分布式云計算架構在區域醫療大數據分析中的優化研究
2021-08-24 01:46:48顏冰冰
智慧健康 2021年19期
關鍵詞:優化
顏冰冰
(蘇州市立醫院北區 信息科,江蘇 蘇州 215000)
0 引言
在醫療信息化不斷深入的背景之下,原本較為單一的數據信息也逐步變得更為多元化,這也給相關技術人員的處理利用提出了更高的要求,因此做好區域醫療數據信息的整合工作就顯得尤為重要。這一舉措不單單能夠有效推動醫療數據更為標準化與規范化,也能夠實現單一數據的有機融合以及從多個維度來進行分析匯總,進而為相關工作提供數據上的支持。
1 分布式云計算在醫療大數據分析中的架構
1.1 整合架構的設計
分布式云計算整體架構如圖1所示。
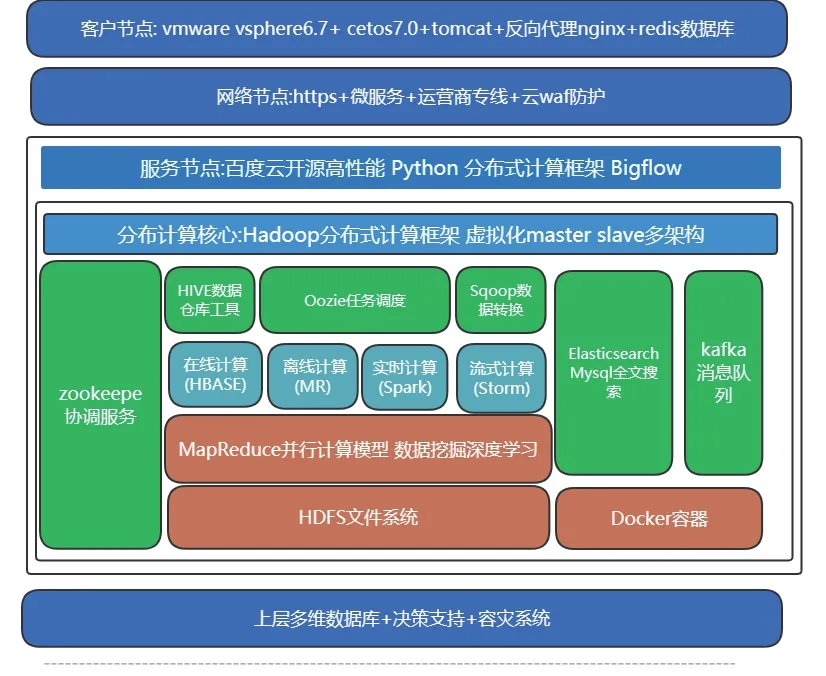
圖1 整體架構設計示意圖
客戶節點包含了主流配置的兩臺物理服務器,并對其進行了內存容量的提升,醫療終端節點中的數據量分別由redis數據庫、Tomcat服務、Nginx反向代理服務進行儲存或利用,被架設于邊界防火墻之中,所使用的帶寬都不低于100M。每個醫療終端節點都和百度云分布式平臺中的服務節點相連接,不同節點之間能夠智能協同,且每個節點所采取的代碼相同,能夠執行在不同的引擎之中[1]。通過這一方式,無需明確Bigflow的實際計算與運行部位,只需要按照單機程序的編寫來獲取獨特的邏輯,就會讓Bigflow將這些計算分發到相應的執行引擎之上執行。Bigflow的目標是為了使分布式程序更簡單,高效,維護更容易,遷移成本更小,進而實現分布式從架構到代碼的環節盡可能精簡的目的。在每個服務節點之間會按照線路建議申請電信運營商級別的CN2線路,以此來保障網絡性能高速且穩定,同時實現最短最優通訊,具體如圖2所示。
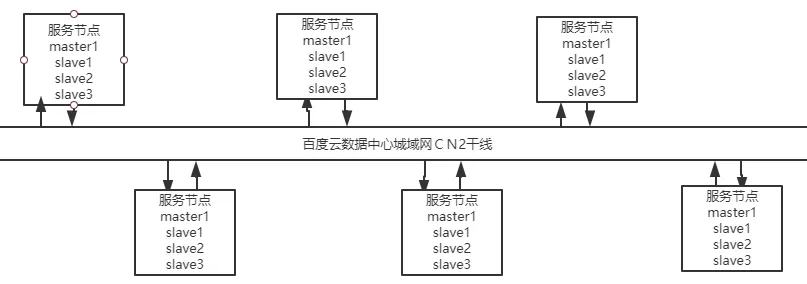
圖2 百度云數據中心城域網CN2干線
分布式計算核心節點由master和多個slave虛擬化服務器單元組成,單元操作系統Cetos7.0.Hadoop+HBase+Spark+Hive為主要組件環境搭建,并由keepalived組件協調各個核心節點做主備切換及負載均衡調優,其中最主要計算組件單元為MapReduce,能夠分布式并行并設計出計算編程模型。
1.2 分布式日志審計系統
分布式日志審計系統主要是為了讓醫療大數據在處理各類信息時能夠更為順暢,通過該系統的應用,可以實現日志分析與處理這一根本目的。分布式日志主要包含了Web應用訪問日志、系統日志等,可以有效對日志中所存在的攻擊行為進行精準定位并分類,這樣一來安全管理人員以及運維工作人員就能夠收獲到加固應用及事后追溯的關鍵依據。在進行分析時會出現數量眾多的日志,醫療云計算就會將其儲存至相應的服務器之中,并為其添加一定的權限,只有已經授權的用戶才能夠進行訪問,有效防止隱私數據泄露這類現象的出現。分布式日志審計系統主要包含了采集層、計算層、匯聚層、數據可視化以及數據存儲層,日志的采集與分類具體流程如下:通過syslog來分布式收集海量日志,并將其傳輸到flume-NG層,以此來統一分發日志[2]。當flume采集系統成功采集數據信息之后,就會將其匯聚到kafka層,并對其進行隊列化處理,讓日志數據信息在傳輸的過程之中更為穩定。接著利用分布式計算集群strom來全面分析與處理日志,定位存在著跨站校本(XSS)、暴力破解登錄、sql注入、目錄遍歷這類攻擊行為的日志,并統計、儲存、預警、可視化結果。利用RESTful API來部署syslog,從而快速下載配置文件,為各類服務的提供奠定基礎。通過SSL/TLS協議來完成對數據信息的加密,以此來確保數據信息具備較強的機密性以及完整性。
1.3 分布式入侵檢測
入侵檢測主要包含了主機層入侵檢測(HIDS)、物理層入侵檢測以及網絡層入侵檢測(NIDS)。在傳統設備之中,要想完成對IDS的部署,必須依賴交換機所提供的鏡像流量,如若用戶數量較多,那么就要保證鏡像流量分屬于不同的端口。在醫療大數據云計算之中,能夠通過各類軟件的應用來上移控制平面,將安全策略自動派發至子系統,通過SDN技術來完成流量調度,利用SDN控制器來將FLOW_MOD指令下發給Open vSwitch這類網絡設備,這樣一來就能夠有效控制匹配策略的相關流量[3]。而要想在私有性較高的云計算之中完成HIDS,就必須部署agent來全方位監控云主機,有效識別、記錄并預警主機用戶的可疑行為、基線安全以及系統文件的完整性。
1.4 分布式應用防火墻
通過反向搭建這一手段能夠有效部署分布式應用防火墻,而要想部署反向代理vWAF,主要采取了以下幾種方式:第一,利用SDN控制器來將FLOW_MOD指令下發,并把Web服務器的HTTP在虛擬網關之中完成與交換機端口的流量定向,這樣一來就能夠將vWAF作為關鍵端口。因為一般是將Web應用服務器地址作為HTTP流量目的IP,但反向代理vWAF并不會對這類流量進行處理,所以必須要對目的地址進行重新定向,利用iptables來轉發相關流量,這樣才能夠讓分布式應用防火墻的作用得以充分的發揮[4]。第二,利用nginx來反向代理分布式應用,讓反向代理服務器能夠收獲相應的流量,這樣一來就能夠實現上佳的安全防護效果。Web應用會將nginx作為對外發布的主要途徑,通過在nginx層部署防護引擎和安全防護規則,可采用Modsecurity作為vWAF的防護引擎,并部署OWASP開源防護規則,這樣的部署方式能夠將nginx層的應用訪問日志通過agent傳輸至分布式日志審計系統中對日志進行分析[5]。
1.5 身份認證
Keystone作為openstack中的安全認證模塊,通過API實現身份認證、服務規則和服務令牌等功能。在f版本之前,openstack只能依賴UUID生成令牌ID,生成的令牌保存在Keystone的后臺數據庫中,并發布到客戶端。在客戶機擁有ID之后,Keystone將驗證請求的合法性。這種方式可能導致請求并發,從而使Keystone成為性能的瓶頸[6]。在f版本之后,在密鑰石中引入了PKI機制。通過將CA的公鑰證書和用戶簽名的公鑰證書存儲在服務器上,可以對令牌進行本地驗證,可以有效解決密鑰問題,同時只要用戶不丟失私鑰,其他用戶就無法竊取和冒充合法用戶,大大提高了系統的安全性openstack的整體安全性。為了在醫學云中實現AAA認證,我們可以使用輕量級目錄訪問協議(LDAP協議)結合Keystone集成,通過Keystone的LDAP身份驅動程序使用安裝的LDAP服務器。Keystone可以從第三方LDAP服務器獲取統一管理用戶,完成open stack的操作。Keystone與tenant、US-Er、role和其他概念兼容。通過LDAP服務對賬戶進行驗證,實現企業和組織內部的統一認證[7]。
2 分布式云計算架構優化方式
結合上文可知,要想對分布式云計算架構進行優化,最為關鍵的便是改善MapReduce組件,具體流程如圖3所示。
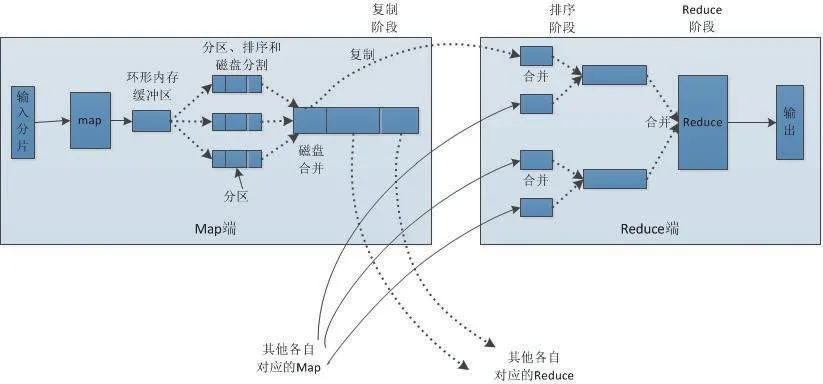
圖3 MapReduce組件優化流程
具體而言,Mapeduce組件優化主要包含了數據輸入問題、Map階段、Reduce階段、ID傳輸問題以及數據傾斜問題這幾個環節,其中數據輸入問題主要是進行小文件的合并,并讓MAP任務速度得以加快,具體做法是將Combine Text ImputFornat作為主要輸入;Map階段主要是對Spill的次數進行減少,以此來實現磁盤IO降低的目的,具體做法是調整io.sort.factor的參數,并讓Merge的文件數目得以增大;Reduce階段主要是適量設定Map與Reduce的數值,具體做法是讓Map與Reduce能夠共存,并對slovstart.completedmaps的參數進行調整;IO傳輸問題主要是為了完成smappy與LZO壓縮編碼器的安裝,具體做法是使用SequenceFlie這類二進制文件;數據傾斜問題主要是為了實現抽樣和范圍分區,具體做法是結合實際情況來自定義分區[8]。
在完成優化之后,計算機的性能也出現了一定的變化,主要體現在數據頻率傾斜在某一個區域的數據量要遠遠大于其他區域,而數據大小傾斜在某一個區域的大小遠遠大于平均值[9]。
3 優化結果測試分析
針對優化后的分布式云計算架構主要是對其進行壓力測試,所使用的軟件為http_load為輕量級高效測試工具,以下為操作系統安裝軟件:
#tar zxvf http_load-18mar2018.tar.gz
#cd http_load-18mar2018
#make &&make install
測試用法命令為:
http_load-p 并發進程數-s時間URL文件
[root@localhost http-load]# http_loadp30-s10 url.txt
21 fetches,30 max parallel,907207 bytes,in 10.0001 seconds
43200.3 mean bytes/connection
2.09998 fetches/sec,90720 bytes/sec
msecs/connect:15.2955mean,17.253max,13.701min
msecs/first-response:968.356mean,3807.22max,42.817min
HTTP response codes:
code 200——21
從中能夠看出測試中共進行了864次請求,最大的并發進程數是921,總傳輸58647207bytes,運行22.0001s。平均每次請求傳輸數據量863210.3,實際就等于總傳輸/請求次數,每秒響應請求數為12.09998,每秒傳遞數據為270720,連接的平均時間為1.2955ms,最大的響應時間為17.253ms,最小的響應時間為19.701ms,響應的平均時間為968.356ms,最大的響應時間為3807.22ms,最小的響應時間49.817ms,最后服務器會將各類狀態碼數量正確返回,此處全部是200正常返回(服務器撐不住時會有502返回)[10]。
4 結語
綜上所述,分布式云計算架構在區域醫療大數據分析中有著至關重要的作用,不但能夠提升分析質量及效率,還能夠有效保障分析結果的準確性。通過以上各流程調試以及優化完成分布式計算應用平臺的建設,旨在為醫療大數據技術的普及與推廣提供理論上的支持,進而促進醫療大數據在不斷擴展和復雜的環境中得以更深的應用和改進。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
