一致性哈希算法的對比研究
2021-09-14 00:14:25潘子浩
電腦知識與技術(shù) 2021年22期
潘子浩


摘要:分布式存儲系統(tǒng)中為了實現(xiàn)高可用、高性能和高擴展性,系統(tǒng)內(nèi)數(shù)據(jù)布局和負載均衡是關(guān)鍵的技術(shù)問題。一致性哈希算法是解決此類問題行之有效的方法。將對比研究幾種一致性哈希算法,包括基本和帶虛擬節(jié)點的一致性哈希,微信存儲系統(tǒng)中應(yīng)用的一致性哈希和谷歌跳躍一致性哈希。對微信存儲應(yīng)用的一致性哈希進行了改進。
關(guān)鍵詞:一致性哈希;虛擬節(jié)點;跳躍一致性哈希
Abstract: In order to achieve high availability, high performance, and high scalability in distributed storage systems, data layout and load balancing in the system are key technical issues. The consistent hashing algorithm is an effective way to solve such problems. Several consistent hashing algorithms will be studied and compared, including basic consistent hashing, consistent hashing with virtual nodes, consistent hashing used in WeChat storage systems and Google jump consistent hashing. The consistent hashing used in WeChat is improved.
Keywords: Consistent hashing; Virtual node; Jump consistent hashing
分布式存儲系統(tǒng)發(fā)展過程中,遇到了多個方面的挑戰(zhàn),其一是數(shù)據(jù)分散存儲在系統(tǒng)中,當(dāng)系統(tǒng)面對海量讀寫請求時,如何保障系統(tǒng)的負載均衡避免出現(xiàn)數(shù)據(jù)傾斜。第二為應(yīng)對系統(tǒng)流量的增長和萎縮,集群系統(tǒng)需要能夠動態(tài)添加和刪除節(jié)點,在保持負載均衡的同時實現(xiàn)數(shù)據(jù)的最小化遷移。一致性哈希算法因為具有良好的均衡性和一致性,在分布式存儲系統(tǒng)中受到廣泛的應(yīng)用。
基本一致性哈希算法在Kager于1997年論文[1]中提出并其后應(yīng)用于Danamo和Switf等系統(tǒng)后,衍生了多種優(yōu)化改進的算法,包括帶虛擬節(jié)點的一致性哈希,微信核心業(yè)務(wù)存儲系統(tǒng)使用的一致性哈希,谷歌跳躍一致性哈希,maglev一致性哈希,負載有界一致性哈希,以及其他改進的一致性哈希算法等。對上述的部分一致性哈希算法,論文將從均衡性和一致性兩個方面進行對比研究,并對微信存儲系統(tǒng)使用的一致性哈希進行了優(yōu)化。其中均衡性是指數(shù)據(jù)經(jīng)過哈希后能盡可能分散到所有服務(wù)器節(jié)點中,每個服務(wù)器處理的數(shù)據(jù)相當(dāng),均衡的算法能最大化系統(tǒng)利用率。一致性是指系統(tǒng)增加節(jié)點需要對數(shù)據(jù)key進行重新映射,數(shù)據(jù)key只能保留在原有節(jié)點或者移動到新節(jié)點上,不能移動到其他的節(jié)點上。
1算法對比
1.1基本一致性哈希和帶虛擬節(jié)點的一致性哈希
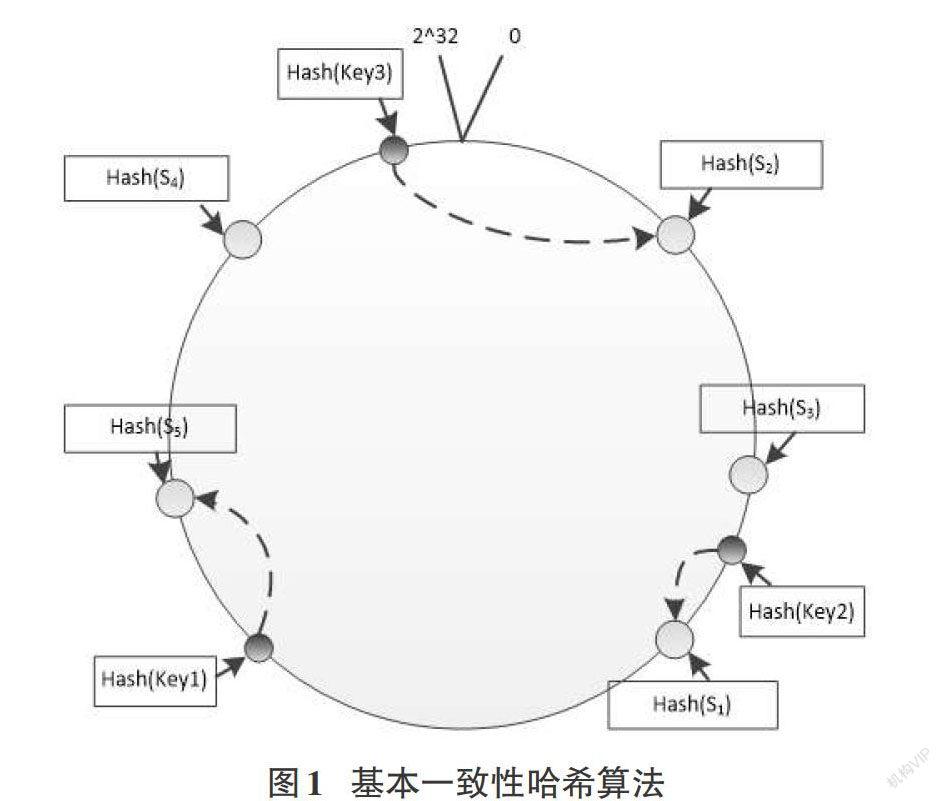
基本的一致性哈希算法原理如圖1,算法過程如下:
(1)設(shè)置一個地址空間范圍為0~(232-1)的哈希環(huán);
(2)使用節(jié)點的特征值(一般使用節(jié)點ip地址)計算哈希值,映射到哈希環(huán)上的一點。如圖1所示節(jié)點S1,其ip地址經(jīng)過哈希后落入哈希環(huán)上一點。對每個節(jié)點都使用同樣的方法映射到哈希環(huán)上;
(3)對存取數(shù)據(jù)key使用相同的哈希函數(shù)計算哈希值映射到哈希環(huán)上,以此位置順時針查找第一個落入到哈希環(huán)的節(jié)點。圖1中key3經(jīng)過哈希后順時針找到了S2節(jié)點。
基本一致性哈希算法并不均衡[2],在哈希環(huán)上復(fù)制虛擬節(jié)點的方法可以改善此算法的均衡度[3],其思想是將一個節(jié)點(也稱為實際節(jié)點或者實節(jié)點)在哈希環(huán)的不同位置上放置多個拷貝(稱為虛擬節(jié)點),并調(diào)整上述算法的第二步,使用實節(jié)點對應(yīng)虛擬節(jié)點的特征計算哈希值映射到哈希環(huán)(比如使用“192.168.1.100#1”作為192.168.1.100實節(jié)點編號為1的虛擬節(jié)點的特征),對每個實節(jié)點設(shè)置一定數(shù)量的虛擬節(jié)點映射到哈希環(huán)上,而要查找數(shù)據(jù)key對應(yīng)的實節(jié)點,是先通過其哈希值順時針找到虛擬節(jié)點再找到對應(yīng)的實節(jié)點。
顯然,新添加一個節(jié)點映射到哈希環(huán)上時,只有這個節(jié)點的哈希值(或者其對應(yīng)虛擬節(jié)點的哈希值)與逆時針方向的前一個哈希值之間的數(shù)據(jù)key會被重新映射到新的節(jié)點,其他數(shù)據(jù)key繼續(xù)保留在原有節(jié)點,兩種算法都滿足一致性的要求。
關(guān)于均衡性,從圖1可以看到,落入節(jié)點的數(shù)據(jù)key的數(shù)量,與每個節(jié)點在哈希環(huán)中負責(zé)的地址空間密切相關(guān),一致性哈希算法的均衡度,可由節(jié)點在哈希環(huán)負責(zé)的地址空間的差異來度量。在實際應(yīng)用中,分布式系統(tǒng)一般是由相同配置的服務(wù)器節(jié)點構(gòu)成,為了提高節(jié)點利用率和減少運營成本,要求選用均衡度較好的一致性哈希算法,另外按照木桶理論,分布式系統(tǒng)最大處理能力由最先進入過載的節(jié)點決定,也就是負載最高的節(jié)點決定了集群整體的性能,而在不考慮熱點數(shù)據(jù)情況下,節(jié)點的負載與其負責(zé)的地址空間成正比例關(guān)系。因此論文用三個與地址空間有關(guān)的指標(biāo)來衡量算法的均衡度:集群中最大地址空間與最小地址空間的比值R1,地址空間值與平均值相差10%、2%以內(nèi)的節(jié)點數(shù)量在總節(jié)點數(shù)的比例R2和R3。
表1展示了使用md5+fnv1_32函數(shù)對節(jié)點或虛擬節(jié)點特征值進行哈希,通過程序統(tǒng)計得到兩種算法在不同節(jié)點數(shù)配置下系統(tǒng)的R1和R2。ip地址和哈希函數(shù)的不同對統(tǒng)計結(jié)果會產(chǎn)生一些變化,但不會影響整體的結(jié)論。
基本一致性哈希算法的一般趨勢是R1值隨著節(jié)點數(shù)的增加而急速增加,此外R2值都比較低,意味著使用此算法的系統(tǒng),其節(jié)點間的負載是非常不均衡的。比如30節(jié)點下,R1已超過了100,系統(tǒng)節(jié)點間會出現(xiàn)負載差異百倍的情況。帶虛擬節(jié)點的一致性哈希算法均衡度得到了明顯的改善,如30個實節(jié)點每個配置30個虛擬節(jié)點,R1已經(jīng)降低到了2以下,遠低于基本一致性哈希中的R1。此外在實節(jié)點數(shù)確定時,虛擬節(jié)點數(shù)的增加可以降低R1和提高R2,提高節(jié)點間均衡度;但虛擬節(jié)點數(shù)確定時,系統(tǒng)增加實節(jié)點時則會升高R1和降低R2,降低節(jié)點間均衡度。但考慮系統(tǒng)的復(fù)雜性,虛擬節(jié)點數(shù)并不會無限制的提高,實際應(yīng)用中每個實節(jié)點配置100個虛擬節(jié)點是一個常用的配置。在此配置下,系統(tǒng)并非完全均衡,比如超過30個實節(jié)點的集群,R1超過了1.5,R2低于0.7,意味著系統(tǒng)會出現(xiàn)高負載是低負載1.5倍的情況,并且超過30%的機器負載偏離了平均負載的10%。
