一種基于跳數修正和跳距優化的DV-Hop定位算法
2021-09-14 09:30:14張媛王梅繆相林丁凰
全球定位系統 2021年4期
關鍵詞:優化
張媛,王梅,繆相林,丁凰
( 1.西安交通大學城市學院計算機系,西安 710018;2.西安交通大學計算機學院,西安 710049)
0 引言
隨著智能信息產業的發展,基于無線傳感器網絡(WSN)[1]在智慧農業、智能康復醫療和戰場防線勘察領域得到了廣泛的應用.多數的WSN 應用需要獲取節點的位置信息[2],需通過定位算法估計節點位置,即對節點進行定位.
目前節點定位算法可分為兩類:測距和非測距定位.基于接收的信號強度指示(RSSI)[3]、到達時間差(TDOA)[4]和到達角度(AOA)[5]屬測距定位算法;質心定位、DV-Hop定位[6]和凸算法屬非測距定位算法.相比于測距定位算法,非測距定位算法無需額外的硬件設備測量距離,降低了定位成本.
作為經典的非測距定位算法,DV-Hop 算法被廣泛應用于估計節點位置.盡管DV-Hop算法的復雜性低,但其也存在一些不足.如最小跳數估計精度不高,跳距估計誤差大.為此,研究人員提出了不同的改進策略.
胡玉蘭等[7]提出基于平均跳距優化的DV-Hop改進算法(AHDD).通過對跳數進行優化,提高估計平均跳距的精度;鄧浪等[8]對DV-Hop算法的跳數進行優化,并利用最小均方差準則估計平均跳距,提高測距精度;Gao等[9]引入粒子群優化算法,利用粒子群算法修正節點位置,提高定位精度.盡管上述算法減少了定位誤差,但仍存在最小二乘法初值敏感以及生物智能算法的復雜度高等問題.
為此,針對DV-Hop算法的定位精度問題,分析了導致定位精度不高的原因,并提出基于跳數修正和跳距優化的DV-Hop定位算法(NHDL). NHDL 算法利用信號強度值對跳數進行修正,并利用錨節點間已知的位置信息對跳距誤差進行優化.同時采用易實現的最小最大法估計節點位置.仿真結果表明:提出的NHDL 算法有效地提高了定位精度.
1 DV-Hop定位及誤差分析
DV-Hop定位算法主要由三個階段構成:1)未知節點與錨節點間的最小跳數的估算;2)未知節點與錨節點間的平均跳距的估算;3)未知節點位置的估算.其中,跳數和平均跳距的估計存在較大的誤差.
1.1 最小跳數的估算
傳統的DV-Hop定位算法不論鄰居節點間的實際距離遠近,只要接收到鄰居節點發送的分組包,就將跳數設置為1.如圖1所示,錨節點L1與未知節點A,節點A與節點B的距離不同,但是對于節點A而言,它們離自己的跳數均為1跳.通過這種方式估算跳數,再利用跳數測算距離必然會產生定位誤差.
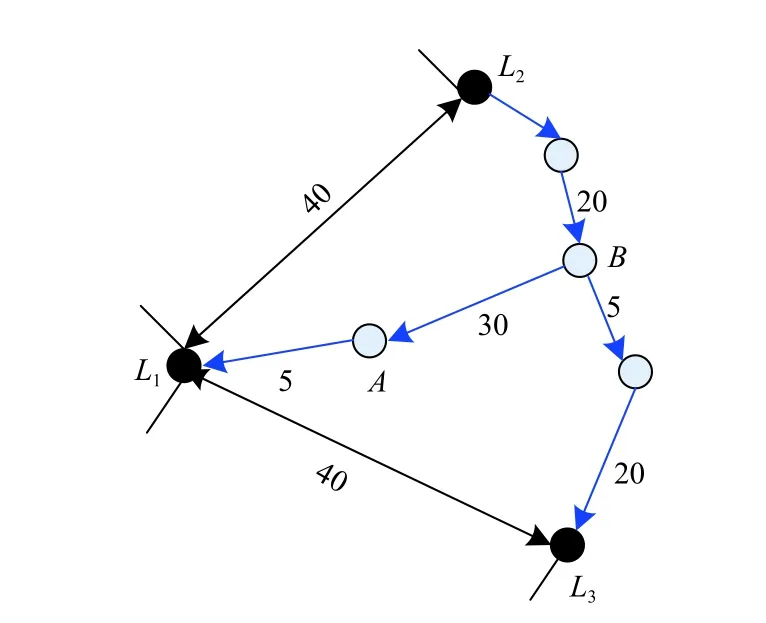
圖1 DV-Hop算法誤差分析圖
1.2 平均跳距的估算
依據DV-Hop 算法估算平均跳距策略,錨節點L1所估算的平均跳距為:( 40+40)/(4+4)=10.未知節點A接收此平均距離信息后,利用跳數與平均跳距的乘積作為離L1的距離: 1 ×10= 10.但是實際上,L1與未知節點A的距離為5.
通過上述分析可知,DV-Hop定位算法在最小跳數和平均跳距的估算階段存在明顯的誤差.為此,NHDL 算法將對跳數和跳距進行修正,再通過最小最大法估計未知節點位置.
2 NHDL定位算法

2.1 基于RSSI 的跳數修正
若直接利用分組包傳遞的次數,估計錨節點間的跳數存在偏差.為此,利用接收的信號強度指示(RSSI)對跳數進行修正.
采用對數衰減模型,通過RSSI 估計距離,如式(1)所示:

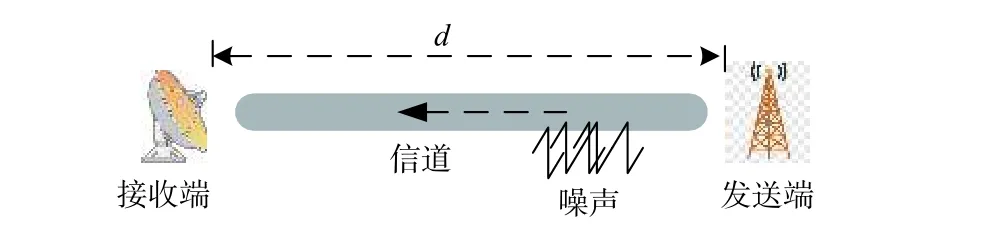
圖2 信號傳輸模型

錨節點將修正后的跳數載入分組包中,向下一跳鄰居節點廣播.接收到分組包后,節點先從分組包中提取跳數值,并檢查是否已保留了離發送節點的跳數值. 若已保留,就比較這兩個跳數值,并存儲兩值中的最小值作為這兩個節點間的跳數.然后,再將此跳數加1,繼續廣播分組包.
2.2 基于錨節點位置的平均跳距優化

2.3 定位盲區感知的錨節點選擇
文中考慮了節點位置屬二維空間.估計二維空間中節點的位置,至少3個錨節點的測距信息.因此,在估計節點位置時,需選擇3個錨節點,并建立相應的距離方程.然而,如果所選擇的3個錨節點位于同一條直線,即共線,就無法估計節點位置,出現定位盲區[10].
為了避免定位盲區,NHDL 算法先通過行列式法計算3個錨節點所形成的區域面積,再判斷區域面積是否為零.若為零,則表示這3個錨節點共線;反之,不共線.具體過程如下:

2.4 基于最小最大法的節點位置估計
首先,未知節點通過修正后的最小跳數以及優化后的跳距,計算離錨節點的距離;然后,利用最小最大法計算自己的位置坐標,即定位.最小最大法的思路如下:未知節點獲取離錨節點的距離后,以錨節點位置為圓心以估計的距離為半徑形成圓的外接矩形.二維空間的位置,至少需要形成以3 個非共線的錨節點的外接矩形;最后,以3個外接矩形所重疊的區域的中心位置為未知節點位置的估計值.

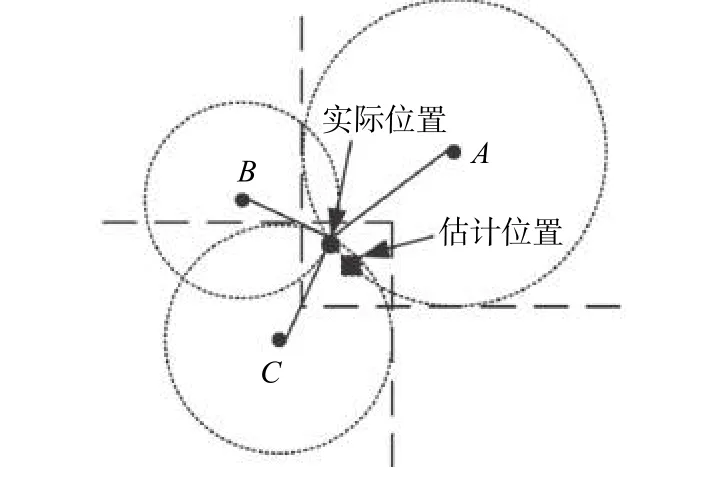
圖3 基于最小最大法的節點位置估計
2.5 定位流程
首先,部署節點.錨節點廣播分組包.網絡內所有節點通過接收分組包以及RSSI值對最小跳數值進行修正,并存儲最小跳數值.
然后,錨節點依據2.2節對平均跳距進行修正,再進行廣播分組包,未知節點接收到分組包后,估算離錨節點的距離.當獲取3 個以上錨節點后,再從中選擇3個非共線的錨節點,并依據最小最大法估計位置,NHDL 定位算法流程如圖4所示.

圖4 NHDL定位算法流程
3 仿真與分析
3.1 仿真環境

3.2 錨節點數對定位精度的影響
本次實驗參數如下:未知節點數n=100;R=20 m;錨節點數從10~40變化.圖5給出了DV-Hop算法、AHDD算法和NHDL 算法的平均定位誤差隨錨節點數的變化情況.
由圖5可知,平均定位誤差隨錨節點數量的增加呈下降趨勢.當錨節點數量較少時,增加錨節點數可以有效地降低平均定位誤差;但當錨節點數達到一定數量后(大于25),平均定位誤差隨錨節點數量增加而變緩慢.這說明并非增加錨節點數就一定能夠降低平均定位誤差.

圖5 錨節點數對平均定位誤差的影響
此外,相比于DV-Hop算法和AHDD算法,提出的NHDL 算法具有較低的平均定位誤差.這歸功于NHDL 算法通過RSSI值對跳數進行了修正,控制了跳數估計的誤差.同時,利用錨節點間已知的位置信息,平均跳距進行了優化,最終提高了定位精度.
3.3 未知節點數對定位精度的影響
本次實驗參數如下:未知節點數從60~200變化,錨節點個數等于10%的未知節點數,節點通信半徑為20 m.DV-Hop 算法、AHDD算法和NHDL 算法的平均定位誤差隨未知節點數的變化情況,如圖6所示.

圖6 未知節點數對平均定位誤差的影響
由圖6可知,節點數的增加有利于定位精度的提升.原因在于:網絡內節點數越多,網絡的連通性越好,節點能夠獲取的定位信息越充分.此外,相比于DV-Hop 算法和AHDD算法,NHDL算法在平均定位誤差性能方面具有較大的優勢.例如,當節點數為200時,NHDL 算法的平均定位誤差為0.122 m,而DV-Hop 算法和AHDD算法的平均定位誤差分別為0.274 m 和0.237 m.
3.4 通信半徑對定位精度的影響
最后,分析通信半徑R對定位精度的影響.本次實驗參數:未知節點數n=100;錨節點數為10 個;通信半徑從15~40 m 變化.
圖7給出DV-Hop算法、AHDD算法和NHDL算法的平均定位誤差隨通信半徑R的變化情況.由圖7可知,通信半徑的增加有利于降低平均定位誤差.原因在于通信半徑越大,節點通信的范圍越大,能夠獲取的定位信息越多,這有利于提高定位精度.

圖7 節點數對平均定位誤差率的影響
此外,相比于DV-Hop算法和AHDD算法,NHDL算法降低了平均定位誤差.在通信半徑較低時,NHDL算法在平均定位誤差性能方面的優勢更明顯.例如,在通信半徑為20 m 時,NHDL 算法的平均定位誤差為0.183 m,而DV-Hop 算法和AHDD算法的平均定位誤差分別為0.520 m 和0.294 m.
4 總結
基于傳統的DV-Hop算法的定位精度不高的問題,提出基于跳數修正和跳距優化的DV-Hop定位算法NHDL. NHDL算法對跳數和跳距的計算過程進行優化,降低定位誤差.利用易實現的最小最大法估計未知節點位置,降低算法的復雜度.仿真結果表明:提出的NHDL 算法有效地降低了定位誤差.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
