GRACE/GRACE-FO空窗期的陸地水儲量變化數據間斷補償:以全球典型流域為例
2021-09-06 12:09:46徐鵬飛蔣濤章傳銀芮明勝劉宇
地球物理學報 2021年9期
徐鵬飛, 蔣濤, 章傳銀, 芮明勝, 劉宇
1 中國測繪科學研究院, 北京 100830 2 山東科技大學測繪與空間信息學院, 山東青島 266590
0 引言
陸地水是不可或缺的重要自然資源,與人類活動密切相關,由于水資源的分布不均,制約著國家和地區的高速發展,嚴重影響我國可持續發展戰略(Zhong et al.,2009).因此,陸地水儲量異常TWSA(Terrestrial Water Storage Anomaly)的長期可持續監測,對于研究水循環過程,合理配置水資源,預防洪澇、干旱等自然災害等有相當重要的科學意義和參考價值(Chen et al.,2009).
2002年初,GRACE(Gravity Recovery and Climate Experiment)衛星開始運行,基于GRACE獲取空間中長尺度的時變重力場信息,可反演TWSA,使TWSA的長期可持續監測成為可能,國內外學者基于GRACE數據對區域TWSA進行了大量研究(Tapley et al.,2004;Yeh et al.,2006;Tiwari et al.,2009;Chen et al.,2014;Long et al.,2016).直至2017年10月,GRACE任務結束,CSR(Center for Space Research)、GFZ(Helmholtz-Centre Potsdam-German Research Centre for Geosciences)、JPL(Jet Propulsion Laboratory)三所機構最新發布的GRACE Level-2 RL06(Release 06)數據更新至2017年6月,但由于衛星后期運行存在的質量問題,一般2016年8月之后的數據不再使用.2018年5月,為延續GRACE任務,GRACE-FO(GRACE Follow-On)成功發射升空,該衛星將繼續監測全球重力場的變化.近期CSR、GFZ、JPL公布了最新的GRACE-FO Level-2 RL06球諧系數數據,下文簡稱GRACE-FO SH,截至2021年1月10日,數據的時間段為2018年6月至2020年11月,由此GRACE與GRACE-FO之間存在了20多個月的數據空窗期.為得到長期連續的TWSA監測結果,更準確的研究TWSA的年際變化與長期趨勢特征,從而合理利用配置水資源,一種有效的針對GRACE/GRACE-FO數據空窗期的TWSA間斷補償方法是十分必要的.
數據間斷的補償可通過時間序列分析或機器學習等方法預測實現,國內外學者針對水儲量變化的預測開展了大量研究工作.Mirzavand和Ghazavi(2015)利用ARMA(Autoregressive Moving Average)、ARIMA(Autoregressive Integrated Moving Average)、SARIMA(Seasonal Autoregressive Integrated Moving Average)對伊朗喀山平原的地下水位進行預測試驗,研究表明可提前60個月對地下水位取得較好的預測效果.Adamowski和Chan(2011)利用小波神經網絡WNN(Wavelet Neural Network)預測加拿大魁北克的地下水位,并與ARIMA方法比較,驗證了該方法的有效性及潛力.Dos Santos和Pereira Filho(2014)利用ANN(Artificial Neural Network),并引入天氣變量,預測圣保羅地區的用水需求,發現天氣對用水消耗存在反饋作用.另外還有WA-ANN(Wavelet Analysis-Artificial Neural Network)、SVR(Support Vector Regression)等其他方法(Adeli and Jiang,2006;Moosavi et al.,2013;王宇譜等,2013;Tiwari and Adamowski,2015;Al-Zahrani and Abo-Monasar,2015;Mukherjee and Ramachandran,2018).傳統的時間序列分析方法實現簡單,基于最小二乘原理構造隨時間變化的函數,向后遞推,從而預測后續序列.然而該方法對于信號成分復雜的時間序列的預測效果較差,且易受到信號中噪聲成分的影響,從而預測失真.相較而言,ANN、WA-ANN、SVR算法的精度較高,但需額外的物理變量進行約束(如氣象數據等),實現困難,計算效率較低.綜上所述,本文將引入奇異譜分析SSA(Singular Spectrum Analysis)+ARMA組合方法(Shen et al.,2018;牛余朋等,2020),預測GRACE/GRACE-FO空窗期的TWSA,從而對TWSA的間斷進行補償.GRACE運行多年,積累了較為充足的樣本,且近期GRACE-FO數據的發布,為間斷補償的精度評定提供了可靠依據.
SSA作為一種時間序列信號的處理方法,在GNSS(Global Navigation Satellite System)數據處理等領域應用較多(王解先等,2013;Kondrashov and Berloff,2015;肖勝紅等,2016),但在水儲量變化的預測方面應用較少,從有限時間序列的動態重構出發,結合特征向量分析(Eigenvector Analysis),SSA方法可充分識別并提取信號中不同成分(如周期、趨勢、噪聲等),且無需引入額外的物理變量,實現較為簡易,特別適合分析預測具有周期特征的TWSA時間序列.Li等(2019)利用SSA方法預測了中國多個地區的水儲量變化,取得了較好的效果,但關于如何選擇訓練樣本、檢驗樣本提高預測模型精度的討論尚不充分.因此,本文將選取TWSA周期特征明顯的全球典型流域為例,驗證SSA方法在典型流域的適用性及間斷補償效果,并進一步討論如何選擇訓練樣本、檢驗樣本構建更適用于間斷補償的預測模型,從而提高GRACE/GRACE-FO數據空窗期TWSA間斷補償結果的精度.此外,雖然SSA方法可以有效對TWSA序列的周期項等主要成分進行分解與重構,但剩余隨機序列中依然存在部分有效信息,而剩余隨機序列可以利用ARMA模型進行擬合遞推.為此,本文引入了SSA+ARMA組合方法進一步提高間斷補償結果的精度.從全球選取亞馬遜流域、多瑙河流域、恒河流域、密西西比河流域、尼日爾河流域、伏爾加河流域、葉尼塞河流域、長江流域這八個典型流域進行試驗,并分別利用SSA+ARMA、SSA、ARMA和WNN算法進行對比分析,驗證SSA+ARMA方法的適用性和有效性.后續采用GRACE-FO SH反演TWSA、Mascons、GLDAS(Global Land Data Assimilation System)數據,評定基于SSA+ARMA方法的TWSA間斷補償結果精度,驗證方法的可靠性.
1 數據
1.1 GRACE/GRACE-FO level-2 RL06
本文使用CSR的GRACE/GRACE-FO RL06 大地水準面球諧模型GSM(Geoid Spherical Harmonic Model)球諧系數文件,階數為60階,下文簡稱GRACE SH.選取GRACE SH的時間段為:2003年1月—2016年8月,共計149個月數據(部分月數據缺失).截至2021年1月10日,新發布的GRACE-FO SH時間段為:2018年6月—2020年11月,共計28個月數據(2018年8月、2018年9月數據缺失).與RL05數據一樣,這些數據扣除了固體潮汐、海洋潮汐、非潮汐的大氣和海洋信號(Bettadpur,2003).與RL05相比,RL06數據在參數選擇、算法設計、數據編輯、背景場模型構建等方面進行了優化,“條帶”誤差與截斷誤差有明顯的改善(Save,2018;G?ttl et al.,2018).數據預處理階段分別用SLR(Satellite Laser Ranging)提供的C20項和來自Swenson的一階項,替換GSM中的C20項、一階項(Swenson and Wahr,2002;Cheng and Tapley,2004).此外,冰川均衡調整(GIA)引起的重力場長期變化趨勢利用了三維壓縮地表負荷滯彈響應模型進行扣除(Geruo et al.,2013).
1.2 Mascons結果
為驗證GRACE SH反演TWSA的可靠性及對間斷補償結果進行精度評定,本文選取JPL、CSR、GFZ的Mascons RL05以及JPL、CSR的Mascons RL06數據進行比較.Mascons RL05數據的分辨率為1°×1°,每月一值,數據時間段為2003年1月至2017年1月.JPL發布的Mascons RL06數據的分辨率為0.5°×0.5°,每月一值.CSR發布的Mascons RL06數據的分辨率為0.25°×0.25°,每月一值.截至2021年1月10日,基于GRACE-FO數據的Mascons RL06結果已經更新至2020年10月.經過泄漏誤差的修復、GIA改正等一系列處理后,具有更好的精度,因此廣泛應用于GRACE SH反演TWSA結果精度的驗證分析(Scanlon et al.,2016).其中Mascons RL05采用的GIA改正模型為三維壓縮地表負荷滯彈響應模型,與本文對GRACE SH的處理一致.而Mascons RL06采用的ICE6G-D模型(Purcell et al.,2016).二者模型存在差異,但差異主要體現在南極地區,在本文所選的研究流域中差異較小(馬超等,2016).
1.3 GLDAS水文模型
本文選用GLDAS V2.1的NOAH模型,時間段為2003年1月—2020年2月,其分辨率為0.25°×0.25°.該模型考慮了0~200 cm的土壤水、植物冠層地表水、雪水當量,不包含地下水部分.本文將利用GLDAS數據求解單尺度因子,一定程度上修復球諧系數濾波引起的泄漏誤差,以及驗證補償結果的可靠性.
2 原理及方法
2.1 GRACE SH反演TWSA方法
GRACE SH可反演流域內等效水高EWH(Equivalent Water Height)變化,然而GRACE重力場模型中存在高階噪聲及“條帶”誤差,因此本文引入了半徑300 km的FAN濾波和P3M15的去相關濾波的組合濾波方法,從而反演得到八個典型流域的TWSA,具體公式如下(Wahr et al.,1998; Han et al.,2005;Zhang et al.,2009;詹金剛等,2011):
×[ΔCn mcos(mλ)+ΔSn msin(mλ)]
(1)
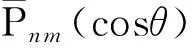
2.2 SSA原理
SSA本質是針對一維時間序列的主成分分析方法,對于X=(x1,x2,…,xN),SSA方法時間序列分析過程主要分為分解與重構兩個方面,具體過程如下(Vautard et al.,1992;Chen et al.,2013):
(1)軌跡矩陣
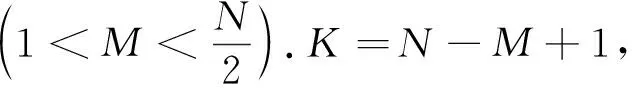
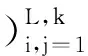
(2)
式中Xi=(xi,…,xi+M-1)T(1≤i≤K).X為M×K階軌跡矩陣.
(2)奇異值分解
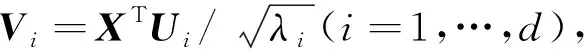
X=X1+X2+…+Xd,
(3)
(3)分組
將d個初等矩陣分成m個互不相交的子集I1,I2,…,Im,設I={i1,i2,…,ip},則對應于子集I的合成矩陣可表示為:
XI=Xi1+Xi2+…+Xip,
(4)
將矩陣X以合成矩陣形式表示為:
X=XI1+XI2+…+XIm,
(5)
因此,分組的過程即是對I1,I2,…,Im的確定過程.
(4)時間序列重構
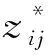
(6)
重構成分能夠反映時間序列的變化特征,各重構成分功率譜密度的相對關系可用于有效信號提取與信噪分離.
2.3 SSA迭代預測方法與SSA+ARMA方法
本文采用的SSA迭代預測算法由SSA迭代插值法發展而來,二者的原理是一樣的(Schoellhamer,2001;Beckers and Rixen,2003;Kondrashov et al.,2010;郭金運等,2018).將GRACE SH反演的TWSA時間序列作為訓練樣本,通過SSA分解對時間序列進行重構.迭代預測的具體步驟如下:
(1)設定預測時長n,將n個0值加到訓練樣本(長度為N)的末尾處,構建總長度為N+n的新序列.
(2)對長度為N+n的新序列進行SSA分解,將第一個重構成分(RC1)末尾處的n個值替換新序列,作為預測數據.之后循環該過程,最終前后兩次SSA分解的RC1之間的殘差小于閾值,根據經驗閾值取0.01 mm(Shen et al.,2018;周茂盛等,2018).
(3)當步驟(2)循環過程結束時,繼續通過SSA分解添加RC2,通過線性疊加RC1和RC2末尾處的n個預測值構建新序列,循環該過程直至前后兩次分解的RC1+RC2之間的差值小于閾值.
(4)重復上述過程,直至用K個RC線性疊加(RC1+RC2+…+RCk)末尾處的n個預測值,且滿足閾值條件,則序列末尾n個值即為TWSA的預測值.
以預測時序與檢驗樣本符合精度最高為準則,結合W-correlation(Weighted Correlation)及FFT(Fast Fourier Transform)方法進行有效性和適用性檢驗(見3.2節),測試最佳窗口長度M和重構階數K,并以此窗口長度M與重構階數K,可以得到基于SSA方法TWSA預測結果.同時RC1+RC2+…+RCk的前N個值為與訓練樣本對應的SSA重構序列,將訓練樣本扣除SSA重構序列后得到剩余隨機序列,建立ARMA(p,q)對剩余序列進行外推預測,SSA預測結果與ARMA外推結果之和為SSA+ARMA的間斷補償結果,此為SSA+ARMA方法(Shen et al.,2018;牛余朋等,2020).
2.4 精度評定指標
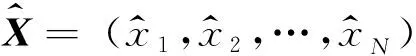
RMSE(Root Mean Square Error):
(7)
RMSE數值越小,表示模擬值序列與觀測值序列的誤差越小,精度越高.
相關系數R(Correlation Coefficient):
(8)
R取值在[-1,1]之間,數值越大,表明兩個序列的周期相位相關性越高.
納什效率系數NSE(Nash-Sutcliffe Efficiency Coefficient):
(9)
NSE取值在(-∞,1]之間,越接近1,表示預測模型可信度高.與R相比,NSE更能反映振幅相關性,因此被廣泛應用于水文模型模擬結果的驗證(Merz and Bl?schl,2004).
3 結果分析
3.1 GRACE SH反演TWSA與Mascons比較
為方便表述,本文以相關代號表示各流域——亞馬遜流域(AZRB)、多瑙河流域(DNRB)、恒河流域(GNRB)、密西西比河流域(MSRB)、尼日爾河流域(NGRB)、伏爾加河流域(VGRB)、葉尼塞河流域(YNSRB)、長江流域(YZRB).八個流域邊界范圍如圖1所示,數據來自HydroSHEDS數據集(https:∥hydrosheds.org/page/overview).
首先利用CSR提供的2003年1月—2016年8月的GRACE RL06 SH反演各流域的TWSA序列.其中有15個月的球諧系數數據缺失,需對其進行插值補全.傳統方法為利用前后兩年或多年該月份球諧系數的均值代替,而本文將采用SSA迭代插值方法對TWSA結果進行插值補全(Shen et al.,2018;周茂盛等,2018).以MSRB為例,結果如圖2所示,圖中為傳統的前后兩年球諧系數均值替代法與SSA迭代插值方法的對比,可以看出SSA方法的插值結果更符合周期變化的特征,這有利于后續SSA方法的周期分解與重構.而傳統方法有明顯的跳變,引入了較大的誤差,特別2012年10月二者結果的差值達6.53 cm.為此,本文將采用SSA迭代插值方法對GRACE SH反演TWSA和Mascons結果的缺失數據補全.
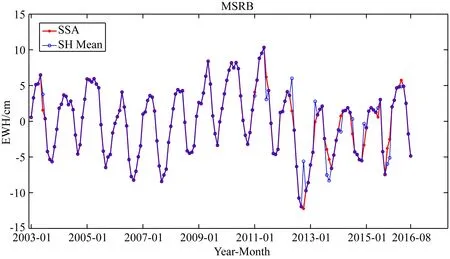
圖2 基于SSA方法與SH平均方法的TWSA插值結果Fig.2 The interpolation results of TWSA using SSA and SH Mean
前文已知,本文采用組合濾波方法來抑制噪聲和“條帶”誤差,但也造成了信號幅值的減小,空間分布衰減,即泄漏誤差.為了恢復相對真實的TWSA,本文采用基于GLDAS數據的單尺度因子法,修復泄漏誤差,該方法將GLDAS格網數據球諧展開并截取至60階,采用與GRACE相同的處理流程得到區域TWSA序列,基于最小二乘原理求解TWSA時間序列與該區域原始GLDAS時間序列的比例系數(馮偉等,2012).由表1可知,不同流域的尺度因子存在差異,將研究流域GRACE SH反演的TWSA序列乘以對應的尺度因子,作為最終的反演結果.為驗證GRACE SH反演TWSA結果的準確性和可靠性,本文將八個典型流域的TWSA分別與三所機構的Mascons RL05和JPL、CSR的Mascons RL06結果進行比較.

表1 不同研究區域的單尺度因子Table 1 Single scale factor in different study areas
如圖3所示,GRACE SH反演的TWSA結果與Mascons結果相比,無論是振幅還是周期相位均有較強的一致性,這表明二者結果吻合性良好,驗證了本文GRACE SH反演TWSA結果的有效性和可靠性,且三所機構不同版本間的Mascons結果差異也不明顯.八個流域TWSA序列均有一定的周期信號特征,其中AZRB、NGRB(圖3a,e)的TWSA序列周期特征最為明顯,規律性更強,而DNRB、MSRB、YZRB(圖3b,d,h)的信號成分復雜、周期特征相對較弱,序列中蘊含了更多的頻率信息.
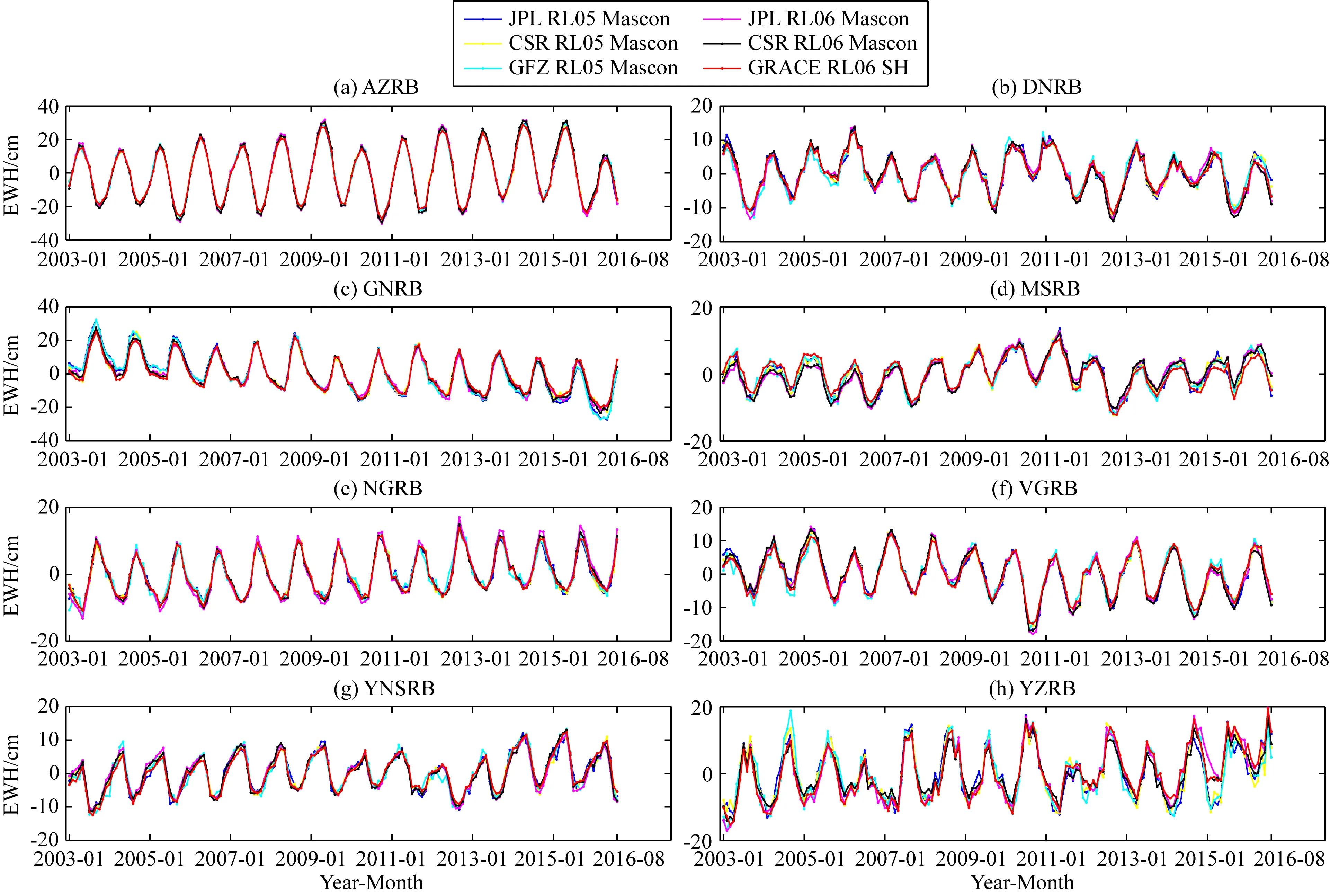
圖3 GRACE SH反演研究區域的TWSA與Mascons結果比較Fig.3 Comparison of TWSA derived from GRACE SH with Mascons in study areas
本文通過計算八個流域的RMSE(cm)、NSE、R,定量評價GRACE SH反演TWSA結果與Mascons結果的符合精度.表2可知,GRACE SH反演TWSA結果與Mascons結果有較高的符合精度,大多數流域的RMSE在2 cm以內,且NSE、R在0.95以上.其中在AZRB、NGRB的符合精度最高,NSE、R都達到了0.99,RMSE也在1.5 cm之內.由NSE可知,在MSRB中,GRACE SH反演的TWSA與Mascons結果有較明顯的差異,特別是RL06的Mascons結果.綜合考慮,CSR的Mascons RL05、Mascons RL06結果與GRACE SH反演結果吻合程度最高,這與本文選取CSR的GRACE SH數據反演TWSA有關.由于Mascons RL05數據的時間范圍所限,后續將采用CSR的Mascons RL06數據與TWSA間斷補償結果對比驗證.
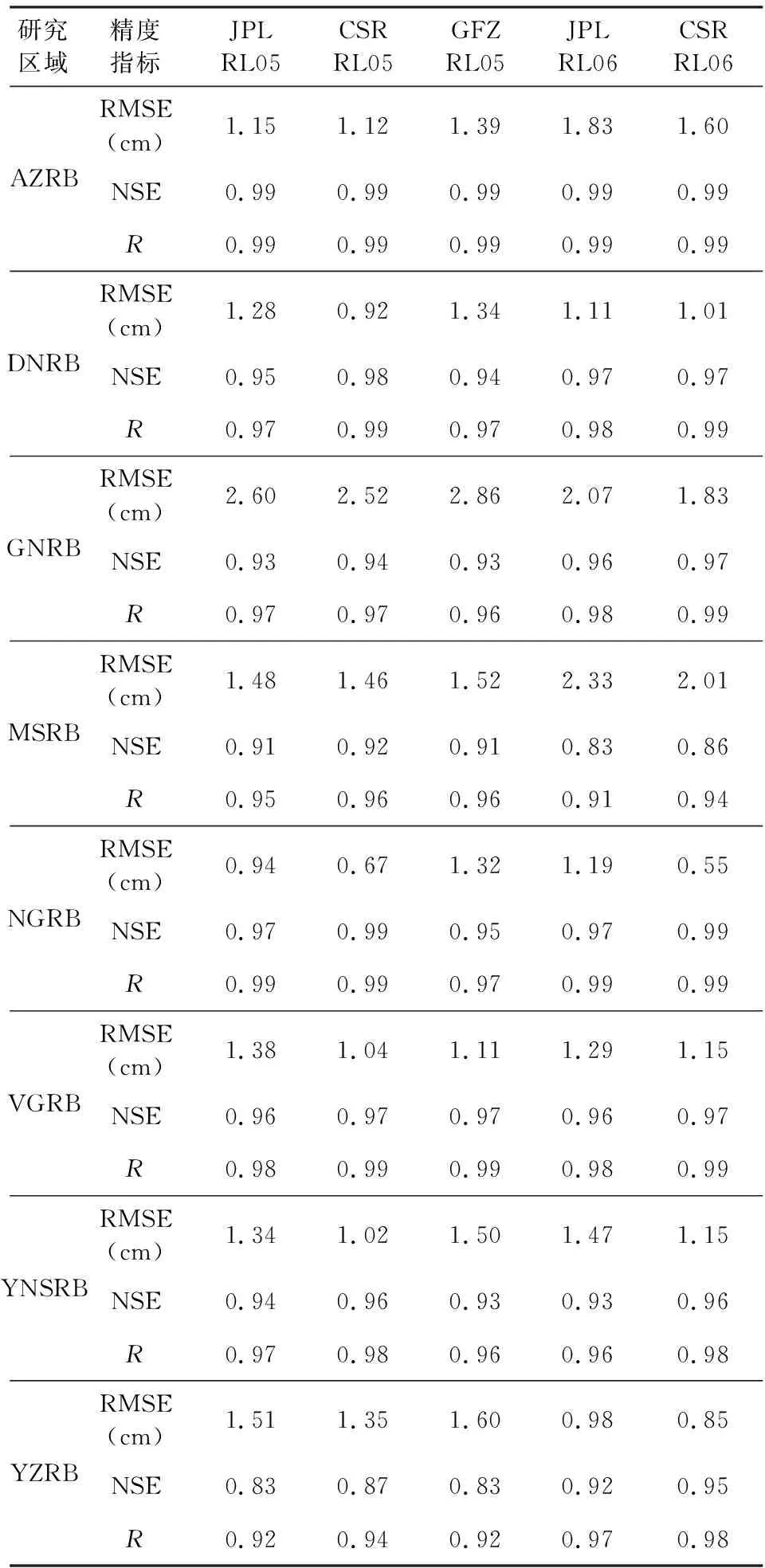
表2 GRACE SH反演研究區域的TWSA的精度評定Table 2 Accuracy assessment of regional TWSA derived from GRACE SH
3.2 SSA方法可行性分析
前文已知,在利用SSA方法預測前,需確定最佳窗口長度M和重構階數K,本文以周期特征明顯的AZRB的TWSA為例,詳細說明該過程.為此將2003年1月至2012年12月的GRACE SH反演TWSA結果作為訓練樣本,共計120個數據.根據經驗,GRACE SH反演的TWSA結果中可能存在3個月周期信號,因此在SSA分解時,將窗口長度M設置為3的倍數,連續測試窗口長度M,從而對分解的重構成分進行周期對分離.以預測時序與檢驗樣本(2013年1月至2016年8月數據)符合精度最高為準則,不斷測試,確定AZRB區域的最佳窗口長度M為48,重構階數K為8.為定量描述各重構成分之間的相關性,檢驗模型的有效性和適用性,本文采用W-correlation進行分析,結果如圖4所示,圖4a可知,前8階的兩兩相鄰的重構成分相關系數均高于0.71,故前8階重構成分中,相鄰的兩個階項可能為周期對(如RC1與RC2、RC3與RC4、RC5與RC6等均具有相同的周期).圖4b中,前8階特征值的貢獻率達98.29%.
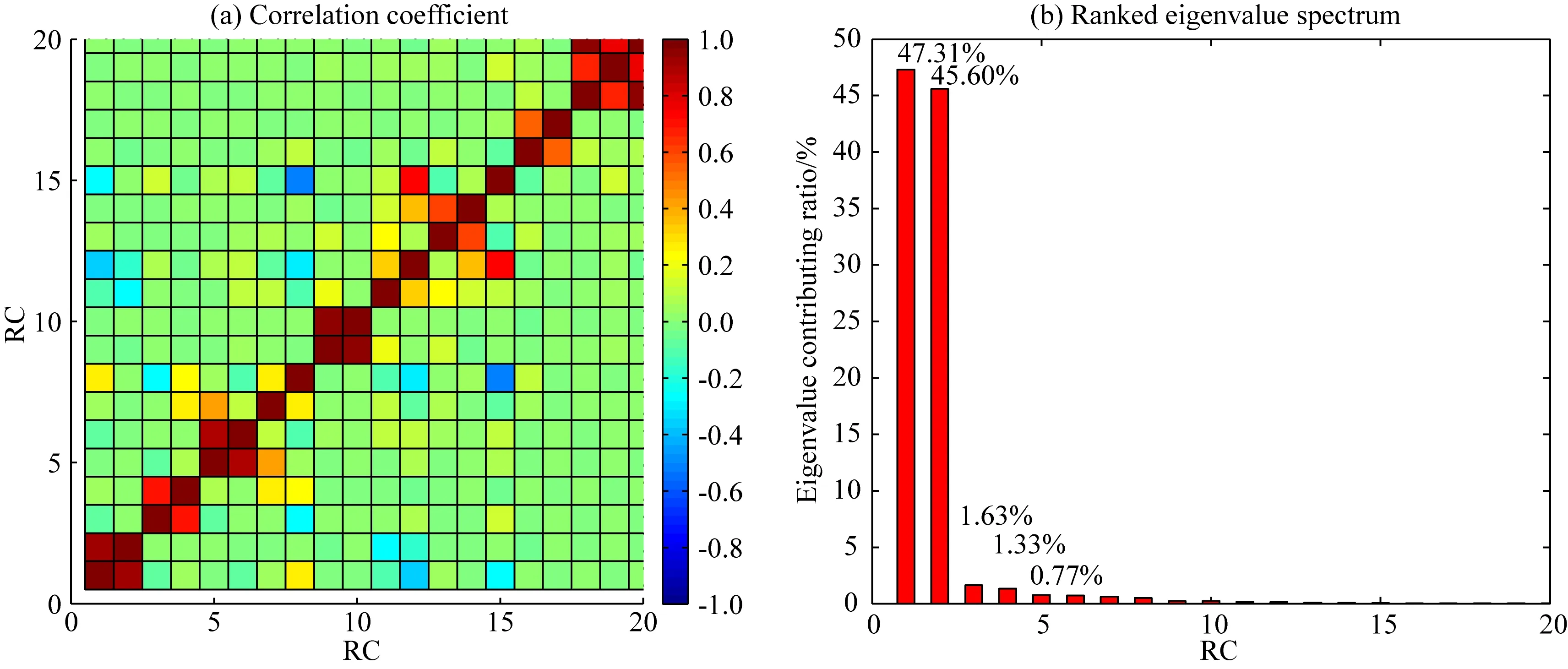
圖4 TWSA時序SSA分解RCs的 W-correlation分析結果Fig.4 W-correlation analysis of the RCs of TWSA with SSA
本文采用FFT方法探測各重構成分的周期特征,將具有相同周期信號特征的重構成分進行分組(Kay and Marple,1981).圖5左側為相鄰兩個RC之和的重構序列,右側為該序列的功率譜密度.由圖可知,RC1+RC2為具有年周期特征的信號,且其功率譜密度最大,對TWSA序列的貢獻率最高,其振幅為:-21.92至22.35 cm;RC3+RC4為具有36個月周期特征的信號;RC5+RC6為具有18個月周期特征信號;RC7+RC8為具有6個月周期特征信號.因此本文選取前8階重構成分對AZRB區域2003年1月至2012年12月的TWSA序列進行重構是適用的.
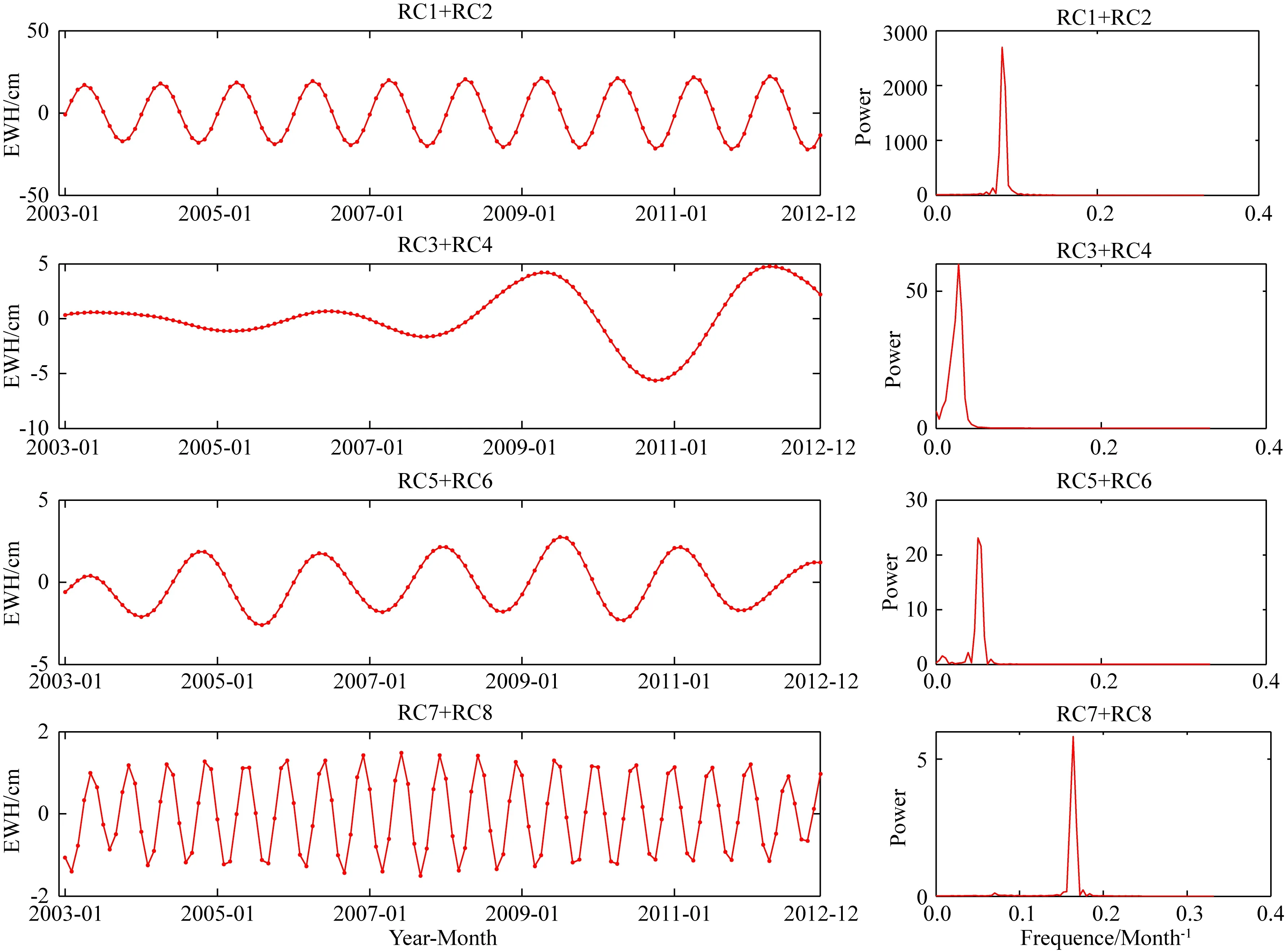
圖5 TWSA時序SSA分解RCs的FFT周期探測結果Fig.5 FFT period detection results of the RCs of TWSA with SSA
如圖6所示,將訓練樣本TWSA序列與SSA重構序列進行對比,兩種結果吻合很好,特別是在周期相位上有很強的一致性,殘差振幅也在2 cm左右,其符合精度分別為RMSE=1.71 cm、NSE=0.99、R=0.99.表明窗口長度M為48、重構階數K為8的重構模型在AZRB是有效的,利用該重構模型繼續生成新的序列,即SSA的預測值,驗證了SSA迭代預測方法的可行性.同時,圖6中殘差序列即為SSA+ARMA方法中的剩余隨機序列,利用ARMA模型對其進行外推,并與SSA方法的預測值相加,即為SSA+ARMA的間斷補償結果.不同流域的SSA預測模型窗口長度M和重構階數K存在差異,根據以上過程最終確定各流域的SSA預測模型參數詳見表4的預測模型A.
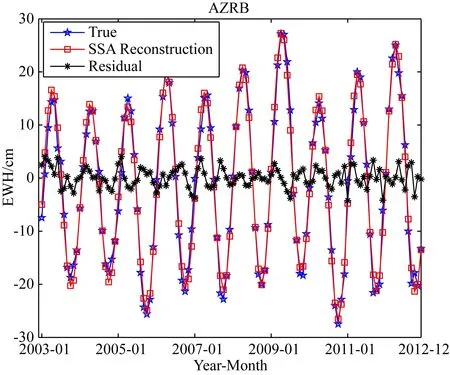
圖6 AZRB區域TWSA序列與其SSA重構序列 結果對比Fig.6 Comparison of SSA reconstruction results with TWSA in AZRB
3.3 ARMA預測模型有效性檢驗
同樣以AZRB流域2003年1月至2012年12月的TWSA序列為樣本,描述預測模型ARMA(p,q)的構建過程.首先對TWSA時間序列進行零均值處理,因為ARMA方法主要針對的是平穩時間序列,所以本文采用了ADF(Augmented Dickey-Fuller)檢驗對TWSA時間序列的平穩性進行檢測,若序列不滿足平穩性要求則需要進行差分處理,直至序列平穩(Luo et al.,2012;Mirzavand and Ghazavi,2015;牛余朋等,2020).利用AIC(Akaike Information Criterion)準則確定p、q,之后基于最小二乘原理求解模型的未知參數.構建模型后,還需有效性檢驗,有效性檢驗標準為擬合樣本序列提取后的殘差序列應與白噪聲相似.本文在AZRB流域所構建ARMA(6,8)模型的有效性檢驗結果如圖7所示.圖7a為反映擬合序列與樣本序列偏差的殘差序列,振幅在-5.06 cm至7.02 cm之間.圖7b為殘差序列的正態QQ(Quantile-Quantile)圖,殘差的數值均分布在紅線附近,且該殘差序列滿足顯著性水平為0.05的Lilliefors假設檢驗,因而具有近似正態分布的特征.圖7c、圖7d中橫軸表示滯后階數,縱軸表示相關系數大小,當滯后階數大于1時,殘差序列的自相關函數、偏自相關函數數值很小,均在隨機區間之內,且不隨滯后階數增大而下降,具有獨立無關的隨機特性.綜上,殘差序列為服從近似正態分布的獨立無關隨機變量,滿足白噪聲特性,所以AZRB流域構建的ARMA(6,8)是有效的,可以用于預測.
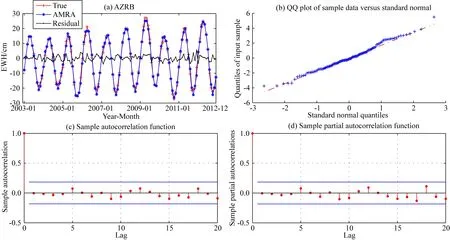
圖7 AZRB區域ARMA(6,8)模型檢驗結果Fig.7 Test results of the ARMA(6,8) model in AZRB
不同流域的ARMA(p,q)模型存在差別,本文對不同流域的參數p、q進行測試,并進行有效性檢驗,最終確定了八個流域的ARMA模型:AZRB采用ARMA(6,8),DNRB采用ARMA(7,6),GNRB采用ARMA(6,7),MSRB采用ARMA(8,8),NGRB采用ARMA(9,8),VGRB采用ARMA(8,8),YNSRB采用ARMA(10,10),YZRB采用ARMA(9,10).在SSA+ARMA方法中,各流域剩余隨機序列的信號成分已發生變化,ARMA模型需要重新確定.
3.4 不同方法的TWSA預測結果比較
為比較SSA方法在典型流域的適用性,將前期120個月(2003年1月至2012年12月)的GRACE SH反演TWSA結果作為訓練樣本,分別用SSA+ARMA、SSA、ARMA與WNN方法預測后續44個月(2013年1月至2016年8月)的TWSA(Chen et al.,2006).并以同期的GRACE SH反演TWSA作為真值檢驗,評估不同方法的預測效果,從而選擇適用于預測TWSA的方法.
如表3所示,四種方法TWSA預測序列均與真值序列有一定程度的吻合,但不同方法、不同流域之間還存在差異.SSA與SSA+ARMA方法的預測值與真值的吻合效果最好,且二者相差不大,ARMA方法效果最差.八個流域中,NGRB的TWSA預測結果精度是最高的,而DNRB、MSRB、YZRB預測結果精度相對較差.NGRB的TWSA時間序列的周期特征明顯,規律性強,因而四種方法的預測結果均與真值時間序列吻合得較好.相反,DNRB、MSRB、YZRB地區的TWSA序列更加復雜多變,蘊含更多的信息,因而預測結果與真值序列符合相對較差.綜合考慮三種精度指標,SSA與SSA+ARMA方法的預測精度較高且相對穩定,除AZRB外,其他多數流域的RMSE在4 cm以內,所有流域的NSE值在0.7以上,R值在0.85以上.WNN方法預測結果也有較高的精度,在DNRB、VGRB流域的預測精度還略優于SSA和SSA+ARMA方法,但在MSRB、YNSRB、YZRB預測精度較低,構建的預測模型適用性較差.相較而言,除在NGRB外,ARMA模型的預測精度最差,特別是在YZRB中,ARMA模型預測結果的NSE只有0.46.
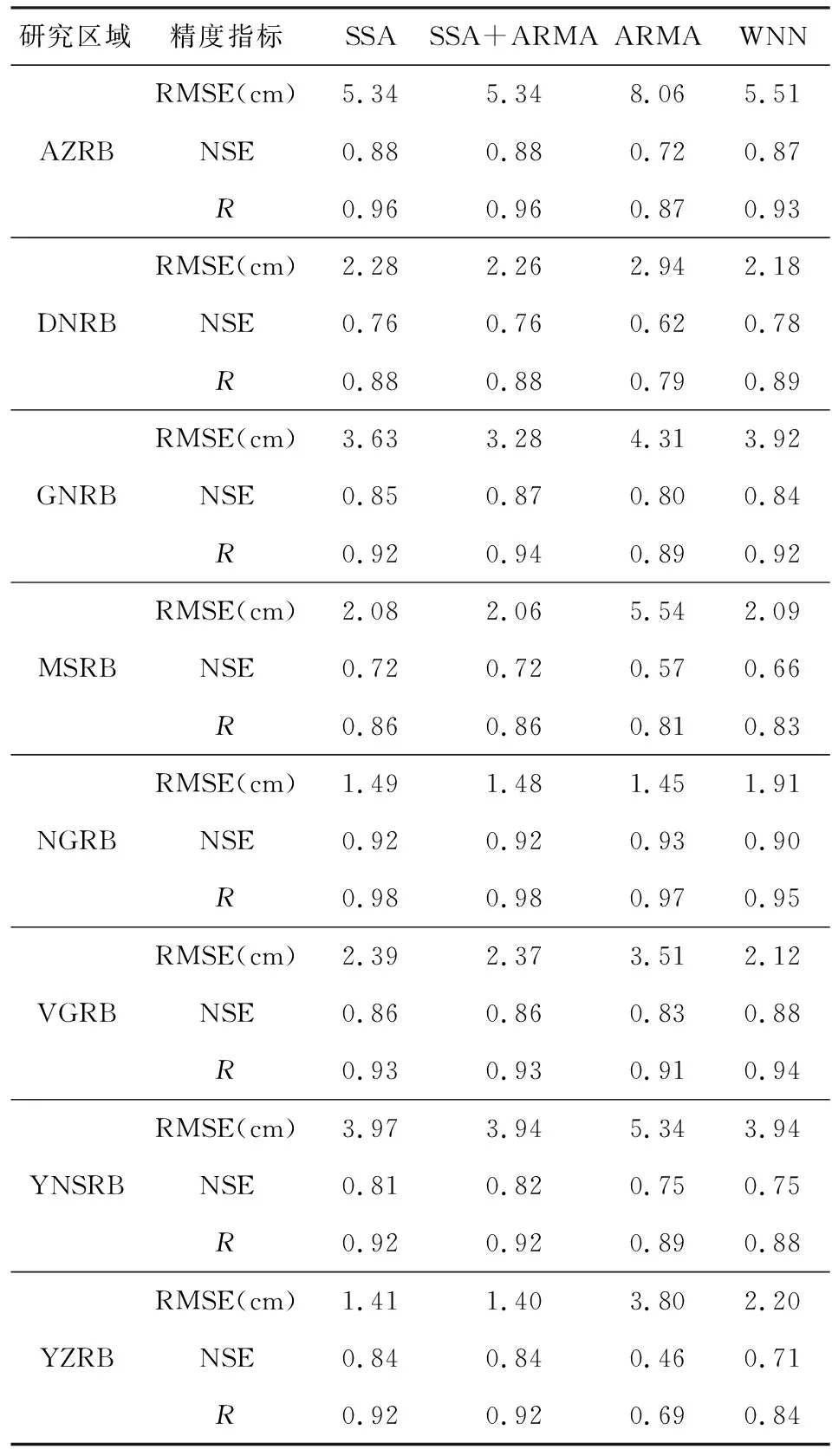
表3 基于不同方法的TWSA預測精度評定Table 3 Evaluation of TWSA′s prediction accuracy based on different methods
圖8為四種方法不同時段的預測精度,對多數流域來說,隨預測時間與訓練樣本時間間隔越來越大,四種方法的預測精度逐漸下降,前兩年的預測精度優于后兩年的預測精度.不同時段中,SSA與SSA+ARMA方法在各流域均有較高的預測精度,且受預測時間長度逐漸增加的影響較小,特別是在YNSRB和YZRB中,2016年SSA+ARMA方法的RMSE分別為2.72 cm和1.59 cm,明顯優于ARMA與WNN方法.ARMA方法預測精度較差,且受預測時間長度的影響較大,2016年AZRB的RMSE達到了14.25 cm.在MSRB、YNSRB、YZRB中,WNN方法2016年的預測精度較差,而AZRB、MSRB中,2016年的預測精度較高.大部分流域中所有時段SSA+ARMA方法的預測精度均略優于SSA方法,但二者差異較小.

圖8 不同方法的TWSA預測結果對比Fig.8 Comparison of TWSA prediction results by different methods
綜上所述,ARMA方法對于周期特征較弱的時間序列預測效果并不理想,易受到序列中噪聲成分的干擾,導致預測結果精度降低.WNN方法為機器學習方法,通過不斷調試學習速率、隱含層節點數等參數構建預測模型,計算效率較低,且因為缺少相關約束,某些流域構建的預測模型并不適用.在后續的研究中,若引入降水等氣象數據作為約束,WNN方法構建模型的效率及預測精度可能會進一步提升,同樣具有很大的潛力.而結合特征向量分析,SSA方法可有效識別并提取時間序列中不同成分,受噪聲的影響小,能從復雜的信號成分中提取更多有用信息,特別適合分析預測具有復雜成分或信號周期特征明顯的TWSA時間序列.
由表3可知,SSA與SSA+ARMA方法相比,SSA+ARMA方法要略優于SSA方法,且主要反映在RMSE上,其精度有0.01至0.1 cm量級的提升.這主要與各流域SSA重構序列的重構階數有關,如圖4b和圖6所示,AZRB的前8階重構成分的貢獻率達98.29%,因此剩余時間序列包含的信息較少,精度提升并不明顯.但各流域的SSA預測模型存在差異,對于SSA重構序列貢獻率較低的流域,SSA+ARMA方法會有較明顯的提升,如GNRB的重構階數K為4(表4中預測模型A),因而SSA重構成分的貢獻率會較低,與SSA方法相比,其RMSE降低了0.35 cm,NSE、R均提升了0.2.
3.5 SSA+ARMA方法的預測模型構建及補償結果精度評定
SSA+ARMA方法的預測精度主要還是由SSA方法的預測精度影響的.因而本文將討論如何選擇訓練樣本、檢驗樣本構建更適用的SSA預測模型,提高GRACE/GRACE-FO數據空窗期TWSA補償結果的精度.在之前的預測試驗中,SSA迭代預測方法構建的各流域預測模型如表4中預測模型A所示,但該模型存在一定的局限性,訓練樣本選取的2003年1月至2012年12月的120個樣本,并未充分考慮全部164個樣本,且訓練樣本與GRACE/GRACE-FO間斷期的時間跨度較大.因此構建的預測模型并不一定適用于數據間斷的補償.GRACE-FO數據作為GRACE的延續,本文對二者的數據處理過程一致,因此本文將GRACE-FO SH反演TWSA結果看作真值.為確定更準確、更適用于GRACE/GRACE-FO空窗期TWSA間斷補償的SSA模型,本文引入GRACE-FO SH反演TWSA及Mascons RL06結果作為檢驗樣本,提出了另外兩種構建預測模型的方案,三種方案區別如圖9.預測模型A與預測模型B和C相比,分析了訓練樣本對預測模型構建的影響,其中預測模型B和C充分考慮了164個訓練樣本.預測模型B和C的區別在于檢驗樣本的選擇,上文已知,隨預測時間與訓練樣本時間間隔越來越大,預測精度逐漸下降.因而預測模型B引入GRACE-FO SH反演TWSA結果作為檢驗樣本,對間斷補償結果序列的末尾進行約束,從而得到更適用于間斷補償的預測模型.相較而言,預測模型C除了引入GRACE-FO SH反演TWSA結果,同時還考慮了Mascons RL06結果,可以對間斷補償結果序列的首尾兩端均進行約束.以預測序列與檢驗樣本符合精度最高為準則,確定了各流域的預測模型A、B、C的參數,即窗口長度M和重構階數K.如表4所示,多數流域依據不同方案構建的SSA預測模型參數存在差異,特別是重構階數K,在預測模型B和C中,AZRB的K為4,表示該流域SSA的重構序列中有4個重構成分,因而剩余隨機序列中會包含較多的有效信息,相反NGRB的K為12,SSA方法對該流域TWSA序列的分解與重構更加充分,剩余隨機序列中包含的有效信息較少.在VGRB、YZRB中,方案二和方案三構建的預測模型B與C是一樣的.

圖9 三種方案的流程圖Fig.9 Flow chart of the three programmes
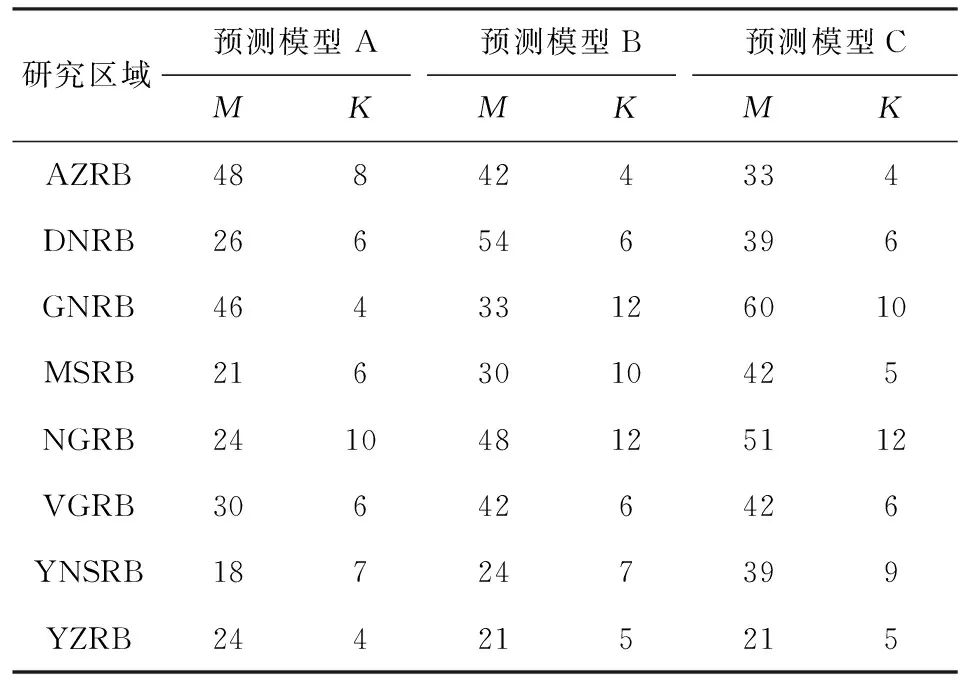
表4 基于不同方案的SSA預測模型Table 4 Prediction models of SSA based on different programmes
本文將GRACE SH反演的2003年1月至2016年8月TWSA序列作為樣本,基于SSA方法分別采用預測模型A、B、C,補償2016年9月至2020年2月的TWSA間斷結果.為檢驗補償結果的準確性及可靠性,受限于數據的包含范圍,本文選取2016年9月至2017年6月的CSR的Mascons RL06結果,2016年9月至2020年2月的GLDAS結果,2018年10月至2020年2月的GRACE-FO SH反演TWSA結果進行對比驗證.其中,GLDAS結果為對下載的格網序列球諧展開并截取至60階后,進行與GRACE數據一樣的處理流程后的結果.同樣的,各類數據均扣除了對應數據2003年1月至2016年8月的均值,其中CSR提供的GRACE-FO RL06 SH扣除了該機構GRACE RL06 SH的2003年1月至2016年8月均值.三種方案在間斷數據補償階段是一樣的,均采用2003年1月至2016年8月的164個TWSA結果為樣本,GRACE-FO SH結果與Mascons結果未參與實際預測過程,因此依據GRACE-FO SH結果與Mascons結果評定補償結果精度是有意義的.
圖10可知,除YZRB中預測模型A的補償結果外,其他間斷補償結果均取得了較好的效果.基于SSA方法的TWSA間斷補償結果與Mascons、GRACE-FO SH結果吻合得較好,這驗證了補償結果的可靠性.表5中RMSE可知,TWSA間斷補償結果與GLDAS結果在振幅上有明顯的差異,但由R可知,GLDAS結果與TWSA間斷補償結果在周期和相位變化上有較強的一致性,這亦能反映間斷補償結果的可靠性.振幅的偏差相對較大是因為GLDAS中只包含了0~200 cm土壤水、植物冠層地表水、積雪的變化,不包含地下水變化,而GRACE則反映了陸地總儲水量的變化和固體地球可能的物理遷移(Chao,2016).因而在后續主要依據GRACE-FO SH反演的TWSA及Mascons結果進行精度評定.
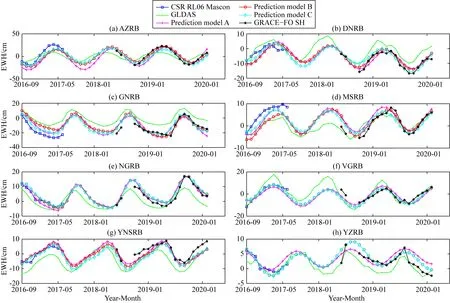
圖10 基于SSA方法TWSA間斷補償結果與GRACE-FO SH,Mascons和GLDAS結果的比較Fig.10 Comparison of TWSA gap compensation results by SSA with GRACE-FO SH,Mascons and GLDAS results
表5可知,各流域中預測模型A、B、C的間斷補償結果精度存在差異.預測模型A的符合精度相對較差,表明在構建預測模型過程中,采用更充足的訓練樣本有利于構建更適用的預測模型.預測模型B、C均取得了較好的預測效果,但在細節上存在差異,預測模型B與GRACE-FO SH結果的符合精度最高,但可能會導致間斷補償結果序列的前部分失真,如DNRB的間斷補償結果與Mascons結果的NSE僅為-0.02;在GNRB中RMSE達10.60 cm.相較而言,預測模型C對間斷補償結果的首尾兩端均進行了約束,不會出現這種問題.但值得注意的是,在MSRB中,比較NSE可得,預測模型B的補償結果要優于預測模型C.這與本文GRACE SH反演的TWSA在該流域與Mascons結果存在較大差異有關(見表2).因此當引入Mascons RL06結果作為檢驗樣本約束間斷補償結果時,反而會降低補償精度.本文采用的GRACE/GRACE-FO SH均為CSR提供的RL06版本,且進行了相同的數據處理流程,可以看為同種數據,相反作為成熟產品的Mascons結果無法保證這一點.因而當預測模型B、C的補償結果符合精度相當時,本文優先考慮預測模型B間斷補償結果.綜上所述,AZRB、DNRB、GNRB、NGRB采用預測模型C的SSA間斷補償結果,MSRB、YNSRB采用預測模型B的SSA間斷補償結果,在VGRB、YZRB構建的預測模型B與C是一樣的.
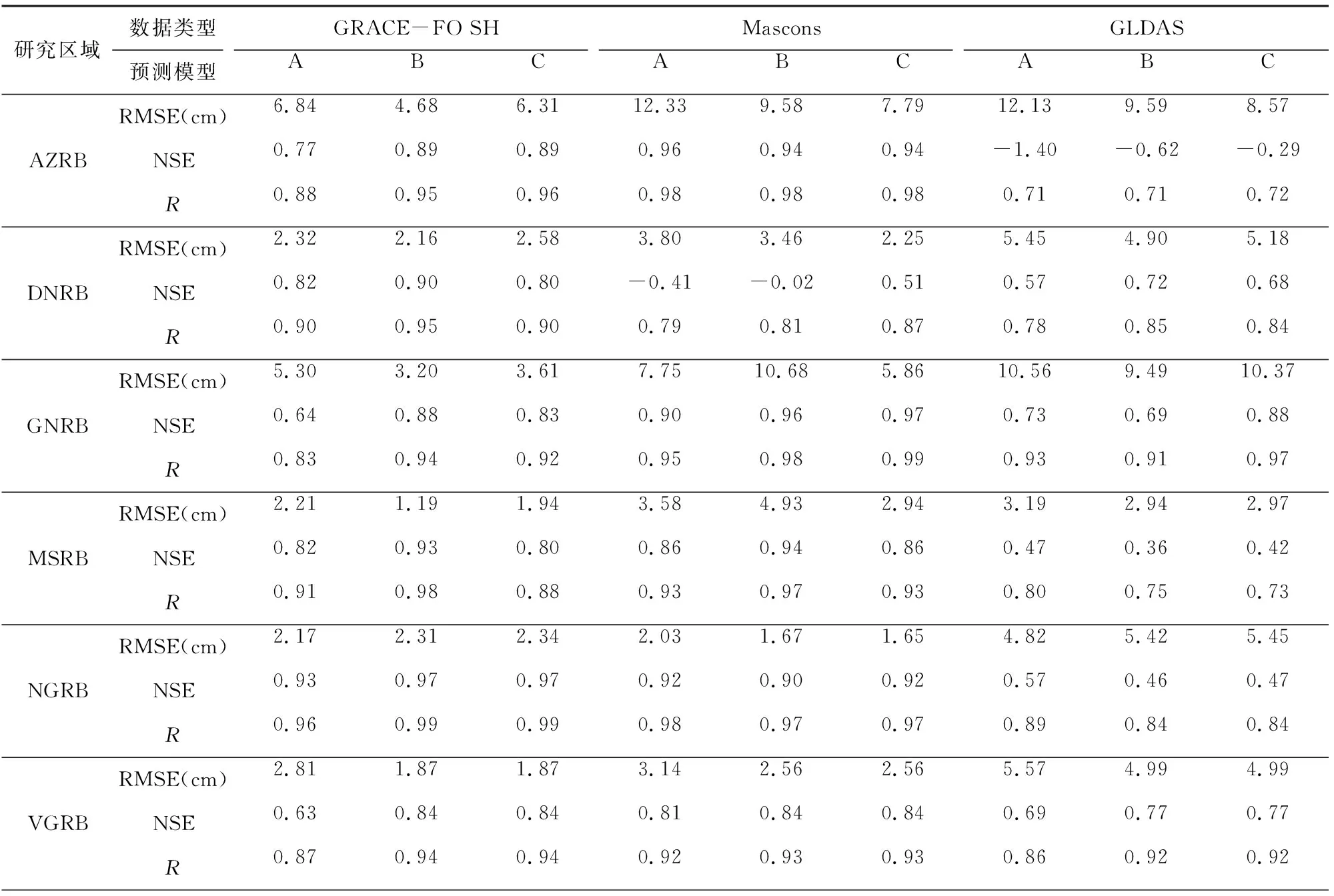
表5 基于SSA方法的TWSA間斷補償結果精度評定Table 5 Accuracy assessment of TWSA gap compensation results by SSA
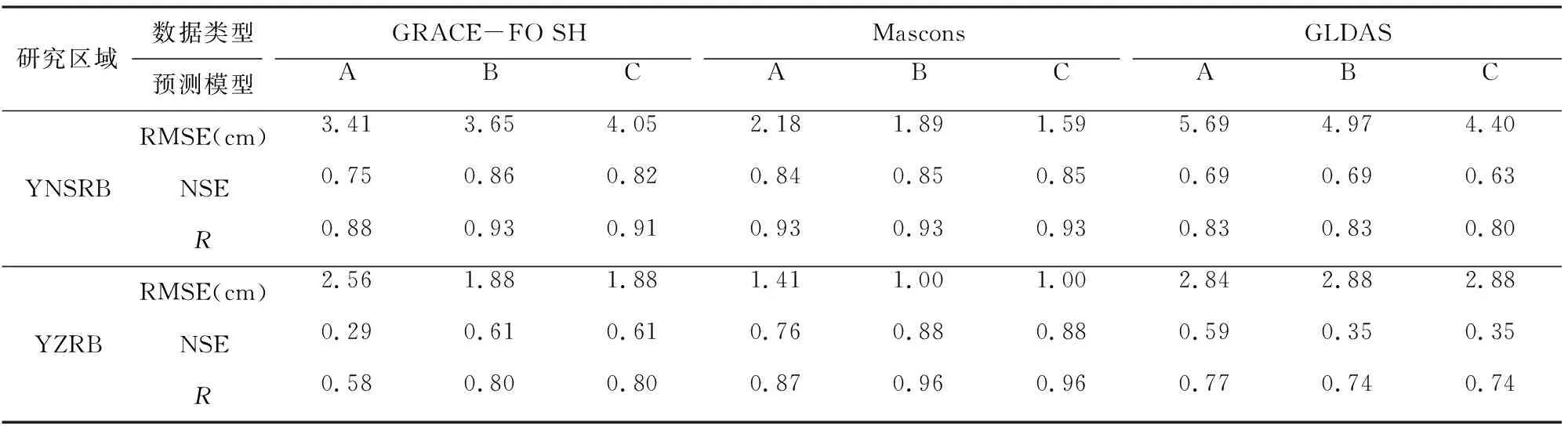
續表5
根據上文選取的基于SSA方法的間斷補償結果,本文進一步采用SSA+ARMA方法提升補償精度.表6可得,SSA+ARMA方法的間斷補償結果整體優于SSA方法,且主要體現在RMSE上.其中AZRB的間斷補償結果的精度提升最為明顯,基于GRACE-FO SH結果的精度評定中,RMSE降低了1.35 cm,基于Mascons結果的精度評定中,RMSE降低了1.01 cm.除AZRB外,DNRB、NGRB、VGRB、YZRB的預測精度也有相對明顯的提升.
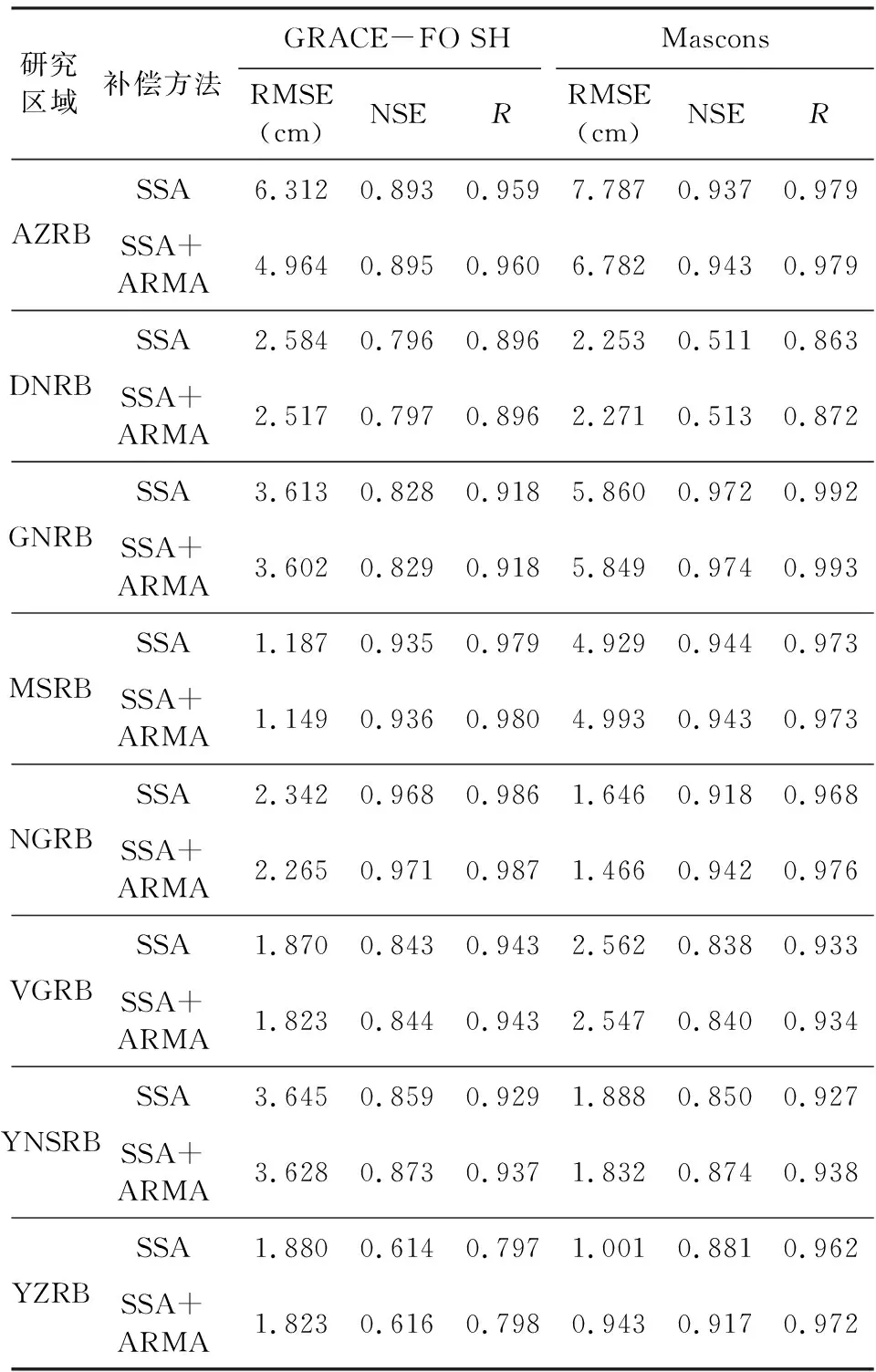
表6 基于SSA+ARMA方法的TWSA間斷補償結果 精度評定Table 6 Accuracy assessment of TWSA gap compensation results by SSA+ARMA
綜上所述,基于SSA+ARMA方法的TWSA間斷補償結果有較高的精度,與同期GRACE-FO SH結果相比,除AZRB的RMSE為4.96 cm外,其他流域的RMSE均在4 cm以內;除YZRB的NSE、R分別為0.61、0.80外,其他流域的NSE值均在0.80以上,R值均在0.90以上.對TWSA序列相對復雜多變的DNRB、YZRB(圖3b,h),間斷補償結果也取得了較好的效果,特別是YZRB(圖10h)的2018年10月—2019年7月周期特征不明顯,而SSA間斷補償結果與GRACE-FO SH結果卻有很強的一致性,這充分體現了SSA方法能識別、提取復雜成分信號中有用信息的特性.在八個典型流域中,NGRB的間斷補償結果精度最高,這可能與該流域受人類活動影響少,TWSA序列具有強周期特征有關.
3.6 基于SSA+ARMA方法的TWSA間斷補償結果試驗
上文三種方案的預測模型構建中,由于部分流域GRACE SH反演的TWSA與Mascon結果符合較差,因而預測模型B和C互有優勢.但在實際應用中,若采用同種數據作為訓練樣本與檢驗樣本,方案三構建的預測模型取得的間斷補償效果更好.截至2021年1月,基于GRACE-FO的CRS RL06 Mascon數據結果已經更新至2020年10月,對基于SSA+ARMA方法的TWSA間斷補償的實際應用提供了充足的數據支持.
本文采用方案三的預測模型構建思路,利用2003年1月至2016年8月的Mascon結果為訓練樣本,2016年9月至2017年6月及2018年10月至2020年2月的Mascon結果作為檢驗樣本構建SSA預測模型.構建預測模型后,在實際應用中為得到精度更高的間斷補償結果,無需考慮精度評定的問題,間斷補償階段應盡可能選擇充足的樣本.因而采用2003年1月至2016年8月及2018年10月至2020年10月的Mascon結果作為樣本,利用SSA+ARMA方法對2016年9月至2018年9月的結果進行補償.如圖11所示,各流域的TWSA間斷補償結果均取得了較好的效果,補償結果與CSR RL06 Mascon結果連接較為緊密,且無論是趨勢項還是周期特征均與原始時序符合得較好.對于典型流域,利用SSA+ARMA方法可以對GRACE/GRACE-FO空窗期的TWSA間斷進行有效補償.表7為SSA+ARMA與SSA方法補償結果的統計信息對比.由標準差和均方根值可知,SSA+ARMA方法的補償結果整體略優于SSA方法,相較SSA方法,SSA+ARMA方法可以顧及到SSA方法未能充分重構的剩余有效信息.
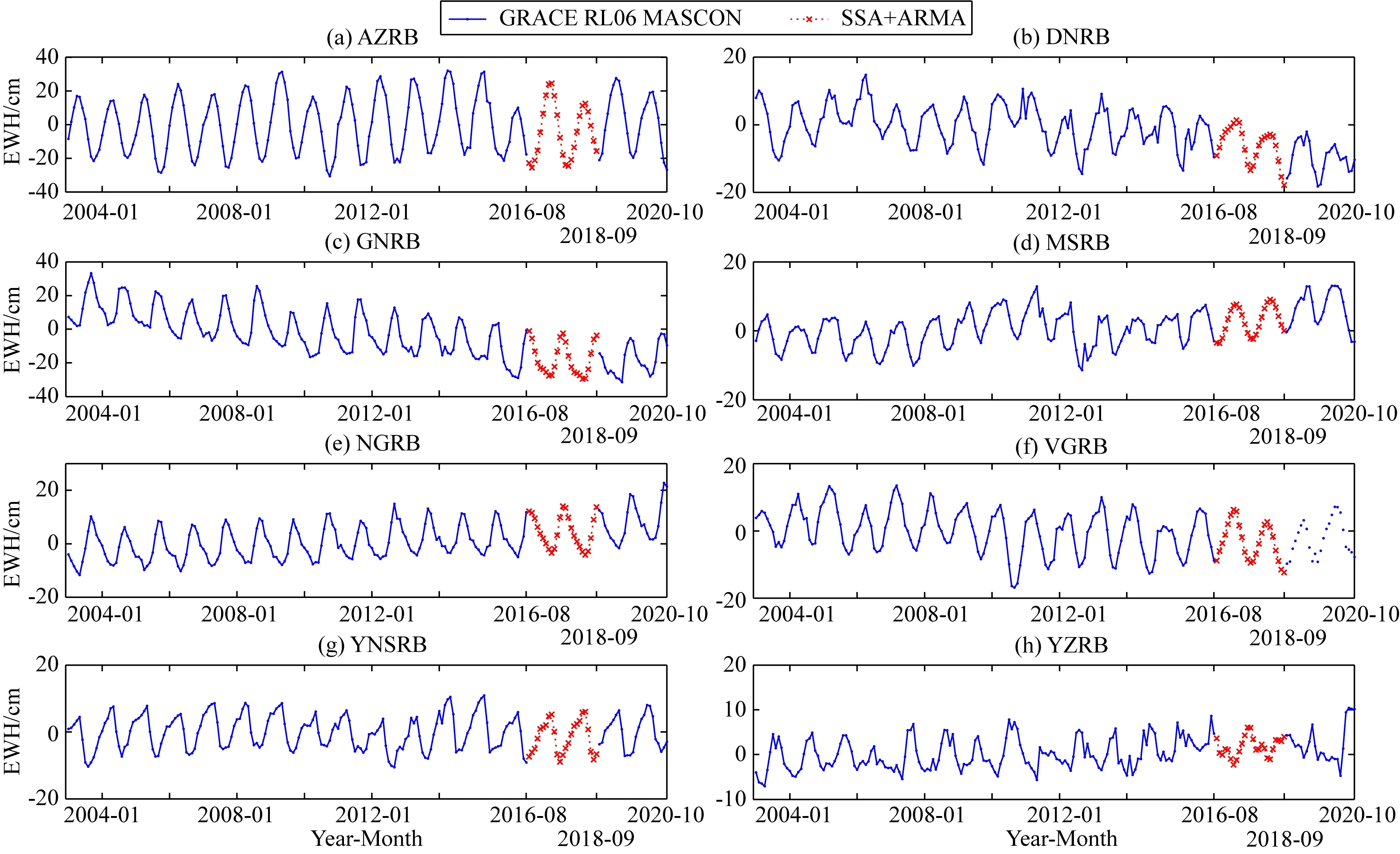
圖11 基于SSA+ARMA方法的TWSA間斷補償結果Fig.11 TWSA gap compensation results by SSA+ARMA
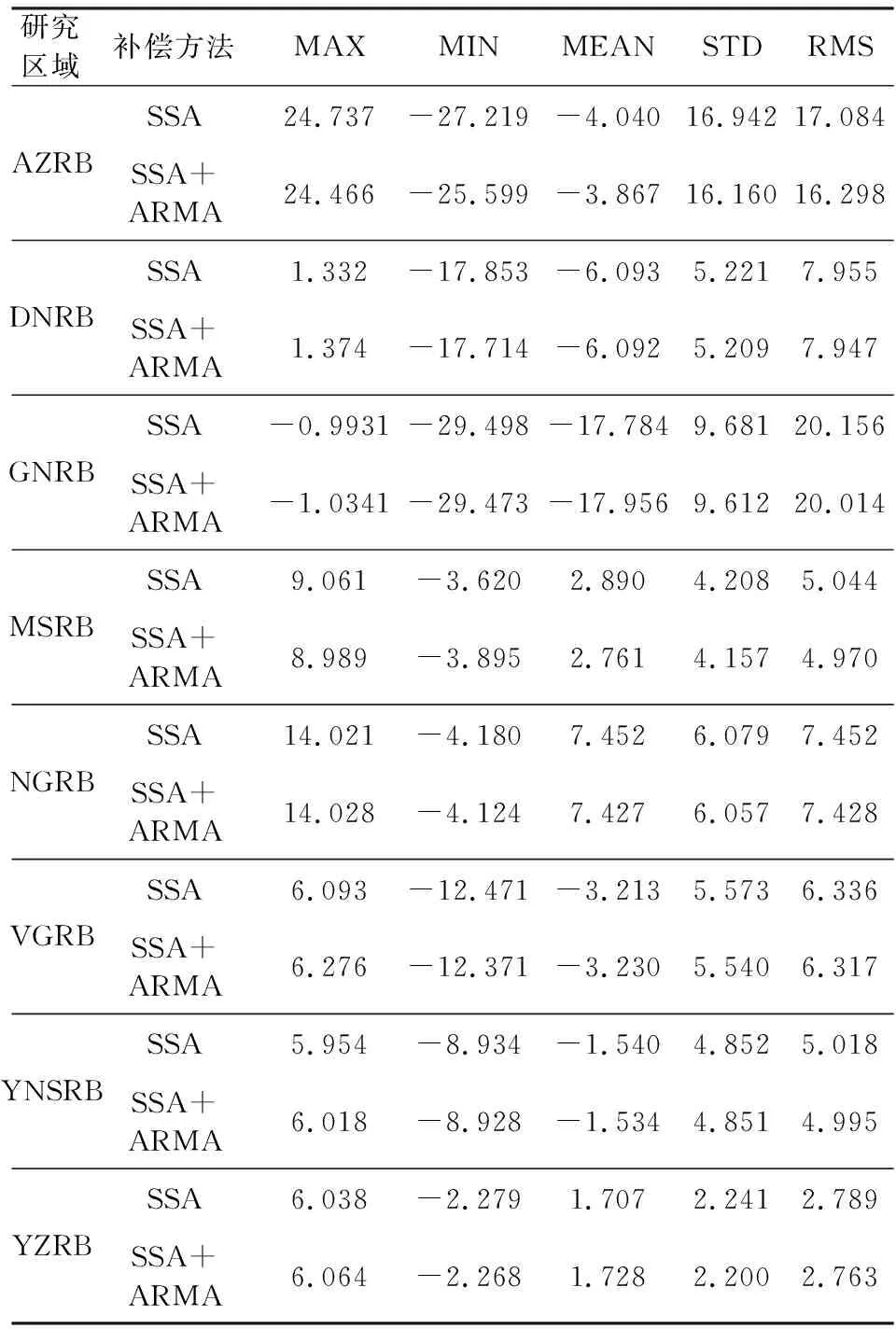
表7 基于SSA+ARMA和SSA的TWSA間斷 補償結果統計信息(單位:cm)Table 7 The statistics of TWSA gap compensation results by SSA+ARMA and SSA (Unit: cm)
4 討論
4.1 SSA預測模型參數確定
FFT及W-correlation方法均為提高構建預測模型效率的輔助方法,本文最終的模型參數確定以預測序列與檢驗樣本的符合精度最高作為準則(包括WNN、ARMA方法).各典型流域均有明顯的周年信號,但半年信號在不同流域存在差異,在構建各流域的SSA預測模型時,重構階數K是否考慮半年信號還應以預測序列與檢驗樣本的符合精度最高為準則.因而本文提出了三種方案來討論如何選取訓練樣本、檢驗樣本,構建更適用于間斷補償的SSA預測模型.引入GRACE-FO SH反演TWSA、Mascons結果作為檢驗樣本,不僅能使訓練樣本更加充足,還能對間斷補償結果進行約束,防止間斷補償結果失真.方案一構建的預測模型A與方案二和方案三構建的預測模型相比表明,充足的訓練樣本有助于構建更適用于間斷補償的SSA預測模型.方案二的預測模型B的補償結果與GRACE-FO SH反演的TWSA符合得更好,但可能會導致補償結果前部分失真(如表5中DNRB、GNRB).方案三的預測模型C對補償結果的首尾兩端均進行約束,但在3.5節中,由于GRACE SH反演的TWSA與Mascons符合精度存在差異的問題,部分流域引入Mascons結果作為檢驗樣本反而可能會導致得不到最佳的預測模型(如表5中MSRB、YNSRB).而3.6節中,當訓練樣本及檢驗樣本均采用Mascon結果或同種數據時,采用方案三構建預測模型的思路能取得更好的間斷補償效果.方案三的主要思想為引入檢驗樣本對間斷補償結果的首尾兩端進行約束,從而構建更適用的預測模型.在實際應用中,訓練樣本與檢驗樣本的長度可以根據研究目的及需求的不同進行調節.
4.2 SSA與SSA+ARMA方法
SSA+ARMA方法的間斷補償結果整體優于SSA方法,且主要體現在RMSE上,其精度有0.01至1 cm量級的提升.表6可得,SSA+ARMA方法對AZRB、DNRB、VGRB、YZRB的精度提升相對明顯,特別是AZRB,基于GRACE-FO SH結果的精度評定中,該流域的RMSE降低了1.01 cm,基于Mascons結果的精度評定中,RMSE降低了1.35 cm.表4可知,AZRB的SSA預測模型C重構階數K為4,扣除SSA重構序列后的剩余隨機時間序列還保留了更多的有效信息,因而再利用ARMA進行外推可以有效提升最終的間斷補償結果的精度.在DNRB、VGRB、YZRB中,預測模型的重構階數K同樣較小.相反,NGRB的預測模型的K為12,因為該流域的TWSA信號周期特征最為顯著,SSA方法能充分分解與重構TWSA時間序列,剩余隨機時間序列包含的有效信號較少,所以SSA+ARMA方法的補償結果精度沒有明顯的提升.當SSA方法無法充分的重構TWSA信號,即預測模型的重構階數K較小,剩余信號中保留更多的有效信息時,SSA+ARMA方法能更明顯的提升間斷補償結果的精度.如表7所示,由最大值、最小值及均值可知,SSA與SSA+ARMA補償結果的振幅差異較小,大部分差異在0.1 cm的量級.由標準差和均方根值可知, SSA+ARMA方法的補償結果整體略優于SSA方法,精度提升量級在0.01至0.1 cm,其中在AZRB的精度提升最為明顯,標準差降低了0.78 cm,均方根值降低了0.79 cm.相較SSA方法,SSA+ARMA方法可以顧及到SSA方法未能充分重構的剩余有效信息.在以后的實際應用中,對于周期特征弱的非典型流域地區的TWSA序列進行間斷補償時,與SSA方法相比,SSA+ARMA方法可能會取得更好的補償精度提升效果.
5 結論
本文引入了SSA+ARMA方法對GRACE/GRACE-FO空窗期的TWSA間斷結果補償的方法.聯合GRACE SH、GRACE-FO SH、Mascons、GLDAS數據,在AZRB、DNRB、GNRB、MSRB、NGRB、VGRB、YNSRB、YZRB八個流域進行了不同方法的預測試驗及SSA+ARMA方法的TWSA間斷補償試驗,分別驗證了SSA+ARMA方法的適用性及有效性.結論如下:
(1)傳統利用多年或前后兩年球諧系數均值替代缺失數據的方法會引入較大的誤差,而本文采用SSA迭代插值方法的插值結果更符合TWSA序列周期變化的特征,更利于后續SSA方法的周期分解與重構.本文GRACE SH反演的TWSA與CSR、JPL、GFZ的Mascons結果有較好的一致性,大多數流域的RMSE在2 cm以內,NSE、R在0.95以上,驗證了反演結果的準確性及可靠性.CSR的Mascons RL05、Mascons RL06結果與GRACE SH反演TWSA結果吻合程度最高.
(2)通過四種方法的預測對比試驗發現,在多數流域中,隨預測時間長度的增加,四種方法的預測精度逐漸下降,但SSA與SSA+ARMA方法受其影響較小.SSA與SSA+ARMA方法的預測精度較高且相對穩定,相較而言ARMA模型的精度最差.ARMA方法對于周期特征較弱的序列預測效果并不理想(如DNRB、MSRB、YZRB),而SSA與SSA+ARMA方法取得了較好的效果,這充分體現SSA方法能識別、提取復雜成分信號中有用信息的特性.
(3)SSA+ARMA方法的補償精度主要受SSA方法補償精度的影響.引入GRACE-FO SH反演TWSA或Mascons結果作為檢驗樣本,采用更充足的訓練樣本,可以構建更適用于間斷補償的SSA預測模型,進而能有效提高最終TWSA間斷補償結果的精度.在實際應用中,若引入同種數據作為檢驗樣本,對間斷補償結果的首尾兩端進行約束,構建的預測模型能取得更好的間斷補償效果.
(4)基于SSA+ARMA方法的TWSA間斷補償結果有較高的精度,與GRACE-FO SH結果有很強的一致性.除AZRB的RMSE為4.96 cm外,其他流域的RMSE均在4 cm以內;除YZRB的NSE、R分別為0.61、0.80外,其他流域的NSE值均在0.80以上,R值均在0.90以上.
(5)在實際應用的試驗中,SSA+ARMA方法的間斷補償結果優于SSA方法,且主要體現在標準差和均方根值上,其精度提升可達0.1 cm量級.相較SSA方法,SSA+ARMA方法可以顧及到SSA方法未能充分重構的剩余有效信息.
綜上,本文提出基于SSA+ARMA方法的TWSA間斷補償是可行且有效的,對實現TWSA的長期持續監測有重要的參考價值和科學意義.
致謝感謝匿名審稿專家對本文提出的寶貴意見.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
