業大學計算機科學與技術學院 江蘇 南京 211816)
0 引 言
隨著互聯網的高速發展,軟件開發也越來越火熱,并伴隨出現了大量開源代碼庫[1-2]。擁有完善注釋的源程序能夠提高軟件系統的可維護性[2-4],加快軟件開發速度。但是當前情況下僅有不到20%的程序有對應的注釋,所以急需開發一種自動生成功能描述性注釋的方法。
文獻[5]提出一種對程序源代碼自動生成功能描述性注釋的方法,通過在GRU神經網絡中增加一個選擇門,從特征向量中選擇有關于功能且與當前狀態相關的特征進行注釋,本質上是一種翻譯任務。文獻[6]提出一種基于模板的生成注釋方法,通過模板對程序和注釋進行處理,遇到不符合模板的代碼和注釋則生成的注釋效果較差,適用范圍太窄。文獻[7]提出一種基于數據挖掘的源代碼注釋自動生成方法,依據文中描述函數注釋關鍵特性的兩種提取規則自動生成函數整體注釋,但該方法僅限于自動生成Linux內核函數的注釋,普遍性不強。文獻[8]提出一種使用神經網絡訓練數據并且利用完全驅動來生成注釋的方法,對C語言代碼片段和SQL查詢語句進行自動注釋,這種方法是將源代碼當成了普通的文本,沒有提取任何程序設計語言所獨有的特征與特點,在源代碼特征提取方面存在缺陷。針對目前存在的問題,本文采用基于LSTM-GRU網絡的機器學習編碼解碼模型,對程序進行自動注釋。
1 方法簡介
本文將Java程序作為研究對象。Java程序注釋主要有以下幾個方面[9]。(1) 類(接口)注釋。描述類(接口)的作用及其用法和使用環境、作者、版本、加入的版本、參考類等。(2) 變量注釋。描述變量的作用。(3) 方法注釋。描述方法的作用、使用方式、返回值、參數說明、用法實例等。
首先,采用雙編碼器對源程序數據集進行預處理,生成特征向量;利用分詞技術、整合成字典并運用編碼技術對中文注釋關鍵詞集進行預處理。然后,利用基于GRU網絡的解碼器進行模型訓練,通過不斷地對參數進行調整,使程序與注釋形成映射關系。
2 源程序自動標注雙碼器模型
本文提出一種基于LSTM-GRU網絡的編碼器-解碼器模型,模型如圖1所示。

圖1 編碼器-解碼器模型
模型主要應用了LSTM和GRU。GRU[10]和LSTM[11]是RNN的兩種主要變體,其目的是對長序列中的長期依賴關系進行建模。RNN是序列建模的重要工具,已成功地應用于多種自然語言處理任務。與前饋神經網絡不同,RNN可以對序列元素之間的依賴關系進行建模。
2.1 源程序特征提取
源程序采用雙編碼器進行處理:序列編碼器(Bi-directional Gated Recurrent Unit,Bi-GRU)、TreeLSTM結構樹編碼器,不僅可以較精確地獲得程序的序列信息,還能夠得到重要的結構信息,彌補了以往方法注釋不精確的缺陷。
定義1程序訓練集為P={P1,P2,…,Pn},程序Pm(1≤m≤n)的源程序表示向量集為Vm={vm1,vm2,…,vmi},注釋關鍵詞表示向量集為Km={km1,km2,…,kmi}。
2.1.1源程序序列特征向量提取
這里采用Bi-GRU序列編碼器提取源程序的序列特征信息。在序列編碼器中,利用GRU可以解決RNN中出現的梯度消失問題。


圖2 GRU單元模型
而Bi-GRU是由反向GRU與正向GRU結合形成。通過兩個方向相反的GRU可以更好地理解上下程序之間的信息與聯系,解決了單向GRU不能利用下一時刻編碼信息的問題。將Bi-GRU層幾個單變量連接的特征向量作為序列編碼器的表示向量Vs。模型如圖3所示。

圖3 Bi-GRU序列編碼器模型
2.1.2源程序結構特征向量提取
源程序結構特征向量采用TreeLSTM結構樹編碼器進行提取。LSTM網絡具備長期記憶功能。整體流程:遺忘→根據現有的輸入和上一個cell的輸出更新狀態→根據現有的狀態輸出預測值。
Java程序具有三種控制結構,包括順序、選擇(if和switch語句)和循環(while、do while和for語句)結構[12-16]。本文主要針對這三種結構進行特征提取。
代碼程序可以抽象為一系列程序節點的集合。程序示例如算法1所示,其中帶圈數字是各個位置表示節點的標號。
算法1代碼程序
標號 voideven()
① {
② ints=0,i=1;
③ for(i<100;i++)
{
④ if(i%2==0)
{
⑤ s+=i;
}
else
{
⑥ s=s;
}
⑦ }
⑧ }
算法1對應的節點控制流圖如圖4所示,其中:head表示語句的開始;end表示語句的結束;com表示普通表達式語句。

圖4 程序轉換節點控制流圖
本文中使用的TreeLSTM擴展了基礎LSTM網絡,使其可以提取樹形結構網絡的特征信息。圖5為TreeLSTM編碼器模型。

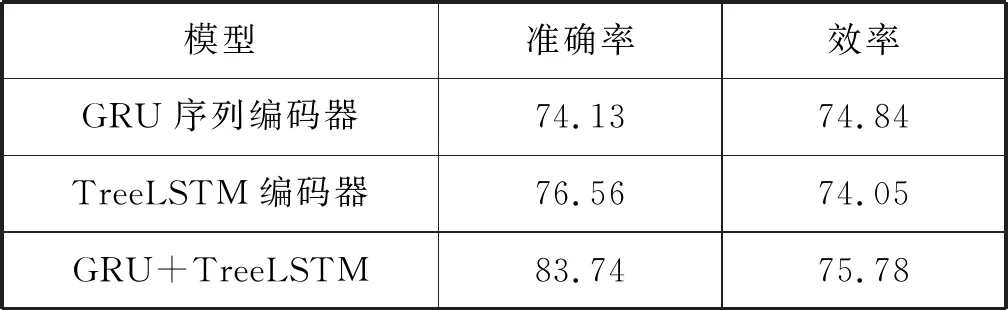
圖5 結構樹編碼器模型(1 根據源程序的結構信息與程序語句構建對應的解析樹,對應的抽象語法樹序列為x=(x1,x2,…,xn),從所有葉子節點開始從底向上經過LSTM網絡遍歷至根節點,最終生成的向量用Vt表示。 TreeLSTM更新后的規則如式(1)-式(6)所示,其中C(j)表示抽象語法樹中第j個節點的孩子節點集合。 (1) 遺忘: fjk=σ(Wf·xj+Uf·hk+bf) (2) 輸入: (3) 輸出: (4) 隱藏: ht=oj×tanh(cj) (5) 單元狀態: (6) 式中:×表示矩陣元素相乘;xt是本時刻輸入的字;Wf、Uf、Wi、Ui、Wo、Uo分別為各個門的權重矩陣;bf、bi、bo是偏置向量;σ是邏輯函數。 計算圖如圖6所示。 圖6 TreeLSTM計算圖 注釋關鍵詞提取[17-19]包含四步。 1) 對程序中所有注釋進行提取:(1) 遇到“//”,(2) 遇到“/*”開始,遇到“*/”結束。 2) 對提取出的詞進行關鍵詞提取。本文采用基于機器學習的雙向LSTM的分詞方法提取關鍵詞。對于分詞任務來說,注釋中每個詞都是平權的,所以本文使用雙向LSTM進行分詞。LSTM接受相同的輸入,但訓練方向不同(從左向右做一次LSTM,然后從右向左做一次LSTM),并將它們的結果連接為輸出。圖7為訓練模型。 圖7 雙向LSTM模型 結果舉例如下: Print(cut_word)(‘內層循環控制一次排序次數’)結果:[‘內層’,‘循環’,‘控制’,‘一次’,‘排序’,‘次數’] 3) 利用Python對分詞后的結果進行降重。 4) 將分詞、降重之后的詞整合成字典并進行編碼,然后根據每個單詞的編號生成其獨有的one-hot向量。 字典是一種可變容器模型,可存儲任意類型數據。整個字典包含在花括號“{}”中。 定義2字典格式為d={k1:v1,k2:v2,…},其中:k(key)為鍵,v(value)為值,且鍵是唯一的,而值不唯一。 解碼器使用單向GRU作為注釋生成模型。將兩個編碼器所得到的向量進行拼接,作為輸入初值V0。 V0=[Vs,Vt] (7) 圖8為單向GRU-decoder模型,在訓練過程中,本文需要將誤差反饋給前面的各層,即利用反向傳播算法,通過對權重不斷地修改來減小誤差,從而實現對神經網絡的訓練,令Vm和Km形成相互映射的關系。 圖8 單向GRU-decoder模型 為了有效評估模型,我們選用了來自www.Pudn.com聯合開發網的高質量數據集,在此網站上約有116 059個實現不同功能的Java文件,且有準確的中文注釋。程序數量足夠大、注釋足夠精確是生成合理訓練模型重要的一部分。利用爬蟲技術收集11 577個Java編程和對應的注釋作為數據集。我們將數據集劃分為訓練集和測試集,訓練集包含10 000對源代碼和注釋,用于訓練模型,測試集包含剩下的1 577對源代碼和注釋,用于評估模型的性能及注釋生成效果[20]。 在此次研究中,使用Keras框架構建神經網絡[21-23],程序主要在CPU顯卡、Python3.68的編譯環境下運行。進行充分的實驗,在解碼器部分對比了不同類型的循環單元:GRU和LSTM。 準確率和效率是評估本次研究中設計模型優劣的重要指標。 GRU是LSTM網絡的一種非常有效的變體,在本次實驗中,我們分別在三種模型下,查看自動注釋的準確率和效率。表1、表2分別展示了當解碼器為單向GRU單元、單向LSTM單元,且數據量為10 000個Java文件時三種模型的對比結果。 表1 利用GRU-decoder進行程序自動注釋(%) 表2 利用LSTM-decoder進行程序自動注釋(%) 可以看出,不管是準確率還是效率,GRU-decoder與LSTM-decoder得到的結果差異都較小,即GRU與LSTM網絡效果近似,但效率方面GRU略微優勝于LSTM。 通過點線圖可以更直觀地觀察實驗效果。 如圖9所示,在雙編碼器狀態下,當數據量較小時,GRU-decoder和LSTM-decoder的效率比較接近,數據量增大后,稍微拉開一些差距,但是差距并不大。 圖9 GRU/LSTM decoder效率對比圖 圖10為在GRU-decoder條件下三種編碼器模型的準確率對比圖,可以很明顯看出利用雙編碼器對程序進行預處理之后的準確率更高。 圖10 GRU-decoder條件下三種模型準確率對比圖 本節通過表3展示一些測試集案例,進一步說明本文方法的可行性。 表3 測試集案例 本文結合編碼器-解碼器提出一種基于機器學習的LSTM-GRU程序自動標注研究方法。與既有技術相比,利用機器學習不僅提取源程序的序列特征,而且提取了重要的結構特征;注釋關鍵詞集為提取的中文詞庫,與以往的機器翻譯有所區別。實驗表明,本文方法可以較好地對Java程序進行自動中文標注,提高可讀性,且訓練數據集越多,準確率越高。下一步將考慮在TensorFlow框架下,通過結合其他神經網絡或加入Attention機制對源程序進行處理,且擴大數據集來進一步提高準確率和效率;同時對其他程序語言進行測試,檢測本文模型的適用范圍。
2.2 注釋關鍵詞提取


2.3 注釋生成模型

3 實 驗
3.1 數據集
3.2 實驗設置
3.3 實驗結果



3.4 案例演示

4 結 語
