基于TensorFlow.js的英文語音識別研究與實現
2021-09-14 02:48:15李東升蘇煜輝陳正銘
電腦知識與技術 2021年22期
李東升 蘇煜輝 陳正銘


摘要:TensorFlow是谷歌基于DistBelief進行研發的第二代人工智能學習系統,而本文將介紹其衍生的js版本即TensorFlow.js框架,并且基于這個框架和瀏覽器環境加載一個預訓練模型來實現語音識別簡單孤立的英文單詞的功能。通過對預訓練模型的使用與優化研究,為進一步使用TensorFlow.js實現更加復雜的商業化功能做了前期探索。
關鍵詞:預訓練模型;TensorFlow.js;語音識別
1 概述
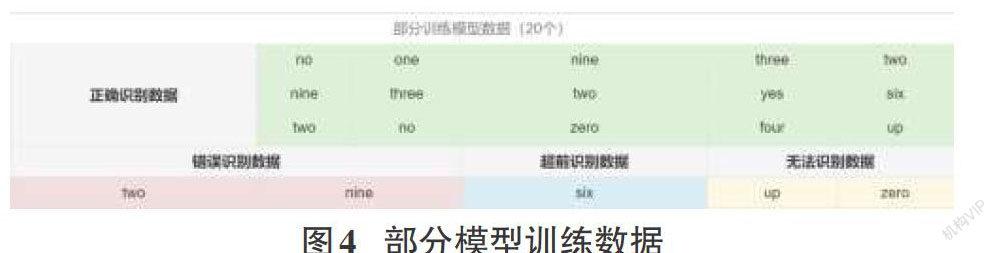
簡單的語音識別實際上也是屬于分類問題,而聲音在計算機中是被當成聲譜圖,既然是圖片類的,那么就可以使用卷積神經網絡來構建訓練模型[1]。實際上很多成熟的語音識別模型也是基于卷積神經網絡構建的,本文也將采用Tfjs-model這個官方模型庫里面的speech-commands這個預訓練好的語音命令模型,該模型可以獲取一秒的音頻片段,十分適合用來實現一個簡單的語音識別功能。
2 TensorFlow.js框架
2.1 TensorFlow.js特性
需要說明的是TensorFlow.js使用的是Tensor,也稱為張量,有別于一般數組,它是向量和矩陣向更高維度的拓展,也可以近似的看成一個多維數組。而神經網絡具有多個神經元和層,每一層都需要存儲N維的數據[5],這些數據往往需要進行N層的遍歷循環計算等,導致其數據結構比較復雜,因此就需要張量這樣一個高維的數據結構來存儲這些數據。
下文中的模型特指人工神經網絡模型,主要由TensorFlow.js框架的sequential方法初始化并根據需求逐步添加輸入層、隱藏層和輸出層。每個神經網絡模型里面都包含一個輸入層、最少一個隱藏層、一個輸出層,每個層由任意個(至少為1個)神經元構成。每個神經元都會包含若干權重、偏置和一個激活函數。
2.2 TensorFlow.js開發環境搭建
所謂“工欲善其事必先利其器”,第一步首先是如何安裝TensorFlow.js。安裝的話其實分為在瀏覽器安裝和在node安裝,考慮到瀏覽器的便捷性和容易上手的特性,所以介紹相對比較簡單的瀏覽器安裝。
完成上述TensorFlow.js庫的安裝后就可以在瀏覽器上運行機器學習模型或者加載預訓練模型。
3 預訓練模型的使用
3.1 預訓練模型
3.2 預訓練模型實現
由于是預訓練模型,故需要從官方倉庫那里下載語音識別模型文件,保存到本地文件夾中,然后就可以在本地開啟靜態文件服務器(http-server或者nginx皆可,這里啟動的地址默認為:http://127.0.0.1:8080)并且能通過靜態服務器訪問到這個文件,下載這個模型文件后還需要安裝對應的依賴,可以在終端命令行運行npm i @tensorflow-models/speech-commands,然后在編寫業務邏輯的地方引入即可完成準備工作,接下來將新建一個script.js文件來書寫具體的訓練邏輯,步驟如下:
語音命令識別器的定義(在線流媒體識別方式):利用導入的模型文件里面自帶的create方法建立一個識別器實例,這個識別器可以用來加載我們的預訓練模型。該識別器需要傳入四個參數(第一個必選,其余為可選的識別參數),這里傳入了瀏覽器傅里葉轉換、null為默認識別單詞(由于已經給出模型地址故應該給null或者undefined)、預訓練模型的地址、預訓練模型的源文件信息(地址和信息來源于剛剛安裝的語言識別依賴):
3.3模型預測
經過上面的步驟之后就已經完成了加載預訓練模型,同時獲得了模型的標簽,接下來就可以通過監聽用戶麥克風的輸入即特征來進行語音識別了。
監聽用戶麥克風:這個可以通過H5實現,但是識別器通過了listen方法也可以讓開發者監聽。需要獲得用戶輸入對應詞匯表中每個單詞對應的符合程度,并且獲取其中符合程度最高的單詞,這個單詞就是根據用戶輸入的語音識別得到的,將這個單詞打印并顯示到頁面:
