圖像描述生成研究進展
2021-09-13 01:54:16李志欣魏海洋張燦龍馬慧芳史忠植
計算機研究與發展 2021年9期
李志欣 魏海洋 張燦龍 馬慧芳 史忠植
1(廣西多源信息挖掘與安全重點實驗室(廣西師范大學) 廣西桂林 541004) 2(西北師范大學計算機科學與工程學院 蘭州 730070) 3(中國科學院智能信息處理重點實驗室(中國科學院計算技術研究所) 北京 100190)
隨著互聯網與信息技術的發展,多媒體數據呈現爆炸性增長的趨勢,從各種信息源(如網絡、新聞、相機等)上可獲得的圖像數據越來越多.由于圖像數據具有海量特性和非結構化特性,如何快速有效地組織、存儲和檢索圖像,成為重要的研究課題,而完備的圖像語義理解則是其中的關鍵問題[1].盡管從信息源上獲取的大多數圖像并沒有對應的語義描述,但人類仍然能夠在很大程度上理解它們.也就是說,人類很容易就能完成涉及復雜視覺識別以及場景理解的各種任務、涉及自然語言交流的各種任務以及2種模態之間的轉換任務.例如,只需快速瀏覽圖像就足以讓人指出并描述關于視覺場景的大量細節,而這對于機器來說目前仍然是難以完成的任務.為了實現圖像數據的結構化和半結構化,從語義上更完備地理解圖像數據,從而進一步研究更符合人類感知的視覺智能,迫切需要機器能夠為給定圖像自動地生成自然語言描述.
計算機視覺研究如何理解圖像和視頻,而自然語言處理研究如何分析和生成文本.盡管這2個領域的研究都采用類似的人工智能和機器學習方法,但在很長一段時間里它們都是各自發展而很少交叉.近幾年,結合視覺和語言的跨模態問題受到了廣泛關注.事實上,許多日常生活中的任務都具有這種跨模態的特性.例如,看報紙時解釋圖片的上下文信息,聽報告時為理解講話而搭配圖表,網頁上提供大量結合視覺信息和自然語言的數據(帶標簽的照片、新聞里的圖片視頻、具有多模態性質的社交媒體)等.為完成結合視覺和語言的任務并充分利用多模態數據,計算機視覺和自然語言處理2個領域的聯系越來越緊密.
在這個新的視覺和語言交叉的研究領域中,圖像描述生成是個重要的任務,該任務包括獲取圖像信息、分析其視覺內容、生成文本描述以說明圖像中的顯著物體和行為等步驟[2-5].圖1給出了4個根據圖像內容生成描述語句的實例.

Fig.1 Examples of image captioning圖1 圖像描述生成實例
從計算機視覺的角度來看,圖像描述生成是個重大的挑戰,因為描述可能涉及圖像的各個方面——可能是關于圖像中的物體及其屬性,也可能是關于場景的特性或者是場景中人和物體的交互行為.而更具挑戰性的是,描述還可能指出圖像中沒有的物體(如等待中的火車)或提供不能直接從圖像推出的背景知識(如畫作中的蒙娜麗莎).總之,好的圖像描述不僅需要有完備的圖像理解,還需要綜合而精煉的表達,因而圖像描述生成任務對于計算機視覺系統是個良好的測試.傳統的視覺任務(如物體檢測[6]或圖像自動標注[7])都是在有限個類別上測試檢測器或分類器的精確率.相比之下,圖像描述生成任務更具綜合性.另一方面,從自然語言處理的角度來看,該任務是個自然語言生成的問題,需要將1個非語言的表示轉換成1個可讀的文本.一般來說,非語言表示是1個邏輯形式、1個數據庫查詢或是1串數字,而圖像輸入通常轉換為1個中間表示向量(如深度特征表示),需要語言模型將之轉換成1個語句.
圖像描述生成任務結合了計算機視覺和自然語言處理2個研究領域,不僅要求完備的圖像語義理解,還要求復雜的符合人類感知的自然語言表達,具備重要的理論意義和應用前景[2-5].在理論上,圖像描述生成的研究將促進計算機視覺和自然語言處理領域的發展.通過構建新的計算模型與計算方法,提高計算機對非結構化信息的理解能力和對海量信息的處理效率,從而為人工智能和認知科學的發展作貢獻.此外,圖像描述生成還具有廣闊的應用前景.首先,圖像描述生成技術可以應用于自動圖像索引,這對于提升圖像檢索的效果和效率具有重大意義,因而圖像描述生成可以應用于圖像檢索的多個應用領域,包括醫療、商業、軍事、教育、數字圖書館等;其次,圖像描述生成技術可以幫助社交媒體平臺(如Facebook,Twitter等)為圖像生成自然語言描述,包括我們在哪里、穿什么和干什么等重要信息,可以直接幫助和指導我們的日常生活;最后,圖像描述生成技術還可以在機器人交互、學前教育和視覺障礙輔助等應用領域起到關鍵的作用.
1 關鍵技術
圖像描述生成的目標是:給定1幅圖像,根據圖像內容生成語法正確語義合理的語句.顯然,圖像描述生成涉及2個基本問題——視覺理解和語言處理.為了保證生成描述語句在語法和語義上的正確性和合理性,需要利用計算機視覺和自然語言處理技術分別處理不同模態的數據并做適當的集成.
近年來,深度學習技術得到迅速發展,并成功應用于計算機視覺和自然語言處理相關領域.圖像描述生成的研究在經歷了早期基于模板的方法和基于檢索的方法之后,大多數方法都是基于深度學習技術構建,并在性能上取得了顯著的提升[4].基于深度學習的圖像描述生成方法涉及的關鍵技術主要包括整體架構、學習策略、特征映射、語言模型和注意機制5個方面,如圖2所示:
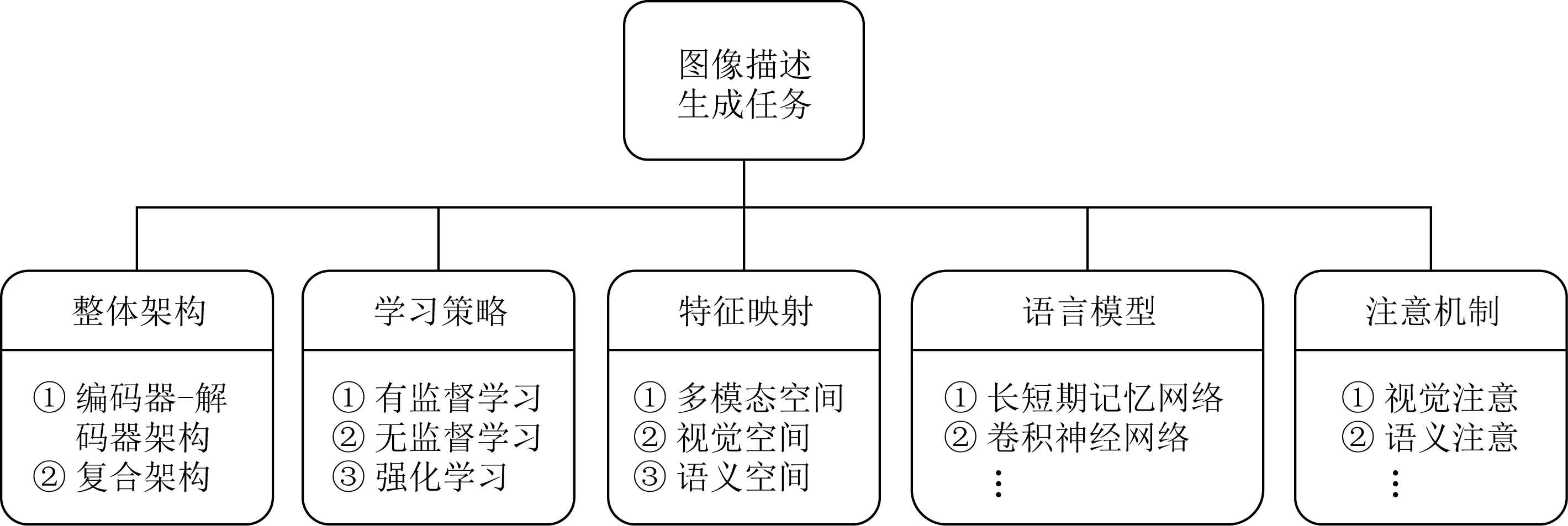
Fig.2 Key technologies of image captioning圖2 圖像描述生成關鍵技術
1.1 整體架構
從整體架構上看,當前主流的基于深度學習技術的圖像描述生成方法大都基于編碼器-解碼器架構或復合架構來構建學習模型.
基于深度學習技術構建的圖像描述生成方法大部分采用端到端的工作方式,這與基于編碼器-解碼器架構的神經機器翻譯方法[8]非常相似.受到這個思路的啟發,可以將圖像描述生成看作一個序列到序列的翻譯問題,輸入是圖像,而輸出是自然語言,并利用編碼器-解碼器架構完成圖像理解和語言生成的任務.這種架構在性能上取得了重要進展,成為當前圖像描述生成方法的主流通用架構.在編碼器-解碼器架構中,編碼器通常采用卷積神經網絡(convolutional neural network,CNN)[9-10]提取圖像特征,而解碼器通常采用循環神經網絡(recurrent neural network,RNN)[11]生成自然語言描述.
基于復合架構的圖像描述生成方法利用概念檢測模型(如物體檢測模型、圖像自動標注模型等)獲取圖像中不同粒度的語義概念[12](包括物體名、標注、短語等形式),再利用并列語言模型或者分層語言模型代替解碼器生成描述語句.這類方法通常由幾個功能獨立的部件組成,各個部件被集成到管道中,為輸入圖像生成自然語言描述.
1.2 學習策略
圖像描述生成的學習策略包括有監督學習、無監督學習和強化學習.
在有監督學習中,使用的訓練數據伴隨著期望輸出的標簽,通常能夠獲得較高的精確率.由于圖像描述生成的基準數據集中每幅圖像都有對應的多條語句或多個語義標簽,因而絕大多數圖像描述生成方法都采用了有監督學習的方法進行訓練.其中應用特別廣泛的包括各種基于有監督學習的深度神經網絡模型:CNN模型成功應用于圖像分類等視覺任務,從AlexNet[13],VGG16[14]到ResNet[15]性能逐步提升;基于區域建議的物體檢測模型能夠自動提取原始圖像中的候選區域,從R-CNN(region CNN)[16],Fast R-CNN[17],Faster R-CNN[18]到R-FCN(region-based fully convolutional networks)[19],在精確率和效率方面取得了很大的提升;RNN模型在自然語言生成方面取得成功,特別是經過改進的長短期記憶網絡(long short-term memory,LSTM)[20]和門控循環單元(gated recurrent unit,GRU)[21]等.這些有監督學習方法都可以嵌入到當前主流的編碼器-解碼器的架構中,作為編碼器或解碼器的組成部分,完成圖像描述生成過程中的基本功能.然而,由于圖像內容的復雜性,精確地標注圖像數據常常是不切實際的,因而難以獲得成對的圖像-語句訓練數據.而無標簽的圖像數據日益增長,這就需要利用無監督學習與強化學習來輔助和改進圖像描述生成方法.
在無監督學習中,訓練數據的標簽是未知的,需要通過學習算法揭示數據的內在性質和規律.無監督學習方法經常用于對圖像或文本進行預處理,主要包括:各種聚類方法,如K均值聚類、高斯混合聚類等;各種降維方法,如主成分分析、多維縮放等;一些用于文檔分析的概率模型,如概率潛在語義分析模型[22]和潛在狄利克雷分布(latent Dirichlet allo-cation,LDA)模型[23]等.此外,生成對抗網絡(gen-erative adversarial network,GAN)[24]是在圖像描述生成中應用最廣泛的無監督學習技術.基于GAN的方法可以從無標簽的數據中學習,通過在生成器和判別器之間的競爭過程來獲得數據的深度特征表示.利用GAN也能對有限的數據集進行擴充,進而提升系統性能.然而,GAN的應用存在2個重要問題:首先,因為圖像上像素值是連續的,GAN可以直接通過反向傳播算法來進行訓練.然而,文本處理是基于離散的數據,這種操作是不可微的,因此很難直接應用反向傳播算法學習.其次,評估器在序列生成中面臨著梯度消失和誤差傳播的問題.對于這些問題,一般需要借助強化學習方法來進行梯度傳導.
強化學習[25]方法由智能體、狀態、動作、獎勵函數、策略和值等參數設計.智能體選擇1個動作,接收獎勵值,并移動到新狀態.策略由動作定義,值由獎勵函數定義.智能體試圖選擇具有最大長期回報的動作,它需要連續的狀態和動作信息來提供獎勵函數的保證.典型的基于強化學習的圖像描述生成方法包含2個網絡:策略網絡和價值網絡,分別被稱為行動者和評論者.評論者(價值網絡)可以用來估計預期的未來獎勵,以訓練行動者(策略網絡).現有的圖像描述生成方法存在“暴露偏差”[26]和評估指標不可微的問題.基于強化學習的訓練方法一方面緩解了“暴露偏差”的問題,另一方面它直接在評估指標上優化語句的生成,從而使模型在訓練目標和測試評估上也保持一致.因此,基于強化學習的模型優化是生成高質量圖像描述的重要保證.
1.3 特征映射
對于圖像描述生成任務而言,將圖像或文本的內容映射到特征空間是最基本的問題.圖像描述生成方法常用的特征空間包括多模態空間、視覺空間和語義空間,并在此基礎上生成自然語言描述.將圖像和文本的內容映射到多模態空間需要集成隱式的映射方法和語言模型,將圖像內容映射到視覺空間通常基于顯式的映射方法,而將圖像內容映射到語義空間則通常需要在視覺空間的基礎上加入概念檢測的部件形成復合映射方法.
由于在圖像描述數據集中包含圖像和相應的描述文本,在基于多模態空間的方法中,編碼器是同時從圖像和描述文本中學習得到公共的多模態空間,然后將這個多模態表示傳遞給語言解碼器.學習得到多模態空間的方法多種多樣,比如可以直接通過加權融合視覺特征和文本特征,或者在融合的基礎上進一步利用各種降維方法學習得到潛在的語義空間.
將圖像內容映射到視覺空間是圖像描述生成的主流方法.在基于視覺空間的方法中,圖像特征和相應的描述文本分別獨立地傳遞給語言解碼器.早期的方法通常是先提取圖像的各種關鍵手工特征(如顏色、紋理、空間關系等特征),然后再利用特征選擇算法將多種手工特征融合為統一的視覺空間.而當前的方法普遍采用預訓練的CNN模型或物體檢測模型直接提取圖像特征來構造視覺空間.
由于通常僅使用CNN模型提取圖像特征構造視覺空間,所以只能從某個特定的角度描述圖像內容,這使得輸入圖像的語義不能被全面理解,從而也限制了圖像描述的性能.因此,另一種可選的方法是在獲取視覺空間表示的基礎上構建語義空間,全面描述圖像中的物體、屬性關系等各種語義要素,再將各個要素進行融合表示成語義屬性向量輸入解碼器生成描述語句.
1.4 語言模型
一般來說,自然語言生成可以看作序列到序列的學習任務.為完成這個任務,研究者提出了多種神經語言模型,如RNN模型[11]、神經概率語言模型[27]和對數雙線性模型[28]等.
RNN在各種序列學習任務中被廣泛應用,但存在梯度消失和梯度爆炸的問題,且不能充分處理長期時序依賴問題.為此,LSTM[20]對RNN加以改進,可以解決RNN無法處理的長期時序依賴問題,也緩解了RNN容易出現的梯度消失問題.原始的RNN隱藏層只有1個單一的tanh層,輸出1個狀態h,它對于短期的輸入非常敏感.LSTM在RNN的基礎上增加了1個單元狀態c,可以保存長期的狀態.同時,LSTM使用了4個相互作用的層,其內部結構如圖3所示:
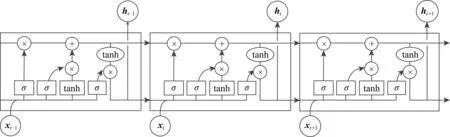
Fig.3 Basic structure of LSTM圖3 LSTM基本結構
LSTM的關鍵在于穿越單元的數據傳送線,它使得單元狀態c的傳輸能夠快速通過,從而實現長期的記憶保留.LSTM使用的3個門(遺忘門、輸入門和輸出門)結構可以選擇性地讓信息通過,從而實現信息的保護和控制.LSTM可用1組公式表示為:
it=σ(Wixxt+Wihht-1),
ft=σ(Wfxxt+Wfhht-1),
ot=σ(Woxxt+Wohht-1),
ct=ft⊙ct-1+it⊙tanh(Wcxxt+Wchht-1),
ht=ot⊙tanh(ct),
(1)
其中,σ是sigmoid函數;c是記憶單元,用于存儲和更新記憶信息,由上一時刻保留的記憶和當前時刻納入的記憶共同組成.f是遺忘門,它決定了上一時刻記憶單元中有多少信息可以保留到當前時刻;i是輸入門,它決定了當前時刻的輸入信息有多少可以納入到記憶單元中;o是輸出門,用來控制記憶單元在當前時刻的輸出,即輸出當前時刻的隱狀態ht.3個控制門都是通過當前時刻輸入的信息和上一時刻LSTM的隱狀態來進行計算(這里為簡單起見省略了偏置量).
在圖像描述生成的任務中,LSTM占據壓倒性的重要地位.它通常用作解碼器,將編碼器得到的中間向量解碼為單詞序列Y=(y1,y2,…,yT),其中yi∈D是預測生成的單詞,D是包含所有單詞的詞典,T是語句的最大長度.單詞由詞嵌入向量表示,每個語句的開頭用1個特殊的開始標記〈start〉,結尾用1個特殊的結束標記〈end〉.在模型解碼過程中,上一時間步生成的單詞會被反饋到LSTM中,結合注意機制,生成當前時間步LSTM的隱狀態ht,然后根據ht預測生成當前單詞yt.
GRU[21]是與LSTM類似的語言模型,它不使用單獨的存儲單元,并且使用較少的門來控制信息流.從結構上看,GRU只有更新門和重置門2個門,把LSTM中的遺忘門和輸入門用更新門來替代,并把單元狀態和隱狀態進行合并,在計算當前時刻新信息的方法和LSTM有所不同.從某些任務的表現上看,GRU與LSTM獲得的性能大致相當,但計算效率更高.因此,GRU既保持了LSTM的效果,又具有更加簡單的結構和更少的參數,也更容易收斂.但是,GRU并不能取代LSTM,因為LSTM在數據集很大的情況下表達效果更好.在圖像描述生成的任務中,要處理的數據量日益增大,LSTM的應用還是要比GRU廣泛得多.
此外,LSTM忽略了語句潛在的層次結構,并需要大量的存儲空間.相比之下,CNN可以學習語句的內部層次結構,并且處理速度比LSTM快.因此,CNN也被用于序列學習任務,如條件圖像生成[29]和機器翻譯[30]等.
1.5 注意機制
視覺注意機制[31]是靈長類和人類視覺系統中的重要機制,本質上是個反饋過程.它有選擇地將視覺皮層的早期表達映射到更突出中心的非拓撲表達,其中只包含場景中特定區域或物體的屬性.這種選擇性映射允許大腦在低層圖像屬性的指導下,將計算資源集中在某個物體上.機器注意機制也是模仿人類的這一能力最初在計算機視覺領域提出,后來被應用于機器翻譯等任務,主要與編碼器-解碼器架構相結合來使用,目前已應用于人工智能的各個領域.
在最初應用于機器翻譯的編碼器-解碼器架構中,編碼器讀取具有可變長度的序列輸入,將其編碼為隱狀態,解碼器根據編碼器的最后1個隱狀態來生成輸出序列.但這個架構存在的潛在問題是大量的源信息可能無法通過固定長度的向量(即編碼器最終的隱狀態)來捕獲,特別是在長語句的情況下,這個問題尤為嚴重.因此,Bahdanau等人[32]將注意機制與編碼器-解碼器架構結合,利用注意機制來對齊源信息和目標輸出.源信息中保留了來自編碼器所有時間步的隱狀態信息,通過注意機制來計算目標輸出當前所需的源信息,這樣可以使模型能夠“關注”源信息的特定部分,并更好地建立源信息與目標信息之間的聯系.注意機制在圖像描述生成的任務中也起著重要的作用.特別是,人們在描述圖像的過程中并不需要一直關注整幅圖像的所有信息,而是更傾向于討論圖像中語義上更顯著的區域和物體.因此,引入注意機制可以將注意集中在圖像的顯著部分,同時生成相應的單詞.
隨著技術不斷發展,出現了各種注意機制,但其本質思想都是對信息進行加權整合,以獲取更重要的信息組成,從而將有限的信息處理資源分配到重要的部分.注意機制大致可以分為上下文注意機制和自注意機制,其主要計算過程可以表示為
α=softmax(f(Q,K)),
(2)
(3)
其中,Q表示查詢(query),K表示鍵(key),V=(v1,v2,…,vn)表示值(value),通常都表示為矩陣形式,α為權重系數.函數f常見的形式包括對應元素相乘、相加以及通過感知機進行融合等.首先,式(2)通過函數f計算得到Q和K的關系,并通過softmax函數對其進行歸一化,得到注意權重分布系數α;其次,式(3)根據權重系數α對信息V=(v1,v2,…,vn)的所有列向量進行加權計算得到整合后的向量vatt.
注意機制計算過程的核心思想是在輸入序列上引入注意權重系數α,優先考慮存在相關信息的位置集,以生成下一個輸出.將源端中的構成元素想象成是由一系列的數據對〈K,V〉構成,此時給定某個元素Q,通過計算Q和各個K的相似性或者相關性,得到每個K對應V的權重系數,然后對V進行加權求和,即得到了最終的輸出.所以本質上注意機制是對源端中元素V進行加權求和,而Q和K用來計算對應的權重系數.不同的注意機制差異主要在于Q,K,V所表示的信息不同.在上下文注意機制中,K和V一般來自源端信息,Q一般來自目標端信息(如在圖像描述生成任務中K和V一般表示編碼端圖像的空間特征,Q一般表示解碼端的上下文信息),上下文注意機制通過計算當前目標端信息Q和源端信息K的關系,來對源端信息V進行整合得到輸出.而在自注意機制中,Q,K,V都是來自源端信息,自注意機制計算了源端信息本身內部存在的依賴關系,從而可以將信息中的重要部分提取出來,得到關系化的特征表示.
無論是理論上還是實踐上,注意機制在各種計算機視覺和自然語言處理任務中都起到了重要作用,在圖像描述生成任務中也占據著重要地位,并顯著提升了系統性能.
2 圖像描述生成方法
圖像描述生成經過多年的發展,研究者提出了大量的方法,對這些方法進行分類也存在多種標準.這里按照圖像描述生成發展過程的時間線對這些方法進行劃分,大致可分為四大類:基于模板的方法、基于檢索的方法、基于編碼器-解碼器架構的方法和基于復合架構的方法.基于模板的方法和基于檢索的方法是早期的方法[2].前者依賴于硬編碼的語言結構,而后者則利用訓練集中現成的描述語句,因此它們的共同缺點是不夠靈活,在生成描述的表達上受到較大的限制.基于編碼器-解碼器架構的方法和基于復合架構的方法則是基于深度學習的方法[3-4],其中又以基于編碼器-解碼器架構的方法更為通用.在深度神經網絡中,CNN等具有強大的圖像特征提取能力,LSTM等具有良好的時間序列數據處理能力,這使得基于深度神經網絡的方法能夠在性能上取得突破,成為當前圖像描述生成的主流方法.
2.1 基于模板的方法
基于模板的方法通過對語法和語義的約束過程來生成圖像描述.通常,該方法先檢測出圖像中特定的一系列視覺概念,然后通過語句模板、特定的語法規則或組合優化算法等將這些概念進行連接以生成描述語句.
Yang等人[33]利用四元組〈名詞,動詞,場景,介詞〉作為生成圖像描述的語句模板.首先使用檢測算法評估圖像中的物體和場景,然后利用語言模型預測可能用于構成描述語句的動詞、場景和介詞,并利用隱Markov模型推理得到最佳的四元組,最后通過填充四元組給出的語句結構生成圖像描述.Kulkarni等人[34]用圖結點分別對應物體、屬性及空間關系等,通過條件隨機場確定需要呈現在圖像描述中的圖像內容,然后基于語句模板將推理的輸出轉換成圖像描述.Li等人[35]首先使用視覺模型檢測圖像并提取物體、屬性和空間關系等語義信息,然后定義三元組〈〈形容詞1,物體1〉,介詞,〈形容詞2,物體2〉〉對識別的結果進行編碼,并執行短語選擇和短語融合,最終得到優化的短語集合作為圖像描述.Mitchell等人[36]使用〈物體,動作,空間關系〉的三元組來表示圖像,并根據視覺識別結果將圖像描述視為1棵樹的生成過程:首先通過對物體名詞的聚類和排序,確定要描述的圖像內容;然后為物體名詞創建子樹,并進一步創建完整的樹;最后,利用Trigram語言模型從生成的完整樹中選擇字符串作為對應圖像的描述.Lebret等人[37]提出了軟模板的方法生成圖像描述.該方法首先提取訓練語句中的短語并進行統計,通過詞向量表示方法將短語表示為高維向量,并使用CNN獲取圖像特征.隨后訓練1個雙線性模型度量圖像特征和短語特征之間的相似度,可以為給定圖像推斷出短語,并在上一階段統計的基礎上進一步生成描述語句.Lu等人[38]提出基于模板生成和填槽的圖像描述生成方法,其主要思想是將生成語句的單詞分為實體詞與非實體詞2個詞表.語句模板由1個語言模型獲得,其單詞來自非實體詞表.實體詞則由物體檢測方法直接從圖像獲得,用于填充語句模板中的空槽,形成1個語句.這種方法開創性地使用神經網絡來提取語句模板,從而成功解決了傳統的基于模板的方法缺乏多樣性輸入的問題.
基于模板的方法能夠生成語法正確的語句,且與圖像內容的相關性強.然而,因為這類方法依賴于視覺模型識別圖像內容的精確性,所以生成的語句在廣泛性、創造性和復雜性上有缺陷.此外,與人工描述相比,使用嚴格的模板作為語句結構使得生成的描述不夠自然.
2.2 基于檢索的方法
給定1幅查詢圖像,基于檢索的方法通過從預先定義的語句集中利用相似度匹配的方法檢索出1個或1組語句作為該圖像的描述語句.生成的描述語句可以是1個現有的語句,也可以是1個由檢索結果得到的多個語句組合而成的語句.
Farhadi等人[39]提出基于三元組〈物體,行為,場景〉構建語義空間以連接圖像和語句.給定1幅查詢圖像,該方法通過求解Markov隨機場將給定圖像映射到語義空間,并使用相應的相似度度量措施計算給定圖像與現有語句的距離,將與給定圖像最相似的語句作為相應的描述.Ordonez等人[40]首先提取給定查詢圖像的全局特征表示,從帶有描述語句的圖像集中檢索出一系列圖像;然后對檢索得到圖像的語句進行重新排序,將排位最靠前的語句作為給定圖像的描述.Hodosh等人[41]利用核典型相關性分析技術將圖像和文本投影到公共空間,使得訓練圖像與其相應的描述相關性最大.在這個公共空間中,通過計算圖像和語句的余弦相似度來選擇排位最靠前的語句作為給定圖像的描述.
文獻[39-41]直接使用檢索得到的語句作為給定查詢圖像的描述,隱含的假設是總存在1個語句適合描述給定圖像,然而現實中此假設未必正確.于是,另一些基于檢索的方法利用檢索得到的語句進行重新組合得到給定圖像的新描述.Gupta等人[42]首先基于給定圖像的全局特征執行檢索,然后訓練1個預測短語相關性的模型從檢索到的圖像中選擇短語,最后根據選定的相關短語生成描述語句.Kuznetsova等人[43]提出了一種基于樹的方法,利用Web圖像來構建圖像描述.在進行圖像檢索和短語提取后,將提取的短語作為樹片段,將模型描述組合為約束優化問題,采用整數線性規劃進行編碼并求解.
隨著深度學習技術的發展,利用深度神經網絡提取圖像特征逐步代替了早期使用的淺層模型和手工特征.Socher等人[44]使用深度神經網絡從圖像中提取特征,并利用最大化邊緣目標函數將得到的多模態特征映射到公共空間,最后基于圖像和語句在公共空間中的相似度進行語句檢索.Karpathy等人[45]提出了將語句片段和圖像片段嵌入公共空間,以便為給定查詢圖像的相關語句進行排序.該方法使用語句的依賴樹關系作為語句片段,將區域CNN檢測圖像得到的結果作為圖像片段,并設計了1個包括全局排序項和片段對齊項的最大化間隔目標的結構,將視覺和文本數據映射到公共空間.于是,圖像和語句之間的相似度可以基于片段相似度來計算,使得語句排序可以在更細的層次上進行.Ma等人[46]提出了多模態CNN框架,包括3種組件:圖像CNN用于編碼視覺數據,匹配CNN用于視覺和文本數據的聯合表示,多層感知機用于對視覺和文本數據的兼容性進行評分.該方法使用匹配CNN的各種變體來解釋圖像與單詞、短語、語句的聯合表示,最終基于多模態CNN的集成框架來確定圖像和語句之間的匹配分數.
基于檢索的方法能夠為給定的查詢圖像傳送格式良好的語句或短語,以生成圖像描述.雖然生成的語句通常語法正確、流暢,但是將圖像描述約束到已經存在的語句中并不能適應新的物體或場景的組合.在某些特殊情況下,生成的描述甚至可能與圖像內容無關.此外,這類方法的性能依賴于大量帶有描述語句的圖像,也使其應用受到很大的限制.
2.3 基于編碼器-解碼器架構的方法
在編碼器-解碼器架構下,編碼神經網絡(通常采用CNN)首先將原始圖像轉換成中間表示(可以是多模態空間或視覺空間等表示形式),然后解碼神經網絡(通常采用LSTM)將中間表示作為輸入,在注意機制的引導下,逐詞生成描述語句.其一般過程如圖4所示:
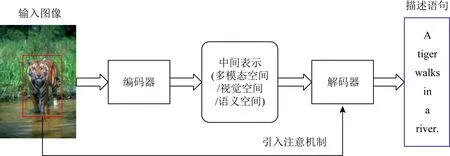
Fig.4 Image captioning based on encoder-decoder architecture圖4 基于編碼器-解碼器架構的圖像描述生成
按照各種圖像描述生成方法所重點關注的關鍵技術的不同,基于編碼器-解碼器架構的方法可進一步分為基于多模態空間的方法、基于視覺空間的方法、基于語義空間的方法、基于注意機制的方法和基于模型優化的方法五大類.
2.3.1 基于多模態空間的方法
這類方法在編碼時利用多個深度神經網絡(如CNN和LSTM)同時處理訓練圖像的視覺模態和文本模態數據,生成公共空間,即得到訓練圖像的多模態空間表示,然后進行解碼生成相應的圖像描述.
Kiros等人[47]最早使用編碼器-解碼器架構完成圖像描述生成任務.首先將圖像文本聯合嵌入模型和多模態神經語言模型相結合,使用CNN和LSTM分別對視覺和文本數據進行編碼;然后通過最小化對偶排位損失,將編碼的可視數據投影到由LSTM隱狀態所覆蓋的嵌入空間中,得到圖像的多模態空間表示;最后利用內容結構化的神經語言模型對多模態空間表示進行解碼,生成描述語句.Karpathy等人[48]提出了一種架構更簡單的深度視覺語義對齊模型,其基本思想是假定語句的某些部分對應的是圖像中特定的未知區域.該模型利用圖像區域CNN、語句雙向RNN和對齊2種模態的結構化目標來推斷語句片段和圖像區域之間的對齊.文本和圖像區域被映射到公共的多模態嵌入空間中,然后利用多模態RNN推斷出視覺和語義的對齊并生成新的描述語句.Mao等人[49]提出了多模態循環神經網絡(multimodal RNN,m-RNN),包含2個子網:1個CNN子網處理圖像和1個RNN子網生成語句.2個子網在多模態層中相互作用構成整個m-RNN模型,以圖像和語句片段作為輸入,計算生成描述語句下一個詞的概率分布.Chen等人[50]提出了一種新的基于多模態空間的方法.一方面,可以從圖像中生成新的描述,從給定的描述中計算視覺特征,即可以表示圖像及其描述語句之間的雙向映射.另一方面,可以從生成的單詞中動態更新圖像的視覺表示,還設計了1個附加的循環視覺隱藏層與RNN共同完成反向映射.
2.3.2 基于視覺空間的方法
這類方法在編碼時通常利用CNN直接處理訓練圖像,即得到圖像的視覺空間表示,或者經過預處理得到融合多個區域特征的視覺空間表示,然后進行解碼生成相應的圖像描述.
Vinyals等人[51]提出了神經圖像描述生成(neural image caption generator,NIC)方法,使用CNN獲取圖像表示并使用LSTM生成圖像描述.NIC的編碼器CNN使用新方法進行批量歸一化,并將CNN最后的隱藏層輸出作為解碼器LSTM的輸入,且LSTM能夠記錄已經使用文本描述過的物體.在生成圖像描述時,圖像信息包含在LSTM的初始狀態中,下一個詞是根據當前時間步和上一個隱狀態生成的,這個過程一直持續到描述語句的結束標記為止.由于圖像信息只在處理過程的開始時輸入,因此NIC可能面臨消失梯度問題,而且在生成長語句時仍然存在問題,開始產生的單詞作用會越來越弱.為此,Donahue等人[52]提出了長期循環卷積網絡.與NIC的不同之處在于,該網絡并不是只在初始階段向系統輸入圖像特征,而是在LSTM的每個時間步都為序列模型同時提供圖像特征和上下文詞特征作為輸入.此外,Jia等人[53]提出了一種LSTM的變體稱為gLSTM,可以生成長語句.該方法將全局語義信息添加到LSTM的每個門和單元狀態中,同時考慮了不同長度的規范化策略來控制描述語句的長度.由于單向LSTM是基于視覺上下文和所有之前生成的文本預測下一個單詞,因而不能生成上下文構造良好的描述.為此,Wang等人[54]提出了基于深度雙向LSTM的方法,其架構由1個CNN和2個獨立的LSTM組成,可以利用過去和將來的上下文信息來學習長期的視覺語言交互,因此能夠生成上下文信息和語義信息豐富的圖像描述.
Mao等人[55]提出了一種特殊的圖像描述生成方法,可以生成圖像中特定物體或區域的描述,稱為引用表達式.使用此表達式可以推斷正在描述的物體或區域,因而該方法可以生成語義明確的描述語句,同時還考慮了場景中的顯著物體.Gu等人[56]提出了逐步求精的學習思想,主要創新在于解碼階段使用了1個粗粒度的解碼器和多個細粒度的解碼器.其中粗粒度解碼器接受圖像特征作為輸入,并獲得粗粒度的描述結果,接下來在每個階段都有1個細粒度解碼器進行更精細的解碼,其輸入來自于上一階段解碼器的輸出結果和圖像特征,最終生成語義更完備的描述語句.Dai等人[57]探索圖像的另一種視覺表示,即用2維特征圖代替傳統的單個向量表示潛在狀態,并通過卷積將它們連接起來.這種空間結構對描述生成過程有顯著影響,對潛在狀態的編輯(例如抑制狀態中的某些區域)可能生成不同的描述.由于這種變體表示能夠保持空間局部性,因此可以加強視覺結構在描述生成過程中的作用.
2.3.3 基于語義空間的方法
隨著圖像描述生成技術的不斷進步,單純使用視覺特征向量表示圖像已經很難提升系統性能,越來越多的研究工作嘗試使用融合視覺特征和語義特征的方法表示圖像.通常認為圖像中的區域、物體和屬性等包含豐富的語義信息,因而不少方法提出在視覺空間的基礎上進一步獲取復雜的語義空間表示,然后利用高級語義信息生成圖像描述的思路.
You等人[58]提出了一種基于圖像語義概念表示的方法,分別使用CNN和1組視覺屬性檢測器從輸入圖像中提取1個全局特征和1組語義屬性,每個屬性對應于所用詞典的1個條目,要生成的單詞和要檢測的屬性共享相同的詞典.于是,解碼過程可以在語義空間上進行,從而獲得優越的性能.Wu等人[59]將視覺概念引入編碼器-解碼器框架,首先從訓練語句中挖掘出1組語義屬性,然后在基于區域的多標簽分類框架下,針對每個屬性訓練1個基于CNN的語義屬性分類器.該分類器可以將圖像表示為1個預測向量,并給出每個屬性在圖像中出現的概率,然后再使用LSTM作為解碼器生成描述圖像內容的語句.Wang等人[60]提出了一種新型的解碼器結構,由1個Skel-LSTM和1個Attr-LSTM聯合構成.前者使用CNN提取圖像特征生成主干語句及其屬性,后者為每個主干語句的屬性生成一系列的主干詞,然后再將2部分內容合成最終的描述語句.
Yao等人[61]提出了改進的架構集成語義屬性與圖像表示,主要采用2組不同的框架結構:在第1組結構中,只向LSTM插入語義屬性,或先向LSTM插入圖像表示再向LSTM插入語義屬性,反之亦然.在第2組結構中,可以控制LSTM的時間步長,決定圖像表示和語義屬性是一次性輸入還是在每個時間步都輸入.Li等人[62]提出了一種聯合視覺和語義的LSTM模型.首先利用Faster R-CNN和CNN分別提取圖像的低層視覺特征和高層語義特征;然后,在LSTM解碼過程中,視覺單元利用視覺特征對圖像中的物體進行定位,而語義單元則將定位后的物體與其語義屬性進行集成,并據此生成相應的單詞.為了揭示圖像中難以直接表達的隱含信息,Huang等人[63]將從知識圖譜中抽取出來的外部知識輸入到LSTM語言生成器的單詞生成階段,以增加某些可能被用來描述圖像內容的單詞的概率,實現內部知識與外部知識的集成,從而能夠生成新穎的圖像描述.
Jiang等人[64]提出了循環融合網絡(recurrent fusion network,RFNet),采用多個CNN作為編碼器,并在編碼器后插入1個循環融合過程,以獲得更好的圖像表示輸入解碼器.融合過程分為2個階段:第1階段利用來自多個CNN表示之間的交互來生成多組思維向量;第2階段則融合生成的多組思維向量,并為解碼器生成1組新的思維向量.Yao等人[65]提出結合圖卷積網絡(graph convolutional network,GCN)和LSTM的架構,將語義關系和空間物體關系集成到圖像編碼器中.該方法基于從圖像中檢測到物體的空間和語義關系來構建圖,然后通過GCN利用圖結構對物體上的推薦區域表示進行細化,基于細化的區域級視覺特征能夠生成更準確的描述.Chen等人[66]提出了一種新的基于組的圖像描述生成方案GroupCap,將組圖像之間的結構相關性和多樣性聯合建模,以實現最佳的協同描述生成.首先提出視覺樹解析器來構造單個圖像中的結構化語義關聯,然后利用樹結構之間的關聯來建模圖像之間的相關性和多樣性,最后將這些關聯建模為約束并發送到基于LSTM的描述生成器中.
為了使現有的編碼器-解碼器架構具有人性化的推理能力,Yang等人[67]提出了一種新的學習框架稱為配置神經模塊(collocate neural module,CNM),用以生成連接視覺編碼器和語言解碼器的“內部模式”.CNM的編碼器包含1個CNN和4個神經模塊(分別對應物體、屬性、關系和功能),用來生成不同的語義特征;解碼器有1個模塊控制器,可以將這些特征融合到1個特征向量中,以便解碼器處理.此外,Yang等人[68]利用符號推理和端到端多模態特征映射2種方法的互補優勢,將語言生成的歸納偏差引入到編碼器-解碼器架構中,使用場景圖來縮減視覺感知和語言構成的鴻溝.場景圖通過有向邊連接物體(或實體)、物體的屬性及物體在圖像或語句中的關系.該方法將圖結構嵌入到向量表示中,并無縫地集成到編碼器-解碼器框架,于是向量表示將歸納偏差從純語言領域轉移到視覺語言領域.Chen等人[69]提出基于抽象場景圖的結構來表示用戶在細粒度級別的意圖,并控制描述的詳細程度.抽象場景圖由3種抽象節點(物體、屬性、關系)組成,以沒有任何具體語義標簽的圖像為基礎.在此基礎上實現的模型能夠有效識別用戶意圖和圖像中的語義信息,因而能夠生成期望的描述語句.
2.3.4 基于注意機制的方法
2.3.1~2.3.3節討論的一些方法在為圖像生成描述時無法隨著時間的推移分析圖像,且通常將場景作為一個整體來考慮,而不考慮與描述語句部分相關的圖像局部層面.基于人類的視覺注意機制[31],研究者提出了利用注意信號來引導圖像描述生成,能夠很好地緩解這個問題.這類方法的典型過程如圖5所示:
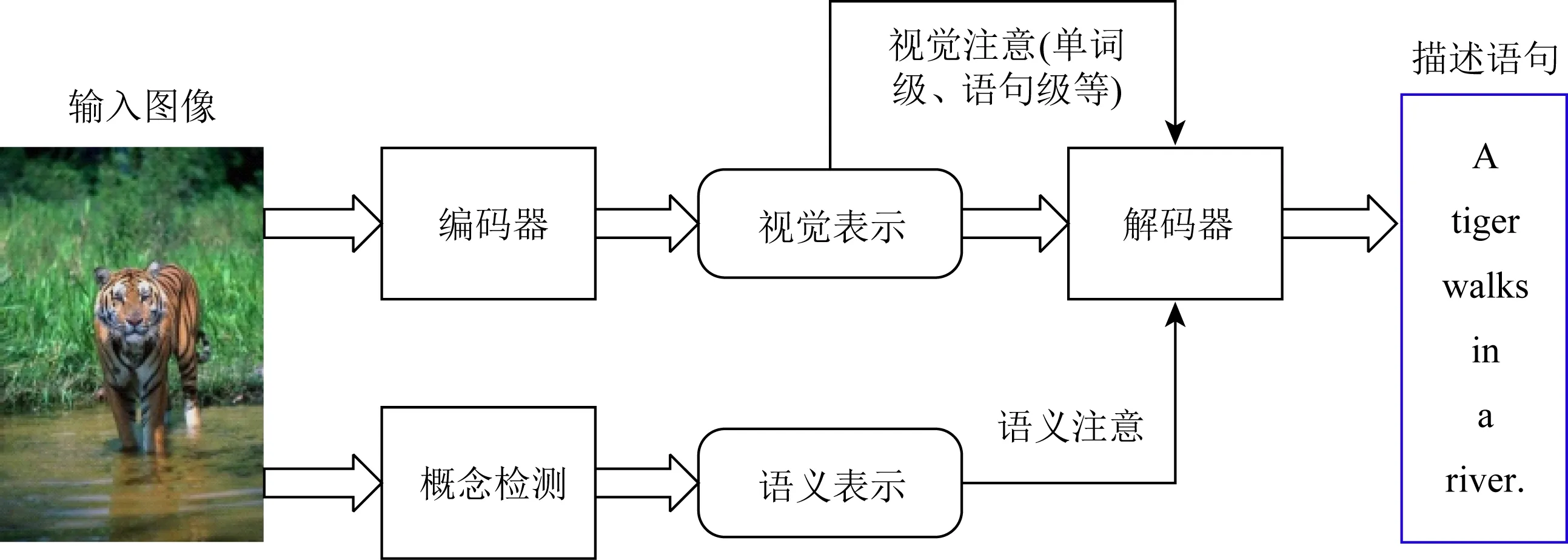
Fig.5 Image captioning guided by attention mechanism圖5 注意機制引導的圖像描述生成
由圖5可見,通過將注意機制引入到編碼器-解碼器框架中,語句生成將以基于注意機制計算的隱狀態為條件.這類方法中使用的注意信息大致可分為視覺注意和語義注意,其中視覺注意又可分為單詞級注意和語句級注意等多個層級.如果希望同時利用多級注意信息,還需要提供協同機制以結合不同的注意.注意機制的重要性體現在,它可以在生成輸出序列的同時動態聚焦于輸入圖像的各個局部層面,因而可以達成整體和局部的平衡.
Xu等人[70]最先在圖像描述生成方法中引入注意機制,提出能夠自動描述圖像顯著內容的方法.該方法首先用CNN將圖像表示為N個向量,每個向量表示圖像的部分區域,然后提出隨機性硬注意機制和確定性軟注意機制2種不同的方法來產生注意信號.在每個時間步中,隨機性硬注意機制從N個位置中選擇1個視覺特征作為上下文向量生成1個單詞,而確定性軟注意機制將所有N個位置的視覺特征結合起來,獲取上下文向量生成1個單詞.Yang等人[71]提出利用評論網絡來強化編碼器-解碼器架構.該方法首先執行多個評論步驟,對編碼器的隱狀態應用注意機制,并在每個評論步驟后都輸出1個思維向量;然后將這些思維向量作為解碼器中注意機制的輸入.
由于注意信號主要集中在RNN每個時間步的圖像上,但有些單詞或短語存在不必要的注意視覺信號,那么這些不必要的視覺信號就可能會影響生成描述的總體性能.因此,Lu等人[72]提出了基于視覺哨兵的自適應注意方法,可以確定什么時候關注圖像區域,什么時候關注語言生成模型.該方法引入新的空間注意方法,可以從圖像中計算出空間特征,然后在自適應注意方法中引入1個擴展的LSTM,能夠產生1個額外的視覺哨兵,為解碼器提供1個回退選項.此外,還有1個哨兵門用以控制解碼器從圖像中獲得信息的多少.Chen等人[73]提出SCA-CNN(spatial and channel-wise attention CNN),在CNN中融合了空間注意和通道注意.在生成圖像描述的過程中,SCA-CNN在多層特征圖中動態地調整多層特征圖和生成語句的上下文,對視覺注意的位置(即多層特征圖中關注的空間位置)和內容(即關注的通道)進行編碼.Fu等人[74]提出了在圖像和文本之間采用平行結構的新方法,在圖像的多個尺度上引入了多個可視區域,能夠根據視覺信息與文本信息之間的語義關系提取抽象語義流,還可以通過引入特定場景的上下文來獲取更高級的語義信息.
基于注意的方法在生成單詞或短語時會尋找圖像的不同區域,但這些方法生成的注意圖并不總是對應于圖像的某個適當的區域,這也會影響描述生成系統的性能.為此,Liu等人[75]提出了新的神經圖像描述生成方法,可以在每個時間步對注意圖進行評估和校正.該方法引入了1個定量的評估指標來計算注意圖,并提出監督注意模型,包含了對齊標注的強監督和語義標簽的弱監督2種監督信息.Pedersoli等人[76]提出了基于區域注意的圖像描述方法,將圖像區域與給定RNN狀態的描述詞相關聯,可以預測RNN的每個時間步的下一個詞和對應的圖像區域.該方法將新的注意機制與空間變換網絡相結合,可以生成高質量的圖像描述.
多數圖像描述方法采用自頂向下的方法構建視覺注意圖,通常從CNN的輸出中獲得一些選擇性區域作為圖像特征.You等人[58]在獲取圖像視覺概念的基礎上提出了新的語義注意模型,可以同時利用自底向上和自頂向下的方法并互補不足.在編碼器-解碼器框架下,全局視覺特征僅在編碼階段的初始步驟發送給CNN,而在解碼階段則使用1個輸出注意函數利用獲取的語義級概念指導LSTM生成對應的圖像描述.Anderson等人[77]提出了結合自底向上和自頂向下的注意機制,其中自底向上的注意機制基于Faster R-CNN推薦圖像區域,使用與推薦區域相關聯的特征向量,而自頂向下的注意機制則確定特征權重.因此,該方法既適用于物體級區域,也適用于其他圖像級顯著區域.Cornia等人[78]提出的圖像描述生成框架既能基于圖像的區域獲取特征,又允許對這些區域序列進行控制.給定圖像區域序列或集合形式的控制信號,該方法通過1個循環架構生成相應的描述.這個循環架構能夠顯式地預測基于區域的各個文本塊,并根據給定控制信號的約束生成多樣化的描述語句.Huang等人[79]提出了“注意上的注意”(attention on attention,AoA)模塊,擴展了傳統的注意機制來確定注意結果和查詢之間的相關性.AoA首先利用注意結果和當前上下文生成“信息向量”和“注意門”,然后通過對它們進行對應元素相乘操作來加上另一個注意,得到最后的“注意信息”,即期望的有用知識.該方法將AoA模塊同時應用于圖像描述生成架構的編碼器和解碼器,因而稱為AoA網絡.
注意機制大致分為上下文注意機制和自注意機制,在此基礎上可以引入單詞級注意、語句級注意和語義級注意等多個層級.結合多級注意機制獲取更好的圖像描述性能是個值得研究的課題.Wei等人[80]在圖像描述生成方法中引入自注意機制,用以提取圖像的語句級注意信息.并在此基礎上進一步提出了雙注意模型,通過結合語句級注意和單詞級注意生成圖像描述.由于該方法能夠結合圖像的全局和局部信息,因而生成的描述表達更準確且語義更豐富.Guo等人[81]對自注意機制進行改進:首先,提出了規范自注意模塊,對自注意重新參數化,有益于自注意內部的規范化;其次,提出了幾何感知自注意模塊,使自注意能夠明確有效地考慮圖像中物體之間的相對幾何關系,從而彌補Transformer模型[30]無法對輸入物體的幾何結構進行建模的局限性.Li等人[82]探討上下文感知組描述的新任務,其目的是以另外1組相關參考圖像作為上下文生成1組目標圖像的描述.為此,提出了將自注意機制與對比特征構建相結合的框架,既能捕捉每個組圖像之間的區分信息,同時也能有效地總結每個組的共同信息.Liu等人[83]提出的方法在生成過程中使用融合網絡集成視覺注意和語義注意.在生成描述語句的每個時間步,解碼器根據生成的上下文自適應地將提取的語義主題信息和圖像中的視覺注意信息合并,從而能夠有效地將視覺信息和語義信息結合起來.Ke等人[84]提出反射解碼網絡以增強解碼器中單詞的長序列依賴性和位置感知能力.該網絡能學習協同關注視覺和文本特征,同時感知每個單詞在語句中的相對位置,以最大化生成語句中傳遞的信息.李志欣等人[85]提出了結合視覺注意和語義注意的圖像描述方法,首先對現有的視覺注意模型進行改進以獲取更準確的圖像視覺信息,然后利用LDA模型與多層感知機提取出一系列主題詞來表示圖像場景語義信息,最后基于注意機制來確定模型在解碼的每一時刻所關注的圖像視覺信息和場景語義信息,并將它們結合起來共同指導模型生成更準確的描述語句.
2.3.5 基于模型優化的方法
由于圖像內容的復雜性,精確地標注圖像數據常常是不切實際的,因而如何充分利用無標簽圖像數據成為重要問題.于是,利用強化學習與無監督學習方法進行模型優化成為自然的思路,也已經在圖像描述生成的任務中獲得了良好的效果.
基于強化學習的圖像描述生成主要針對評估指標進行優化,能夠提高模型的整體評估得分.其過程通常分為2步:首先,構建結合CNN和RNN的“策略網絡”用于控制解碼器生成圖像描述;其次,構建結合CNN和RNN的“價值網絡”用于評估當前生成的部分描述語句,將獎勵信息反饋給第一個網絡,并調整動作以生成高質量的描述語句.這類方法的典型過程如圖6所示:
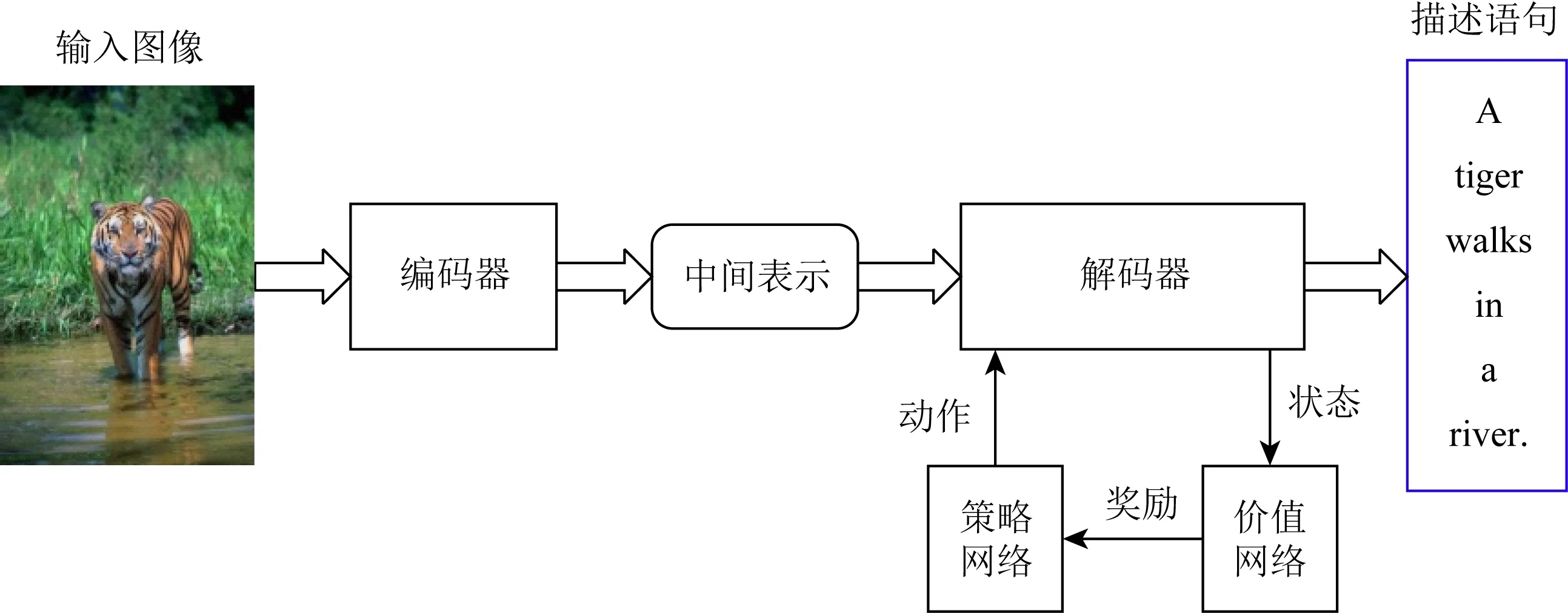
Fig.6 Image captioning based on reinforcement learning圖6 基于強化學習的圖像描述生成
Ranzato等人[86]提出基于RNN的策略梯度序列模型,利用強化學習方法直接在評估指標上優化模型,從而得到更好的描述生成結果.Liu等人[87]通過優化評估指標及其線性組合確保描述語句在語法上的流暢性以及描述語句在語義上與圖像相符合.該方法使用蒙特卡洛模擬方法代替了最大似然估計訓練與策略梯度混合的方法,比原來的混合方法更容易優化并獲得了更好的結果.Ren等人[88]提出的方法整體架構包含2個網絡,在每個時間步聯合計算最佳的下一個單詞.“策略網絡”作為局部指導,有助于根據當前狀態預測下一個單詞;“價值網絡”作為全局指導,對考慮到當前狀態所有可能擴展得到的獎勵值進行評估.該方法能夠在正確預測單詞的同時調整網絡,因而最后生成與原始描述相匹配的描述語句.Rennie等人[89]提出了自批評序列訓練(self-critical sequence training,SCST)的強化學習方法,不是通過估計一個“基線”來規范化獎勵和減少方差,而是利用自己的測試時間推理算法的輸出來對獎勵信號進行規范化.這種訓練方法可以避免估計獎勵信號和規范化的過程,同時可以根據其測試時間推理過程來協調模型.Zhang等人[90]提出了基于行動者-評論者強化學習的方法,可直接對評估指標不可微的問題進行優化.行動者將整個任務視為序列決策問題,并可以預測序列的下一個標簽;評論者的工作是預測獎勵值,如果預測的獎勵值符合預期,行動者將繼續根據其概率分布抽樣得到輸出.此外,由于現有大多數基于強化學習的圖像描述生成方法只關注語言策略,而不關注視覺策略(如視覺注意),因此無法捕捉對合成推理至關重要的視覺上下文.于是,Liu等人[91]提出了上下文感知視覺策略網絡(context-aware visual policy network,CAVP)以生成序列級的圖像描述,將視覺上下文集成到序列視覺推理中.CAVP在每一個時間步都將先前的視覺注意作為上下文進行顯式的解釋,然后根據當前的視覺注意判斷上下文是否有助于當前單詞的生成.與傳統的每一步只確定1個圖像區域的視覺注意相比,CAVP可以隨著時間的推移處理復雜的視覺合成.CAVP及其后續的語言策略網絡可以使用行動者-評論者策略梯度方法對任何評估指標進行端到端的高效優化.
基于無監督學習的方法可以充分利用無標簽圖像數據,增強現有的訓練數據并進一步優化模型.對抗學習是一類重要的無監督學習方法.與傳統的方法相比,基于對抗學習的圖像描述生成方法可以生成更多樣化的圖像描述,并能與強化學習策略相結合以提升描述語句質量.Dai等人[92]提出了新的基于條件GAN[93]的學習框架,在給定圖像和評估器(評估描述與視覺內容的匹配程度)的條件下,通過聯合學習得到生成器(生成圖像描述).在訓練序列生成器的過程中,該方法通過策略梯度算法優化模型,允許生成器沿著通道接收早期反饋.Shetty等人[94]采用對抗訓練與近似Gumbel采樣器[95]相結合,試圖將模型生成的分布與人類感知分布相匹配.該方法不僅在描述的正確性方面與當前先進方法相當,而且能夠生成多樣化的描述,偏向性顯著降低并且更符合人類感知.Chen等人[96]提出了跨域圖像描述生成器,使用新的對抗訓練方法來利用目標域中的未配對數據,可以在不需要目標域成對圖像-語句訓練數據的情況下,從源域到目標域自適應語句樣式.該方法引入了2個評論者網絡來指導圖像描述生成器:領域評論者評估生成的語句能否與目標域中的語句區分;多模態評論者評估圖像及其生成的語句是否有效成對.Dognin等人[97]研究基于條件GAN訓練圖像描述生成模型,提出了基于上下文感知的LSTM描述生成器和協同注意判別器,實現了圖像和描述語句之間的語義對齊.該工作還討論了圖像描述生成模型的自動評估問題,提出了1個新的語義評分方法,并證明了它與人類判斷的相關性.Feng等人[98]提出了無監督圖像描述生成模型,由圖像編碼器、語句生成器和判別器組成.CNN將給定的圖像編碼成1個特征表示,生成器根據這個特征表示輸出1個語句來描述圖像,判別器用于區分描述是由模型生成的還是從語句語料庫生成.生成器和判別器以不同的順序耦合以執行圖像和語句的重構.該模型通過策略梯度聯合引入對抗性獎勵、概念獎勵和圖像重構獎勵對生成器進行訓練.Gu等人[99]提出了基于場景圖的無配對圖像描述生成方法,其架構包括圖像場景圖生成器、語句場景圖生成器、場景圖編碼器和語句解碼器.該方法利用文本模態數據訓練場景圖編碼器和語句解碼器,并將場景圖特征從圖像模態映射到語句模態,從而實現圖像和語句之間的場景圖對齊.
綜上所述,基于編碼器-解碼器架構的方法通常采用端到端的方式將圖像中的內容轉換為描述語句,是當前圖像描述生成的主流方法.這類方法的參數可以聯合訓練,具有簡潔有效的特點,但有時難于識別復雜圖像中的細節,從而影響描述語句的質量.
2.4 基于復合架構的方法
在復合架構下,首先使用圖像理解部件來檢測輸入圖像中的視覺概念;然后,將檢測到的視覺概念發送到文本生成部件以生成多個候選描述語句;最后,使用一個多模態相似度模型對候選描述語句進行后處理,選擇其中的高質量語句作為輸入圖像的描述.其一般過程如圖7所示:
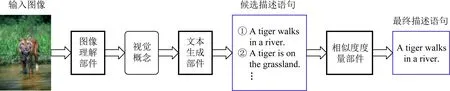
Fig.7 Image captioning based on compositional architecture圖7 基于復合架構的圖像描述生成
Fang等人[100]提出的圖像描述生成方法由視覺檢測器、語言模型和多模態相似度模型組成,先找出訓練語句中最常見的單詞,再通過CNN提取視覺特征,使用多示例學習方法訓練對應于每個單詞的視覺檢測器.給定1幅圖像,根據圖像中檢測到的單詞,采用最大熵語言模型生成候選描述語句.最后,利用深度多模態相似度模型將圖像和文本片段映射到公共空間并進行相似度度量,對候選描述語句進行重新排序.在這個工作的基礎上,Tran等人[101]提出了開放領域圖像描述系統,使用基于ResNet的視覺模型來檢測廣泛的視覺概念,同樣使用最大熵語言模型生成候選描述,并使用深度多模態語義模型進行描述語句排序.該系統增加了對地標和名人的檢測,及用于處理描述復雜圖像的信心模型.
為了對圖像內容進行詳細的描述,Ma等人[102]提出了使用結構詞進行圖像描述生成,分為結構詞識別和語句翻譯2個階段.該方法首先使用多層優化方法生成分層次的概念,將圖像表示為四元組〈物體,屬性,行為,場景〉,也就是所謂的結構詞.然后再利用基于LSTM的編碼器-解碼器翻譯模型,將結構詞翻譯成描述語句.Wang等人[103]提出了并行融合RNN和LSTM的架構,利用RNN和LSTM的互補性提高圖像描述生成的性能.該方法首先將輸入通過RNN單元和LSTM單元并行映射到隱狀態,然后將這2個網絡中的隱狀態與單詞預測的某些比率合并以生成圖像描述.此外,Gan等人[104]在圖像描述生成中引入語義合成網絡,其中語義概念向量由圖像中所有可能的概念合成,比視覺特征向量和場景向量具有更大的潛力,可以生成覆蓋圖像整體意義的描述.
盡管基于深度學習的圖像描述生成方法取得了很好的效果,但它們在很大程度上依賴于大量成對的圖像-語句數據集.而且這些方法只能在上下文中生成物體的描述,難于生成有新意的描述語句.發現新物體的方法試圖在生成的描述語句中出現不包含在訓練集的圖像-語句對中的物體,因此這類方法大多基于復合架構設計.Hendricks等人[105]提出了深度合成描述方法,利用大型物體識別數據集和外部文本語料庫,并通過在語義相似的概念之間傳遞知識來生成圖像語句數據集中不存在的新物體描述.Yao等人[106]在CNN和RNN的架構中引入復制機制來生成新物體的描述,首先使用自由獲取的物體識別數據集來為新物體開發分類器,然后將RNN逐詞生成的標準語句與復制機制結合起來,可以在輸出語句的適當位置選擇有關新物體的單詞.Venugopalan等人[107]提出的方法試圖發現圖像中的新物體,能夠充分利用外部知識來源,包括來自物體識別數據集的有標簽圖像,以及從無標簽文本中提取的語義知識.該方法提出了最小化聯合目標的訓練方法,可以從不同的數據源中學習,并利用分布式語義嵌入,使得模型能夠概括和描述在數據集之外的新物體.
基于復合架構的方法一般專注于識別復雜圖像中的細節,期望生成高質量的圖像描述,但這類方法通常包含多個獨立部件,訓練過程比較復雜.
除了以上方法之外,與圖像描述生成領域相關的還有一些其他研究方向和實現方法.除了發現新物體的描述方法和多樣化描述方法之外,風格化描述方法[108-109]希望生成的描述語句能模仿人類的獨特風格,而故事生成方法[110]試圖將生成的描述語句進一步組成段落故事,等等.也就是說,圖像描述生成的研究空間還非常廣,有待研究者進一步開展新的研究和改進現有方法.
3 實驗評估與性能比較
本節介紹圖像描述生成研究中常用的數據集和評估措施,并給出若干典型方法在2個基準數據集上獲得的性能評估指標數值.
3.1 數據集
在圖像描述生成的研究過程中,研究者構建了多個不同的數據集.本節介紹最常用的5個基準數據集,即MS COCO[111],Flickr8K[41],Flickr30K[112],Visual Genome[113],IAPR TC-12[114].
3.1.1 MS COCO數據集
MS COCO數據集[111]是一個用于圖像描述生成、物體識別、語義分割任務的大型數據集,通過在自然環境中收集日常復雜場景和常見物體的圖像而創建,包含用于識別和分割等任務的多種特征.該數據集規模在不斷地擴充,目前圖像數量已超過300 000幅圖像,每幅圖像包含至少5個人工標注的參考描述語句,共有91個分類,其中82個分類每個都超過5 000個實例物體.由于該數據集的規模大、圖像內容復雜,已成為圖像描述生成任務中最常用的數據集.
3.1.2 Flickr8K數據集
Flickr8K數據集[41]包含從Flickr提取的8 000幅圖像,主要內容包括人類和動物,每幅圖像都包含來自于亞馬遜眾包服務的5條描述語句.在圖像標注過程中,工作人員要求專注于圖像本身并描述其內容,而不考慮圖像中拍攝的文本.Flickr8K數據集中共有8 000幅圖片,其中訓練集6 000幅,驗證集和測試集各有1 000幅.
3.1.3 Flickr30K數據集
Flickr30K數據集[112]從Flickr8K數據集擴展而來,是一個用于圖像描述生成和語言理解的數據集.該數據集包含了31 783幅圖像,每幅圖像包含5條描述語句.圖像內容主要涉及人的日常生活和運動等,且不為訓練、測試和驗證提供任何固定的劃分.該數據集還包含公共物體檢測器、顏色分類器,并有選擇較大物體的偏向.
3.1.4 Visual Genome數據集
圖像描述生成不僅需要識別圖像的可視物體,還需要推理它們之間的相互作用和屬性.與前面數據集的描述語句針對整個場景不同,Visual Genome數據集[113]針對圖像中的多個區域有單獨的描述語句.該數據集有7個主要部分:區域描述、物體、屬性、關系、區域圖、場景圖和問答對.數據集包含的圖像數量超過108 000幅,每幅圖像平均包含35個物體、26個屬性和21個物體之間的成對關系.
3.1.5 IAPR TC-12數據集
IAPR TC-12數據集[114]收集了運動、相冊、動物、風景等自然場景圖像共20 000幅,圖像中通常包含多個物體,每幅圖像都包含多種語言(包括英語、德語等)的描述語句.該數據集用于圖像自動標注任務時,通常經過預處理后保留其中19 627幅,共包含291個語義標簽,平均每幅圖像4.7個標簽,劃分為17 665幅訓練圖像和1 962幅測試圖像.
3.2 評估措施
由于圖像描述生成系統輸出的自然語言描述的復雜性,評估其性能非常困難.為了評估生成的語句在語言質量和語義正確性方面是否與人類感知一致,研究者設計了多種度量指標來評估生成語句的質量,包括BLEU(bilingual evaluation understudy)[115],ROUGE(recall-oriented understudy for gisting evaluation)[116],METEOR(metric for evaluation of translation with explicit ordering)[117],CIDEr(con-sensus-based image description evaluation)[118],SPICE(semantic propositional image caption eval-uation)[119]等.其中BLEU和METEOR來源于機器翻譯,ROUGE來源于文本摘要,而CIDEr和SPICE是專門為評估圖像描述語句提出的.
3.2.1 BLEU
BLEU[115]是用于評估機器生成文本質量的度量指標,用候選語句的可變短語長度來匹配參考語句,通過計算精確率以衡量它們的接近程度.換言之,BLEU度量是通過n-gram模型比較候選語句和參考語句來確定的,使用unigram將候選語句與參考語句進行比較計算BLEU-1,使用bigram將候選語句與參考語句進行匹配計算BLEU-2,以此類推.根據經驗,確定最大值為4的序列,以獲得與人類判斷最佳的相關性.對于BLEU指標,unigram分數用于解釋語句相似度,而較高的n-gram分數用于解釋語句流暢性.但是,BLEU度量不考慮語法正確性,且受到生成文本大小的影響,在生成的文本很短時BLEU分數通常較高.因而在某些情況下,BLEU分數高并不意味著生成了高質量的文本.
3.2.2 ROUGE
ROUGE[116]通過計算召回率來衡量文本摘要質量,將單詞序列、單詞對和n-gram與人類創建的參考摘要進行比較.根據計算方法的不同,ROUGE又可分為ROUGE-N,ROUGE-L,ROUGE-W,ROUGE-S這4種類型,不同類型的ROUGE指標用于不同的任務.其中ROUGE-L旨在評估機器翻譯的充分性和靈活性,該度量指標采用候選語句和參考語句之間的最長子序列來度量它們在語句層次上的相似性.由于該度量指標自動包含序列中最長的公共n-gram,因而可以自然地捕獲語句級結構.
3.2.3 METEOR
METEOR[117]是用于評估自動機器翻譯的度量指標,它首先在候選語句和人類標注的參考語句之間進行廣義unigram匹配,然后根據匹配結果計算得分.計算涉及到匹配詞的精確率、召回率和對齊率.在多個參考語句的情況下,所有獨立計算出的參考語句中的最佳分數作為候選的最終評價結果.該度量指標的引入是為了彌補BLEU度量的不足,因為BLEU度量僅基于n-gram匹配的精確率得到.
3.2.4 CIDEr
CIDEr[118]是評估圖像描述質量的自動一致性度量指標,衡量圖像描述語句與人類標注的參考語句的相似度.該指標將候選語句中的n-gram出現在參考語句中的頻率進行編碼,并使用TF-IDF(term frequency-inverse document frequency)對每個n-gram進行加權來計算相似度,從而能夠體現生成的圖像描述與人類感知的一致性.這個度量指標的目的是從語法性、顯著性、重要性和準確性等方面對生成的描述語句進行評估.
3.2.5 SPICE
SPICE[119]是基于語義命題內容的圖像描述度量指標,它將候選語句和參考語句都轉換為場景圖表示,通過場景圖計算指標得分來評估描述語句質量.場景圖對圖像描述中的物體、屬性和關系進行了顯式編碼,并在編碼過程中抽象出自然語言的大部分詞匯和句法特征.
綜上所述,各個性能度量指標都有各自的適用范圍和優缺點,表1對此作了總結和比較.
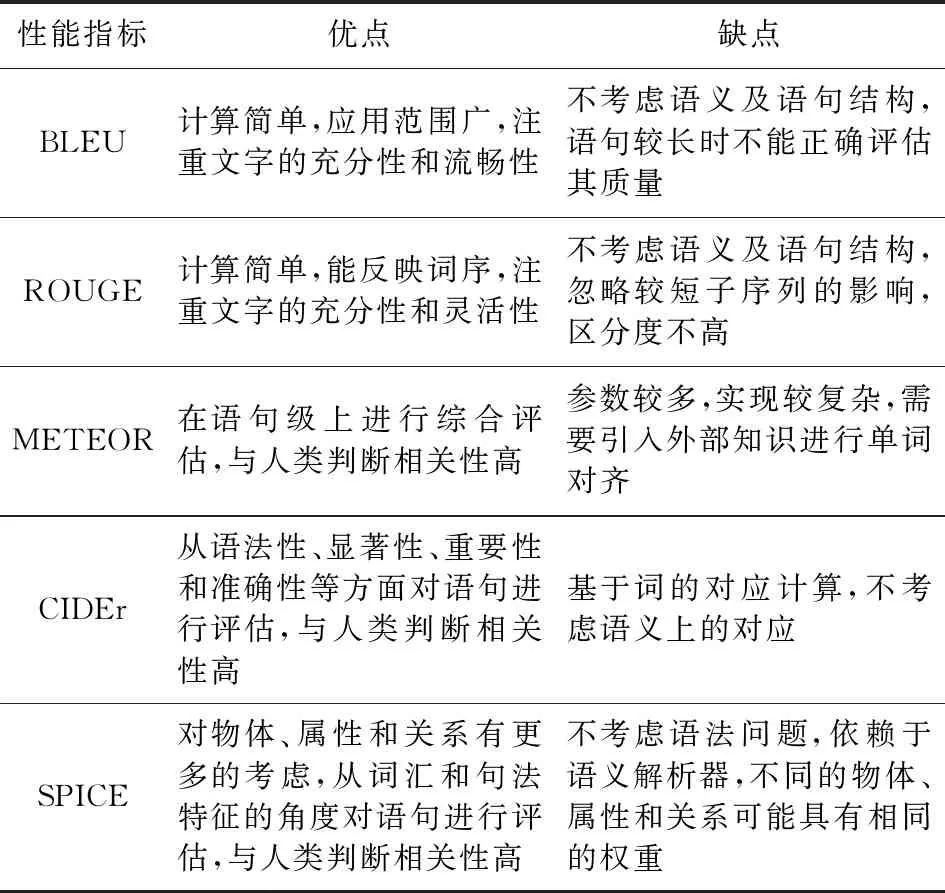
Table 1 Comparison of Advantages and Disadvantages of Performance Metrics表1 性能度量指標優缺點比較
3.3 典型方法性能比較
本節以最常用的MS COCO和Flickr30K數據集為基準,報告了一些典型方法在這2個數據集上得到的性能指標數據,并做簡要分析.
3.3.1 MS COCO數據集上的性能比較
MS COCO數據集是目前圖像描述生成領域應用最廣的基準數據集,大多數方法都報告了在該數據集上的實驗結果.由于基于模板的方法和基于檢索的方法性能普遍較低,而且大部分都沒有使用基準數據集和評估措施進行實驗,因此這里選取進行性能比較的典型方法都是基于深度學習的方法.所選方法包括:基于多模態空間的方法BRNN[48]和m-RNN[49];基于視覺空間的方法NIC[51],gLSTM[53],Stack-Cap[56];基于語義空間的方法ATT-FCN[58],Att-CNN+LSTM[59],RFNet[64],SGAE[68];基于注意機制的方法Soft-Attention[70],Adaptive[72],SCA-CNN[73],RA+SS[74],Up-Down[77],AoANet[79],VASS[85];基于模型優化的方法SCST[89]和G-GAN[92];基于復合架構的方法SCN-LSTM[104].所選19種典型方法在MS COCO數據集上的實驗結果如表2所示:
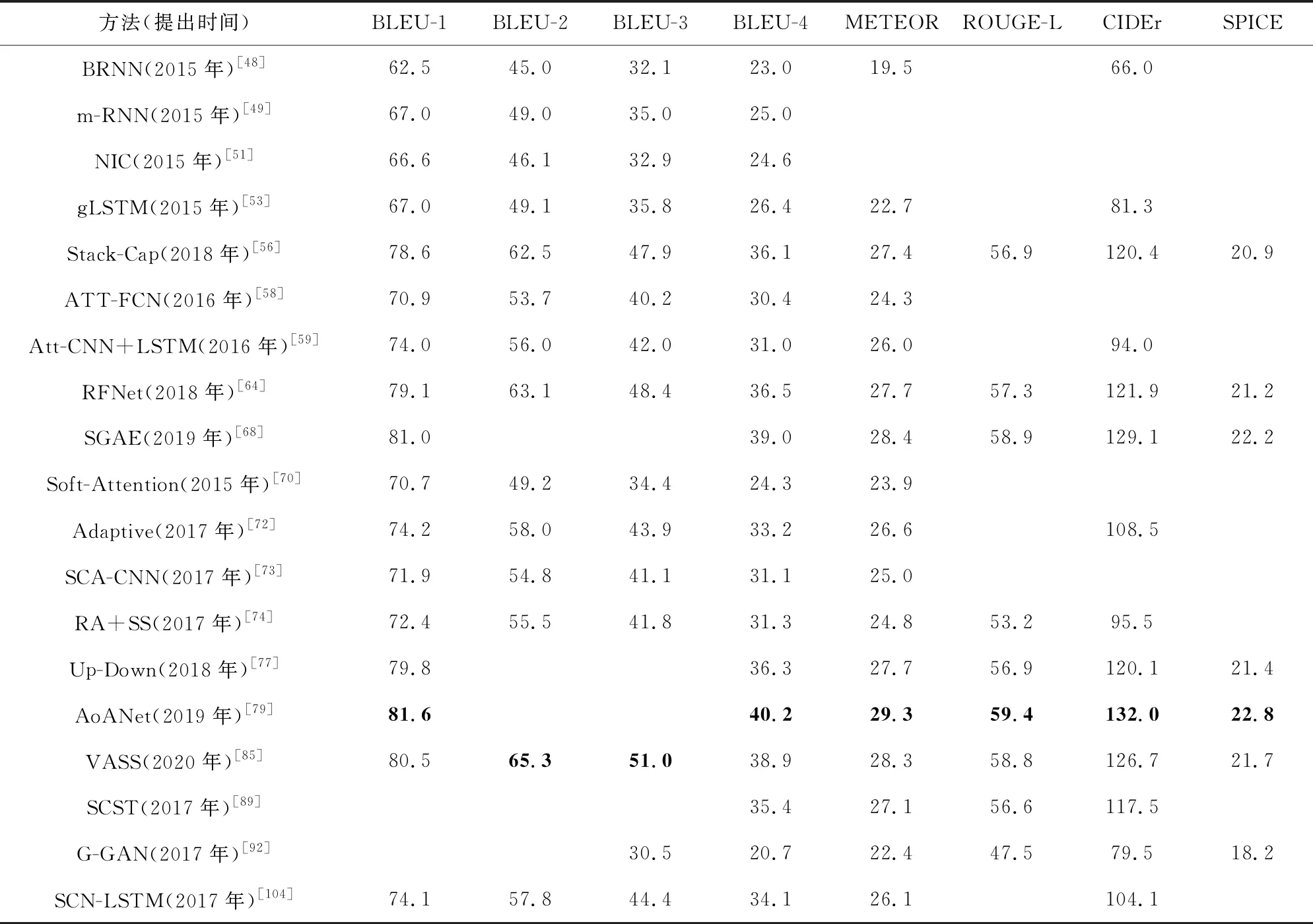
Table 2 Performance Comparison of Various Typical Methods on MS COCO Dataset表2 在MS COCO數據集上各種典型方法的性能比較
從表2中數據可以看出,圖像描述生成的性能指標大致隨著時間的推移逐步升高.近幾年基于注意機制的方法AoANet,VASS,Up-Down和基于語義空間的方法SGAE,RFNet性能指標要明顯高于前幾年的方法,其中AoANet的大部分指標在表2中最高.這19種方法大都設計了良好的網絡范式,融合了多種圖像特征生成復合的語義表示,同時結合不同的注意機制來指導描述語句的生成.這說明融合多種圖像特征和集成多級注意的方法對于生成準確的描述語句是行之有效的,也是未來的發展趨勢.基于視覺空間的方法Stack-Cap和基于強化學習的方法SCST的性能指標也相當高,這表明對視覺空間進行改進的方法可以獲得良好的性能,同時也表明強化學習對于提升描述語句的準確性非常有效.此外,盡管G-GAN方法的性能指標相對較低,但基于無監督學習的方法注重生成描述語句的多樣性和自然性,當前的性能指標并不能完全衡量其描述語句是否符合人類感知.
3.3.2 Flickr30K數據集上的性能比較
表3給出了一些典型方法在Flickr30K數據集上的實驗結果.由于這些方法都沒有報告SPICE的數值,所以只列出了其余7個性能指標的數值.此外,3.3.1節中的Stack-Cap,RFNet,SGAE,AoANet,Up-Down,SCST方法都沒有報告在Flickr30K上的實驗結果,因此在表3中沒有列出這些方法.
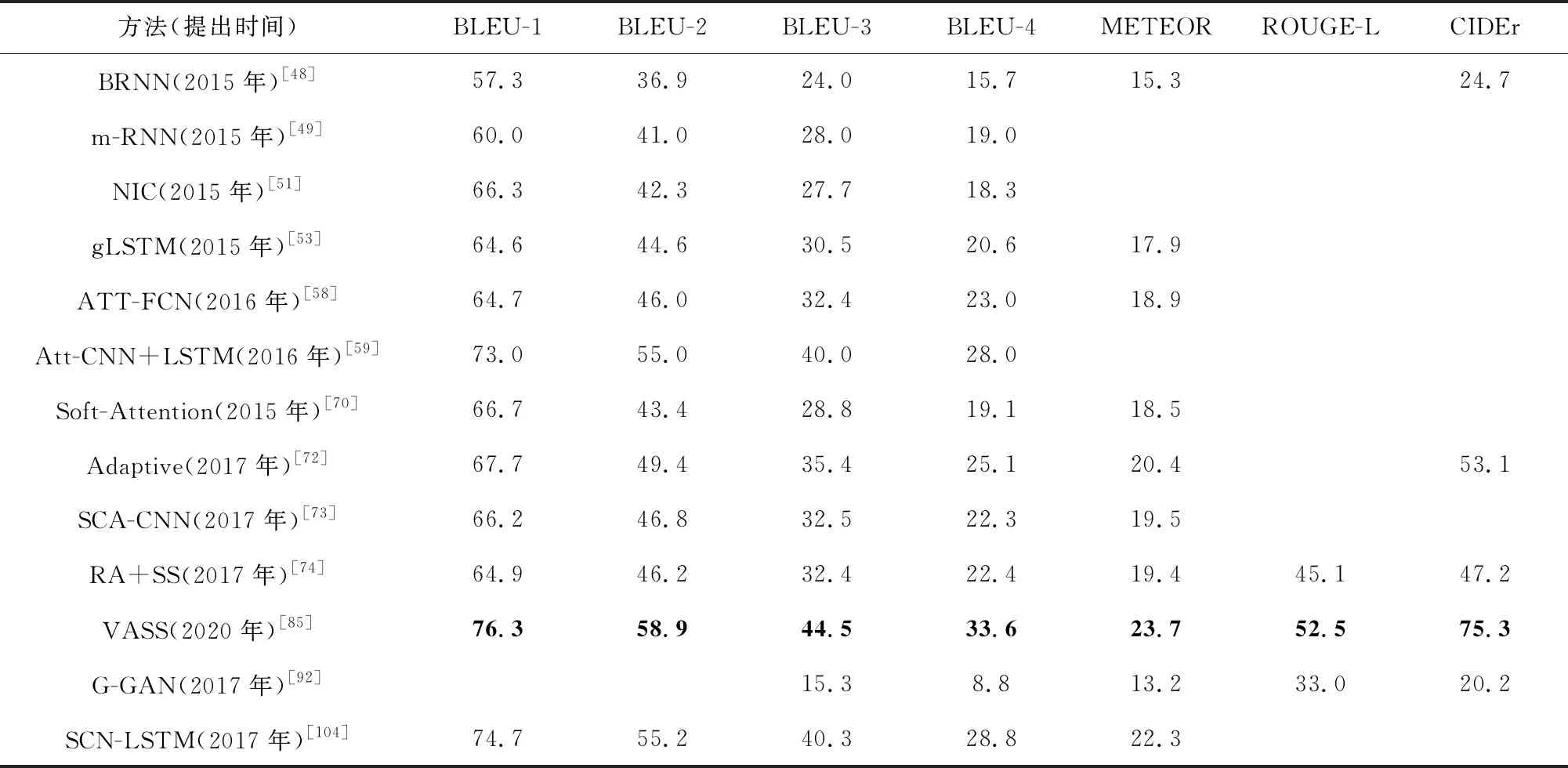
Table 3 Performance Comparison of Various Typical Methods on Flickr30K Dataset表3 在Flickr30K數據集上各種典型方法的性能比較
從表3可以看出,在Flickr30K數據集上,基于注意的方法VASS在這些典型方法中獲得了最高的性能指標,而基于復合架構的方法SCN-LSTM性能指標也相當高.這說明基于注意機制的方法和基于語義空間的方法仍然將在未來的研究中占據重要地位,而復合架構在圖像描述生成的發展中具有較大的潛力,其大致趨勢與在MS COCO數據集上的實驗結果一致.
4 未來趨勢展望
圖像描述生成近年來受到了研究者的廣泛關注,收獲了很多重要成果.然而,盡管目前基于深度學習的主流方法獲得了有效的結果和良好的性能,但仍然面臨著多方面的重大挑戰,也是未來的重點研究方向和發展趨勢.
4.1 識別細粒度語義生成區分性強的圖像描述
基于深度學習的方法能夠識別圖像中的一些重要語義概念(如老虎、鳥等),但是對于細粒度語義概念(如東北虎、夜鶯等)的識別仍然是個難題,需要在物體檢測、語義分割和圖像自動標注等課題的基礎上尋求解決方案.圖像細粒度語義識別的重大挑戰主要體現在類間差異小和類內差異大,如何檢測并學習圖像中的物體及其關鍵部件成為關鍵問題[5].此外,細粒度語義標注的成本要高于傳統語義標注,難于獲得大規模訓練集,這使得很多強監督方法難于實際應用,需要借助弱監督方法完成識別任務.在圖像描述生成任務中,識別細粒度的圖像語義對于生成更準確更具區分性的描述語句有重要意義.
4.2 改進語言模型生成語法正確的圖像描述
目前的圖像描述生成方法大都采用LSTM等深度神經網絡模型逐詞生成描述語句.但這類模型并沒有完全解決長期依賴問題,且本身的順序特征阻止了并行化,使得計算比較耗時.Transformer模型[30]使用注意結構取代LSTM,減少了計算量同時提高了并行效率,但這個思路還沒有在圖像描述生成任務上得到廣泛應用.在圖像描述生成過程中,引入新的有效的語言模型對于生成語句的語法和語義正確性無疑能起到重要作用.但是,改進語言模型本身是個難題,需要廣大自然語言處理領域的研究者通過長期的工作逐步解決問題.
4.3 探索學習架構生成完整細致的圖像描述
目前圖像描述生成的通用學習架構是編碼器-解碼器架構,將圖像描述生成過程視為從圖像“翻譯”到文本的過程.這種架構通常將圖像編碼為中間向量再以此作為依據進行解碼,中間向量包含的信息至關重要.如果中間向量包含的信息不足,將會導致生成的語句信息不完整.所以,這種架構有很大的改進空間,可以考慮改進編碼器端獲取更優的中間向量,也可以考慮改進解碼器端以便更充分地利用中間向量包含的信息.此外,編碼器-解碼器架構并不是唯一可行的學習架構,提出全新的學習架構顯然也是改善圖像描述質量的途徑.基于復合架構的方法強調識別復雜圖像中的細節,取得了一些進展,但還沒有重大突破.對于學習架構的探索,仍然是圖像描述生成領域的重要課題.
4.4 利用多級注意機制生成語序合理的圖像描述
注意機制在很多計算機視覺的任務中都得到了很好的應用,也已經證明能夠顯著提升圖像描述生成的性能.但目前多數注意模型只關注圖像中的局部實體特征,沒有關注實體間的相互關系,生成的圖像描述存在語義不夠完整和語序不合理的問題.為此,需要進一步挖掘不同層級的注意并加以整合,如協同單詞級和語句級的注意[80]、結合視覺注意與語義注意[85]等方法都是建立在整合不同層級注意的基礎上.如何設計整合不同層級注意并使它們協同工作的機制,以生成語義和語序更合理的圖像描述,仍然是圖像描述生成領域的重點研究方向.
4.5 集成外部知識推理生成新穎自然的圖像描述
現有的方法存在生成的圖像描述與原始描述過于相似的問題,且不具備像人類一樣的推理能力,難于發現圖像中隱含的新物體和新行為.然而,僅僅依靠圖像的視覺內容本身,很難解決這個問題.一個可行的思路是在圖像描述生成方法中引入外部知識并進行適當地推理[63],模仿人類自主學習新知識的方法和能力,使得生成的描述語句新穎自然,從而實現初步的視覺推理.如何引入外部知識,并通過知識圖譜等方法集成到現有的學習框架,使其具備從局部到整體、從屬性到語義的視覺推理能力,是圖像描述生成未來研究面臨的重大挑戰.
4.6 基于模型優化生成準確多樣的圖像描述
現有的圖像描述生成方法通常要依賴大量的圖像-語句對樣本進行訓練,才能取得較高的性能.然而,人工標注費時費力,難以獲得大量的有標簽樣本,這使得圖像描述的性能容易出現瓶頸.因此,基于無監督學習的方法擴充訓練集及基于強化學習的方法優化系統的評估指標成為突破性能瓶頸的重要思路.目前,生成的圖像描述在各種評估指標上都已經很高,但這很大程度上是因為生成的圖像描述可區分性不夠強.一方面,對于視覺內容有差異的圖像,生成的描述語句差異性不高,即生成語句的語義粒度不夠細致、描述不夠準確;另一方面,對于同一幅圖像,生成的描述語句相似度很高,即難于生成多樣化的描述語句.基于無監督學習的方法可以充分利用無標簽圖像擴充訓練集,生成多樣化的描述語句;而基于強化學習的方法則可以利用獎勵函數指引圖像描述生成的方向,使得系統生成更準確可靠的描述語句.
4.7 設計更符合人類感知的性能評估措施
目前圖像描述生成領域有BLEU,ROUGE,METEOR等多種常用的性能評估措施,但這些措施有各自的適用范圍,不能完全反映生成描述語句的質量.即使性能指標數值很高的系統生成的描述語句也仍然可能不符合人類感知,也就是說評估措施與人類判斷之間仍然存在著鴻溝.為緩解這個問題,一方面可以利用強化學習技術縮減評估措施與人類感知之間的差距,另一方面則需要設計出更好更全面的評估措施,既能反映描述語句質量(如語句多樣性度量),也能盡量與人類判斷保持一致,從而能夠更客觀地反映圖像描述生成系統的優劣.
5 結束語
綜上所述,圖像描述生成是一個極具挑戰性的課題,既要考慮圖像視覺理解的全局完整性和局部顯著性,也要考慮生成描述語句的語法正確性和表達自然性,還有可能需要指出圖像中不存在的物體和行為,生成有新意或者有風格的描述語句.在現有的技術條件下,為了最大限度地滿足用戶需求并生成更符合人類感知的描述語句,需要在多個方面開展更深入的研究:充分學習圖像中的視覺內容,獲得不同粒度的語義信息;改進語言模型保證生成語句的正確性;探索新的學習架構提升描述語句的質量;結合不同層級的注意信息指導語言生成;在外部知識的幫助下,借助知識推理增強模型功能;利用強化學習和無監督學習技術進一步優化模型;設計良好的性能評估措施,使得系統對生成語句的判斷盡量客觀并與人類判斷保持一致.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
