集成多種策略模型的維漢神經網絡機器翻譯系統
2021-08-19 08:22:52宜年艾山吾買爾劉勝全
現代計算機 2021年21期
宜年,艾山·吾買爾,劉勝全
(1.新疆大學信息科學與工程學院,烏魯木齊830046;2.新疆多語種信息技術重點實驗室,烏魯木齊830046)
0 引言
神經網絡機器翻譯(Neural Machine Translation,NMT)是最近幾年研究人員主要關注的機器翻譯方法,該方法隨著計算能力的提升和網絡結構的優化使得其在多個翻譯任務上的性能超過統計機器翻譯,從而成為當前機器翻譯領域中最引人注目的方法。2014年Sutskever等人[1]提出了一種端到端的神經網絡機器翻譯框架——編碼器-解碼器結構。隨后Bahdanau等人[2]提出了注意力機制,改進了編碼器-解碼器模型對于長句子翻譯不好的缺陷。2017年Facebook提出了ConvS2S翻譯模型[3],該模型根據利用多層卷積神經網絡和門控機制來構建翻譯模型,使得模型的訓練時間更短和性能更好。2017年Google根據編碼器-解碼器框架和注意力機制提出一種基于自注意力(Self-Atten?tion)機制的Transformer模型[4],該模型相比于之前利用循環神網絡和多層卷積神經網路的模型。它僅使用自注意力機制來構成編碼器和解碼器,從而使得模型訓練時間顯著縮短,并進一步提升了機器翻譯的性能。Transformer是目前學術界和工業界使用最廣泛的機器翻譯模型。在本次的維漢機器翻譯任務中,我們使用Transformer模型實現了維漢機器翻譯模型,主要選用Facebook團隊研發的FairSeq開源系統。
1 神經網絡機器翻譯及相關策略
1.1 基于自注意力機制的Transformer模型
Vaswani等人[4]提出了Transformer模型。它在機器翻譯領域取得了顯著的提升。不同于RNNSearch模型,它是完全基于自注意力機制,能夠有效地提升模型訓練的效率。但它同RNNSearch一樣,同樣由編碼器和解碼器構成。Transformer模型中的編碼器與RNN?Search的作用相同,都是用于將源語言序列所包含的語義信息轉換為特征向量。Transformer的編碼器有N層結構相同的子層組成。其中每一個子層都由多頭注意力和前饋神經網絡以及殘差網絡構成。多頭注意力通過利用自注意力來提取序列中所包含的信息,前饋神經網絡這可以將包含提取信息的特征向量進行特征組合和非線性映射。使得特征向量在向量空間上更接近目標語言的特征向量。而殘差網絡是為了防止模型結構因為過于復雜而引起的退化。
對于第k層編碼器,其的公式為:
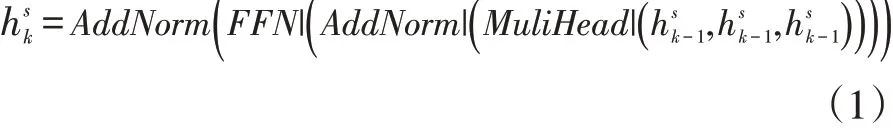
公式中MultiHead()為多頭注意力;FFN()為前饋神經網絡;AddNorm()為殘差網絡。為k-1層編碼器的輸出,dmodel為模型隱狀態的維度。當k=1時為詞嵌入層的輸出。它由詞向量和位置信息向量加和得到。通過N次上述過程的迭代可以的得到序列的特征向量hs,它為編碼器最后一層的輸出即之后會將該特征向量輸入到解碼器中,用于預測目標序列的字符。
解碼器的結構與編碼器的結構類似,也是由N層結構相同的子層組成。不同于編碼器,解碼器的每個子層都由三部分組成,其中兩部分與編碼器的相同。不同的是在多頭注意力之前增加了一個遮掩多頭注意力(MaskMultiHead())用于提取已知的目標序列的特征。對于第K層的遮掩多頭注意力,其公式為:
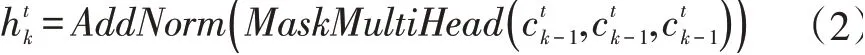
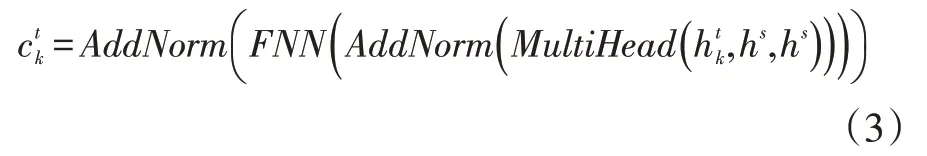
通過將ct經過線性轉換和softmax操作之后,可以得到目標序列的概率:

Linear為線性操作。在訓練階段,可以通過最小化交叉熵損失(最大化目標序列概率)來指導模型的更新:

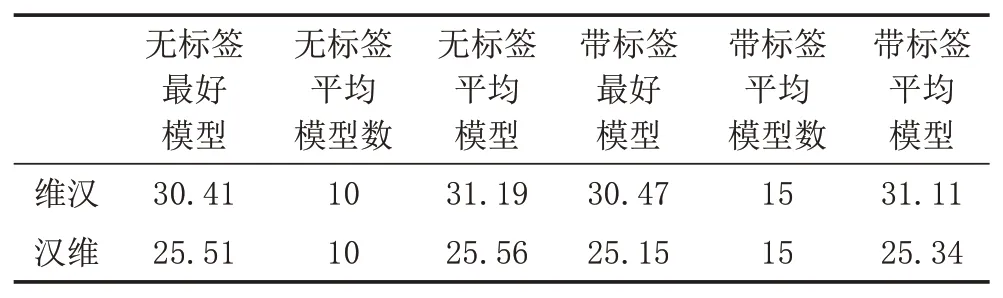
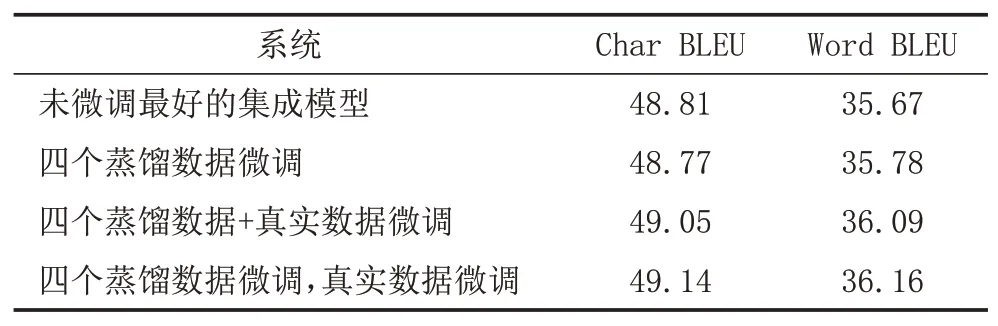
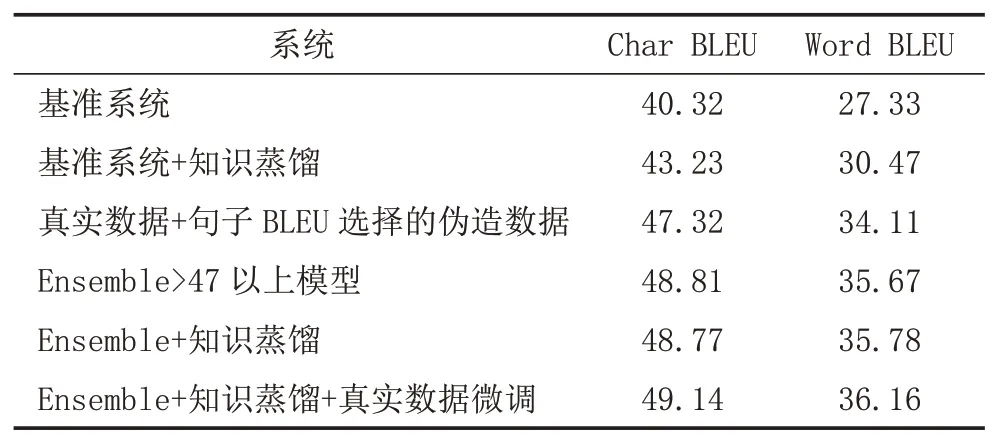
y 文獻[5]提出了通過反向翻譯(Back Translation,BT)的方法,利用單語言數據提高模型性能的方法,反向翻譯已成為機器翻譯系統最主要的數據增強方法。本次評測提供了目標端的漢語單語言文本,通過數據預處理保留了6881603條句子。本文中,使用CCMT2020提供的維漢數據,采用知識蒸餾的方法實現了漢維翻譯模型,對全部單語數據進行循環翻譯(Round Trip Translation)構建《真實漢語句子、偽造維語句子、偽造漢語句子》的語料庫利用語言模型的困惑度、sim(Y,YPseudo)、領域相似度、Y,XPseudo的詞語對齊值等對DPseudo進行排序,然后與真實數據合并進行使用。文獻[6]提出了添加 偽造數據不一定全部是質量高的數據,如何從大量的偽造數據中選出質量高,而且對模型性能提升有幫助的數據是充分挖掘反向翻譯的關鍵問題之一[7]。本評測系統研發中,借鑒已有的方法,嘗試采用基于語言模型計算偽造句子困惑度、通過詞對齊計算句子對齊度、對真實句子和循環翻譯的句子計算BLEU值、領域相似度計算等方法來評價數據質量,根據實驗結果使用插值化的方式使用多種評價值的方法,對評價值不在0-1之間的方法,使用Max-Min方法對困惑度進行歸一化,以便于在插值化使用的保證每個評價值都在0-1之間。 (1)基于語言模型計算偽造句子的困惑度:該方法中利用雙語語料庫的維吾爾語文本,利用KenLM1https://github.com/kpu/kenlm工具實現維吾爾語N-Gram語言模型,并對反向翻譯得到的偽造維語句子計算困惑度,按照困惑度高低對所有句子進行排序,然后使用Max-Min方法對困惑度進行歸一化,以便于在插值化使用的保證每個評價值都在0-1之間。 (2)利用句子詞語對齊工具fast_align1對偽造的維漢句對計算基于對齊率的歸一化句子對齊質量值。 (3)利用循環翻譯的結果,對真實的漢語句子和偽造得到的漢語句子計算句子BLEU,按照BLEU值進行排序。 (4)領域相似度是基于預訓練模型的基礎上,2019年騰訊CCMT評測報告[8]中的兩層全連接網絡的方法計算,模型直接加載預訓練語言模型,獲得句子向量,將句子向量輸入到兩層的全連接層中,以實現領域內外作為分類器目標進行建模,具體公式為: 領域內數據為正例,通用領域數據為負例,訓練BERT領域二分類器,使用BERT領域二分類器對偽造數據中的漢語數據使用分類器進行分類,得到分類為正例和負例的概率,其中分類為正例的概率為領域相似度值。 領域內數據選取:以開發集和訓練集的每個句子計算相似度,使用編輯距離方法計算字符串相似度,開發集里面每個句子和訓練集中的每個句子計算相似度,大于0.5的保留然后排序,將最相似的20個句子保存起來;開發集里面每個句子和單語漢語中的每個句子計算相似度,大于0.5的保留然后排序,將最相似的20個句子保存起來,如果大于0.5的不夠20條,有多少就保留多少。 由于訓練分類器,領域內數據和通用領域數據應當有一定的差別。因此采用和選領域內數據相同的方法選取參與訓練的通用領域數據。 具體做法:中文開發集作為領域內數據集,使用編輯距離方法計算字符串相似度,給開發集里面每個句子和訓練集中的每個句子計算相似度,小于0.5,大于0.1的保留然后排序,將最不相似的100個句子保存起來,給開發集里面每個句子和漢語單語每個句子計算相似度,小于0.5,大于0.1的保留然后排序,將最不相似的100個句子保存起來,將得到的這些最不相似的句子合并之后,將長度小于5的句子去掉,去重,從中隨機選和領域內數據相同數量的數據作為通用領域數據。 知識蒸餾(Knowledge Distillation,KD)[9]是一種知識遷移的方法,是一種基于“教師-學生網絡思想”的訓練方法,由于其簡單、有效,在工業界被廣泛應用。針對NMT的特點,本文采用句子級的知識蒸餾方法來獲取偽造數據,具體的知識蒸餾過程包括不同策略和機構的模型訓練、生成翻譯文件、混合真實和蒸餾文件從新訓練系統。本系統中,分別使用Left2Right(L2R)、Right2Left(R2L)、Source2Target(S2T)、Target2Source(T2S)方式訓練四個Teacher模型,然后生成訓練數據的四個蒸餾文件,與真實數據合并,采用最大似然估計的方法訓練得到學生模型。 Sennrich等人[10]在WMT16比賽中使用模型參數平均方法,該方法可以提升模型魯棒性。模型平均是指在使用不同數據和不同方式進行訓練過程中保存在驗證集上翻譯結果最好的N個模型,并在利用這N個模型翻譯源端語言時對其翻譯得到的目標端字符概率平均,是一種融合策略[11]。利用在訓練中得到的N個模型預測當前時刻木掰斷語言單詞的概率分別,進而將多個模型的預測的概率分布進行加權平均,以聯合預測最終輸出。本文中,對真實數據與偽造數據混合訓練的多種策略的模型、知識蒸餾后的模型等進行模型平均,根據實驗結果選用合理的系統。 在本次的維漢機器翻譯任務中,對維漢雙語數據和機器翻譯數據都進行了預處理和過濾,主要操作全角字符轉半角字符、處理轉義字符、控制字符等特殊字符過濾、分詞及token、單語、雙語語料篩選等,維吾爾語分詞使用本課題組自己開發的工具,漢語分詞使用清華大學分詞系統THULAC,過濾掉句子長度比例3以上的句子,最終保留維漢句子164315條。對漢語單語數據,除了采用以上的預處理方法之外,去掉了“網址,email”或句子中英文或數字的單詞比例超過句子的25%的句子以及長度大于100漢語單詞的句子,最終保留了6881603條句子。數據統計如表1所示。 表1 評測數據統計分析 在本次的機器翻譯評測中,我們使用的操作系統版本為CentOS 7.2,CPU為Intel Xeon CPU E5-2640,內存256G,顯卡NVIDIA Tesla V100(4塊),顯存16G。本次實驗中,使用了Transformer模型,采用了Facebook開源的FairSeq1https://github.com/pytorch/fairseq系統的PyTorch版本。本次評測采用FairSeq系統Transformer Big Model,每個模型使用1塊GPU核進行訓練,BPE,每個batch大約含有4096 to?ken,模型訓練60 epoch,每epoch保存一次模型用于之后的模型平均。模型中詞嵌入層的維度為1024,解碼器和編碼器包含6個子層,其中每個子層的頭自注意力機制使用16個頭,前饋神經網絡中隱層維度為4096。本次評測采用了dropout機制,dropout設為0.3。使用Adam梯度優化算法來訓練得到最終的模型參數,其中β 1=0.90,β2=0.98。初始學習率為0.001,warmup步數設定為4000,beam size=24。漢語和維語端均使用BPE切分,每一個的BPE詞表大小為8K,聯合切分。 為了充分利用評測提供的漢語單語數據,對偽造平行語料庫進行數據規模和選擇方法方面的實驗,使用10個模型進行平均得到模型的平均值。本實驗中,使用維漢真實數據實現漢維翻譯模型對全部漢語單語數據進行翻譯,使用維吾爾語文本訓練得到基于N-Gram的語言模型,實驗數據是通過語言模型對偽造數據計算困惑度排序,按照排序結果依次提取。 從表2可以看出,3百萬數據的Best Model和平均模型的值處于第二的水平,最好單模型的結果略低于4百萬數據訓練的單模型,平均模型的水平略低于3.5萬數據訓練的平均模型,所以本系統中確定選用3百萬句對維漢偽造語料庫。 表2 反向翻譯不同規模數據的實驗對比分析 如何從偽造語料庫中選擇使用對系統訓練幫助最大的數據是充分挖掘單語言的關鍵問題之一。本文中,為了選出來最好的數據,單獨和插值化的方式使用語言模型計算偽造句子的困惑度、領域相似度、循環翻譯的原句子和最終偽造句子的句子BLEU值分數、詞對齊分數等作為評價偽造句子質量的方法從維漢偽造平行語料庫選擇300萬數據與真實數據合并訓練模型,實驗結果如表3所示,表3使用偽造數據使用知識蒸餾的漢維和維漢翻譯。 表3 不同數據選擇方法的實驗結果 從實驗結果可以看出,通過循環翻譯把漢語句子翻譯成維語,然后把偽造維語句子再一次使用機器翻譯翻譯成漢語,對最初的真實漢語句子和最后的偽造漢語句子進行相似度計算的方法評價偽造維語句子的方法是最有效的數據選擇方法之一,其次領域相似度也是相對有一定效果。插值化的方式合并使用詞對齊分數、領域相似度、句子BLEU、句子困惑度等也能接近句子BLEU的水平,集成Char BELU 47以上的模型得到模型值為48.81。 為了提高系統的適應性,提高僅有少量數據的潛力,采用知識蒸餾的方法開展了實驗,分析了知識蒸餾的可行性,并在表4中的模型就使用4種方式進行了知識遷移和微調。從表4可以看到,不同解碼方向和不同語言方向的確對模型性能具有較大的影響。 表4 Teacher模型的實驗結果 從表4和表5,可以看出知識蒸餾對維漢模型和漢維模型的性能有較大幅度的提升。為了測試蒸餾文件加入類似于反向翻譯的偽造數據添加標簽的作用,實驗中分別實現了不帶任何標簽的蒸餾數據與真實數據合并的學生模型、帶 表5 Student模型的實驗結果 根據表5的結果,利用四個蒸餾數據和真實數據,對表3中Char BLEU值大于47的模型進行基于三種策略的微調:①直接利用四個蒸餾數據對模型進行微調,然后集成模型;②四個蒸餾數據和真實數據的混合數據對所有模型進行微調,然后集成模型;③使用四個蒸餾數據進行微調,然后再使用真實的數據進行微調,最終集成模型。 表6 知識蒸餾與微調系統結果對比 表7 多個系統在開發集上的性能對比 本文對機器翻譯系統性能有影響的反向翻譯和數據評價、知識蒸餾、微調、模型平均等進行比較詳細的對比實驗,并融合使用以上多種策略所得到的模型后,取得了顯著提升。從本文實驗中,可以得到通過反向翻譯生成偽造數據,并合理的方式篩選機器翻譯得到的偽造數據對提高低資源翻譯模型幫助非常明顯。1.2 反向翻譯與偽造數據選擇
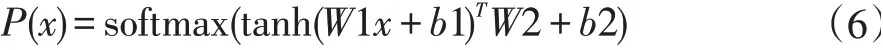
1.3 知識蒸餾與微調
1.4 模型平均
2 數據
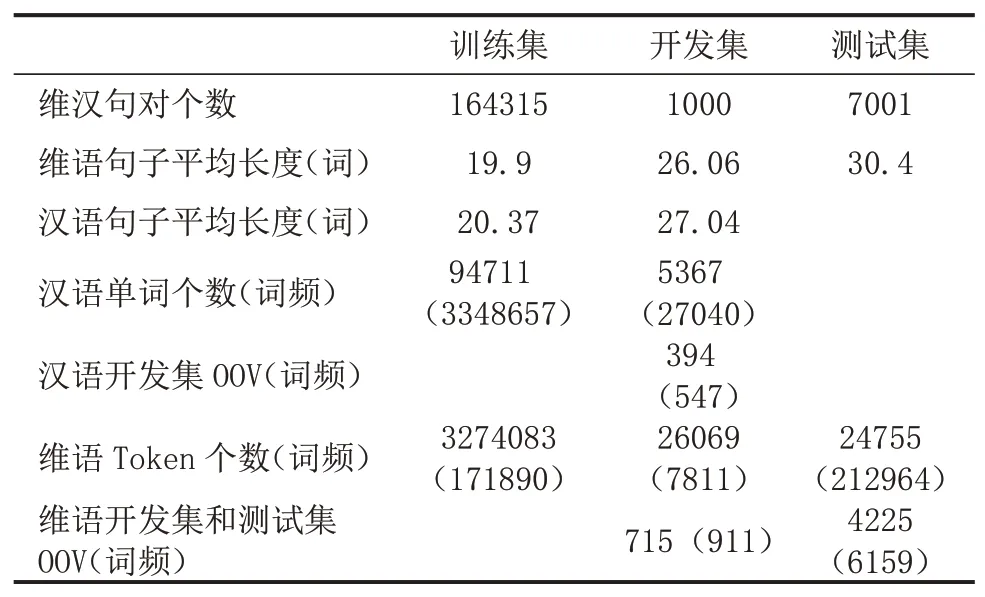
3 實驗
3.1 實驗環境
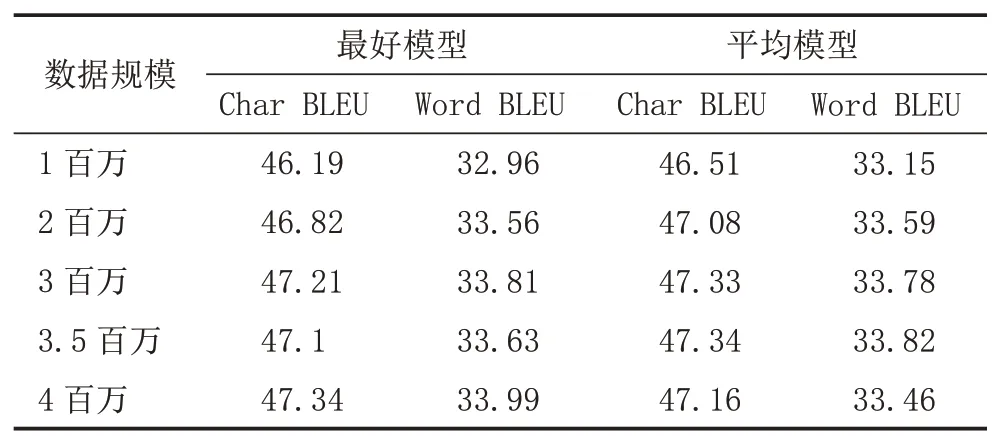
3.2 偽造數據選用實驗
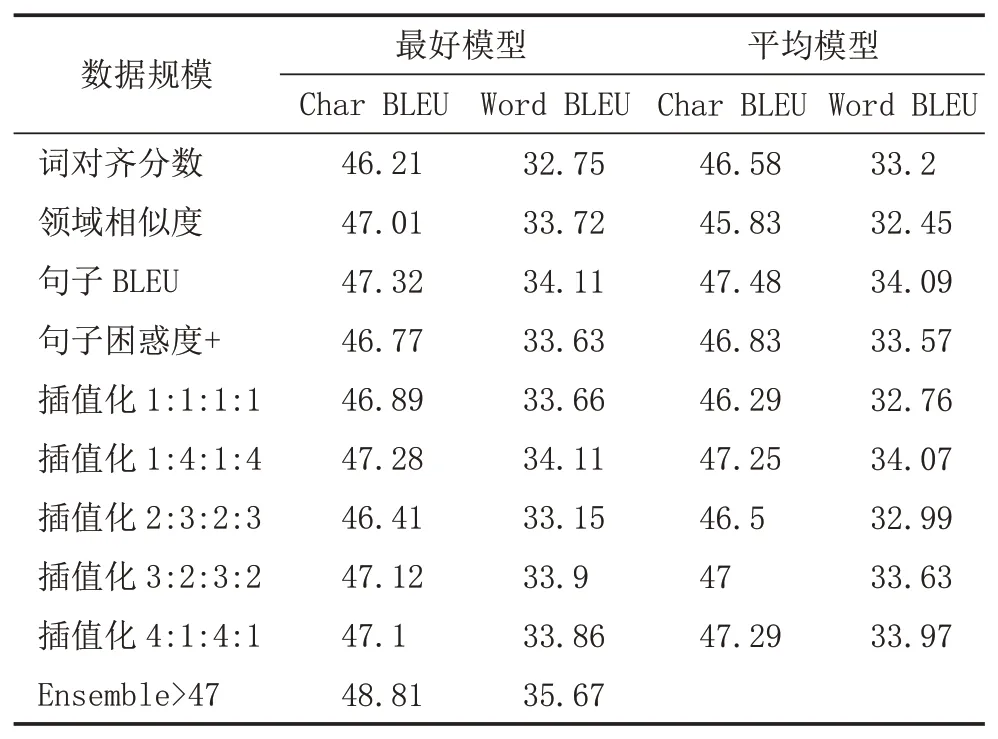
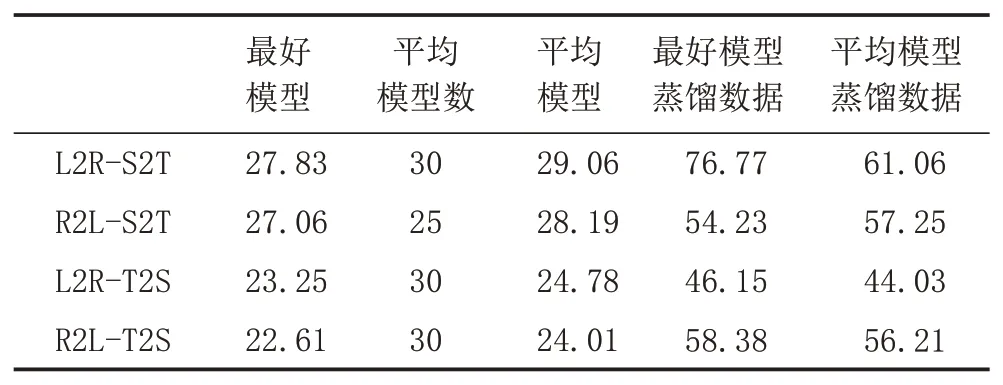
3.3 知識蒸餾、微調和模型平均實驗
4 結語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
光學精密工程(2016年6期)2016-11-07 09:07:19
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
