運用自然語言處理技術及時發現群眾反映的熱點問題
2021-09-12 14:51:22方小宇羅補干周鑠洋郭麗莎
科技尚品 2021年7期
方小宇 羅補干 周鑠洋 郭麗莎


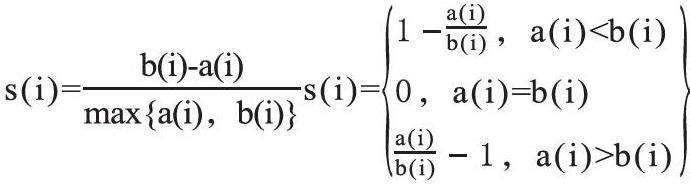
摘 要:某一時段內群眾集中反映的某一問題被稱為熱點問題。面對紛繁復雜的各類留言,人工尋找最需解決的問題即熱點問題,會耗費很多的時間和精力。因此,利用自然語言處理技術在眾多留言中挖掘熱點問題,是社會治理創新發展的新趨勢,有助于政府及時了解民意,提升服務效率。為了解決這個問題,通過對搜集的留言進行數據預處理,運用Single-Pass聚類算法,對留言進行聚類,利用輪廓系數進一步優化聚類效果,最終通過TextRank的自動文摘算法計算每個標題的權重并排名。權重越大的標題,說明群眾反映的問題最強烈,以此實現對熱點問題的及時發現。
關鍵詞:熱點問題;Single-Pass聚類;TextRank
中圖分類號:TP391文獻標識碼:A文章編號:1674-1064(2021)07-096-03
DOI:10.12310/j.issn.1674-1064.2021.07.047
1 國內外研究現狀
熱點事件提取是話題檢測與跟蹤(Topic detection and tracking,簡稱TDT)的一個分支[1],TDT是信息檢索的研究領域之一,包含五種任務,如表1所示。
TDT以事件信息組織為特征,以事件為目標。因此,大部分研究將TDT技術應用于事件檢測中(event detection)。相比傳統的信息檢索,TDT更傾向于處理動態非確定的概念,類別和基于內容的話題。然而傳統的信息檢索技術如文本分類、話題模型(topic model)、LSA等適合文檔分類和索引的方法,但卻不太適合事件和新事件發現,因而Allan、Laverenko等人提出基于傳統全文相似度的上界來檢測[2]。
事件檢測有許多種方法,主流的方式是采用聚類,這樣檢測事件可以借鑒傳統的信息檢索方法聚類對文檔進行聚類,將關聯文檔按照一定的度量方法,通常是相似度,將相關文檔放到同一個類中。每一個類代表一個單獨的事件或者話題。聚類可以分為兩類,一類是層次聚類(Hierarchical clustering)建立關系,將關系相近的簇聚成一類,分層進行聚類;另一類平聚類(flat clustering)并不利用層次關系聚類[3]。
Single-Pass聚類的類別生成是通過較新的數據與先前所有簇的相似程度。如果足夠相似,那么新的數據將被聚到先前的簇中;如果不夠相似,則作為新簇。Single-Pass被廣泛用于TDT中的新事件檢測任務中,Ron Papka提出了將Single-Pass聚類用于在線的新事件檢測中[4],每一個類用簇的平均值作為質心向量來表示。Hila Beckert提出一種集成方法,從文檔結構中提取標題詞、描述詞、地點和時間作為特征進行Single-Pass的聚類,側重相似度的度量,提出了歸一化互信息方法進行評價[5]。
2 主要步驟和任務
熱點問題挖掘主要包括文本預處理、文本聚類、聚類評估和熱點問題排行四個模塊。
2.1 基于Single-Pass聚類算法的留言聚類分析
首先將文本進行預處理,并建立VSM(Vector Space Model)向量,其能夠以空間上的相似度表達語義的相似度,直觀易懂。當文檔被表示為文檔空間的向量,就可以通過計算向量之間的相似性來度量文檔間的相似性。然后運用Single-Pass算法對文本進行聚類分析。
Single pass算法的基本流程[7]是,首先將第一篇到達的文本設為種子文件,然后后面依次到達的文本與已有的文本進行相似度比較,得到與先前文本最大的相似度。如果這個相似度大于給定的閥值,則將這個文本分配到與其相似度最大的文本所在的話題類中去;如果將此文本與所有的己存在文本比較,其相似度都小于給定的閾值,則以此文本建立一個新的聚類[6],該算法流程如圖1所示。
通過聚類,可以獲得每條回復所屬的話題(label列),聚類結果顯示共有254類。
2.2 基于輪廓系數的聚類效果評估
輪廓系數(Silhouette Coefficient),是聚類效果好壞的一種評價方式,最早由Peter J.Rousseeuw在1986年提出。其結合內聚度和分離度兩種因素,可以用來在相同原始數據的基礎上,評價不同算法或者算法不同運行方式對聚類結果所產生的影響。評估方法如下:
計算樣本i到同簇其他樣本的平均距離ai。ai越小,說明樣本i越應該被聚類到該簇。將ai稱為樣本i的簇內不相似度,簇C中所有樣本的ai均值稱為簇C的簇內不相似度。
計算樣本i到其他某簇Cij的所有樣本的平均距離bij,稱為樣本i與簇Cj的不相似度。定義為樣本i的簇間不相似度:bi=min{bi1,bi2,bik},bi越大,說明樣本i越不屬于其他簇。
根據樣本i的簇內不相似度ai和簇間不相似度bi,定義樣本i的輪廓系數:
判斷:si接近1,則說明樣本i聚類合理;si接近-1,則說明樣本i更應該分類到另外的簇;若si近似為0,則說明樣本 在兩個簇的邊界上。
筆者運用輪廓系數法對聚類結果進行評估,使用sklearn的silhouette_score方法實現,結果如圖2所示。
由圖2可知,隨著閾值的提高,輪廓系數也相應上升,聚類結果也有大幅提升,因此筆者重新選擇較大的閾值來獲取所需聚類結果。
2.3 基于TextRank的自動文摘算法
TextRank是一種基于圖的用于文本的排序算法[8],基本思想來自Google的PageRank算法[7]。類似于網頁的排名,對于詞語可得到詞語的排名,對于句子也可得到句子的排名,所以TextRank可以進行關鍵詞提取,也可以進行自動文摘。其用于自動文摘時的思想是:將每個句子看成PageRank圖中的一個節點,若兩個句子之間的相似度大于設定的閾值,則認為這兩個句子之間有相似聯系,對應的這兩個節點之間便有一條無向有權邊,邊的權值是相似度,接著利用PageRank算法即可得到句子的得分,把得分較高的句子作為文章的摘要。
TextRank算法的主要步驟如下:
預處理:分割原文本中的句子得到一個句子集合,然后對句子進行分詞以及去停用詞處理,篩選出候選關鍵詞集;
計算句子間的相似度:在原論文中采用如下公式計算句子1和句子2的相似度:
對于兩個句子之間相似度大于設定閾值的兩個句子節點,用邊連接起來,設置其邊的權重為兩個句子的相似度。
計算句子權重:
其中,Wi表示第i個句子的權重,Join(i)代表與第i個句子相連的全部句子集合,Similar(a,b)表示a與b的相似度。由該公式多次迭代計算直至收斂穩定之后,可得各句子的權重得分。
形成文摘:將句子按照句子得分進行倒序排序,抽取得分排序最前的幾個句子作為候選文摘句,再依據字數或句子數量要求,篩選出符合條件的句子組成文摘。
3 熱點問題排行
3.1 基于統計的總體問題的熱點排行
熱點問題(hot problem)的熱門程度依賴于兩個因素,一個是熱門詞語出現在留言中的次數,另一個是該詞在多少個留言中出現。熱點問題不可能一直熱門,隨著時間流轉,熱門程度會衰減,新的熱點問題會出現。因此,筆者將熱點問題定義為,一個問題在一段時間內頻繁出現。
根據對熱點問題的定義,筆者認為一個事件在一段時間內發生的次數越多,則其熱度越高,即熱度高的事件,留言出現的頻率也越高,同時,熱度受到持續時間的影響也不應過大。因此,筆者結合上述分析給出熱度指數的計算公式:
其中,Hot為事件的熱度指數,n為該事件在留言中出現的條數,N為總留言數,T為事件的持續時間,當持續事件小于10天時,文章取T=10。
3.2 基于TextRank自動文摘算法的熱點內部話題排行
利用TextRank算法進行熱點內部話題排行的過程:首先對每簇熱點問題合并所有的留言標題,接著用TextRank算法計算每個標題的權重,然后按照權重排序,得到標題的排行文件,用權重最高的標題當成主話題,至此過程結束。最終得到的熱點問題排行前五的結果如表2所示。
由表2看出,每條熱點都通過熱度指數大小進行排序,通過增加一列“hot_rate”來代表問題的熱度。該值越大,代表該類問題的熱度越高,由此就實現對群眾反映強烈的熱點問題的匯總。
參考文獻
[1] J.Allan,J.Carbonell,G.Doddington,et al.Topic detection and tracking pilot study:Final report[C].In Proceedings of Broadcast News Transcription and Understanding Workshop.Lansdowne,VA:NIST,1998:94-218.
[2] J.Allan,V.Laverenko.First story detection in TDT is hard[C].In Proceedings of the 9th international conference on Information and Knowledge Management(CIKM).New York,NY,USA:ACM press,2000:374-381.
[3] David M,Blei Ng,Andrew Y.Latent Dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[4] C.D.Manning,P.Raghavan,H.Schiutze.Introduction to information retrieval[M].New York,USA:Cambridge University Press,2008:108-200.
[5] Ron Papka,James Allan.On-line new event detection using single pass clustering[R].Technical Report:UM-CS-1998-021.MA,USA:University of Massachusetts Amherst,1998:20-30.
[6] Hila Becker,Mor Naaman,Luis Gravano.Event identification in social media.Twelfth International Workshop on the Web and Databases(WebDB 2009)[C].Providence,Rhode Island,USA:Association for the advancement artificial intelligence,2009:110-104.
[7] 張培偉.基于改進Single-Pass算法的熱點話題發現系統的設計與實現[D].武漢:華中師范大學,2015.
[8] 蒲梅,周楓,周晶晶,等.基于加權TextRank的新聞關鍵事件主題句提取[J].計算機工程,2017,43(8):219-224.
