面向深度學習的彈載圖像處理異構加速現狀分析
2021-08-23 02:36:12陳棟田宗浩
航空兵器 2021年3期
關鍵詞:深度學習
陳棟 田宗浩

摘 要: 本文分析了深度學習算法向工程應用轉化存在的問題,結合陸軍智能彈藥的特點和發展趨勢,分別從深度學習模型壓縮、量化,硬件平臺加速設計以及異構加速框架設計等方面進行研究,提出了面向深度學習的彈載圖像處理異構加速體系,實現從算法開發到硬件異構移植的流程化設計。隨后,利用DeePhi Tech的異構加速框架DNNDK對Yolo v3模型進行壓縮、量化,權重壓縮率90%以上,模型參數壓縮率80%以上,實現了Yolo v3的輕量化設計。在DPU硬件加速架構的基礎上,實現算法向彈載嵌入式平臺的移植,其功耗和識別檢測效率滿足彈載圖像處理的要求。
關鍵詞:彈載圖像;深度學習;FPGA;脈動陣列;Winograd卷積
中圖分類號:TJ760; TP18? 文獻標識碼: A? 文章編號:1673-5048(2021)03-0010-08
0 引? 言
萬物互聯時代的到來為部隊裝備智能化建設帶來了新的機遇,信息和微電子等前沿技術在軍事領域的廣泛應用催生出大批精良的新式裝備,使得傳統的作戰理念發生翻天覆地的變化。對炮兵來說,彈藥的智能化水平主要體現在目標自主識別、跟蹤及毀傷,完全依靠彈上的控制系統獨立完成作戰任務,并且命中精度和抗干擾能力更強。目前,國內外對精確制導彈藥的研究主要集中在衛星、激光、雷達以及圖像等幾種模式。其中,衛星制導精度依賴于目標的定位精度,激光制導需要前沿觀察所在彈丸工作末期給予激光指引,與雷達制導同屬被動制導,易于被敵發現,而圖像制導利用圖像傳感器采集目標反射或輻射的可見光信息形成圖像,抗干擾能力強,不易被目標發現,通過充分挖掘圖像中的信息實現目標的自主識別、定位和毀傷[1]。
隨著深度學習(Deep Learning, DL)算法被應用到社會的各行各業,卷積神經網絡[2](Convolution Neural Network, CNN)突破傳統人工挖掘圖像特征導致目標識別準確率低的瓶頸,通過多隱層的網絡結構、良好的數據集訓練、深度挖掘圖像的特征信息,大幅度提升了目標識別的準確率。隨后,各種基于CNN的改進模型被不斷提出,在提升目標識別準確率的同時網絡層次逐步加深,這也對計算平臺的計算、存儲以及功耗提出了更高要求。彈丸內部空間小、作用時間短,嵌入式硬件平臺的處理速度成為制約深度學習算法向彈載平臺部署的關鍵因素。為此,需要在深度學習算法和硬件異構平臺加速兩個方面進行研究,滿足彈載圖像目標檢測實時性的要求,推動圖像制導彈藥的智能化發展。
1 智能化圖像制導彈藥關鍵技術分析
1.1 圖像制導彈藥智能化需求分析
深度學習未得到廣泛應用之前,圖像制導彈藥主要利用手工特征提取、圖像模板匹配等方法對目標進行識別檢測,依賴人的先驗知識,不能從本質上刻畫圖像的特征,識別準確率低,檢測速度慢;而未來作戰樣式復雜多變,非接觸、突發性戰爭成為主要特點,戰爭爆發后指揮員可能并不明確敵目標的主要特征,很難做到制導彈藥的準確識別和精確打擊,傳統意義上的圖像制導彈藥會更依賴于人的主觀判斷識別目標,在瞬息萬變的戰場環境下可能錯失最佳攻擊時間。深度學習模型具有強大的表征和建模能力,通過監督或非監督的學習方式進行訓練,逐層、自動地學習目標的特征表示,通過將底層特征抽象形成高層特征,實現待檢測目標本質的描述。利用前期學習到的各種目標特征信息,彈載處理器對采集到的圖像進行深度挖掘、推理與融合,判斷目標類別、
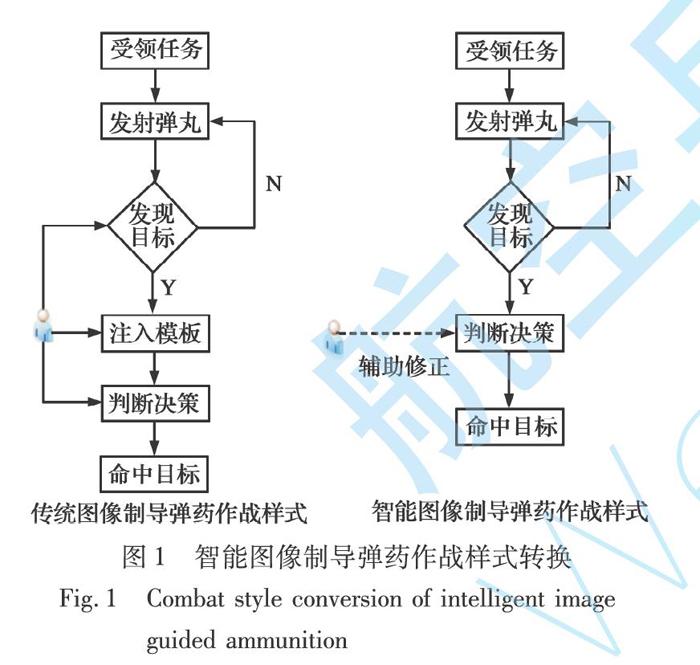
位置,自主控制彈丸命中目標,實現“感知-判斷-決策-行動”的新型作戰樣式,自主完成偵察與打擊任務,如圖1所示。
由圖1看出,傳統圖像制導彈藥將采集的圖像信息回傳至地面站進行處理,嚴重依賴于人的先驗知識,并且對未知、不確定目標往往做不到首發命中。此外,彈丸作用時間短,任務不可逆,數據量龐大的圖像信息回傳至地面站處理過程中存在較大時延,滿足不了系統實時性要求;而智能圖像制導彈藥極大釋放人的作用,利用學習到的目標特征自主完成識別打擊任務,僅需要指揮員對彈藥決策信息進行輔助修正,降低誤判率。由于整個處理過程在彈載平臺自主實現,降低了數據傳輸對帶寬的壓力,大大降低系統延遲,增強制導彈藥的響應時間。
1.2 智能圖像制導彈藥目標檢測算法分析
彈體在空中運動復雜,彈載圖像受彈體姿態的影響產生各種變化,例如圖像旋轉變化、圖像尺度變化以及戰場環境因素帶來的目標遮擋等非本質性變化,這些影響因素給圖像特征提取及目標檢測帶來嚴峻的挑戰。CNN的最大特點為權值共享和局部連接,相比淺層網絡和傳統手工特征提取算法能更簡潔緊湊地提取特征,具備對特征旋轉、平移、縮放等畸變的不變性。隨著深度學習技術在圖像領域深入研究,出現越來越多的新理論、新方法,基于候選區域的方法和基于回歸思想的端到端的方法相互借鑒[3-4],不斷融合,取得了很好的效果。
基于候選區域的目標檢測算法(兩階段法)通過Selective Search[5]和Edge Boxes[6]等算法提取圖像中的候選區域(Region proposal),在此基礎上對候選區域進行分類和位置校準。例如R-CNN算法采用Selective Search方法對圖像進行分割劃分、整合,得到不同大小的候選區域,利用CNN在候選區域上進行特征提取,顯著提升了目標檢測的準確率。由于R-CNN算法對輸入圖像大小要求嚴格,圖像縮放操作損失部分有用信息,并且其在提取候選區域時存在大量的重復運算,嚴重影響算法的檢測速度和效果。為解決R-CNN對輸入圖像尺寸敏感問題,基于空間金字塔池化層(Spatial Pyramid Pooling, SPP)的SPP-Net算法[7]以及Fast R-CNN算法[8]被提出,利用不同的池化窗口將圖像映射到同一維度,保存完整的圖像信息,檢測精度得到提升。但對于候選區域的操作仍然消耗大量的時間,算法的實時性問題仍未解決。Faster R-CNN算法[9]利用一個全卷積網絡RPN(Region Proposal Network)提取圖像特征,將候選區域從2 000多個降到300個,提升了算法檢測速度。但其網絡中的多次下采樣操作使圖像紋理細節特征損失較多,對小目標的識別檢測準確率較低。為此,一些基于高層特征和低層特征融合的算法被用于提升小目標檢測精度,如超特征網絡HyperNet(Hyper Feature Net)[10]、多尺度特征金字塔網絡FPN(Feature Pyramid Networks)[11]等,在降低候選區域數量的同時保證對小目標的檢測精度。雖然基于候選區域的目標檢測算法精度和速度不斷提升,但是由于RPN結構的存在,其檢測速度從本質上受到限制,難以滿足彈載平臺對于檢測算法實時性的要求。
基于回歸的檢測算法(單階段法)不需要產生候選區域,即給定輸入圖像,直接在圖像的多個位置上回歸出這個位置的目標邊框以及目標類別,在保證一定準確率的前提下,速度得到極大提升。例如文獻[12]提出的Yolo算法,可以通過對圖像的直接檢測確定目標的邊界框和類別,檢測速度提高到45 f/s,但其對緊鄰目標和小目標的檢測效果不佳。近年來,Yolo系列算法通過BN操作、殘差網絡特征融合等算法改進,使得模型檢測精度和速度大幅度提升,并且對小目標的適應性增強,模型的規模也在不斷減小,如Yolo v2/v3[13],Tiny-Yolo,SlimYolo[14]等。同樣,SSD算法及其改進模型[15-16]在Faster R-CNN算法anchor機制下,針對小目標檢測進行了拓展研究,提高了模型的檢測精度和速度,如DSSD,DSOD,RSSD等。結合彈載圖像的特點以及深度學習在目標檢測中的發展趨勢,基于Yolo系列的算法在衛星[17]、無人機以及彈載平臺[18-19]目標識別檢測中得到成功應用。為此,本文擬在彈載平臺部署單階段目標檢測算法,實現目標的快速識別和定位,為決策和人工輔助修正過程留出充足的響應時間。
隨著網絡結構的不斷加深和改進,模型的檢測精度不斷提高,但是隨之帶來的是龐大的數據量問題,尤其是訓練得到的參數信息會隨著網絡的深度呈指數增加,這給在邊緣部署深度學習算法帶來了嚴峻挑戰。對于嵌入式設備而言,存儲空間、計算資源、能耗以及體積限制了理論模型向工程實現的轉換,輕量化模型設計成為解決此問題的重要途徑。早在1989年深度學習模型還沒有被廣泛應用之前,LeCun教授就在文獻[20]中提出剔除神經網絡中不重要參數信息思想,達到壓縮模型尺寸的作用,當前很多深度學習模型剪枝算法都是基于文獻[20]提出的OBD方法的改進。深度學習模型壓縮技術在于減少參數冗余而不會損失較大的預測精度,關鍵技術難點為壓縮量化指標的確定,其研究主要集中在精細化的模型設計、量化、Low-Rank分解、模型/通道剪枝以及遷移學習等方面,相關研究均在特定模型中取得較好的壓縮效果,如圖2所示。
模型精細化設計將卷積核分解成多個小卷積核組合,優化模型結構的同時大大減少網絡參數。量化是通過降低權重參數的比特位數進行模型壓縮,例如將32 bit浮點權重轉換為8 bit整型以及權重二值化、三值化等,在保證模型精度的同時,極大提高了計算效率,降低了內存占用率。模型訓練出的權重矩陣中很多信息是冗余的,Low-Rank分解是用若干小矩陣表達出大矩陣包含的信息,并且不損失模型精度,大大降低模型的計算復雜度和內存開銷。模型剪枝分為結構化、非結構化以及中間隱層剪枝,其核心思想是通過判定指標確定模型節點、通道以及參數的重要程度,剔除對模型精度影響不大的部分,并通過再訓練對模型進行微調。根據剪枝再訓練過程又可分為永久剪枝和動態剪枝,其中永久剪枝完全依賴于訓練模型的權重信息,裁剪完成后不再參與訓練過程。但是對于網絡模型來說,某些權重信息是對后面權重參數的重要補充,永久裁剪后極大降低模型的精度,動態裁剪就是將這些誤裁剪的節點重新恢復回來,降低重要參數被裁剪的風險。遷移學習來源于Teacher-Student方法,在結構復雜、泛化性好、精度高的Teacher模型基礎上“引導”結構簡單、參數量少的Student模型訓練,得到和Teacher模型精度相近的結果。
1.3 智能圖像制導彈藥硬件異構加速研究
對于彈載嵌入式平臺而言,硬件是支撐,軟件是靈魂,結構復雜的深度學習算法離不開硬件平臺強勁的計算能力。考慮到彈載應用環境、作戰任務的特殊性,智能圖像制導彈藥的軟硬件系統要滿足實時性、低功耗以及體積小等各方面要求。
1.3.1 彈載硬件處理器分析
彈載硬件處理器是智能圖像制導彈藥的控制中心,完成圖像采集、目標檢測以及制導控制等功能。國內外鮮有將人工智能技術應用到彈載平臺,其根本原因在于高性能處理器和彈載應用環境的適配問題,傳統制導彈藥大多利用CPU和DSP等處理器完成簡單的數據采集、控制等功能,目標檢測等復雜算法在PC端實現,存在較高時延,因此高性能硬件處理器成為制約彈藥智能化發展的首要因素。
目前,面向AI的高性能硬件處理器可以分為CPU,GPU,FPGA,ASIC以及由其組成的多核結構等。其中,CPU的順序執行架構決定其在大規模數值計算中存在較大時延,不能滿足彈載任務對實時性的要求;GPU包含大量的計算核心,很適合加速并行程度很高的深度學習算法,但GPU的功耗較大,空間狹小的彈載平臺不可能提供足夠的能耗供GPU工作;與通用處理器CPU和GPU相比,專用處理器ASIC為特定任務定制化的芯片,能獲得高效的處理速度和較低的功耗。例如Google的TPU(Tensor Processing Unit, 張量處理器)[39]、國內寒武紀芯片[40]、IBM的TrueNorth以及華為2018年推出的達芬奇架構的昇騰(Ascend 310/910)AI處理器等[41]。由于ASIC針對特定任務量身定做,靈活性差,并且缺少統一的軟硬件開發平臺,算法移植難度大,無疑提高了智能彈藥研發的周期和門檻。現場可編程門陣列(Field Programmable Gate Array, FPGA)是一種計算密集型器件,能夠支持各種數據類型精度,例如FP32,INT8及二進制等,芯片上提供許多專用的算術計算單元、邏輯資源模塊、片內的存儲資源、外圍I/O接口等,其可編程特性可以方便地重新配置數據路徑,無論是大規模并行、適度并行、流水線連續或者混合形式,都能獲得較好的計算能力和效率,更容易滿足彈載平臺計算、效率、時延和靈活性需求。另外,隨著深度學習模型計算復雜度的提高,單一處理器的計算能力遠不能滿足需求。伴隨著各硬件處理器制造工藝水平的發展,多核化、高效能、混合異構等成為高性能處理器的發展趨勢,充分利用各自的性能優勢進行數據處理,可以更好地提升系統的算力。
考慮到彈載任務的特殊性以及對功耗和硬件體積等限制,基于CPU+FPGA的異構體系逐漸成為智能彈藥實現深度學習推理過程的主選方案。例如文獻[42]研究了基于FPGA的彈載圖像數字采集系統,大大降低圖像采集時延;文獻[43]將SIFT跟蹤算法移植到FPGA平臺,實現高于25 f/s的跟蹤速度;文獻[44]實現了多種深度學習模型在Zynq-7000系列、Zynq UltraScale+MpSoC系列等硬件平臺的移植工作,為彈載平臺部署提供了理論基礎。
在FPGA上實現深度學習算法加速,主要考慮計算模塊、控制模塊以及數據傳輸模塊的設計,其中,計算模塊主要是對卷積運算的硬件加速,是整個硬件加速設計的核心環節;控制模塊是整個加速單元的控制系統,負責系統參數同步、初始化以及啟動各子模塊;數據傳輸模塊主要負責片上緩存和片外內存間的數據調度。各模塊之間協調工作,實現各個功能的流水線設計,高效利用硬件資源,滿足彈載FPGA異構平臺對實時性和功耗的要求。
1.3.2 卷積計算硬件加速
在深度學習模型中,卷積計算量對模型的性能至關重要,對卷積運算進行優化可以從根源上降低模型的計算復雜度,其計算復雜度表示為[45]
O[n, k,? p, q]=∑C-1c=0∑R-1r=0∑S-1s=0F[k, c, r, s]·
D0[n, c, g(p, u, R, r, pad_h),
g(q, v, S, s, pad_w)](1)
式中:F為卷積核;D為輸入數據;R和S為卷積核的行列;u, v為卷積核在行列方向的滑動步長;pad_h和pad_w為輸入數據擴張大小,并且n∈[0, N),k∈[0, K),p∈[0, P),q∈[0, Q),N為每個batch的輸入圖像個數,K為輸出特征圖的個數,P和Q為輸出特征圖的行列,與輸入圖像的行列、滑動步長以及擴張大小有關。
目前,主流的深度學習硬件加速單元通常采用向量內積[46]、二維陣列及Winograd卷積[47]方式實現卷積神經網絡中的矩陣和向量操作。向量內積是將輸入和權重參數轉換成矩陣乘法形式,利用循環展開和循環分片實現數據的并行流水線設計,其計算復雜度為O(n3),數據映射結構如圖3所示。
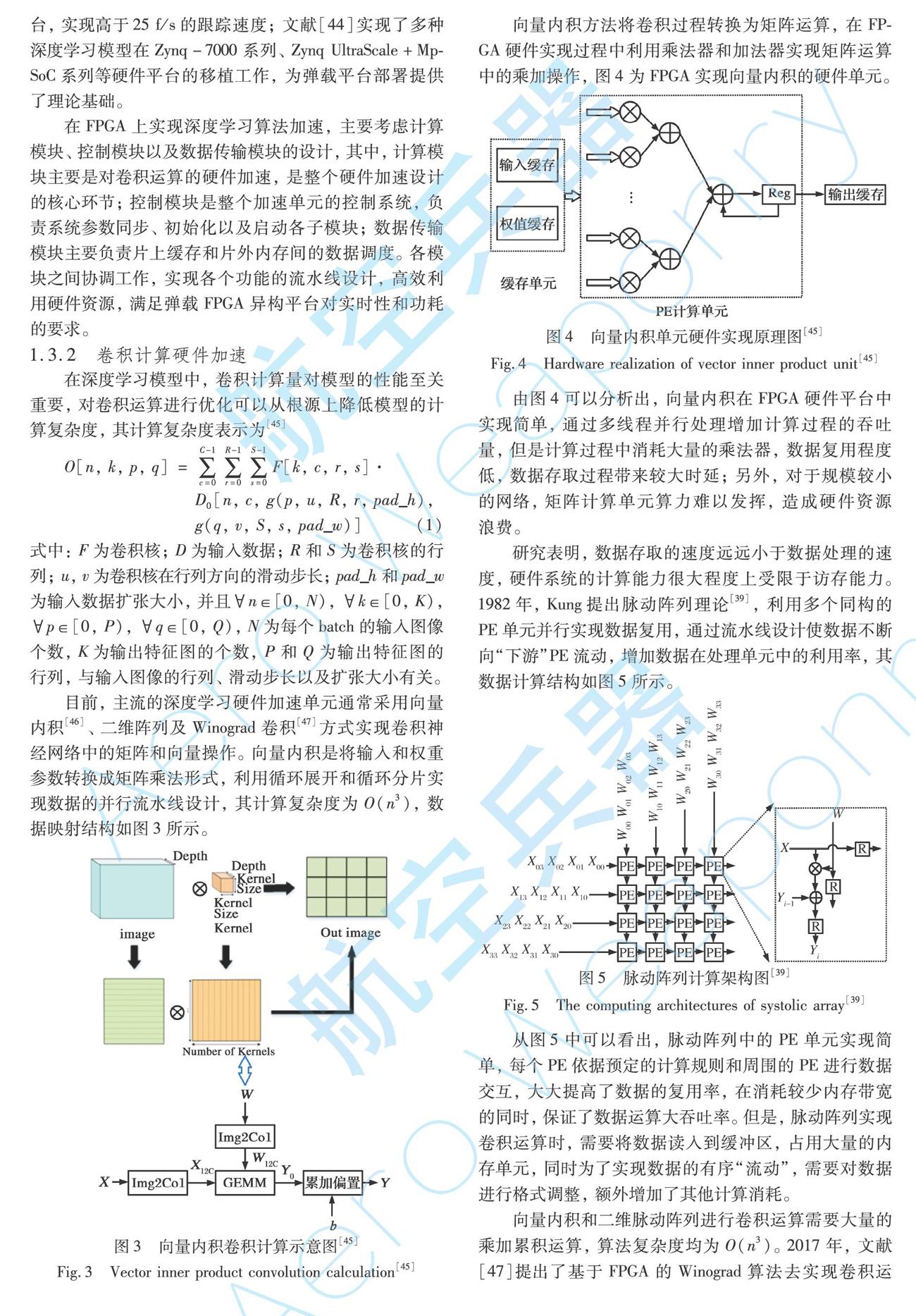
向量內積方法將卷積過程轉換為矩陣運算,在FPGA硬件實現過程中利用乘法器和加法器實現矩陣運算中的乘加操作,圖4為FPGA實現向量內積的硬件單元。
由圖4可以分析出,向量內積在FPGA硬件平臺中實現簡單,通過多線程并行處理增加計算過程的吞吐量,但是計算過程中消耗大量的乘法器,數據復用程度低,數據存取過程帶來較大時延;另外,對于規模較小的網絡,矩陣計算單元算力難以發揮,造成硬件資源浪費。
研究表明,數據存取的速度遠遠小于數據處理的速度,硬件系統的計算能力很大程度上受限于訪存能力。1982年,Kung提出脈動陣列理論[39],利用多個同構的PE單元并行實現數據復用,通過流水線設計使數據不斷向“下游”PE流動,增加數據在處理單元中的利用率,其數據計算結構如圖5所示。
從圖5中可以看出,脈動陣列中的PE單元實現簡單,每個PE依據預定的計算規則和周圍的PE進行數據交互,大大提高了數據的復用率,在消耗較少內存帶寬的同時,保證了數據運算大吞吐率。但是,脈動陣列實現卷積運算時,需要將數據讀入到緩沖區,占用大量的內存單元,同時為了實現數據的有序“流動”,需要對數據進行格式調整,額外增加了其他計算消耗。
向量內積和二維脈動陣列進行卷積運算需要大量的乘加累積運算,算法復雜度均為O(n3)。2017年,文獻[47]提出了基于FPGA的Winograd算法去實現卷積運算,利用加法器代替乘法器減少大量卷積計算中的乘法操作,降低運算復雜度,提高運算速度。對于一維和二維Winograd卷積計算,文獻[47]給出了相應的推理證明,如下所示:
Y=AT[(Gg)⊙(BTd)](2)
Y=AT[[GgGT]⊙[BTdB]]A(3)
式(2)和式(3)分別為一維、二維的Winograd卷積計算。其中:g為卷積核;d為輸入信號;G為卷積核矩陣;BT為輸入轉置矩陣;AT為輸出轉置矩陣;⊙為點乘運算。計算過程如圖6所示。
由圖6可以看出,Winograd卷積計算充分利用了向量內積和脈動陣列兩者的優勢,并利用加法器代替傳統矩陣計算中大量的乘法操作,實現快速卷積計算,其一維和二維的計算復雜度分別可以表示為O(n)和O(n2),大大降低算法的復雜度。
通過分析可知,任何一個卷積硬件加速架構都有各自的優勢,當硬件平臺資源充足時,可以采用易于實現、吞吐量大的加速方案,而當資源不足時,要合理劃分硬件資源對卷積進行優化設計,實現硬件資源的高效利用。
1.3.3 智能彈藥異構加速體系設計
由于彈載嵌入式平臺加速深度學習模型主要考慮推理過程,因此,可以在線下利用GPU訓練搭建好的網絡模型,獲得最優的權重參數,再通過模型量化、剪枝等方法實現網絡的輕量化設計,最后結合硬件平臺資源分布,合理設計硬件加速單元,實現深度學習模型向嵌入式硬件平臺的高效移植,其設計流程如圖7所示。
其中,模型輕量化設計和硬件加速單元設計是智能彈藥異構設計的關鍵環節。結合深度學習模型卷積層、池化層、激活函數以及全連接層的特征,設計標準化的壓縮模型,以適應針對不同彈載任務的深度學習算法。此外,充分分析各處理器在執行深度學習算法中卷積運算、數據共享、指令控制以及任務調度中的性能,設定優先級,讓最合適的單元執行相關任務,使得在硬件資源有限條件下獲得高效的加速性能。
2 基于DPU的Yolo v3異構加速設計
文中1.1節對智能圖像制導彈藥任務的特殊性、不可逆性等特點進行了詳細分析,為在戰爭中掌握主動權,基于深度學習的識別檢測算法既要準確率高,又要速度快。通過對當前目標檢測算法性能分析,Yolo v3在檢測速度和識別準確率方面都表現出極佳的性能。為此,本文采用Yolo v3實現戰場目標的識別檢測。
為加快深度學習模型向彈載嵌入式平臺移植,利用深鑒科技的DNNDK(Deep Neural Network Development Kit)編譯器[48]對深度學習模型進行編譯加速。DNNDK面向深度學習異構計算平臺DPU(Deep-Learning Processor Unit)[49],涵蓋卷積神經網絡推理階段的模型壓縮、編譯優化和高效運行時支持等各種功能,為深度學習模型在DPU異構平臺上的應用提供了全棧式編譯環境,如圖8所示。
由圖8可以看出,DNNDK編譯器為線下訓練好的模型提供了針對DPU硬件加速架構的全棧式編譯環境,可以實現深度學習算法性能分析、壓縮以及DPU異構計算等。其中,DECENT工具將訓練好的模型實現高效壓縮,并且不會帶來太大的精度損失;DNNC編譯器將深度學習模型和DPU指令一一映射,實現計算負載和內存訪問的高效結合;N2Cube為深度學習模型在DPU硬件加速平臺實現資源分配、任務調度以及系統驅動等提供了多種輕量級接口函數,以便實現對硬件資源的充分利用。為此,利用DNNDK來實現Yolo v3在嵌入式硬件平臺的移植、實現。
首先,實驗使用Tensorflow框架,在1塊16 GB的Nvidia GTX1080Ti GPU上完成Yolo v3和Tiny-Yolo v3模型的訓練[13],數據集采用公開的無人機目標檢測VisDrone2018-Det[14]數據集和彈載相機采集的實景沙盤圖像。其中,VisDrone2018-Det數據集為無人機俯視視角拍攝的不同光照、環境以及密度條件下的場景圖像,包含行人、汽車、摩托車等10類目標,訓練集圖片6 471張,驗證集圖像548張,測試集圖像1 580張;彈載相機
采集的實景沙盤圖像包含火炮、自行火炮、遠程火箭炮、坦克和步戰車等5類目標,并通過翻轉、旋轉和亮度增強等手段對數據集進行擴充,目標圖像共2 000張,其中訓練集1 600張,驗證集100張,測試集300張。
模型訓練過程中將兩種方式收集的數據集整合,共15類目標,10 599張圖片,輸入圖像大小裁剪為416×416,模型參數設置為:學習率0.001,動量0.9,權重衰減率0.000 5,每批次處理圖像32張,經過不斷迭代訓練后,模型的損失函數基本維持不變,得到訓練好的權重參數。利用測試集對訓練好的Yolo v3和Tiny-Yolo v3模型進行測試,其在Nvidia GTX1080Ti GPU平臺上的檢測幀率、mAP和功耗如表1所示。隨后,在上述模型訓練結果的基礎上,利用DNNDK編譯器對訓練模型的權重參數進行量化、壓縮,并將量化后的模型轉化為可在FPGA上執行的底層文件,選用zcu104硬件平臺[48]實現Yolo v3和Tiny-Yolo v3的目標識別檢測。
上述四個模型分別在兩種數據集測試樣本上的識別檢測結果如圖9所示。
通過表1和圖9的分析發現,深度學習模型經過DNNDK編譯器壓縮、編譯后,參數量和權重大大減少,雖然基于DPU硬件加速后的深度學習模型存在漏檢和檢測位置偏移問題,但是其精度損失微乎其微,并且這些性能損失可以人工輔助修正,而其在FPGA上的低功耗性能為深度學習模型在邊緣設備部署帶來更大的優勢。
3 結 束 語
本文分析了深度學習算法向智能圖像制導彈藥目標識別、檢測和跟蹤等工程實現中存在的突出問題,從深度學習模型壓縮、高性能處理器、卷積硬件加速等方面進行研究,提出了面向深度學習的彈載圖像處理異構體系模型。針對圖像制導彈藥的任務需求,選擇準確、快速的目標識別檢測算法,通過模型輕量化設計減少模型冗余參數,利用合適的卷積加速理論實現深度學習模型在硬件平臺的移植。本文利用深鑒科技提出的DNNDK編譯器,實現了Yolo v3算法在zcu104硬件平臺的移植,模型參數壓縮率80%以上,權重數據壓縮率90%以上,檢測速度滿足彈載平臺實時檢測的要求,為智能圖像制導彈藥工程實現提供了設計參考。
參考文獻:
[1] 錢立志. 電視末制導炮彈武器系統關鍵技術研究[D]. 合肥: 中國科學技術大學, 2006.
Qian Lizhi. Research on the Key Technology of TV Terminal Guided Artillery Weapon System[D]. Hefei:? University of Science and Technology of China, 2006. (in Chinese)
[2] Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks[C]∥Advances in Neural Information Processing Systems, 2012, 25(2):? 1097-1105.
[3] 趙永強, 饒元, 董世鵬, 等. 深度學習目標檢測方法綜述[J]. 中國圖象圖形學報, 2020, 25(4):? 629-654.
Zhao Yongqiang, Rao Yuan, Dong Shipeng, et al. Survey on Deep Learning Object Detection[J]. Journal of Image and Graphics, 2020, 25(4):? 629-654. (in Chinese)
[4] 阮激揚. 基于YOLO的目標檢測算法設計與實現[D]. 北京:? 北京郵電大學, 2019.
Ruan Jiyang. Design and Implementation of Target Detection Algorithm Based on YOLO[D]. Beijing:? Beijing University of Posts and Telecommunications, 2019. (in Chinese)
[5] Uijlings J R R, van de Sande K E A, Gevers T, et al. Selective Search for Object Recognition[J]. International Journal of Compu-ter Vision, 2013, 104(2):? 154-171.
[6] Zitnick C L, Dollár P. Edge Boxes:? Locating Object Proposals from Edges[C]∥Proceedings of the 13th European Conference on Computer Vision, 2014:? 391-405.
[7] He K M, Zhang X Y, Ren S Q, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9):? 1904-1916.
[8] Girshick R. Fast R-CNN[C]∥Proceedings of the 2015 IEEE International Conference on Computer Vision, 2015: 1440-1448.
[9] Ren S Q, He K M, Girshick R, et al. Faster R-CNN:? Towards Real-Time Object Detection with Region Proposal Networks[C]∥ Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015: 91-99.
[10] Shrivastava A, Gupta A, Girshick R. Training Region-Based Object Detectors with Online Hard Example Mining[C]∥ Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 761-769.
[11] Lin T Y, Dollar P, Girshick R, et al. Feature Pyramid Networks for Object Detection[C]∥Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017:? 936-944.
[12] Redmon J, Divvala S, Girshick R, et al. You Only Look Once:? Unified, Real-Time Object Detection[C]∥ Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016:? 779-788.
[13] Redmon J, Farhadi A. YOLOv3:? An Incremental Improvement [EB/OL]. (2018-04-08) [2020-06-01]. https: ∥arxiv. xilesou. top/pdf/1804. 02767. pdf.
[14] Zhang P Y, Zhong Y X, Li X Q, et al. SlimYOLOv3:? Narrower, Faster and Better for Real-Time UAV Applications[EB/OL]. (2019-07-25) [2020-06-01]. https: ∥arxiv. org/ftp/arxiv/papers/1907/1907. 11093. pdf.
[15] Fu C Y, Liu W, Ranga A, et al. DSSD: Deconvolutional Single Shot Detector[EB/OL]. (2017-01-23) [2020-06-01]. https: ∥arxiv. org/pdf/1701. 06659. pdf.
[16] Shen Z Q, Liu Z, Li J G, et al. DSOD: Learning Deeply Supervised Object Detectors from Scratch[C]∥Proceedings of the 2017 IEEE International Conference on Computer Vision, 2017: 1937-1945.
[17] 喻鈞, 康秦瑀, 陳中偉, 等. 基于全卷積神經網絡的遙感圖像海面目標檢測[J]. 彈箭與制導學報, 2020, 35(6):? 24-31.
Yu Jun, Kang Qinyu, Chen Zhongwei, et al. Sea Surface?? Target Detection in Remote Sensing Images Based on Full Convolution Neural Network[J]. Journal of Projectiles, Rockets, Missiles and Guidance, 2020, 35(6):? 24-31. (in Chinese)
[18] 侯凱強, 李俊山, 王雪博, 等. 彈載人工智能目標識別算法的嵌入式實現方法研究[J]. 制導與引信, 2019, 40(3):? 40-45.
Hou Kaiqiang, Li Junshan, Wang Xuebo, et al. Research on Embedded Implementation Method of Missile-Borne Artifical Intelligence Target Recognition Algorithms[J]. Guidance & Fuze, 2019, 40(3):? 40-45. (in Chinese)
[19] 楊傳棟, 劉楨, 馬翰宇, 等. 一種基于改進YOLOv3的彈載圖像多目標檢測方法[J]. 彈箭與制導學報, 2020, 22(6): 1-6.
Yang Chuandong, Liu Zhen, Ma Hanyu, et al. A Multi-Target Detection Method for Missile-Borne Images Based on Improved YOLOv3[J]. Journal of Projectiles, Rockets, Missiles and Guidance, 2020, 22(6): 1-6. (in Chinese)
[20] LeCun Y, Denker J S, Sollar S A. Optimal Brain Damage[C]∥Advances in Neural Information Processing Systems, 1990:? 598–605.
[21] Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet:? AlexNet-Level Accuracy with 50× Fewer Parameters and <0.5 MB Model Size[EB/OL]. (2016-11-04)[2020-06-01]. https: ∥arxiv. org/abs/1602. 07360.
[22] Qin Z, Zhang Z N, Chen X T, et al. FD-MobileNet:? Improved MobileNet with a Fast Downsampling Strategy[C]∥25th IEEE International Conference on Image Processing, 2018:? 1363-1367.
[23] Chollet F. Xception:? Deep Learning with Depthwise Separable Convolutions[EB/OL]. (2017-04-04)[2020-06-01]. https: ∥arxiv. org/abs/1610. 02357.
[24] Wang S J, Cai H R, Bilmes J, et al. Training Compressed Fully-Connected Networks with a Density-Diversity Penalty[J]. International Conference on Learning Representations, 2017:? 1121-1132.
[25] Dettmers T. 8-Bit Approximations for Parallelism in Deep Learning[EB/OL]. (2016-02-19)[2020-06-01]. https: ∥arxiv. org/abs/1511. 04561.
[26] Li F F, Zhang B, Liu B. Ternary Weight Networks[EB/OL]. (2016-11-19)[2020-06-01]. https: ∥arxiv. org/abs/1605. 04711.
[27] Courbariaux M, Hubara I, Soudry D, et al. Binarized Neural Networks:? Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1[EB/OL]. (2016-04-17)[2020-06-01]. https: ∥arxiv. org/abs/1602. 02830.
[28] Lebedev V, Ganin Y, Rakhuba M, et al. Speeding-Up Convolutional Neural Networks Using Fine-Tuned CP-Decomposition[EB/OL]. (2015-04-24)[2020-06-01]. https: ∥arxiv. org/abs/1412. 6553.
[29] Zhang X Y, Zou J H, He K M, et al. Accelerating Very Deep Convolutional Networks for Classification and Detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10):? 1943-1955.
[30] Kim Y D, Park E, Yoo S, et al. Compression of Deep Convolutional Neural Networks for Fast and Low Power Mobile Applications[EB/OL]. (2015-11-20)[2020-06-01]. https: ∥arxiv. org/abs/1511. 06530.
[31] Novikov A, Podoprikhin D, Osokin A, et al. Tensorizing Neural Networks[EB/OL]. (2015-11-20)[2020-06-01]. https:∥arxiv. org/abs/1509. 06569.
[32] Hu H Y, Peng R, Tai Y W, et al. Network Trimming:? A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures[EB/OL]. (2016-07-12)[2020-06-01]. https: ∥arxiv. org/abs/1607. 03250.
[33] Li H, Kadav A, Durdanovic I, et al. Pruning Filters for Efficient ConvNets[EB/OL]. (2017-03-10) [2020-06-01]. https: ∥arxiv. org/abs/1608. 08710.
[34] Molchanov P, Tyree S, Karras T, et al. Pruning Convolutional Neural Networks for Resource Efficient Inference[EB/OL]. (2016-11-19)[2020-06-01]. https: ∥arxiv. org/abs/1611. 06440.
[35] Anwar S, Hwang K, Sung W. Structured Pruning of Deep Convolutional Neural Networks[J]. ACM Journal on Emerging Techno-logies in Computing Systems, 2017, 13(3):? 1-18.
[36] Moya Rueda F, Grzeszick R, Fink G A. Neuron Pruning for Compressing Deep Networks Using Maxout Architectures[EB/OL]. (2017-07-21)[2020-06-01]. https: ∥arxiv. org/abs/1707. 06838.
[37]? Yim J, Joo D, Bae J, et al. A Gift from Knowledge Distillation:? Fast Optimization, Network Minimization and Transfer Learning [C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2017:? 7130-7138.
[38] Hinton G, Vinyals O, Dean J. Distilling the Knowledge in a Neural Network[EB/OL]. (2015-03-09)[2020-06-01]. https: ∥arxiv. org/abs/1503. 02531.
[39]? Jouppi N P, Young C, Patil N, et al. In-Datacenter Performance Analysis of a Tensor Processing Unit[EB/OL]. (2017-04-16)[2020-06-01]. https: ∥arxiv. org/abs/1704. 04760.
[40]? Chen T S, Du Z D, Wang J, et al. DianNao:? A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning[J]. ACM Sigarch Notices, 2014, 49(4): 269-284.
[41] 梁曉峣. 昇騰AI處理器架構與編程:深入理解CANN技術原理及應用[M]. 北京:? 清華大學出版社, 2019.
Liang Xiaoyao. Shengteng AI Processor Architecture and Programming:Deep Understanding the Technology Principle and Application of CANN [M]. Beijing:? Tsinghua University Press, 2019. (in Chinese)
[42] 高陽. 彈載數字圖像采集系統研究[D]. 太原:? 中北大學, 2017.
Gao Yang. Research on Digital Image Acquisition System for Missile[D]. Taiyuan: ?North University of China, 2017. (in Chinese)
[43] 邱曉冬. 基于FPGA的SIFT圖像匹配系統實現與優化[D]. 南京:? 東南大學, 2019.
Qiu Xiaodong. Implementation and Optimization of SIFT Algorithm Based on FPGA [D]. Nanjing:? Southeast University, 2019. (in Chinese)
[44]? XILINX White Paper. Vitis AI Library User Guide [EB/OL]. (2019-10-01)[2020-06-01]. https: ∥www. xilinx. com/support/documentation/ai_inference/v1_6/ug1354-xilinx-ai-sdk. pdf.
[45] Dukhan M. The Indirect Convolution Algorithm[EB/OL]. (2019-07-03)[2020-06-01]. https: ∥arxiv. org/abs/1907. 02129.
[46] Chetlur S, Woolley C, Vandermersch P, et al. CuDNN:? Efficient Primitives for Deep Learning[EB/OL]. (2014-11-18)[2020-06-01]. https: ∥arxiv. org/abs/1410. 0759.
[47] Liang Y, Lu L Q, Xiao Q C, et al. Evaluating Fast Algorithms for Convolutional Neural Networks on FPGAs[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 39(4): 857-870.
[48]? XILINX White Paper. DNNDK User Guide [EB/OL]. (2019-08-13) [2020-06-01]. https: ∥www. xilinx. com/support/documentation/sw_manuals/ai_inference/v1_6/ug1327-dnndk-user-guide. pdf.
[49] XILINX White Paper. Zynq DPU v3.2 Product Guide [EB/OL]. (2020-03-01)[2020-06-01]. https: ∥www. xilinx. com/support/documentation/ip_documentation/dpu/v3_2/pg338-dpu. pdf.
Research on Heterogeneous Acceleration of Deep
Learning Method for Missile-Borne Image Processing
Chen Dong, Tian Zonghao*
(Laboratory of Guidance Control and Information Perception Technology of High Overload Projectiles,
Army Academy of Artillery and Air Defense of PLA, Hefei 230031, China)
Abstract:
The problem existing in the transformation of? deep learning algorithm to engineering application is analyzed. Combining with the? characteristics and development trends of army intelligent ammunition, the missile-borne image processing heterogeneous accelerate system for deep learning is put forward based on the research of compression, quantitative and hardware heterogeneous acceleration, realizing heterogeneous hardware design. The DNNDK is used to compress and quantify the Yolo v3 model. The weight and parameter compression rate are more than 90% and 80%, realizing the lightweight design of Yolo v3. Based on the DPU hardware acceleration architecture, the algorithm is transplanted to the missile-borne embedded platform, and its power consumption and detection efficiency meet the requirements of missile-borne image processing.
Key words: missile-borne image; deep learning; FPGA; systolic array; Winograd convolution
收稿日期:2020-06-01
基金項目:軍隊“十三五”預研基金項目 (301070103)
作者簡介:陳棟(1983-),男,安徽合肥人,副教授,博士,研究方向為新型彈藥技術研究與運用、武器系統運用與保障工程。
通訊作者:田宗浩(1991-),男,河北晉州人,博士研究生,研究方向為智能彈藥、圖像處理。
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
