光纖傳能的移動式激光誘導擊穿光譜鋼鐵快速檢測與分類
2021-08-17 02:53:14李文鑫陳光輝曾慶棟袁夢甜何武光江澤方聶長江余華清郭連波
光譜學與光譜分析 2021年8期
李文鑫, 陳光輝,3, 曾慶棟,*, 袁夢甜,3, 何武光, 江澤方,劉 洋, 聶長江, 余華清, 郭連波
1. 湖北工程學院物理與電子信息工程學院,湖北 孝感 432000 2. 華中科技大學武漢光電國家研究中心,湖北 武漢 430074 3.湖北大學物理與電子科學學院,湖北 武漢 430062
引 言
鋼鐵行業是我國國民經濟的支柱性產業,是關系到國計民生的基礎性行業。2018年我國全年鋼鐵產量已占世界總產量的50%。最近幾年由于產能過剩,中低端和粗鋼的生產所占比重很大,因此大部分鋼鐵行業都處于虧損狀態,未來加大高端鋼材的產量是改變嚴峻形勢的唯一方式。在實際生產中,根據不同用途需要向鋼內加入不同的合金元素來改變鋼鐵的某方面的性能,比如硫(S)可以改善鋼的切削性、 加工性和磁性,但也會引起鋼的熱脆性,降低鋼的機械性能,如使疲勞極限、 塑性和耐磨性顯著下降等,影響鋼件的使用壽命; 磷(P)具有強烈的固溶強化作用,可以增加鋼的強度和硬度,但也會降低鋼的塑性和韌性等等。由于不能準確識別廢材所含材料就無法合理的再利用,每年有大量的廢棄鋼鐵的堆積,這不僅污染環境也是資源的浪費。為了提高鋼鐵廢棄物的回收利用率,如何對鋼鐵材料進行快速檢測分類成為了一個新的研究熱點。現有的元素分析方法有X射線熒光光譜分析方法、 原子吸收光譜分析技術和電感耦合等離子體-原子發射光譜分析技術等,由于這些技術都有各自的缺點和不足[1-4],尚不能滿足快速檢測的需要,因此急需一種新的快速在線檢測技術。
激光誘導擊穿光譜(laser induced breakdown spectroscopy,LIBS)是一種近年來發展迅速的原子發射光譜技術,它采用高能量激光脈沖聚焦到樣品表面產生等離子體,通過對等離子體中原子和離子能級躍遷輻射出的特征光譜采集和分析,獲得被測樣品中所含的元素種類及其含量[5-6]。LIBS技術具有無需進行樣品預處理,分析速度快,非接觸,對樣品幾乎無損等優點,在工業生產實時在線監測方面具有很大的發展潛力[7-9]。采用LIBS技術結合分類算法對材料進行快速分類是當前研究的一個熱點。
傳統的分類算法一般采用K臨近法,然而該算法的特征譜線選取較為復雜。由于鋼鐵合金中的基體元素為Fe元素,其中還含有Cr,Ni,C,Mn,Ti,Mo,Cu等多種元素,相比于其他類型材料,鋼鐵合金樣品的LIBS譜線異常豐富,各元素間的相互干擾更為復雜,為LIBS定量分析帶來了很多挑戰[10-11]。
支持向量機(support vector machine,SVM)是一種基于結構風險最小化準則的學習方法,它能夠利用核函數變換將原始非線性數據轉化為高維線性數據,剔除大量冗余數據,具有很強的魯棒性和容錯性。2015年,楊友盛等[12]利用SVM強大的分類功能,通過Si和Mn對應的特征譜線波長和光譜強度,利用Si、 Mn含量和溫度來判定轉爐終點。結果顯示該模型的準確率達98%以上,證明了在實驗環境不變的情況下,SVM分類模型可以用在光譜定性分析上。2016年,谷艷紅等[13]對土壤中的Cr元素進行定量分析,采用LIBS技術結合SVM的方法,相比于傳統定量分析方法,大大提高了定量分析的精度,其定標曲線擬合相關系數由0.689提高到0.998,表明SVM算法具有良好的實用性。然而,在使用SVM算法時,當直接輸入大量特征時容易發生過擬合,從而導致模型的泛化程度降低,此時需要對輸入向量進行降維處理。合理地選擇樣品組成元素的特征譜線組合作為輸入,可降低輸入向量的維度。人工選擇特征譜線組合較耗時繁瑣且效果難以保證。采用譜線遍歷組合優化輸入向量的降維方法可對所有組合測試,尋找最優的輸入向量,但相關工作鮮有報道。
本工作采用基于光纖傳能的移動式LIBS系統結合SVM算法對特種鋼材進行快速檢測和分類,并提出一種基于預選譜線然后遍歷組合的方法對輸入向量進行優化降維,建立基于SVM算法的光譜識別模型,實現對不同牌號的特種鋼材的快速分類。
1 實驗部分
1.1 儀器
基于光纖傳能的移動式LIBS實驗裝置如圖1所示,采用的激光器為一款緊湊型調Q的Nd∶YAG激光器(型號: Ultra 50,美國Bigsky公司生產),該激光器輸出波長為532 nm,脈沖重復頻率為10 Hz。輸出的激光脈沖經過耦合模塊耦合進一根芯徑為1 mm的傳能光纖,經光纖輸出的最大單脈沖激光能量約為29 mJ,經過準直透鏡進行準直,然后被二向色鏡反射后,經過聚焦透鏡聚焦在樣品靶材表面,激發產生等離子體光譜。等離子體光譜經透鏡采集耦合到光纖,然后傳輸到一臺緊湊型光纖光譜儀(型號為Avaspec-2048 USB2,10 μm狹縫,2 400線·mm-1(VE)光柵)。該光譜儀的光譜波長范圍約為290~1 020 nm,光譜分辨率為0.08~0.11 nm。配有一個門控2048像素的CCD陣列探測器(型號為Sony 554),主要功能是將光信號轉換為電信號。光譜信號隨后通過USB接口傳輸并顯示在筆記本電腦上。每次光譜采集的積分時間設置為1.1 ms,采集延遲時間設為1.3 μs。
1.2 樣本
實驗采用14個特鋼材料作為分析樣品,分別對其進行編號,各樣品中各元素的參考濃度(Wt%)和對應的編號如表1所示(該參考濃度由生產廠家采用火花直讀法測得,分析精度在5%以內)。實驗參數設置如1.1節所述,對每個樣品采集30幅光譜,每幅光譜由10個激光脈沖產生的光譜經過平均后得到,14個樣品共采集420幅光譜。

圖1 LIBS實驗裝置(a): 原理框圖; (b): 樣機Fig.1 LIBS system(a): Schematic; (b): Prototype
1.3 SVM算法簡介
SVM算法是在統計學理論基礎上發展起來的一種機器學習算法,是一種二分類模型,其基本模型是定義在特征空間上的最大間隔分類器,在解決小樣本、 非線性及高維模式識別問題時具有許多特有的優勢。本工作使用中國臺灣大學林智仁(Lin Chih-Jen)教授等開發設計的一個簡單易用和快速有效的SVM軟件包libsvm-3.23進行數據處理。將數據分為兩部分: 訓練集和測試集,訓練集與測試集設置相同的標簽,每個輸入都是一組特征向量與一個判斷樣品屬性的標簽值。SVM工具箱先通過訓練集計算出一個分類模型,然后對測試集進行預測,并將預測的標簽與真實標簽做出對比,以驗證模型的準確性。
在等離子體光譜中,由于激光能量的波動、 樣品的不均勻性和激光與物質相互作用過程的復雜性,單一元素的校準模型往往不能滿足定量分析的要求,特別是基體元素為Fe時,譜峰重疊嚴重,導致單一元素的特征譜線強度穩定性較差[15]。因此難以用單一元素的特征譜線作為SVM的特征參數來建立定量分析模型去準確識別鋼鐵種類,而采用多元素的多條譜線信息輸入支持向量機模型時,模型訓練效果較好,主要是因為多種譜線信息的輸入可以有效校正基體效應的影響。
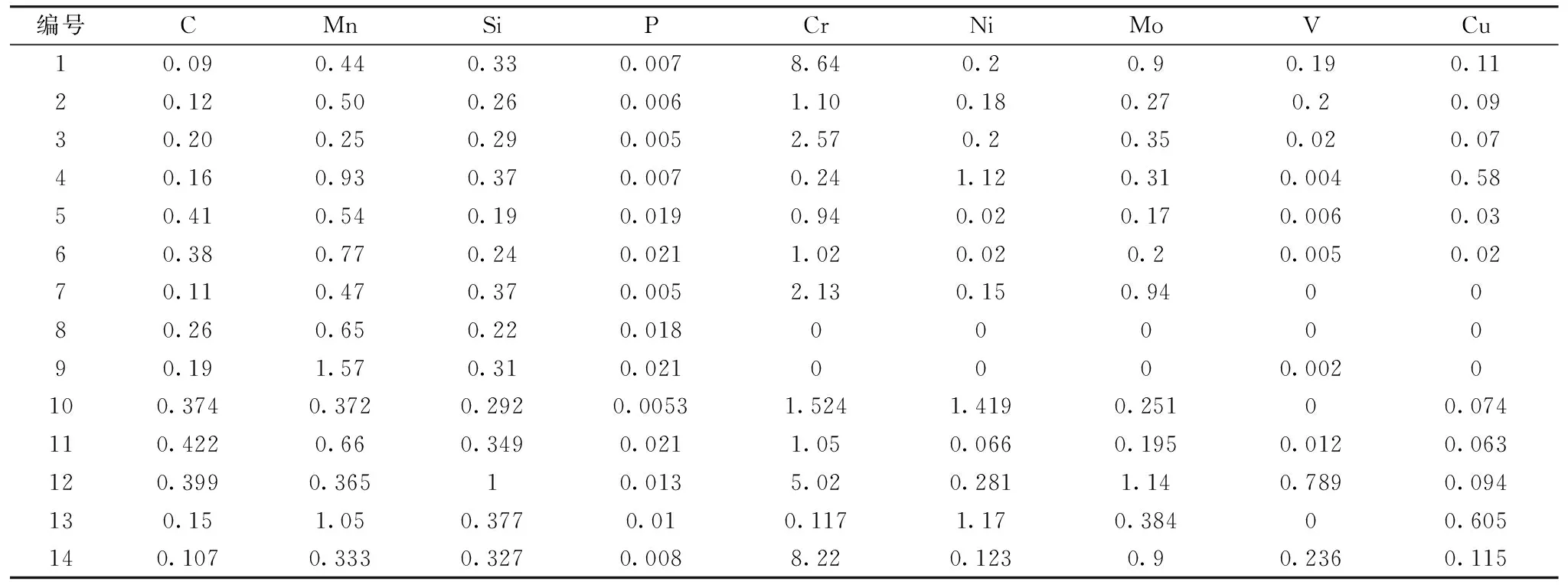
表1 14個鋼鐵樣品中各元素的含量信息(Wt%)Table 1 The concentration information of each element in 14 types of steel samples
2 結果與討論
2.1 特征光譜的選取
以美國國家標準與技術研究院(National Institute of Standards and Technology,NIST)的原子光譜數據庫為參照,結合課題組自主研發的LIBSystem軟件自帶的光譜數據庫,對14種鋼鐵的等離子體發射光譜進行采集與分析,其光譜如圖2所示。
建模前,首先預選出Mn,Ni,Cr,Mo和V元素的共計51條待測譜線(見表2),然后,用Fe: 404.58 nm的譜線作為參考線,對51條譜線進行歸一化處理。預選譜線的原則是,以NIST光譜數據庫為依據,同時挑選譜線強度較高、 波形完整、 沒有自吸收現象和不被其他元素干擾的譜線作為分析線,這樣有利于建立多元素變量的分析模型來識別不同牌號的鋼鐵。
在統計學習中,各類變量經常存在相關性導致輸入向量的維度過高,造成訓練模型出現過擬合問題,需要對輸入變量進行降維處理。常見的降維方法有人工選取、 PCA和線性判別分析(linear discriminant analysis,LDA)等。但傳統的降維方法常常會在降維的過程中丟失信息,導致模型準確度不理想,而人工選譜則過于麻煩,測試結果有可能出現誤判。測試覆蓋度有限及人力成本有限是測試技術所面臨的瓶頸。上述難題表明了對實現自動化選譜處理的渴望。本工作在分類前首先預選出可能的理想譜線,然后通過計算機將預選譜線隨機組合,并且將這些組合作為輸入特征建立多個SVM分類模型,以尋找到一個理想可靠的模型對鋼鐵進行分類識別。
2.2 直接SVM分類結果
實驗中,采用交叉驗證法獲得SVM算法中懲罰因子C和核函數參數g的最優值,由前文可知,每個鋼鐵樣品采集30組光譜數據,隨機選擇其中20組作為訓練集,另10組作為測試集。因此訓練集有280組,測試集有140組光譜數據。同時,依據表1的樣品編號分別設置特鋼的標簽值為1~14。首先,用訓練集的280組光譜數據訓練SVM模型,再將測試集中的140組光譜數據輸人該SVM模型進行預測。預測結果如圖3所示,圖中,符號“°”代表每組光譜數據的實際標簽,符號“×”代表預測的標簽,當“°”與“×”重合時,表示預測值與實際值一致; 相反,“°”與“×”不重合時,表示未能正確識別。
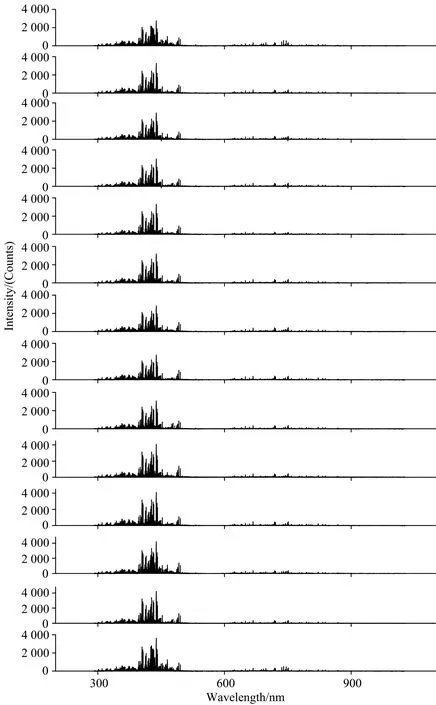
圖2 14種特鋼樣品的等離子體發射光譜Fig.2 The emission spectra of 14 types ofspecial steel samples

表2 選擇的特征譜線Table 2 The selected emission lines
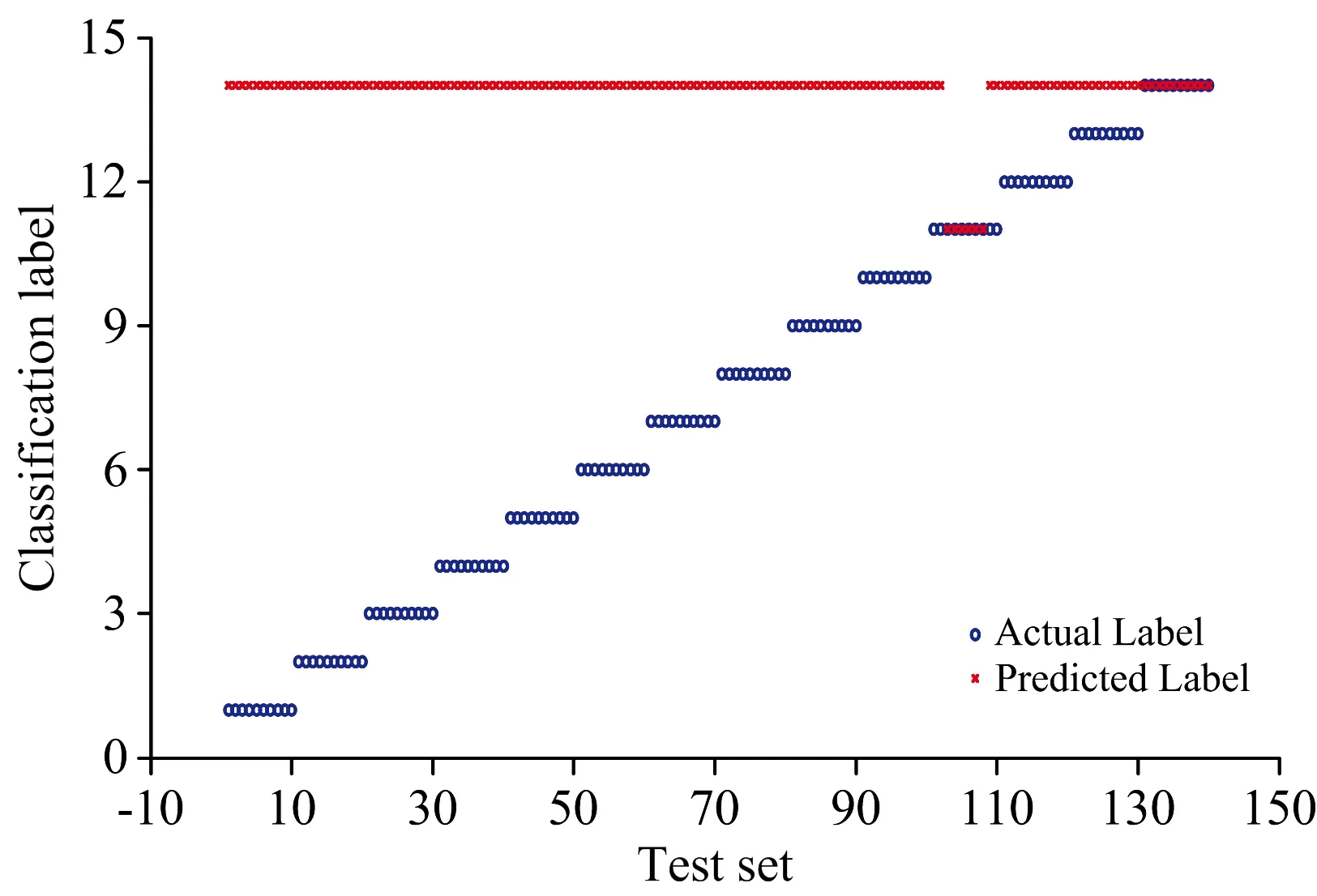
圖3 SVM的預測結果Fig.3 The prediction results by SVM
由圖3可見,當將14個鋼鐵樣品的測試集140個光譜數據直接輸入訓練后的SVM模型時(選取的譜線為表2中的Mn,Mo,V,Cr和Ni的強譜線,共51條),圖中出現了124個誤判點,僅11號樣品的分類效果較好,可能的原因是原始光譜的總體波動過大,導致預測結果趨于一個樣品,即14號樣品。而11號樣品的波動對分類結果影響可能不是特別大,使得部分數據被正確預測。可見,采用51條金屬元素的特征譜線作為SVM分類器模型的輸入向量時,14種鋼鐵的平均識別正確率僅為11.43%,此時的模型并不理想。
2.3 歸一化光譜數據后SVM分類結果
為了減小光譜數據波動的影響,進一步的提高SVM分類算法的準確率,以Fe: 404.58 nm的譜線作為參考線,對所選的待測元素的特征譜線光譜強度做歸一化處理,將歸一化后的光譜強度作為SVM分類模型的輸入量進行訓練和預測,預測結果如圖4所示。結果表明,譜線強度做歸一化處理后可以校正實驗測量條件的擾動造成的偏差,減小實驗條件波動的影響。
由圖4可見,將歸一化處理后的測試集共140個光譜數據輸入訓練后的SVM模型時,圖中出現了6個誤判點。由圖可見,出現誤判的點為5,6和11號樣品,根據表1各樣品的元素濃度可知,5,6和11號樣品所含Mn,Cr,Ni,Mo和V元素的濃度極其相似,例如,對Cr元素而言,6號與11號Cr元素含量分別為1.02%和1.05%; 對Ni元素而言,5和6號樣品所含的濃度含量都為0.02%; 對V元素而言,5和6號樣品中所含的濃度含量分別為0.006%和0.005%。以上元素濃度差別十分微弱,并且由于目前絕大多數的激光器能量并不十分穩定,導致某些樣品中相似濃度的元素譜線做歸一化后強度值極為接近,系統模型受此影響從而發生了誤判。
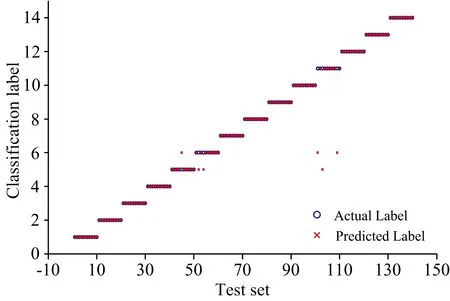
圖4 歸一化后SVM的預測結果Fig.4 The prediction results of normalized spectra by SVM
采用歸一化處理后的51條特征譜線作為SVM分類器模型的輸入向量,14種特鋼的平均識別正確率為95.71%,此時的分類模型雖能識別大多特種鋼材,但精準度還并不理想。
2.4 譜線遍歷組合后SVM分類結果
為了進一步提高分類的準確性,使用MATLAB程序遍歷不同譜線的組合作為輸入變量,進行多次建模,最終挑選出最優的輸入特征,即6條最優特征譜線組合(如表3所示),此時的SVM判斷準確率達到了100%,其實驗結果如圖5所示。
表4為不同輸入特征下的準確率與建模時間的比較。由表4可知,采用數據歸一化處理+遍歷組合選出的6條最優特征譜線作為輸入向量時,SVM模型識別準確度達到100%。這是由于在眾多譜線中,算法通過遍歷各種組合,只余下辨識度高、 代表性強的譜線作為輸入向量,使得模型的精準度得到大幅提升。從平均建模時間來看,對數據采用歸一化+遍歷組合的算法處理后,其建模時間也大大縮短,相比于使用原始光譜的SVM分類模型,其建模時間減小了37%。
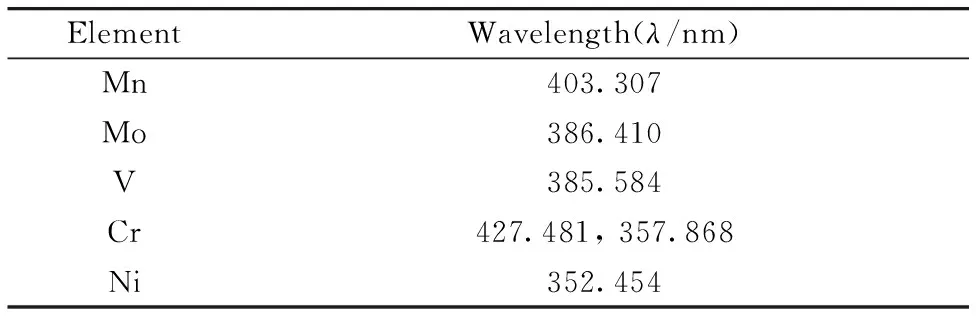
表3 SVM預測準確度達100%的6條特征譜線Table 3 The 6 spectral lines with SVM predictionaccuracy of 100%
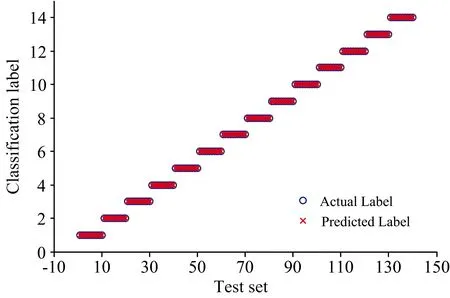
圖5 挑選6條特征譜線后SVM預測結果Fig.5 The SVM prediction results using selecting6 special spectral lines

表4 不同輸入下SVM的平均預測準確率和平均建模時間Table 4 The average prediction accuracy and mean modelingtime of SVM with different inputs
3 結 論
基于光纖傳能的移動式LIBS樣機平臺,采用預選譜線+遍歷組合的降維方法與SVM算法相結合,對14個特鋼材料的LIBS光譜進行快速分類。SVM算法計算簡單、 訓練速度快、 并且每次訓練的模型穩定。然而,當單獨將51條預選譜線作為輸入特征輸入到SVM算法時,測試集中140組光譜數據在直接輸入大量特征時發生了過擬合,導致模型的泛化程度降低,預測準確度僅為11.43%,此時,對14種特鋼材料的分類精度并不理想; 當采用歸一化光譜數據作為輸入特征輸入到SVM算法時,預測準確度提高到95.71%,說明對光譜數據進行歸一化處理可以顯著提高SVM模型的分類準確性; 而當51條預選譜線經過譜線遍歷組合降維之后,僅剩6條被選擇的譜線作為輸入特征時,此時的SVM模型預測準確度達到了100%。實驗結果表明,采用譜線遍歷組合的方法是一種行之有效的降維方法。同時,該降維方法相對于人工選取特征譜線來說,方便快捷,操作簡單,對模型的優化程度高。當面臨大量特征數據時,機器自動選取特征與人工挑選譜線相比具有明顯優勢。可以看出,基于譜線遍歷組合降維方法的SVM算法模型結合LIBS技術,在材料快速分類方面具有很好的工業應用前景。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
