基于自編碼器的對抗樣本生成模型
2021-09-14 00:14:25陳夢悅
電腦知識與技術 2021年22期
關鍵詞:深度學習
陳夢悅
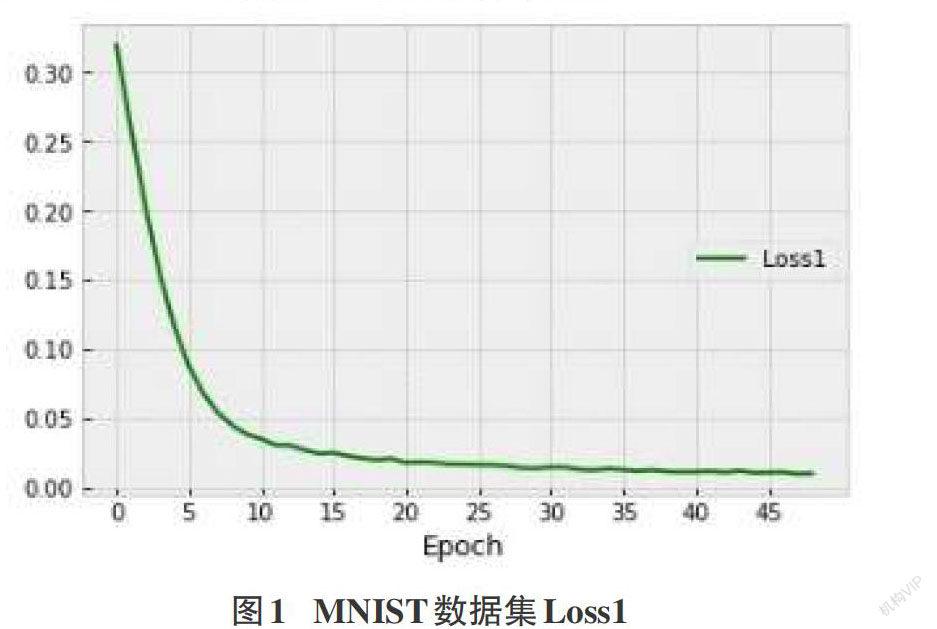
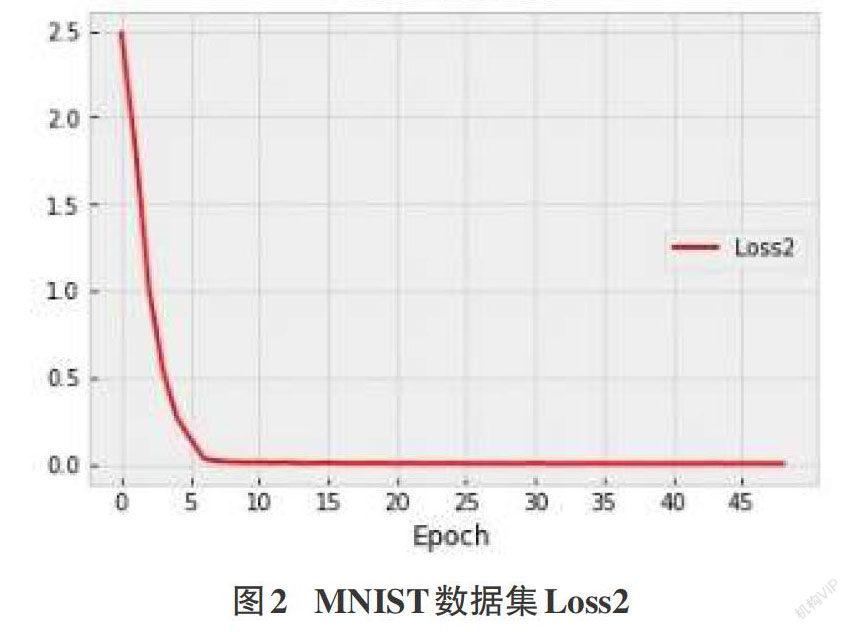
摘要:由于人工智能系統對于數據的依賴以及深度學習算法的不可解釋性,導致目前的人工智能系統面臨嚴重的安全風險。其中,對抗樣本是目前深度學習面臨的主要威脅之一。為了更好地應對對抗樣本攻擊帶來的安全威脅,需要對對抗樣本的構造機制有充分的了解。因此,深度學習領域中關于對抗樣本的構造方法有了大量的研究。該文提出了一種基于自編碼器的對抗樣本生成方法,不需要強大的背景知識,降低計算成本,實驗結果證實所提出的方法的先進性和可用性。
關鍵詞:深度學習;對抗樣本;自編碼器
Absrtact:Due to the dependence of artificial intelligence system on data and the unexplainability of deep learning algorithm, the current artificial intelligence system is facing serious security risks. Among them, counter sample is one of the main threats to deep learning. In order to better deal with the security threats brought by counter sample attacks, we need to have a full understanding of the construction mechanism of counter sample. Therefore, in the field of deep learning, there has been a lot of research on the construction method of confrontation samples. This paper proposes a method of generating a countermeasure sample based on selfencoding. It does not require strong background knowledge and reduces computation cost. Experimental results confirm the advanced and usability of the proposed method.
Key words: deep learning; adversarial examples; autoencoder
1背景知識
日益增多的社會信息交流系統和軟件中,幾乎連接著人們的方方面面,改變著人們的學習,工作方式以及日常生活,在豐富精神文化生活的同時,也帶來了風險。網絡與信息安全問題是世界各國信息時代所面臨的主要難題,作為信息保護的主要環節,這個風險和問題需要一直被重視。人們的生活成本需求在信息化、科技化、人性化、智能化驅動下,精準定位智能需求,多元擴展智能來源,彈性發揮智能能效,個性化定制智能服務等多機制入手,把握信息時代之魂,關注信息時代之需,聚焦信息時代之變,引領信息時代之風。以及新理論新技術和經濟社會發展的強烈需求的共同推動下,人工智能科學持續創新,逐步走向工業世界。雖然深度學習[1]技術有著廣泛的應用前景,但是對于現階段的研究水平而言,以深度學習為基礎的人工智能應用面臨嚴重的安全風險。2018年3月26日,由全球最大的網絡預約汽車服務公司Uber研發的L4自動駕駛汽車在亞利桑那州的公共道路上撞上行人,這是世界上首次自動駕駛造成的死亡。今年5月,Uber事故的初步報告顯示,Uber的自動操作軟件無法準確識別受害者何時過馬路。目前深度學習在隱私保護和安全領域面臨諸多問題,其中最為突出的安全問題是對抗樣本[2],上述兩個案例背后的始作俑者正是對抗樣本。對抗樣本[3-5]是目前深度學習面臨的主要威脅之一, 對抗樣本是指通過對原始樣本進行一些細微的擾動來使得目標模型以高置信度給出一個截然不同的預測結果。為了更好地應對對抗樣本攻擊帶來的安全威脅,針對當前對抗樣本構造方法存在的缺陷,本文提出了一種基于自編碼器的對抗樣本生成方法,主要貢獻包括:本文是通過在原始樣本經過降維之后,對其低維的特征表示進行擾動,從而構造對抗樣本。通過大量的實驗,我們證明了該構造方法的有效性。
2自編碼器
自編碼器是深度學習中比較著名的無監督學習方法,最早的概念來自Rumelhart等人在《Nature》上發表的論文。后來,Burlard等人做出了詳細的闡述。自編碼器的輸入層和輸出層分別代表神經網絡的輸入層和輸出層,隱層承擔編碼器和解碼器的工作,編碼過程是從高緯度輸入層到低緯度隱層的轉換。另一方面,解碼過程是從低維層到高階輸出層的轉換過程。轉換過程通過比較輸入和輸出之間的差異來定義損失函數。在轉換過程中,不需要標記數據。整個過程就是求解損失函數最小化的過程。這也是編碼器名稱的來源。自編碼器是一種人工神經網絡,通過無監督學習有效地顯示輸入數據。自動編碼器是一種數據壓縮算法,數據壓縮和解壓功能與數據、丟失相關,并從樣本中自動學習。如果提到大多數自動編碼器,壓縮和解壓縮功能是通過神經網絡實現的。自編碼器是一種自監督算法,不是無監督算法。自監督學習是監督學習的一個例子,標簽生成自輸入數據。為了獲得一個自監督模型,需要一個可靠的目標和損失函數。設定重新配置輸入的目標可能不是正確的選擇。基本上,模型需要在像素級重新配置。輸入不是機器學習的興趣,而是學習高級抽象特征。在實踐中,如果主任務是分類定位等任務,則這些任務的最佳特征基本上是重構輸入的最差特征。這種輸入數據的有效表示稱為編碼,它比輸入數據的維數更小,允許使用自編碼器降維。更重要的是,自編碼器可以作為一個強大的特征檢測器用于深度神經網絡的先驗訓練。此外,自編碼器可以隨機生成與訓練數據相似的數據,這稱為生成模型。一般來說,常見的自編碼器包括編碼和解碼兩個階段。編碼器和解碼器的結構一般來說是對稱的。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
