基于顧及曲率自適應鄰域的點云單點分類方法
2021-08-24 06:41:38何鄂龍
現代制造技術與裝備 2021年7期
何鄂龍
(中國船舶集團有限公司第七一五研究所,杭州 310023)
1 技術背景
隨著LiDAR(Light Detection and Ranging)技術的快速發展,通過機載激光掃描、地面激光掃描和移動激光掃描可以更加快速地獲取城市點云數據[1]。點云分類是三維點云場景分析中的關鍵[2],現已經成為攝影測量和遙感領域的研究主題[3]。
在點云分類任務中,點云數據缺失和不均勻的密度分布給分類任務帶來了巨大挑戰[4]。經典算法是提取典型的特征[5],并基于監督分類算法進行點云分類[6],可以分為點云鄰域重構、點云局部特征提取和點云分類3個步驟[7]。
點云局部特征可以有效地表達實際場景中物體的結構信息,通常由局部鄰域的點云空間分布統計得到[2]。三維鄰域的構建可分為固定尺度方法和自適應尺度方法[4]。固定鄰域方法受限于場景先驗知識、點云密度以及曲率分布等。自適應鄰域方法通過點云局部鄰域的空間分布情況生成鄰域,可以有效消除點云密度分布不均和線狀分布帶來的影響,但需要真實數據的先驗信息作為參數。最小熵方法通過搜索鄰域k或鄰域半徑r確定最優鄰域[2],其中基于鄰域半徑r的方法容易受到密度變化的影響,基于鄰域k的方法容易受到線狀分布的影響。
本文采用點云單點分類方法對點云數據進行分類,創造性地提出了顧及曲率的自適應鄰域估計方法,有效增強了點云統計特征的可分離性,進一步提升了分類效果。
2 算法流程
本文的點云分類方法主要包括曲率的自適應鄰域估計、特征提取和監督分類3部分。整體的算法流程如圖1所示。
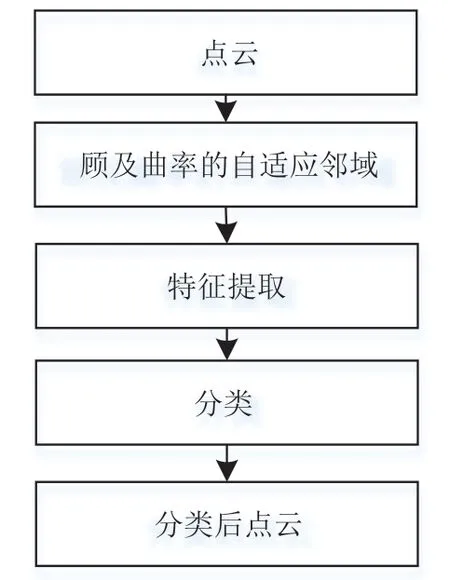
圖1 點云分類方法流程
2.1 顧及曲率的自適應鄰域估計
點云的曲率用于描述三維點所在表面的局部變化情況,通常由一定鄰域范圍內點集的統計信息得到。傳統的方法是使用鄰域內三維點集的協方差矩陣。基于協方差矩陣的3個特征值,可以得到點云數據的曲率信息:

點云曲率被歸一化到[0,1/3],0表示三維點處于一個平面,1/3表示三維點處于混亂的分布狀態。點云分布情況和自適應鄰域的半徑分布,如圖2所示。通常點云數據中植被和物體的邊界區域曲率較大,如圖2(c)所示,此類點需要較小的鄰域半徑,反之小曲率區域,需要較大的鄰域。因此,良好可分的特征提取方法需要要合適的自適應鄰域。
圖2(d)為基于k-最小熵的自適應鄰域vk,k的取值范圍為10~100,取值間隔Δk=1,點云鄰域在區域Ⅰ中的高密度規則區域呈現為一種纖細的線狀分布,不足以提供魯棒的特征。圖2(e)為基于r-最小熵的自適應鄰域vr,r的取值范圍為0.25~2.00 m,采樣間隔Δr=0.05 m。在區域Ⅱ中存在與區域Ⅰ一樣的問題。從區域Ⅲ可以看到,植被區域的鄰域尺寸較大,無法有效提取細節特征。因為沒有考慮點云在復雜城區場景中的不均勻分布,所以當前的自適應鄰域在高密度的規則區域仍然呈現出線狀分布。

圖2 點云分布情況以及自適應鄰域的半徑分布。
基于兩種最小熵的鄰域估算方法,本文設計了一種估計曲率的自適應鄰域估算方法vc。該方法主要是基于曲率閾值ct將點云數據預分割為規則區域和非規則區域,然后分而治之,如圖3所示。
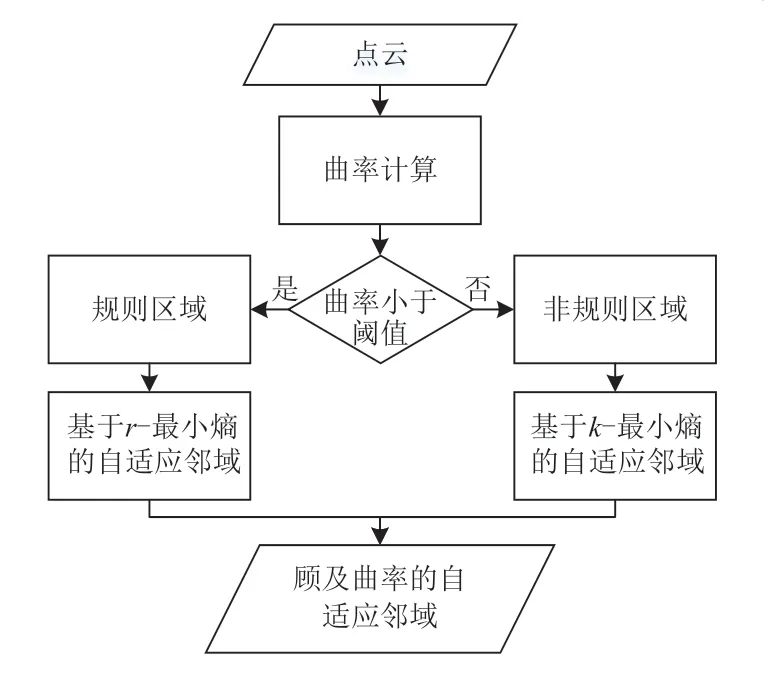
圖3 顧及曲率自適應鄰域估算方法流程圖
由于離散點沒有足夠的鄰近點支撐鄰域構建,曲率需設置為1/3。點云數據中當曲率大于ct時被分類為散亂區域,并使用vk方法估算鄰域,小于ct的則被分為規則區域,并使用vr方法估算鄰域。

由于現實場景中的點云先驗知識是未知的,點云自適應鄰域需要以較小的邊界覆蓋場景中絕大部分類型的物體,并減小運算量。自適應鄰域vk法選取最小邊界kmin=10,通過主成分分析(Principal Components Analysis,PCA)法來估算3D局部幾何特征,并根據數據的計算量合理設置上邊界值。同時,自適應鄰域vr法應設置下邊界rmin=0.25 m,避免vr鄰域集中在點云數據中某一條掃描線上。由于自適應鄰域vc估算方法已經考慮了點云數據中規則與非規則區域的先驗信息,并將參數k的上邊界設置為50,以減小運算量,變化范圍為10~50,采樣間隔Δk=1。在本文方法中,綜合考慮城市場景中物體的大小分布,自適應鄰域的最大尺寸被限制為3 m。在規則區域內,鄰域通常較大,可以將參數r的下邊界設置為0.5 m來減少運算量。參數r∈[0.5,2.0],以Δr=0.05 m的步長采樣,劃分為30個尺度計算。通過上述兩種辦法,生成最終的顧及曲率自適應鄰域vc。
曲率閾值通過k-means方法得到,因此要將點云數據劃分為兩個聚類,初始化聚類中心為點云中的最大曲率和最小曲率值。設兩個聚類的中心點曲率值為cur1和cur2(cur2>cur1),ct計算如下:

從圖2(e)中可以看到,在立面和地面等規則分布區域的點云數據通常有較大的點云鄰域尺寸,而相對散亂分布的區域,其鄰域尺寸相對較小。
2.2 特征提取
因為部分公開數據集點云數據只包含點云的空間位置特征,所以本文只選用點云數據的幾何特征。點云特征可以表示為三維點所在局部表面的結構信息,主要通過計算局部鄰域內點集的空間分布得到。本文方法通過點云曲率增強了點云單點特征的可分離性。點云特征主要包括點云立面度量V、歸一化高差Dz以及基于特征值的特征Lλ、Pλ、Sλ和Cλ。
基于點云法線信息,可以得到點云的立面度特征:

式中:V表示點云局部平面與水平面之間的角度;nz是點云法向量的第3個分量。
歸一化高差Dz,計算如下:

式中:Dz主要表示鄰域內點集的高差分布情況;dz為點云鄰域內的高差;zmax和zmin為鄰域內點云最大值最小值。式(6)中hmax和hmin分別代表點云中的最大高度和最小高度。
特征值特診計算如下:

式中:Lλ、Pλ和Sλ的和為1,分別代表點云鄰域內的線性度、平面度以及離散度。
2.3 點云分類
本文點云分類使用隨機森林(Random Forest,RF)方法,采用200棵樹,樹的高度為,其中d為分類特征的緯度。
3 實驗結果
3.1 數據介紹
為評估本文方法的有效性,使用Oakland 3D Point Cloud Dataset進行點云分類,并將數據手動標記為植被、電線、電線桿/樹干、地面和立面5類。
3.2 實驗內容
實驗中,考慮點云曲率閾值的影像,并驗證基于k-means的方法估算曲率閾值的有效性,同時比較基于k-最小熵的自適應鄰域vk、基于r-最小熵的自適應鄰域vr和顧及曲率自適應鄰域vc這3種不同的自適應鄰域的估算方法。
3.3 結果與討論
實驗結果評價指標采用分類結果的召回率(Recall)、分類結果的正確率(Precision)、召回率和正確率的平均值(F1-score)以及代表分類結果的整體正確率(Overall Accuracy)。由于測試數據是非均衡數據集,整體正確率容易受點云數據中占比較大的類別影響,在實驗中使用召回率和正確率以及平均值來評價不同類別的分類結果。
實驗使用半徑r=1 m來估算Oakland Point Cloud的曲率信息,選取閾值ct=0.03將點云數據分為規則和非規則區域。
通過k-means方法得到曲率閾值,初始聚類中心為0和1/3,迭代17次后達到穩定狀態。各類別點云數據在規則區域和非規則區域的分布情況如表1所示。
從表1可以得到,90%的植被點和地面點都被有效區分開。為了評估曲率閾值的有效性,實驗從區間ct∈[0.5,2.0]按照Δc=0.005的步長實驗得到整體精度,如圖4所示。當ct=0.03時,達到最高精度96.1%,驗證了k-means方法選取曲率閾值的有效性。

圖4 不同曲率閾值下的整體正確率

表1 通過ct=0.03劃分的規則區域與非規則區域類別分布情況
由于自適應鄰域估算方法vc綜合了vk和vr的優點,對比這3種方法的結果如表2所示。從表2可以看到,自適應鄰域估算方法顯著提高了各個類別的3項指標結果。通過將點云數據劃分為規則與非規則區域,可以充分挖掘vk和vr的潛力。

表2 評價指標比較 (單位:%)
4 結語
本文提出了一種基于顧及曲率自適應鄰域的點云單點分類方法。基于Oakland數據集的實驗表明,該方法有效提取了點云自適應鄰域信息,并增強了點云單點特征的魯棒性和可分性。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
Coco薇(2017年11期)2018-01-03 20:59:57
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
