基于K階互信息估計的位置感知網絡表征學習
2021-08-17 00:51:24儲曉愷范鑫鑫畢經平
計算機研究與發展 2021年8期
儲曉愷 范鑫鑫 畢經平
1(中國科學院大學 北京 100049) 2(中國科學院計算技術研究所 北京 100190)
圖(網絡)是節點與邊的集合,其中節點代表了一類特定的事物,而邊則代表了節點與節點之間的關聯.現實世界中的大量數據均可抽象為圖結構數據,比如社交網絡、生物網絡、學術網絡等.為了更好地支持這些基于圖結構數據的應用和分析,如何合理有效地表征網絡節點成為了關鍵所在.傳統的獨熱碼方式(one-hot),由于其空間復雜度會隨著節點規模的擴增而快速增大,嚴重限制了大規模網絡數據處理和分析的能力,并且獨熱碼無法表達節點間的相關性,間接影響了下游任務的效果.近年來,隨著深度神經網絡和表征學習在圖像、自然語言處理等領域取得重大的成功,不少研究者開始關注如何對圖中的節點進行低維表征,使得該表征可以保留網絡節點間的相關性,即網絡表征學習[1-3].現如今,網絡表征學習已經在多種網絡處理和分析任務上證明其有效性,包括網絡節點分類[4-5]、鏈接預測[6-7]、社區發現[8-9]等.
迄今為止,學術界已經提出許多網絡表征學習方法[1,10-11].大部分方法通常關注如何建模節點的近鄰信息.然而,少有方法重視節點的位置信息在表征中的作用.對于每個節點,它相對于網絡中其他節點的最短距離標定了該節點在網絡中的位置.相較于近鄰信息,節點的位置信息包含更寬的感受野和更全面的結構上下文信息,而這類信息在一些與結構分析相關的數據挖掘任務中是至關重要的.如圖1所示,如果只重視近鄰信息,那么用戶(節點)A和B因其直接相連將會獲得相似的節點表征.然而,當我們考慮兩者的位置信息,會發現他們在不同的距離上有著完全不同的鄰居節點,這意味兩者的表征應具有較大的差異性.因此,如果表征模型可以感知到2個節點在各階鄰居上的差異,那么學到的表征將能夠支撐更多與網絡結構或與節點距離相關的下游任務.然而,現有的方法通常只關注節點的近鄰信息,雖然部分方法(如GraRep[12])通過計算節點間轉移概率的方式捕捉中心節點與高階節點間的相關性,但這種方式卻模糊了各階鄰居間的界限,使得模型仍然無法捕捉節點的位置信息.

Fig. 1 The importance of positional information in network embedding圖1 位置信息在節點表征中的作用
為了將節點的位置信息嵌入到節點表征中,本文提出了一種基于k階互信息估計[13-14]的位置感知網絡表征學習模型(position-aware network rep-resentation learning viak-step mutual information estimation, PMI),該模型通過最大化節點與其各階鄰居之間的互信息,從而捕捉到節點的全局位置信息.其直觀解釋在于:處于不同網絡位置的節點,在不同階結構上通常擁有不同的鄰居,因此在模型訓練的過程中,激勵每個節點去分別記住并區別自身在各階的鄰居節點.通過這種方式,模型可以從節點的各階鄰居獲取不同的上下文信息,從而學得更具區分性的節點表征.本文的主要貢獻涵蓋3個方面:
1) 提出了一種基于K階互信息最大化的表征學習模型PMI,該模型不僅可以保留節點的局部結構信息,還可以捕捉節點的全局位置信息;
2) 為了捕捉節點的位置信息,PMI最大化每個節點與其K階鄰居間的互信息,從而讓每個節點能夠識別并記住其各階鄰居;
3) 在4種不同類型的真實網絡數據集上進行多種代表性網絡分析實驗,包括鏈接預測、多標簽分類、網絡重構等.實驗結果表明PMI可以有效地獲取高質量的節點表征.此外,在另一項鄰居匹配任務上的實驗結果表明:相較于現有的工作,本文提出的PMI模型可以有效地捕捉節點的位置信息.
1 相關工作
1.1 網絡表征學習
隨著網絡數據的大規模增加,近年來大量研究者對網絡節點表征開展了研究[1,6,10].本文主要針對同質網絡下的網絡表征學習問題,即節點與邊的類型有且僅有一種.大部分研究類比自然語言和網絡節點在統計特征上的相似性[1],提出基于語言模型的網絡表征學習.文獻[1]提出了DeepWalk模型,首先通過隨機游走(random walks)獲取節點序列,再利用語言模型SkipGram[15]獲取節點的表征.在DeepWalk的基礎上,文獻[10]修改了節點的采樣策略,提出了一種帶偏好的隨機游走策略(biased random walks),該策略權衡了廣度優先搜索(breadth first search, BFS)和深度優先搜索(depth first search, DFS).除此之外,一些文獻也通過直接建模鄰居間的相關性來學習節點表征.基于近鄰相似的假設,文獻[13]著重捕捉一階或二階鄰居間的關系,并采用負采樣策略對大型網絡進行訓練.文獻[12]通過計算節點的K階轉移矩陣來建模高階節點間的相關性,并通過矩陣分解獲取節點表征.一些工作[11]也利用自動編碼機來學習節點表征,通過最小化自動編碼機的輸入和輸出來學習節點的表征.文獻[11]證明這種方式等同于學習節點間的二階關系.不同以上基于近鄰假設的方法,文獻[16]認為空間結構相似的節點在表征空間中也應當相近,基于結構相似性假設,作者建立一個多層次的帶權重網絡來衡量節點間的結構相似性.然而,上述工作均無法捕捉節點的位置信息.針對該問題,本文提出一種基于K階互信息估計的網絡表征學習方法,最大化節點與其各階鄰居間的互信息,讓每個節點能夠記住并識別來自不同階的鄰居,從而將位置信息融入節點表征中.
除了上述針對同質網絡的表征學習方法,一些研究者提出在其他不同類型網絡場景下的表征學習方法,包括異構信息網絡[17-18]、多層網絡[19-20]、符號網絡[21-23]、屬性網絡[24-25]等.此外,一些文獻著手于為不同的應用設計對應的表征學習方法,如社區發現[26-27]、結構識別[28-29]等.近幾年,圖神經網絡(graph neural networks, GNNs)[30-32]成為了屬性網絡表征學習的熱門,其在半監督學習下的圖分類、節點分類等問題上超越了傳統方法,取得了優異的效果.
1.2 互信息估計

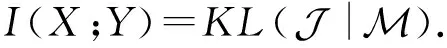
(1)
盡管式(1)在形式上十分簡潔,但它的精確計算僅適用于離散變量或是已明確先驗分布的連續變量,因此,它的適用場景較為有限.為解決該問題,文獻[33]提出一種基于神經網絡的互信息估計模型MINE,利用DV(Donsker-Varadhan)表征推導式(1)的下界:
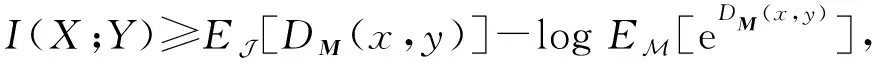
(2)
其中,DM(·,·)是參數為M的雙線性函數,該方法在學習更好的生成模型方面表現出了很強的一致性.
受到MINE的啟發,文獻[14]首次將互信息的神經估計應用到無監督圖像表征學習中,并提出DIM模型.作者認為在很多場景下,并不需要關心具體的互信息值,而更關心變量間互信息的相對大小.因此,DIM模型用J-S散度(Jensen-Shannon divergence)替代K-L散度,并采用一種對抗訓練的方式最大化正樣本間的互信息:

(3)
其中,sp(x)=log(1+ex)為softplus激活函數,變量z為采樣出的負樣本.通過式(3),DIM最終最大化每張圖片的全局特征與其每個像素表征間的互信息,并取得了優異的效果.
受到MINE的啟發,文獻[34]提出模型DGI并首次將互信息估計應用到屬性網絡節點表征學習中,最大化網絡全局表征與節點局部表征間的互信息.而文獻[35]提出了模型GMI,該模型最大化中心節點表征與其一階鄰居屬性間的互信息.本文所提出的PMI模型與上述DGI和GMI模型存在較大的不同,如圖2所示:1)本文針對的是網絡結構表征,并不包含屬性信息;2)本文方法通過最大化中心節點與其各階鄰居間的互信息,從而獲取每個節點的位置信息.
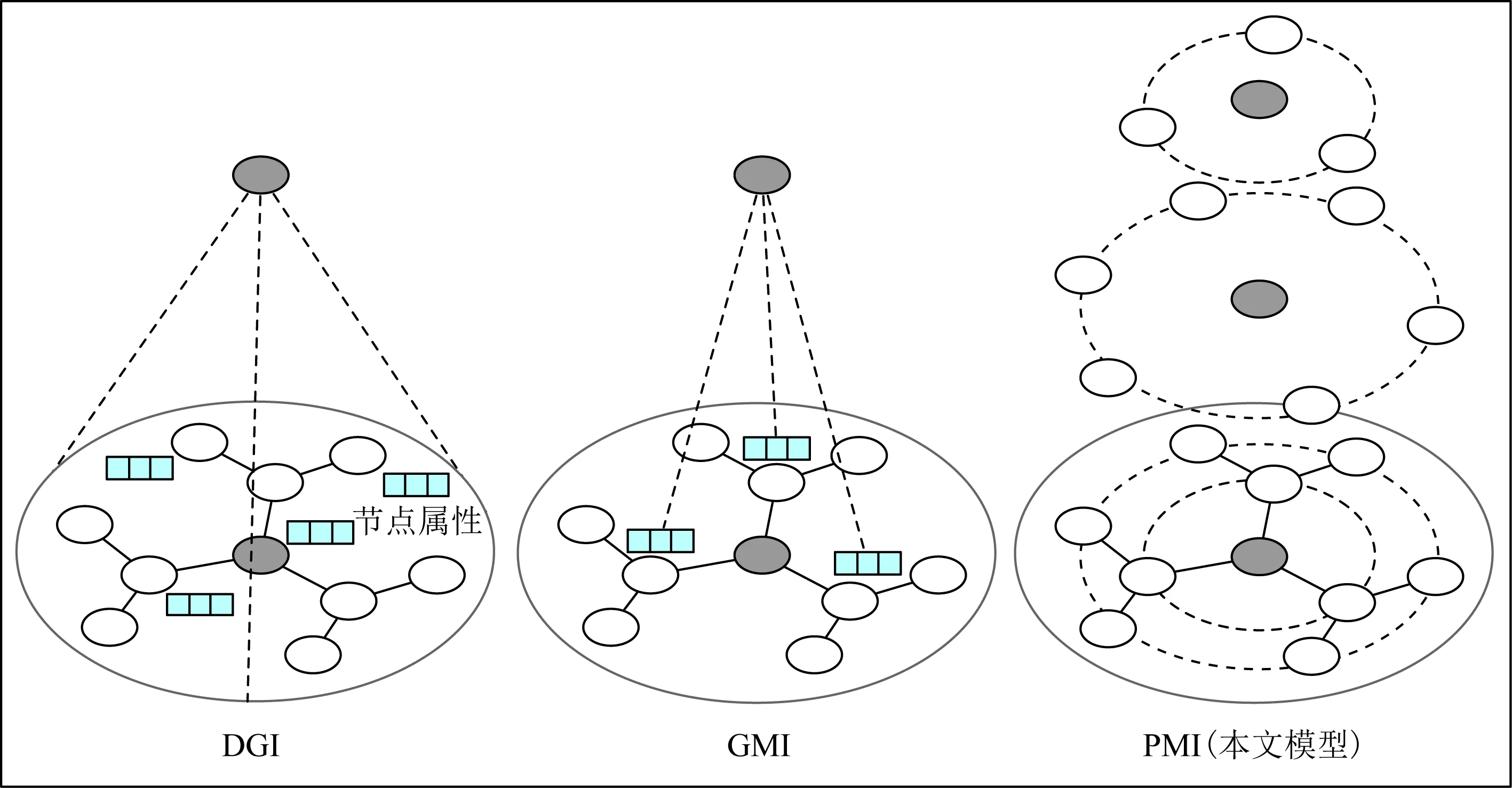
Fig. 2 Difference from current mutual information-based embedding models圖2 本文工作與現有基于互信息的圖表征模型的不同
2 問題定義
首先給出本文方法涉及到的相關定義,表1列出了本文的主要符號以及對應的含義.
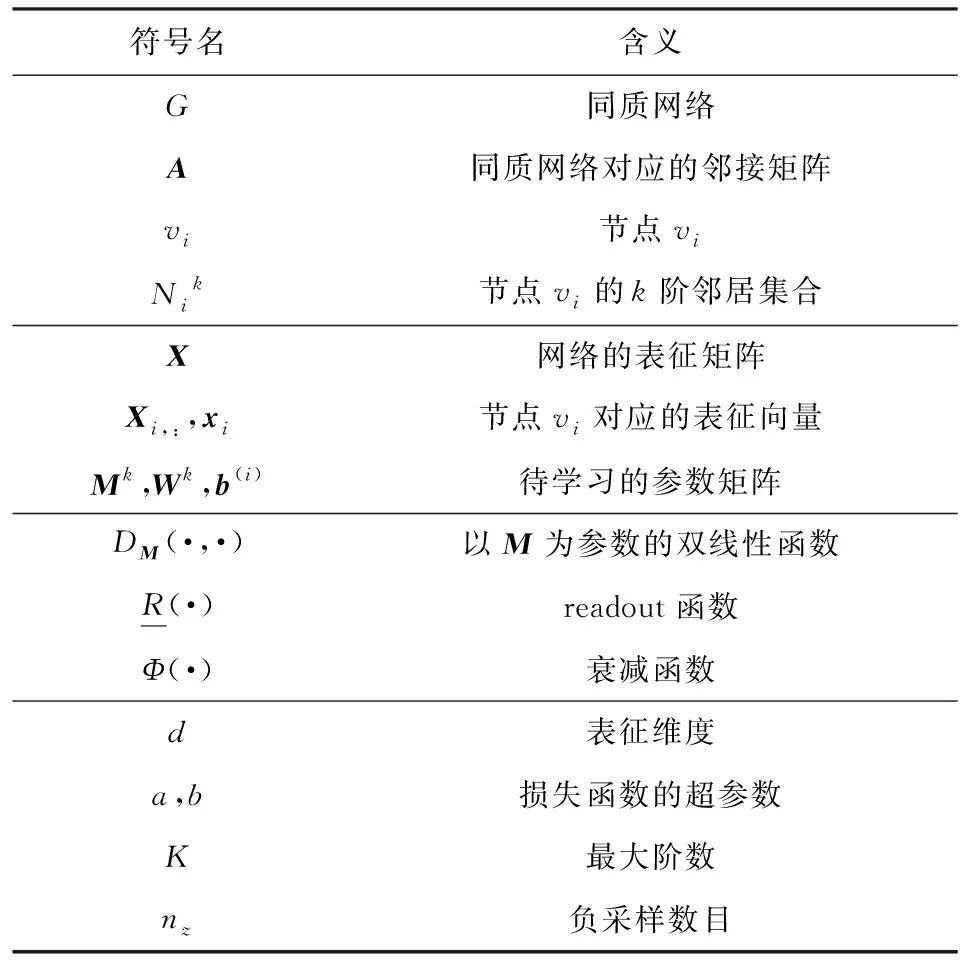
Table 1 Primary Notations and Explanations表1 主要符號和對應含義
定義1.同質網絡.給定一個無向圖G=(V,E;A),其中V={v1,v2,…,vn}代表節點集,E代表邊集合,矩陣A是圖G的鄰接矩陣,其中Ai,j=1當且僅當節點v1和v2間存在一條邊,否則Ai,j=0.
本文方法通過最大化每個節點與其各階鄰居間的互信息學習節點的表征,其中第k階鄰居和網絡表征學習的定義分別如下:
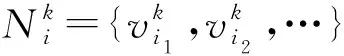
定義3.網絡表征學習.給定圖G,網絡表征學習旨在學習圖G中節點的表征矩陣X∈n×d,其中d是表征維度,其中矩陣的每一行向量Xi,:表示節點vi的表征.在后續的論述中為了簡明起見,也用xi代表vi的表征.
現有的網絡表征學習模型無法學習到節點的位置信息.為了解決該問題,我們認為關鍵在于訓練的過程中,適當地激勵節點記住并區別其在各階上的鄰居節點.為此,我們嘗試將互信息神經估計融入網絡表征學習中,為各種下游分析任務生成位置感知的節點表征.
3 基于互信息估計的位置感知表征學習方法
3.1 總體框架
如圖3所示,本文提出的PMI模型主要分為2個模塊:1)K階互信息估計模塊用于捕捉每個節點的位置信息;2)網絡重構模塊用于學習網絡的基本結構信息.因此,最終優化函數也分為2部分:
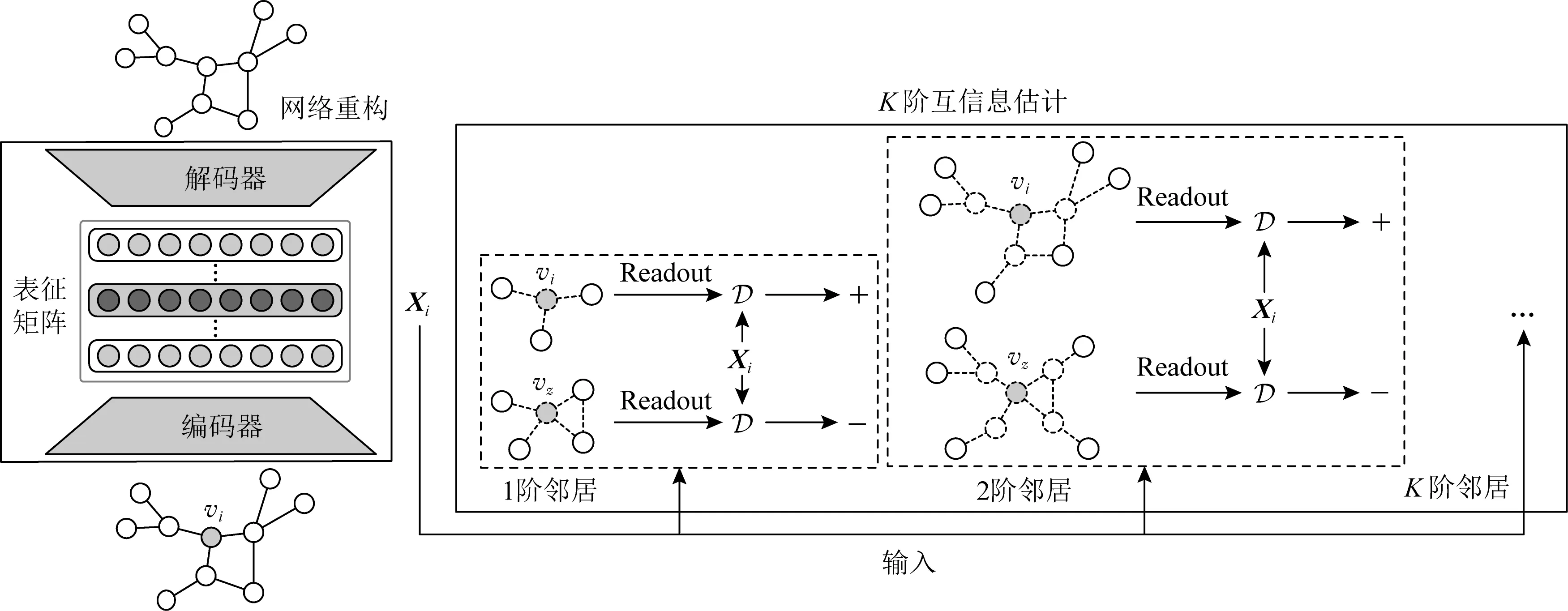
Fig. 3 An illustration of the proposed model PMI圖3 本文提出的PMI模型
(4)
其中JMI代表K階互信息估計模塊的優化函數,而JAE則對應了網絡重構模塊的優化目標,超參數α和β用來權衡兩者.接下來,我們逐一介紹面向K階鄰居的互信息最大化和基于自動編碼機的結構學習模塊,最后對本文方法的復雜度進行分析并給出優化方案.
3.2 面向K階鄰居的互信息估計
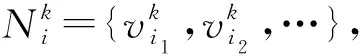
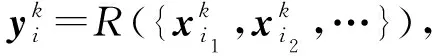
(5)
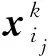
接下來,介紹最大化中心節點vi與第k階鄰居節點集合的互信息.在式(3)的基礎上,我們定義互信息估算公式為

(6)
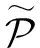
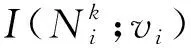
因此,面向第k階鄰居的互信息最大化的優化目標定義為
(7)
其中X是待學習的表征矩陣.最終,總優化目標定義為與階數k相關的加權和:
(8)
考慮到位于更高階的鄰居節點對于中心節點的影響力往往越弱,在式(8)中,我們添加了一個與階數相關的衰減函數Φ(k)來控制不同階的鄰居對于中心節點影響力的強弱,該衰減函數滿足Φ(k+1)≤Φ(k),并且當k>0時有Φ(k)>0.
3.3 基于自動編碼機的結構學習
面向K階鄰居的互信息最大化模塊盡管可以讓節點表征獲取節點對應的位置信息,但無法學習到網絡中最基本的結構信息,即邊信息,而邊信息在多種下游任務中是極其重要和基礎的,丟失該信息將會極大地影響下游任務的效果.因此,PMI模型需要另一個模塊來學習網絡中的基本結構信息.盡管當前對于結構信息的表征學習模型[2,11-12]層出不窮,但我們發現自動編碼機模型是最契合本文方法的一類模型,因為它可以直接建模近鄰間的關系而不對互信息估計產生影響.同時,這也有助于我們設計一種端到端的學習模式.
盡管已有大量工作基于不同假設設計不同的自編碼機模型[11,36-37],但PMI模型僅需要一個能夠捕捉基本結構信息的模塊,因此我們采用一種簡單的自編碼機模型,通過直接重建網絡中的邊來學習網絡結構.
自編碼機的編碼器部分采用2層的DNN(deep neural network),其中第i層的DNN定義為
X(i)=σ(W(i)X(i-1)+b(i)),
(9)
其中,X(i)是第i層DNN的輸入特征,且有X(0)=A為網絡的鄰接矩陣,W(i)和b(i)為待學習的參數,σ(·)為激活函數,這里我們使用修正線性單元ReLu(·)作為激活函數.第2層DNN的輸出就是節點的表征X=X(2).
對于解碼器模塊,我們采用一個簡單的點乘形式重構整個網絡:
Z=σ(XTX),
(10)
其中σ(·)=1/(1+e-x)為sigmoid函數.這種簡單的點乘形式不僅有效減少本模型的參數量,而且可以避免繁重的編碼機預訓練過程[11,38].
最后,自編碼機的優化目標為重構出的網絡與真實網絡的距離:
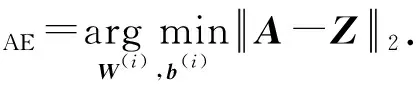
(11)
3.4 復雜度分析
模型的復雜度主要分為2個部分:K階互信息估計模塊和自動編碼機模塊.對于前者,每一階的互信息估算的復雜度為O(d2|V|),對于自動編碼機模塊,DNN層的計算復雜度為O(d(i-1)d(i)|V|),其中d(i-1)和d(i)代表第i層DNN的輸入和輸出維度.因此,整個模型的復雜度為
4 實驗評估
為了評估本文提出的PMI模型的有效性,我們將模型訓練得到的節點表征作為下游網絡分析任務的輸入,測試其在多標簽分類、鏈接預測和網絡重構任務上的效果.此外,為了驗證學到的表征是否能夠捕捉其全局位置信息,我們在4.5節進行對于表征中位置信息的進一步分析,測試模型在鄰居對齊任務上的效果.最后,我們對PMI模型中的參數敏感度進行實驗分析.
4.1 實驗設置
我們使用的真實網絡數據來自多個不同領域,統計數據如表2所示,各個數據集的具體描述如下:
1) PPI[10].該網絡是蛋白質相互作用網絡(protein-protein interactions)的子圖,數據來源于文獻[3].
2) IMDB[39].該網絡數據抽取自MovieLens(1)https://grouplens.org/datasets/movielens/,其中每個節點代表一部電影,節點間的連邊表示2部電影出自同一位導演.
3) WordNet(2)http://www.mattmahoney.net/dc/textdata/.該網絡為維基百科中的單詞共現網絡,每個節點表示一個單詞,而單詞間的連接表示2個單詞在同一個文檔中共同出現.
4) VoteNet[1].該數據來自于斯坦福的公開數據集who-votes-on-whom,是一個投票網絡.

Table 2 Network Statistics表2 各數據集的網絡統計數據
為了驗證PMI模型的效果,我們與當前7種具有代表性的網絡表征學習方法進行比較,包括基于隨機游走的方法(DeepWalk[1]和Node2Vec[10])、基于近鄰估計的方法(LINE[2]和GraRep[12])、基于自動編碼機的方法(SDNE[11])和基于互信息的方法(DGI[34]和GMI[35]).為了公平比較,包括本文方法在內的所有方法的節點表征維度d均設置為128.對于模型Node2Vec,我們采用grid search方法在參數空間p,q∈{0.25,0.5,1,2,4}中搜索其最佳參數;對于LINE,我們分別優化1階近鄰和2階近鄰,并將兩者學到的表征進行拼接獲取最終表征;對于模型GraRep,我們同樣采用grid search在參數空間K∈{1,2,3,4,5}中搜索其最佳超參.由于本文PMI模型僅考慮網絡結構信息,我們將歸一化后的鄰接矩陣作為模型SDNE,DGI,GMI和PMI的輸入.此外,遵循文獻[11]中的策略,我們使用深度置信網絡(deep belief network, DBN)[38]對SDNE模型進行參數初始化.本文方法的其他超參設置為:最大階數K=3,負采樣數目nz=5,自動編碼機的各層輸出維度分別為256和128,超參數α=β=1,并使用Φ(k)=k-1作為衰減函數.
4.2 多標簽分類
我們首先測試各模型在多標簽分類任務上的效果.采用multi-class SVM[40]作為模型分類器,并將節點表征作為SVM的輸入特征來訓練分類器.選擇20%的標簽節點作為訓練樣本,剩下的80%用作測試和效果評估.對于每個模型,重復上述實驗5次并計算每個模型的Micro-F1,實驗結果如表3所示.結果表明,本文方法在所有數據集上均取得最好的效果,在各數據集上分別有1.63%,1.36%和1.59%的提升.進一步分析可以發現:基于隨機游走的方法(DeepWalk和Node2Vec)在各數據集上的效果優于其他對比方法;而LINE和SDNE的表現也較為穩定,但由于這2種方法過于強調近鄰相似,導致整體效果不佳;相比之下,GraRep的表現在各個數據集上非常不穩定,比如其在PPI上的分類效果較差,這主要因為GraRep引入的高階信息中包含了大量的噪音,這些信息影響了節點分類的效果,也影響了節點表征的區分性;另外2種基于互信息的方法DGI和PMI在多標簽分類任務上的表現也欠佳,這2種方法的表征依賴于高質量的節點屬性信息,當輸入的網絡結構信息并不包含具有鮮明特性的局部結構信號時,它們無法學到具有區分性的節點表征.相比之下,由于本文方法采用了一種K階互信息最大化策略,其目的是讓每個節點記住它的各階鄰居,PMI模型可以有效地從上下文信息中學到結構相似性,從而最終在多標簽分類任務上取得較好的效果.

Table 3 Results of Multi-label Classification表3 多標簽分類結果 %
4.3 網絡重構
網絡重構任務測試學到的節點表征是否可以保留原網絡的結構信息.在本文中,實驗設置與文獻[11]類似:每個模型依據學到的表征相似性推理出k條可能在網絡中存在的邊,計算精確率precision@k,該指標表示在k次預測的邊中有多少在原網絡中是真實存在的.我們以IMDB和VoteNet數據集為例,比較每個模型的推理精確率.
如圖4所示,PMI模型在2個數據集上都展現出更加穩定的提升.盡管SDNE和LINE在k較小時表現較優,但當更多的邊需要被推測時(即更大的k),2種方法的精確率都出現大幅度下降.另一個比較有趣的發現是,2種基于互信息的方法(DGI和GMI)也取得了較為不錯的效果,這說明通過加強節點與局部鄰居的互信息或增強節點與全局結構的互信息都有助于表征獲取豐富的網絡結構信息.另一方面,PMI模型由于采用一種K階互信息最大化的策略,使得每個節點的表征都攜帶其全局位置信息,可以在網絡重構任務上取得最好的效果.
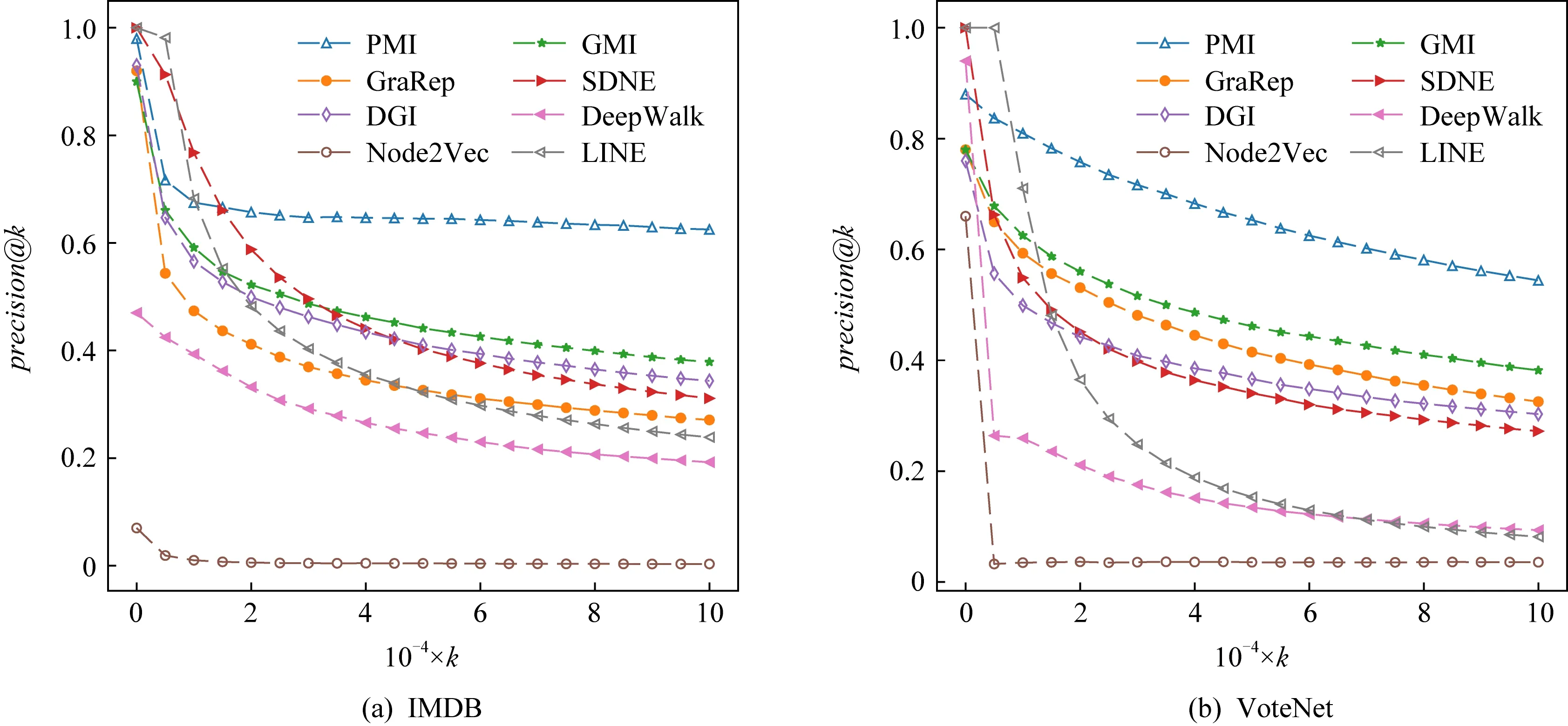
Fig. 4 Performance on network reconstruction圖4 網絡重構結果
4.4 鏈接預測
鏈接預測是網絡分析中的重要任務,其目的在于預測網絡中缺失的或潛在的連接關系,我們通過探究表征是否可以捕捉一些潛在的關聯信息來進一步比較表征質量.對每個網絡數據集,我們首先隨機刪除20%的邊作為測試集,剩下的部分則作為每個模型的輸入用作表征學習.對測試集中的每條邊,我們采樣一條網絡中不存在的邊作為負樣本,將鏈接預測任務轉為二分類任務進行評估,并使用AUC(area under curve)作為評價指標.實驗結果如表4所示.
從實驗結果中可以發現,本文提出的PMI模型在3個數據集上均取得最好的效果,說明采用的K階互信息最大方法可以有效地捕捉網絡結構信息.此外,其他2種基于互信息的方法(DGI和GMI)均可取得非常不錯的效果,結合4.3節在網絡重構任務上的效果,我們可以得到這樣一個結論:最大化節點與其近鄰或全局結構的互信息有助于模型捕捉網絡更深層的結構信息.其他幾種方法,如DeepWalk,Node2Vec,GraRep也在其中幾個數據上取得不錯的效果,但整體效果并不穩定.我們認為出現該問題的原因在于表征無法獲得節點的全局位置信息.直觀上,在圖上距離越近的節點越容易產生關聯,因此節點的位置信息對于鏈接預測任務而言是非常重要的.而相反,本文提出的PMI方法通過最大化中心節點與各階鄰居的互信息,讓中心節點能夠記住其任意階的鄰居,從而使得學到的表征可以保留全局位置信息,捕捉更多網絡結構中的隱藏信息,最終在鏈接預測任務上取得令人滿意的效果.
4.5 案例研究
為了研究本文提出的PMI模型是否可以使得表征學習到節點的全局位置信息,本節進行一個新穎的實驗:鄰居對齊.該實驗的目標是讓每個節點識別來自同一階的節點并區分來自不同階的節點.通過該實驗,我們可以從側面知曉學到的表征是否包含了位置信息.
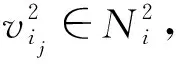
1) 本文方法在2個數據集上均取得最優的效果.這說明通過本文方法學到的節點表征可以有效記住各階的鄰居信息,從而區分不同階的節點.
2) 大部分方法都可以有效地識別1階鄰居,這主要是由于近鄰假設導致1階鄰居節點通常與中心節點在向量空間中更近,因此較為容易區分.但對于其他階的鄰居節點,我們發現大部分方法(尤其是基于隨機游走和自編碼機方法)的效果存在明顯下降,比如SDNE在PPI上區分3階鄰居時僅有52%左右的準確率,而DeepWalk在2個數據集上識別3階鄰居時均只有55%左右的準確率.這些實驗結果均說明當前方法通常會混淆來自不同階的鄰居節點.
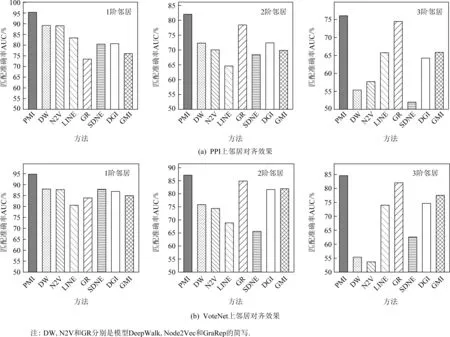
Fig. 5 Results of neighbor alignment圖5 鄰居對齊結果
3) GraRep在區分3階鄰居的效果上與本文方法相當,這是因為GraRep建模節點對間的轉移概率,而較高階的轉移概率會遠小于低階的轉移概率,因此GraRep可以比較有效地識別3階鄰居節點.盡管如此,在2個數據集上GraRep均無法有效地區分近鄰節點(如1階鄰居),這說明GraRep易混淆1階鄰居和其他階的鄰居節點,無法有效地捕捉到節點位置信息.在4.2和4.4節的實驗中,相關任務均要求模型能夠有效地捕捉近鄰信息,本節的實驗結果也解釋了為什么GraRep在之前的實驗中效果并不理想.
小結:本文提出的PMI模型可以激勵節點表征記錄其各階鄰居的信息,從而有效地識別來自于不同階的鄰居節點.結合PMI模型在4.2~4.4節實驗中杰出的表現,我們可以發現節點的位置信息對于下游網絡分析任務而言是極其重要的.
4.6 參數學習
本節探究不同的超參設置對PMI模型的影響.我們選擇PPI和VoteNet兩個數據集,并在2個常見分析任務(多標簽分類和鏈接預測)上進行參數學習.
我們首先研究衰減函數Φ(x)和最大階數K對于模型的影響,比較5種具有不同衰減速度的衰減函數在最大階數K∈{1,2,3,4,5}上的效果,相關實驗結果如圖6(a)所示.從結果中我們發現不同網絡分析任務對于2類超參的偏好是不同的.在多標簽分類任務中,當不考慮衰減函數時(即Φ(x)=1),整體效果會隨著階數K的增大而快速降低;相反,Φ(x)=1在鏈接預測任務上可以取得不錯的效果,其準確率隨K的增大而升高.總體而言,衰減函數Φ(x)=x-1,21-x,e1-x較為契合本文PMI模型.同時,對多標簽分類任務來說,階數K=2較為合適,這也暗示近鄰信息往往決定節點的類別.而相反,隨著K的增大,鏈接預測的效果普遍上升,說明高階信息對于鏈接預測任務是比較重要的,因為高階信息可以讓表征在更加寬的感受野中學習節點的位置信息.
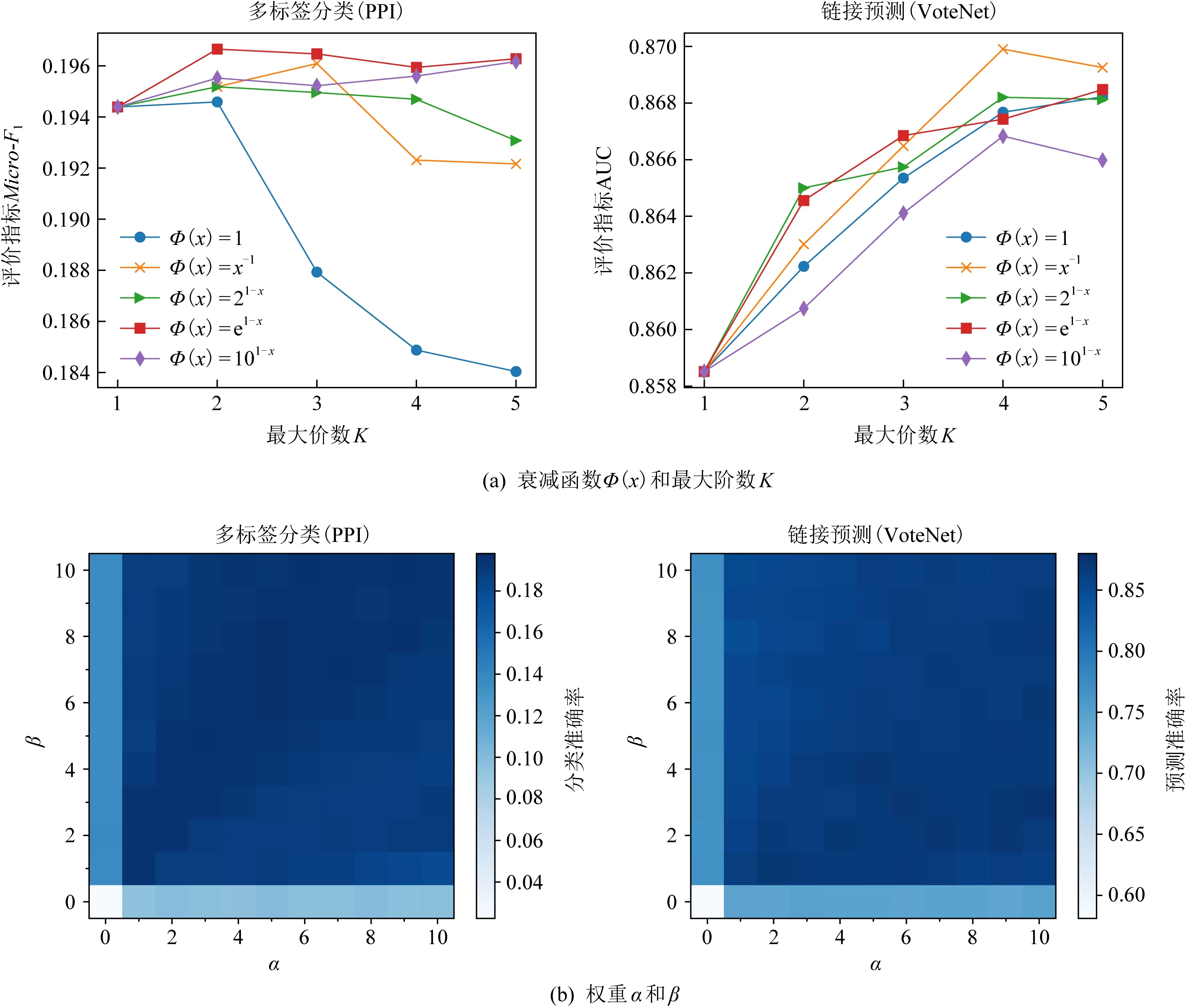
Fig. 6 Parameter study on two different tasks圖6 在2種不同任務上的參數學習結果
接下來,我們研究損失函數中超參α和β對于效果的影響,兩者用于平衡互信息估計和網絡重構損失的權重.我們以0.1為步長,將α和β分別從0.0增加到1.0,并用熱力圖展示不同參數組合對多標簽分類和鏈接預測效果的影響,結果如圖6(b)所示.總體上,PMI模型對于兩者的取值并不是很敏感,但當α和β分別取0時,方法有明顯的下降,這也從側面反映位置信息和結構信息對于節點表征都很重要.另一方面,我們也發現2類任務對于超參的偏好也是不一樣的.對于多標簽分類任務而言,顏色較深的區域往往靠近對角線附近,這說明對于分類任務,位置信息和結構信息同等重要;而對于鏈接預測任務,右下角的區域顏色較深,這意味著一個較大的α值會取得更好的效果,也說明節點的位置信息對于鏈接預測而言更加重要.
5 總 結
本文主要針對現有網絡表征學習方法中位置信息缺失的問題,提出一種位置感知的網絡表征學習PMI模型.在本文方法中,我們最大化每個中心節點與其各階鄰居之間的互信息,從而在訓練的過程中激勵每個節點記住其K階鄰居的信息,我們在4個不同領域的真實數據集上進行了多標簽分類、鏈接預測、網絡重構實驗,實驗結果表明本文所提PMI模型較現有表征學習模型不僅在各類下游網絡分析任務上有所提升,并且通過在鄰居對齊任務上的進一步分析,驗證了PMI模型學到的表征可以有效地獲取節點的位置信息.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中老年保健(2021年12期)2021-11-30 02:58:01
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
中華詩詞(2018年11期)2018-03-26 06:41:34
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年8期)2016-10-09 02:11:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
