基于多維度的網絡數據融合篩選技術
2021-08-26 02:50:02李麗娟劉榮吉原小衛
中國新技術新產品 2021年10期
李麗娟 劉榮吉 原小衛
(1.成都九洲電子信息系統股份有限公司,四川 成都 610041 ;2.盲信號處理國家級重點實驗室,四川 成都 610041)
0 引言
隨著新一代通信技術的迅速發展,網絡規模不斷擴大,通信鏈路速率快速提升,承載業務更加多樣化,信息隱匿技術廣泛應用,網絡攻擊手段日趨多元化、組織化、隱蔽化,這些都使網絡管理工作越來越復雜,難度增加。網絡流量監測是網絡管理、網絡運營、網絡優化和網絡安全的重要基礎,是掌握網絡運行規律和理解網絡行為的支撐技術,是網絡安全審計系統的關鍵環節[1]。目前,網絡流量監測主要從4個層面展開:基于 Bit-level、基于Packet-level、基于Flow-level以及基于Stream-level的流量分析[2]。
在網絡管理工作中,往往存在網絡優化、特定問題查找、可疑目標鎖定、網絡行為溯源和取證等需求,需要從不同層面精準地采集網絡數據,進一步分析處理,其中包括多個層面融合采集的需求。通常使用模式匹配的方式對網絡數據進行標記、篩選,模式相對簡單(例如五元組),規則相對固化,在數據匹配的靈活性方面有所欠缺,用戶體驗欠佳;此外,由于傳統匹配模式多為串行處理,即對一個網絡數據的處理按規則進行先后處理,該模式的處理性能較低,進而導致所支持的規則集合規模無法擴大、系統整體處理能力受限。因此,該文研究一種行之有效的多維度融合匹配技術,以期大幅擴大篩選規則集合的規模,增加數據處理的靈活性,有效提升整體處理性能,滿足用戶需要,在大規模在線網絡數據處理環境下是很有必要的。
1 基于多維度的網絡數據融合篩選關鍵技術
1.1 軟件定義數據篩選規則
軟件定義數據篩選規則(Software-Defined Filter Rules,SDFR)是一套面向在線網絡優化、應用過濾、攻擊監測與特殊數據識別等應用的網絡數據篩選規則描述語言。
SDFR提供跨網絡協議棧層次的靈活數據篩選表達式描述方法,支持從鏈路層、網絡層、傳輸層到應用層協議字段的全棧數據特征描述,并支持對包長度等統計類特征描述[3]。SDFR支持掛載第三方插件的方式來提供規則的可擴展性,并通過動作描述來支持各類命中數據處置方案,包括采樣輸出、原始報文數據以及元數據輸出等。
SDFR定義如下。
SDFR: =
規則主體包括3部分,分別為規則頭部(RULE_HEADER)、規則體(RULE_BODY)、規則動作(RULE_ACTION)。其中,規則頭部必須存在,規則體、規則動作均可以為空。
規則體通過多個表達式定義特征匹配、計算規則,表達式之間使用&&連接。在語法單元之間和前后可加入若干個空格,以增強規則的可讀性。
規則動作指示規則命中后,如何進行后續操作,每個動作后使用“;”表示結束。在語法單元之間和前后可加入若干個空格,以增強規則的可讀性。
1.2 流程引擎驅動
流程引擎是多維度融合篩選處理的控制中心[4],通過對SDFR的解讀,形成篩選規則集合,并映射到規則矩陣,生成待置位結果矩陣,按需要驅動相應維度處理線程,最后將單維結果向量進行按位與操作,完成整個篩選處理流程。全過程包括規則預處理、規則匹配和規則命中標記3個部分的處理流程。
1.2.1 規則預處理
規則預處理完成規則解析,通過SDFR的語法分析、詞法分析,完成規則合法性檢測;將多維規則集合中每一條規則不同維度的內容抽取出來,完成規則按維度分類,形成二維規則矩陣;同時,根據規則維度建立多個變量(bitmap)作為命中結果向量,每個bitmap代表一個維度規則集的匹配結果,bitmap每個bit位對應一個規則,將規則集合和bitmap雙向映射起來,便于匹配后根據bitmap的下標快速查詢規則。
創建bitmap命中結果向量時,bit位設為1表示對應的規則恒命中;設為0表示匹配過程中根據匹配結果來更改。
1.2.2 規則匹配
規則匹配實現基于數據包、報文、深度報文的多維特征匹配,匹配對象為網絡數據流[5]。網絡數據流具有多維度屬性,包括自定義頭部、五元組和承載內容等報文屬性以及階段屬性,包括會話創建、會話重組和會話超時等階段/狀態。在會話流的創建階段,可以解析出五元組、自定義頭部屬性,此時即可完成五元組匹配和自定義維度匹配,更新相應的結果向量;會話重組階段不做任何匹配;會話超時后可獲取完整的承載內容,此時完成關鍵詞匹配和正則表達式匹配。通過分階段進行不同維度的匹配,降低了匹配次數,同時又保證了準確性。
為了了解參保人員的基本情況,筆者隨機走訪了幾個村進行實地調研,發放調查問卷120份,調查對象為男性70人,女性50人,年齡段主要集中在31-59歲,占調查總人數的91.7%;60歲以上的10人。受教育情況為,小學及以下、初中和高中的人數分別為61人、47人和12人。經濟來源情況:純務農的63人,這部分人員月均收入均在1000元以下;手工藝者27人,月均收入約在2000—4000元,經商者12人,依靠子女供養的18人。
1.2.3 規則命中標記
規則命中標記處理將規則匹配后生成的多個單維bitmap結果向量進行按位與運算,并根據結果向量中值為1的下標查詢出規則ID,形成命中規則列表。
1.3 矩陣處理機制
規則矩陣主要存儲規則集合信息,由多個單維規則向量構成,與之相對應為命中結果矩陣。矩陣處理機制以二維矩陣的模式處理網絡數據流的匹配命中情況[6],分為行處理和列處理。行處理代表單維規則集的匹配處理,例如五元組、關鍵詞和正則表達式等,處理結果為單維bitmap結果向量;列處理代表不同維度的匹配處理結果,將不同行結果向量進行按位與運算,得到多維融合匹配結果向量。
2 多維網絡數據融合篩選技術工程實現
2.1 多維網絡數據融合篩選流程
多維網絡數據融合篩選流程如圖1所示,由融合匹配規則集預處理、網絡數據包解析和融合匹配處理3個模塊組成。其中,融合匹配規則集預處理實現規則拆解和各維度規則預處理,網絡數據包解析完成各維度屬性要素解析和抽取,融合匹配處理完成各維度并行匹配和結果集融合處理。
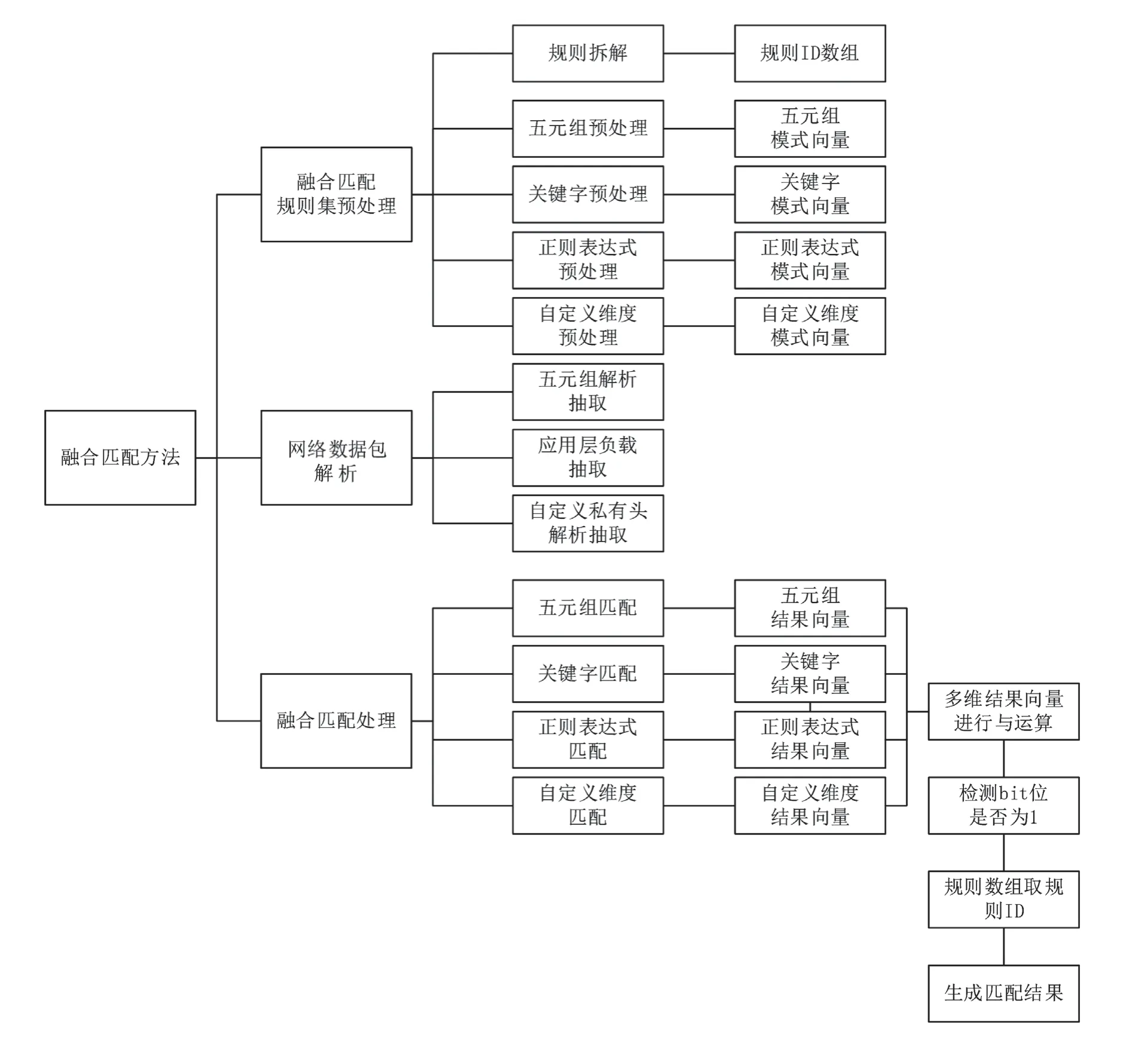
圖1 多維網絡數據融合篩選流程圖
五元組匹配采用ACL算法,實現對精確五元組和模糊五元組的匹配處理。ACL算法設計初衷是進行防火墻的訪問控制,對數據包匹配的默認操作是返回優先級最高的規則,該設計丟棄了對規則集合中剩余規則的匹配,不滿足對多用戶多規則的數據篩選需求,因此,筆者對ACL算法進行了修改,改為返回命中的所有規則集合。
關鍵詞匹配完成對復雜關鍵詞的匹配,對AC算法進行優化,使其支持前向、后向和模糊匹配。
正則表達式匹配實現對通用正則規則的匹配[7],支持單幀匹配和流匹配模式。
自定義維度匹配對鏈路層屬性、數據長度和TCP標志位等信息進行匹配處理。
多維融合篩選處理在對網絡數據流進行規則矩陣匹配處理后,對結果向量進行按位與操作,檢測結果向量每個bit位是否為1,以判定所對應ID的規則是否命中,根據命中ID數組反查規則矩陣,得到該數據流命中的所有規則集合。
2.2 實驗驗證
該文提出的多維度網絡數據融合篩選方法已在實際場景中應用,在真實環境中對不同量級的規則集合下網絡數據篩選能力進行測試,分規則集合中是否包括正則表達式規則2種情況,測試結果如圖2所示。該文實驗所用服務器配置如下:CPU為Intel Xeon E5 v2630;主頻為2.20 GHz;內存為128G;Intel為萬兆網口;操作系統為CentOS 7.564位。
在圖2中,橫坐標代表規則集合數,縱坐標代表可在線處理網絡流量。從圖中可以看出,在10萬條多維組合規則前提下,可處理流量約為5 Gbps;另外,可以觀察到,正則規則的存在對網絡數據篩選整體性能有顯著影響,即使添加限定范圍內的少量正則規則,也會大幅降低整體處理性能。
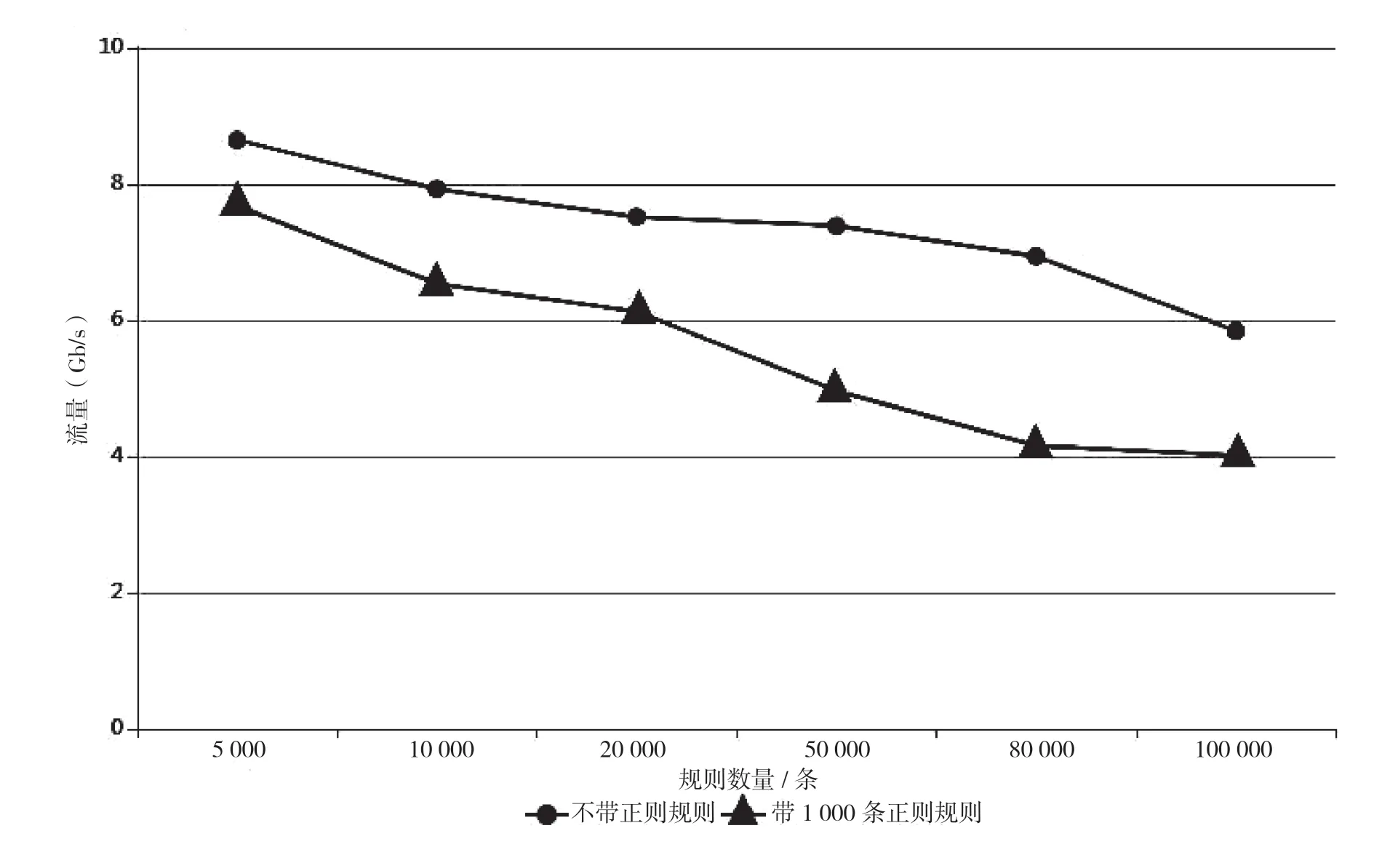
圖2 不同規模規則集合下篩選處理性能測試結果
3 結語
該文提出的數據篩選技術通過對多維度融合匹配規則集合進行預處理,將融合匹配條件進行拆解、轉換,形成多維匹配模式矩陣,將每條具有多維特征的規則轉換為規則矩陣中的一個列向量,同時將融合匹配規則的ID映射在規則矩陣行向量中,可通過數組下標實現快速訪問;隨后,對網絡數據進行解析處理,得到不同維度的屬性信息,并針對這些屬性信息按相應的匹配條件分別進行匹配處理,并形成相應的行結果向量,最后,將多個行結果向量進行按位與操作,實現對多維匹配結果的融合處理。檢測融合篩選結果向量為1的bit位及該bit位ID序號,按序號訪問規則矩陣,獲取對應的匹配命中規則集。該技術將多個維度的篩選需求解耦到不同的處理流程,實現了網絡數據匹配的并行處理,提升了支持融合匹配規則的數量級,并大幅提升了融合匹配的處理性能。
該文提出的多維度網絡數據融合篩選技術,已應用于特定場景下的網絡數據處理設備中,具備支持規則容量大、性能穩定以及規則易擴展等特點,具有很強的實用性。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
作文成功之路·小學版(2020年9期)2020-10-28 08:06:36
現代出版(2020年3期)2020-06-20 07:10:34
Coco薇(2017年11期)2018-01-03 20:59:57
商周刊(2017年7期)2017-08-22 03:36:22
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
