基于多級(jí)語(yǔ)義的判別式跨模態(tài)哈希檢索算法
2021-09-09 08:09:18劉芳名
計(jì)算機(jī)應(yīng)用 2021年8期
劉芳名,張 鴻
(1.武漢科技大學(xué)計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,武漢 430065;2.智能信息處理與實(shí)時(shí)工業(yè)系統(tǒng)湖北省重點(diǎn)實(shí)驗(yàn)室(武漢科技大學(xué)),武漢 430065)
0 引言
隨著網(wǎng)絡(luò)的應(yīng)用和普及,多媒體數(shù)據(jù)在信息交互過(guò)程中急劇增長(zhǎng),這些多媒體數(shù)據(jù)種類(lèi)多樣、數(shù)量龐大,通常表達(dá)形式各異但描述的是同一事物[1-2]。現(xiàn)實(shí)中用戶(hù)在查找某一個(gè)事物的相關(guān)信息時(shí),渴望返回的結(jié)果有價(jià)值且全面豐富。因此,實(shí)現(xiàn)從一種模態(tài)數(shù)據(jù)(如文本)檢索出其他的模態(tài)(圖像或音頻)中與之相關(guān)數(shù)據(jù)的跨模態(tài)檢索得到研究者的關(guān)注。由于數(shù)據(jù)的規(guī)模和維度的增長(zhǎng),對(duì)大規(guī)模數(shù)據(jù)集的檢索時(shí),大部分的跨模態(tài)檢索方法遭受到高昂的存儲(chǔ)代價(jià)和時(shí)間損耗。跨模態(tài)哈希能夠?qū)⒏呔S度數(shù)據(jù)映射為緊湊的二進(jìn)制哈希碼并保留數(shù)據(jù)之間的相關(guān)性,此外跨模態(tài)哈希采用哈希碼表示高維數(shù)據(jù),在降低檢索時(shí)間的同時(shí)提高了檢索效率。因而跨模態(tài)哈希逐漸成為研究熱點(diǎn),盡管跨模態(tài)哈希檢索方法不斷突破,但是由于跨模態(tài)數(shù)據(jù)表達(dá)不一致導(dǎo)致的異構(gòu)鴻溝[3]和不同類(lèi)型數(shù)據(jù)在語(yǔ)義描述上存在差別所導(dǎo)致的語(yǔ)義鴻溝[4]是跨模態(tài)哈希檢索的難點(diǎn)。
為了解決跨模態(tài)數(shù)據(jù)間的異構(gòu)鴻溝,一些無(wú)監(jiān)督哈希方法通過(guò)潛在的語(yǔ)義信息學(xué)習(xí)統(tǒng)一哈希碼。盡管消除了異構(gòu)差異,但是缺乏標(biāo)簽語(yǔ)義監(jiān)督信息,不能較好地提高檢索性能。有監(jiān)督的跨模態(tài)哈希方法,如文獻(xiàn)[5]提出的判別性跨模態(tài)哈希(Discriminative Cross-modal Hashing,DCH)算法將標(biāo)簽信息嵌入到哈希碼學(xué)習(xí)過(guò)程使得類(lèi)內(nèi)數(shù)據(jù)彼此靠近,但明顯忽略了數(shù)據(jù)類(lèi)間關(guān)系。其他大多數(shù)方法[6-8]僅關(guān)注了跨模態(tài)數(shù)據(jù)類(lèi)間關(guān)系,卻不能聚合類(lèi)內(nèi)數(shù)據(jù)。生成對(duì)抗網(wǎng)絡(luò)(Generative Adversarial Network,GAN)[9]可以學(xué)習(xí)數(shù)據(jù)的真實(shí)分布,為了保持?jǐn)?shù)據(jù)原始的分布關(guān)系,最近許多基于此的跨模態(tài)檢索算法被提出。其中生成對(duì)抗網(wǎng)絡(luò)的半監(jiān)督跨模態(tài)哈希(Semi-supervised Cross-modal Hashing by Generative Adversarial Network,SCH-GAN)[10]在生成對(duì)抗網(wǎng)絡(luò)基礎(chǔ)上利用強(qiáng)化學(xué)習(xí),設(shè)計(jì)能使用未標(biāo)記數(shù)據(jù)相關(guān)性分布信息的生成對(duì)抗模型,有效提高了半監(jiān)督跨模態(tài)哈希的準(zhǔn)確性。引用標(biāo)簽信息和GAN中對(duì)抗思想的自我監(jiān)督的對(duì)抗式哈希(Self-Supervised Adversarial Hashing,SSAH)[11],最大化跨模態(tài)語(yǔ)義相關(guān)性和不同模態(tài)之間的一致性表示。
為了在保留類(lèi)間關(guān)系同時(shí)能夠進(jìn)行類(lèi)內(nèi)聚合,文獻(xiàn)[12]中提出的平等指導(dǎo)判別式哈希(Equally-Guided Discriminative Hashing,EGDH)關(guān)注語(yǔ)義結(jié)構(gòu)和判別性之間的聯(lián)系,使得最終學(xué)習(xí)到的哈希碼在保留語(yǔ)義相關(guān)性的同時(shí)具有判別性,實(shí)現(xiàn)較高的跨模態(tài)檢索精度。然而EGDH算法中采用的是0/1二值相似度矩陣監(jiān)督信息來(lái)指導(dǎo)函數(shù)學(xué)習(xí),多標(biāo)簽中豐富的語(yǔ)義信息被忽略了,也使得學(xué)習(xí)的哈希碼中語(yǔ)義關(guān)聯(lián)信息減少,降低跨模態(tài)檢索精度。
針對(duì)判別性哈希碼不能充分聚合類(lèi)內(nèi)數(shù)據(jù),以及二值相似度矩陣不能包含充足的語(yǔ)義相關(guān)信息的問(wèn)題,本文提出一種基于多級(jí)語(yǔ)義的判別式跨模態(tài)哈希檢索算法——ML-SDH(Multi-Level Semantics Discriminative guided Hashing)。該算法構(gòu)建了保留標(biāo)簽之間的多級(jí)語(yǔ)義關(guān)聯(lián)的多級(jí)相似度矩陣,充分利用多標(biāo)簽類(lèi)別中有價(jià)值的語(yǔ)義關(guān)聯(lián)信息;同時(shí)實(shí)現(xiàn)語(yǔ)義結(jié)構(gòu)的保留與判別性哈希碼學(xué)習(xí)兩者的結(jié)合,將哈希學(xué)習(xí)和多級(jí)語(yǔ)義學(xué)習(xí)嵌入到一個(gè)完整的深度學(xué)習(xí)框架中,探究基于哈希的檢索和分類(lèi)之間的聯(lián)系。通過(guò)上述方式保證了該算法學(xué)習(xí)到的哈希碼不僅具有豐富的多級(jí)語(yǔ)義信息,而且能夠更好地凸顯出跨模態(tài)數(shù)據(jù)之間的判別性。實(shí)驗(yàn)結(jié)果表明本文算法能夠有效提高跨模態(tài)檢索準(zhǔn)確率。
1 相關(guān)工作
跨模態(tài)哈希檢索在建立語(yǔ)義關(guān)聯(lián)的過(guò)程中學(xué)習(xí)哈希碼,并將哈希檢索的優(yōu)點(diǎn)運(yùn)用到跨模態(tài)檢索問(wèn)題中,在大規(guī)模的跨模態(tài)檢索任務(wù)中得到研究者們的關(guān)注。目前,跨模態(tài)哈希檢索方法可分為無(wú)監(jiān)督方法和有監(jiān)督方法。
無(wú)監(jiān)督哈希方法從未標(biāo)記數(shù)據(jù)的分布中學(xué)習(xí)哈希函數(shù)。傳統(tǒng)的無(wú)監(jiān)督哈希方法,將跨模態(tài)數(shù)據(jù)投影到漢明空間學(xué)習(xí)相似的哈希碼,如文獻(xiàn)[13]中提出的跨模式相似性敏感哈希(Cross-Modality Similarity-Sensitive Hashing,CMSSH)檢索算法,將哈希函數(shù)的學(xué)習(xí)當(dāng)成一個(gè)二元碼分類(lèi)問(wèn)題,最后利用boosting算法來(lái)進(jìn)行求解,學(xué)習(xí)了相似的哈希碼,但是檢索時(shí)間較長(zhǎng)。因而學(xué)習(xí)統(tǒng)一哈希碼的跨模態(tài)檢索方法[6-9]被廣泛應(yīng)用。其中文獻(xiàn)[7]提出的協(xié)同矩陣分解哈希(Collective Matrix Factorization Hashing,CMFH)算法使用協(xié)同矩陣分解求解公共的潛在語(yǔ)義空間,再根據(jù)共同的潛在語(yǔ)義學(xué)習(xí)統(tǒng)一的哈希碼。雖然減少了檢索時(shí)間,但是缺少監(jiān)督信息,檢索精度也不高。
有監(jiān)督哈希方法使用帶標(biāo)簽訓(xùn)練數(shù)據(jù)的語(yǔ)義監(jiān)督信息,比無(wú)監(jiān)督哈希方法提高了檢索進(jìn)度。文獻(xiàn)[14]使用的語(yǔ)義相關(guān)性最大化(Semantic Correlation Maximization,SCM)跨模態(tài)檢索算法,結(jié)合標(biāo)簽信息最大化數(shù)據(jù)的相關(guān)性。在文獻(xiàn)[15]中的語(yǔ)義保留哈希(Semantics Preserving Hashing,SePH)使用標(biāo)簽信息構(gòu)造一個(gè)親和力矩陣,并通過(guò)該矩陣的概率分布建模生成統(tǒng)一的哈希碼。成對(duì)關(guān)系指導(dǎo)的深度哈希(Pairwise Relationship guided Deep Hashing,PRDH)[16]使用成對(duì)跨模態(tài)數(shù)據(jù)的關(guān)聯(lián)信息指導(dǎo)哈希碼生成。以上這些方法僅關(guān)注了跨模態(tài)數(shù)據(jù)間關(guān)系或跨模態(tài)內(nèi)數(shù)據(jù)關(guān)系,無(wú)法在保持多級(jí)語(yǔ)義結(jié)構(gòu)的同時(shí)提高哈希碼的判別性。本文提出的跨模態(tài)哈希檢索模型,使用多級(jí)語(yǔ)義指導(dǎo)分類(lèi)器,在探究哈希碼的語(yǔ)義信息與判別性之間的聯(lián)系的同時(shí),能夠指導(dǎo)其他跨模態(tài)數(shù)據(jù)學(xué)習(xí)保持語(yǔ)義相似性和判別性的統(tǒng)一哈希碼,從而實(shí)現(xiàn)跨模態(tài)哈希檢索。
2 多級(jí)語(yǔ)義的判別式哈希表示
本文提出的基于多級(jí)語(yǔ)義的判別式跨模態(tài)哈希檢索算法的框架如圖1所示。為了充分使用標(biāo)簽中的語(yǔ)義信息,首先,本文提出多級(jí)語(yǔ)義標(biāo)簽矩陣;接著利用該多級(jí)語(yǔ)義標(biāo)簽矩陣構(gòu)建多級(jí)語(yǔ)義指導(dǎo)分類(lèi)器;最后使用該分類(lèi)器指導(dǎo)不同模態(tài)數(shù)據(jù)學(xué)習(xí)各自的哈希函數(shù)。
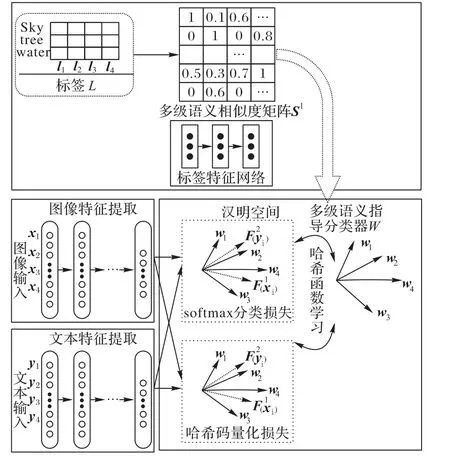
圖1 基于多級(jí)語(yǔ)義的判別式跨模態(tài)哈希檢索算法框架Fig.1 Framework of cross-modal retrieval based on multi-level semantic and discriminative hashing
2.1 基于多級(jí)語(yǔ)義的哈希表示



表1 符號(hào)定義Tab.1 Symbol definition
使用標(biāo)簽中的多級(jí)語(yǔ)義信息學(xué)習(xí)語(yǔ)義指導(dǎo)向量,并建通用分類(lèi)器W。在這個(gè)過(guò)程中,相似度損失與文獻(xiàn)[3]提出的基于深度語(yǔ)義相關(guān)學(xué)習(xí)的哈希(Deep Semantic Correlation learning based Hashing,DSCH)算法中相同。標(biāo)簽網(wǎng)絡(luò)的多級(jí)語(yǔ)義損失函數(shù)計(jì)算如下:

第二項(xiàng)為哈希碼量化損失,最后一項(xiàng)保證學(xué)習(xí)到的哈希碼正負(fù)值均衡分布。式(8)離散優(yōu)化后的哈希碼W是蘊(yùn)含多級(jí)語(yǔ)義的哈希表示。
2.2 分類(lèi)和多級(jí)語(yǔ)義哈希檢索
跨模態(tài)數(shù)據(jù)中的語(yǔ)義信息是實(shí)現(xiàn)基于哈希檢索的關(guān)鍵,多級(jí)語(yǔ)義相似度哈希碼中蘊(yùn)含了跨模態(tài)數(shù)據(jù)中豐富的語(yǔ)義信息,有助于實(shí)現(xiàn)高效的跨模態(tài)檢索。判別分類(lèi)方法將哈希碼當(dāng)作可區(qū)分的特征,使得最終的哈希碼具有判別性。語(yǔ)義相似度矩陣中蘊(yùn)含了語(yǔ)義相關(guān)信息,可用于實(shí)現(xiàn)基于哈希的檢索,分類(lèi)器可以用于數(shù)據(jù)保持判別性。因此,實(shí)現(xiàn)判別性和語(yǔ)義關(guān)聯(lián)相結(jié)合就是實(shí)現(xiàn)分類(lèi)和基于哈希的檢索相結(jié)合。


算法1總結(jié)了多級(jí)語(yǔ)義的判別式跨模態(tài)哈希檢索算法。整個(gè)算法過(guò)程分為兩部分:多級(jí)語(yǔ)義結(jié)構(gòu)的分類(lèi)器W的學(xué)習(xí)和跨模態(tài)數(shù)據(jù)哈希函數(shù)F1(θ2;xi),F(xiàn)2(θ3;yj)的學(xué)習(xí)。也就是需要優(yōu)化θ1、θ2、θ3。根據(jù)語(yǔ)義相似度損失函數(shù)J1和反向傳播算法更新θ1。根據(jù)式(6)計(jì)算wm更新W。依據(jù)更新的W和式(11)、(12),使用反向傳播算法分別更新θ2、θ3。
算法1 基于多級(jí)語(yǔ)義的判別式跨模態(tài)哈希檢索算法。
輸入:訓(xùn)練樣本文本數(shù)據(jù)X,圖像數(shù)據(jù)Y,標(biāo)簽L,哈希編碼長(zhǎng)度c,參數(shù)λ、γ、μ、η,學(xué)習(xí)率r1、r2、r3。
輸出:文本和圖像數(shù)據(jù)學(xué)習(xí)哈希函數(shù)過(guò)程中的超參數(shù)θ2、θ3,哈希碼H1、H2。
1)隨機(jī)初始化超參數(shù)θ1、θ2、θ3
2)重復(fù)
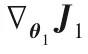
②根據(jù)式(8)計(jì)算wm并更新W。
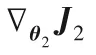
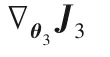
3)直到收斂
4)根據(jù)式(13)和式(14)計(jì)算,輸出H1、H2。
3 實(shí)驗(yàn)與結(jié)果分析
為了驗(yàn)證本文算法的有效性,本文在NUS-WIDE和mirflickr-25k兩個(gè)基準(zhǔn)數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),并和跨模態(tài)檢索算法CMFH[8]、SCM[14]、SePH[15]、DCMH(Deep Cross-Modal Hashing)[11]、PRDH[16]、EGDH[12]進(jìn)行兩個(gè)跨模態(tài)檢索任務(wù)的實(shí)驗(yàn)比較:圖像檢索文本、文本檢索圖像。
3.1 數(shù)據(jù)集描述
mirflickr-25k數(shù)據(jù)集[17],包含25 000個(gè)數(shù)據(jù)樣本,每個(gè)樣本中包含圖片文本標(biāo)簽對(duì),每個(gè)樣本被標(biāo)注成24種語(yǔ)義概念中的多種類(lèi)別,這些樣本都是多標(biāo)簽數(shù)據(jù)。與DCMH[9]一致,本文也刪除mirflickr-25k中無(wú)標(biāo)簽數(shù)據(jù),保留20015個(gè)帶標(biāo)簽的數(shù)據(jù)樣本作為實(shí)驗(yàn)數(shù)據(jù)集。其中每個(gè)樣本文本模態(tài)用1 386維詞袋(Bag-of-Words Vector,BoWV)向量表示。
NUS-WIDE數(shù)據(jù)集[18],最初包含269 648個(gè)樣本實(shí)例,同樣是多類(lèi)別標(biāo)簽數(shù)據(jù)樣本集合,每個(gè)實(shí)例都是帶有標(biāo)簽的圖像,都使用81個(gè)類(lèi)別的標(biāo)簽進(jìn)行標(biāo)注。本文與DCMH[11]類(lèi)似,選用前10個(gè)最常用語(yǔ)義標(biāo)簽的186 577個(gè)帶標(biāo)簽的圖像文本實(shí)例樣本對(duì)作為的數(shù)據(jù)集。每個(gè)樣本數(shù)據(jù)文本模態(tài)用2 000維BoWV向量表示。
在mirflickr-25k數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),隨機(jī)選取5 000個(gè)樣本作為訓(xùn)練集,2 000個(gè)數(shù)據(jù)對(duì)作為測(cè)試集,其余的樣本作為驗(yàn)證集。在NUS-WIDE數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn)時(shí),同樣隨機(jī)選取5 000個(gè)樣本作為訓(xùn)練集,選用2 000個(gè)樣本對(duì)作為測(cè)試集,其余的樣本作為驗(yàn)證集。
為了與基于淺層結(jié)構(gòu)的CMFH、SCM、SePH哈希方法公平比較,在實(shí)驗(yàn)中使用由預(yù)訓(xùn)練的快速卷積神經(jīng)網(wǎng)絡(luò)模型(Convolutional Neural Networks Fast,CNN-F)[19]網(wǎng) 絡(luò) 提 取 的4 096維圖像特征作為基于淺層結(jié)構(gòu)的方法的圖像輸入數(shù)據(jù)。
3.2 參數(shù)設(shè)置
標(biāo)簽特征網(wǎng)絡(luò)由三層前饋神經(jīng)網(wǎng)絡(luò)組成:第一層為輸入層;第二層包含4 096個(gè)神經(jīng)元;最后一層神經(jīng)元個(gè)數(shù)與哈希碼bit位數(shù)相同,標(biāo)簽網(wǎng)絡(luò)的輸出用于構(gòu)建多級(jí)語(yǔ)義指導(dǎo)分類(lèi)器。圖像特征網(wǎng)絡(luò)與CNN-F結(jié)構(gòu)相同,只將最后一層神經(jīng)元個(gè)數(shù)改為c,并將激活函數(shù)設(shè)置為tanh函數(shù)。和大多數(shù)使用深度網(wǎng)絡(luò)框架實(shí)現(xiàn)跨模態(tài)檢索的方法相同,本文使用在ImageNet[20]數(shù)據(jù)集上進(jìn)行預(yù)訓(xùn)練的CNN-F前七層初始化圖像特征提取網(wǎng)絡(luò)。文本網(wǎng)絡(luò)由三層神經(jīng)網(wǎng)絡(luò)構(gòu)成:第一層為輸入層,第二層包含4 096個(gè)神經(jīng)元,最后一層神經(jīng)元個(gè)數(shù)與哈希碼位數(shù)相同。
將學(xué)習(xí)率r1、r2和r3設(shè)置為10-6~10-2,θ1、θ2、θ3參數(shù)隨機(jī)初始化。在文本檢索圖像和圖像檢索文本檢索任務(wù)中,將哈希碼長(zhǎng)度選取為16 bit、32 bit、64 bit不同位數(shù)時(shí),分別與其他對(duì)比算法的檢索結(jié)果進(jìn)行比較。
3.3 評(píng)價(jià)標(biāo)準(zhǔn)
跨模態(tài)哈希算法的檢索性能使用平均準(zhǔn)確率(mean Average Precision,mAP)、topK-precision曲線(xiàn)和查準(zhǔn)率查全率(Precision-Recall,PR)曲線(xiàn)評(píng)估。mAP和topK-precision曲線(xiàn)用于測(cè)量漢明排序準(zhǔn)確度,漢明排序是根據(jù)查詢(xún)數(shù)據(jù)和檢索集中數(shù)據(jù)的漢明距離進(jìn)行排序。mAP衡量所有查詢(xún)樣本的平均檢索精度,是平均準(zhǔn)確率(Average Precision,AP)的均值,可以被定義成如下:

其中:R表示輸入查詢(xún)數(shù)據(jù)后檢索到的樣本個(gè)數(shù),Q表示被檢索到的數(shù)據(jù)中與查詢(xún)數(shù)據(jù)相關(guān)的樣本總數(shù),M(r)表示被檢索到的數(shù)據(jù)中前r個(gè)結(jié)果的準(zhǔn)確率,δ(r)表示第r個(gè)數(shù)據(jù)是否與查詢(xún)數(shù)據(jù)相關(guān)。PR表示查準(zhǔn)率和查全曲線(xiàn)。topK-precision曲線(xiàn)用于測(cè)量返回的前K個(gè)數(shù)據(jù)準(zhǔn)確率。
3.4 實(shí)驗(yàn)結(jié)果分析
參數(shù)λ、γ、μ、η一般設(shè)置為1,不做進(jìn)一步對(duì)分析。本文將對(duì)其做敏感性分析,讓超參數(shù)分別從{0.001,0.01,0.1,1,2}中選取不同值進(jìn)行實(shí)驗(yàn),某一參數(shù)進(jìn)行實(shí)驗(yàn)時(shí),其他參數(shù)將固定其取值。圖2是在mirflickr-25k數(shù)據(jù)集上,哈希碼長(zhǎng)度被設(shè)為16 bit時(shí),超參數(shù)λ、γ、μ、η從{0.001,0.01,0.1,1,2}中選取不同值的mAP的曲線(xiàn)。
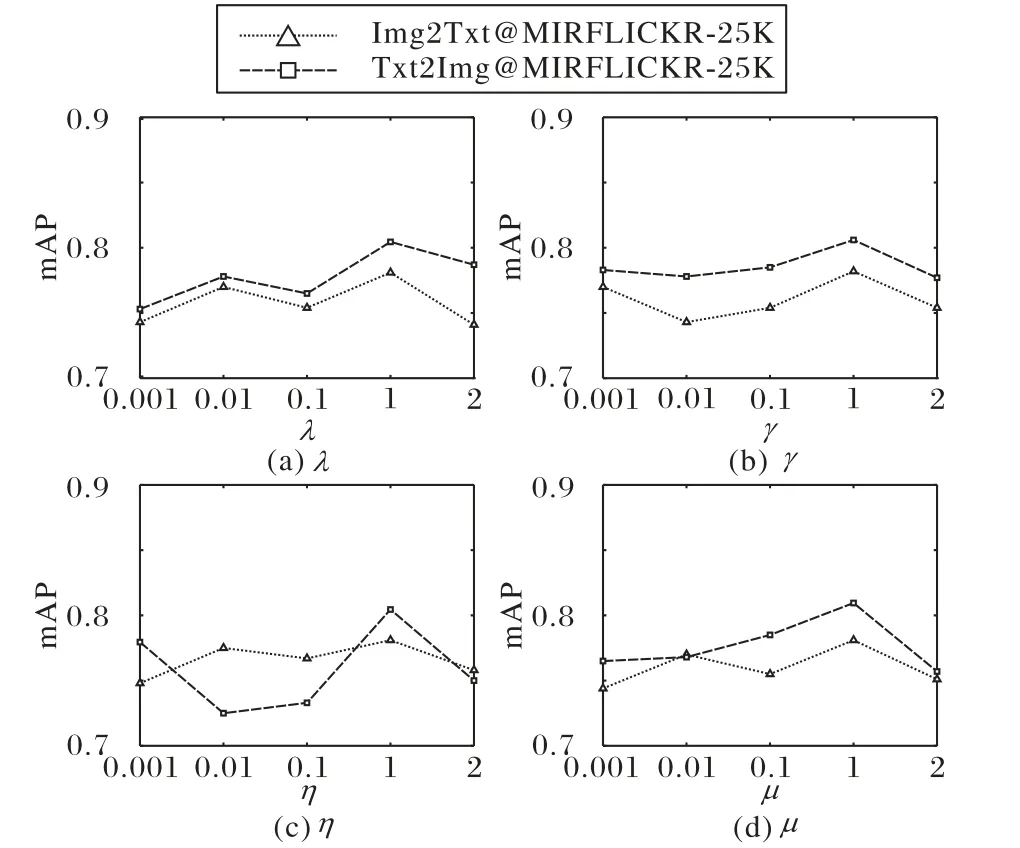
圖2 參數(shù)分析Fig.2 Parameter analysis
分析圖2,發(fā)現(xiàn)超參數(shù)取值在[0.01,2]區(qū)間時(shí),取得更好的效果,此時(shí)圖像和文本模態(tài)數(shù)據(jù)量化生成的哈希碼保留了更多的語(yǔ)義信息以及判別性。通過(guò)以上分析能夠發(fā)現(xiàn)參數(shù)在[0.01,2]內(nèi),mAP值結(jié)果不敏感,也就是此時(shí)已經(jīng)具有較好的性能,因而實(shí)驗(yàn)將超參數(shù)λ、γ、μ、η均設(shè)置為1,可以證明實(shí)驗(yàn)結(jié)果的正確性。
表2和表3展示了在mirflickr-25k和NUS-WIDE數(shù)據(jù)集上進(jìn)行兩個(gè)跨模態(tài)檢索任務(wù),當(dāng)哈希碼長(zhǎng)度選取不同位數(shù)時(shí),各種檢索算法的mAP值。在選取不同長(zhǎng)度的哈希碼時(shí),本文算法的mAP值都比其他對(duì)比算法的檢索結(jié)果有提升,說(shuō)明本文提出的算法確實(shí)提高了檢索性能。
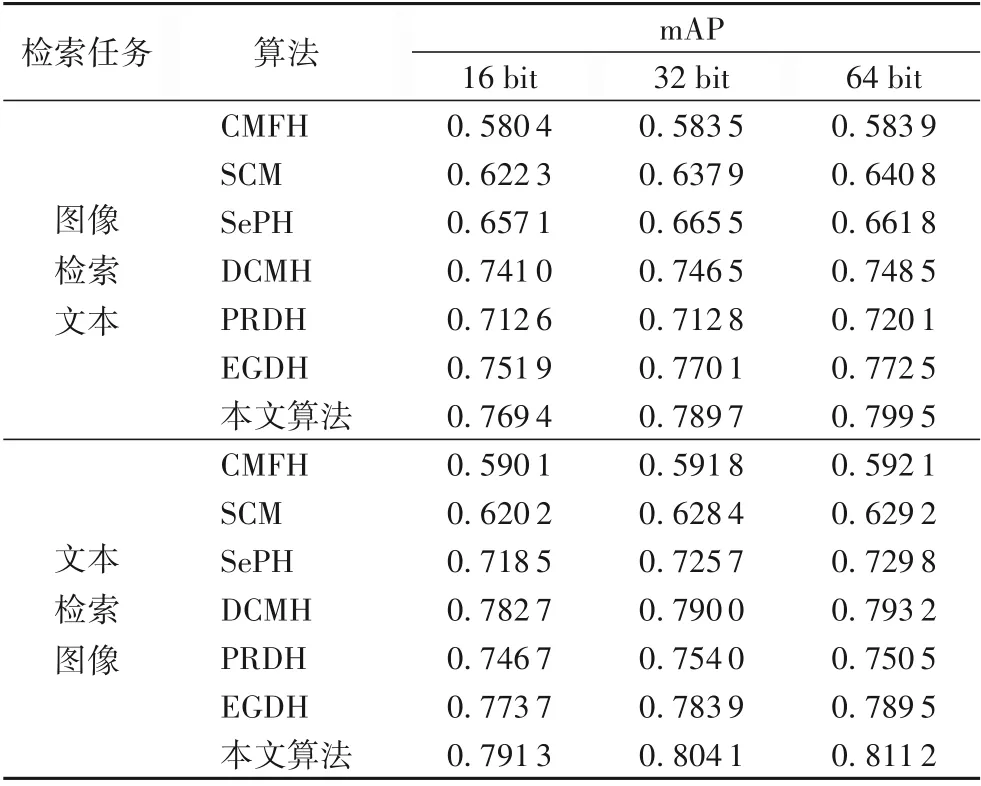
表2 在mirflickr-25k數(shù)據(jù)集上各算法的mAP值Tab.2 mAPof different algorithmson mirflickr-25k dataset
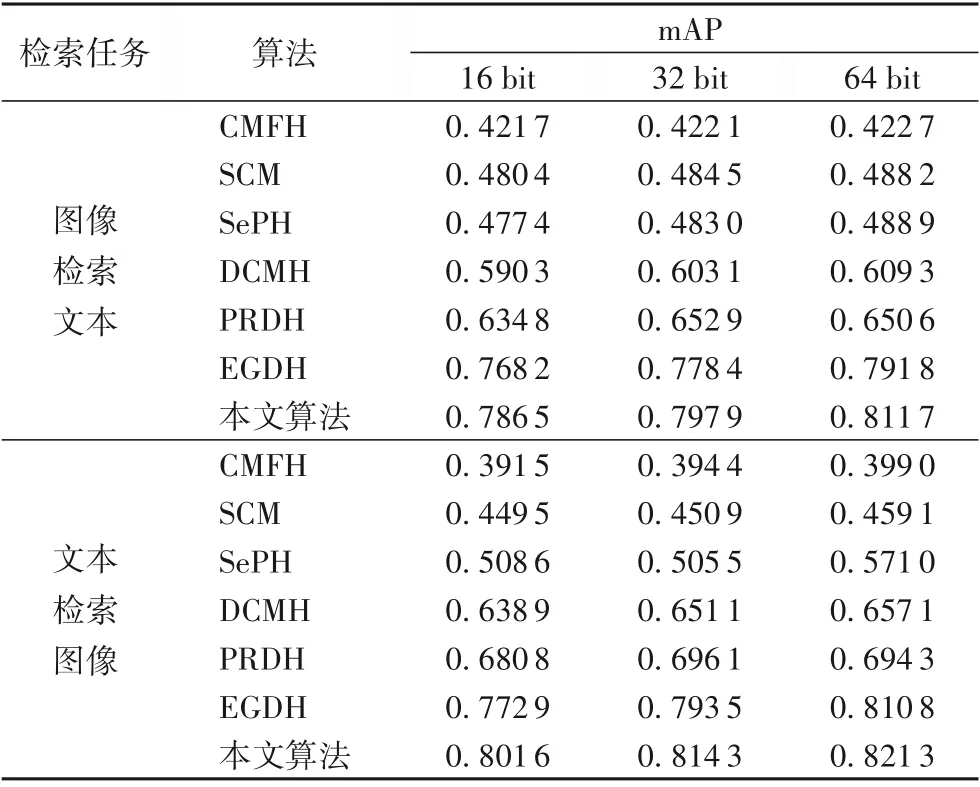
表3 在NUS-WIDE數(shù)據(jù)集上各算法的mAP值Tab.3 mAPof different algorithmson NUS-WIDE dataset
與基于淺層結(jié)構(gòu)的哈希算法(CMFH、SCM、SePH)相比,本文算法的mAP值明顯較高。這是因?yàn)樯顚咏Y(jié)構(gòu)在特征提取方面具有更好的性能。與PRDH比較,本文算法在兩數(shù)據(jù)集上的mAP值明顯增長(zhǎng)5%以上,因?yàn)楸疚臉?gòu)建的語(yǔ)義結(jié)構(gòu)和判別性分類(lèi)之間的聯(lián)系,對(duì)于聚合類(lèi)內(nèi)數(shù)據(jù)和保留完成的語(yǔ)義結(jié)構(gòu)起到了作用。與沒(méi)有使用判別信息的算法(CMFH、SCM、SePH、DCMH)相比較,本文算法的性能明顯提升,這是因?yàn)楸疚乃惴▽W(xué)習(xí)的哈希碼具有更好的語(yǔ)義判別性能,實(shí)驗(yàn)結(jié)果表明本文提出的算法具有更好的優(yōu)越性。與EGDH相比,本文算法在mirflickr-25k和NUS-WIDE數(shù)據(jù)集上mAP增長(zhǎng)幅度從1.05%到2.87%。在兩個(gè)數(shù)據(jù)上的進(jìn)行兩種檢索任務(wù)時(shí)實(shí)驗(yàn)結(jié)果表明:本文算法的平均準(zhǔn)確率的均值比DCMH、EGDH算法將高出2.73%、18.1%、1.15%和1.96%,與PRDH比平均分別高出了6.14%、13.7%。因?yàn)楸疚乃惴ㄊ褂昧硕嗉?jí)語(yǔ)義信息,而語(yǔ)義信息是提升跨模態(tài)檢索性能的關(guān)鍵,實(shí)驗(yàn)結(jié)果也證明了本文算法的有效性。
圖3給出了在哈希碼長(zhǎng)度設(shè)為32 bit時(shí),各對(duì)比算法在mirflickr-25k數(shù)據(jù)集上對(duì)于圖像檢索文本和文本檢索圖像任務(wù)的PR和topK-precision曲線(xiàn)。從最終的實(shí)驗(yàn)結(jié)果可以發(fā)現(xiàn),在任一個(gè)檢索任務(wù)中,本文提出算法的PR曲線(xiàn)(六角星曲線(xiàn)表示)都位于其他算法的右上方,說(shuō)明本文算法的查準(zhǔn)率、查全率均優(yōu)于其他對(duì)比算法。本文提出算法的topK-precision曲線(xiàn)位于其他算法的上方,說(shuō)明使用本文所提出算法進(jìn)行跨模態(tài)檢索的結(jié)果中,檢索結(jié)果的前K個(gè)數(shù)據(jù)與查詢(xún)數(shù)據(jù)相關(guān)的準(zhǔn)確率更高。
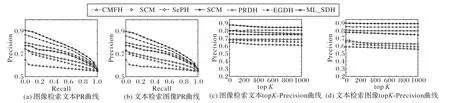
圖3 在mirflickr-25k數(shù)據(jù)集上哈希碼長(zhǎng)度為32時(shí)PR曲線(xiàn)和top K-precision曲線(xiàn)Fig.3 PR curvesand top K-precision curveswith hash code length of 32 bit on mirflickr-25k dataset
圖4展示了在哈希碼長(zhǎng)度設(shè)為32 bit時(shí),各對(duì)比算法在NUS-WIDE數(shù)據(jù)集上對(duì)于圖像檢索文本和文本檢索圖像任務(wù)的PR和topK-precision曲線(xiàn)。從實(shí)驗(yàn)結(jié)果可以總結(jié):本文算法比其他算法檢索的結(jié)果具有更高的檢索精度。本文算法的topK-precision和PR曲線(xiàn)均在最上方(六角星曲線(xiàn)表示),表明本文算法在漢明排序和進(jìn)行哈希查找時(shí)明顯優(yōu)于具有代表性的其他算法。這是因?yàn)樵诖笠?guī)模數(shù)據(jù)集上,本文算法仍可以在保持類(lèi)間多級(jí)語(yǔ)義關(guān)系同時(shí)又能聚合類(lèi)內(nèi)數(shù)據(jù),減小了哈希碼的種類(lèi)數(shù),提高跨模態(tài)檢索的性能。
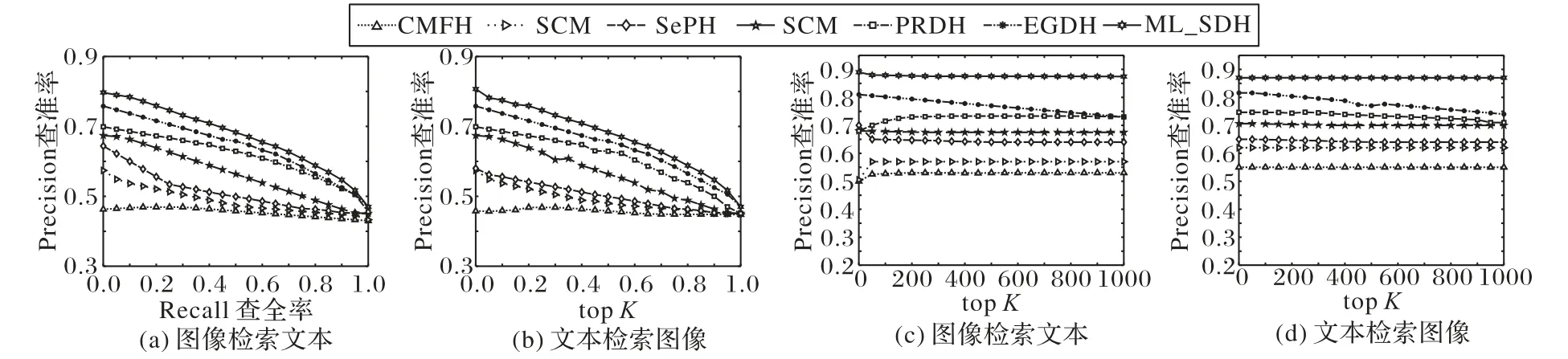
圖4 在NUS-WIDE數(shù)據(jù)集上哈希碼長(zhǎng)度為32時(shí)的PR曲線(xiàn)和top K-precision曲線(xiàn)Fig.4 PR curvesand top K-precision curveswith hash code length of 32 bit on NUS-WIDE dataset
4 結(jié)語(yǔ)
本文提出了基于多級(jí)語(yǔ)義的判別式跨模態(tài)哈希檢索算法,該算法考慮到跨模態(tài)多標(biāo)簽數(shù)據(jù)中的多級(jí)語(yǔ)義信息對(duì)于檢索結(jié)果的重要性,使用了多級(jí)語(yǔ)義相似度矩陣學(xué)習(xí)語(yǔ)義指導(dǎo)向量,構(gòu)建多級(jí)語(yǔ)義指導(dǎo)分類(lèi)器。該分類(lèi)器指導(dǎo)不同模態(tài)數(shù)據(jù)學(xué)習(xí)各自的哈希函數(shù),使得最終學(xué)習(xí)的哈希碼既保持了判別性也保持了類(lèi)內(nèi)和類(lèi)間關(guān)系,實(shí)現(xiàn)了分類(lèi)和多級(jí)語(yǔ)義哈希檢索的結(jié)合。本文在mirflickr-25k和NUS-WIDE兩個(gè)基準(zhǔn)數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),與幾種前沿的跨模態(tài)檢索算法比較,實(shí)驗(yàn)結(jié)果表明本文算法在mAP值等檢索精度上有明顯提升。
猜你喜歡
開(kāi)放教育研究(2020年2期)2020-03-31 01:54:14
中華手工(2017年2期)2017-06-06 23:00:31
現(xiàn)代語(yǔ)文(2016年21期)2016-05-25 13:13:44
湖北經(jīng)濟(jì)學(xué)院學(xué)報(bào)·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機(jī)學(xué)院學(xué)報(bào)(2015年4期)2015-02-28 14:30:00
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
中外會(huì)展(2014年4期)2014-11-27 07:46:46
計(jì)算物理(2014年2期)2014-03-11 17:01:39
外語(yǔ)學(xué)刊(2011年1期)2011-01-22 03:38:33
外語(yǔ)學(xué)刊(2010年2期)2010-01-22 03:31:03
