基于非遞減時序隨機游走的動態異質網絡嵌入
2021-08-17 00:51:26郭佳雯白淇介林鑄天宋春瑤袁曉潔
計算機研究與發展 2021年8期
郭佳雯 白淇介 林鑄天 宋春瑤 袁曉潔
1(南開大學網絡空間安全學院 天津 300350) 2(天津市網絡與數據安全技術重點實驗室(南開大學) 天津 300350)
在當前信息時代,現實世界中的各類數據天然以網絡圖模型存在,蘊藏著各種豐富且復雜的信息.通過對網絡數據進行分析和預測,人們可以挖掘數據中潛在的信息并加以利用,例如分析用戶畫像、進行定制化內容推薦等.但由于網絡數據通常以鄰接矩陣表示,規模大、維度高,難以直接作為機器學習模型的輸入進行分析和預測.因此,網絡表示學習或網絡嵌入為研究者提供了一種方法,它將高維網絡映射到低維向量空間,并盡可能地保留原有網絡的結構和語義信息[1].
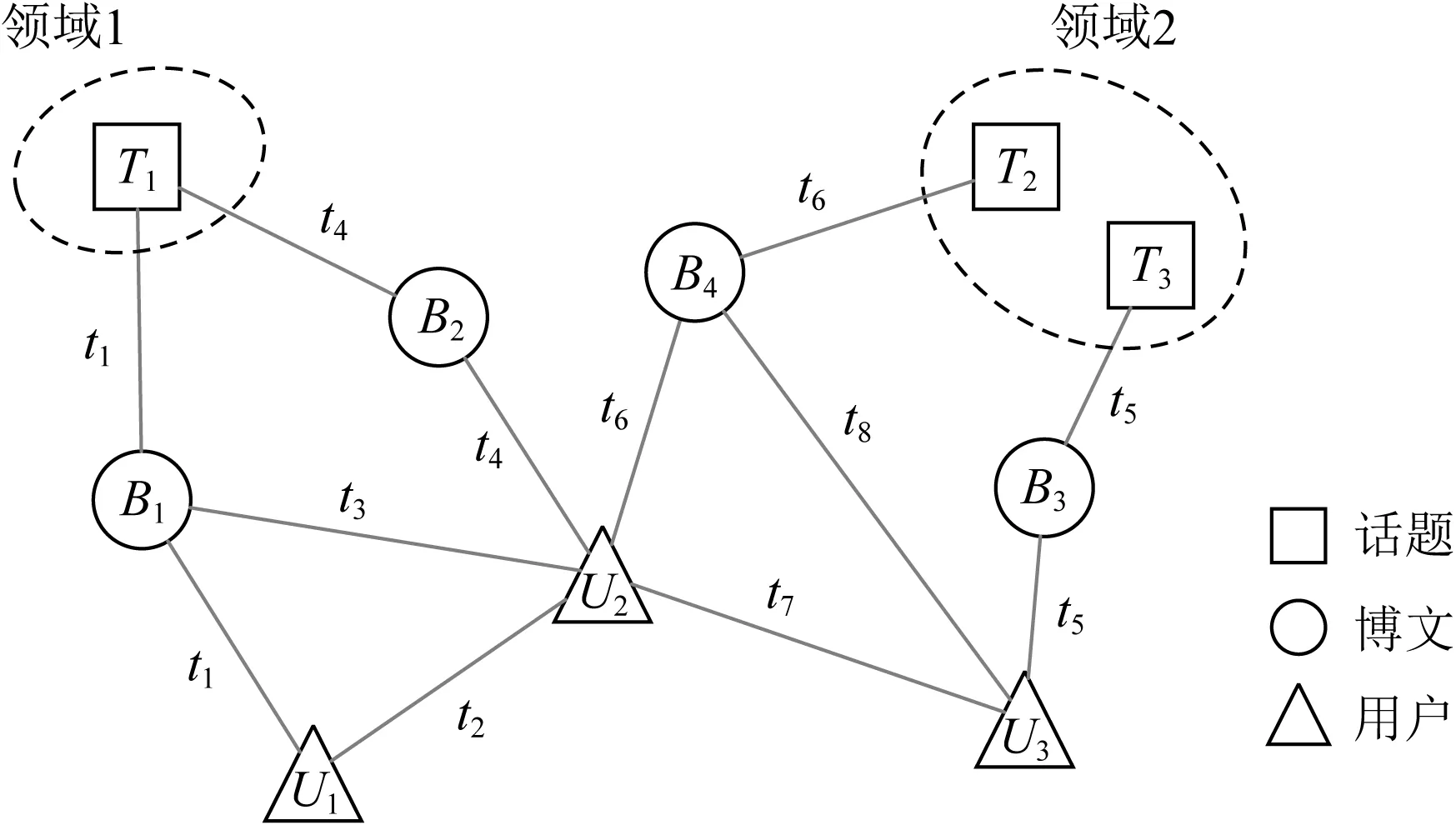
Fig. 1 Sample of dynamic heterogeneous information network圖1 動態異質信息網絡示意圖
現有的網絡嵌入研究大多集中在靜態網絡上,包括靜態同質網絡嵌入和異質信息網絡嵌入.在靜態網絡嵌入研究中,主要考慮如何對網絡的拓撲結構和異質網絡中語義信息進行保留,而不考慮任何時間信息.然而,現實世界中的復雜網絡會隨著時間的推移而快速發展.如圖1所示,一個動態異質信息網絡(dynamic heterogeneous information network, DHIN)包含不同類型的節點和邊,并隨著時間實時變化.網絡的演變趨勢,我們稱之為時間特征,節點和邊的類型或標簽所隱含的語義稱之為異質特征,它們攜帶了大量包含豐富語義的信息.此外,我們希望動態異質網絡嵌入算法的時間效率能夠盡可能高,以便滿足實時性需求.
現有研究已經證明,忽略網絡的異質特性將由于信息損失造成嵌入質量的下降[2].由于動態異質網絡是在異質信息網絡的基礎上同時具備時間戳信息,因此網絡的邊通常產生在語義緊密相關但分屬不同類別的節點之間.并且,具有語義相關性的異質節點之間的邊也經常具有相同的時間戳.例如圖1所示,時刻t1用戶U1在話題T1上發表了博文B1,則在動態異質網絡中的局部結構為:在具有語義關聯的節點U1,B1,T1之間建立時間戳為t1的邊.和動態同質網絡不同的是,受異質網絡語義信息的影響,語義密切相關的節點之間更有可能出現完全相同的時間戳,而非發生時間具有先后順序的、遞增的時間戳,這將為動態同質網絡嵌入中基于時間順序的隨機游走帶來新的挑戰.
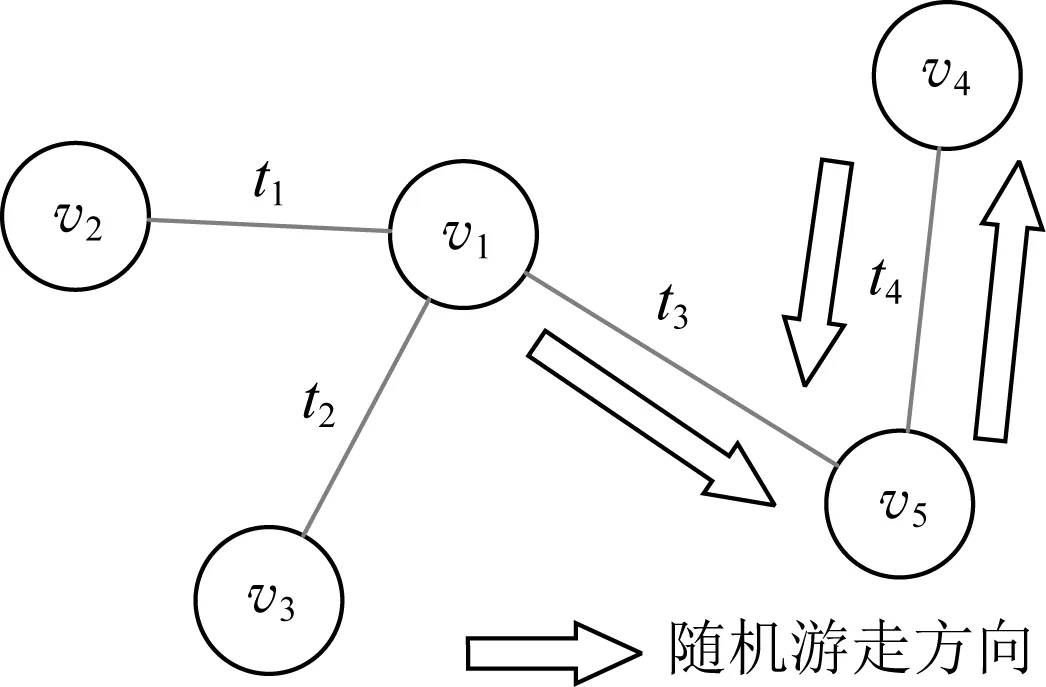
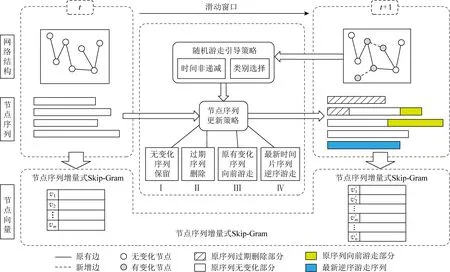
與忽略異質特征類似,如果不考慮時間特征,同樣會發生重大的信息損失.以圖1的社交網絡為例.在t 近年來,越來越多的學者開始關注動態網絡嵌入的問題,已經有一些動態同質網絡嵌入的方法,如連續時間動態網絡嵌入(continuous-time dynamic network embeddings, CTDNE)[3],但對動態異質網絡嵌入的研究還較少.盡管網絡通過退化,能夠將豐富的異質網絡嵌入方法和動態同質網絡嵌入方法應用于DHIN嵌入,但仍存在3個問題:1)現有針對動態同質網絡嵌入的方法大多是針對快照圖設計的,而非針對實時變化的動態圖,不能增量式地進行網絡表示學習,難以滿足動態網絡推斷實時性的要求;2)動態同質網絡嵌入和靜態網絡嵌入方法會忽略網絡的動態信息或異質特征,造成嚴重的信息損失;3)動態異質網絡由于其同時具備動態和異質特性,引入了局部結構具有相同時間戳的新的復雜性.因此,本文提出一種針對實時演化的動態異質網絡的增量式表示學習方法,綜合考慮網絡的動態和異質信息,通過時序非遞減的隨機游走規則解決局部相同時間戳帶來的挑戰. 動態異質網絡嵌入的一大關鍵問題是如何捕捉網絡實時演化信息.受CTDNE[3]的啟發,一個直接的想法是,我們在圖上進行由時序引導的隨機游走,以模擬信息隨時間在網絡上傳遞的過程.通過這種方式,可以很容易地使模型以增量的方式進行游走,游走經過的邊上的時間戳遞增,并依據游走序列最后一步的時間戳進行游走序列的接續擴展. 但是,將時序引導的隨機游走應用在動態異質網絡嵌入上仍然存在一些挑戰. 1) 如何組織游走規則,以保證我們在新到來的時間戳中捕捉到網絡中新的變化,并不失去游走的隨機性.如果直接應用CTDNE中的游走規則,保證始終走過新時間戳或時間段上新到來的所有邊,可以很好地保留演變的趨勢,但在某些情況下存在以下2個問題.一個是當圖的規模較大時,由于不斷到來的邊的增長速度很快,且允許平行邊(即同一對節點間的多條邊)存在,算法所需要的內存大小可能難以接受.另一個是,由于動態網絡變化速率通常較快,并且部分動態網絡的時間信息粒度較粗,同一時間片內會有大量新邊流入.由于在同一時間片內涌入的大量連接之間也具有較強的相關性和信息的流動,算法難以捕獲相同時間片內部的信息,并且當處理某些具有特殊元結構的異質圖時,某些類型的節點上可能存在大部分邊緣處于相同時間戳的情況,例如數據集AMiner[4]和DBIS[5],其論文類型節點P與會議節點C、作者節點A之間,以論文發表時間作為建立連接的時間戳,因此節點P上所連邊一定處于相同時間戳.為了解決這一問題,我們采用和CTDNE中基于邊的隨機游走不同的方式:基于節點進行隨機游走,由于網絡中節點數通常遠小于邊數,因此算法所需要的內存大小始終為節點數的指定倍數;此外,采用非遞減的時序約束隨機游走,允許游走在滿足一定條件下選擇那些仍在當前時間片中的邊. 2) 如何同時保留時間特征和異質特征.如果我們將時間約束和類型約束直接結合在隨機游走上,序列的長度會因為更嚴格的限制而變短.因此我們必須在它們之間進行折中,允許在滿足時間約束的前提下適當放寬對類型的約束. 3) 對于動態圖的時間信息,我們利用的是圖流中的時間戳,而不是具體時間下的網絡快照,因此,節點、邊和時間戳的數量都會隨著時間增長.當我們訓練模型時,事先并不知道下一個時間戳會發生什么,所以一些基于預知整個過程中所有節點和時間的深度學習方法不適合這樣的問題.因此,我們提出了一種基于增量隨機游走的新方法. 本文的主要貢獻包括以下3個方面: 1) 提出了一種基于隨機游走的增量算法框架TNDE(temporally non-decreasing dynamic hetero-geneous network embedding)來處理實時動態網絡嵌入的表示學習.該算法能夠隨著時間的推移增量式學習,不需要預知圖的結構、時間戳總數等額外信息,并且它基于節點視角來組織游走,使用有限的內存,其上界是可預測的. 2) 提出了時序非遞減的方法來解決動態異質網絡中隨機游走的時間戳陷入問題.引入類型約束以同時捕捉網絡的時間和異質特征,并設計折中策略以防止由于約束過于嚴格而導致的游走序列過短問題. 3) 在3個真實數據集上的實驗表明,TNDE能夠顯著提升嵌入質量,在下游鏈路預測和節點分類任務上得到了2.4%~92.7%的性能提升,并在保證良好下游任務準確度的前提下,大幅縮短算法運行時間.通過比較3個特性不同的數據集的實驗結果,證明TNDE在不同類型的網絡中具有良好的通用性. 靜態網絡包括靜態同質網絡和靜態異質網絡.在靜態網絡嵌入問題上,學者們已經做了大量的研究工作,代表性綜述包括文獻[1,6-8].文獻[9-10]是靜態異質網絡嵌入上的代表性調研綜述,從背景和代表性方法到研究方向和挑戰進行了全面的討論. 對于靜態同質網絡嵌入,3類代表性方法包括:基于矩陣分解的方法HOPE[11]和M-NMF[12];基于隨機游走的方法DeepWalk[13],Node2Vec[14]和NRNR[15];基于深度神經網絡的方法SDNE[16],SDAE[17]和SiNE[18]. 對于靜態異質網絡嵌入,有基于度量學習的模型PME[19],可以同時保留一階和二階相似性;以及基于圖注意力網絡的方法HAN[20]和HetGNN[21].另外,部分靜態異質網絡嵌入方法主要考慮單一下游任務的性能.例如,文獻[22]和[23]關注于節點分類,而文獻[24]則是為推薦任務設計的. 靜態異質網絡嵌入中最經典的是基于元路徑引導隨機游走的方法Metapath2Vec[2].它基于Deep-Walk的思想,利用word2vec[25]對圖中節點進行表示學習,并通過預定義的元路徑引導隨機游走,以保留異質網絡中的語義信息.此外,還有許多其他基于隨機游走的異質網絡嵌入方法.例如,ESim[26]和HIN2Vec[27]均使用元路徑引導隨機游走.但是基于元路徑的方法需要依賴網絡的先驗知識進行元路徑的選取,并且元路徑選取的好壞將很大程度上影響嵌入質量.JUST[28]方法不使用指定的元路徑,而是對不同類型的節點進行有偏采樣,使得游走中下一跳的節點類型參照歷史類別進行選擇,避免了基于元路徑的方法對先驗知識和元路徑選擇依賴的問題. 動態網絡中,節點和邊隨時間變化,根據網絡動態的呈現形式,通常可以劃分為快照網絡和實時動態網絡2種.快照是一種靜態圖,它存儲了網絡在某一時刻的結構.快照網絡指的是流式網絡中不同時間戳上得到的一系列快照,而實時動態網絡則是帶有時間戳的、不斷出現新邊和節點的圖流. 目前動態網絡嵌入上的研究大部分集中在動態同質網絡上.Zhou等人[29]提出了一種基于三元閉合過程的模型DynamicTriad,以保留給定快照網絡的結構信息和演化模式.Du等人[30]提出了一種啟發式算法DNE,將基于Skip-Gram的網絡嵌入方法擴展到動態環境中.Peng等人[31]提出了一種增量式Skip-Gram,結合現有的網絡嵌入模型Node2Vec[14]中的游走方式,能夠對快照間的演變信息進行良好的保留.但是上述方法主要針對快照網絡進行設計,不區分某一變化發生的具體時間戳,時間粒度粗.而對于具有時間戳、細粒度的實時動態網絡嵌入,Zuo等人[32]提出了一種基于Hawkes過程的方法HTNE來捕捉歷史信息的影響.Lee等人[3]提出了一種基于時序隨機游走的模型CTDNE,該模型采用時間戳嚴格遞增的順序進行隨機游走.但上述針對動態同質網絡的方法,僅考慮了網絡的動態特征,忽略動態異質網絡的異質信息會造成嚴重的信息損失. 目前,越來越多的學者對動態異質網絡嵌入產生了興趣,但其上的研究工作仍十分缺乏.例如,DANE[33]是一種用于動態屬性網絡的譜方法,它能夠良好保留網絡的屬性標簽和動態特性,但它假設在訓練過程中所有的節點都是事先已知的.DyHNE[34]通過元路徑增廣鄰接矩陣的擾動來增量式捕捉變化,進而利用特征值擾動得到更新后的嵌入,但其對演化趨勢信息的建模能力有所欠缺,對近期頻繁發生的事件和過去頻繁發生的事件區分能力不足.受動態同質網絡嵌入方法DynamicTriad[29]的啟發,Bian等人提出了一種基于元路徑和三元組開/閉過程的表示學習方法Change2vec[35],針對2個連續的靜態網絡快照之間的差異進行處理,能夠兼顧網絡的動態特性和異質特性,有良好的時間效率.但其關注的是快照網絡而不是實時動態網絡,并且不是所有重要的變化都會導致三元開/閉過程.此外,動態網絡上還有基于深度學習的嵌入方法,但由于其往往需要預知完整圖的節點集或時間戳集合而無法滿足動態網絡實時增量具有不可預知性的要求. 綜上所述,現有網絡嵌入方法主要集中在靜態網絡和動態同質網絡上,動態異質網絡嵌入方法仍較少;且現有動態方法大多針對快照網絡,而非實時動態網絡,難以捕獲細粒度時間信息;基于譜方法或深度神經網絡的方法由于其時間空間開銷大,且大多需要預知全圖信息,而難以適應實時動態網絡的需要.因此,除現有動態異質網絡嵌入方法外,能夠解決實時動態異質網絡嵌入問題的最接近的路線包括:可在不同時間點上反復調用的靜態異質網絡表示學習方法,忽略動態異質網絡類型信息的動態同質網絡嵌入方法和基于隨機游走的動態異質網絡嵌入方法.因此我們分別從上述路線中各自選取了代表性的算法作為實驗對比方法. 在詳細描述我們的算法之前,首先給出實時動態異質信息網絡嵌入問題的形式化定義和相關概念,并對動態異質網絡中由于局部結構上時間戳相同帶來的時間戳陷入問題進行描述. 在本節中,我們首先利用文獻[3,6,9,36]中的異質信息網絡和實時動態網絡的形式化定義給出定義1和定義2,并給出實時動態異質信息網絡的定義.然后形式化說明實時動態異質信息網絡表示學習問題,并說明表示學習問題的輸入和輸出. 定義1.異質信息網絡.給定一個無向圖G=(V,E,L),其中V={v1,v2,…,vn}代表節點集,E={e1,e2,…,em}代表邊集,L=Lv∪Le代表節點和邊的類型集合.當類型數量|L|>2,且滿足節點類型數量|Lv|≥1,邊類型數量|Le|≥1時,該無向圖被稱為異質信息網絡. 定義2.無向實時動態網絡.給定一個無向圖G=(V,E,Γ),其中V和E分別代表節點和邊的集合,允許兩節點u,v之間建立多條直連邊,Γ代表映射函數Γ:E→+,即任意邊ei=(u,v,t)∈E,對應正實數域上一個時間戳t,則該無向圖被稱為實時動態網絡. 值得注意的是,本文關注的是具有連續時間戳的實時動態網絡,而非將動態網絡切割成一系列網絡靜態狀態的快照網絡.換而言之,我們關注的是有連續邊輸入的圖流.定義3描述了本文的主要研究對象. 定義3.實時動態異質信息網絡.實時動態異質信息網絡是同屬于異質信息網絡和實時動態網絡的無向圖G=(V,E,L,Γ),允許在同一對節點之間建立多條連接.其中,V代表節點集,E代表邊集,L代表節點和邊的類型集合,Γ:E→+表示將邊映射到相應時間戳的函數. 由于實時動態異質信息網絡是基于流的,并允許同一對節點之間存在平行邊,因此快照網絡和實時動態網絡的嵌入方法有一些關鍵區別.首先,它們捕捉的是不同粒度的動態特征.快照通常不包含時間戳,并且快照間的時間間隔較長,因此把快照間的差異稱為粗粒度的變化;而在實時動態網絡中,每條邊都攜帶時間戳,因此把某一時刻下網絡的變化稱為細粒度的變化.實時動態網絡的嵌入方法通常利用具體的時間戳來捕捉細粒度的時間特征,而快照網絡的模型則是處理2個連續快照之間的粗粒度變化.其次,它們對平行邊問題的態度不同.快照網絡嵌入通常將快照處理成簡單圖,不考慮平行邊;而在實時動態網絡嵌入中,同一對節點間在不同時刻可能產生多次連接,因此需考慮平行邊,以便捕獲到細粒度時間信息. 本文目標是通過捕捉異質特征和時間特征來學習實時動態異質網絡中節點的低維向量表示.該模型以一個無向的、具有平行邊的實時動態異質網絡G=(V,E,L,Γ)作為輸入.若節點數|V|=n,則最終輸出一個n×d的矩陣,其中d?n,各行d維向量即為保留了拓撲特征、異質語義信息和時間特征的節點表示. 由于本文算法的主要挑戰之一是解決在動態異質網絡上進行時序隨機游走時產生的時間戳陷入問題.因此,在介紹具體解決方式前,本節將對時間戳陷入問題產生的原因及過程進行描述. 實時動態網絡在演化過程中,隨著事件的不斷發生而在節點之間生成新的邊連接,因此邊建立的先后順序將隱含信息的傳遞方向.例如將圖2的動態網絡看作郵件網絡的一個表示,節點v1分別于時刻t1,t2,t3向v2,v3,v5發送工作郵件,v5通過一段時間的整理,再于時刻t4向v4發送工作郵件,即完成一次從節點v1到v4的郵件信息傳遞.由于在實時動態網絡中,網絡的動態信息是通過邊上的時間戳來表示,因此針對實時動態網絡的嵌入方法需要關注時間戳中動態信息的建模方式,通過時序遞增引導隨機游走即可建模網絡中潛在的信息傳遞語義. Fig. 2 Time trapped problem on dynamic network圖2 動態網絡上的時間戳陷入問題 以圖2為例,t1≤t2≤t3≤t4,在動態異質信息網絡上應用時序遞增引導隨機游走,從節點v1出發得到序列{v1,v5,v4},能夠模擬信息從v1到v4的信息傳遞過程.但是游走到v4后,如果允許時間戳停留在游走當前的時間戳,則下一跳將返回v5.由于v4和v5沒有時間戳大于t4的邊,則將從v5再次走到v4,在兩節點之間反復游走直到滿足序列長度限制,從而造成在t4時間戳上的陷入問題. 時間戳陷入問題即可描述為:在無向實時動態網絡上,由于時序非減的隨機游走允許時間戳停留在當前時刻,而造成的在某一時間戳上隨機游走陷入局部少數節點之間的反復游走、進而降低模型準確度的問題. 為解決這一問題,動態同質網絡嵌入方法CTDNE采用時間戳嚴格遞增的方式游走,即不允許游走停留在上一時刻,回避了時間戳陷入的前提條件.而在時間戳粒度較大的網絡中,例如以年為單位的引文網絡中,某年同一會議上發表的論文具有相同的時間戳.這意味著在某個階段,它們對同一個領域感興趣,這是重要的時間信息.規定時間戳嚴格遞增的約束,可能會造成游走序列過短、丟失重要語義信息、訓練效果差的情況. 區別于動態同質網絡,動態異質信息網絡由于其同時具備異質網絡特性和時間信息而存在更為復雜的結構.異質網絡特性將使得不同類別的節點之間的不同類別的邊具有更豐富的語義信息.因此在動態異質網絡嵌入過程中,我們一方面需要利用網絡當中的時間戳信息來建模網絡演化模式,另一方面還需要綜合考慮網絡中不同類別的節點和邊所代表的語義信息. 而值得注意的是,在異質網絡中,由于每個具有語義信息的事件往往涉及到多類別的節點,事件發生這一動作將引起多類節點之間同時產生多條邊連接,從而該邊上具有完全相同的時間戳,而不具有事件發生的先后順序.例如圖1中,節點B4上所連接的時間戳為t6的邊表示時刻t6用戶U2在話題T2上發表博文B4.如果不允許時間戳停留在上一跳的時刻,則當游走從U2走到B4后,將在B4處終止或轉向時刻t8收藏了該文的用戶U3(t8>t6),無法形成“某用戶某時刻在某話題上發表某博文”這一核心語義的游走序列(“用戶-博文-話題”).因此,在動態異質網絡中,由于大量存在局部結構上邊的時間戳相同的情況,不允許停留在當前時間戳將使得在異質網絡中無法產生具有緊密語義聯系的游走序列,因此需設計能夠解決時間戳陷入問題的時序非遞減的游走策略. 在本節中,我們提出了實時動態異質網絡上的一種基于時序非遞減隨機游走的增量表示學習方法(temporally non-decreasing dynamic heterogeneous network embedding, TNDE).首先給出模型整體框架,然后分別對于模型中時序非遞減的算法和增量更新策略細節進行描述. 在介紹模型的細節之前,首先對TNDE算法進行概述.第1步采用滑動窗口模擬網絡動態演化,第2步處理網絡中待更新的序列,第3步根據游走策略進行增量游走,最后使用增量式Skip-Gram學習更新后的序列.圖3展示了TNDE的算法框架. Fig. 3 Framework of TNDE圖3 TNDE模型框架 受CTDNE[3]中提出的時序游走的啟發,為了更好地保留動態異質網絡中的時間特征,特別是在相同時間片上的具有強語義的時間信息,同時避免時間戳陷入問題,我們提出了一種基于非遞減時序的隨機游走方法.根據當前游走的歷史情況,允許游走有一定概率在當前時間戳下繼續延伸,并將時序約束與類型有偏引導隨機游走相結合,綜合考慮了網絡的時序和異質信息.與CTDNE不同,本文中序列的游走方式從節點角度進行組織,從而將算法的空間開銷從O(|E|)降至O(|V|),并便于后續進行序列的接續游走等增量更新.游走算法的具體細節在3.2節中描述. 由于動態網絡在不斷演進的過程中,節點表示除受當前新增信息影響外,還受歷史信息的影響,因此通過對節點的游走序列進行增量更新,再利用更新后的節點序列進行向量表示的增量式學習,能夠綜合當前和歷史信息,并減少計算開銷,加速算法運行.每當滑動窗口移動,有新的邊到來時,網絡中節點相關的游走序列將會出現序列段失效刪除或能夠進行接續游走的情況.此外,為保證最新時間上的信息得到保留,模型依據指定比例p選取一定數量的序列進行逆向的非遞減時序隨機游走,通過反轉序列使其等價于正向游走.在得到新時刻的游走序列后,為了縮短運行時間,并保持所學到的向量表示在下游任務中的推斷能力,采用增量式Skip-Gram模型[31]學習,得到最終的節點向量表示.增量更新算法細節在3.3節中進行描述. TNDE的整體框架如算法1所示.通過滑動窗口模擬圖流,在每個滑動窗口中,對當前有效節點采用incrementalUpdateW(3.3節)增量式更新相關的游走序列,并選定后續需要接續游走和逆序游走的序列位置,之后對上述序列調用temporalRW函數(3.2節)進行時序非遞減的隨機游走,將各有效節點增量更新后的游走序列作為增量式Skip-Gram函數incrementalSkipGram(3.3節)的輸入,增量學習給定的動態異質信息網絡G在當前時刻的向量表示X. 算法1.TNDE算法框架. 輸入:動態異質信息網絡G、類別停留概率衰減因子α、時間停留概率衰減因子β、逆序更新比例p、最終向量表示維度d; 輸出:動態異質信息網絡節點表示X. ①T←getSortedTime(G);/*將圖G中所有時間戳排序放入集合T中供滑動窗口運行*/ ② 初始化walks為空; ③ for 第i次滑動窗口在T上滑動 ④Gi←getValidGraph(T,i); ⑤ 初始化Wvalid為空; ⑥ forGi中每個節點vj ⑦walksj←incrementalUpdateW(Gi, vj,walk,p); ⑧walksj←temporalRW(Gi,vj,walksj); ⑨ 把walksj加入Wvalid; ⑩ end for 本節描述算法中核心的融合類型約束的非遞減時序隨機游走策略,即算法1中的temporalRW函數. 在第2節介紹時間戳陷入問題時已經提到,在現實生活或實際應用中,由于數據標記的時間戳粒度不同,仍然會有在同一時間戳上新增的邊;并且在動態異質網絡中,由異質節點形成的強語義局部結構上的邊往往具有相同的時間戳.因此,為了更好地保留時間信息,基于時間戳約束的隨機游走算法應允許游走過程中停留在當前時間片,同時需要解決允許時間停留引起的時間戳陷入問題.因此,我們提出了一種基于歷史游走信息的非遞減時序隨機游走的策略. 非遞減時序隨機游走是指在給定無向實時動態網絡G=(V,E,Γ)上,沿著時間戳非遞減有序的方向選取邊進行隨機游走.所形成的節點序列{v1,v2,…,vl}滿足3個條件: 1) 對于任意1≤i 2) 對于任意1≤i 3) 選擇Γ(vi,vi+1)=Γ(vi+1,vi+2)的概率隨著在同一時間戳上連續停留次數的增加而降低. 上述時序游走策略中的第3點要求即是為了解決時間戳陷入問題而設計的.當網絡中的節點沒有足夠多的滿足時間條件的鄰居,或者同一時間戳的邊數遠遠多于更遠時間戳的邊數時,如果不限制時間停留概率,就很容易造成時間戳陷入問題,在局部節點之間徘徊,從而損害模型性能. 式(1)描述了節點v在時間戳ti中停留的概率, (1) 如圖4所示,不同形狀分別表示不同類別的節點.當前節點v的上一跳節點為節點u,當前游走時間戳為t1,且已n次停留在時間戳t1,則v的下一跳仍選擇時間戳t1邊的概率為βn,選擇大于t1的時間戳的概率為1-βn.由于當前節點上的邊具有多個時間戳,令Tv表示v上大于t1的所有時間戳集合,Tv={t2,t3}.下一跳選擇Tv中任一時間戳的概率為(1-βn)/|Tv|. Fig. 4 Sample of non-decreasing temporal random walk圖4 非遞減時序隨機游走示意圖 隨機游走的引導策略基于以下2個原則:一是隨機游走中采樣的邊要滿足邊上時間戳非遞減的條件,以保留網絡的時序信息;二是要滿足異質網絡類型選擇的要求. 在采用不同的時間和異質信息約束的情況下,二者共同作用的方式有所區別.受文獻[28]啟發,這里我們采用基于歷史游走類型進行有偏類型選擇的策略,以避免元路徑約束過于嚴格,和時間約束相疊加后,滿足條件的序列長度短的問題.并且我們還采取折中方案,優先考慮時間約束,在滿足時間約束的前提下盡可能在類別約束引導下前進. 式(2)描述了在下一跳選定時間戳ti的前提下,節點v下一跳仍在類別l中停留的概率: (2) 其中,l為節點v的類別,Nv(ti,l)為時間戳ti節點v的類別為l的鄰居,Nv(ti)為在時間戳ti與v相連的所有鄰居,m為序列在當前類別下已游走的長度,α為控制停留在當前節點相同域的概率衰減速度參數.α越大則游走越傾向于停留在相同的節點類別中,α越小則游走越傾向于探索其他類別的節點.本文中,為良好保留動態異質網絡的類別信息,參考JUST[28]中參數設置,α=0.2. 以圖4為例,當節點v已選定下一跳時間戳t2后,將在該時間戳下的鄰居中進行節點類別的選擇.令Lv表示該時間戳下v的鄰居類別集合,且不包含v自身的類別l1.若節點v不具有類別為l1的鄰居時,從Lv中任選一個類別;若v只有類別為l1的鄰居時,選擇類別l1;若v既有類別為l1的鄰居,還有其他類型的鄰居,且已停留在l1類別m次,如圖4所示,則仍選取類型l1的概率為αm,選擇其他類型的概率為1-αm.由于可能存在多種其他類別,因此選擇其中某類別的概率為(1-αm)/|Lv|. 本節描述的時序非遞減的方法,能夠解決動態異質網絡中隨機游走的時間戳陷入問題,引入類型約束以同時捕捉網絡的時間和異質特征,并設計折中策略以平衡時間和類型信息的重要性,防止由于約束過于嚴格而導致的游走序列過短問題. 在本節中,我們將討論模型中使用的增量策略.正如在算法框架中所述,TNDE選定需要以增量的方式更新的游走序列,即函數incrementalUpdateW,包括需要接續游走和逆序游走的序列位置,對其應用上述時序隨機游走策略進行增量游走;最后將更新后的相關游走序列作為增量Skip-Gram的輸入,即函數incrementalSkipGram. 3.3.1 增量游走更新incrementalUpdateW 首先介紹增量游走的工作原理.一方面由于實時動態網絡中歷史信息對節點嵌入的影響需要得到保留,增量式更新游走序列能夠減少歷史信息的計算開銷;另一方面事件的影響具有時間衰減效應,近期頻繁發生的事對當前狀態的影響更大,因此需要處理3個問題:如何沿著現有的路徑繼續游走,如何剔除現有路徑中的失效數據,如何保持最新的數據始終被學到. 為了滿足增量游走的要求,首先對于每個節點,算法維護了一組由節點ID標識的游走序列.在隨時間增量式更新游走序列的過程中,每條由節點ID標識的序列反映了與該節點相關的變化,這些序列對影響其對應節點的網絡變化敏感. 每條序列可以看作是一個隨著游走不斷進行而不斷滑動的滑動窗口.為了在處理接續游走和無效數據丟棄時節省時間和空間,我們將一個序列劃分為多個子窗口,子窗口的長度為LW.對于每個子窗口,只需要記錄其中最新的邊時間戳和節點類型.當子窗口中最新的時間戳無效時,整個子窗口內的序列將被丟棄.由于我們將一個子窗口作為一個操作單元,忽略了子窗口中各個具體的時間戳和節點類型等細節,因此LW越大,算法的成本越低.在本文實驗中,我們使用LW=2作為默認值. 網絡中發生的變化包括節點或邊的產生和消失.變化影響的區域是變化部分的直接連接節點.當網絡中的滑動窗口移動,新的時間片到達時,對于未受變化影響的節點,由節點ID標識的現有游走序列剔除失效數據,其他保持不變.而對于受變化影響的節點,更新相應的、以其節點ID標識的游走序列.序列的增量式更新策略主要包括以下4種,分別對應圖3中標號:Ⅰ.無變化序列保留,Ⅱ.剔除現有序列中的無效節點和邊,Ⅲ.延續現有游走序列,Ⅳ.在新的時間片上逆向游走生成序列. Ⅰ. 無變化序列保留,即對于不涉及變化的序列保持不變. Ⅱ. 剔除現有序列中的無效數據是針對網絡當前所有有效節點的對應序列,以序列子窗口為單位,檢查子窗口時間戳是否已過期失效.若失效,則整個子窗口丟棄. Ⅲ. 延續游走序列同理,在需要進行延續的序列上,檢查最新子窗口的時間戳和類別信息,應用3.2節中介紹的時序游走策略,在現有序列基礎上進行游走. Ⅳ. 在新的時間片上逆向游走則是為了保證能夠學到更新的數據.這里提到的逆向游走就是非遞減時序游走的反向過程.正向游走是從歷史信息沿著時間戳非遞減的方向往近期游走,而逆向游走則是從當前時刻沿著時間戳非遞增的方向往歷史數據游走.為了捕捉最新的演化信息,保持歷史信息的效果,并且不增加過多的計算成本,我們設置參數p來控制新變化節點開始的反向游走的比例.本文根據實驗經驗設置p=0.2,以保證運行時間與準確度的平衡. 由于動態場景下,網絡連接變化靈活,因此在不同情況下逆向游走序列的更新數目也不同.令每個節點標識的游走序列數為r,則r×p為反向游走的標準比例.式(3)所示為節點v標識的r條游走序列中需要逆序游走更新的序列數: (3) 其中,newC為當前節點v上有效邊數,oldC為節點v標識的序列中尚未完全失效的歷史游走序列數.即當有效邊數較少,與歷史序列之和未達到序列總數上限或有效邊數未達到標準比例r×p時,逆向游走生成newC條序列;當有效邊數和歷史序列數都較多,均能超過其對應標準比例r×p和r-r×p時,生成標準比例數目的逆向游走序列r×p條(取整);其他情況即為有效邊數較多而歷史序列數較少,但其二者之和超過序列總數上限,則生成r-oldC條逆向游走,使序列總數達到上限,盡可能利用空閑空間. 3.3.2 增量表示學習incrementalSkipGram 在增量式更新游走序列后,我們將更新后的節點涉及的序列輸入增量式Skip-Gram模型進行節點增量表示學習,即函數incrementalSkipGram.該模型建模網絡中的變化節點帶來的影響,沿用前次Skip-Gram訓練后的模型參數,對變化的節點序列增量式進行表示學習,模型Loss函數為 (4) 為了評估TNDE嵌入算法的性能,驗證模型效用,在本節中,我們選取了4個代表性對比算法和TNDE進行比較,在3個真實數據集中評估它們在鏈路預測和節點分類這2個下游任務中的性能.所有算法均使用Python實現,運行在一臺配備Intel Core i7 3.40 GHz處理器和64 GB內存的機器上.本文已公開TNDE的源代碼(1)https://github.com/guaw/TNDE. 實驗選取3個不同領域、不同大小且具有不同結構的數據集,表1為它們的統計信息. Table 1 Information of Datasets表1 數據集信息 DBLP.文獻[37]提供了DBLP數據集的許多版本.我們選擇了2014年5月的DBLP集合,使用了其提供的10個領域子集數據.該網絡由“發表”和“合著”信息組成,其中節點類型包括作者(A)和會議(C),A-C和A-A形式的邊分別表示發表和合著關系,其局部結構上具有強語義信息.邊上的時間戳代表建立關系的年份,時間戳數量較少且粒度粗,每一時間片內的平均邊速率高. Enron.該數據集由文獻[38]提供,是從安然公司收集的電子郵件通信網絡.該網絡包含了公司內部115名員工之間發送的43 160封郵件,具有豐富的類型信息.節點類型是員工的職位,每條邊上的時間戳表示郵件的發送時間.為便于后續描述,我們用1~9的數字代替具體文本來表示每個不同的節點類型. TKY.該數據集文獻[39]是由FourSquare提供的用戶在東京的簽到數據.節點類別包括用戶(U)和地點(P)兩類,每條邊上的時間表示用戶在某地簽到的時間.該網絡為二部圖,具有豐富的細粒度時間戳信息,并具有一定數量的相同時間片上的邊. 由于當前流行的基于圖神經網絡的算法時間復雜度較高,難以適應實時動態網絡的嵌入要求,例如目前最先進的針對動態同質網絡嵌入的DySAT[40]和針對動態異質網絡嵌入的LIME[41],其時間復雜度遠高于其他基于隨機游走的模型方法.因此我們選擇以下4種不同的基于隨機游走的對比方法進行比較,靜態異質網絡嵌入方法JUST、分別針對實時動態和快照的動態同質網絡嵌入方法CTDNE和ISGNS、針對快照的動態異質網絡嵌入方法Change2vec.上述方法的時間復雜度如表2所示,其中采樣和嵌入分別表示模型在對應階段的時間復雜度. Table 2 Time Complexity表2 時間復雜度 為保證公平性,實驗過程中各方法涉及到的所有通用參數均保持一致,節點向量的維度d=128,從每個節點或(在CTDNE中)從每條邊出發的游走輪數r=10,游走序列最大長度l=80.考慮到不同數據集的時間戳數量和粒度,在各方法實驗過程中,對于不同數據集滑動窗口的設置為:在Enron上滑動步長為5,共滑動4次;在DBLP上滑動步長為10,共滑動5次;在TKY上滑動步長為10 000,共滑動56次.對于靜態網絡嵌入方法,則在滑動窗口每次移動后的位置對當前網絡快照進行表示學習;對于針對快照網絡的方法,則學習各相鄰快照之間的差異信息. JUST[28]是一種靜態異質信息網絡嵌入方法,基于類別信息能夠動態調整游走偏好的類別.為了更好地捕捉節點的類別信息,游走類別初始停留概率參數α=0.2,使得游走過程中算法傾向于經過異質邊探索新類型的節點,而少有比率選擇同質邊進而停留在當前節點類別.其余參數均選取原作默認設置.為保證實驗公平性,TNDE中對應的類別停留參數α也設置為0.2. CTDNE[3]是一種實時動態同質網絡嵌入方法,其中隨機游走以邊為角度進行組織,按照時間戳嚴格遞增順序選取下一條邊.每條游走序列最小長度w=5,算法中批量更新的大小與滑動窗口滑動步長保持一致,以保證CTDNE能夠在有限時間戳數量的網絡中生成符合要求的游走序列,且序列不過短. ISGNS[31]是一種針對快照的動態同質網絡嵌入方法,該算法游走階段采用node2vec中的策略.超參數按照node2vec默認設置為p=1,q=1. Change2vec[35]是一種針對快照的動態異質網絡嵌入方法,使用元路徑引導隨機游走.為保證元路徑選取的質量,各數據集上使用的元路徑均基于該數據集語義進行選取,并且考慮到選取不同元路徑對于模型方法效果的影響,在實驗中綜合考慮了多條元路徑進行隨機游走.具體來說,對于DBLP,我們使用元路徑ACA和CAC來引導從每個節點開始的隨機游走.對于TKY,使用UPU和PUP來引導.對于Enron,由于其節點類型多,尋找具有良好語義信息的長元路徑比較困難,我們針對不同類型選擇了一系列短元路徑:1-2,2-3,3-4,4-5,5-6,6-7,7-8,8-9,9-1.這些元路徑表示的是2個職位的員工之間頻繁的溝通關系,并且這樣選取元路徑能夠保留圖中類別之間的整體關聯性,沒有將網絡根據不同類別完全分割成互不相連的域. 在實時動態網絡中,對網絡嵌入的需求會隨時、頻繁地發生,因此,為了滿足動態網絡嵌入的需求,算法的運行時間非常重要.在保證下游推斷任務具有良好準確度的前提下,算法的時間成本越低越好.因此在本節中,我們首先對TNDE和其他4種對比方法所需的運行時間進行了評估.表3為各方法分別在3個實驗數據集上的運行總時間. Table 3 Runtime表3 運行時間 s 從表3中可以看出,靜態模型JUST和基于邊視角組織游走的動態方法CTDNE在表示學習上花費的時間較多.每當需要獲得嵌入的時候,靜態模型都要在當前全圖上運行,完全重新訓練模型.因此,從實驗結果也能夠看出,靜態方法JUST在各數據集上的時間開銷均為最大,和其他動態方法的運行時間相差1~2個數量級.靜態方法應用在動態網絡嵌入問題上,由于其運行時間過長而難以適應動態網絡嵌入在時間實時性方面的需要,因此后續推斷任務準確度不再與靜態方法進行對比. 而對于CTDNE,每當一定量新邊到來時都會嘗試多次隨機游走,保留滿足長度要求的序列,即嘗試生成的序列數為網絡中邊的倍數.但實時動態網絡中允許相同節點對之間具有平行邊,這意味著邊數可以遠大于節點數.因此,CTDNE比我們基于節點視角的游走花費的時間有數量級的增長,尤其是在邊密集的網絡上,例如平均節點度為750.61的Enron.在該網絡上CTDNE的運行時間高達靜態方法JUST的19倍、動態方法的數百上千倍. 根據表3運行時間結果和下游任務準確度(4.4節)可知,與對比方法相比,Enron數據集上,TNDE方法取β<0.9的情況下所需時間均為最短,且鏈路預測指標AUC達到0.77~0.91,與對比方法相當,甚至有所提升;鏈路預測指標Micro為0.24~0.32不等,弱于Change2vec但與另2種動態同質網絡嵌入方法相當.在DBLP和TKY上,TNDE取β=0用時僅次于Change2vec方法,相比另2種動態同質網絡嵌入方法運算時間降低了39.06%~97.46%.雖然在DBLP和TKY上,應用Change2vec所需要的時間比TNDE短,但從4.4節展示的實驗結果可以看出,它在下游任務中幾乎沒有表現出歸納能力,而TNDE方法在下游任務中具有出色的歸納結果.因此,綜合考慮算法運行時間與下游任務準確度,TNDE在不同數據集上具有良好的通用性,綜合表現最優,可以在保持歸納性能的前提下,大大縮短學習嵌入的運行時間. 在本節中,我們針對實時動態異質網絡嵌入方法保留時間信息和異質信息的能力,分別通過鏈路預測和節點分類2個下游任務來進行評估.在分析具體實驗數據之前,我們注意到2個下游任務在一定程度上具有相反的趨勢,即鏈路預測效果出眾的方法,在節點分類上的實驗效果往往欠佳.其原因在于鏈路預測任務是通過邊的2個端點向量的相似度來判斷未來是否會出現這條邊,兩端點向量的余弦相似度越大,未來節點間產生連接的可能性就越大;節點分類任務則恰恰相反,是通過節點向量之間的距離來劃分不同的類別,節點相似度越高,被歸入同一類別的可能性就越大. 而值得注意的是,在異質網絡中,無論是動態還是靜態,經常發生關聯的節點通常分別屬于不同的類別.因此,當嵌入模型在鏈路預測任務中表現良好時,意味著2個屬于不同類別的端點在嵌入空間中很接近,使得分類器很難準確地分辨它們,從而導致在節點分類任務中表現不佳,反之同理. 4.4.1 鏈路預測 為模擬實時動態網絡嵌入在鏈路預測任務中的動態變化情況,每組數據集上的實驗隨著滑動窗口的每次滑動進行評估.由于TKY數據集時間片數量多,窗口滑動次數多,因此我們將每滑動10次的位置作為一個時間點,從中選取了5個重要的時間點,報告該時刻網絡的鏈路預測指標.實驗使用當前時刻下網絡的嵌入表示,計算節點之間的余弦相似度,使用從當前時間點到下一次評估的時間點之間的數據作為測試集正例,從網絡中抽取與正例等量的負例共同組成測試集,并使用AUC來評估當前時刻鏈路預測結果的性能.AUC值越高,說明鏈路預測結果越好;AUC越接近0.5,表示鏈路預測效果越差,接近隨機預測.實驗報告了各評估時間點上的AUC,以及AUC的平均得分,結果如表4所示,報告了TNDE在β控制下的最優結果,其中在DBLP和Enron上取β=1,在TKY上取β=0.5. Table 4 AUC of DBLP Link Prediction表4 DBLP鏈路預測指標AUC 根據表4數據并綜合考慮算法的運行時間可以看出,在時間明顯縮短的條件下,TNDE仍然可以取得良好的鏈路預測效果;并且,通過調節時間停留概率參數β,能夠在犧牲一定時間效率的情況下取得較大的性能提升.同為處理動態異質網絡嵌入的Change2vec表現最差,盡管其運行時間短,但在DBLP和TKY上幾乎沒有推斷能力. 在TKY數據集下,TNDE方法選取β=0.5時的實驗結果,其時間開銷與CTDNE相當,AUC提升了2.4%,與ISGNS和Change2vec相比提升了15.2%~47.5%.并且在算法取β=0,即時間開銷遠低于CTDNE和ISGNS的情況下,TNDE的AUC仍能達到0.700,比ISGNS和Change2vec高3.1%~32.0%. 在DBLP數據集下,實驗報告了TNDE模型取β=1時的結果.相比ISGNS,AUC降低了9.5%,但其時間效率提升了12.5%;相比CTDNE,AUC提升了30.5%,運行時間效率提升了49.7%. 在Enron數據集下,表4中報告了TNDE取β=1的情況,運行時間略有升高但能取得3.5%~18.5%的鏈路預測性能提升,β=0.9的情況下,運行時間略有下降,AUC仍能達到0.915,有2.5%~17.4%的提升. 4.4.2 節點分類 本節中使用邏輯回歸分類器進行節點多標簽分類任務.數據集按時間戳順序被分成2部分,前75%作為訓練集,后25%作為測試集.每組實驗重復5次,并分別報告Macro-F1和Micro-F1的平均分數以評估分類效果[42].分數越高,說明嵌入在節點分類任務中的性能越好.實驗結果如表5所示,其中報告了TNDE在β控制下的最優結果,在DBLP,Enron和TKY上β分別取0.5,0.8和0.9. 從表5中可以看出,Change2vec方法在DBLP和TKY數據集中分類表現欠佳,但其在Enron數據集上明顯高于其他算法.這是因為Change2vec算法在抽取快照間差異后,在其上進行了基于元路徑引導的隨機游走.由于指定元路徑能夠人為地干預隨機游走中游走路徑的選擇,使得所生成的序列將指定元路徑中相關聯的節點聚集得比較近,而沒有通過元路徑關聯起來的節點類型離得很遠.因此,在DBLP和TKY兩個具有明顯局部結構、節點類別較少的網絡中,元路徑帶來的積極影響不突出.而在Enron數據集中,節點類別較多,且節點類別與網絡拓撲結構之間是弱耦合的關系,則指定元路徑的游走方式能更好地協助模型生成具有良好分類能力的節點嵌入.TNDE在Enron數據集上僅次于Change2vec算法,且在另外2個數據集上都能取得最好的節點分類結果. Table 5 Macro-F1 and Micro-F1 of Node Classification表5 節點分類指標Macro-F1和Micro-F1 由于不同類別的節點數量存在差距,Macro-F1指標的差異更為明顯.在DBLP數據集上,表5報告了TNDE取β=0.5下的實驗結果,與各對比方法相比,Macro-F1能夠提高7.9%~60.6%,且從表3可以看出,與ISGNS和CTDNE相比,算法運行時間降低92%~95.4%.在Enron中,TNDE取β=0.8,雖然Macro-F1低于Change2vec,但相比CTDNE和ISGNS兩種動態同質網絡方法有27.5%~50.2%的提升,且算法運行時間為3.22 s,比3種對比方法用時下降了28.4%~99.91%.在TKY數據集上,TNDE取β=0.9,Macro-F1能夠提高11.4%~92.7%;考慮到算法運行時間,β=0時算法運行時間效率相比ISGNS提升了39.1%,盡管Macro-F1相比ISGNS下降了14.95%,但仍能達到0.723,且比CTDNE和Change2vec仍有38.3%~47.1%的提升. 從異質性信息的角度考慮,CTDNE和ISGNS方法均針對動態同質網絡,忽略網絡的異質信息,從表5的實驗結果來看,這2種方法在節點分類任務上低于本文方法TNDE,本文方法能夠在Macro-F1上取得7.9%~92.7%的提升,在異質性更強的Enron數據集上表現提升尤其明顯,能夠體現不考慮異質性的信息丟失問題. 綜上所述,與其他對比方法相比,TNDE方法在大多數情況下能夠取得最好的節點分類結果,能夠對動態異質網絡的異質信息進行良好保留,在不同類型的網絡中具有很好的通用性;并且通過調節時間停留概率參數β,能在保證良好分類效果的情況下大大減少算法的運行時間. 4.4.3 小 結 理論分析與實驗結果均顯示,這2個不同的推斷任務由于任務本身特性而難以同時達到最優結果,即在鏈接預測中表現較好的方法在節點分類中往往表現較差,反之同理.實驗還表明,TNDE可以顯著提升鏈路預測和節點分類的準確度,良好保留動態異質網絡的時間和異質信息,并在保證良好鏈路預測和分類效果的前提下,獲得運行時間效率的大幅提升. 4.5.1 參數β影響分析 本節中,我們從算法運行時間、下游任務準確度方面評估了算法中的參數β對嵌入質量的影響.選定α=0.2,將β從0到1分別取{0,0.1,0.3,0.5,0.7,0.8,0.9,1}.圖5~8分別展示了算法運行時間、鏈路預測AUC、節點分類Macro-F1和Micro-F1指標的變化情況.由于不同數據集所用時間差異較大,為了在同一張圖中更清晰地表示算法運行時間在3個不同數據集中的變化趨勢,圖5分別設置了2個時間刻度,左軸為TKY,DBLP所用時間刻度,右軸為Enron所用刻度. Fig. 5 The variation of runtime with β圖5 運行時間隨β變化情況 Fig. 6 The variation of AUC with β圖6 AUC隨β變化情況 Fig. 7 The variation of Macro-F1 with β圖7 Macro-F1隨β變化情況 Fig. 8 The variation of Micro-F1 with β圖8 Micro-F1隨β變化情況 如圖5所示,算法運行時間隨著β的增大而增加.其主要原因在于,參數β決定了初始狀態下,時序游走過程中選擇仍在當前時刻的邊的概率,以及概率的衰減速度.參數β較大則游走傾向于停留在當前時間片的邊中,β較小則游走傾向于選擇更遠的時間點上的邊.由于β的增大實際上是對嚴格增時序約束限制的放寬,允許游走的范圍隨著β而變大,進而生成的隨機游走序列長度也會增長,引起算法運行時間的上升. 實驗數據顯示,在β<0.9時,網絡表示學習時間隨β的增大近似線性增長,而當β逼近1時,算法運行時間陡增.時間陡增的主要原因是,β逼近1意味著網絡中每次進行隨機游走時,有極大的概率選擇當前時間片內的邊,而難以向更遠的時間游走,產生時間戳的陷入,導致游走序列長、算法運行時間長.結合圖6~8的下游任務指標也能夠看出,對于時間粒度細、局部結構具有較少相同時間片的數據集,例如TKY,當β=1時下游任務效果具有明顯下降. 因此,對于時間粒度細、局部結構具有較少相同時間片的數據集則可將β調小,使得游走更傾向于向遠方時間點探索.而對于時間片較少、相同時間戳下具有大量邊的數據集,如Enron和DBLP,則可將β適當調大,以便在相同時間片內的邊上進行較為充分的游走探索.同時注意,由于β逼近1時存在的運行時間陡增和算法性能下降的趨勢,β可調至0.8左右,以保證算法在運行時間和嵌入質量上均具有良好表現. 4.5.2 參數α影響分析 在本節中,我們同樣從算法運行時間、下游任務準確度方面評估了算法中的參數α對嵌入質量的影響.實驗選定β=0.7,將α從0到1分別取{0,0.2,0.4,06,0.8,1}.圖9~12分別展示了算法運行時間、鏈路預測AUC、節點分類Macro-F1和Micro-F1指標的變化情況.由于不同數據集所用時間差異較大,為了在同一張圖中更清晰地表示算法運行時間在3個不同數據集中的變化趨勢,圖9分別設置了2個時間刻度,左軸為TKY,DBLP所用時間刻度,右軸為Enron所用刻度. Fig. 9 The variation of runtime with α圖9 運行時間隨α變化情況 Fig. 10 The variation of AUC with α圖10 AUC隨α變化情況 Fig. 11 The variation of Macro-F1 with α圖11 Macro-F1隨α變化情況 Fig. 12 The variation of Micro-F1 with α圖12 Micro-F1隨α變化情況 如圖9所示,算法運行時間隨著α的增大而基本持平,在節點類別較多的Enron數據集上,運行時間隨α的增大而略有下降.其主要原因在于,參數α決定了初始狀態下,時序游走過程中下一跳仍選擇當前類別節點的概率,以及概率的衰減速度.參數α較大則游走傾向于選擇仍為當前類別的節點,α較小則游走傾向于選擇不同類別的節點.由于α的增大實際上是傾向于游走中選擇相同類別的節點,在少類別的數據集中對游走過程允許范圍的影響較小,進而對生成的隨機游走序列長度影響較小,因此算法運行時間基本持平.而在Enron數據集中由于類別更多,當α增大時,傾向于在相同類別間游走,減少了跨越不同類別的游走,因此算法運行時間略有下降. 在實驗設置中,鏈路預測任務是面向未來鏈接的預測,其主要考察模型嵌入對于網絡動態演化模式、動態信息的建模和保留能力;而節點分類任務面向節點的類別進行劃分,主要考察模型嵌入對于網絡類別信息,即網絡異質信息的建模和保留能力. 由圖10能夠看出,面向網絡動態演化模式的鏈路預測任務對于調節類別的參數α不敏感.僅在α逼近1時,由于將游走約束在一類節點上,忽略了不同類別節點之間的關系,從而導致鏈路預測結果下降. 由圖11,12的節點分類結果能夠看出,對于類別較多、不同節點類別間關系松散的數據集Enron來說,隨著α的增大,隨機游走的范圍將逐漸收縮到某一類別的節點,能夠聚集該類別的節點信息,使得相同類別節點的向量表示彼此接近,而不同類別節點的向量表示相距較遠,利于節點分類任務.對于節點類別和邊類別較少的二部圖TKY來說,α對于游走類別影響有限,因此算法時間和下游任務指標對α變化不敏感.對于同樣節點類別較少但分布不均勻的DBLP來說,當α逼近1時,大量游走序列集中在數量較多的A類別節點上,引起分類結果的下降. 因此,對于節點類別較少的數據集,如DBLP和TKY,可將α調小,使得游走更傾向于向不同類別節點探索.而對于類別豐富的數據集,如Enron,可將α適當調大,以便捕獲同類節點之間的關系.需要注意,由于α逼近1時算法性能有下降趨勢,建議在0~0.8對α取值,以保證算法綜合考慮類別信息,在運行時間和嵌入質量上均具有良好表現. 在這項工作中,我們提出了一種基于時序隨機游走的動態異質信息網絡增量表示學習框架TNDE,該框架設計了允許時間停留在當前時間片的非遞減時序隨機游走策略,保留了動態異質網絡嵌入強語義局部結構中的時間信息,并引入基于節點類型的有偏游走概率以保留網絡異質信息.使用更新參數p來平衡最新信息和歷史信息的比例,使用時間停留概率衰減因子β來平衡停留在當前時間和向更遠時間探索的概率,并通過使用子窗口對游走序列進行增量式更新和使用增量Skip-Gram來進行增量式表示學習,降低算法運行成本.實驗結果表明,與靜態異質網絡方法相比,TNDE能夠顯著降低算法運行時間;與其他動態嵌入方法相比,TNDE可以顯著提升鏈路預測和節點分類的準確度,良好保留動態異質網絡的時間和異質信息,并在保證良好鏈路預測和分類效果的前提下,獲得運行時間效率的大幅提升. 作者貢獻聲明:郭佳雯負責論文方法構建、部分對比實驗和論文寫作;白淇介負責部分對比實驗和部分論文修改工作;林鑄天負責部分對比實驗;宋春瑤和袁曉潔提供了論文方法思路指導和論文撰寫指導.1 相關工作
1.1 靜態網絡嵌入
1.2 動態網絡嵌入
2 實時動態異質信息網絡中的基本概念
2.1 問題定義
2.2 時間戳陷入問題
3 基于時序非遞減的增量嵌入模型TNDE
3.1 模型框架
3.2 融合類型約束的非遞減時序隨機游走
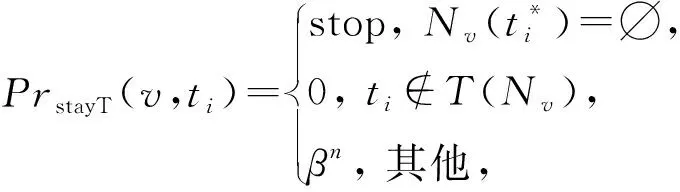
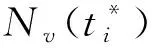
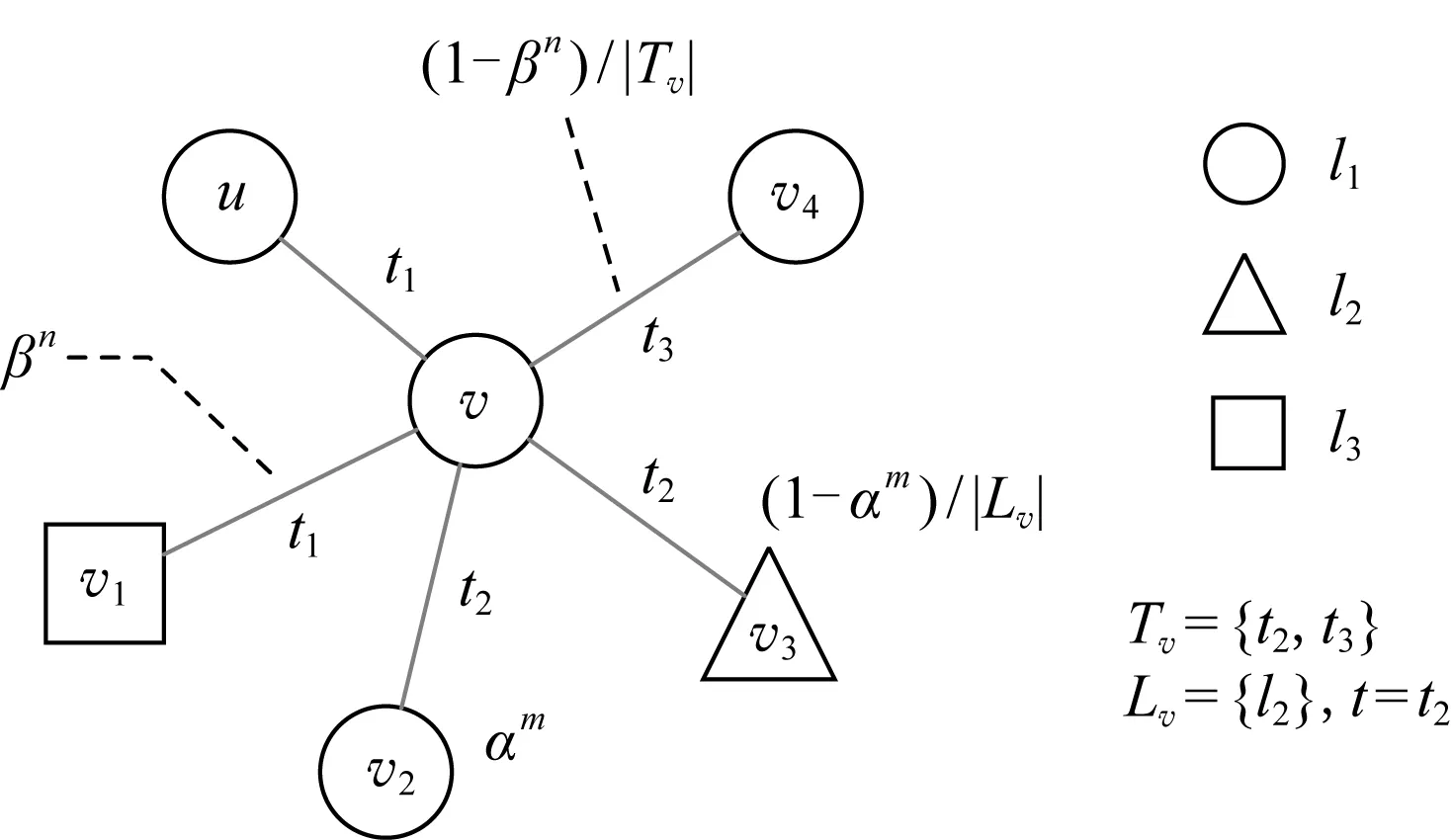
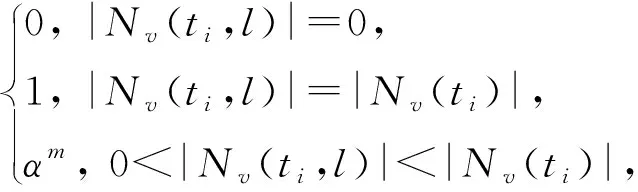
3.3 增量游走更新與增量表示學習策略
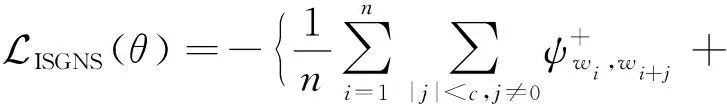
4 實 驗
4.1 數據集

4.2 對比方法與實驗設置
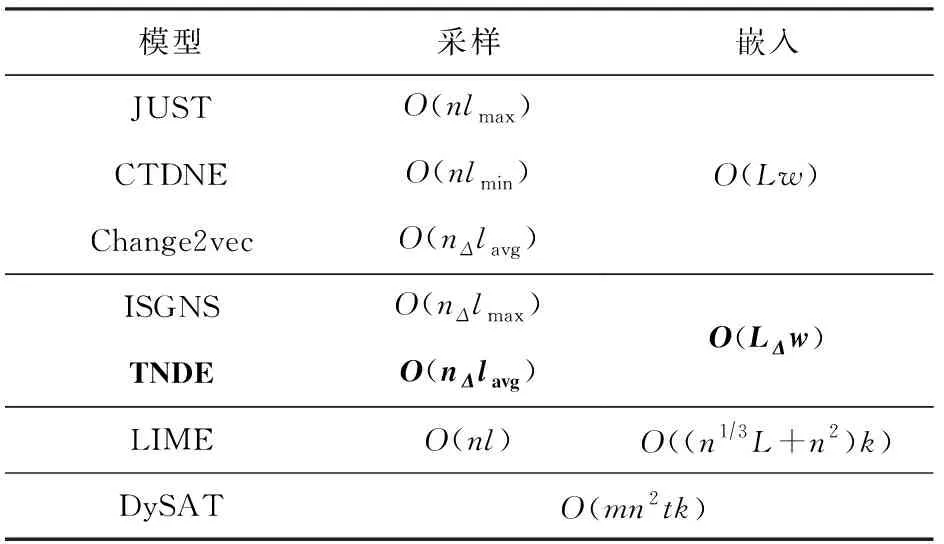
4.3 運行時間
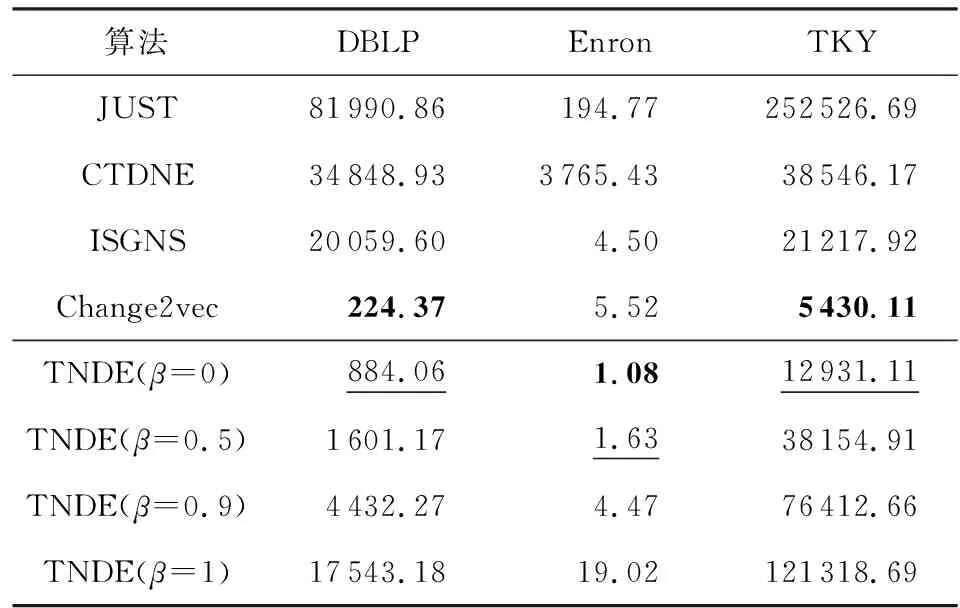
4.4 下游任務準確度對比分析
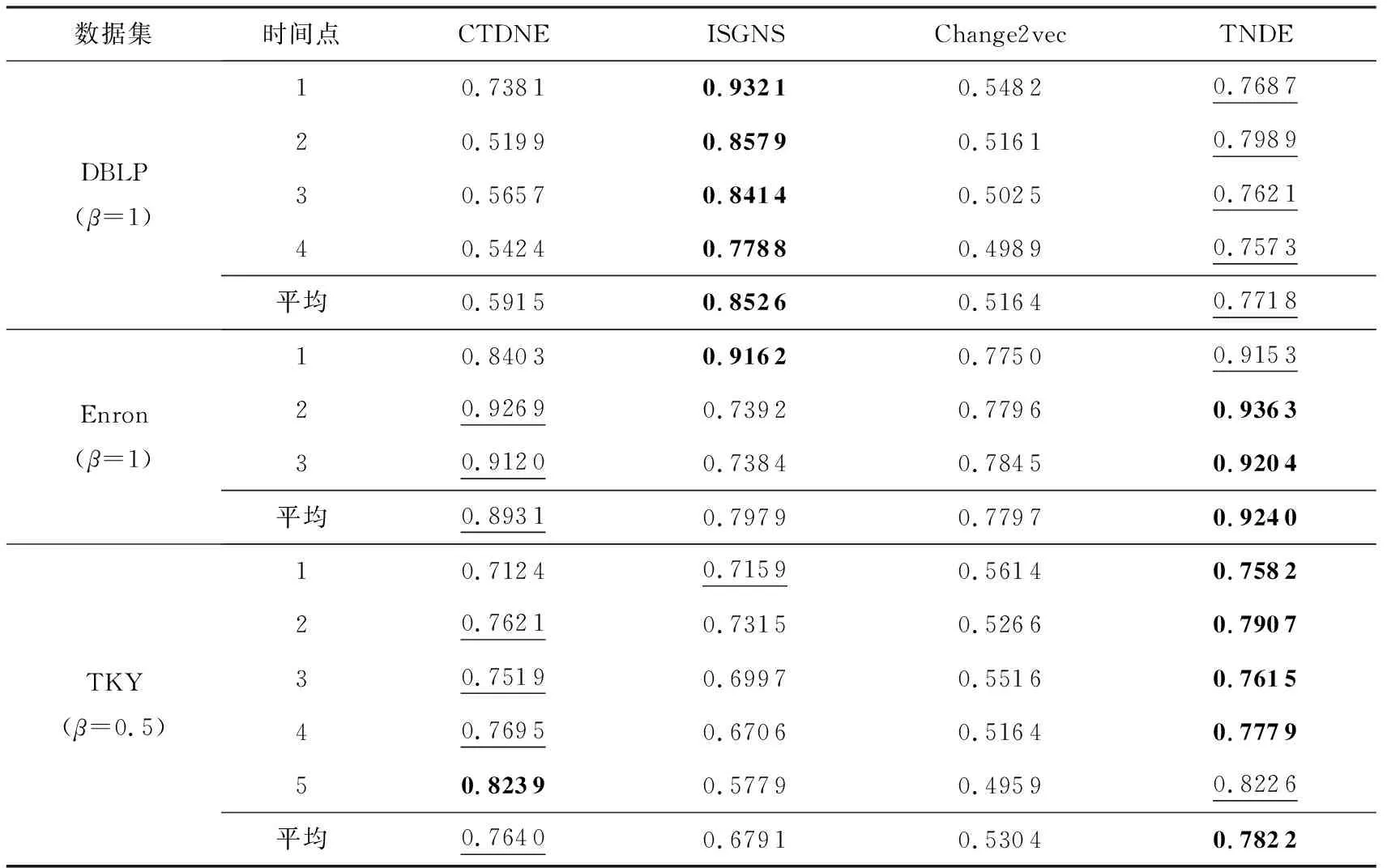
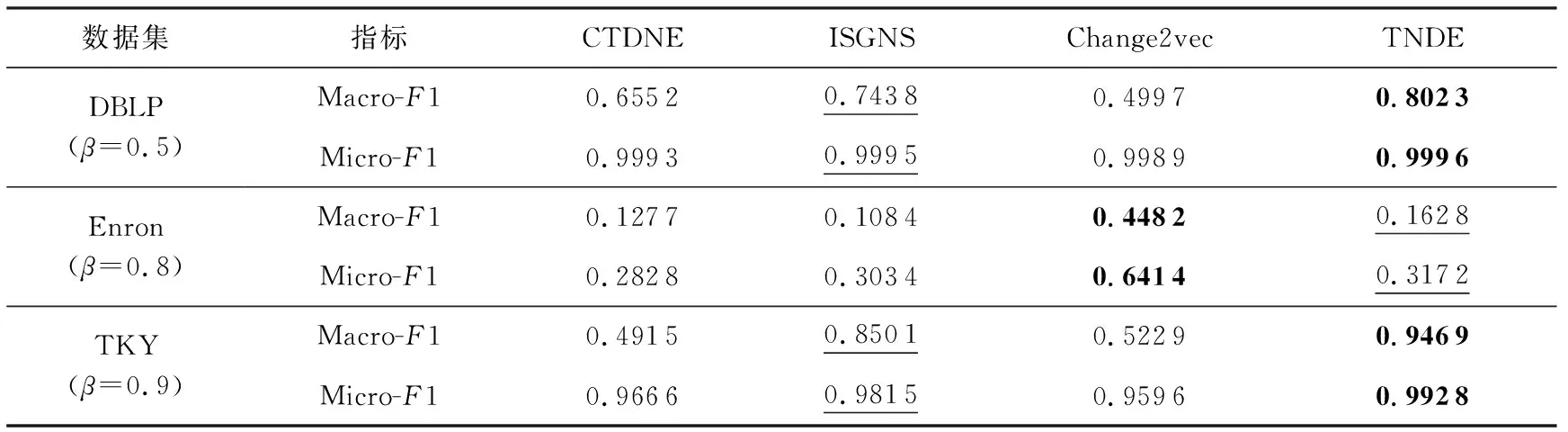
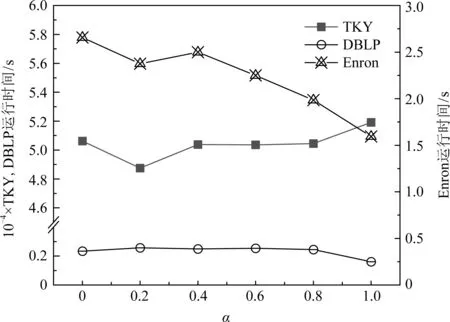
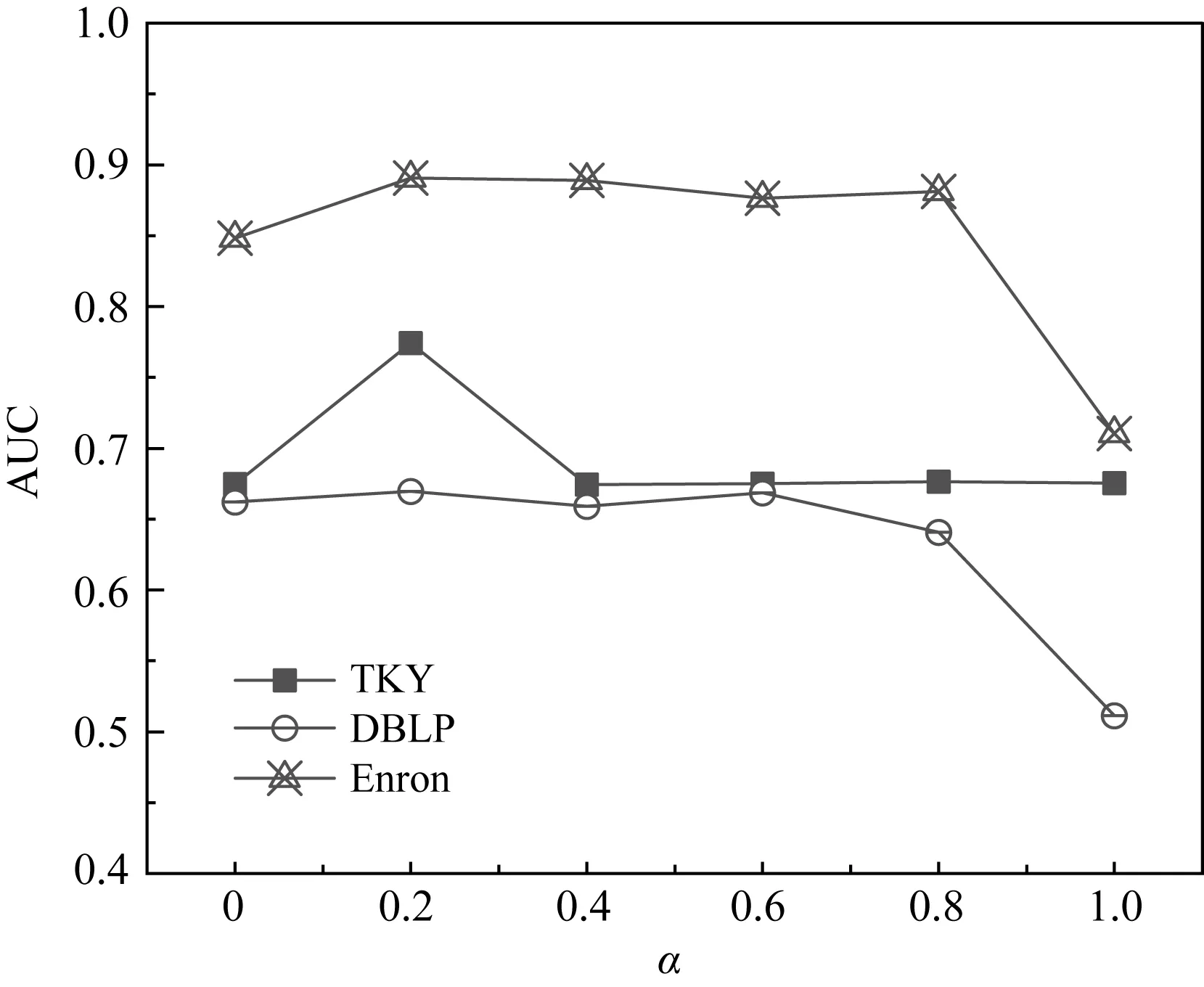
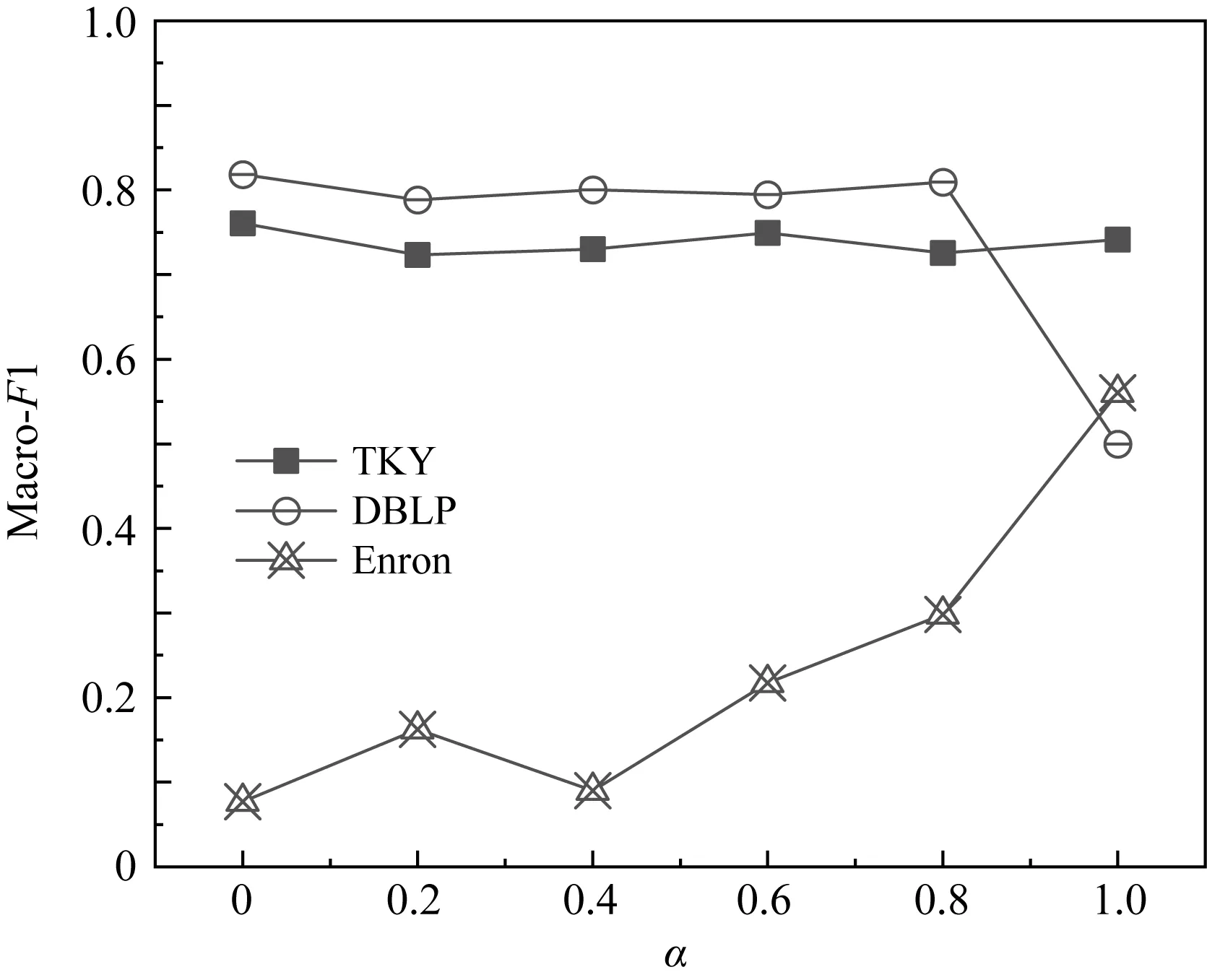
4.5 參數分析
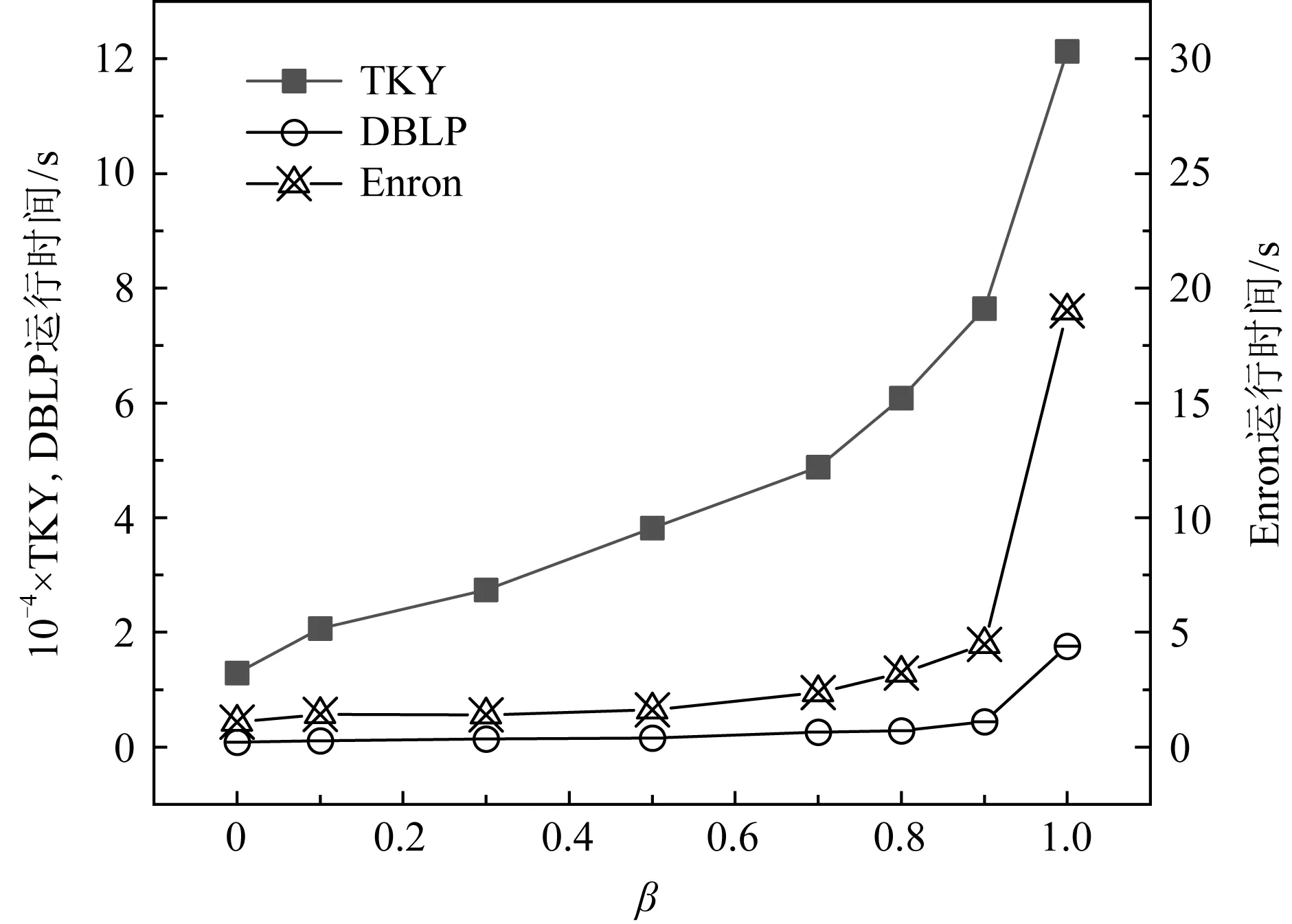
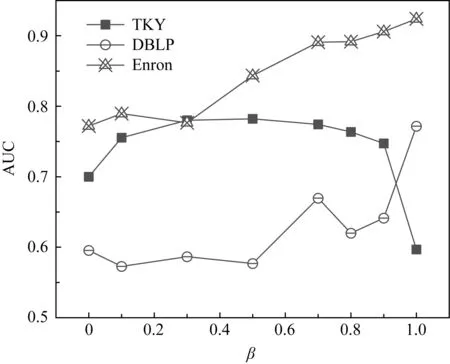
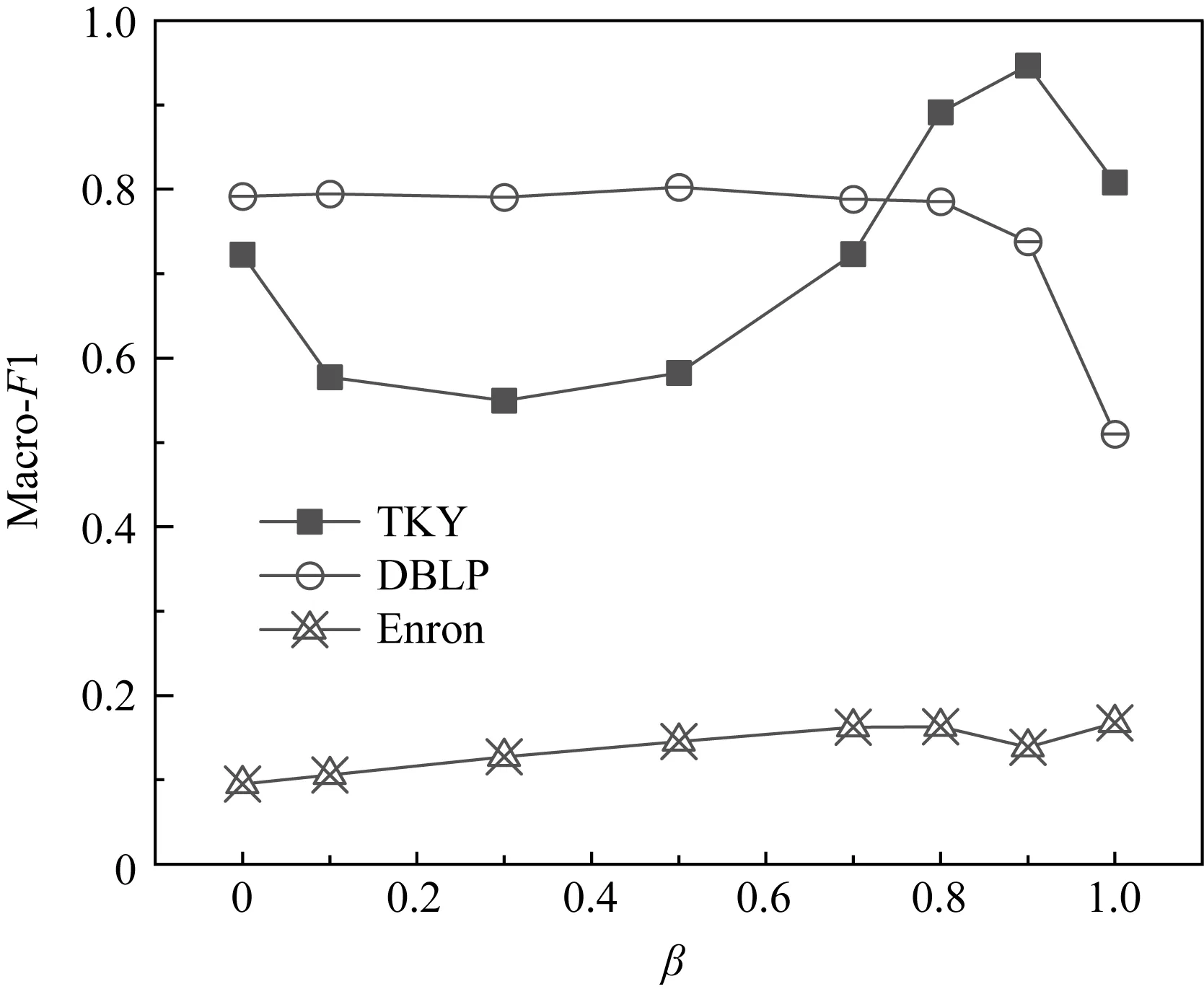
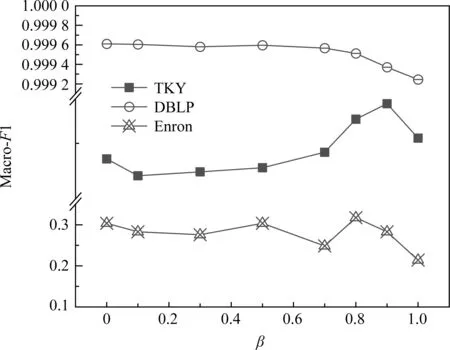

5 結 論
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14中華手工(2017年2期)2017-06-06 23:00:31Coco薇(2016年2期)2016-03-22 02:42:52Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年7期)2015-08-11 15:03:12小雪花·成長指南(2015年4期)2015-05-19 14:47:56中外會展(2014年4期)2014-11-27 07:46:46建筑創作(2001年3期)2001-08-22 18:48:14祝您健康(1987年3期)1987-12-30 09:52:32祝您健康(1987年2期)1987-12-30 09:52:28
